O tópico de hoje - a confiabilidade do World of Tanks Server - é bastante escorregadio. A confiabilidade do jogo é comprometida, portanto, tudo precisa ser feito rapidamente e rapidamente no desenvolvimento do jogo. A carga nos servidores é grande e os usuários tendem a quebrar algo apenas por interesse. Levon Avakyan, da RIT ++, disse o que a Wargaming está fazendo para garantir a confiabilidade.
Geralmente, quando se fala em confiabilidade, monitoramento, teste de estresse, etc., são mencionados o tempo todo. Não há nada sobrenatural nisso, e o relatório foi dedicado a momentos específicos de Tanks.

Sobre o palestrante: Levon Avakyan trabalha para a Wargaming como chefe de serviços e confiabilidade de jogos da WoT e lida com os problemas de confiabilidade do servidor de tanques.
Hoje vou falar sobre como fazemos isso, incluindo o que é o servidor do World Of Tanks, o que consiste, o que é construído, para que você entenda o assunto da conversa. Além disso, consideraremos o que pode dar errado dentro do próprio servidor e em torno dele, porque o jogo já é mais do que o servidor. Também falaremos um pouco sobre os processos, porque muitos esquecem que um processo bem estabelecido na produção faz parte do sucesso, não apenas em termos de economia de recursos (muitas práticas vêm da produção real), mas afeta a qualidade e a confiabilidade da solução.

Geralmente, quando eles falam sobre confiabilidade, monitoramento, teste de estresse, etc., são mencionados o tempo todo. Não o incluí aqui porque acho chato. Não descobrimos nada sobrenatural nisso. Sim, também temos um sistema de monitoramento, realizamos testes de estresse com testes de estresse para aumentar a confiabilidade do sistema e saber onde ele pode cair. Mas hoje vou falar sobre o que é mais específico para tanques.
BigWorld Technology
Este é um mecanismo de back-end, bem como um kit de ferramentas para criar MMOs.
Esse mecanismo bastante antigo do BigWorld Server (originado no final dos anos 90 - início dos anos 2000) é um conjunto de processos diferentes que suportam o jogo. Os processos são iniciados em um cluster, interconectados em uma rede de máquinas. Interagindo entre si, os processos mostram ao usuário algum tipo de mecânica de jogo.
O mecanismo é chamado BigWorld, porque é muito bom fazer jogos nele, nos quais há um grande campo (espaço), no qual ocorrem operações militares (batalhas). Para tanques, isso se encaixa perfeitamente.
Em termos de confiabilidade, os seguintes recursos principais foram investidos no BigWorld:
- Balanceamento de carga. O mecanismo aloca recursos, tentando alcançar dois objetivos:
- use o menor número possível de máquinas;
- ao mesmo tempo, não carregue seus aplicativos para que a carga deles exceda um determinado limite.
- Escalabilidade. Adicionamos o carro ao cluster, lançamos processos nele - o que significa que você pode contar mais batalhas e aceitar jogadores.
- Alta disponibilidade. Se, por exemplo, um carro caiu ou algo deu errado com um dos processos do jogo que serve o jogo em si, não há com o que se preocupar - o jogo não notará, será restaurado em outro local e funcionará.
- Manter a integridade e consistência dos dados. Este é o segundo nível de tolerância a falhas. Se houver vários clusters, como em Tanks, e houve algum tipo de desastre no datacenter ou no canal principal, isso não significa que perderemos completamente os dados do jogo que a pessoa jogou. Vamos nos recuperar, a consistência será.
Os processos que estão em nosso sistema e suas funções- CellApp é o processo responsável por processar o espaço do jogo ou parte dele.
Como eu disse, o BigWorld trabalha com certos espaços que dividimos em células. Cada célula específica do nosso espaço de jogo é calculada por um aplicativo específico.
- CellAppMgr - o processo que coordena o trabalho do CellApp, balanceamento de carga.
CellApp pode ser muitos, portanto, deve haver um processo que os controle.
- O BaseApp gerencia entidades, isola os clientes do trabalho com o CellApp.
Uma das coisas fundamentais no BigWorld é o conceito de entidade - por exemplo, a conta de um jogador. Tudo o que fazemos no campo de batalha, fazemos com essa entidade. CellApps calcula física e mecânica de jogo, como tiro. BaseApp trabalha com entidades. Serve a conta, tanque, etc.
- ServiceApp é um BaseApp especializado que implementa algum tipo de serviço.
Esta é uma versão simplificada do BaseApp, um processo que faz várias coisas de serviço. Por exemplo, alguém deve ser capaz de ler no RabbitMQ. Isso não é sobre entidades de jogo, mas também é necessário.
- O BaseAppMgr gerencia o BaseApp e o ServiceApp, porque também existem muitos deles.
- O LoginApp cria novas conexões de clientes e também proxies de usuários no BaseApp.
- O DBApp implementa uma interface de acesso ao armazenamento (bancos de dados). Trabalhamos com Percona, mas pode ser outro banco de dados.
- O DBAppMgr coordena o trabalho do DBApp.
- O InterClusterMgr gerencia a comunicação entre clusters .
- O Revisor é um inspetor de processos que pode reiniciar os processos.
- Bwmachined - um daemon que é executado em cada máquina no cluster para coordenar seu trabalho. Ele permite que todos os gerentes da BaseApp se comuniquem.
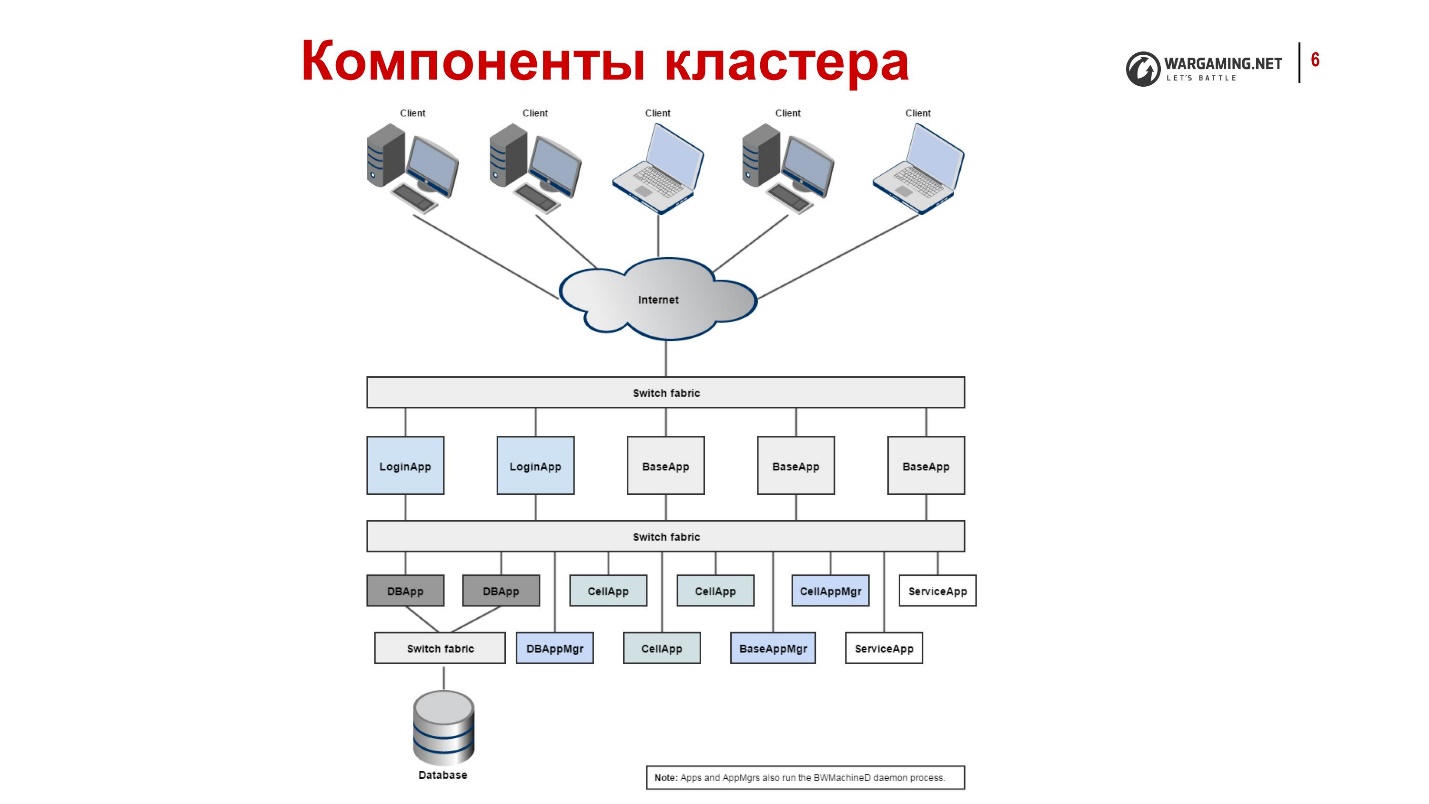
É assim que os tanques ficam por dentro, ainda que brevemente:
- Os clientes se conectam via Internet, acessam o LoginApp.
- O LoginApp os autoriza a usar o DBApp e emite um endereço do BaseApp.
- Mais clientes jogam com eles.
Tudo isso está espalhado por muitas máquinas, cada uma com um BWMachineD, que pode gerenciar tudo isso, orquestrar etc.
Ecossistema do World of Tanks
O que há por aí? Parece que existe um servidor de jogo e jogadores - escolheu um tanque, foi jogar. Mas, infelizmente (ou com alegria), o jogo está se desenvolvendo e a mecânica do jogo de "apenas atirar" não é mais suficiente. Consequentemente, o servidor do jogo começou a ficar cheio de vários serviços, alguns dos quais geralmente eram impossíveis de executar dentro do servidor, enquanto começamos a remover outros especialmente para aumentar a velocidade de entrega de conteúdo ao jogador. Ou seja, é mais rápido escrever um pequeno serviço em Python que faz algum tipo de mecânica de jogo do que dentro do servidor em todos os BaseAPPs, clusters de suporte etc.
Algumas coisas, por exemplo, sistemas de pagamento foram originalmente emitidos. Nós suportamos outros, porque a Wargaming desenvolve mais de um jogo, afinal. Esta é uma trilogia: Tanques, Aviões, Navios, e há Blitz e planos para novos jogos. Se eles estivessem dentro do BigWorld, não poderiam ser convenientemente usados em outros produtos.
Tudo foi muito rápido e caoticamente, o que resultou em algumas tecnologias de zoológico usadas em nosso ecossistema de tanques.
Principais tecnologias e protocolos:
1. Python 2.7, 3.5;
2. Erlang;
3. Scala;
4. JavaScript;
Frameworks
5. Django;
6. Falcão;
7. assíncio;
Armazenamento:
8. Postgres;
9. Percona.
10. Memcached e Redis para armazenamento em cache.
Todos juntos para o jogador, este é o servidor do tanque:
- Ponto único de autorização;
- Bate-papo
- Clãs;
- Sistema de pagamento;
- Sistema de torneios;
- Meta-jogos (mapa global, áreas fortificadas);
- Portal de Tanques, Portal do Clã;
- Gerenciamento de conteúdo etc.
Mas se você olhar, essas são coisas ligeiramente diferentes escritas em diferentes tecnologias. Isso causa alguns problemas de confiabilidade.
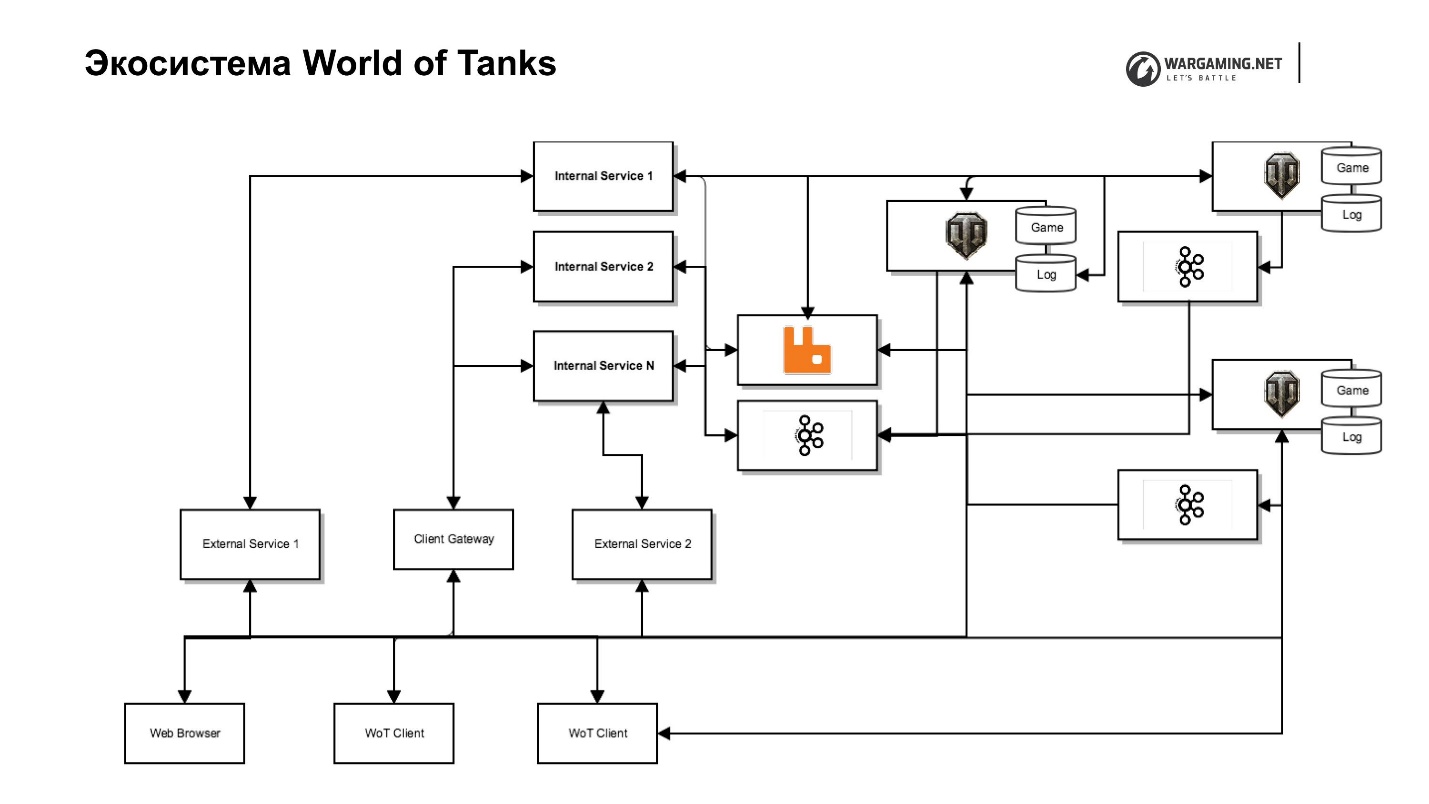
O diagrama mostra nosso servidor tanque junto com seu ecossistema. Há um servidor de jogos, serviços da Web (interno e externo), incluindo serviços completamente especiais, localizados na rede de back-end e que executam funções de serviço e serviço para eles, que realmente implementam as interfaces. Por exemplo, existe um serviço de clã com seu próprio portal de clãs, que permite gerenciar esse clã, há um portal do próprio jogo etc.
Essa separação nos permite nos preocupar menos com segurança, porque ninguém tem acesso à rede interna - menos problemas. Mas isso leva a esforços adicionais, porque precisamos de proxies que dêem acesso se for necessário enviá-lo para fora.
Eu já disse que tomamos a decisão de remover parte da lógica do jogo e outras coisas do servidor. Havia uma tarefa de alguma forma incluir tudo no cliente. Temos um maravilhoso Gateway de Cliente que permite que um cliente de tanque acesse diretamente um servidor de algumas das APIs desses Serviços Internos - os mesmos clãs ou API de nossos meta-jogos.
Além disso, colocamos a CEF (Chromium Embedded Framework) dentro do cliente do tanque. Agora temos o mesmo navegador. O jogador não o distingue da janela do jogo. Isso permite que você trabalhe com toda a infraestrutura, ignorando o trabalho com o servidor do jogo.
Temos muitos clusters - aconteceu - vou lhe dizer o porquê. É assim que a região da CEI se parece.
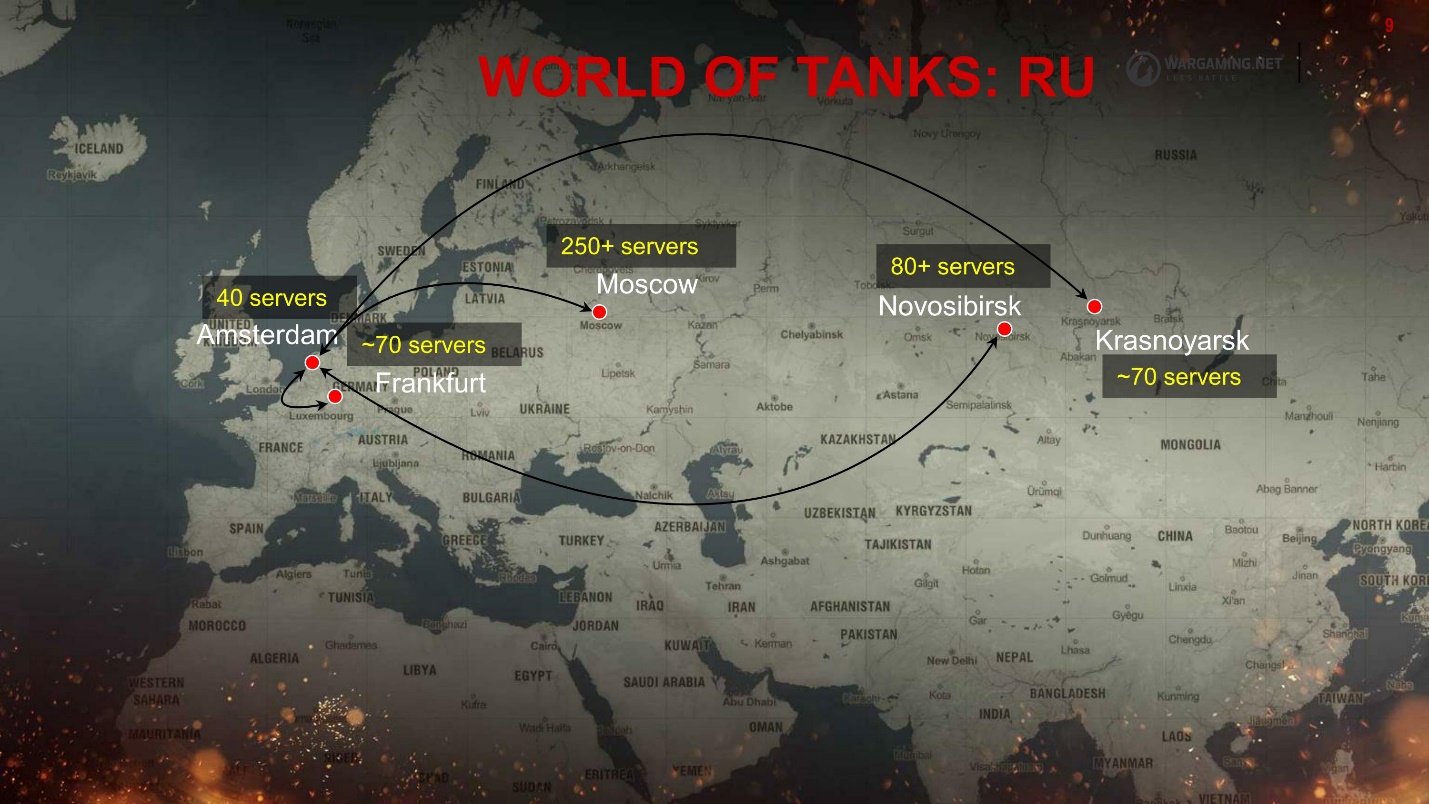
Tudo está espalhado pelos data centers. Os jogadores, dependendo de onde o ping é melhor, se conectam ao local. Mas todo o ecossistema não é dimensionado dessa maneira, é principalmente na Europa e Moscou, o que também nos adiciona alguns problemas de confiabilidade - latência e encaminhamento extras.
É assim que o ecossistema do World of Tanks se parece.
O que pode dar errado com toda essa economia? O que você quiser! E vai J. Mas vamos desmontar.
Pontos principais de falha dentro de um cluster
Falha em uma única máquina ou processo
A opção mais simples que podemos prever é a falha de uma máquina ou processo dentro de um cluster. Temos grupos de 10 a 100 carros - algo pode voar. Como eu disse, o próprio BigWorld fornece mecanismos prontos para uso que nos permitem ser mais confiáveis.
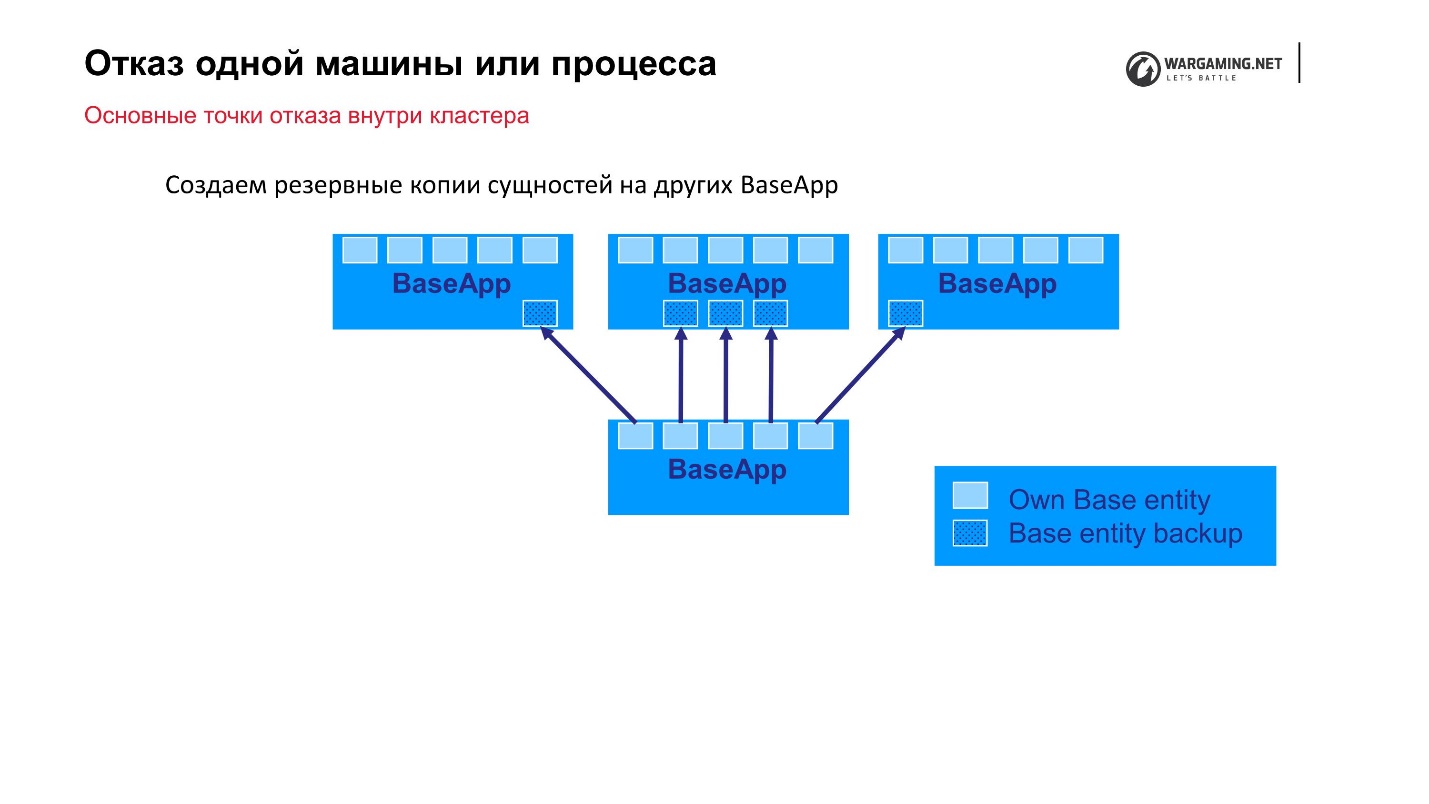
Esquema padrão: existem BaseApps espalhados por diferentes máquinas. Nesses BaseApp, existem entidades que contêm entidades de estado. Cada BaseApp faz o backup com Round Robin em outros.
Suponha que tivéssemos um arquivo e algum BaseApp morresse ou a máquina inteira morresse - tudo bem! Os BaseApps restantes deixaram essas entidades, elas serão restauradas e a jogabilidade do jogador não sofrerá.
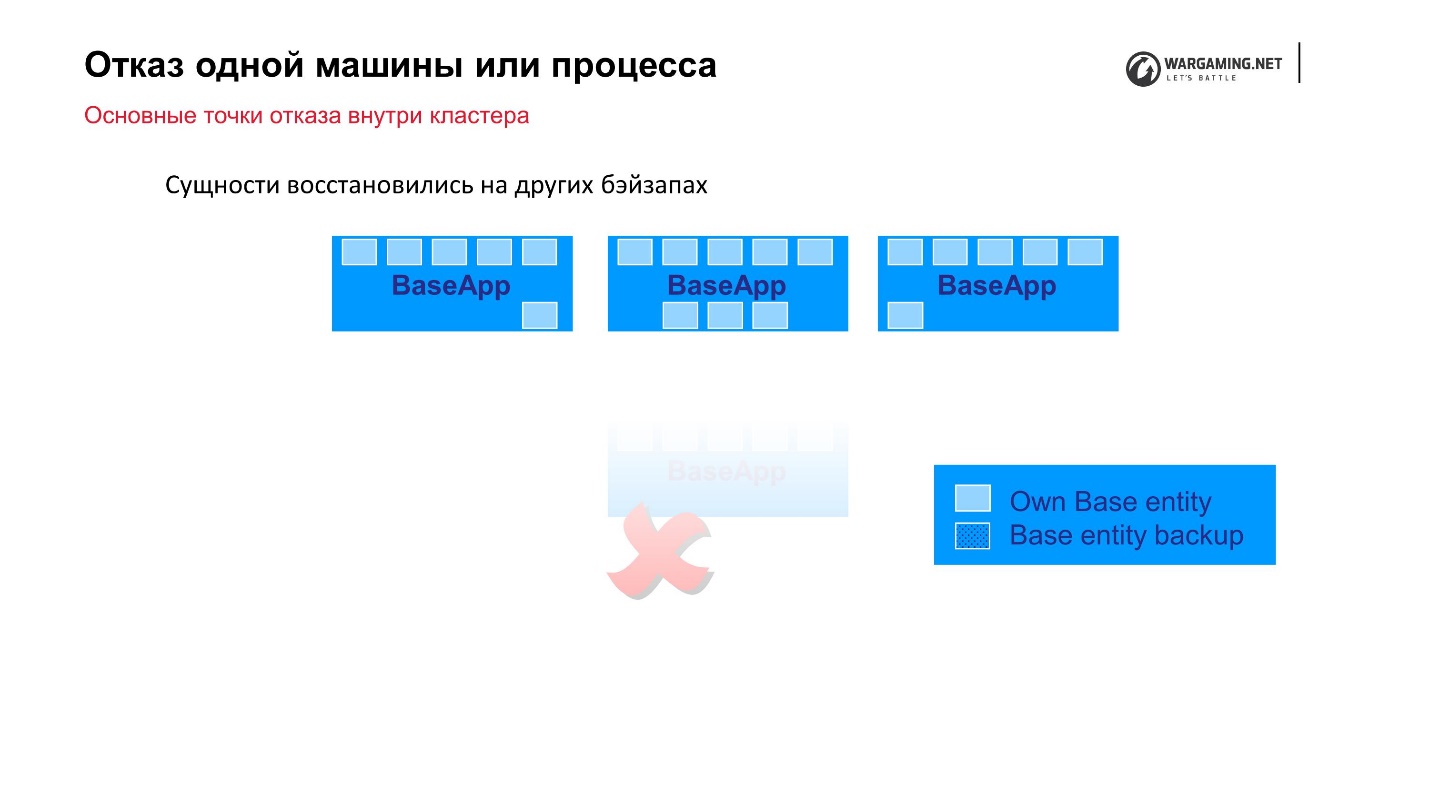
Os CellAPPs fazem exatamente a mesma coisa, a única coisa é que eles armazenam seus estados no BaseApps também, e não em outros CellAPPs.
Parece ser um mecanismo confiável, mas ...
Você tem que pagar por tudo
Com o tempo, começamos a observar o seguinte.
• A criação de cópias de segurança das entidades começa a ocupar cada vez mais recursos do sistema e tráfego de rede.
De fato, o próprio processo de backup começa a afetar a estabilidade do sistema quando dentro do cluster a maior parte da rede está ocupada transmitindo cópias para Round Robins.
• O tamanho das entidades aumenta com o tempo, à medida que novos atributos e mecânicos de jogo são adicionados.
Mas o mais desagradável é que o tamanho dessas entidades cresce como uma avalanche. Por exemplo, um jogador executa alguma ação (compra a propriedade do jogo) e essa operação começou a ficar mais lenta. Ainda não o concluímos, mas salvamos as alterações nesses atributos. Ou seja, o sistema é muito ruim e ainda estamos começando a aumentar o tamanho do backup que precisa ser feito. Há um efeito de bola de neve.
• A estabilidade geral do sistema diminui
Devido ao fato de estarmos tentando escapar da queda de uma máquina ou processo, diminuímos a estabilidade de todo o sistema.
O que fizemos para lidar com isso ? Decidimos para cada entidade destacar o que realmente precisa ser copiado. Dividimos os atributos em mutáveis e imutáveis, e não copiamos toda a entidade, mas fazemos backup apenas de seus atributos mutáveis. Dessa forma, simplesmente reduzimos a quantidade de informações que realmente precisam ser mantidas em ferro. Agora, ao adicionar um novo atributo, quem faz isso deve ver mais claramente onde atribuí-lo. Mas, em geral, isso nos salvou da situação.
Para ser completamente franco, esse mecanismo foi estabelecido no BigWorld, mas, em algum momento, no Tanks, ele não era mais suportado até o fim, e nem toda entidade pode se recuperar do backup. Em navios, por exemplo, os caras apoiam isso. Lá, você pode desligar as máquinas com segurança - as informações serão restauradas em outras máquinas e o cliente não notará nada. Infelizmente, esse nem sempre é o caso em tanques, mas obteremos o retorno de toda essa funcionalidade para que funcione como deveria.
Falha no data center. Multi-cluster
Se de repente não um ou dois carros caíssem, e começamos a perder todo o data center, ou seja, o cluster completamente, que propriedades o sistema deveria ter para que o jogo não caísse em tal situação?
- Cada cluster deve ser independente, ou seja:
- deve ter seu próprio banco de dados;
- o cluster processa apenas seus espaços (arenas de batalha).
Assim, se algumas arenas atingem, outras ainda funcionam. - Os agrupamentos devem se comunicar entre si para que se possa dizer ao segundo: "Eu caí!" Quando surgir, os dados serão restaurados a partir das cópias salvas.
- Também é desejável que você possa transferir o usuário de cluster para cluster.
No momento, o esquema do nosso multi-cluster se parece com isso.
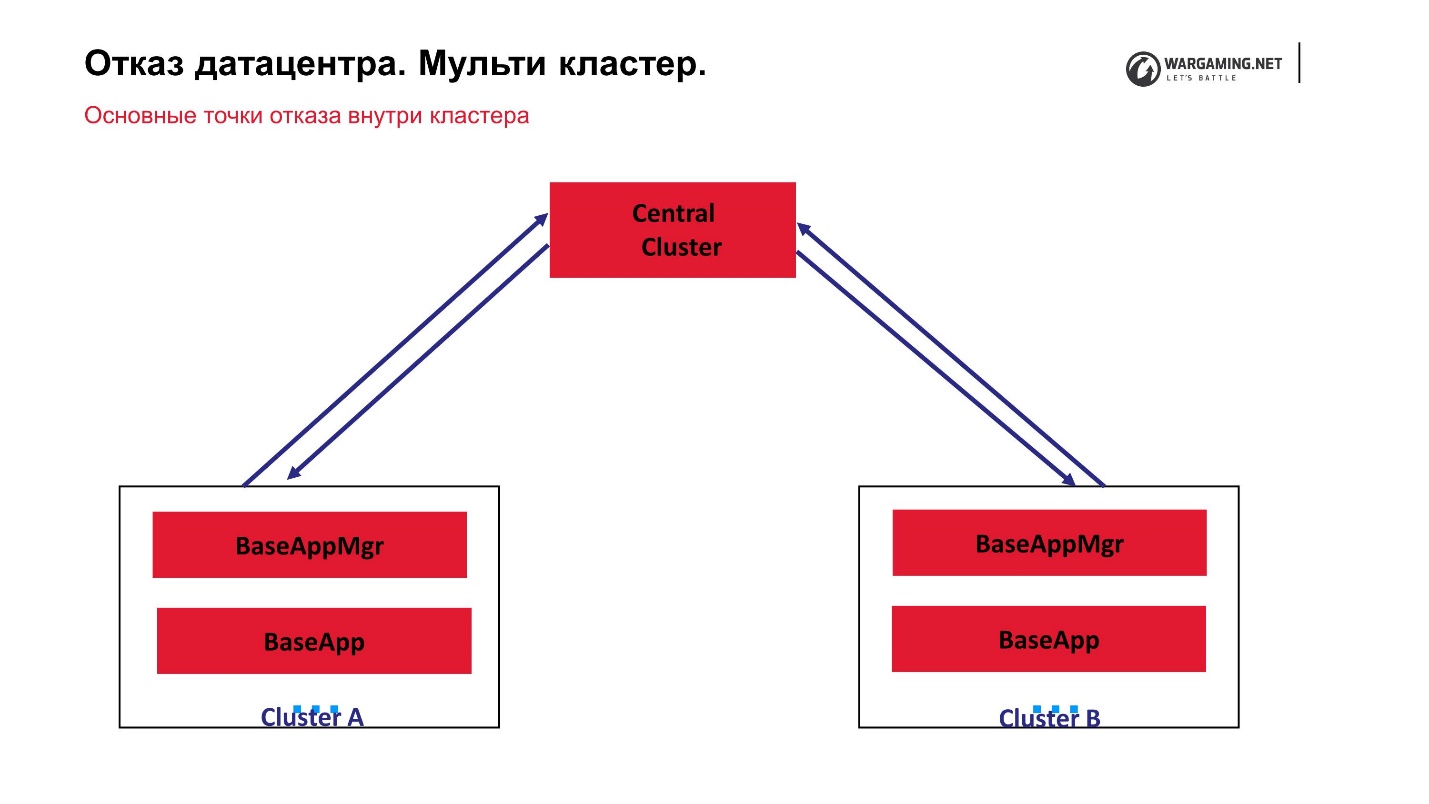
Temos um cluster central e o que chamamos de periféricos nos quais as batalhas reais estão sendo travadas. O CellApp não está sendo executado no cluster central, caso contrário, é exatamente o mesmo que todos os outros. É o ponto central do processamento da conta: eles aumentam para lá, são enviados para a periferia e, na periferia, uma pessoa já está jogando. Ou seja, a falha de qualquer um dos clusters não leva à perda de operacionalidade de todo o jogo. Mesmo a falha do cluster central simplesmente não permite que novos jogadores entrem, mas aqueles que já estão jogando na periferia podem continuar o jogo.
O fato de que tudo funciona para nós através do cluster central acabou porque, em geral, a própria tecnologia BigWorld supõe que exista um gerenciador especial entre processos de gerenciamento de processos. De fato, esses gerentes inter claster podem ser um pouco criados.
Historicamente, os tanques precisavam de um cluster múltiplo, porque começaram a crescer avalanche online. Quando atingimos o pico de 200 mil jogadores, o tráfego de entrada deles simplesmente parou de ser colocado no datacenter pela rede. Tivemos que literalmente ajoelhar algum tipo de solução para que os players pudessem ser lançados em vários data centers.
De fato, só vencemos, porque agora temos um multi-cluster. Também se tornou útil para os jogadores, porque o ping, ou seja, a acessibilidade na rede, afeta muito a jogabilidade. Se o atraso for superior a 50-70 ms, isso já começará a afetar a qualidade do jogo, porque em Tanks absolutamente tudo é calculado no servidor. Não há cálculos no cliente. Portanto, lembre-se de que praticamente não há nada a ser feito. Obviamente, alguns mods são feitos lá, mas eles não afetam o processo em si. Você pode tentar adivinhar o que vai acontecer, mas afetar a mecânica do jogo - não.
Devido a essa abordagem, nosso
cluster central tornou-se um ponto de falha . Tudo estava fechado para ele. Decidimos - já que essas máquinas e uma grande base de covis de caça estão lá, deixemos nossos periféricos lidar exclusivamente com a luta. Então realmente não há necessidade de armazenar grandes quantidades de informações - as batalhas estão sendo disputadas e estão sendo disputadas - vamos bloquear tudo lá.
Para reescrever absolutamente tudo, a fim de fugir do conceito de cluster central, agora não há tempo, nem desejo especial. Mas decidimos, primeiro, ensinar grupos de periféricos a se comunicarem. Depois, abrimos um buraco neles para que fosse possível influenciá-los usando serviços de terceiros.
Por exemplo, para criar uma batalha mais cedo, era necessário informar ao cluster central que era necessário criar uma batalha em algumas periferias. Além disso, por mecanismos internos, as entidades se movimentaram, a essência da arena foi criada, etc.
Agora é possível entrar em contato diretamente com a periferia, ignorando o cluster central. Então, removemos o trabalho extra dele. Mas até agora não há desejo de mudar completamente para um esquema no qual todos os clusters são quase ponto a ponto, e tudo isso é controlado por alguns processos, mas não pelo cluster.
Lembro que, além do cluster de jogos com seus BaseApps, CellApps e outros, temos um ecossistema.
Tentamos garantir que o desempenho do ecossistema não afete a jogabilidade. Na pior das hipóteses, por exemplo, o sistema de torneios não funciona, mas você pode jogar aleatoriamente - de qualquer maneira, a maioria das pessoas joga aleatoriamente. Sim, reduzimos a qualidade, mas em geral, você pode sobreviver várias horas sem torneios.
Isso nem sempre acontece. Em primeiro lugar, já existem esses serviços da Web que estão profundamente embutidos no jogo. Por exemplo, um único ponto de autorização é um serviço que permite que você efetue login na Web ou em algum lugar do mesmo lugar e efetue login em todo o universo Wargaming.
O segundo exemplo é um serviço que serve para compras e transações de jogos. Ele também teve que ser trazido para o jogo apenas porque precisávamos de um rastro das compras do jogador. O fato é que, em algumas regiões, somos obrigados a exibir informações ao cliente sobre quais propriedades do jogo foram compradas com dinheiro real e qual foi usada. O sistema inicialmente não assumiu isso, ninguém o expôs há cinco anos, mas a
lei é dura: você precisa fazer - faça .
Pontos de falha do ecossistema do World of Tanks
Número do problema 1. Carga aumentada
Temos um cluster múltiplo no qual 10 clusters com um grande número de máquinas. Os jogadores jogam e a web é pequena. Ninguém compra mais cinco máquinas em cada data center. Mas, ao mesmo tempo, fornecemos a mesma funcionalidade e tudo o que é necessário dentro do cliente. Esse é o principal problema.
A interatividade e reatividade da interface é a principal fonte de aumento da carga do ecossistema.
Vou dar dois exemplos do serviço de clã:
- Você quer convidar outro jogador para o clã. Obviamente, quero que o convidado receba imediatamente uma notificação e ele possa se juntar a você. Para implementar isso, é necessário fazer com que o serviço do clã notifique o cliente de alguma forma ou solicite ao serviço da web de tempos em tempos: “Alguma coisa mudou? Tenho novos convites? Esta é a primeira opção de onde a carga extra pode vir.
- Os tanques têm um regime fortificado. Suponha que seja jogado não por uma pessoa, mas por várias. Todos os jogadores têm uma janela aberta com áreas fortificadas. O comandante construiu o edifício. É aconselhável que, para todos que têm essa janela aberta, o prédio apareça imediatamente.
A decisão na testa com a pesquisa não é muito boa. De fato, está funcionando, basta que você aloque tantas capacidades para isso que esse recurso não trará nenhum lucro para a empresa. E se o recurso não gerar lucro, você não precisará fazê-lo.
Meu conselho pessoal sobre como lidar com isso: a melhor maneira de tornar o sistema mais confiável sob carga é geralmente reduzir a carga de alguma maneira lógica.
Você não deve se deitar com ferro, criar sistemas com novos ventiladores, otimizar alguma coisa. De qualquer forma, quanto maior a carga, mais artefatos aparecerão dos quais você não pode se afastar. Além disso, os artefatos ocorrerão mesmo em níveis cada vez mais baixos de abstração - primeiro com aplicativos, depois com diferentes serviços da Web, e você chegará à rede (Cisco, etc.). Em algum nível, você simplesmente não pode resolver os problemas.
Se você pensar com cuidado, eles podem ser simplesmente evitados.
A primeira coisa que fizemos foi
aprender a notificar os clientes por meio de um servidor de jogos usando sua infraestrutura. Por exemplo, quando um convite é enviado ao clã, dizemos ao servidor: “Convidamos essas e essas pessoas” e, em seguida, o próprio cluster encontra aquele para quem a notificação deve ser enviada, principalmente porque eles têm uma conexão. Ou seja, pressionamos o serviço, e ninguém constantemente nos derrama. , , . , , .
—
Web-sockets (nginx-pushstream) . , Web-sockets. , Chromium Embedded Framework — , , Web-sockets Nginx. pushstream, Web-sockets .
№ 2.
, , ,
— . , , — .
, , .
? : - , - , , . - , , . .
.

,
120 Game Play . . , , . , . .
3 , :
- HTTP API;
- RabbitMQ — ;
- Apache Kafka .
, , , , , . , - — , . , .
1. HTTP— HTTP. , , -, . :
, , . , , , Django, 100 200 , API, . , , - 30-40 , , . , — .
, , HTTP, — . . — — . ,
, , , .
. . - , - API — API, .
— , . , , . , 10 , - 100 500. , HTTP . nginx' , — .
, HTTP , .
2. RabbitMQRabbitMQ BigWord .
— - , , , .
: . , API: « N — ». , , , , — . , .
«», «», — .
RabbitMQ , , , , , , , .
— RabbitMQ .
3. Kafka, , — Kafka. , RabbitMQ - .
, , , . , , . . Kafka. , — , .
, . , , - — .
Kafka , , , - , . .
— .

:
- . , - , ..
- — , , , .
- — , . , , .
. , , , entity. . , , .
DLC
, DLC (Development Lifecycle) — , , .
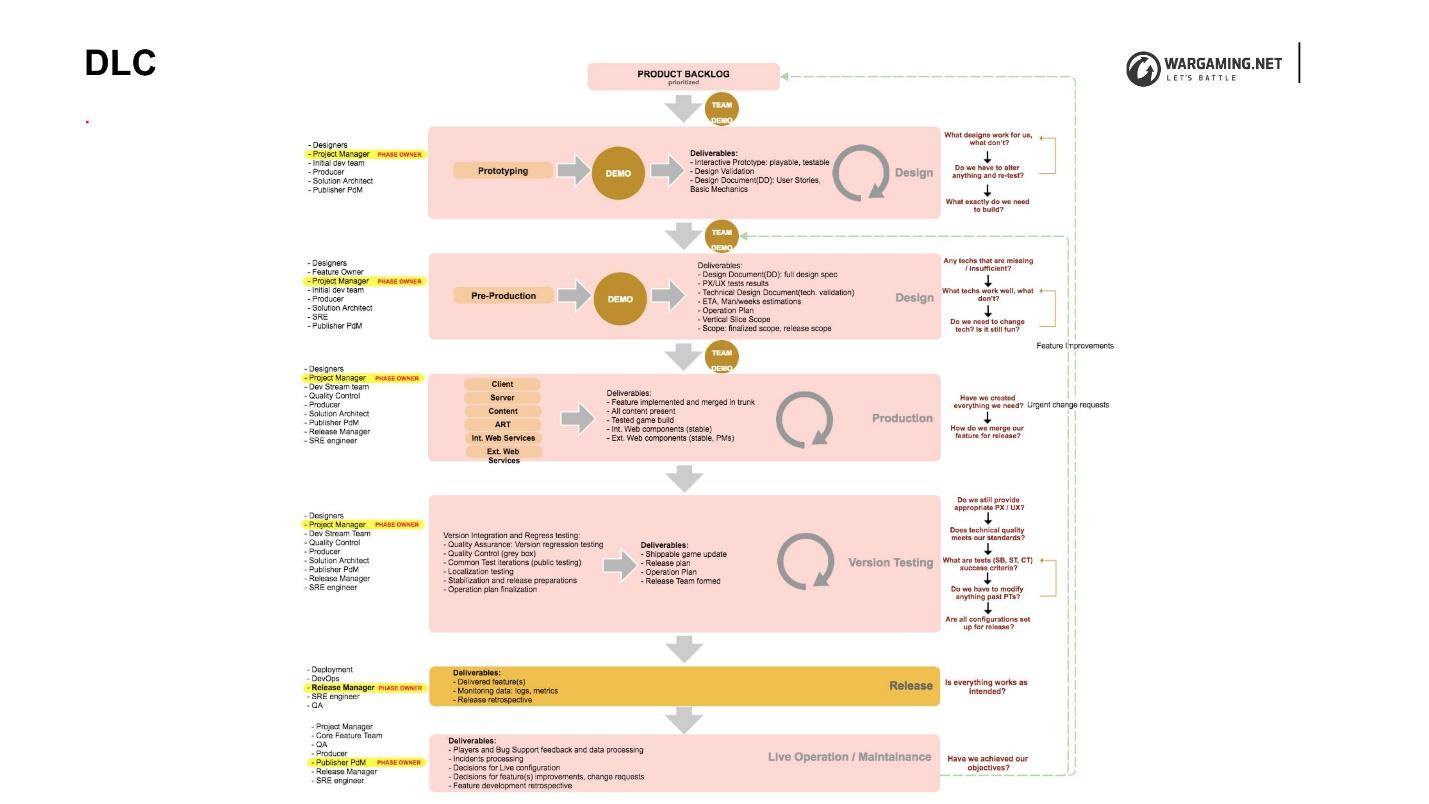
, , . DLC , , . , . , , , .
DLC, . , , , .
DLC, , :
•
( )., , «- , », . , , , , .
• : SRE.
, solution-, technical-owner, reability- — , - , game- . , , , . - , , , , . , .
•
SRE .— - . , . , SRE -. SRE , : « , , , — !» , .
QA , , - , , — .
BigWorld Technology «» . , . . « », .
« » , , . — «» (, ) — . , . , - .
: ++. , 40 , . , .RootConf — DevOpsConf Russia . DevOps 1 2 , . , . , — !