Antes de responder à pergunta "Como medir o sucesso?", Você precisa entender o que "sucesso" significa para você. Para Dev e Ops, a definição de sucesso é diferente. Para o Dev, um projeto bem-sucedido é totalmente testado. Para operação - monitoramento. Testes e monitoramento são necessários, mas os testes nunca oferecem 100% de cobertura do problema, e uma resposta de 200 do HTTP não é suficiente para garantir que o sistema funcione bem. Leon Fayer , do RIT ++, defendeu o ponto de vista de que os DevOps não pagam para garantir que todas as métricas no monitoramento estejam na zona verde. Eles pagam para fazer os usuários felizes . Se você está insatisfeito - o negócio está perdendo dinheiro e ninguém se importa que tudo seja verde.
Sob um gato, existem muitos exemplos da prática que comprovam esse ponto de vista. Vamos descobrir por que entender os negócios, como monitorar o sucesso do ponto de vista comercial e por que os desenvolvedores comuns precisam dele.

Sobre o orador: Leon Fayer nasceu em uma república outrora amigável, mas cresceu nos Estados Unidos. Comecei a programar há muitos anos e, durante esse período, trabalhei como programador, gerente, a quem simplesmente não trabalhava. Participou de startups - algumas tiveram mais sucesso e outras não.
Por muitos anos, Leon trabalha no OmniTI. Essa empresa é especializada no desenvolvimento de sistemas escalonáveis, de modo que Leon tem uma oportunidade única de projetar e construir sistemas para os sites mais visitados do mundo - Wikipedia, National Geographic, Casa Branca, MTV, etc.

Antes de responder à pergunta "Como medir o sucesso?", Você precisa entender o que "sucesso" significa para você. Para cada pessoa, a resposta será diferente.
Se você está lendo este artigo, provavelmente está envolvido com o DevOps. Você é mais dev do que ops? Ou, inversamente, mais Ops que Dev? Para Dev e Ops, a definição de sucesso é um pouco diferente: para Dev, é claro, está testando.
Teste
Para mim, como programador, o teste bem-sucedido significa que tudo está em ordem, tudo está bem, tudo funciona - você pode executá-lo na produção. O problema é que eu também sou cínico e não sou fã de testes como tal. Não porque é difícil, e não porque é longo - mas porque o teste não dá o que eu quero.

Entenda-me corretamente, o teste é um processo obrigatório , deve ser incluído em qualquer projeto, mas claramente não é suficiente para garantir o sucesso .
Existem muitas opções de teste diferentes:
- testes de desempenho;
- testes de usuário;
- teste automático ...

Quantos métodos de teste você usa - 1, 2, 3, 5? E o que, você não está acordado à noite em alerta? Tudo funciona na produção?
O problema é que o teste dá a ilusão de sucesso . É pré-determinado: sabemos que o trem deve sair do ponto A e chegar ao ponto B, para isso estamos testando. Existem opções que estamos considerando. Se o trem cair do volante ou ficar sem madeira, isso não será uma surpresa. Mas não testamos, por exemplo, assaltos a trens. Não podemos testar isso porque não sabemos que essa opção é possível.
Existem alguns problemas devido aos quais os testes simplesmente não são suficientes. O primeiro, é claro, é um problema de dados . O fato de a tarefa funcionar localmente, mas por algum motivo não funcionar na produção, é um problema padrão.
Não importa o quanto tentemos. Não importa quantas repetições vivemos - o desenvolvimento e a produção nunca serão iguais. Haverá outra linha no banco de dados, haverá outra solicitação extra - sempre haverá algo em produção que não esperávamos.
Wolfe + 585 - o sobrenome mais longo do mundo:
Hubert blaine
Wolfeschlegelsteinhausenbergerdorffwelchevoralternwaren-gewissenhaftschaferswessenschafewarenwohlgepflegeundsorgfaltigkeitbeschutzen-vorangreifendurchihrraubgierigfeindewelchevoralternzwolfhunderttausendjahres-vorandieerscheinenvonderersteerdemenschderraumschiffgenachtmittungsteinund- siebeniridiumelektrischmotorsgebrauchlichtalsseinursprungvonkraftgestartsein-langefahrthinzwischensternartigraumaufdersuchennachbarschaftdersternwelchege-habtbewohnbarplanetenkreisedrehensichundwohinderneuerassevonverstandig-menschlichkeitkonntefortpflanzenundsicherfreuenanlebenslanglichfreudeundruhe-mitnichteinfurchtvorangreifenvorandererintelligentgeschopfsvonhinzwischensternartigraum,
Sr.
Poucos sistemas sobreviverão se alguém digitar esse sobrenome no formulário. Eu sei pelo menos 5 pontos diferentes onde todo o sistema pode voar.
Portanto, o segundo problema é o problema com os usuários .

São pessoas tão interessantes que quebram qualquer coisa. Se não houvesse usuários, tudo seria muito mais fácil, para ser honesto.
Mesmo se houver um botão na sua interface do usuário, eles ainda encontrarão um método para interromper o que estamos fazendo.
O melhor exemplo é o World of Warcraft .

Para quem não sabe, este é um jogo online jogado por 10 milhões de pessoas. Ao mesmo tempo, havia bugs bastante lendários. Corrupção no sangue é um exemplo perfeito de como os usuários estragam tudo.
Como em qualquer brinquedo, no World of Warcraft novos conteúdos, novas idéias, novos chefes apareciam constantemente. Um dos novos chefes amaldiçoou um dos 40 jogadores do grupo. O princípio da maldição era como uma bomba-relógio - lentamente tirou a vida de todos ao redor. Ou seja, era necessário fugir para o lado - havia toda uma mecânica. E tudo correu bem até que, em algum momento, um dos jogadores decidiu se teletransportar para a cidade durante a batalha ...

Na cidade havia milhares de pessoas de todos os níveis, os menores também. Além disso, ainda havia personagens não jogadores que também foram infectados com uma maldição. Durante o dia, os servidores estavam vazios. Era impossível ir a qualquer lugar, onde houvesse outros jogadores. Tornou-se uma praga de jogo no sentido mais verdadeiro da palavra. Eu tive que reiniciar todos os servidores para remover a maldição e mudar a mecânica. E tudo por causa de um testador - nem sei como chamá-lo.
O terceiro problema principal é o problema da dependência externa . Todos nós descobrimos isso: a API da qual você depende repentinamente para de funcionar; ou você para de controlar a API.
Mas há um problema maior com isso. A dependência externa pode ser não apenas direta, mas também indireta. Todos nós usamos o OpenSource agora. Cada produto OpenSource depende de algumas bibliotecas, que também são OpenSource e são suportadas por outra pessoa. Quando algo quebra, quebra não apenas neste pequeno módulo, mas em tudo o que depende dele.
Provavelmente o exemplo mais ideal foi recentemente, cerca de um ano atrás - esse é o teclado esquerdo . Este é um módulo npm no node.js que expõe os espaços antes da sequência (no início de uma linha). Não discutiremos por que este módulo foi feito. Mas acontece que foi incluído em muitos módulos populares. Em algum momento, o autor decidiu que tinha o suficiente, removeu este módulo do npm e 70% do código escrito em node.js voou.
Se você acha que este é um caso isolado, está enganado.
Há também o módulo is-odd, que agora está em npm. Este módulo define um número par ou não.
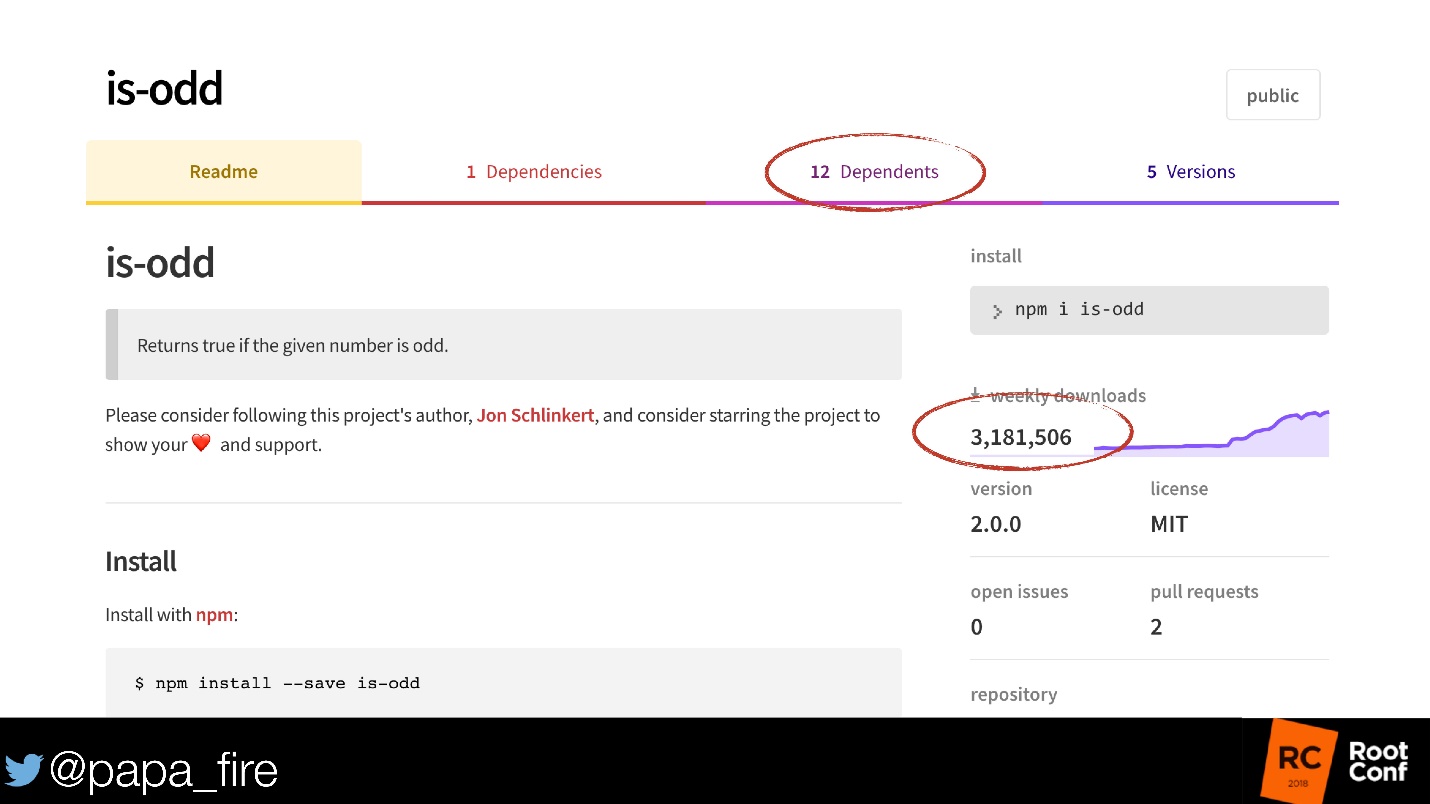
Não discutiremos o fato de que 3 milhões de pessoas não sabem como verificar a paridade / estranheza. Mas existem mais 12 módulos que o utilizam! E não se sabe quantos desses módulos ainda estão usando os módulos. Se lhe parece que não há nada para quebrar - existem 5 versões!
Voltando às nossas ovelhas - há muitas outras opções:
- Míope - não sabemos o que acontecerá no futuro. Y2K é um exemplo perfeito. Ninguém pensou que em 2000 tudo o que estava escrito em Kobol voaria.
- Número de opções de teste .
Há um bom exemplo novamente com o World of Warcraft - eles têm muitos bons exemplos sobre esse assunto.
Seis meses após o lançamento do jogo, começaram a surgir recursos para que alguns jogadores não pudessem entrar em uma caverna. Descobriu-se que apenas uma versão de raça e gênero não podia entrar nesta caverna - eram taurens femininas.
Por que demorou 6 meses para encontrar esse erro - afinal, milhões de pessoas estão jogando? Porque tauren é uma raça fictícia, uma mistura de homem e touro. A mulher Tauren é uma vaca falante. Ninguém queria brincar de vaca, então por 6 meses nenhuma pessoa atingiu o nível máximo para entrar na caverna e encontrar esse bug. Por conseguinte, ninguém o testou.
- Mudança nos dados de origem. Realmente não sabemos o que acontecerá amanhã.
De qualquer forma, existem poucos testes. Mas os testes não oferecem 100% de cobertura. Portanto, o teste não garante sucesso. Isso gradualmente nos leva à segunda parte - Ops. Para exploração, o sucesso está monitorando .
Monitoramento
Há muitas razões pelas quais o monitoramento é necessário:
- código perfeito não existe;
- sistemas estão se tornando mais complexos;
- crescente dependência externa;
- antecipação -> resposta;
- ...
O monitoramento é necessário porque tudo está mudando. Esta é a principal razão. Além disso, está em produção, tudo muda constantemente lá, e precisamos detectar isso.
O que o monitoramento deve cobrir? - é isso aí! Esta é uma resposta curta, mas deve cobrir tudo.

Isso tudo é um pouco abstrato. De fato, todos temos uma lista de verificação que monitoramos:
- infraestrutura
- Bases de dados
- Aplicações
- pontos de integração;
- solicitar tempo de processamento;
- carga;
- ...
Pode haver um milhão de coisas. Muitos coletam centenas, milhares e dezenas de milhares de métricas em seus sistemas.
Coletaremos muitas métricas para isso:
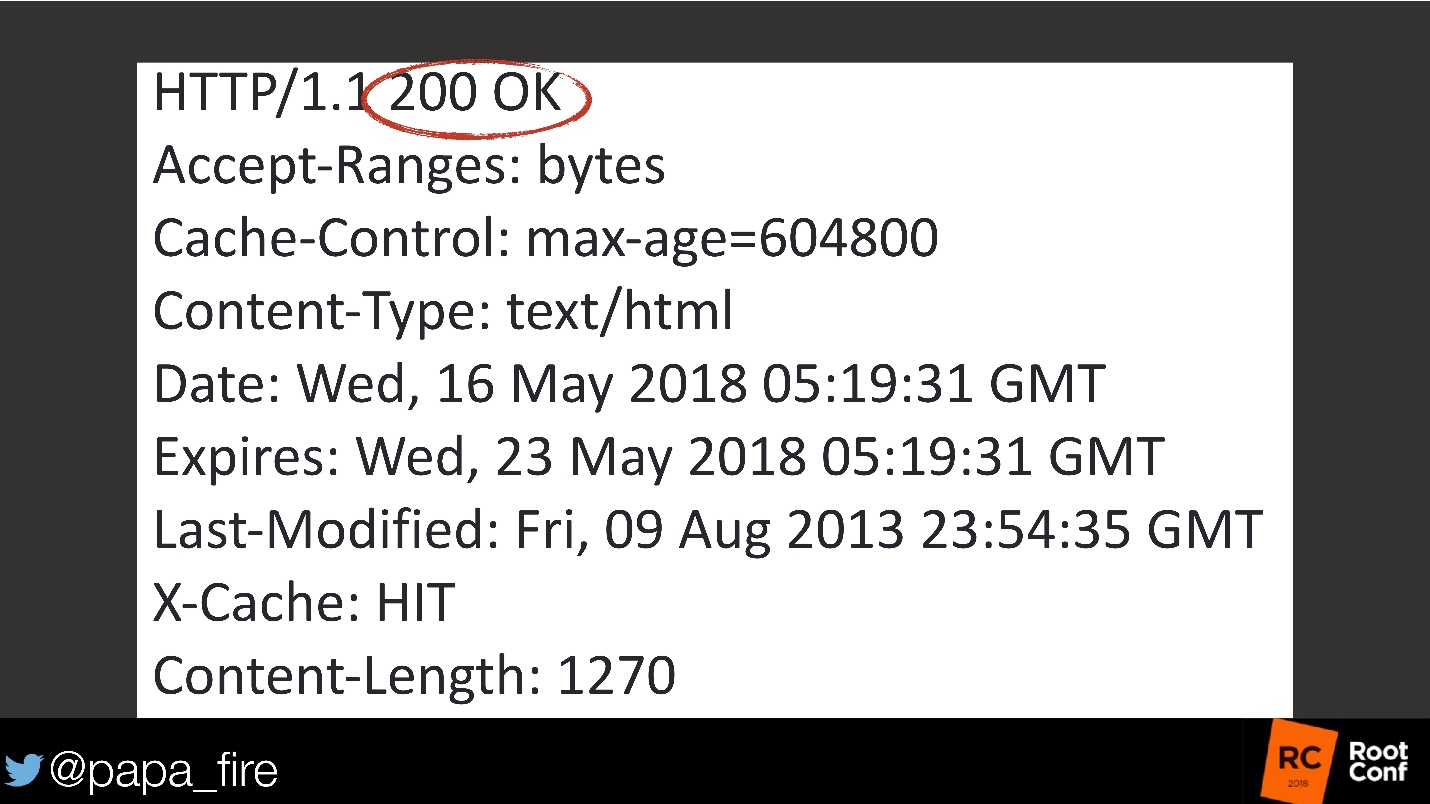
Claro, estou exagerando, mas tudo o que precisamos do ponto de vista do Ops é que o HTTP retorne 200 . Isso significa que está tudo bem com o site. Quando um site funciona, significa que os bancos de dados funcionam, os aplicativos funcionam - tudo está em ordem. Do ponto de vista da Ops, o sucesso é exatamente isso: todos os gráficos estão na zona verde, tudo está funcionando corretamente - tudo está bem!

Todo mundo sabe o que é o Twitter. Eles processam 500 milhões de tweets por dia - um número louco.

Mas eles também são conhecidos por seus erros. Os erros são lendários em sua complexidade ou facilidade - de que lado olhar.
Eles cometeram um erro: o site estava funcionando, o cliente poderia escrever um tweet, clicar em um botão, eles disseram obrigado, o tweet foi enviado - e é isso! Ele não apareceu em lugar nenhum e simplesmente desapareceu, e o monitoramento mostrou que tudo estava em ordem. O site retorna uma solicitação de 200 - a API funciona. Mas não há tweets!
Tenho uma cotação favorita de um cliente. Consertei os problemas em três telas por uma hora e ele gritou por que nada funciona. Quando tentei explicar quais problemas eu estava corrigindo, uma pessoa que digitou com dois dedos e não entendeu como usar um computador me disse:
"Enquanto eu continuar a ganhar dinheiro, é uma merda para mim que os servidores estejam ligados."
De certa forma, isso é muito correto, e o exemplo do Twitter confirma isso: todas as métricas mostraram que tudo estava em ordem do ponto de vista dos desenvolvedores, mas do ponto de vista do trabalho dos negócios, não estava em ordem.
Para ser sincero, somos todos culpados. Obviamente, as empresas que produzem produtos de monitoramento são as principais culpadas. Mas nós também, porque tradicionalmente coletamos métricas do sistema. Estamos acostumados a trabalhar com sistemas pequenos - um, talvez dois servidores. Se eles funcionarem, tudo estará em ordem.
Agora, temos um pouco mais de servidores do que dois, ou até dez, e apenas medir a integridade do sistema ou a integridade do programa não é suficiente. Devemos acompanhar o trabalho de outra coisa.
Voltando à cotação, não paguei para que tudo fosse verde. Sou pago para que meus usuários ou gerentes fiquem satisfeitos - alguém deve estar feliz com o resultado . Se todos os usuários estiverem descontentes, ninguém se preocupa com o fato de tudo estar verde.
Monitoramento de negócios
Dissemos que o monitoramento é necessário porque tudo está mudando. Mas quando tudo muda, as mudanças afetam os negócios: algo quebrou - o dinheiro parou de entrar, algo foi reparado - o dinheiro começou a fluir novamente - uma correlação direta. Ou eles não influenciam, mas se não monitoramos os negócios, não sabemos disso.
Como um exemplo vivo, o gráfico de leitura de cache é familiar para todos.
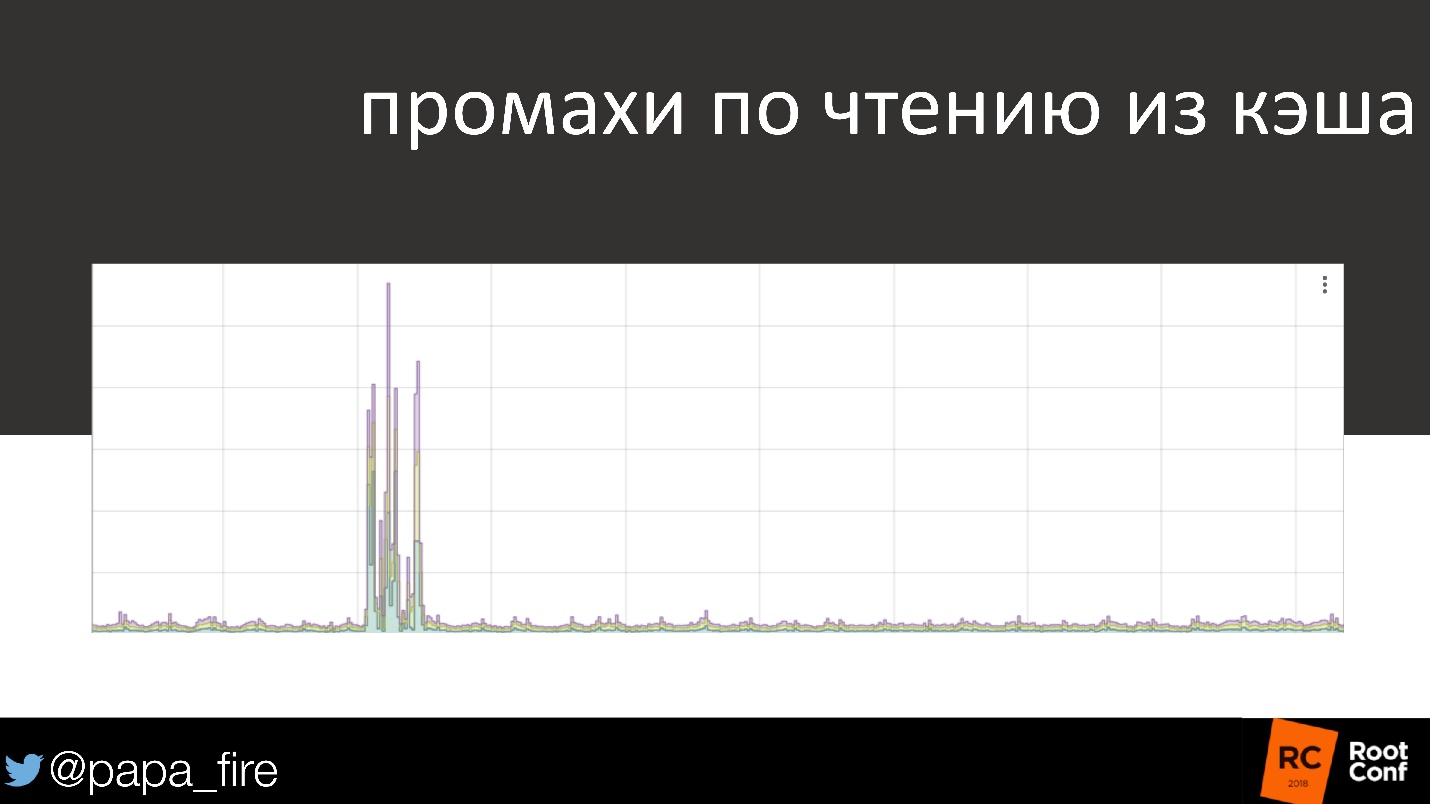
90% das vezes, tudo está em ordem, quase todas as solicitações vão para o cache. E de repente algo aconteceu - e muito sério. Este é um problema que deve acordar às 3 da manhã, alguém que o resolva. Mas, se a velocidade de download dos usuários não mudar, isso é realmente um problema?
Em inglês, existe o termo Observabilidade - observabilidade. São eles: monitoramento, registro, alerta. Portanto, o termo monitoramento é um pouco. Queremos observar tudo - colete métricas do sistema em cada nó, se necessário. Mas queremos monitorar o negócio, porque emociona a todos. Este é um indicador de sucesso.
Para fazer isso, devemos:
1. Entenda o problema - o que exatamente precisamos monitorar.
2. Determine a linha de base - ou seja, é suficiente que a velocidade de download do usuário não seja alterada para que ninguém acorde no meio da noite quando a leitura do cache parar de funcionar.
3. A correlação de dados é um dos fatores mais importantes. Se o marketing coleta dados sobre receita e você coleta dados em servidores e não pode comparar essas duas observações, elas têm muito pouco significado.
Eu costumo dar muitos exemplos. Não importa o quão absurdos eles pareçam, eles são todos da minha vida, e eu passei muitos nervos neles.
Exemplo: eu tinha um cliente com 100 milhões de usuários. Era uma empresa de marketing na Internet que enviou muitos e-mails e usou testes A / B. Para eles, coletamos 6 mil métricas.
Tudo, como sempre, começou com uma ligação. O telefone toca - significa que algo aconteceu.
- Temos um problema. Algo não está funcionando.
- OK, o que exatamente não funciona? Em que isso é expresso?
- Começamos a receber menos renda.
- e
- Algo não funciona no sistema.
- Eu não entendo. Se tiver menos renda, converse com sua equipe de vendas. Por que você está me ligando?
- Não, tenho certeza de que algo no sistema não funciona!
- Tudo bem, vamos ver.
Graças a Deus tínhamos uma métrica de receita, para podermos ver. O gráfico mostra realmente que, em algum momento, sua renda caiu 15%. Dado o número de usuários, isso é bastante significativo.
Ok, eu tenho que olhar. Antes de tudo, verifico a velocidade do download - normal.
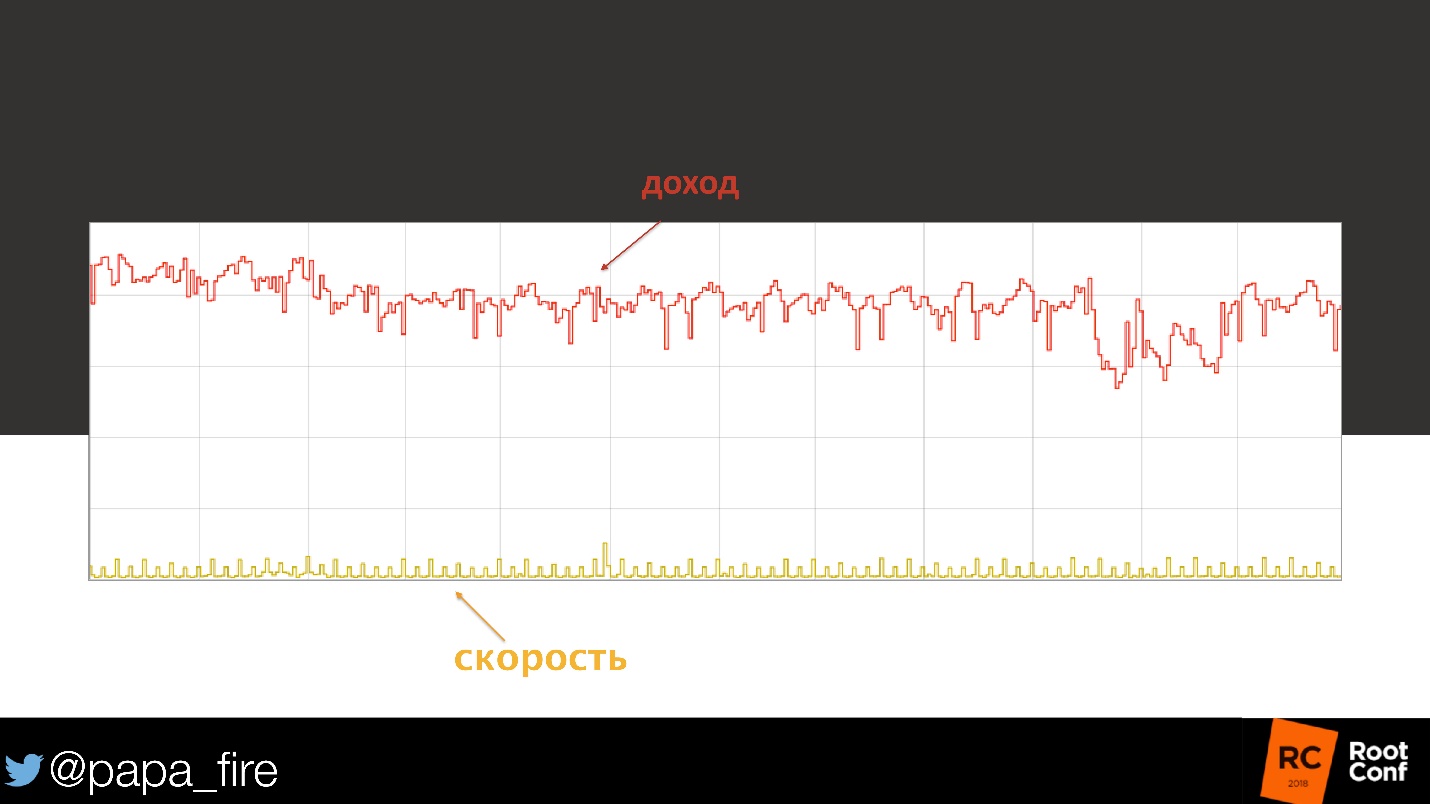
Observamos a carga no banco de dados - tudo está dentro de limites razoáveis, parece que nada mudou. Então começamos a observar a carga da CPU, em nós individuais, em caches.
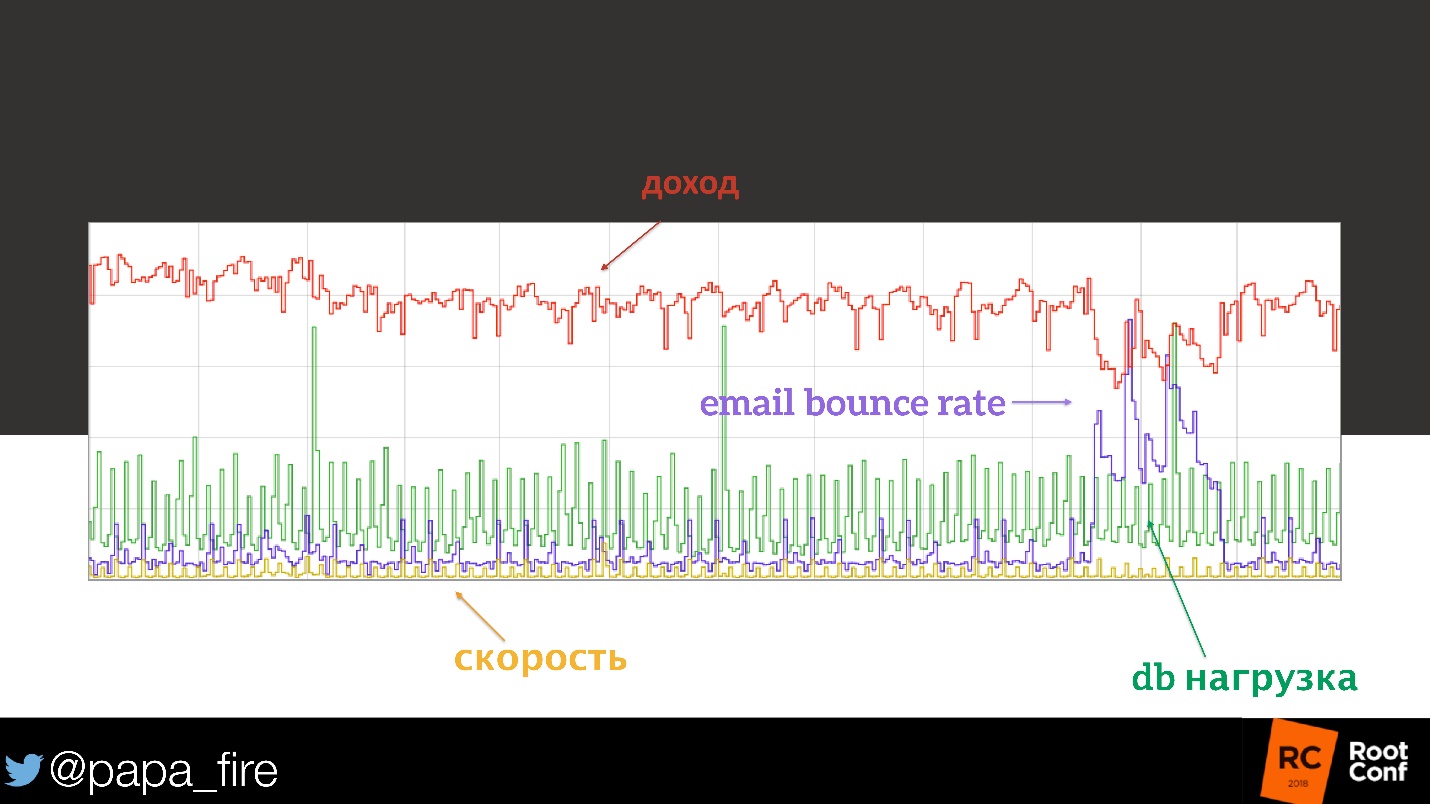
Tudo estava em ordem. Até chegarmos às métricas do boletim por e-mail. Um dos grandes fornecedores acidentalmente colocou seu domínio na lista negra. A porcentagem de seu marketing por e-mail deixou de alcançar os usuários, o que significa que menos pessoas: receberam cartas, clicaram no botão, foram ao site e compraram algo.
Aqui está essa correlação!
Temos a sorte de ter essas métricas. Se não os tivéssemos, nós os adicionaríamos - esta é uma resposta muito simples.
O maior erro que as pessoas cometem é acreditar que o monitoramento pode ser colocado no final do projeto. É como um recurso: para criar seu próprio projeto, monitorizar - e pronto, estamos prontos!
A instrumentação nunca pode ser finalizada. Sempre existem problemas que são desconhecidos desde o início. Como no teste, você não pode escrever testes e cobrir tudo, porque não sabe o que é "tudo". Não sabemos como prever o futuro e como prever um negócio, portanto, não sabemos o que é "tudo".
Um exemplo absolutamente idêntico ao que estou falando. Foi o CEO, que acordou em uma conferência em Paris pela manhã, bebeu café, olhou para o correio e a declaração de renda e me ligou com o mesmo problema: a renda caiu.
Lembro-me bem, porque ele tinha nove da manhã e eu tinha seis horas antes, também no sábado. Acabei de ser transportado para casa de uma festa de aniversário - mas isso não importa. Então, às três da manhã, sento-me no computador e começamos a seguir os mesmos passos. Ou seja, olhamos para a carga no sistema, para o número de registro.
O único desvio da norma que encontramos é uma porcentagem menor de autorizações bem-sucedidas. Ou seja, a quantidade é a mesma, mas a porcentagem é um pouco menor. Eu sei que isso pode ser spam, etc. Mas todas as outras métricas técnicas são absolutamente normais. E chegamos ao ponto em que estávamos quase caminhando ao longo das linhas no banco de dados e tentando verificar se havia algo que pudesse chamar a atenção. Absolutamente nada!
Sentamos no meio do domingo, continuamos na segunda-feira também, mas já tínhamos certeza de que o problema não era técnico. Deixe que eles mesmos decidam. E aqui na segunda-feira me sento no trabalho e um funcionário do departamento de contabilidade me liga:
- Ouça, você pode me ajudar rapidamente?
- o que você precisa?
- Você pode remover o selo American Express do site?
- Claro que posso! Por que de repente?
- Você sabe, discutimos com eles aqui, e até aceitarmos americanos
Expresse em geral.
"Peço desculpas por perguntar, quando você parou de tomá-los?"
- Antes do final de semana, na minha opinião - na sexta ou no sábado .
Ninguém em sã consciência jamais colocaria uma coleção de métricas sobre a porcentagem de autorizações de um determinado tipo de cartão de crédito! Após este incidente, é claro, nós estabelecemos.
Por que estou lhe dizendo isso? Você deve primeiro olhar para os negócios, porque todos esses problemas sistêmicos eram simplesmente invisíveis. Eles não acordaram ninguém no meio da noite, não vimos que eram problemas. É fácil notar uma queda na renda e todo o resto precisa ser rastreado para que você possa correlacionar esses dados com os dados comerciais.
Sucesso nos negócios
Para um negócio, o sucesso pode ser diferente; depende dos objetivos. Mais importante, como isso pode ser medido? Tradicionalmente, medimos o desempenho do sistema, às vezes como engenheiros, esquecendo que você pode medir qualquer coisa.
Por exemplo, você pode medir seu próprio alcoolismo. A propósito, eu não estou brincando. Em nosso escritório, há uma cerveja de pressão com quatro torneiras. Como somos todos engenheiros, meu colega decidiu usar sensores Raspberry Pi para ver quanta cerveja bebemos e qual.

Parece uma piada simples, mas na verdade é conveniente, porque vemos quando a cerveja termina e precisamos substituir o barril. Em geral, podemos ver quando as pessoas bebem, de que cerveja elas mais gostam - escura, clara etc. A propósito, o pico é meu aniversário.
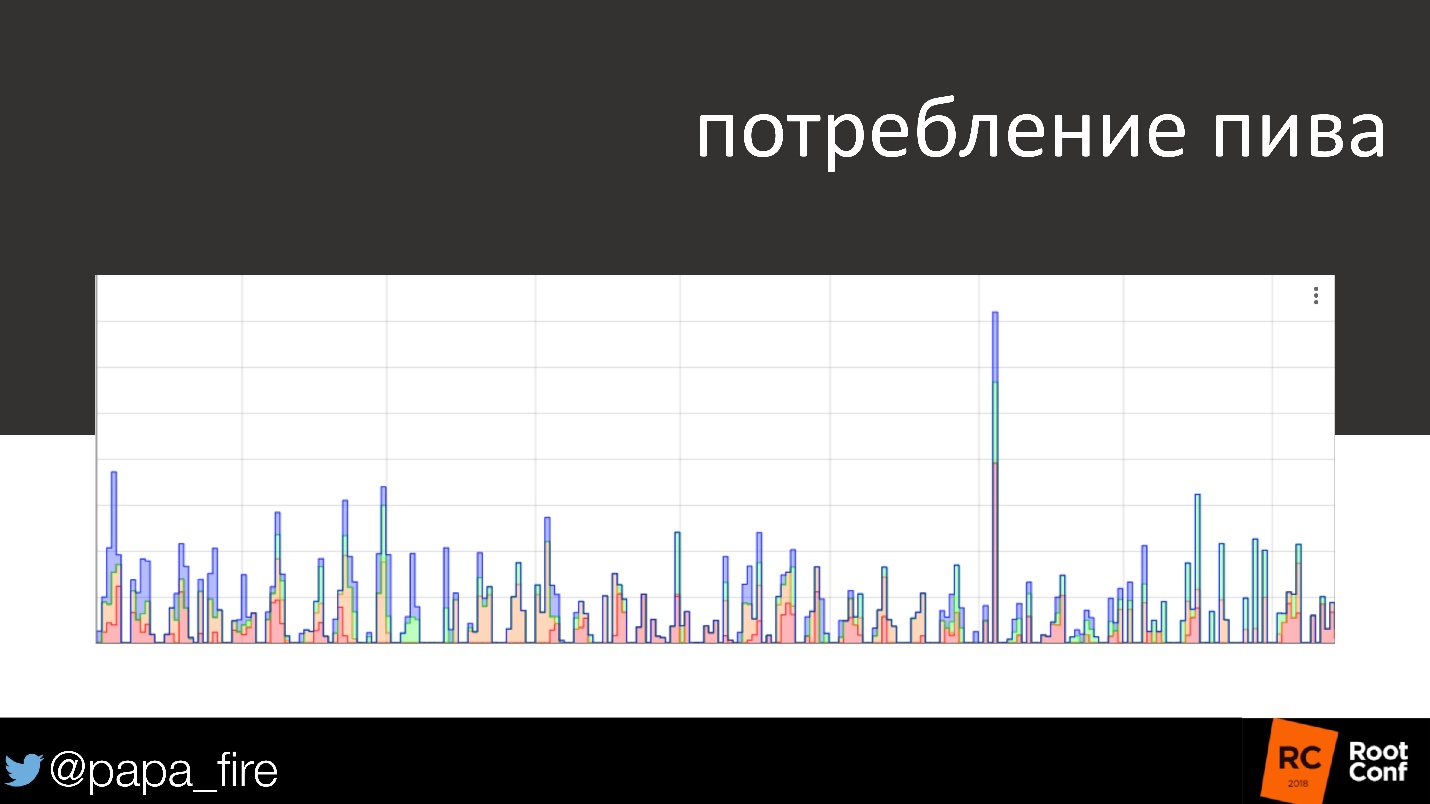
Absolutamente por acaso, encontramos outra aplicação para isso.
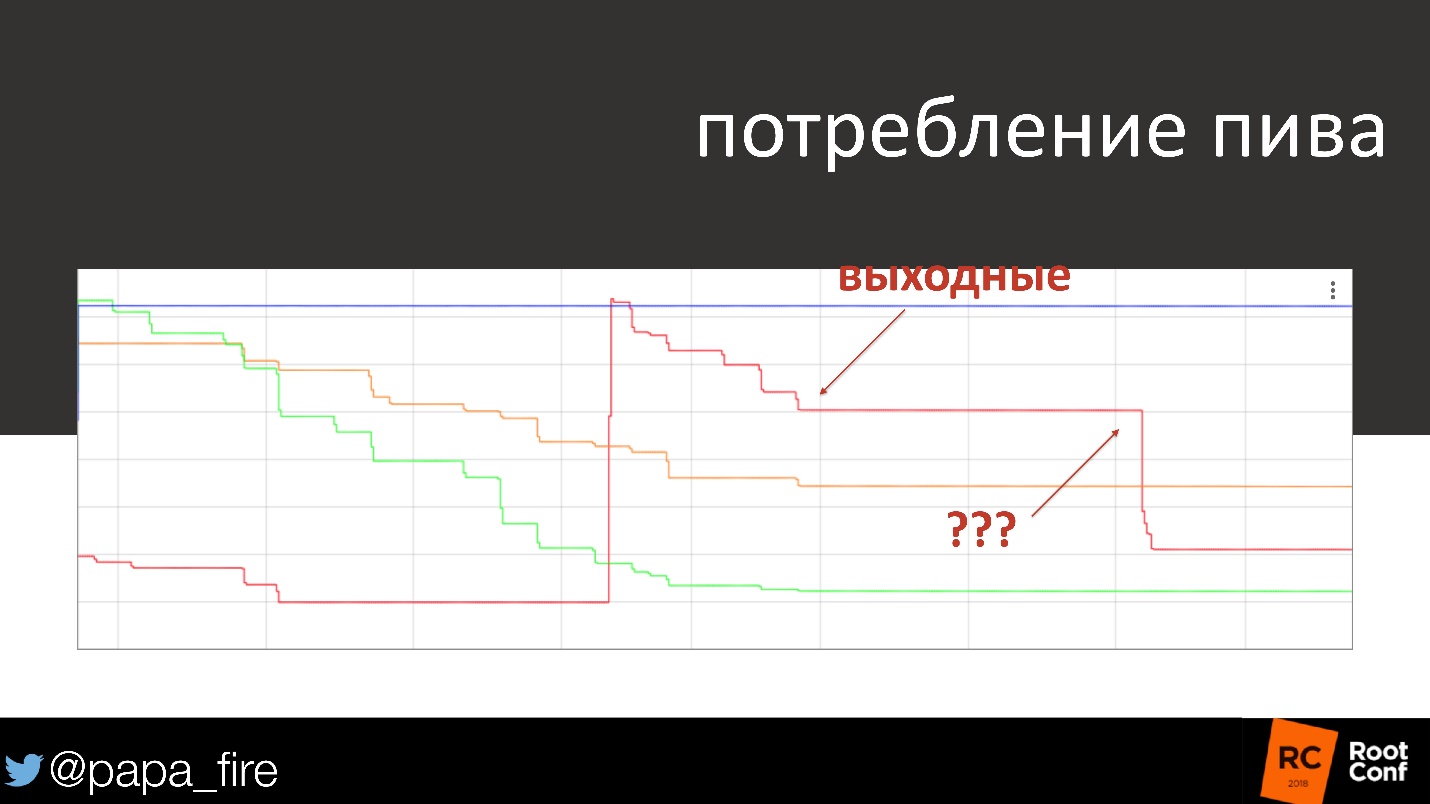
O gráfico mostra o consumo de cerveja durante vários dias e fins de semana. No fim de semana, o consumo de álcool geralmente diminui, quase desaparece. Um dia, chegamos na segunda-feira, observamos a programação e vemos que alguém no sábado bebeu um quarto de barril de cerveja. O gráfico mostra a hora exata em meia hora. Aconteceu que os faxineiros que chegaram no sábado tiveram de ressaca, então ficaram de ressaca.
Uma piada, mas no final eles tiveram sérios problemas, porque geralmente é ruim beber no trabalho e até a cerveja de outra pessoa!
No final, qualquer métrica pode ser útil. Até essa métrica, que coletamos exclusivamente para nossos fãs, acabou sendo importante em outra coisa. Mas, basicamente, as métricas realmente necessárias se resumem ao dinheiro. O dinheiro é mais importante para os negócios.
Normalmente, os critérios para o sucesso de um negócio são algo que envolve dinheiro:
- lucro;
- renda
- custos
- eficácia.
Métricas de negócios:
- Registo
- compras;
- visualizações de anúncios
- conversões;
- porcentagem de retorno;
- quantidade de cerveja bêbada
Tudo isso tem um equivalente monetário.A propósito, provavelmente, todas essas métricas já foram coletadas na sua empresa - por vendas ou por marketing. Para que você não precise inventar uma roda, basta levar as métricas existentes para o seu próprio sistema.
Tudo deve ser considerado no contexto dos negócios. Conversamos sobre métricas especiais para os negócios. Outros, nomeadamente métricas técnicas, também podem ser considerados neste contexto.
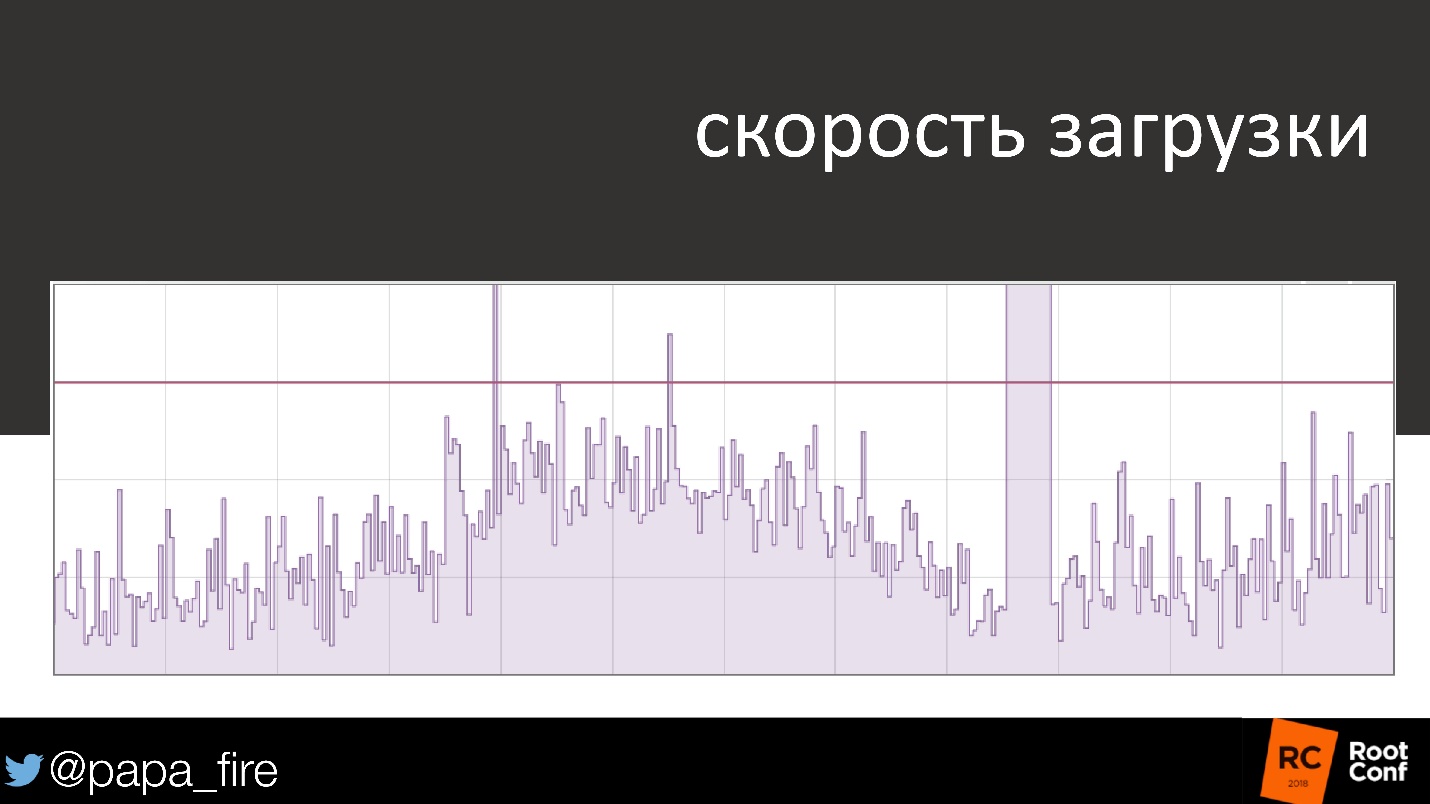
Por exemplo, a velocidade do download é uma programação bastante padrão. No início, tudo está em ordem, sobe e desce, e de repente é um problema claro. Foi reparado e o cronograma retornou ao seu formato padrão - o 99º percentil está abaixo do limite, o SLA não é violado.
Se você seguir a mesma agenda e observar o número de usuários afetados, o problema imediatamente parecerá diferente.
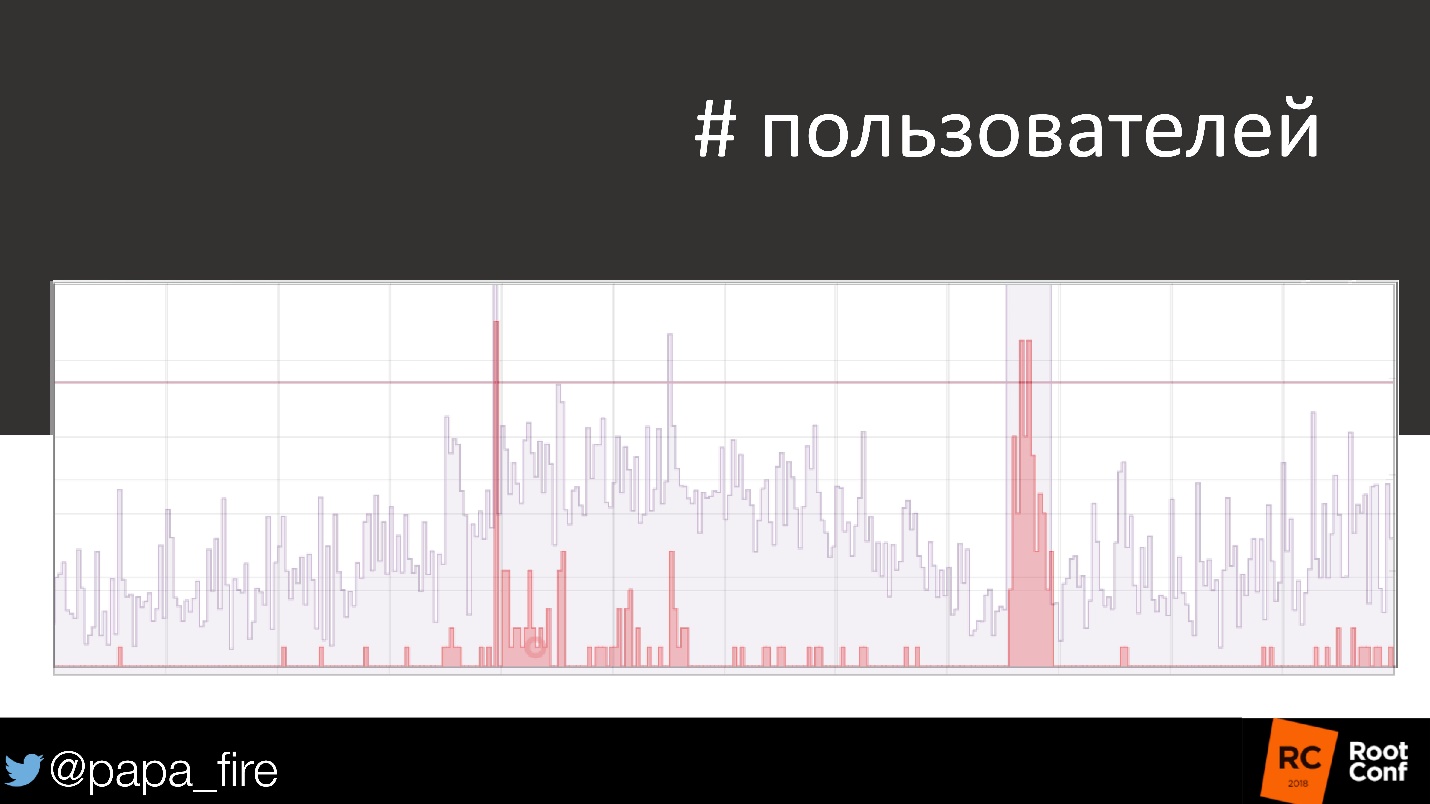
, . , , , . , .
. , . . . , 3 , .
— . , , , , .
.
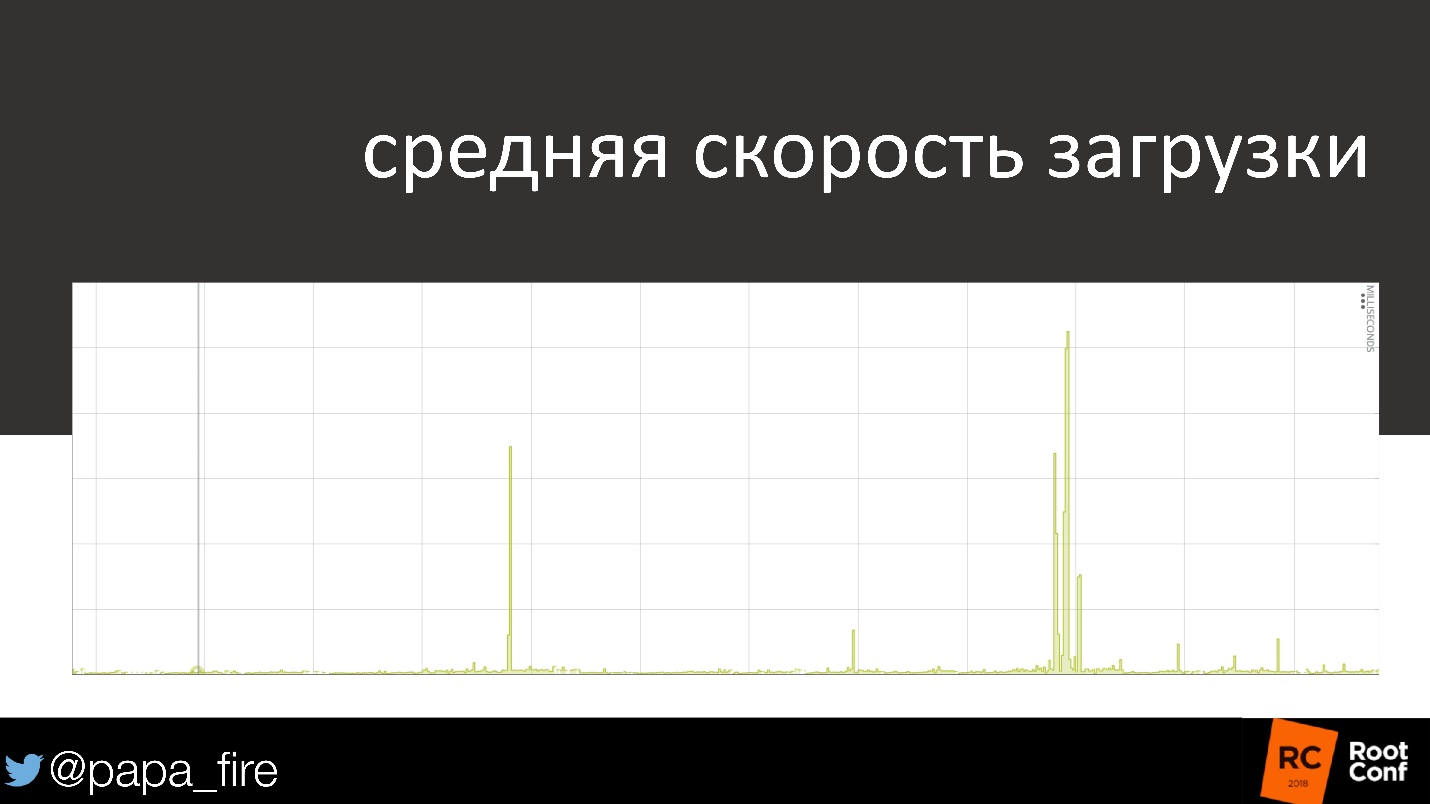
: , , , - .
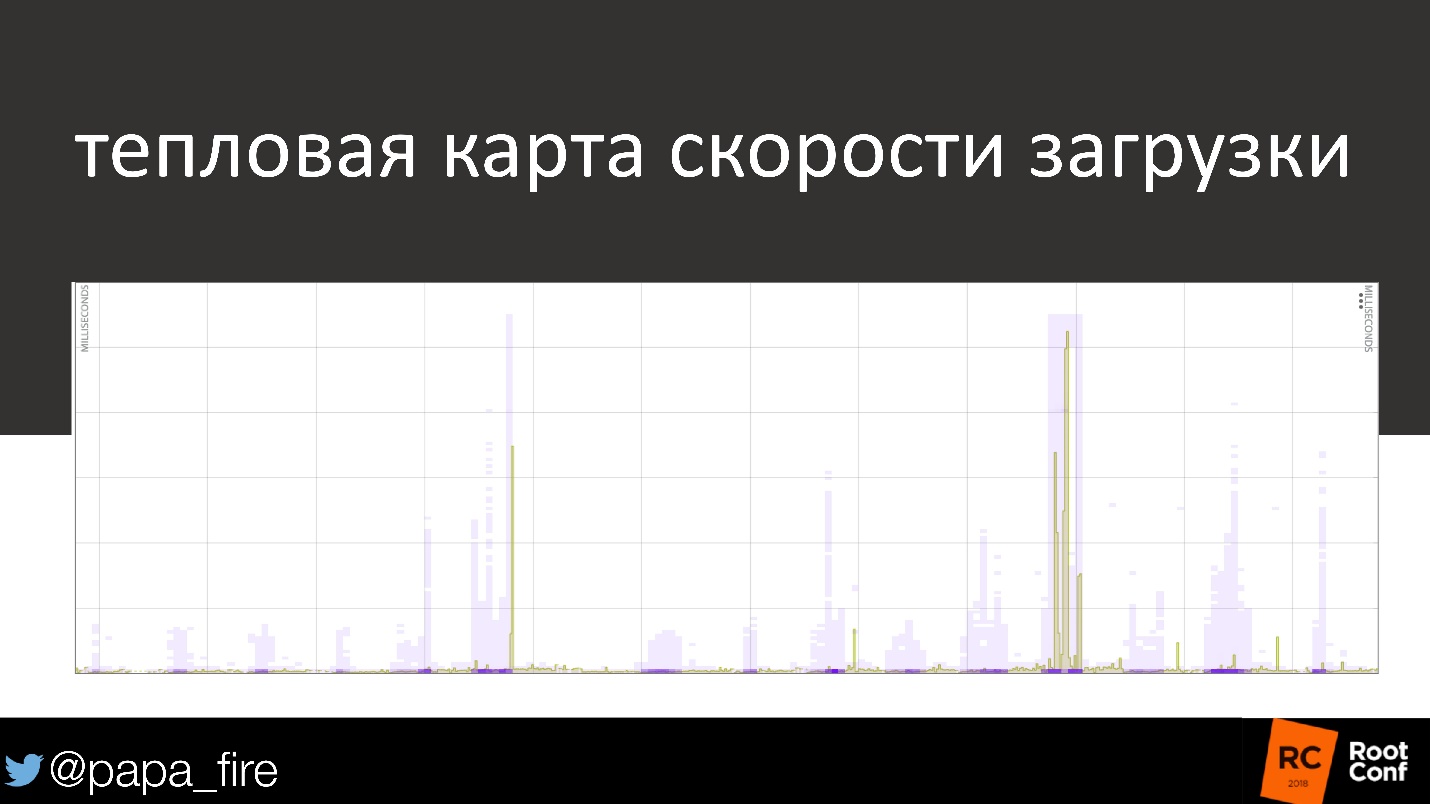
, . , , , 50 % « », , .
1 ?
1-2 . . 10 000 , . , 10 000 , - .
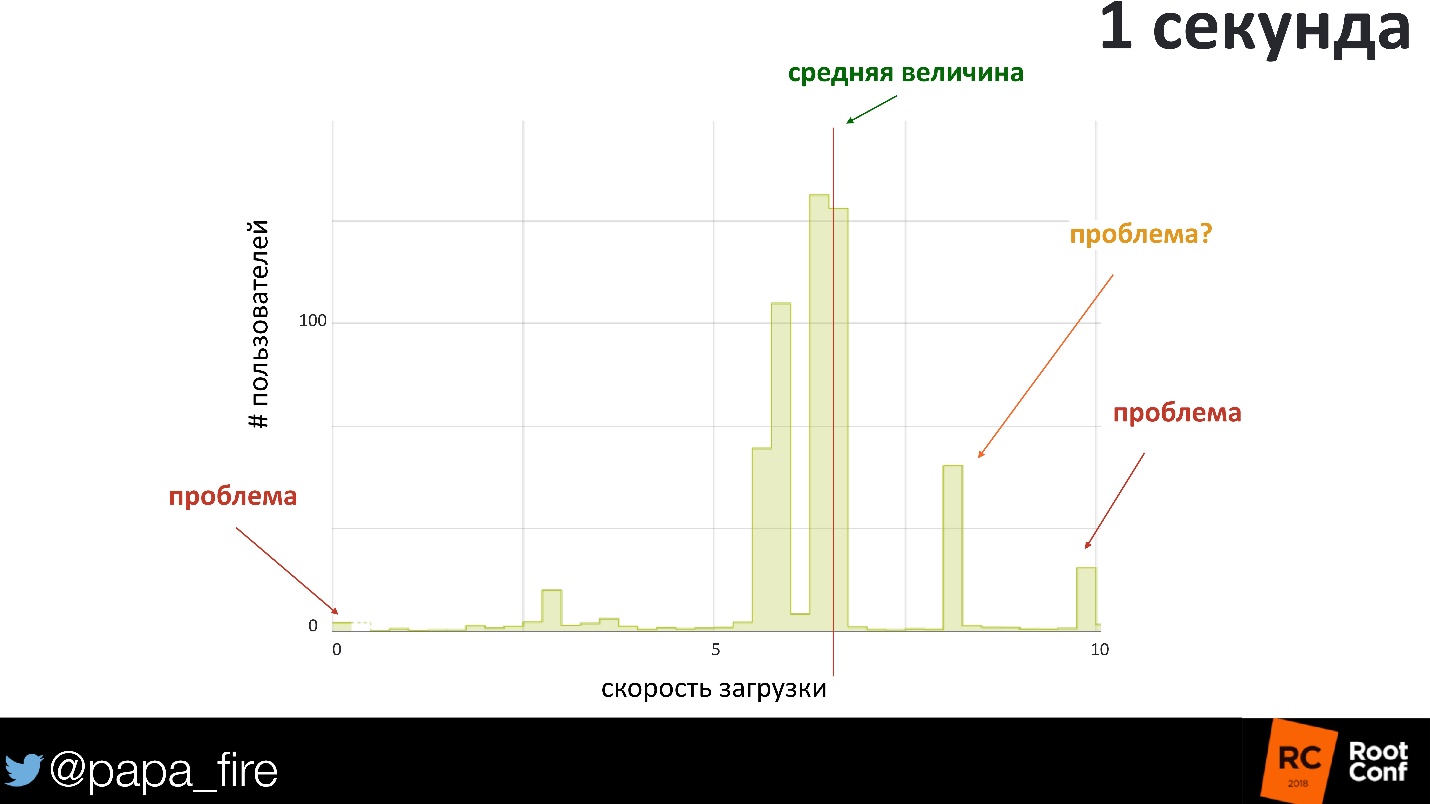
1 . 600-700 . , 600 — , . , , . 800 , , — .
, , . 0 , - , ! .
, - . — , .
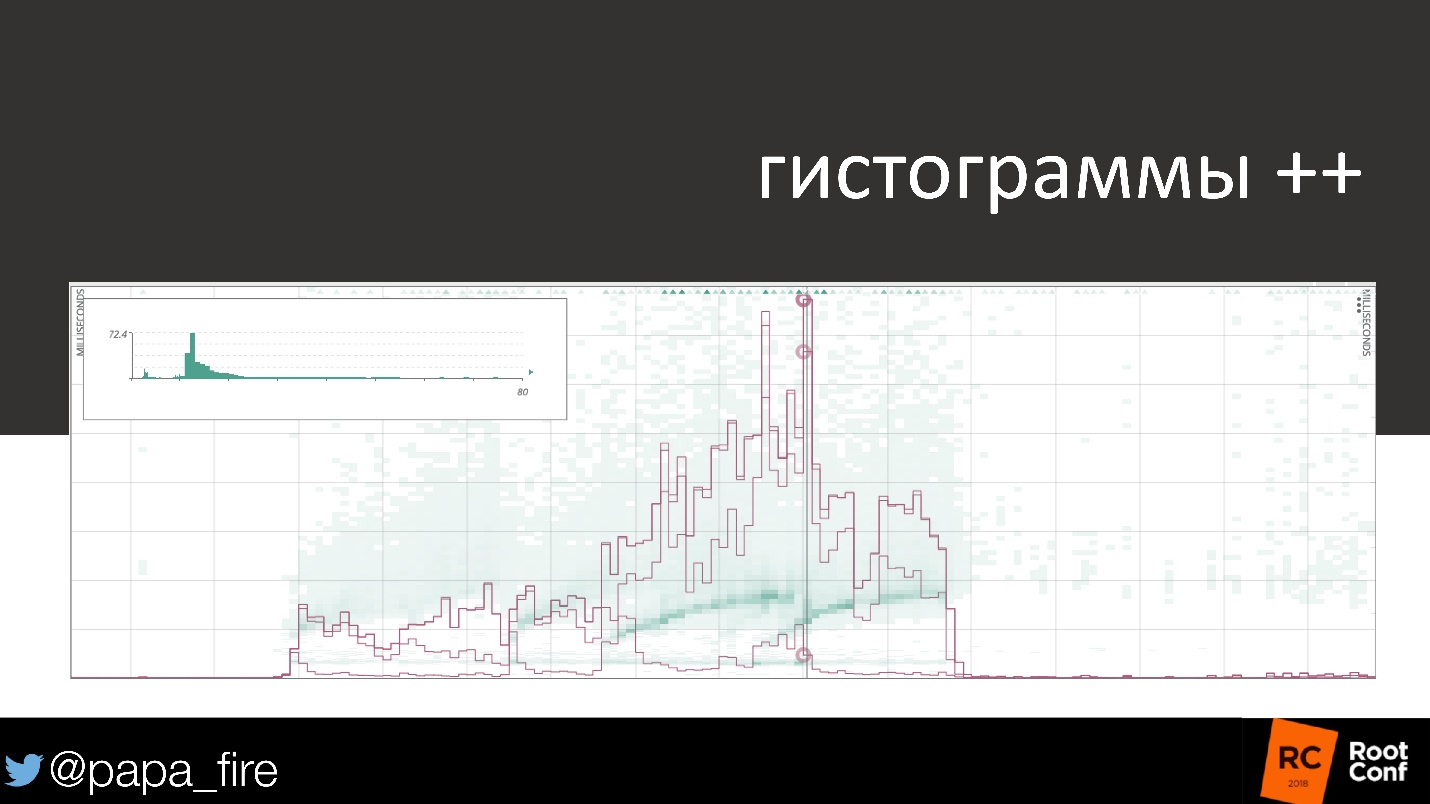
99- 50- , . , .
, — , DevOps — .
, , .
Value stream mapping — . , . , , , , , . , , .
:
- MTTD (mean time to discovery) — , .
- MTTR (mean time to recovery) — , .
- , .
- / .
, , , , . : « — . , , ».
, , . , .
. , — , , . , . .
— , , . , , , . — .
Nos dias 1 e 2 de outubro, uma conferência profissional sobre a integração dos processos de desenvolvimento, teste e operação do DevOpsConf na Rússia será realizada em Moscou .
Se você está apenas começando a trabalhar nos princípios do DevOps, esta será uma ótima oportunidade para analisar exemplos de trabalho reais desde o início até uma implementação bem-sucedida e se inspirar em idéias como o relatório de Leon. Para profissionais avançados, haverá relatórios com uma imersão profunda no tópico, detalhes importantes e discussões de novos produtos.
Venha e veja como o desenvolvimento, teste e operação podem ser inseparáveis .