Alguns meses atrás, foi lançada a primeira versão do Kepler.gl - uma nova ferramenta de código-fonte aberto para visualizar e analisar grandes conjuntos de dados geográficos.
Neste artigo, sugiro que você se familiarize com os principais recursos do aplicativo e crie usando duas visualizações cartográficas que nos permitirão descobrir alguns fatos interessantes sobre estacionamento pago em Moscou.
Mas primeiro, algumas palavras sobre quem e por que criaram o Kepler.gl
Inicialmente, o Kepler.Gl foi criado pela equipe de engenharia da Uber para analistas de empresas que queriam entender melhor "como a cidade está se movendo", usando para isso uma enorme quantidade de dados de tráfego de informações geográficas coletadas diariamente por milhares de "uber" em várias cidades do mundo.
No entanto, em maio deste ano, a empresa anunciou o acesso aberto a este aplicativo e publicou todo o código-fonte do Kepler.gl no GitHub
Principais recursos do Kepler.gl
Independentemente das ferramentas de análise de dados selecionadas, dos serviços ou estruturas de mapas usados, bem como das bibliotecas para criar várias visualizações, o processo de trabalhar nelas é reduzido para 4 estágios principais:
- coleta de informações
- processamento de dados
- pesquisa e análise de dados preparados (para identificar dependências, procurar anomalias etc.)
- criação de visualização
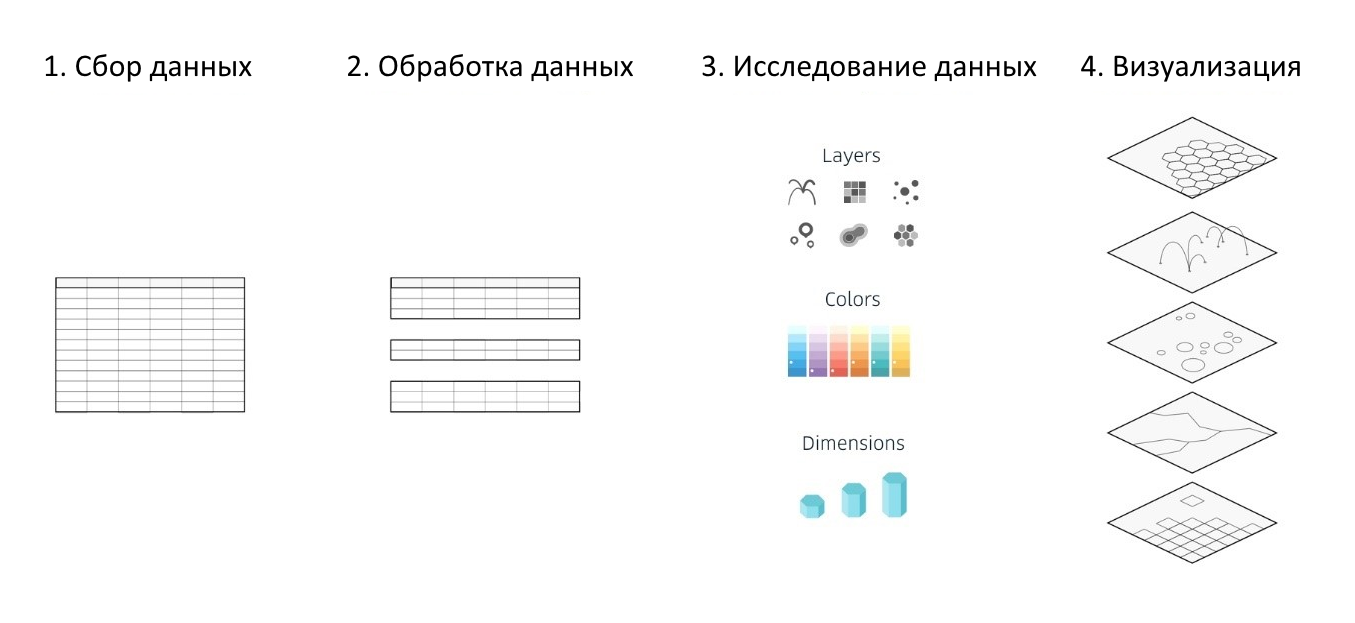 Figura 1. Os estágios básicos da criação de uma visualização
Figura 1. Os estágios básicos da criação de uma visualizaçãoO Kepler.gl automatiza e simplifica parcialmente 3 das 4 etapas listadas, o que simplifica significativamente todo o processo de análise e visualização de grandes conjuntos de dados e ajuda a criar um mapa interativo informativo e, o mais importante, colorido, baseado em seus próprios conjuntos de dados geográficos em apenas meia hora.
Ao mesmo tempo, a experiência de programação ou design não é absolutamente necessária, porque a filtragem e a agregação de dados, escolhendo uma maneira de exibir dados, dependendo de vários parâmetros dos objetos em estudo, sobrepondo informações de várias fontes, alternando entre os modos 2D e 3D e muito mais são configuradas usando o painel da interface do usuário.
Como usar o Kepler.gl para análise de dados
A maneira mais fácil é começar a conhecer o Kepler.gl usando sua versão online, disponível no
kepler.gl ou, se você não confia em servidores de terceiros, pode implantar uma versão local para si mesmo, seguindo as instruções no
GitHub .
A seguir, usarei os dados sobre "Estacionamento pago em Moscou" fornecidos pelo "Portal de Dados Abertos" do governo de Moscou. Este conjunto contém informações sobre mais de 9 mil objetos localizados na rede de ruas, incluindo informações sobre o custo e o número de vagas de estacionamento.
Etapa 1. Carregamento de Dados
Até o momento, o Kepler.gl suporta três formatos de dados de origem: geojson, json e csv. Depois de salvar os dados em um dos formatos indicados (neste exemplo eu uso .csv), simplesmente os carregamos no aplicativo. A propósito, aqui, na caixa de diálogo de download, para se familiarizar com o aplicativo, você também pode usar uma das dezenas de conjuntos de dados de teste predefinidos.
Nota Para o Chrome, o tamanho máximo do arquivo de upload não deve exceder 250 Mb. Os criadores do Kepler.gl sugerem o uso do Safari se você precisar baixar um arquivo maior. No entanto, em qualquer caso, é necessário lembrar que o desempenho do aplicativo depende do dispositivo no qual está sendo executado. Afinal, todas as manipulações associadas à agregação, filtragem e exibição de dados ocorrem no cliente.
Etapa 2. Exibindo Dados em um Mapa
O aplicativo suporta 9 tipos de camadas de visualização (camada de visualização de dados), que diferem entre si em um conjunto de parâmetros personalizáveis:
- camada pontual
- camada de arcos (arco)
- camada de linhas (linha)
- grade (grade)
- grade hexagonal (Hexbin)
- polígonos de camada (Poligon)
- camada de cluster (Claster)
- camada de ícone (ícone)
- mapa de calor (mapa de calor)
Além disso, mesmo as camadas do mesmo tipo, exibindo o mesmo conjunto de dados, podem diferir drasticamente, dependendo da configuração selecionada.

Figura 2. Mapas criados no kepler.gl usando vários tipos de camadas
O Kepler.gl não limita o número de camadas usadas ao exibir o conjunto de dados de teste. As camadas são desenhadas no mapa na mesma ordem em que estão localizadas na lista de camadas no painel lateral. Essa sequência pode ser facilmente alterada simplesmente arrastando as camadas correspondentes uma na outra na guia Camadas.
Ao usar várias camadas, preste atenção ao parâmetro "Layer Blending", responsável por como as camadas se sobrepõem. É uniforme durante toda a visualização, o que torna impossível o uso de diferentes tipos de mistura para diferentes camadas.
Atualmente, três valores para este parâmetro estão disponíveis:
- Normal
Nesse caso, as camadas inferiores não afetam a cor dos pontos (ou outros elementos) das camadas superiores.
- Aditivo
Com esse tipo de sobreposição, os valores de cor dos elementos correspondentes são somados. É conveniente para identificar áreas de alta densidade, que neste caso serão mais brilhantes. - Subtrativo
Diferentemente do aditivo, ele não adiciona, mas subtrai o significado das cores nas áreas que se cruzam. É conveniente quando se usa um cartão não escuro, mas claro.
Assim, para visualizar nossos dados no mapa, é necessário criar pelo menos uma camada usando-os. Vale ressaltar que, após o download do arquivo, o Kepler.gl tentará identificar os campos que contêm informações de localização geográfica e exibi-los instantaneamente, criando automaticamente camadas dos tipos correspondentes (geralmente ponto ou polígono).
No entanto, no nosso caso, devido à diferença nos formatos de dados esperado e usado, você deverá especificar a fonte de coordenadas. Para fazer isso, primeiro exclua as camadas de polígono criadas por Kepler.gl e, em seguida, adicione manualmente uma nova camada de tipo Ponto. Como fonte de coordenadas, usamos os campos Latitude_WGS84 e Longitude_WGS84 em vez do campo Coordenadas selecionado automaticamente pelo aplicativo para renderizar dados no mapa.
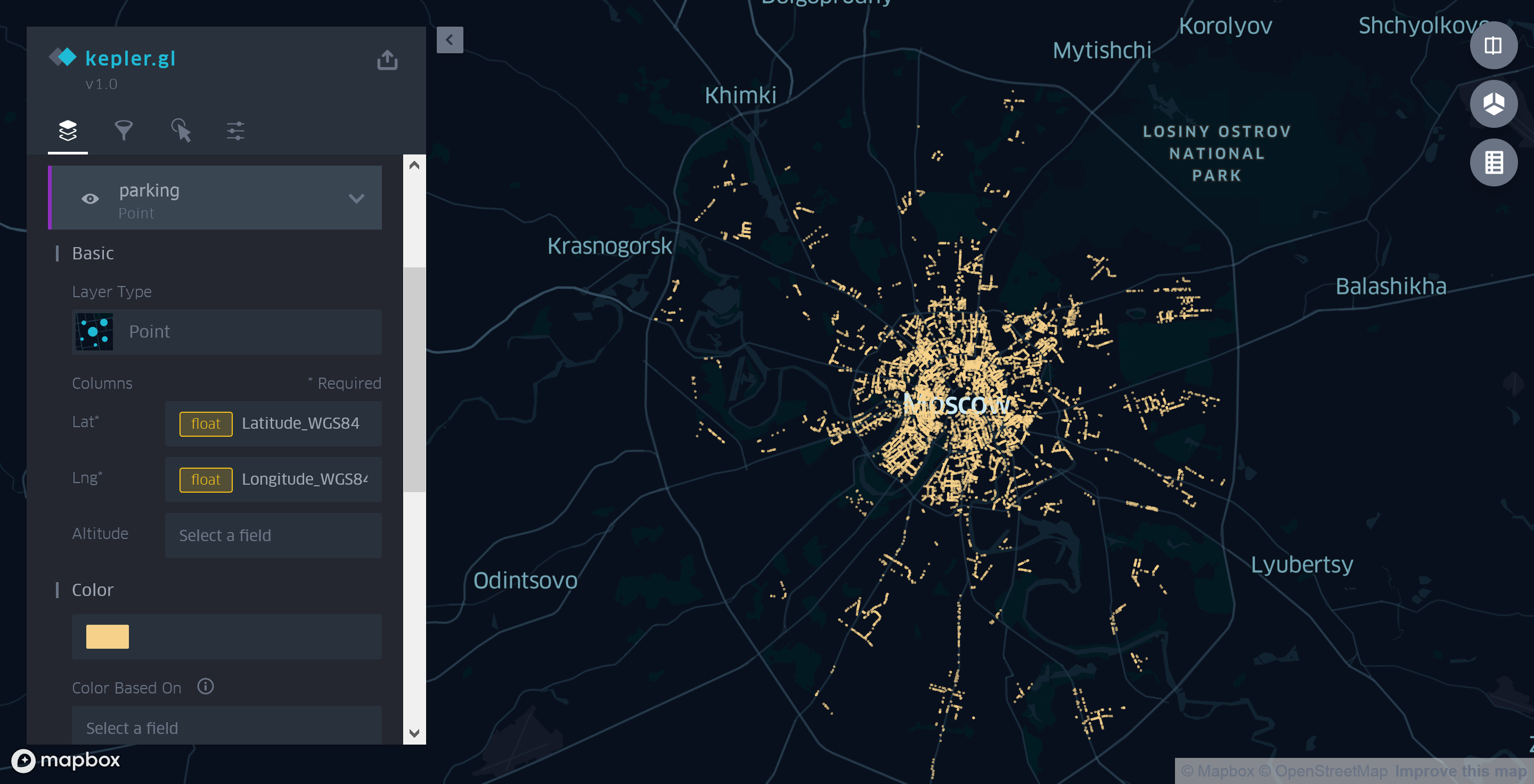
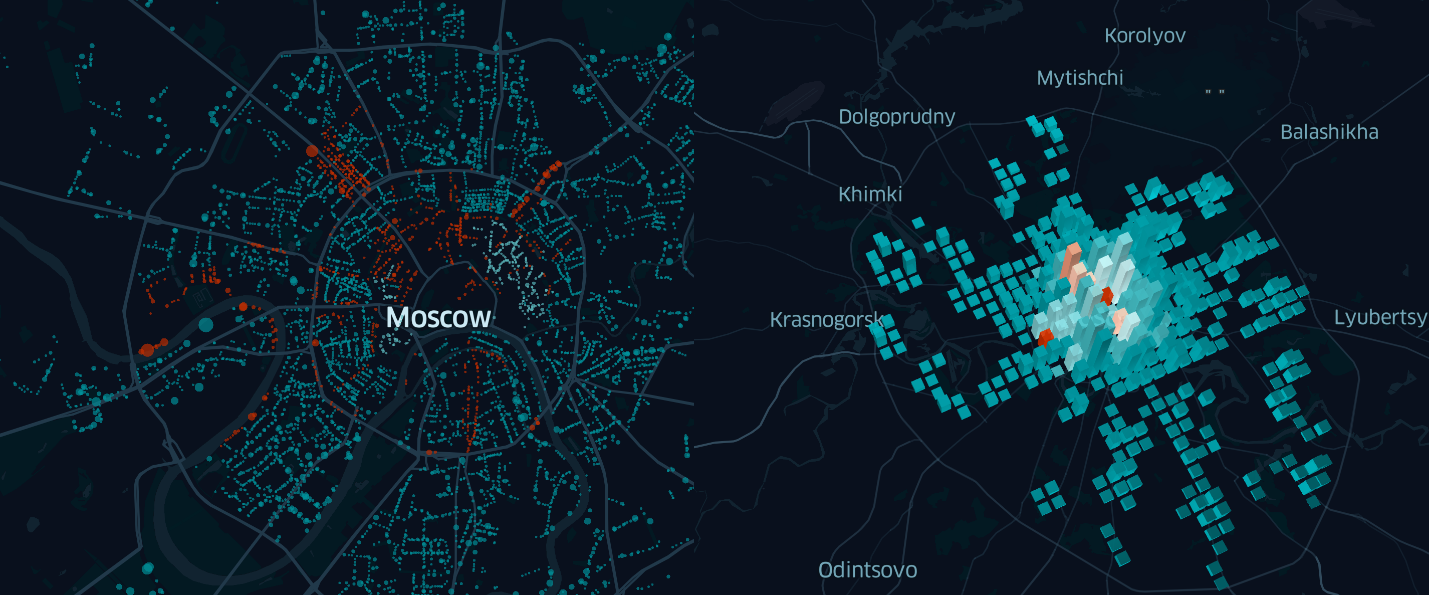
Figura 3. Usando a camada pontual Kepler.gl para exibir os estacionamentos de Moscou
Nesta modalidade, o cartão não é muito informativo. A única coisa que se pode dizer, olhando para ela, é que há mais estacionamentos no centro do que nos arredores.
Portanto, é hora de usar outras informações sobre os objetos estudados para uma análise mais detalhada e procurar fatos e / ou padrões interessantes.
Etapa 3. Modificação da aparência do mapa com base nos dados relacionados nos objetos exibidos
O conjunto baixado do Open Data Portal contém muitas informações sobre cada um dos estacionamentos, no entanto, dois parâmetros me pareceram os mais interessantes - o custo de uma hora de estacionamento e o número de vagas disponíveis.
Onde estão os estacionamentos mais caros em Moscou? Existe uma relação entre o tamanho do estacionamento e a distância do centavo? Qual é a diferença no custo de uma hora de estacionamento dentro e fora do Ring Garden? Para responder a essas perguntas, basta alterar um pouco as configurações de exibição da camada de pontos criada anteriormente e olhar novamente o mapa.
Primeiro, mude a cor dos pontos, dependendo do custo de uma hora de estacionamento neste local. Para fazer isso, na lista suspensa "Cor baseada em", como base para a escolha de uma cor, indicamos o parâmetro "Preço" do conjunto de dados original.

Figura 4. Usando cores para exibir informações de custo do horário de estacionamento
Já nesta fase, várias observações interessantes podem ser feitas. Por exemplo, que nem todo o centro é igualmente caro para os motoristas, mas em Tverskaya é melhor ser um pedestre
Agora vamos ver a capacidade dos estacionamentos. Para isso, usaremos o campo "CarCapacity" como um parâmetro básico para determinar o raio de um ponto (o atributo "Radius Based On" de uma camada de pontos). Defina o intervalo do raio de 0 a 30px.

Figura 5. Personalização do tamanho dos pontos, dependendo do número de vagas
Assim, em apenas alguns minutos, nosso mapa de estacionamento se tornou notavelmente mais informativo. Agora, mesmo uma rápida olhada nela permite não apenas comparar a política de preços de diferentes áreas da cidade, mas também avaliar aproximadamente suas chances de encontrar um espaço livre, considerando não apenas o número de estacionamentos nas proximidades, mas também o espaço.
Etapa 4. Agregando dados com Kepler.gl
O uso de uma camada de pontos para exibir cada um dos mais de 9000 estacionamentos já nos permitiu fazer algumas observações interessantes, mas o mapa não nos permite responder facilmente perguntas como "Onde há mais vagas de estacionamento por unidade de área?". Para responder, precisamos usar uma das camadas de agregação.
Atualmente, o Kepler.Gl suporta 4 tipos de camadas: grade (Grade), grade hexagonal (Hexbin), mapa de calor (Mapa de calor) e cluster (Cluster). Os dois últimos tipos (Cluster e Mapa de Calor) são convenientes quando você precisa agregar dados por apenas um parâmetro. A grade e a grade hexagonal permitem analisar valores agregados por vários parâmetros simultaneamente.
Para responder à pergunta colocada anteriormente, alteraremos o tipo de camada de pontos que criamos anteriormente para "grade" (Grade), isso não apenas avaliará o número total de vagas por unidade de área, mas também salvará informações sobre o custo médio de uma hora de estacionamento neste local.
Defina o tamanho da grade como 1km2 (o mínimo disponível em Kepler.gl). O valor do parâmetro Coverage é reduzido de 1 para 0,7, para que um pequeno espaço apareça entre as células, o que melhora a legibilidade do mapa final.
Nota A lista de opções disponíveis para personalização varia de acordo com o tipo de camada selecionado. Você pode encontrar mais detalhes sobre os atributos suportados por cada um deles na documentação oficial do Kepler.gl.
A cor de cada célula na nova visualização, como antes, dependerá do custo de uma hora de estacionamento. No entanto, agora, além do nome do campo no conjunto de dados usado, também precisamos indicar como o Kepler.gl agregará essas informações. Os métodos de agregação dependem do tipo de campo selecionado. No nosso caso, "Preço" é um tipo numérico (int) e o aplicativo oferece uma das 5 opções:
- valor mais alto (mínimo)
- menor valor (máximo)
- quantidade (soma)
- valor médio (médio)
- mediana
A altura de cada uma das colunas da grade refletirá o número total de vagas nesta área. Para fazer isso, vá para o modo 3D de visualização do mapa. Em seguida, na guia "Camadas" do painel lateral , selecione "Ativar altura" para a nossa camada de agregação e selecione o campo "CarCapacity" como parâmetro base.
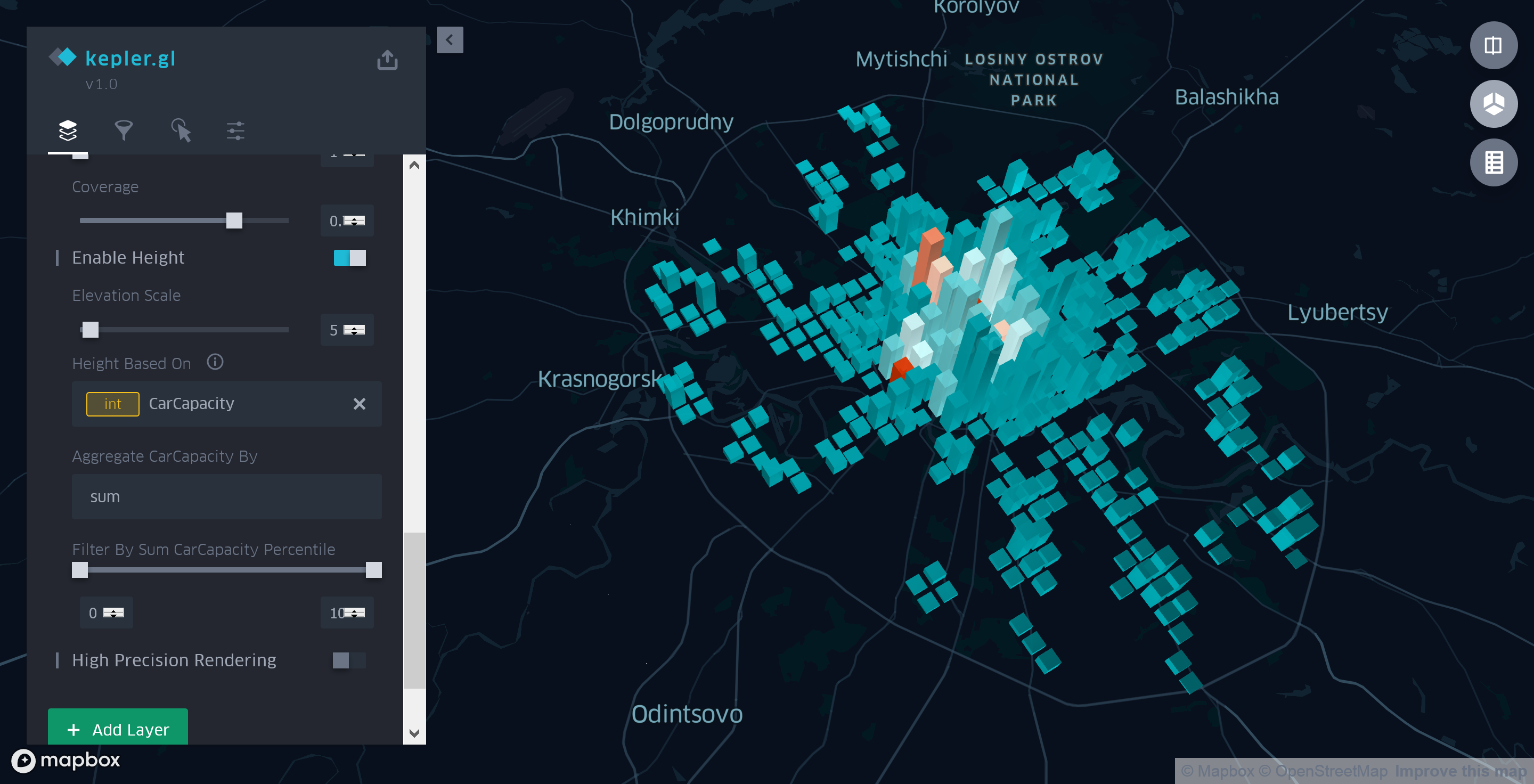
Figura 6. Informações generalizadas sobre o custo e a capacidade do estacionamento
Assim, depois de gastar mais alguns minutos na configuração da camada de agregação, podemos dizer com segurança que, dentro do Anel do Jardim, não apenas o número de estacionamentos, mas também o número real de vagas é muito maior do que fora.
Conclusão
Neste artigo, usando um exemplo específico, apenas parte dos recursos do Kepler.gl foi considerada uma ferramenta moderna para visualização e análise básica de vários dados geográficos. Se você estiver interessado neste aplicativo, recomendo que você também se familiarize com os artigos e tutoriais abaixo, além de experimentar a filtragem de dados, configurar dicas de ferramentas e estilos de mapa e outros recursos desse aplicativo.
E no próximo artigo, mostrarei maneiras de compartilhar as visualizações e mapas que você criou, bem como sobre o uso do Kepler.gl como um componente React para seu aplicativo da web.
Links úteis