“A equipe do @Cloudflare acabou de fazer alterações que melhoraram significativamente o desempenho da nossa rede, especialmente para as solicitações mais lentas. Quanto mais rápido? Estimamos que estamos economizando na Internet cerca de 54 anos por dia que seriam gastos esperando os sites serem carregados .
” - Matthew Prince
tweet , 28 de junho de 2018
10 milhões de sites, aplicativos e APIs usam o Cloudflare para acelerar o download de conteúdo para os usuários. No pico, processamos mais de 10 milhões de solicitações por segundo em 151 data centers. Ao longo dos anos, fizemos muitas alterações em nossa versão do Nginx para lidar com o crescimento. Este artigo é sobre uma dessas alterações.
Como o Nginx funciona
O Nginx é um dos programas que usa loops de processamento de eventos para resolver
o problema
do C10K . Cada vez que um evento de rede chega (uma nova conexão, solicitação ou notificação para enviar uma quantidade maior de dados etc.), o Nginx acorda, processa o evento e retorna para outro trabalho (isso pode estar processando outros eventos). Quando um evento chega, os dados estão prontos, o que permite processar com eficiência muitas solicitações simultâneas sem tempo de inatividade.
num_events = epoll_wait(epfd, events, events_len, -1); // events is list of active events // handle event[0]: incoming request GET http://example.com/ // handle event[1]: send out response to GET http://cloudflare.com/
Por exemplo, aqui está a aparência de um pedaço de código para ler dados de um descritor de arquivo:
// we got a read event on fd while (buf_len > 0) { ssize_t n = read(fd, buf, buf_len); if (n < 0) { if (errno == EWOULDBLOCK || errno == EAGAIN) { // try later when we get a read event again } if (errno == EINTR) { continue; } return total; } buf_len -= n; buf += n; total += n; }
Se fd for um soquete de rede, os bytes já recebidos serão retornados. A última chamada retornará
EWOULDBLOCK . Isso significa que o buffer de leitura local terminou e você não deve mais ler neste soquete até que os dados apareçam.
E / S de disco é diferente da rede
Se fd for um arquivo regular no Linux,
EWOULDBLOCK e
EWOULDBLOCK nunca aparecerão e a operação de leitura sempre aguardará a leitura de todo o buffer, mesmo que o arquivo seja aberto usando
O_NONBLOCK . Conforme escrito no manual
aberto (2) :
Observe que esse sinalizador não é válido para arquivos regulares e dispositivos de bloqueio.
Em outras palavras, o código acima é essencialmente reduzido a isso:
if (read(fd, buf, buf_len) > 0) { return buf_len; }
Se o manipulador precisar ler do disco, ele bloqueará o loop de eventos até que a leitura seja concluída e os manipuladores de eventos subsequentes aguardem.
Isso é normal para a maioria das tarefas, pois a leitura de um disco geralmente é muito rápida e muito mais previsível do que esperar por um pacote da rede. Especialmente agora que todo mundo tem um SSD e todos os nossos caches estão em SSDs. Nos SSDs modernos, um atraso muito pequeno, geralmente em dezenas de microssegundos. Além disso, você pode executar o Nginx com vários fluxos de trabalho para que um manipulador de eventos lento não bloqueie solicitações em outros processos. Na maioria das vezes, você pode confiar no Nginx para processar solicitações de forma rápida e eficiente.
Desempenho do SSD: nem sempre como prometido
Como você deve ter adivinhado, essas suposições nem sempre são verdadeiras. Se cada leitura sempre leva 50 μs, a leitura de 0,19 MB em blocos de 4 KB (e lemos em blocos ainda maiores) levará apenas 2 ms. Mas os testes mostraram que o tempo até o primeiro byte às vezes é muito pior, especialmente nos percentis 99 e 999. Em outras palavras, a leitura mais lenta de cada 100 (ou 1000) leituras geralmente leva muito mais tempo.
As unidades de estado sólido são muito rápidas, mas conhecidas por sua complexidade. Eles possuem computadores nessa fila e reordenam a E / S e também executam várias tarefas em segundo plano, como coleta de lixo e desfragmentação. De tempos em tempos, as solicitações diminuem visivelmente. Meu colega
Ivan Bobrov lançou vários benchmarks de E / S e registrou atrasos de leitura de até 1 segundo. Além disso, alguns de nossos SSDs apresentam mais picos de desempenho do que outros. No futuro, levaremos esse indicador em consideração ao comprar um SSD, mas agora precisamos desenvolver uma solução para o equipamento existente.
Distribuição uniforme de carga com SO_REUSEPORT
É difícil evitar uma resposta lenta a cada 1000 solicitações, mas o que realmente não queremos é bloquear as 1000 solicitações restantes por um segundo inteiro. Conceitualmente, o Nginx é capaz de processar muitas solicitações em paralelo, mas inicia apenas um manipulador de eventos por vez. Então, adicionei uma métrica especial:
gettimeofday(&start, NULL); num_events = epoll_wait(epfd, events, events_len, -1); // events is list of active events // handle event[0]: incoming request GET http://example.com/ gettimeofday(&event_start_handle, NULL); // handle event[1]: send out response to GET http://cloudflare.com/ timersub(&event_start_handle, &start, &event_loop_blocked);
O 99º percentil (p99)
event_loop_blocked excedeu 50% do nosso TTFB. Em outras palavras, metade do tempo ao atender a uma solicitação é o resultado do bloqueio do ciclo de processamento de eventos por outras solicitações.
event_loop_blocked mede apenas metade do bloqueio (porque as chamadas pendentes para
epoll_wait() não
epoll_wait() medidas), portanto, a proporção real do tempo bloqueado é muito maior.
Cada uma de nossas máquinas executa o Nginx com 15 fluxos de trabalho, ou seja, uma E / S lenta bloqueará no máximo 6% das solicitações. Mas os eventos não são distribuídos igualmente: o trabalhador principal recebe 11% das solicitações.
SO_REUSEPORT pode resolver o problema de distribuição desigual. Marek Maikovsky escreveu anteriormente sobre a
desvantagem dessa abordagem no contexto de outras instâncias do Nginx, mas aqui você pode ignorá-la principalmente: as conexões upstream no cache são duráveis, para que você possa negligenciar um ligeiro aumento no atraso ao abrir a conexão. Essa alteração de configuração sozinha com a ativação do
SO_REUSEPORT melhorou o pico de p99 em 33%.
Movendo read () para um pool de threads: não é um marcador de prata
A solução é tornar o read () sem bloqueio. Na verdade, essa função é
implementada no Nginx normal ! Usando a seguinte configuração, read () e write () são executados no conjunto de encadeamentos e não bloqueiam o loop de eventos:
aio threads; aio_write on;
Mas testamos essa configuração e, em vez de melhorar o tempo de resposta em 33 vezes, notamos apenas uma pequena alteração na p99, a diferença está dentro da margem de erro. O resultado foi muito desanimador, então adiamos temporariamente essa opção.
Existem várias razões pelas quais não tivemos melhorias significativas, como os desenvolvedores do Nginx. No teste, eles usaram 200 conexões simultâneas para solicitar arquivos de 4 MB ao disco rígido. Os Winchesters têm muito mais latência de E / S; portanto, a otimização tem um efeito maior.
Além disso, estamos preocupados principalmente com o desempenho do p99 (e p999). A otimização do atraso médio não resolve necessariamente o problema de pico de emissão.
Finalmente, em nosso ambiente, os tamanhos de arquivo típicos são muito menores. 90% de nossos acertos no cache são menores que 60 KB. Quanto menores os arquivos, menos casos de bloqueio (geralmente lemos o arquivo inteiro em duas leituras).
Vamos examinar a E / S do disco quando atingida no cache:
// https://example.com 0xCAFEBEEF fd = open("/cache/prefix/dir/EF/BE/CAFEBEEF", O_RDONLY); // 32 // , "aio threads" read(fd, buf, 32*1024);
32K nem sempre são lidos. Se os cabeçalhos forem pequenos, você precisará ler apenas 4 KB (não usamos E / S diretamente, portanto o kernel arredondará para 4 KB).
open() parece inofensivo, mas na verdade consome recursos. No mínimo, o kernel deve verificar se o arquivo existe e se o processo de chamada tem permissão para abri-lo. Ele precisa encontrar o inode para
/cache/prefix/dir/EF/BE/CAFEBEEF , e para isso ele terá que procurar
CAFEBEEF em
/cache/prefix/dir/EF/BE/ . Em suma, no pior dos casos, o kernel realiza esta pesquisa:
/cache /cache/prefix /cache/prefix/dir /cache/prefix/dir/EF /cache/prefix/dir/EF/BE /cache/prefix/dir/EF/BE/CAFEBEEF
São 6 leituras separadas que o
open() produz, em comparação com 1
read() ! Felizmente, na maioria dos casos, a pesquisa cai no
cache do
dentry e não atinge o SSD. Mas é claro que o processamento de
read() em um pool de threads é apenas metade da imagem.
Acorde final: aberto sem bloqueio () em conjuntos de encadeamentos
Portanto, fizemos uma alteração no Nginx para que
open() seja executado principalmente dentro do pool de threads e não bloqueie o loop de eventos. E aqui está o resultado de abrir () e ler () sem bloqueio ao mesmo tempo:
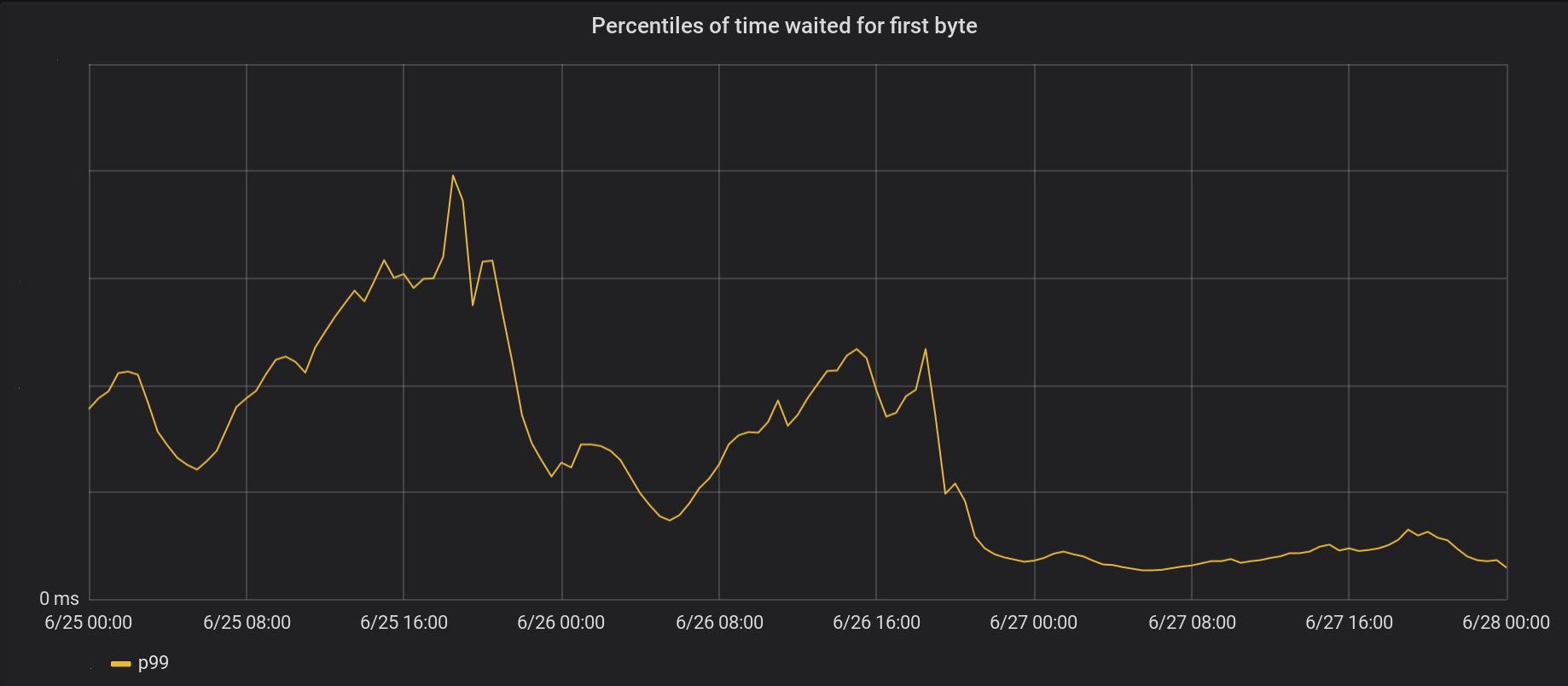
Em 26 de junho, lançamos as alterações nos 5 data centers mais movimentados e no dia seguinte - em todos os outros 146 data centers do mundo. O pico total de TT99 p99 diminuiu 6 vezes. De fato, se resumirmos o tempo todo o processamento de 8 milhões de solicitações por segundo, pouparemos à Internet 54 anos de espera todos os dias.
Nossa série de eventos ainda não se livrou completamente dos bloqueios. Em particular, o bloqueio ainda ocorre na primeira vez em que o arquivo é armazenado em cache (
open(O_CREAT) e
rename() ) ou ao atualizar a revalidação. Mas esses casos são raros se comparados aos acessos ao cache. No futuro, consideraremos a possibilidade de mover esses elementos para fora do loop de processamento de eventos para melhorar ainda mais o fator de atraso p99.
Conclusão
O Nginx é uma plataforma poderosa, mas escalar cargas extremamente altas de E / S do Linux pode ser uma tarefa assustadora. O Nginx padrão transfere a leitura em threads separados, mas em nossa escala, geralmente precisamos dar um passo adiante.