Esta é uma história sobre como transportar JavaScript para a plataforma doméstica Elbrus, feita por caras da UniPro. O artigo fornece uma breve análise comparativa de plataformas, detalhes de processos e armadilhas.

O artigo é baseado em um relatório de Dmitry (
dbezheckov ) Bezhetskov e Vladimir (
volodyabo ) Anufrienko com HolyJS 2018 Piter. Abaixo do corte, você encontrará a transcrição em vídeo e texto do relatório.
Parte 1. Elbrus, originalmente da Rússia
Primeiro, vamos entender o que é Elbrus. Aqui estão alguns dos principais recursos desta plataforma em comparação com o x86.
Arquitetura VLIW
Uma solução arquitetural completamente diferente da arquitetura superescalar, que é mais comum no mercado atualmente. O VLIW permite que você expresse intenções mais refinadas no código devido ao controle explícito de todos os dispositivos lógicos aritméticos independentes (ALUs), que a Elbrus possui, a propósito, 4. Isso não exclui a possibilidade de tempo de inatividade de algumas ALUs, mas aumenta o desempenho teórico em um ciclo de relógio o processador.
Agrupamento de equipe
Os comandos do processador pronto são combinados em pacotes configuráveis (pacotes configuráveis). Um pacote é uma grande instrução que é executada por relógio condicional. Possui muitas instruções atômicas que são executadas independentemente e imediatamente na arquitetura Elbrus.

Na imagem à direita, os retângulos cinza indicam os pacotes obtidos pelo processamento do código JS à esquerda. Se tudo estiver claro com as instruções ldd, fmuld, faddd, fsqrts, a declaração de retorno no início do primeiro pacote será surpreendente para as pessoas que não estão familiarizadas com o montador da Elbrus. Esta instrução carrega o endereço de retorno da função floatMath atual no registro ctpr3 antecipadamente, para que o processador possa fazer o download das instruções necessárias. Então, no último pacote, já fazemos a transição para o endereço pré-carregado em ctpr3.
Também vale a pena notar que Elbrus tem muito mais registros 192 + 32 + 32 versus 16 + 16 +8 para x86.
Especulativo explícito versus implícito
Elbrus suporta especulatividade explícita no nível do comando. Portanto, podemos chamar e carregar a.bar da memória antes mesmo de verificar se não é nulo, como pode ser visto no código à direita. Se a leitura lógica no final for inválida, o valor em b será simplesmente marcado como incorreto e não será possível acessá-lo.

Suporte à execução condicional
Elbrus também suporta execução condicional. Considere isso no exemplo a seguir.

Como podemos ver, o código do exemplo anterior sobre especulatividade também é reduzido devido ao uso da convolução da expressão condicional em dependência, não pelo controle, mas pelos dados. O hardware da Elbrus suporta registros de predicado, nos quais você pode armazenar apenas dois valores verdadeiros ou falsos. Sua principal característica é que você pode marcar instruções com esse predicado e, dependendo do seu valor no momento da execução, a instrução será executada ou não. Neste exemplo, a instrução cmpeq executa a comparação e coloca seu resultado lógico no predicado P1, que é usado como um marcador para carregar o valor de b no resultado. Portanto, se o predicado for igual a true, o valor 0 permanecerá no resultado.
Essa abordagem permite transformar um gráfico de controle de programa bastante complexo em execução de predicado e, consequentemente, aumenta a plenitude do pacote. Agora podemos gerar equipes mais independentes com diferentes predicados e preenchê-los com pacotes configuráveis. O Elbrus suporta 32 registros de predicado, o que permite codificar 65 fluxos de controle (mais um pela ausência de um predicado no comando).
Três pilhas de hardware comparadas a uma na Intel
Dois deles estão protegidos contra modificações pelo programador. Um - a pilha da cadeia - é responsável por armazenar endereços para retornos de funções, o outro - a pilha do registrador - contém os parâmetros pelos quais são passados. A terceira pilha de usuários - armazena variáveis e dados do usuário. Na intel, tudo é armazenado em uma pilha, o que gera vulnerabilidades, uma vez que todos os endereços de transição, os parâmetros estão em um local que não é protegido por modificações pelo usuário.
Nenhum preditor dinâmico de ramificação
Em vez disso, um esquema com preparações de conversão e transição de if é usado para que o pipeline de execução não pare.
Então, por que precisamos de JS no Elbrus?
- Substituição de importação.
- Introdução da Elbrus ao mercado de computadores domésticos, onde o Javascript já é necessário para o mesmo navegador.
- A Elbrus já é necessária no setor, por exemplo, com Node.js. Portanto, você precisa portar o Node para essa arquitetura.
- O desenvolvimento da arquitetura da Elbrus, bem como especialistas neste campo.
Se não houver intérprete, dois compiladores vêm
A implementação anterior da v8 do Google foi tomada como base. Funciona assim: uma árvore de sintaxe abstrata é criada a partir do código-fonte e, dependendo se o código foi executado ou não, usando um dos dois compiladores (Crankshaft ou FullCodegen), respectivamente, é criado o código binário otimizado ou não otimizado. Não há intérprete.

Como o FullCodegen funciona?
Os nós da árvore de sintaxe são traduzidos em código binário, após o qual tudo é "colado". Um nó tem cerca de 300 linhas de código em um assembler de macro. Isso, em primeiro lugar, oferece um amplo horizonte de otimizações e, em segundo lugar, não há transições de bytecode, como no intérprete. É simples, mas ao mesmo tempo há um problema - durante a portabilidade, você terá que reescrever muito código no assembler de macros.
No entanto, tudo isso foi feito, e o resultado foi uma versão do compilador FullCodegen 1.0 para Elbrus. Tudo foi feito no C ++ runtime v8, eles não otimizaram nada, o código do assembler foi simplesmente reescrito do x86 para a arquitetura Elbrus.
Codegen 1.1
Como resultado, o resultado não foi exatamente o esperado e foi decidido lançar o FullCodegen 1.1:
- Tornou menos tempo de execução, escreveu em um montador de macro;
- Adicionadas conversões if manuais (na figura, por exemplo, a variável js é verificada como verdadeira ou falsa);

Observe que a verificação de NaN, indefinido, nulo é feita de cada vez, sem usar if, o que seria necessário na arquitetura Intel.
- O código não foi apenas reescrito com a Intel, mas implementou especulatividade em stubs e implementou o atalho também através do MAsm (assembler de macros).
Os testes foram realizados no Google Octane. Máquinas de teste:
- Elbrus: E2S 750 MHz, 24 GB
- Intel: núcleo i7 de 3,4 GHz, 16 GB
Mais resultados:

No histograma está a proporção dos resultados, ou seja, quantas vezes Elbrus é pior que a Intel. Em dois testes, Crypto e zlib, os resultados são notavelmente piores, porque o Elbrus ainda não possui instruções de hardware para trabalhar com criptografia. Em geral, dada a diferença de frequências, ficou muito bom.
A seguir, é apresentado um teste em comparação com o interpretador js do firefox, que faz parte da distribuição padrão do Elbrus. Mais é melhor.
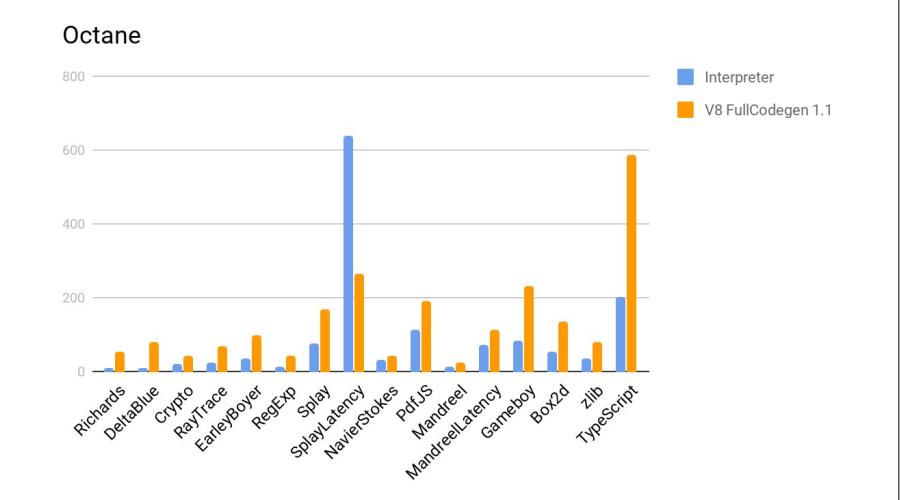
Veredicto - o compilador fez um bom trabalho novamente.
Resultados do Desenvolvimento
- O novo mecanismo JS passou nos testes test262. Isso confere o direito de ser chamado de ambiente de tempo de execução completo ECMAScript 262.
- A produtividade aumentou em média cinco vezes em comparação com o mecanismo anterior - o intérprete.
- O Node.js 6.10 também foi portado como um exemplo do uso da V8, pois não foi difícil.
- No entanto, ainda é pior que o Core i7 no FullCodegen por sete vezes.
Nada parecia pressagiar
Tudo ficaria bem, mas aqui o Google anunciou que não suporta mais o FullCodegen e o virabrequim e eles serão excluídos. Depois disso, a equipe recebeu uma ordem de desenvolvimento para o navegador Firefox e mais sobre isso posteriormente.

Parte 2. Firefox e seu macaco-aranha
É sobre o mecanismo do navegador Firefox - SpiderMonkey. Na figura, as diferenças entre esse mecanismo e o V8 mais recente.
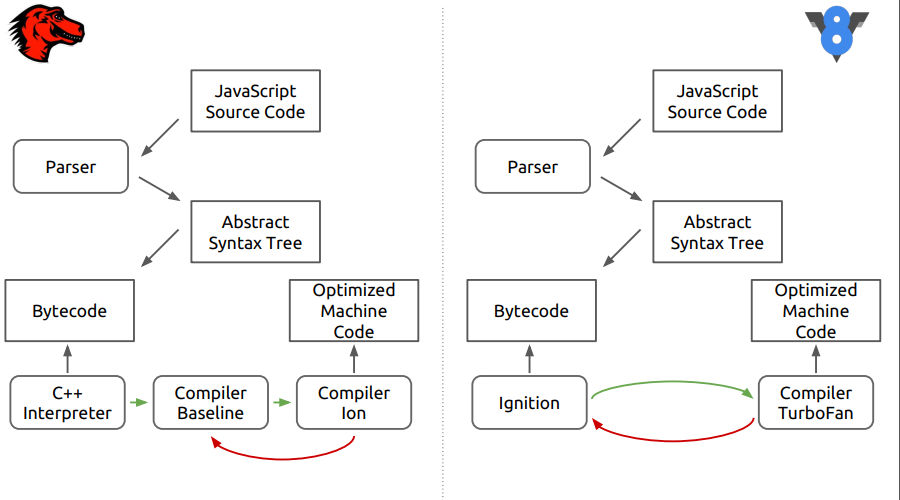
Pode-se ver que, no primeiro estágio, tudo parece que o código-fonte é analisado em uma árvore de sintaxe abstrata, depois no código de bytes, e então as diferenças começam.
No SpiderMonkey, o bytecode é interpretado pelo interpretador C ++, que basicamente se assemelha a um grande switch, dentro do qual são feitos os saltos do bytecode. Além disso, o código interpretado entra na linha de base do compilador neotimizador. Em seguida, na fase final, o compilador de otimização Ion é incluído no caso. No mecanismo V8, o bytecode é processado pelo interpretador Ingnition e, em seguida, pelo compilador TurboFan.
Linha de base, eu escolho você!
A portabilidade começou com o compilador Baseline. É essencialmente uma máquina empilhada. Ou seja, existe uma certa pilha da qual as células ele pega variáveis, lembra-se delas, realiza algumas ações com elas, após as quais ele retorna as variáveis e os resultados das ações de volta às células da pilha. Abaixo, em algumas fotos, esse mecanismo é mostrado passo a passo em relação à função simples foo:
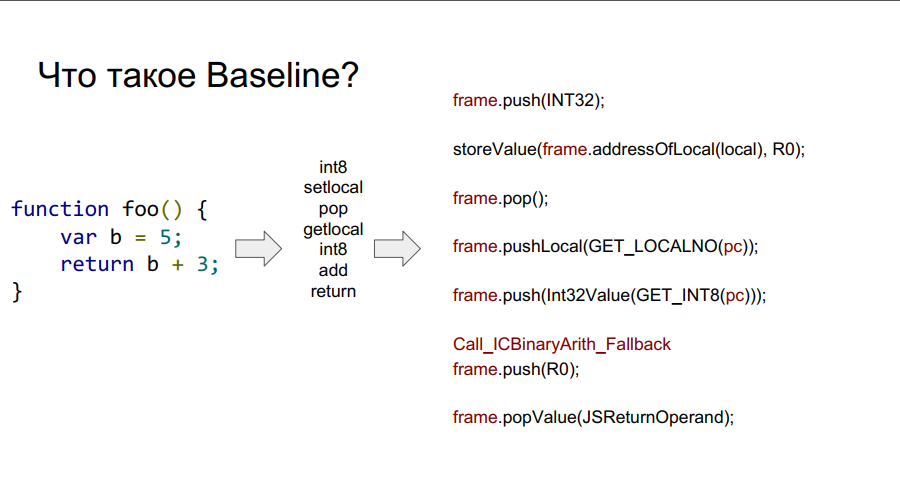


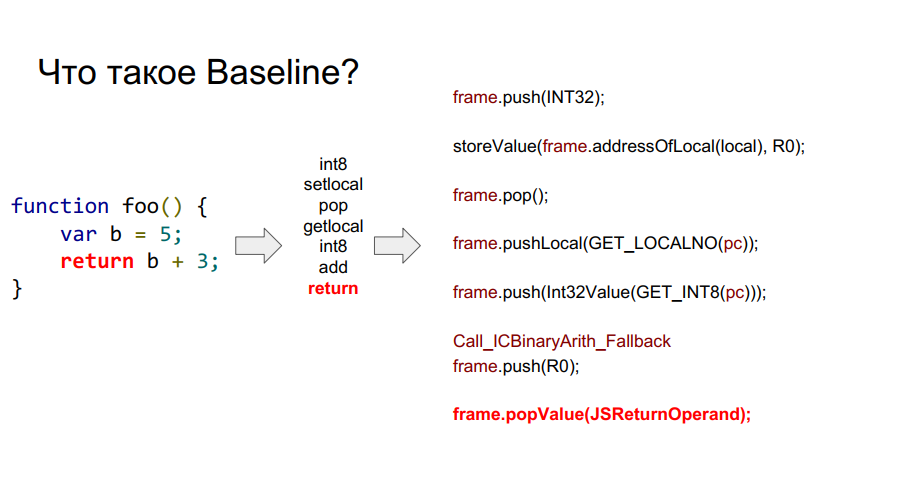
O que é um quadro?
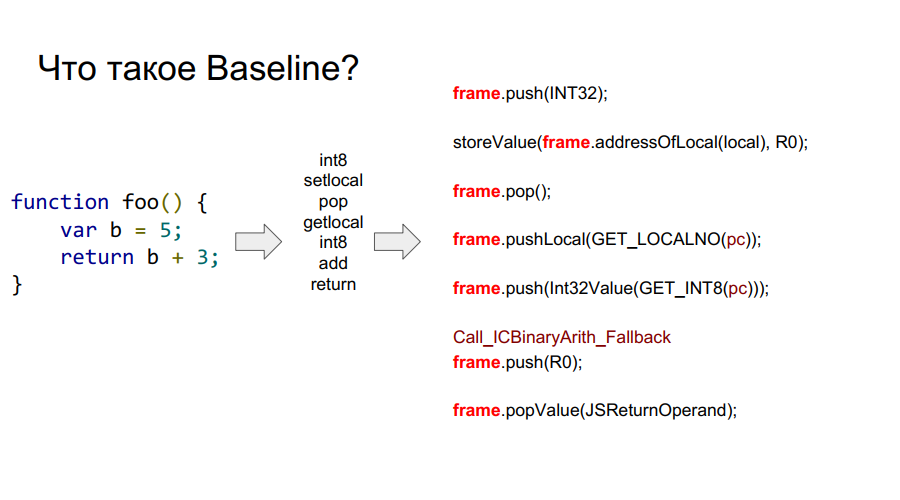
Nas imagens acima, você pode ver o quadro de palavras. Grosso modo, este é um contexto Javascript no hardware, ou seja, um conjunto de dados na pilha que descreve qualquer uma das suas funções. Na imagem abaixo, a função é foo e, à direita, é o que parece na pilha: argumentos, descrição da função, endereço de retorno, indicação do quadro anterior, porque a função foi chamada de algum lugar e para retornar corretamente ao local da chamada, essas informações devem ser armazenadas em pilha e, em seguida, variáveis locais próprias funções e operandos para cálculos.

Assim, as
vantagens da linha de base :
- Parece o FullCodegen, então sua experiência com portabilidade foi útil;
- Port o assembler, obtenha um compilador funcional;
- É conveniente depurar;
- Qualquer esboço pode ser reescrito.
Mas também há
desvantagens :
- Código linear, até você executar um código de byte, você não poderá executar o seguinte, o que não é muito bom para arquitetura com computação paralela;
- Como funciona com bytecode, você não otimiza realmente.
Restou apenas implementar o macro assembler e obter um compilador pronto. A depuração não era um bom presságio, bastava olhar a pilha na arquitetura x86 e depois a que foi obtida ao se portar para encontrar o problema.
Como resultado, em testes com o novo compilador, a produtividade triplicou:

No entanto, o Octane não suporta exceções. E sua implementação é muito importante.
Trabalho excepcional
Primeiro, vamos ver como as exceções funcionam no x86. Enquanto o programa está sendo executado, os endereços de retorno das funções são gravados na pilha. Em algum momento, uma exceção ocorre. Passamos para o manipulador de exceções de tempo de execução, que usa os quadros mencionados acima. Descobrimos onde exatamente ocorreu a exceção, após o qual precisamos rebobinar a pilha para o estado desejado e, em seguida, o endereço de retorno muda para o local onde a exceção será processada.
O problema é que, devido a outro dispositivo de pilha na arquitetura Elbrus, isso não funcionará. Será necessário calcular por chamadas do sistema quanto você precisa retroceder na pilha Chain. Em seguida, fazemos uma chamada do sistema para obter a pilha de chamadas. Em seguida, no endereço na pilha Chain, substituímos o endereço que faz o retorno.
Abaixo está uma ilustração da sequência dessas etapas.

Não é a maneira mais rápida, no entanto, a exceção é tratada. Mas ainda assim, na Intel, parece um pouco mais simples:

Com Elbrus, haverá mais saltos para o manipulador:

É por isso que você não deve basear a lógica do programa em exceções, especialmente no Elbrus.
Otimize-o!
Portanto, o tratamento de exceções é implementado. Agora, mostraremos como fizemos tudo um pouco mais rápido:
- Reescrever caches inline;
- Fez um arranjo manual (e depois automático) de atrasos;
- Eles fizeram os preparativos para as transições (com maior código): quanto mais cedo a transição for preparada, melhor;
- Coletor de Lixo Incremental Suportado
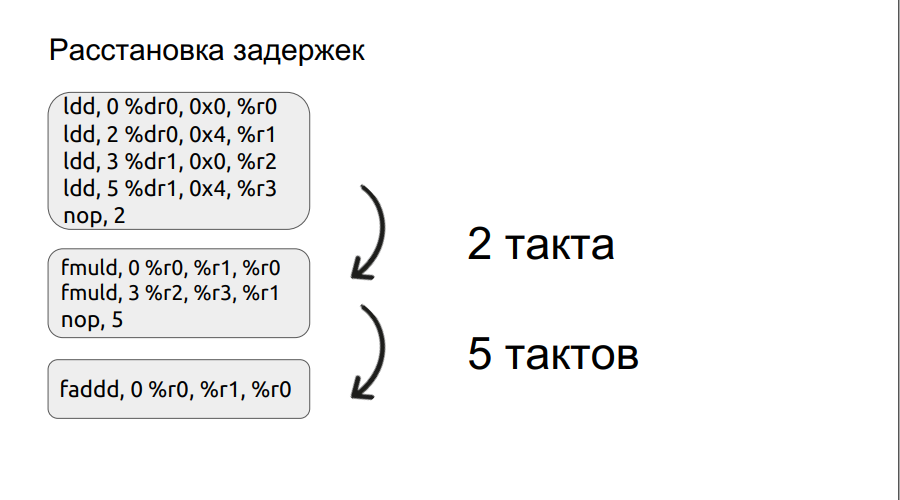
O segundo parágrafo abordará um pouco mais detalhadamente. Nós já examinamos um pequeno exemplo de trabalho com bundles e vamos adiante.

Qualquer operação, por exemplo, carregamento, não é feita em um ciclo, neste caso, é feita em três ciclos. Portanto, se queremos multiplicar dois números, entramos na operação de multiplicação, mas os próprios operandos ainda não foram carregados, o processador pode esperar apenas o carregamento. E ele aguardará um certo número de medidas, um múltiplo de quatro. Mas se você definir manualmente o atraso, o tempo de espera poderá ser reduzido, melhorando assim o desempenho. Além disso, o processo de organização dos atrasos foi automatizado.
Resultados da otimização BaseLine v1.0 vs Baseline v1.1. Claro, o motor se tornou mais rápido.

Como os programadores não podem fazer uma pistola de íons?
Na onda de sucesso da implementação da linha de base v1.1, decidiu-se portar o compilador de otimização Ion.

Como o compilador de otimização funciona? O código fonte é interpretado, a compilação é iniciada. No processo de execução do bytecode, o Ion coleta dados sobre os tipos usados no programa e a análise de "funções quentes" - aquelas executadas com mais frequência do que outras. Depois disso, é tomada a decisão de compilá-los melhor e otimizar. Em seguida, é construída uma representação de alto nível do compilador, um gráfico de operação. O gráfico é otimizado (opção 1, opção 2, opção ...), uma representação de baixo nível é criada, consistindo em instruções da máquina, registros são reservados, um código binário diretamente otimizado é gerado.
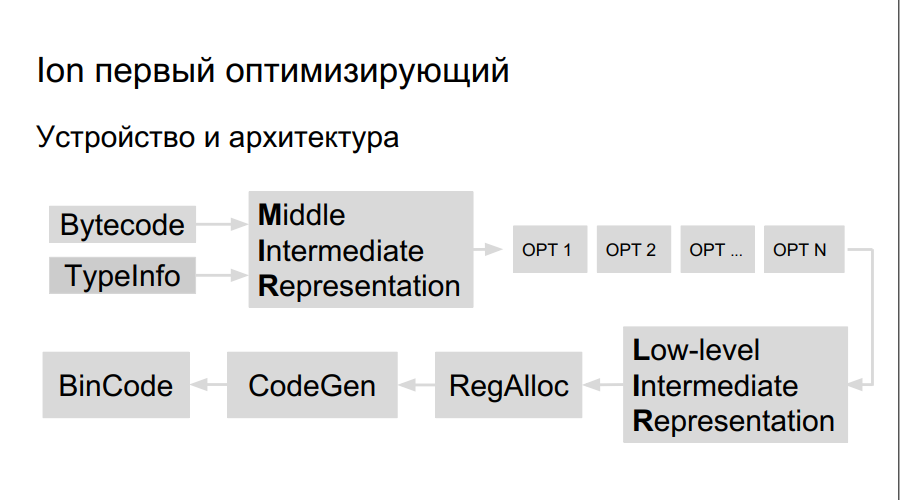
Existem mais registros no Elbrus e as equipes são grandes, portanto precisamos:
- Planejador de equipe
- Alocador de registro próprio;
- LIR Próprio (Representação Intermediária de Baixo Nível);
- Gerador de código próprio.
A equipe já tinha experiência em portar Java para Elbrus, eles decidiram usar a mesma biblioteca para geração de código para portar Ion. Ela é chamada TANGO. Tem:
- Planejador de equipe
- Alocador de registro próprio;
- Otimizações de baixo nível.
Resta introduzir uma representação de alto nível no TANGO, para fazer um seletor. O problema é que a visão de baixo nível no TANGO é como assembler, que é difícil de manter e depurar. Como deve ser o compilador por dentro? Para um melhor entendimento, a Mozilla criou seu próprio compilador HolyJit; há também uma opção para escrever seu próprio mini-idioma para traduzir entre uma representação de alto e baixo nível.
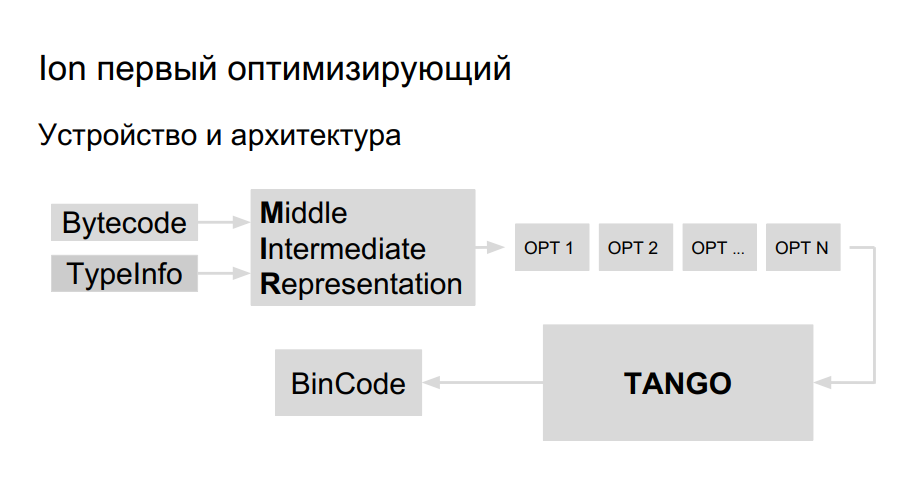
O desenvolvimento ainda está em andamento. Bem, além de como não exagerar na otimização.
Parte 3. O melhor é o inimigo do bem
Compilação como é
O processo de otimização em Ion, quando o código esquenta e depois compila e otimiza, é ganancioso, isso pode ser visto no exemplo a seguir.
function foo(a, b) {
return a + b;
}
function doSomeStuff(obj) {
for (let i = 0; i < 1100; ++i) {
print(foo(obj,obj));
}
}
doSomeStuff("HollyJS");
doSomeStuff({n:10});
JS Shell ( ), Mozilla, :

. , , - bailout (). , . foo object, , , . , :
function doSomeStuff(obj) {
for (let i=0; i < 1100; ++i) {
if (!(obj instanceof String))
print(foo_only_str(obj, obj));
}
}
, .
. , , DCE.
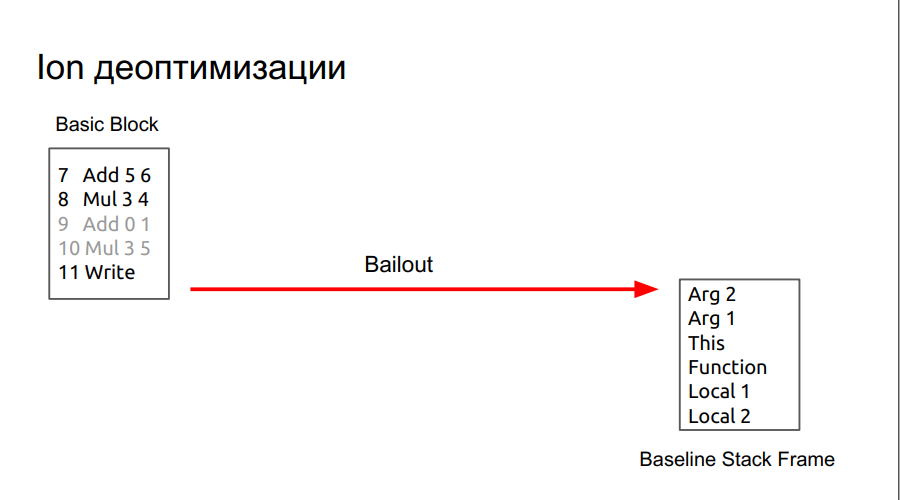
, , , .
, , , SpiderMonkey Resume Point. - , . , baseline . , runtime , . lowering, regAlloc, (snapshot), , . baseline .
:

runtime x86 : , . . , , , , , . , , Type . :
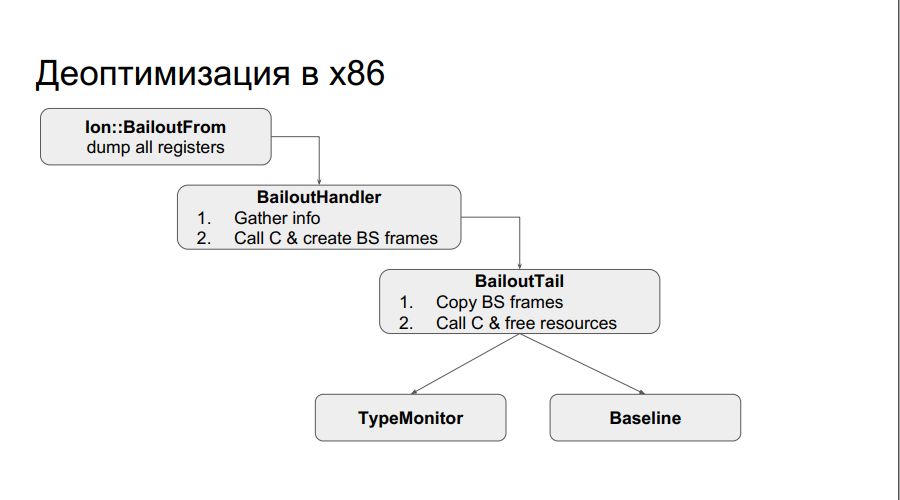
, , chain . , , .
: , chain-, N , , baseline, .
, .
:

Ion 4- baseline. :
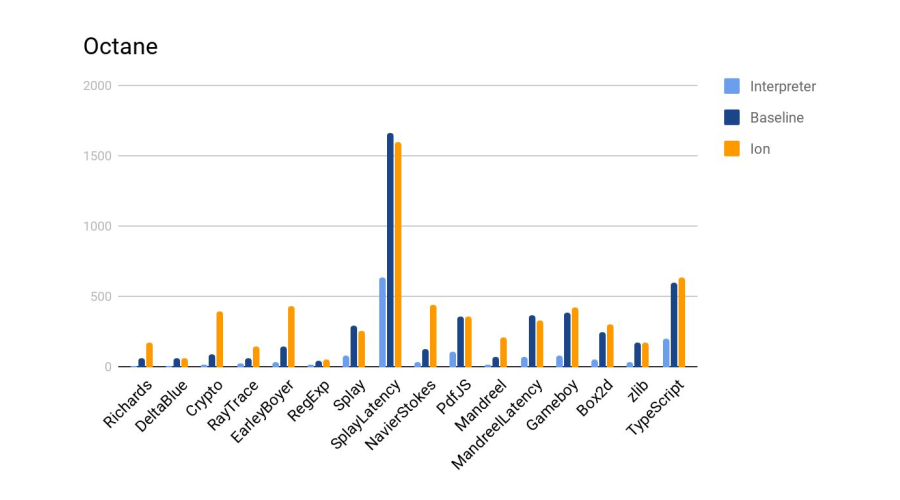
, , SpiderMonkey, V8 Node. — . .
. , , chain-.
, : 24-25 HolyJS, . — , .