
As tarefas de armazenamento e acesso a dados são um ponto problemático para qualquer sistema de informação. Mesmo um sistema de armazenamento bem projetado (doravante denominado SHD) durante a operação revela problemas associados a desempenho reduzido. Atenção especial deve ser dada a um conjunto de problemas de dimensionamento quando a quantidade de recursos envolvidos se aproximar dos limites estabelecidos pelos desenvolvedores de armazenamento.
A razão fundamental para a ocorrência desses problemas é a arquitetura tradicional baseada em forte ligação às características de hardware dos dispositivos de armazenamento usados. A maioria dos clientes ainda escolhe o método de armazenamento e acesso a dados, levando em consideração as características das interfaces físicas (SAS / SATA / SCSI), e não as reais necessidades dos aplicativos utilizados.
Há doze anos, essa foi uma decisão lógica. Os administradores de sistema selecionaram cuidadosamente os dispositivos de armazenamento de informações com as especificações necessárias, por exemplo SATA / SAS, e contaram com a obtenção de um nível de desempenho com base nos recursos de hardware dos controladores de disco. A luta foi pelo volume de caches do controlador RAID e por opções que impedem a perda de dados. Agora, essa abordagem para resolver o problema não é ideal.
No ambiente atual, ao escolher sistemas de armazenamento, faz sentido iniciar não a partir de interfaces físicas, mas a partir do desempenho expresso em IOPS (o número de operações de E / S por segundo). O uso da virtualização permite usar com flexibilidade os recursos de hardware existentes e garantir o nível de desempenho necessário. De nossa parte, estamos prontos para fornecer recursos com as características realmente necessárias para a aplicação.
Virtualização de armazenamento
Com o desenvolvimento de sistemas de virtualização, foi necessário encontrar uma solução inovadora para armazenar e acessar dados, garantindo a tolerância a falhas. Este foi o ponto de partida para a criação de SDS (armazenamento definido por software). Para atender às necessidades de negócios, esses repositórios foram projetados com a separação de software e hardware.
A arquitetura do SDS é fundamentalmente diferente da tradicional. A lógica de armazenamento ficou abstraída no nível do software. A organização do armazenamento tornou-se mais fácil devido à unificação e virtualização de cada um dos componentes desse sistema.
Qual é o principal fator que dificulta a implementação do SDS em todos os lugares? Esse fator geralmente é uma avaliação incorreta das necessidades dos aplicativos utilizados e uma avaliação de risco incorreta. Para uma empresa, a escolha da solução depende do custo de implementação, com base nos recursos atuais consumidos. Poucas pessoas pensam - o que acontecerá quando a quantidade de informações e o desempenho necessário excederem os recursos da arquitetura selecionada. Pensando na base do princípio metodológico “não se deve multiplicar a existência sem necessidade”, mais conhecida como “lâmina de Occam”, determina a escolha em favor das soluções tradicionais.
Poucos entendem que a necessidade de escalabilidade e confiabilidade do armazenamento de dados é mais importante do que parece à primeira vista. A informação é um recurso e, portanto, o risco de sua perda deve ser segurado. O que acontecerá quando um sistema de armazenamento tradicional for desativado? Você precisará usar a garantia ou comprar novos equipamentos. E se o sistema de armazenamento for descontinuado ou tiver terminado o "tempo de vida" (o chamado EOL - Fim da Vida)? Pode ser um dia sombrio para qualquer organização que não pode continuar usando seus próprios serviços familiares.
Não há sistemas que não tenham um único ponto de falha. Mas existem sistemas que podem sobreviver facilmente à falha de um ou mais componentes. Os sistemas de armazenamento virtual e tradicional foram criados levando em consideração o fato de que mais cedo ou mais tarde ocorrerá uma falha. Esse é apenas o "limite de força" dos sistemas de armazenamento tradicionais estabelecidos no hardware, mas nos sistemas de armazenamento virtual é determinado na camada de software.
Integração
Mudanças dramáticas na infraestrutura de TI são sempre um fenômeno indesejável, repleto de tempo de inatividade e perda de fundos. Somente a implementação tranquila de novas soluções permite evitar consequências negativas e melhorar o trabalho dos serviços. Por isso, a Selectel projetou e
lançou a nuvem com base na VMware , líder reconhecida no mercado de virtualização. O serviço criado por nós permitirá que cada empresa resolva toda a gama de tarefas de infraestrutura, incluindo armazenamento de dados.
Vamos dizer exatamente como decidimos sobre a escolha de um sistema de armazenamento, bem como quais vantagens essa escolha nos deu. Obviamente, os sistemas de armazenamento tradicionais e o SDS foram considerados. Para entender claramente todos os aspectos de operação e riscos, oferecemos uma visão mais profunda do tópico.
Na fase de design, os seguintes requisitos foram impostos aos sistemas de armazenamento:
- tolerância a falhas;
- performance
- escala
- a capacidade de garantir velocidade;
- operação correta no ecossistema VMware.
O uso de soluções de hardware tradicionais não poderia fornecer o nível de escalabilidade necessário, pois é impossível aumentar constantemente o volume de armazenamento devido a limitações de arquitetura. A reserva no nível de um data center inteiro também foi de grande dificuldade. Por isso, voltamos nossa atenção para o SDS.
Existem várias soluções de software no mercado de SDS que nos serviriam para criar uma nuvem baseada no VMware vSphere. Entre essas soluções, podemos destacar:
- Dell EMC ScaleIO;
- SAN virtual hiperconvergente do Datacore;
- HPE StoreVirtual.
Essas soluções são adequadas para uso com o VMware vSphere, no entanto, elas não se integram ao hypervisor e são executadas separadamente. Portanto, a escolha foi feita em favor do VMware vSAN. Vamos considerar em detalhes como é a arquitetura virtual dessa solução.
Arquitetura
Imagem retirada da documentação oficialAo contrário dos sistemas de armazenamento tradicionais, todas as informações não são armazenadas em nenhum momento. Os dados da máquina virtual são distribuídos igualmente entre todos os hosts e o dimensionamento é feito adicionando hosts ou instalando unidades de disco adicionais neles. Duas opções de configuração são suportadas:
- Configuração AllFlash (apenas unidades de estado sólido, tanto para armazenamento de dados quanto para cache);
- Configuração híbrida (armazenamento magnético e cache de estado sólido).
O procedimento para adicionar espaço em disco não requer configurações adicionais, por exemplo, criando um LUN (número da unidade lógica, números de disco lógico) e configurando o acesso a eles. Assim que o host é adicionado ao cluster, seu espaço em disco fica disponível para todas as máquinas virtuais. Essa abordagem tem várias vantagens significativas:
- falta de ligação ao fabricante do equipamento;
- tolerância a falhas aumentada;
- garantir a integridade dos dados em caso de falha;
- único centro de controle do console do vSphere;
- escala horizontal e vertical conveniente.
No entanto, essa arquitetura exige muito da infraestrutura de rede. Para garantir o máximo rendimento, em nossa nuvem, a rede é construída no modelo Spine-Leaf.
Rede
O modelo de rede tradicional de três camadas (núcleo / agregação / acesso) tem várias desvantagens significativas. Um exemplo marcante são as limitações dos protocolos Spanning Tree.
O modelo Spine-Leaf usa apenas dois níveis, o que oferece as seguintes vantagens:
- distância previsível entre dispositivos;
- o tráfego segue a melhor rota;
- facilidade de dimensionamento;
- Exclusão de restrições do protocolo L2.
Uma característica importante de uma arquitetura desse tipo é que ela é otimizada para a passagem de tráfego "horizontal". Os pacotes de dados passam por apenas um salto, o que permite uma estimativa clara dos atrasos.
Uma conexão física é fornecida usando vários links de 10 GbE por servidor, cuja largura de banda é combinada usando o protocolo de agregação. Assim, cada host físico recebe acesso de alta velocidade a todos os objetos de armazenamento.
A troca de dados é implementada usando um protocolo proprietário criado pela VMware, que permite a operação rápida e confiável da rede de armazenamento no transporte Ethernet (de 10 GbE e superior).
A transição para o modelo de objeto de armazenamento de dados permitiu um ajuste flexível do uso do armazenamento, de acordo com os requisitos dos clientes. Todos os dados são armazenados na forma de objetos que são distribuídos de uma certa maneira entre os hosts do cluster. Esclarecemos os valores de alguns parâmetros que podem ser controlados.
Tolerância a falhas
- FTT (Falhas em tolerar). Indica o número de falhas do host que o cluster pode manipular sem interromper a operação regular.
- FTM (Método de tolerância a falhas). O método de garantir tolerância a falhas no nível do disco.
a. Espelhamento
Imagem retirada do blog VMware.
Representa uma duplicação completa de um objeto e as réplicas sempre estão localizadas em diferentes hosts físicos. O análogo mais próximo desse método é o RAID-1. Seu uso permite que o cluster processe rotineiramente até três falhas de qualquer componente (discos, hosts, perda de rede etc.). Este parâmetro é configurado definindo a opção FTT.
Por padrão, essa opção tem o valor 1 e 1 réplica é criada para o objeto (apenas 2 instâncias em hosts diferentes). À medida que o valor aumenta, o número de cópias será N + 1. Assim, com um valor máximo de FTT = 3, 4 instâncias do objeto estarão em hosts diferentes.
Este método permite atingir o desempenho máximo às custas da eficiência do espaço em disco. Pode ser usado nas configurações híbrida e AllFlash.
b. Codificação de apagamento (análogo do RAID 5/6).
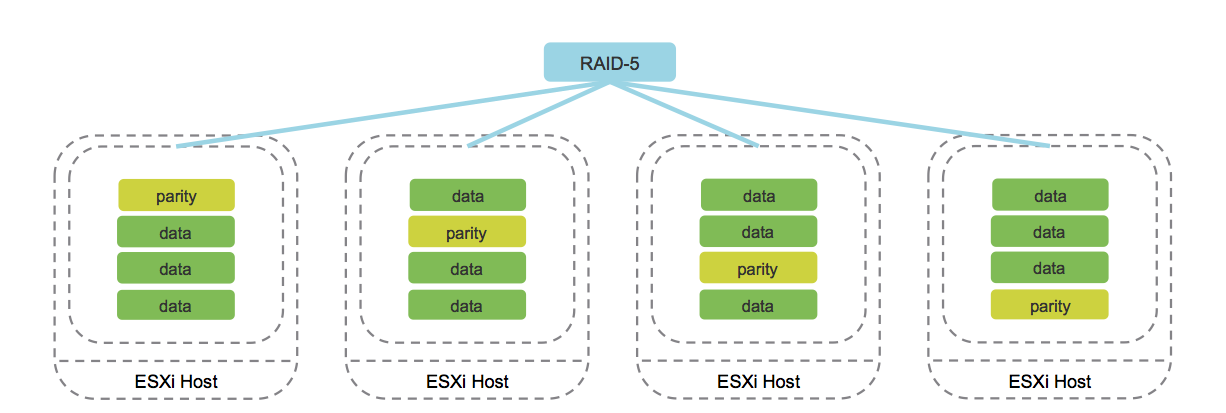
Imagem retirada do blog cormachogan.com.
O trabalho deste método é suportado exclusivamente nas configurações do AllFlash. No processo de registro de cada objeto, são calculados os blocos de paridade correspondentes, que permitem recuperar dados de maneira exclusiva em caso de falha. Essa abordagem economiza significativamente espaço em disco comparado ao espelhamento.
Obviamente, a operação desse método aumenta a sobrecarga, que é expressa em uma diminuição na produtividade. No entanto, dado o desempenho da configuração do AllFlash, essa desvantagem é nivelada, tornando o uso do Erasure Coding uma opção aceitável para a maioria das tarefas.
Além disso, o VMware vSAN apresenta o conceito de "domínios de falha", que são um agrupamento lógico de racks de servidor ou cestas de disco. Assim que os elementos necessários são agrupados, isso leva à distribuição de dados entre diferentes nós, levando em consideração os domínios de falha. Isso permite que o cluster sobreviva à perda de um domínio inteiro, pois todas as réplicas correspondentes dos objetos estarão localizadas em outros hosts em um domínio de falha diferente.
O menor domínio de falha é um grupo de discos, que é uma unidade de disco conectada logicamente. Cada grupo de discos contém dois tipos de mídia - cache e capacidade. Como uma mídia de cache, o sistema permite usar apenas discos de estado sólido, e os discos magnéticos e de estado sólido podem atuar como portadores de capacidade. A mídia de cache ajuda a acelerar os discos magnéticos e a reduzir a latência ao acessar dados.
Implementação
Vamos falar sobre quais limitações existem na arquitetura VMware vSAN e por que são necessárias. Independentemente das plataformas de hardware usadas, a arquitetura fornece as seguintes restrições:
- não mais que 5 grupos de discos por host;
- não mais que 7 portadores de capacidade em um grupo de discos;
- não mais que 1 portadora de cache em um grupo de discos;
- não mais que 35 transportadoras de capacidade por host;
- não mais que 9000 componentes por host (incluindo componentes testemunha);
- não mais que 64 hosts em um cluster;
- não mais que 1 vSAN-datastore por cluster.
Por que isso é necessário? Até que os limites especificados sejam excedidos, o sistema operará com a capacidade declarada, mantendo um equilíbrio entre desempenho e capacidade de armazenamento. Isso permite garantir a operação correta de todo o sistema de armazenamento virtual como um todo.
Além dessas limitações, um recurso importante deve ser lembrado. Não é recomendável preencher mais de 70% do volume total de armazenamento. O fato é que, quando 80% é alcançado, o mecanismo de reequilíbrio é iniciado automaticamente e o sistema de armazenamento começa a redistribuir dados em todos os hosts do cluster. O procedimento consome bastante recursos e pode afetar seriamente o desempenho do subsistema de disco.
Para atender às necessidades de uma ampla variedade de clientes, implementamos três pools de armazenamento para facilitar o uso em vários cenários. Vamos olhar para cada um deles em ordem.
Conjunto de discos rápido
A prioridade para a criação desse pool era obter armazenamento que proporcionasse desempenho máximo para hospedar sistemas altamente carregados. Os servidores desse pool usam um par de Intel P4600 como cache e 10 Intel P3520 para armazenamento de dados. O cache neste pool é usado para que os dados sejam lidos diretamente da mídia e as operações de gravação ocorram no cache.
Para aumentar a capacidade útil e garantir a tolerância a falhas, é usado um modelo de armazenamento de dados chamado Erasure Coding. Esse modelo é semelhante a uma matriz RAID 5/6 regular, mas no nível de armazenamento de objetos. Para eliminar a probabilidade de corrupção de dados, o vSAN usa um mecanismo de cálculo de soma de verificação para cada bloco de dados 4K.
A validação é realizada em segundo plano durante as operações de leitura / gravação, bem como para dados "frios", cujo acesso não foi solicitado durante o ano. Quando a incompatibilidade de soma de verificação é detectada e, portanto, a corrupção de dados é detectada, o vSAN recupera automaticamente os arquivos sobrescrevendo.
Conjunto de unidades híbridas
No caso desse pool, sua principal tarefa é fornecer uma grande quantidade de dados, garantindo um bom nível de tolerância a falhas. Para muitas tarefas, a velocidade do acesso aos dados não é uma prioridade, o volume e o custo do armazenamento são muito mais importantes. O uso de unidades de estado sólido como esse armazenamento terá um custo excessivamente alto.
Esse fator foi o motivo da criação do pool, que é um híbrido de armazenamento em cache de unidades de estado sólido (como em outros pools é o Intel P4600) e discos rígidos de nível empresarial desenvolvidos pela HGST. Um fluxo de trabalho híbrido acelera o acesso aos dados solicitados com freqüência armazenando em cache as operações de leitura e gravação.
No nível lógico, os dados são espelhados para eliminar a perda no caso de uma falha de hardware. Cada objeto é dividido em componentes idênticos e o sistema os distribui para diferentes hosts.
Piscina com recuperação de desastres

A principal tarefa do pool é atingir o nível máximo de tolerância a falhas e desempenho. O uso da tecnologia
Stretched vSAN nos permitiu
distribuir o armazenamento entre os data centers Tsvetochnaya-2 em São Petersburgo e Dubrovka-3 na região de Leningrado. Cada servidor neste pool está equipado com um par de unidades Intel P4600 de alta capacidade e alta velocidade para operação em cache e 6 unidades Intel P3520 para armazenamento de dados. No nível lógico, esses são 2 grupos de discos por host.
A configuração do AllFlash não tem uma desvantagem séria - uma queda acentuada no IOPS e um aumento na fila de solicitações de disco com um volume aumentado de acesso aleatório aos dados. Assim como em um pool com discos rápidos, as operações de gravação passam pelo cache e a leitura é feita diretamente.
Agora, sobre a principal diferença do resto das piscinas. Os dados de cada máquina virtual são espelhados dentro de um data center e, ao mesmo tempo, replicados de forma síncrona para outro data center pertencente a nós. Assim, mesmo um acidente grave, como uma interrupção completa da conectividade entre data centers, não será um problema. Mesmo uma perda completa do data center não afetará os dados.
Um acidente com uma falha completa do site - a situação é bastante rara, mas o vSAN pode sobreviver com honra sem perder dados. Os convidados do nosso evento
SelectelTechDay 2018 puderam ver por si mesmos como o cluster vSAN estendido sofreu uma falha completa no site. As máquinas virtuais ficaram disponíveis apenas um minuto depois que todos os servidores em um dos sites foram desligados pela energia. Todos os mecanismos funcionaram exatamente como planejado, mas os dados permaneceram intocados.
O abandono da arquitetura de armazenamento familiar acarreta muitas mudanças. Uma dessas mudanças foi o surgimento de novas "entidades" virtuais, que incluem o dispositivo testemunha. O significado desta solução é rastrear o processo de gravação de réplicas de dados e determinar qual é relevante. Ao mesmo tempo, os dados em si não são armazenados nos componentes testemunha, apenas metadados sobre o processo de gravação.
Esse mecanismo entra em vigor no caso de um acidente, quando ocorre uma falha durante o processo de replicação, o que resulta em réplicas fora de sincronia.
Para determinar qual delas contém informações relevantes, é usado um mecanismo de determinação de quorum. Cada componente tem um "direito de voto" e recebe um certo número de votos (1 ou mais). O mesmo “direito de voto” possui componentes de testemunhas que desempenham o papel de árbitros em caso de situação controversa.
Um quorum é alcançado apenas quando uma réplica completa está disponível para um objeto e o número de "votos" atuais é superior a 50%.
Conclusão
A escolha do VMware vSAN como sistema de armazenamento tornou-se uma decisão importante para nós. Essa opção passou no teste de estresse e no teste de tolerância a falhas antes de ser incluída em nosso projeto de nuvem baseado em VMware.
De acordo com os resultados do teste, ficou claro que a funcionalidade declarada funciona conforme o esperado e atende a todos os requisitos de nossa infraestrutura de nuvem.
Tem algo a dizer com base em sua própria experiência com o vSAN? Bem-vindo aos comentários.