Por muitos anos, o Mail.ru sediou campeonatos de aprendizado de máquina, sempre que a tarefa é interessante e complexa. Esta é a minha quarta vez participando de competições, gosto muito da plataforma e da organização e foi com bootcamps que meu caminho para o aprendizado competitivo de máquinas começou, mas consegui ocupar o primeiro lugar pela primeira vez. No artigo, mostrarei como mostrar um resultado estável sem reciclagem na tabela de classificação pública ou em amostras atrasadas, se a parte do teste for significativamente diferente da parte de treinamento dos dados.
Desafio
O texto completo da tarefa está disponível no
link →. Em resumo: existem 10 GB de dados, em que cada linha contém três tipos json de "chave: contador", uma determinada categoria, um determinado carimbo de data e hora e um ID do usuário. Várias entradas podem corresponder a um usuário. É necessário determinar a qual classe o usuário pertence, a primeira ou a segunda. A métrica de qualidade para o modelo é ROC-AUC, está bem escrita sobre isso no blog de Alexander Dyakonov
[1] .
Entrada de arquivo de exemplo
00000d2994b6df9239901389031acaac 5 {"809001":2,"848545":2,"565828":1,"490363":1} {"85789":1,"238490":1,"32285":1,"103987":1,"16507":2,"6477":1,"92797":2} {} 39
Solução
A primeira ideia que surge de um cientista de dados que baixou com êxito um conjunto de dados é transformar as colunas json em uma matriz esparsa. Neste ponto, muitos participantes tiveram problemas com a falta de RAM. Ao implantar uma única coluna em python, o consumo de memória era maior do que o disponível em um laptop comum.
Algumas estatísticas secas. O número de chaves exclusivas em cada coluna é 2053602, 20275, 1057788. Além disso, na parte do trem e na parte de teste, existem apenas 493866, 20268, 141931. 427994 usuários únicos no trem e 181024 na parte de teste. Aproximadamente 4% da classe 1 na parte de treinamento.
Como você pode ver, temos muitos sinais, usá-los todos é uma maneira óbvia de superajustar no trem, porque, por exemplo, as árvores de decisão usam combinações de sinais, e existem ainda mais combinações únicas de um número tão grande de sinais e quase todos eles existem apenas na parte de treinamento dados ou em teste. No entanto, um dos modelos básicos que eu tinha era lightgbm com amostra de col ~ ~ 0.1 e regularização muito estrita. No entanto, apesar dos enormes parâmetros de regularização, mostrou um resultado instável nas partes pública e privada, como ocorreu após o término da competição.
O segundo pensamento da pessoa que decidiu participar dessa competição provavelmente seria coletar o trem e o teste, agregando informações por identificadores. Por exemplo, a quantidade. Ou no máximo. E aqui acontece duas coisas muito interessantes que o Mail.ru inventou para nós. Em primeiro lugar, o teste pode ser classificado com uma precisão muito alta. Mesmo de acordo com estatísticas sobre o número de entradas para cuid e o número de chaves exclusivas em json, o teste excede significativamente o trem. O classificador base deu 0,9+ roc-auc no reconhecimento do teste. Em segundo lugar, os contadores não fazem sentido, quase todos os modelos passaram da mudança de contadores para sinais binários da forma: não há / não há chave. Até as árvores, que em teoria não deveriam ser piores pelo fato de que, em vez de uma unidade, há um certo número, parecem ser recicladas para contadores.
Os resultados no ranking público excederam muito os da validação cruzada. Aparentemente, isso se deve ao fato de o modelo ter sido mais fácil de construir o ranking de dois registros no teste do que no trem, porque um número maior de sinais indicava mais termos para o ranking.
Nesta fase, ficou completamente claro que a validação nesta competição não é uma coisa simples e nem informações públicas nem currículos de outros participantes, que poderiam ser levados a atrair no bate-papo oficial
[2] . Por que isso aconteceu? Parece que o trem e o teste são separados por tempo, o que foi confirmado mais tarde pelos organizadores.
Qualquer membro experiente do kaggle aconselhará imediatamente a validação Adversarial
[3] , mas não é assim tão simples. Apesar de a precisão do classificador para o trem e o teste ser próxima de 1 pelo roc-auc métrico, não há muitas entradas semelhantes no trem. Tentei resumir amostras agregadas a cuid com o mesmo objetivo para aumentar o número de registros com um grande número de chaves exclusivas em json, mas isso causou inconvenientes na validação cruzada e em público, e eu tinha medo de usar esses modelos.
Há duas maneiras: procure valores eternos com aprendizado não supervisionado ou tente usar recursos que são mais importantes para o teste. Eu fui nos dois sentidos, usando o TruncatedSVD para não supervisionar e selecionando os recursos pela frequência no teste.
A primeira etapa, no entanto, fiz um auto-codificador profundo, mas me enganei, pegando a mesma matriz duas vezes, não consegui corrigir o erro e usei todo o conjunto de sinais: o tensor de entrada não se encaixava na memória da GPU em nenhum tamanho de camada densa. Eu encontrei um erro e, mais tarde, não tentei codificar recursos.
Gerei SVD de todas as maneiras imaginativas: no conjunto de dados original com cat_feature e no subsequente somatório por cuid. Para cada coluna separadamente. Por tf-idf em json como saco de palavras
[4] (não ajudou).
Para uma variedade maior, tentei selecionar um pequeno número de recursos no trem, usando A-NOVA para a parte do trem de cada dobra na validação cruzada.
Modelos
Os principais modelos básicos: lightgbm, vowpal wabbit, xgboost, SGD. Além disso, usei várias arquiteturas de redes neurais. Dmitry Nikitko, que ocupava o primeiro lugar no ranking público, aconselhou o uso do
HashEmbeddings , este modelo após uma seleção de parâmetros mostrou um bom resultado e melhorou o conjunto.
Outro modelo de rede neural com busca de interações (estilo de máquina de fatoração) entre 3-4-5 colunas de dados (três entradas à esquerda), estatística numérica (4 entradas), matriz SVD (5 entradas).
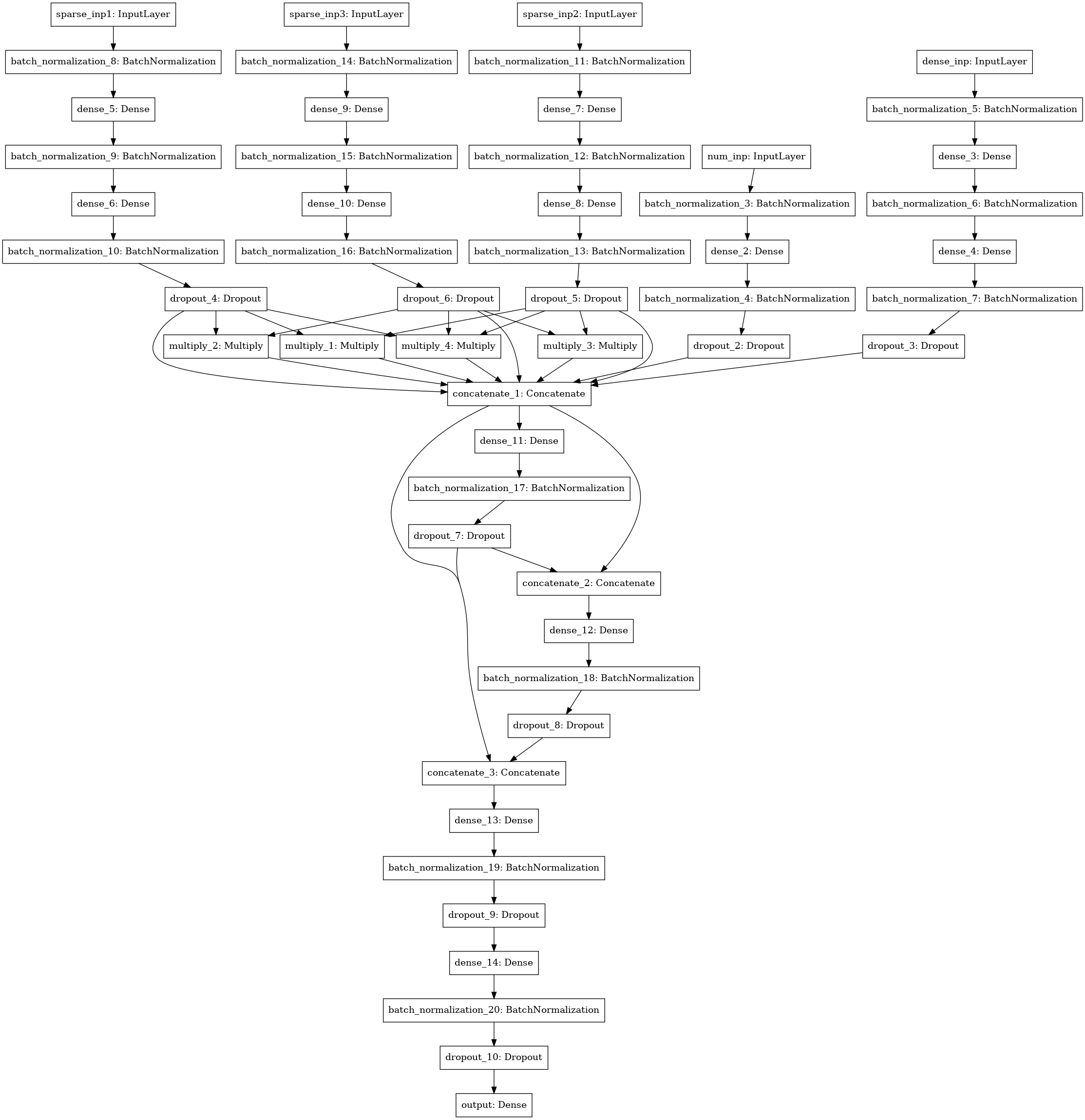
Ensemble
Eu contei todos os modelos por dobras, calculando a média das previsões dos modelos treinados em várias dobras. As previsões de trem foram usadas para empilhamento. O melhor resultado foi mostrado pela pilha de nível 1 usando xgboost nas previsões dos modelos de base e 250 atributos de cada coluna json, selecionados de acordo com a frequência com que o atributo se encontrou no teste.
Passei ~ 30 horas do meu tempo na solução, contando com um servidor com 4 núcleos core-i7, 64 gigabytes de RAM e um GTX 1080. Como resultado, minha solução se mostrou bastante estável e passei do terceiro lugar no ranking público para o primeiro privado.
Uma parte substancial do código está disponível em um bitbucket na forma de laptops
[5] .
Quero agradecer ao Mail.ru por concursos interessantes e outros participantes pela comunicação interessante no grupo!
[1]
ROC-AUC no blog de Aleksandrov Dyakonov[2]
Official Chat ML BootCamp official[3]
Validação adversa[4]
palavras-chave[5]
código fonte para a maioria dos modelos