 Para mim, começou seis anos e meio atrás, quando, pela vontade do destino, fui atraído para um projeto fechado. Cujo projeto - não pergunte, não vou contar. Só posso dizer que a ideia dele era simples como um ancinho: incorporar o front-end do clang no IDE. Bem, como foi feito recentemente no QtCreator, no CLion (em certo sentido), etc. Clang era então uma estrela em ascensão, muitos estavam pensando na possibilidade de finalmente usar o analisador C ++ completo quase de graça. E a ideia, por assim dizer, estava literalmente no ar (e o preenchimento automático do código incorporado na API do clang foi sugerido por Be), você só precisava pegá-lo e fazê-lo. Mas, como Boromir disse: "Você não pode simplesmente aceitar e ...". Então aconteceu neste caso. Para detalhes - Wellcome sob cat.
Para mim, começou seis anos e meio atrás, quando, pela vontade do destino, fui atraído para um projeto fechado. Cujo projeto - não pergunte, não vou contar. Só posso dizer que a ideia dele era simples como um ancinho: incorporar o front-end do clang no IDE. Bem, como foi feito recentemente no QtCreator, no CLion (em certo sentido), etc. Clang era então uma estrela em ascensão, muitos estavam pensando na possibilidade de finalmente usar o analisador C ++ completo quase de graça. E a ideia, por assim dizer, estava literalmente no ar (e o preenchimento automático do código incorporado na API do clang foi sugerido por Be), você só precisava pegá-lo e fazê-lo. Mas, como Boromir disse: "Você não pode simplesmente aceitar e ...". Então aconteceu neste caso. Para detalhes - Wellcome sob cat.
Primeiro sobre o bem
Os benefícios de usar o clang como um analisador interno no IDE C ++, é claro. No final, as funções do IDE não se limitam apenas à edição de arquivos. Este é um banco de dados de caracteres, tarefas de navegação, dependências e muito mais. E aqui um compilador de pleno direito dirige-se à sua altura máxima, porque dominar todo o poder do pré-processador e modelos em um analisador auto-escrito relativamente simples é uma tarefa não trivial. Como você geralmente precisa fazer muitos compromissos, o que obviamente afeta a qualidade da análise de código. Quem se importa - pode ver, por exemplo, o analisador interno do QtCeator aqui: analisador Qt Creator C ++
No mesmo local, no código-fonte do QtCreator, você pode ver que o acima não é tudo o que o IDE requer do analisador. Além disso, você precisa de pelo menos:
- realce de sintaxe (lexical e semântico)
- todos os tipos de dicas "on the fly" com a exibição de informações no símbolo
- dicas sobre o que há de errado com o código e como corrigi-lo / complementá-lo
- Conclusão de código em uma ampla variedade de contextos
- a refatoração mais diversificada
Portanto, nos benefícios listados anteriormente (realmente sério!), As vantagens terminam e a dor começa. Para entender melhor essa dor, primeiro você pode ver o relatório de Anastasia Kazakova ( anastasiak2512 ) sobre o que é realmente necessário no analisador de código incorporado no IDE:
A essência do problema
Mas é simples, embora possa não ser óbvio à primeira vista. Em poucas palavras, então: clang é um compilador . E refere-se ao código como um compilador . E aguçado pelo fato de que o código foi fornecido a ele já concluído, e não o esboço do arquivo que agora está aberto no editor do IDE. Os compiladores não gostam de bits de arquivos, como construções incompletas, identificadores escritos incorretamente, retrunde em vez de retornar e outras delícias que podem surgir aqui e agora no editor. Obviamente, antes da compilação, tudo isso será limpo, consertado e alinhado. Mas aqui e agora, no editor, é o que é. E é dessa forma que o analisador incorporado no IDE chega à tabela a cada 5-10 segundos. E se a versão auto-escrita dele "entende perfeitamente" que está lidando com um produto semi-acabado, então clang - não. E muito surpreso. O que acontece como resultado de tal surpresa depende "de", como eles dizem.
Felizmente, o clang é bastante tolerante a erros de código. No entanto, pode haver surpresas - luz de fundo desaparecendo repentinamente, curva de preenchimento automático, diagnóstico estranho. Você precisa estar preparado para tudo isso. Além disso, o clang não é onívoro. Ele tem o direito de não aceitar nada nos cabeçalhos do compilador, que aqui e agora é usado para criar o projeto. Intrínsecas complicadas, extensões não padrão e outras, um ..., recursos - tudo isso pode levar a erros de análise nos locais mais inesperados. E, claro, desempenho. Editar um arquivo de gramática no Boost.Spirit ou trabalhar em um projeto baseado no llvm será um prazer. Mas, sobre tudo em mais detalhes.
Código pré-fabricado
Então, digamos que você iniciou um novo projeto. Seu ambiente gerou um espaço em branco padrão para main.cpp e nele você escreveu:
#include <iostream> int main() { foo(10) }
O código, do ponto de vista do C ++, francamente, é inválido. Não há definição da função foo (...) no arquivo, a linha não está concluída, etc. Mas ... Você acabou de iniciar. Este código tem direito a esse tipo. Como esse código percebe um IDE com um analisador auto-escrito (neste caso, CLion)?
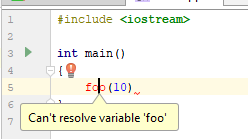
E se você clicar na lâmpada, poderá ver o seguinte:
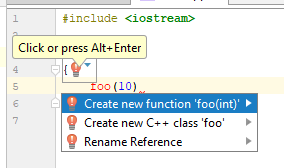
Esse IDE, sabendo algo, um pouco mais sobre o que está acontecendo, oferece a opção muito esperada: criar uma função a partir do contexto de uso. Ótima oferta, eu acho. Como o IDE baseado em clang se comporta (neste caso, Qt Creator 4.7)?
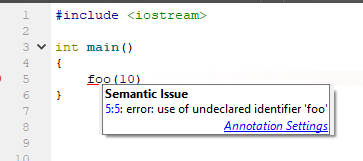
E o que está sendo proposto para corrigir a situação? Mas nada! Somente renomear padrão!
A razão para esse comportamento é muito simples: para clang, esse texto está completo (e não pode ser mais nada). E ele constrói o AST com base nessa suposição. E então tudo é simples: o clang vê um identificador indefinido anteriormente. Este é um texto em C ++ (não em C). Nenhuma suposição é feita sobre a natureza do identificador - ele não está definido, portanto, um pedaço de código é inválido. E no AST para esta linha nada aparece. Ela simplesmente não está lá. E o que não está no AST é impossível de analisar. É uma pena, irritante, tudo bem.
O analisador incorporado no IDE vem de algumas outras suposições. Ele sabe que o código não está concluído. Que o programador está agora apressando o pensamento e os dedos atrás dela não têm tempo. Portanto, nem todos os identificadores podem ser definidos. É claro que esse código está incorreto do ponto de vista dos altos padrões de qualidade do compilador, mas o analisador sabe o que pode ser feito com esse código e oferece opções. Opções bastante razoáveis.
Pelo menos até a versão 3.7 (inclusive), problemas semelhantes ocorreram neste código:
#include <iostream> class Temp { public: int i; }; template<typename T> class Foo { public: int Bar(Temp tmp) { Tpl(tmp); } private: template<typename U> void Tpl(U val) { Foo<U> tmp(val); tmp. } int member; }; int main() { return 0; }
Dentro dos métodos da classe de modelo, o preenchimento automático baseado em clang não funcionou. Tanto quanto eu consegui descobrir, o motivo estava na análise de modelos de duas passagens. O preenchimento automático no clang é acionado na primeira passagem, quando as informações sobre os tipos realmente usados podem não ser suficientes. No clang 5.0 (a julgar pelas notas de versão), isso foi corrigido.
De uma maneira ou de outra, podem ser situações em que o compilador não é capaz de criar o AST correto (ou tirar as conclusões corretas do contexto) no código editado. E, nesse caso, o IDE simplesmente não "verá" as seções correspondentes do texto e não poderá ajudar o programador de nenhuma maneira. O que, é claro, não é ótimo. A capacidade de trabalhar efetivamente com código incorreto é o que o analisador precisa no IDE e o que o compilador comum não precisa. Portanto, o analisador no IDE pode usar muitas heurísticas, que para o compilador podem ser não apenas inúteis, mas também prejudiciais. E para implementar dois modos de operação nele - bem, você ainda precisa convencer os desenvolvedores.
"Este papel é abusivo!"
O IDE do programador geralmente é um (bem, dois), mas há muitos projetos e cadeias de ferramentas. E, é claro, não quero fazer gestos extras para mudar da cadeia de ferramentas para a cadeia de ferramentas, de projeto para projeto. Um ou dois cliques, e a configuração da compilação muda de Debug para Release, e o compilador de MSVC para MinGW. Mas o analisador de código no IDE permanece o mesmo. E ele deve, juntamente com o sistema de compilação, alternar de uma configuração para outra, de uma cadeia de ferramentas para outra. Uma cadeia de ferramentas pode ser algum tipo de exótica ou cruzada. E a tarefa do analisador aqui é continuar analisando corretamente o código. Se possível com um mínimo de erros.
o clang é onívoro o suficiente. Ele pode ser forçado a aceitar extensões do compilador da Microsoft, o compilador gcc. Podem ser passadas opções no formato desses compiladores, e o clang até as entenderá. Mas tudo isso não garante que o clang aceite qualquer posição das miudezas coletadas no tanque gcc. Qualquer __builtin_intrinsic_xxx pode se tornar uma pedra de tropeço para ele. Ou a linguagem constrói que a versão atual do clang no IDE simplesmente não suporta. Provavelmente, isso não afetará a qualidade da construção do AST para o arquivo editado no momento. Mas construir uma base global de caracteres ou salvar cabeçalhos pré-compilados pode quebrar. E isso pode ser um problema sério. Um problema semelhante pode vir a ser um código semelhante, não nos cabeçalhos das cadeias de ferramentas ou de terceiros, mas nos cabeçalhos ou nos códigos-fonte do projeto. A propósito, tudo isso é uma razão suficientemente significativa para informar explicitamente ao sistema de compilação (e IDE) sobre quais arquivos de cabeçalho para o seu projeto são "estranhos". Pode facilitar a vida.
Novamente, o IDE foi originalmente projetado para ser usado com diferentes compiladores, configurações, cadeias de ferramentas e muito mais. Projetado para lidar com código, cujos elementos não são suportados. O ciclo de lançamento do IDE (nem todos :)) é mais curto que o dos compiladores; portanto, existe o potencial de atrair novos recursos mais rapidamente e responder aos problemas encontrados. No mundo dos compiladores, tudo é um pouco diferente: o ciclo de lançamento é de pelo menos um ano, os problemas de compatibilidade entre compiladores são resolvidos por compilação condicional e repassados aos ombros do desenvolvedor. O compilador não precisa ser universal e onívoro - sua complexidade já é alta. clang não é exceção.
A luta pela velocidade
Na parte do tempo gasto no IDE, quando o programador não está sentado no depurador, ele edita o texto. E seu desejo natural aqui é torná-lo confortável (caso contrário, por que um IDE? Posso conviver com um bloco de notas!) O conforto, em particular, envolve a alta velocidade de reação do editor às alterações de texto e pressionamento de teclas de atalho. Como Anastasia observou corretamente em seu relatório, se cinco segundos depois de pressionar Ctrl + Space, o ambiente não respondeu com a aparência de um menu ou de uma lista do preenchimento automático, isso é terrível (sério, tente você mesmo). Em números, isso significa que o analisador embutido no IDE tem cerca de um segundo para avaliar as alterações no arquivo e reconstruir o AST, e outro e meio ou dois para oferecer ao desenvolvedor uma opção sensível ao contexto. Segundo. Bem, talvez dois. Além disso, o comportamento esperado é que, se o desenvolvedor alterou o apelido .h e depois mudou para o .cpp-shnik, as alterações feitas serão "visíveis". Os arquivos, aqui estão eles, abertos nas janelas vizinhas. E agora um cálculo simples. Se o clang, iniciado a partir da linha de comando, pode lidar com o código-fonte em cerca de dez a vinte segundos, onde está o motivo para acreditar que, quando iniciado a partir do IDE, ele lidará com o código-fonte muito mais rápido e se encaixará nesse segundo ou dois? Ou seja, funcionará uma ordem de magnitude mais rápido? Em geral, isso pode estar terminado, mas não vou.
Cerca de dez a vinte segundos para a fonte, é claro, eu exagerei. Embora, se alguma API pesada seja incluída lá ou, por exemplo, boost.spirit com Hana pronto, e tudo isso seja usado ativamente no texto, 10 a 20 segundos ainda serão bons valores. Mas mesmo que o AST esteja pronto segundos depois de três ou quatro após o lançamento do analisador interno - já é muito tempo. Desde que esses lançamentos devam ser tão regulares (para manter o modelo e o índice de código em um estado consistente, realce, prompt, etc.), bem como sob demanda - a conclusão do código também é o lançamento do compilador. É possível reduzir de alguma forma esse tempo? Infelizmente, no caso de usar o clang como um analisador, não há muitas possibilidades. Razão: essa é uma ferramenta de terceiros na qual ( idealmente ) as alterações não podem ser feitas. Ou seja, cavar o código clang com perftool, otimizar, simplificar algumas ramificações - esses recursos não estão disponíveis e você tem a ver com o que a API externa fornece (no caso de usar libclang, também é bastante restrito).
A primeira, óbvia e, de fato, a única solução é usar cabeçalhos pré-compilados gerados dinamicamente. Com a implementação adequada, a solução é excelente. Aumenta a velocidade de compilação às vezes, pelo menos. Sua essência é simples: o ambiente coleta todos os cabeçalhos de terceiros (ou cabeçalhos fora da raiz do projeto) em um único arquivo .h, cria pch a partir desse arquivo e inclui implicitamente esse pch em cada fonte. Obviamente, um efeito colateral óbvio aparece: no código-fonte ( no estágio de edição ), podem ser vistos símbolos que não estão incluídos nele. Mas isso é uma cobrança pela velocidade. Eu tenho que escolher E tudo ficaria bem, se não fosse por um pequeno problema: o clang ainda é um compilador. E, sendo um compilador, ele não gosta de erros no código. E se de repente (de repente! - consulte a seção anterior) houver erros nos cabeçalhos, o arquivo .pch não será criado. Pelo menos, estava na versão 3.7. Alguma coisa mudou a esse respeito desde então? Eu não sei, há uma suspeita de que não. Infelizmente, não há mais nenhuma oportunidade de verificar.
Opções alternativas, infelizmente, não estão disponíveis pelo mesmo motivo: clang é um compilador e uma coisa "em si". Intervir ativamente no processo de geração do AST, de alguma forma fazê-lo mesclar o AST de diferentes partes, manter bases de símbolos externas e te e te - alas, todos esses recursos não estão disponíveis. Somente API externa, apenas incondicional e configurações disponíveis através das opções de compilação. E então a análise do AST resultante. Se você se sentar na versão C ++ da API, um pouco mais de oportunidades estarão disponíveis. Por exemplo, você pode brincar com FrontendActions personalizadas, fazer configurações mais refinadas para opções de compilação, etc. Mas, neste caso, o ponto principal não será alterado - o texto editado (ou indexado) será compilado independentemente dos outros e completamente. Só isso. O ponto.
Talvez (talvez!) Algum dia haverá um garfo do clang upstream especialmente adaptado para uso como parte do IDE. Possivelmente. Mas, por enquanto, tudo é como é. Digamos que a integração da equipe do Qt Creator (até a fase "final") com a libclang levou sete anos. Eu tentei o QtC 4.7 com um mecanismo baseado em libclang - admito que eu pessoalmente gosto da versão antiga (na auto-escrita) mais simplesmente porque funciona melhor nos meus casos: solicita e destaca e tudo mais. Não vou me comprometer a estimar quantas horas humanas eles gastaram nessa integração, mas me atrevo a sugerir que durante esse período seria possível concluir meu próprio analisador. Pelo que sei (por indicações indiretas), a equipe que trabalha no CLion procura cautelosamente a integração com o libclang / clang ++. Mas essas são suposições puramente pessoais. A integração no nível do Language Server Protocol é uma opção interessante, mas especificamente para o caso C ++, costumo considerar isso mais como um paliativo pelos motivos listados acima. Ele simplesmente transfere problemas de um nível de abstração para outro. Mas talvez eu seja confundido com o LSP - o futuro. Vamos ver De qualquer maneira, a vida dos desenvolvedores de IDEs modernos para C ++ é cheia de aventuras - com o clang como back-end ou sem ele.