A idéia surgiu na sua cabeça para reescrever seu aplicativo corporativo ousado do zero? Se a partir do zero, então é uau. Pelo menos duas vezes menos código, certo? Mas alguns anos se passarão, e também crescerá, se tornará legado ... não há muito tempo e dinheiro para que a reescrita funcione perfeitamente.
Calma, as autoridades ainda não permitirão reescrever nada. Resta refatorar. Qual é a melhor maneira de gastar seus pequenos recursos? Como refatorar onde limpar?
O título deste artigo inclui uma referência ao livro do tio Bob
"Arquitetura limpa" , e foi feito com base em um maravilhoso relatório de Victor Rentea (
twitter ,
site ) na JPoint (sob o gato que ele começará a falar na primeira pessoa, mas por enquanto leia a introdução). Lendo livros inteligentes, este artigo não substitui, mas para uma descrição tão curta é apresentada muito bem.
A idéia é que coisas populares como “Arquitetura Limpa” sejam realmente úteis. Surpresa Se você precisar resolver um problema muito específico, um código simples e elegante não exige esforço extra e engenharia em excesso. A arquitetura pura diz que você precisa proteger seu modelo de domínio contra efeitos externos e informa exatamente como isso pode ser feito. Uma abordagem evolutiva para aumentar o volume de microsserviços. Testes que tornam a refatoração menos assustadora. Você já sabe tudo isso? Ou você sabe, mas você tem medo de pensar nisso, porque é um horror o que você terá que fazer então?
Quem deseja obter uma pílula mágica anti-procrastinação que ajudará a parar de tremer e começará a refatoração - bem-vindo à gravação em vídeo do relatório ou abaixo do gato.
Meu nome é Victor, sou da Romênia. Formalmente, sou consultor, especialista técnico e arquiteto líder da IBM romena. Mas, se me pedissem para definir uma definição de minha atividade, sou um evangelista de código puro. Gosto de criar um código bonito, limpo e com suporte - como regra, falo sobre isso nos relatórios. Ainda mais, sou inspirado pelo ensino: treinando desenvolvedores nas áreas de Java EE, Spring, Dojo, Desenvolvimento Orientado a Testes, Desempenho em Java, bem como no campo do evangelismo mencionado - os princípios dos padrões de código limpo e seu desenvolvimento.
A experiência em que minha teoria se baseia é principalmente o desenvolvimento de aplicativos corporativos para o maior cliente IBM da Romênia - o setor bancário.
O plano para este artigo é o seguinte:
- Modelagem de dados: estruturas de dados não devem se tornar nossos inimigos;
- Organização da lógica: o princípio da "decomposição do código, que é demais";
- "Onion" é a mais pura arquitetura de filosofia do Script de Transação;
- Testar como uma maneira de lidar com os medos dos desenvolvedores.
Mas primeiro, vamos relembrar os principais princípios que nós, como desenvolvedores, devemos sempre lembrar.
Princípio da responsabilidade exclusiva

Em outras palavras, quantidade versus qualidade. Por via de regra, quanto mais funcionalidade a sua turma contiver, pior será a qualidade. Ao desenvolver grandes classes, o programador começa a ficar confuso, cometer erros na criação de dependências e o código grande, entre outras coisas, é mais difícil de depurar. É melhor dividir essa classe em várias classes menores, cada uma das quais será responsável por alguma subtarefa. É melhor ter alguns módulos firmemente acoplados do que um - grande e lento. A modularidade também permite a reutilização da lógica.
Ligação fraca do módulo

O grau de ligação é uma medida de quão estreitamente seus módulos interagem entre si. Ele mostra quão amplamente o efeito das alterações que você faz em qualquer ponto do sistema é capaz de se espalhar. Quanto maior a vinculação, mais difícil é fazer modificações: você altera alguma coisa em um módulo e o efeito se estende para longe e nem sempre da maneira esperada. Portanto, o indicador de ligação deve ser o mais baixo possível - isso fornecerá mais controle sobre o sistema que está passando por modificações.
Não repita

Suas próprias implementações podem ser boas hoje, mas não tão boas amanhã. Não permita copiar suas próprias práticas recomendadas e, assim, distribuí-las em uma base de código. Você pode copiar do StackOverflow, de livros - de qualquer fonte autorizada que (como você sabe com certeza) ofereça uma implementação ideal (ou próxima disso). Melhorar sua própria implementação, que ocorre mais de uma vez, mas multiplicada por toda a base de código, pode ser muito cansativo.
Simplicidade e concisão

Na minha opinião, esse é o princípio principal que deve ser observado na engenharia e no desenvolvimento de software. "O encapsulamento prematuro é a raiz do mal", disse Adam Bien. Em outras palavras, a raiz do mal está na "reengenharia". O autor da citação, Adam Bien, ao mesmo tempo estava envolvido em aceitar aplicativos herdados e, reescrevendo completamente seu código, recebeu uma base de código 2-3 vezes menor que a original. De onde vem tanto código extra? Afinal, surge por uma razão. Seus medos dão origem a nós. Parece-nos que, acumulando um grande número de padrões, gerando indiretos e abstrações, fornecemos nosso código com proteção - proteção contra as incógnitas de amanhã e os requisitos de amanhã. Afinal, de fato, hoje não precisamos de nada disso, inventamos tudo isso apenas em prol de algumas "necessidades futuras". E é possível que essas estruturas de dados interfiram posteriormente. Para ser sincero, quando alguns de meus desenvolvedores me procuram e dizem que ele encontrou algo interessante que pode ser adicionado ao código de produção, eu sempre respondo da mesma maneira: "Cara, isso não será útil para você".
Não deve haver muito código, e aquele que deve ser simples - a única maneira de trabalhar normalmente com ele. Essa é uma preocupação para seus desenvolvedores. Você deve se lembrar que eles são os índices do seu sistema. Tente reduzir o consumo de energia, reduzir os riscos com os quais eles terão que trabalhar. Isso não significa que você precise criar sua própria estrutura, além disso, eu não o aconselharia a fazer isso: sempre haverá erros em sua estrutura, todos precisarão estudá-la, etc. É melhor usar os recursos existentes, dos quais existe uma massa hoje. Estas devem ser soluções simples. Anote manipuladores de erro globais, aplique tecnologia de aspecto, geradores de código, extensões Spring ou CDI, configure escopos de Solicitação / Encadeamento, use manipulação e geração de bytecodes em tempo real, etc. Tudo isso será sua contribuição para a coisa realmente mais importante - o conforto do seu desenvolvedor.
Em particular, gostaria de demonstrar a você a aplicação das áreas Solicitação / Encadeamento. Eu observei várias vezes como isso simplificou incrivelmente os aplicativos corporativos. O ponto principal é que ele oferece a oportunidade, como usuário conectado, de salvar os dados do RequestContext. Assim, o RequestContext armazenará os dados do usuário em um formato compacto.

Como você pode ver, a implementação requer apenas algumas linhas de código. Depois de escrever o pedido na anotação necessária (não é difícil fazê-lo se você usar o Spring ou CDI), você se libertará da necessidade de passar o login do usuário para os métodos e o que quer que seja: os metadados do pedido armazenados no contexto navegam de forma transparente no aplicativo. O proxy com escopo definido permitirá que você acesse os metadados da solicitação atual a qualquer momento.
Testes de regressão

Os desenvolvedores têm medo de requisitos atualizados porque têm medo de procedimentos de refatoração (modificações no código). E a maneira mais fácil de ajudá-los é criar um conjunto de testes confiável para testes de regressão. Com isso, o desenvolvedor terá a oportunidade, a qualquer momento, de testar seu tempo de operação - para garantir que não interrompa o sistema.
O desenvolvedor não deve ter medo de quebrar nada. Você deve fazer tudo para que a refatoração seja percebida como algo bom.
A refatoração é um aspecto crítico do desenvolvimento. Lembre-se, exatamente no momento em que seus desenvolvedores têm medo de refatorar, o aplicativo pode ser considerado um legado.
Onde implementar a lógica de negócios?
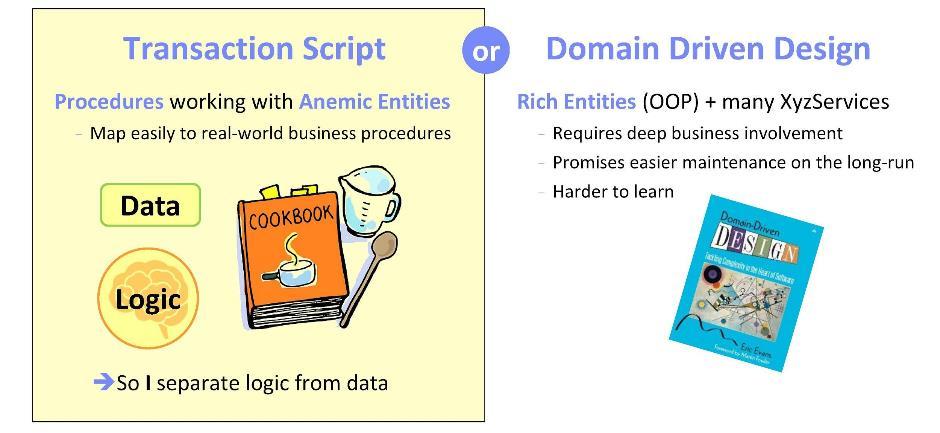
Iniciando a implementação de qualquer sistema (ou componentes do sistema), nos perguntamos: onde é melhor implementar a lógica do domínio, ou seja, os aspectos funcionais da nossa aplicação? Existem duas abordagens opostas.
O primeiro é baseado na filosofia do
Script de Transação . Aqui, a lógica é implementada em procedimentos que funcionam com
entidades anêmicas (ou seja, com estruturas de dados). Essa abordagem é boa porque, no decorrer de sua implementação, é possível confiar nas tarefas de negócios formuladas. Enquanto trabalhava em aplicativos para o setor bancário, observei repetidamente a transferência de procedimentos de negócios para software. Posso dizer que é realmente muito natural correlacionar cenários com software.
Uma abordagem alternativa é usar os princípios do
Design Orientado a Domínio . Aqui você precisará correlacionar especificações e requisitos com uma metodologia orientada a objetos. É importante considerar cuidadosamente os objetos e garantir um bom envolvimento comercial. A vantagem dos sistemas projetados dessa maneira é que, no futuro, eles serão facilmente mantidos. No entanto, na minha experiência, dominar essa metodologia é bastante difícil: você se sentirá mais ou menos corajoso não antes de seis meses estudando-a.
Para meus desenvolvimentos, sempre escolhi a primeira abordagem. Posso garantir que, no meu caso, funcionou perfeitamente.
Modelagem de dados
Entidades
Como modelamos os dados? Assim que o aplicativo tiver tamanhos mais ou menos decentes,
os dados persistentes aparecerão necessariamente. Esse é o tipo de dados que você precisa armazenar por mais tempo que o restante - são as
entidades de domínio do seu sistema. Onde armazená-los - seja no banco de dados, em um arquivo ou gerenciando diretamente a memória - não importa. O importante é
como você os armazenará - em quais estruturas de dados.

Essa opção é dada a você como desenvolvedor e depende apenas de você se essas estruturas de dados funcionarão a seu favor ou contra você ao implementar requisitos funcionais no futuro. Para que tudo seja bom, você deve implementar entidades colocando neles grãos de
lógica de domínio reutilizada . Como especificamente? Vou demonstrar vários métodos usando um exemplo.

Vamos ver o que eu forneci à entidade Cliente. Em primeiro lugar, implementei um
getFullName() sintético getFullName() getter que retornará a concatenação de firstName e lastName. Também implementei o método
activate() - para monitorar o estado da minha entidade, encapsulando-o. Nesse método, coloquei, primeiramente, uma
operação de validação e, em segundo lugar,
atribuir valores aos campos status e enabledBy, para que não haja necessidade de setters para eles. Também adicionei à entidade Customer os
isActive() e
canPlaceOrders() , que implementam a validação lambda dentro de mim. Isso é chamado de encapsulamento de predicado. Esses predicados são úteis se você usar filtros Java 8: você pode transmiti-los como argumentos aos filtros. Eu aconselho você a usar esses ajudantes.
Talvez você esteja usando algum tipo de ORM como o Hibernate. Suponha que você tenha duas entidades com comunicação bidirecional. A inicialização deve ser realizada em ambos os lados; caso contrário, como você entende, você terá problemas ao acessar esses dados no futuro. Mas os desenvolvedores geralmente esquecem de inicializar um objeto de uma das partes. Ao desenvolver essas entidades, você pode fornecer métodos especiais que garantam a inicialização bidirecional. Dê uma olhada em
addAddress() .

Como você pode ver, esta é uma entidade muito comum. Mas por dentro está a lógica do domínio. Tais entidades não devem ser escassas e superficiais, mas não devem ser sobrecarregadas com a lógica. O excesso de lógica ocorre com mais frequência: se você decidir implementar toda a lógica no domínio, para cada caso de uso, será tentador implementar algum método específico. Como regra, existem muitos casos de uso. Você não receberá uma entidade, mas uma grande pilha de todos os tipos de lógica. Tente observar a medida aqui: apenas a
lógica reutilizada é colocada no domínio e apenas
em uma pequena quantidade.
Objetos de valor
Além das entidades, você provavelmente também precisará de valores de objetos. Essa é apenas uma maneira de agrupar dados do domínio para que você possa movê-los posteriormente pelo sistema juntos.
O objeto de valor deve ser:
- Pequeno . Sem
float para variáveis monetárias! Tenha cuidado ao escolher tipos de dados. Quanto mais compacto seu objeto, mais fácil é para um novo desenvolvedor descobrir isso. Esta é a base para uma vida confortável.
- Imutável . Se o objeto for realmente imutável, o desenvolvedor pode ficar calmo, pois seu objeto não alterará seu valor e não será interrompido após a criação. Isso estabelece as bases para um trabalho calmo e confiante.

E se você adicionar uma chamada de método
validate() ao construtor, o desenvolvedor poderá se acalmar pela validade da entidade criada (ao passar, digamos, uma moeda inexistente ou uma quantia negativa de dinheiro, o construtor não funcionará).
A diferença entre uma entidade e um objeto de valor
Os objetos de valor diferem das entidades por não terem um ID fixo. As entidades sempre terão campos associados à chave estrangeira de alguma tabela (ou outro armazenamento). Objetos de valor não possuem esses campos. Surge a pergunta: os procedimentos para verificar a igualdade de dois objetos de valor e duas entidades são diferentes? Como os objetos de valor não possuem um campo de ID, para concluir que dois desses objetos são iguais, é necessário comparar os valores de todos os seus campos em pares (ou seja, examinar todo o conteúdo). Ao comparar entidades, basta fazer uma única comparação - por ID do campo. É no procedimento de comparação que reside a principal diferença entre entidades e objetos de valor.
Objetos de transferência de dados (DTOs)

Qual é a interação com a interface do usuário (UI)? Você deve passar os
dados para exibição para ele . Você realmente precisará de outra estrutura? Assim é. E tudo porque a interface do usuário não é sua amiga. Ele tem seus próprios pedidos: ele precisa que os dados sejam armazenados de acordo com a forma como eles devem ser exibidos. Isso é maravilhoso - às vezes são as interfaces de usuário e seus desenvolvedores que nos exigem. Então eles precisam obter dados para cinco linhas; então, eles vêm à mente para criar um campo booleano
isDeletable para o objeto (o objeto pode ter esse campo em princípio?) para saber se o botão Excluir está ativo ou não. Mas não há nada para se indignar. As interfaces de usuário simplesmente têm requisitos diferentes.
A questão é: nossas entidades podem ser confiadas a eles para uso? Muito provavelmente, eles os mudarão, e da maneira mais indesejável para nós. Portanto, forneceremos a eles outra coisa -
Data Transfer Objects (DTO). Eles serão especialmente adaptados aos requisitos externos e a uma lógica diferente da nossa. Alguns exemplos de estruturas de DTO são: Formulário / Solicitação (proveniente da interface do usuário), Visualização / Resposta (enviada à interface do usuário), Critérios de pesquisa / Resultados da pesquisa etc. Você pode, de certo modo, chamar isso de modelo de API.
Primeiro princípio importante: o DTO deve conter um mínimo de lógica.
Aqui está um exemplo de implementação do
CustomerDto .
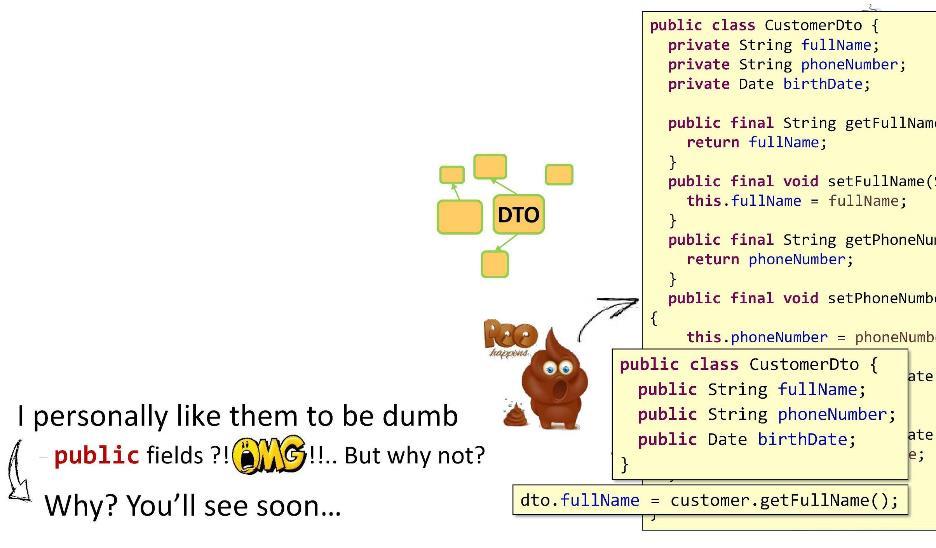
Conteúdo: campos
particulares , getters
públicos e setters para eles. Tudo parece estar super. OOP em toda a sua glória. Mas uma coisa é ruim: na forma de getters e setters, eu implementei muitos métodos. No DTO, deve haver o mínimo de lógica possível. E então, qual é a minha saída? Eu faço os campos públicos! Você dirá que isso funciona mal com as referências de método do Java 8, que haverá limitações etc. Mas, acredite ou não, eu fiz todos os meus projetos (10 a 11 peças) com esses DTOs. O irmão está vivo. Agora, como meus campos são públicos, posso definir facilmente o valor como
dto.fullName simplesmente colocando um sinal de igual. O que poderia ser mais bonito e mais simples?
Organização lógica
Mapeamento
Portanto, temos uma tarefa: precisamos transformar nossas entidades em DTO. Implementamos a transformação da seguinte maneira:
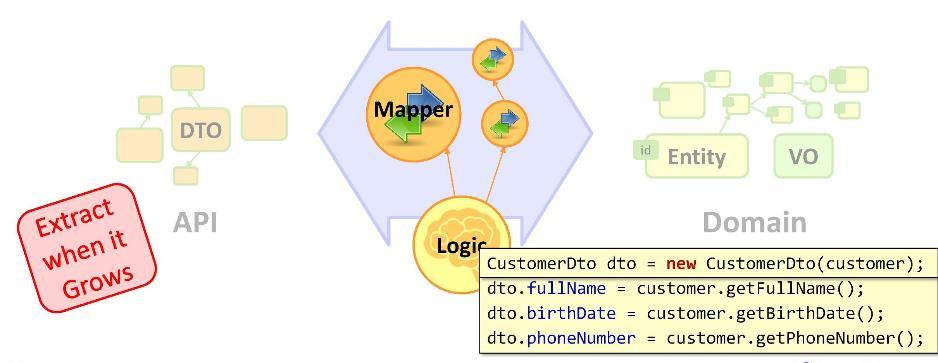
Como você pode ver, declarando um DTO, passamos para as operações de mapeamento (atribuição de valor). Preciso ser desenvolvedor sênior para escrever tarefas regulares nesses números? Para alguns, isso é tão incomum que eles começam a trocar de sapatos em movimento: por exemplo, copie dados usando algum tipo de estrutura de mapeamento usando reflexão. Mas eles sentem falta do principal - que mais cedo ou mais tarde, a interface do usuário irá interagir com o DTO, como resultado da qual a entidade e o DTO divergem em seus significados.
Pode-se, por exemplo, colocar operações de mapeamento no construtor. Mas isso não é possível para nenhum mapeamento; em particular, o designer não pode acessar o banco de dados.
Portanto, somos forçados a deixar as operações de mapeamento na lógica de negócios. E se eles têm uma aparência compacta, não há nada com que se preocupar. Se o mapeamento não demorar algumas linhas, mas mais, é melhor colocá-lo no chamado
mapeador . Um mapeador é uma classe projetada especificamente para copiar dados. Isso, em geral, é coisa antediluviana e clichê. Mas, por trás deles, você pode ocultar nossas muitas tarefas - para tornar o código mais limpo e mais fino.
Lembre-se: um
código que cresceu muito deve ser movido para uma estrutura separada . No nosso caso, as operações de mapeamento eram realmente um pouco demais, então as movemos para uma classe separada - o mapeador.
Os mapeadores permitem acesso ao banco de dados? Você pode ativá-lo por padrão - isso geralmente é feito por razões de simplicidade e pragmatismo. Mas expõe você a certos riscos.
Ilustrarei com um exemplo. Com base no DTO existente, criamos a entidade
Customer .
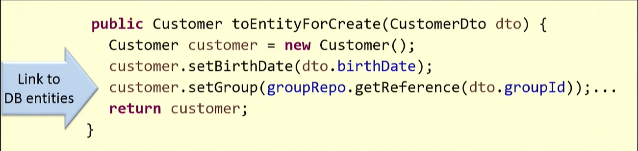
Para o mapeamento, precisamos obter um link para o grupo de clientes no banco de dados. Então, eu executo o método
getReference() , e ele me devolve alguma entidade. A solicitação provavelmente irá para o banco de dados (em alguns casos, isso não acontece, e a função stub funciona).
Mas o problema não nos espera aqui, mas no método que executa a operação inversa - transformando a entidade em DTO.

Usando um loop, examinamos todos os endereços associados ao Cliente existente e os convertemos em endereços DTO. Se você usa ORM, provavelmente, quando você chama o método
getAddresses() , o carregamento lento será realizado. Se você não usar o ORM, essa será uma solicitação aberta a todos os filhos desse pai. E aqui você corre o risco de mergulhar no "problema N + 1". Porque
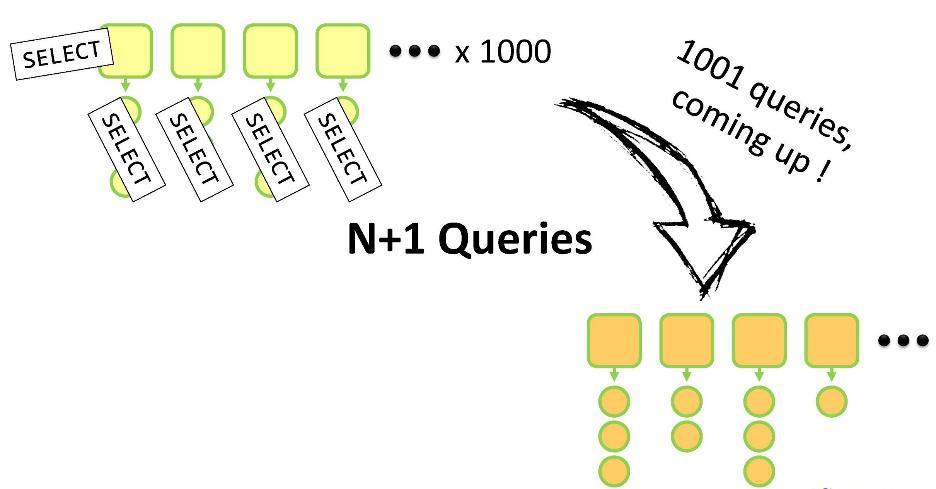
Você tem um conjunto de pais, cada um com filhos. Por tudo isso, você precisa criar seus próprios análogos dentro do DTO. Você precisará executar uma consulta
SELECT para percorrer N entidades-pai e N consultas para selecionar os filhos de cada uma delas. Pedido total de N + 1. Para 1000 entidades pai do
Customer , essa operação levará de 5 a 10 segundos, o que, é claro, leva muito tempo.
Suponha que, no entanto, nosso método
CustomerDto() seja chamado dentro do loop, convertendo a lista de objetos Customer para a lista CustomerDto.
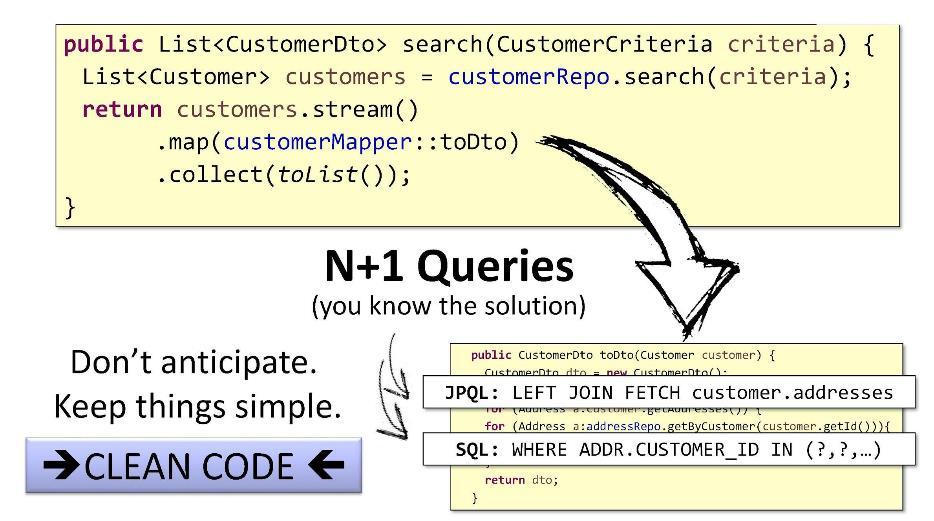
O problema com as consultas N + 1 tem soluções padrão simples: no
JPQL, você pode usar
FETCH por customer.addresses para recuperar filhos e conectá-los usando
JOIN ; no SQL, você pode usar o desvio
IN e a
WHERE .
Mas eu faria diferente. Você pode descobrir qual é o tamanho máximo da lista de filhos (isso pode ser feito, por exemplo, com base em uma pesquisa com paginação). Se a lista contiver apenas 15 entidades, precisaremos de apenas 16 consultas. Em vez de 5ms, gastaremos em tudo, digamos, 15ms - o usuário não perceberá a diferença.
Sobre otimização
Eu não o aconselharia a olhar para o desempenho do sistema no estágio inicial de desenvolvimento. Como Donald Knud disse: "A otimização prematura é a raiz do mal". Você não pode otimizar desde o início. É exatamente isso que precisa ser deixado para mais tarde. E o que é especialmente importante:
sem suposições - apenas medições e avaliação de medições!Tem certeza de que é competente que é um verdadeiro especialista? Seja humilde em se avaliar. Não pense que você entende a JVM até ler pelo menos alguns livros sobre a compilação JIT. Acontece que os melhores programadores da nossa equipe vêm até mim e dizem que
acham que encontraram uma implementação mais eficiente. Acontece que eles novamente inventaram algo que apenas complica o código. Então eu respondo várias vezes: YAGNI. Nós não precisamos disso.
Freqüentemente, para aplicativos corporativos, nenhuma otimização de algoritmos é necessária. O gargalo para eles, em regra, não é compilação e nem no que diz respeito ao processador, mas todos os tipos de operações de entrada e saída. Por exemplo, lendo um milhão de linhas de um banco de dados, gravações volumosas em um arquivo, interação com soquetes.
Com o tempo, você começa a entender quais gargalos o sistema contém e, reforçando tudo com as medidas, começará a otimizar gradualmente. Por enquanto, mantenha o código o mais limpo possível. Você descobrirá que esse código é muito mais fácil de otimizar ainda mais.
Preferir composição sobre herança
Voltar ao nosso DTO. Suponha que definamos um DTO como este:

Podemos precisar dele em muitos fluxos de trabalho. Mas esses fluxos são diferentes e, provavelmente, cada caso de uso assumirá um grau diferente de preenchimento de campo. Por exemplo, obviamente precisaremos criar um DTO mais cedo do que quando tivermos informações completas do usuário. Você pode deixar temporariamente os campos em branco. Porém, quanto mais campos você ignorar, mais você desejará criar um novo DTO mais rígido para esse caso de uso.
Como alternativa, você pode criar cópias de um DTO excessivamente grande (no número de casos de uso disponíveis) e, em seguida, remover campos extras para cada cópia. Mas para muitos programadores, em virtude de sua inteligência e alfabetização, dói muito pressionar Ctrl + V. O axioma diz que copiar e colar é ruim.
Você pode recorrer ao princípio de
herança conhecido na teoria OOP: basta definir um DTO básico e criar um herdeiro para cada caso de uso.
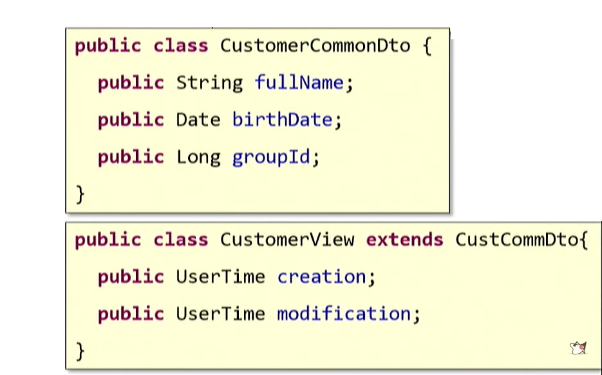
Um princípio bem conhecido é: "Prefira composição ao invés de herança". Leia o que diz:
"estende" . Parece que deveríamos ter “expandido” a classe de origem. Mas se você pensar bem, o que fizemos não é "expansão". Esta é a verdadeira "repetição" - a mesma vista lateral de copiar e colar. Portanto, não usaremos herança.
Mas o que devemos então ser? Como ir para a composição? Vamos fazer desta maneira: escreva um campo no CustomerView que aponte para o objeto do DTO subjacente.
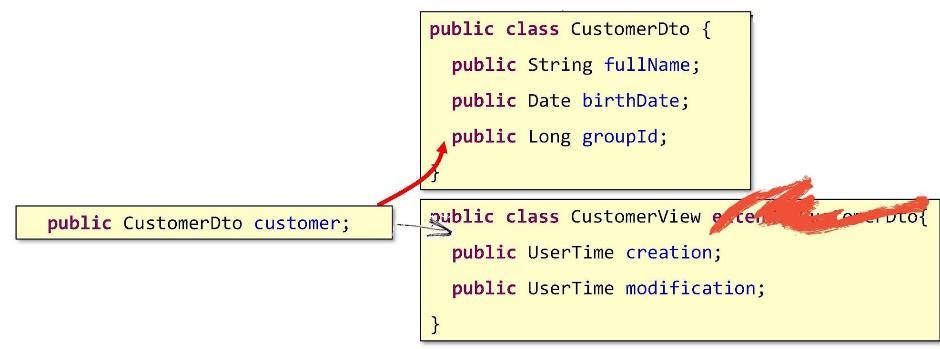
Assim, nossa estrutura básica será aninhada por dentro. É assim que a composição real sai.
Independentemente de usarmos herança ou resolvermos o problema por composição - todos esses são detalhes, sutilezas que surgiram profundamente no curso de nossa implementação. Eles são muito
frágeis . O que significa frágil? Dê uma olhada neste código:

A maioria dos desenvolvedores para quem eu mostrei isso imediatamente deixou escapar que o número "2" é repetido e, portanto, precisa ser retirado como uma constante. Eles não perceberam que o empate nos três casos tem um significado completamente diferente (ou "valor comercial") e que sua repetição nada mais é do que uma coincidência. Colocar um dois em uma constante é uma decisão legítima, mas muito frágil. Tente não permitir lógica frágil no domínio. Nunca trabalhe com estruturas de dados externas, em particular com o DTO.
Então, por que o trabalho de eliminar a herança e introduzir a composição é inútil? Precisamente porque criamos o DTO não para nós mesmos, mas para um cliente externo. E como o aplicativo cliente analisará o DTO recebido de você - você só pode adivinhar. Mas, obviamente, isso terá pouco a ver com sua implementação. Os desenvolvedores, por outro lado, podem não fazer distinção entre os DTOs básicos e não básicos que você pensou cuidadosamente; eles provavelmente usam herança, e talvez copiar e colar estupidamente isso é tudo.
Fachadas

Vamos voltar à imagem geral do aplicativo. Aconselho você a implementar a lógica do domínio através do
padrão Facade , expandindo fachadas com
serviços de domínio, conforme necessário. Um serviço de domínio é criado quando muita lógica se acumula na fachada e é mais conveniente colocá-lo em uma classe separada.
Seus serviços de domínio devem necessariamente falar o idioma do seu modelo de domínio (suas entidades e objetos de valor). Em nenhum caso eles devem funcionar com o DTO, porque o DTO, como você se lembra, são estruturas que mudam constantemente no lado do cliente, muito frágeis para um domínio.
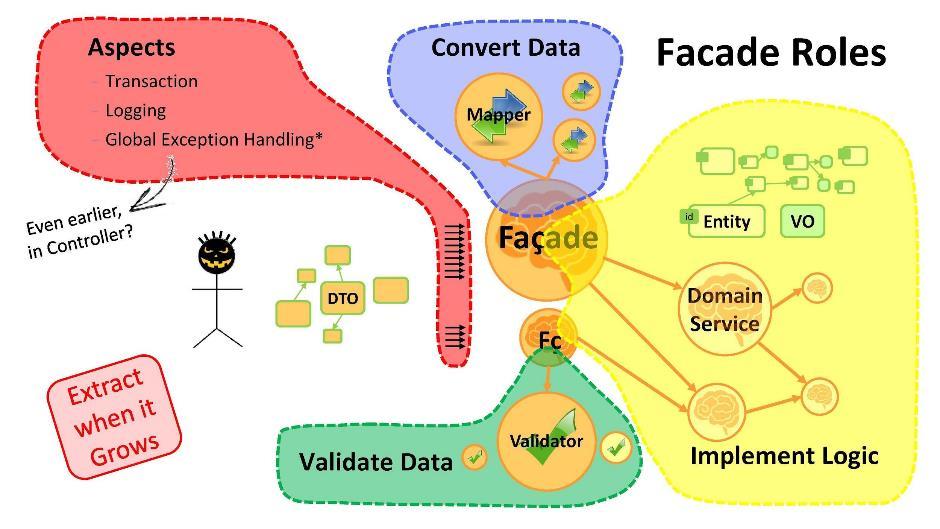
Qual é o objetivo da fachada?
- Conversão de dados. Se temos entidades de um lado e DTO do outro, é necessário realizar transformações de um para o outro. E esta é a primeira coisa que as fachadas servem. Se o procedimento de conversão aumentar em volume - use as classes do mapeador.
- A implementação da lógica. Na fachada, você começará a escrever a lógica principal do aplicativo. Assim que se tornar muito - leve as peças ao serviço de domínio.
- Validação de dados. Lembre-se de que quaisquer dados recebidos do usuário são, por definição, incorretos (contendo erros). A fachada tem a capacidade de validar dados. Esses procedimentos, quando o volume é excedido, geralmente são levados aos validadores .
- Aspectos Você pode ir além e fazer com que cada caso de uso passe por sua fachada. Depois, adicionará coisas como transações, log e manipuladores de exceções globais aos métodos de fachada.Eu observo que é muito importante ter manipuladores de exceções globais em qualquer aplicativo que capture todos os erros não capturados por outros manipuladores. Eles ajudarão muito seus programadores - eles lhes darão paz de espírito e liberdade de ação.
Decomposição de muito código
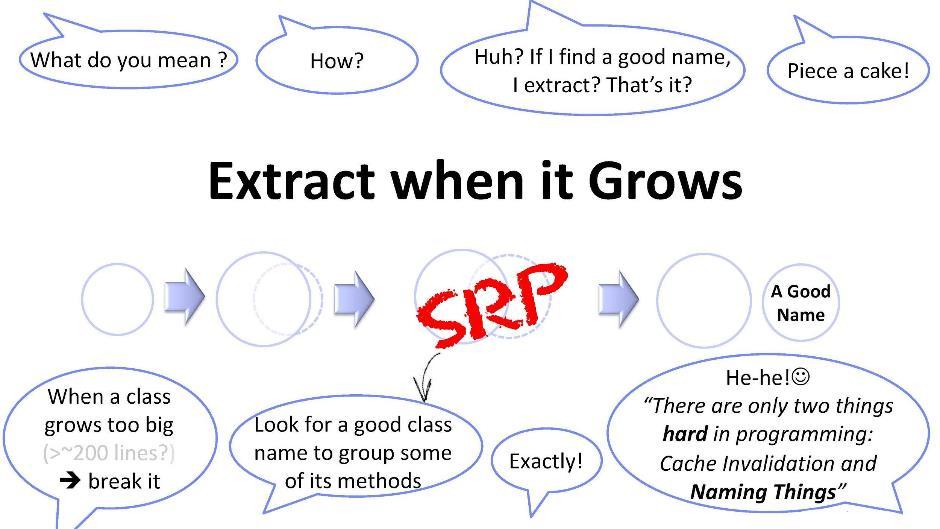
Mais algumas palavras sobre esse princípio. Se a classe alcançou algum tamanho inconveniente para mim (digamos, 200 linhas), devo tentar dividi-la em pedaços. Mas isolar uma nova classe de uma existente nem sempre é fácil. Precisamos apresentar algumas maneiras universais. Um desses métodos é procurar nomes: você está tentando encontrar um nome para um subconjunto dos métodos da sua classe. Assim que você conseguir encontrar um nome, sinta-se à vontade para criar uma nova classe. Mas isso não é tão simples. Na programação, como você sabe, existem apenas duas coisas complexas: isso está invalidando o cache e inventando nomes. Nesse caso, inventar um nome envolve a identificação de uma subtarefa oculta e, portanto, não previamente identificada por ninguém.
Um exemplo:
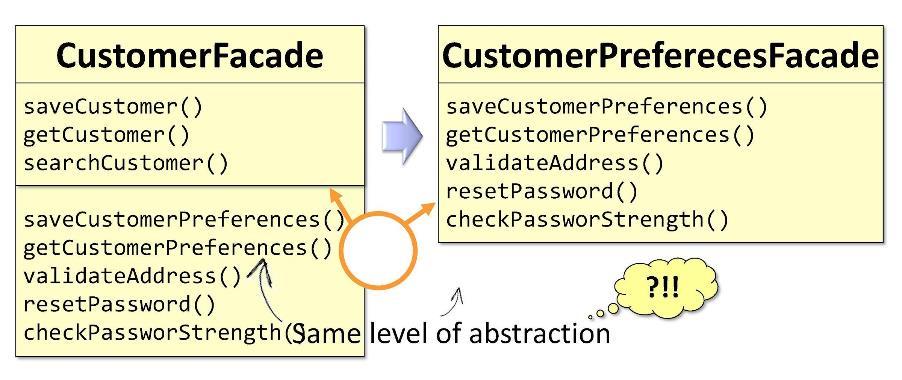
Na fachada original do
CustomerFacade alguns dos métodos estão diretamente relacionados ao cliente e outros relacionados às preferências do cliente. Com base nisso, poderei dividir a classe em duas quando atingir tamanhos críticos. Recebo duas fachadas:
CustomerFacade e
CustomerPreferencesFacade . A única coisa ruim é que essas duas fachadas pertencem ao mesmo nível de abstração. A separação por níveis de abstração implica em algo diferente.
Outro exemplo:

Suponha que exista uma classe
OrderService em nosso sistema na qual implementamos um mecanismo de notificação por email. Agora, estamos criando um
DeliveryService e gostaríamos de usar o mesmo mecanismo de notificação aqui. Copiar e colar é excluído. Vamos fazer assim: extrair a funcionalidade de notificação para a nova classe
AlertService e gravá-la como uma dependência para as
OrderService DeliveryService e
OrderService . Aqui, em contraste com o exemplo anterior, a separação ocorreu precisamente nos níveis de abstração.
DeliveryServicemais abstrato que AlertService, porque o usa como parte de seu fluxo de trabalho.A separação por níveis de abstração sempre pressupõe que a classe extraída se torne uma dependência e a extração seja realizada para reutilização .A tarefa de extração nem sempre é fácil. Também pode acarretar algumas dificuldades e exigir alguma refatoração de testes de unidade. No entanto, de acordo com minhas observações, é ainda mais difícil para os desenvolvedores procurar qualquer funcionalidade na enorme base de código monolítico do aplicativo.Programação em par
 Muitos consultores falarão sobre programação em pares, sobre o fato de que hoje é uma solução universal para qualquer problema de desenvolvimento de TI. Durante isso, os programadores desenvolvem suas habilidades técnicas e conhecimentos funcionais. Além disso, o processo em si é interessante, reúne a equipe.Falando não como consultores, mas humanamente, o mais importante é o seguinte: a programação em pares melhora o "fator de barramento". A essência do "fator de barramento" é que deve haver o maior número possível de pessoas com conhecimento sobre a estrutura do sistema . Perder essas pessoas significa perder as últimas pistas para esse conhecimento.A refatoração de programação em pares é uma arte que requer experiência e treinamento. É útil, por exemplo, a prática de refatoração agressiva, realização de hackathons, cortes, codificação de Dojos, etc. Aprogramação em pares funciona bem nos casos em que você precisa resolver problemas de alta complexidade. O processo de trabalho em conjunto nem sempre é simples. Mas garante que você evitará a "reengenharia" - pelo contrário, obterá uma implementação que atenda aos requisitos definidos com o mínimo de complexidade.
Muitos consultores falarão sobre programação em pares, sobre o fato de que hoje é uma solução universal para qualquer problema de desenvolvimento de TI. Durante isso, os programadores desenvolvem suas habilidades técnicas e conhecimentos funcionais. Além disso, o processo em si é interessante, reúne a equipe.Falando não como consultores, mas humanamente, o mais importante é o seguinte: a programação em pares melhora o "fator de barramento". A essência do "fator de barramento" é que deve haver o maior número possível de pessoas com conhecimento sobre a estrutura do sistema . Perder essas pessoas significa perder as últimas pistas para esse conhecimento.A refatoração de programação em pares é uma arte que requer experiência e treinamento. É útil, por exemplo, a prática de refatoração agressiva, realização de hackathons, cortes, codificação de Dojos, etc. Aprogramação em pares funciona bem nos casos em que você precisa resolver problemas de alta complexidade. O processo de trabalho em conjunto nem sempre é simples. Mas garante que você evitará a "reengenharia" - pelo contrário, obterá uma implementação que atenda aos requisitos definidos com o mínimo de complexidade. Organizar um formato de trabalho conveniente é uma das suas principais responsabilidades para a equipe. Você deve cuidar constantemente das condições de trabalho do desenvolvedor - fornecer a ele total conforto e liberdade de criatividade, especialmente se forem necessárias para aumentar a arquitetura do design e sua complexidade.
Organizar um formato de trabalho conveniente é uma das suas principais responsabilidades para a equipe. Você deve cuidar constantemente das condições de trabalho do desenvolvedor - fornecer a ele total conforto e liberdade de criatividade, especialmente se forem necessárias para aumentar a arquitetura do design e sua complexidade.Sou arquiteto. Por definição, eu estou sempre certo. ”
Essa estupidez é periodicamente expressa publicamente ou nos bastidores. Na prática de hoje, os arquitetos são encontrados cada vez menos. Com o advento do Agile, esse papel passou gradualmente aos desenvolvedores seniores, porque geralmente todo o trabalho, de uma maneira ou de outra, é construído em torno deles. O tamanho da implementação está aumentando gradualmente e, com isso, é necessário refatorar e novas funcionalidades estão sendo desenvolvidas.Arquitetura de cebola
Cebola é a mais pura filosofia do Script de Transação. Construindo-o, somos guiados pelo objetivo de proteger o código que consideramos crítico e, para isso, o movemos para o módulo de domínio. Em nossa aplicação, os mais importantes são os serviços de domínio: eles implementam os fluxos mais críticos. Mova-os para o módulo de domínio. Obviamente, também vale a pena mover todos os seus objetos de domínio para cá - entidades e objetos de valor. Todo o resto que compilamos hoje - DTO, mapeadores, validadores etc. - se torna, por assim dizer, a primeira linha de defesa do usuário. Porque o usuário, infelizmente, não é nosso amigo, e é necessário proteger o sistema dele.Atenção a esta dependência:
Em nossa aplicação, os mais importantes são os serviços de domínio: eles implementam os fluxos mais críticos. Mova-os para o módulo de domínio. Obviamente, também vale a pena mover todos os seus objetos de domínio para cá - entidades e objetos de valor. Todo o resto que compilamos hoje - DTO, mapeadores, validadores etc. - se torna, por assim dizer, a primeira linha de defesa do usuário. Porque o usuário, infelizmente, não é nosso amigo, e é necessário proteger o sistema dele.Atenção a esta dependência: O módulo de aplicativo dependerá do módulo de domínio - ou seja, não o contrário. Ao registrar essa conexão, garantimos que o DTO nunca entrará no território sagrado do módulo de domínio: eles simplesmente não são visíveis e inacessíveis a partir do módulo de domínio. Acontece que, em certo sentido, cercamos o território do domínio - restringimos o acesso a estranhos.No entanto, o domínio pode precisar interagir com algum serviço externo. Com meios externos hostis, porque ele está equipado com seu DTO. Quais são as nossas opções?Primeiro: pule o inimigo dentro do módulo.
O módulo de aplicativo dependerá do módulo de domínio - ou seja, não o contrário. Ao registrar essa conexão, garantimos que o DTO nunca entrará no território sagrado do módulo de domínio: eles simplesmente não são visíveis e inacessíveis a partir do módulo de domínio. Acontece que, em certo sentido, cercamos o território do domínio - restringimos o acesso a estranhos.No entanto, o domínio pode precisar interagir com algum serviço externo. Com meios externos hostis, porque ele está equipado com seu DTO. Quais são as nossas opções?Primeiro: pule o inimigo dentro do módulo.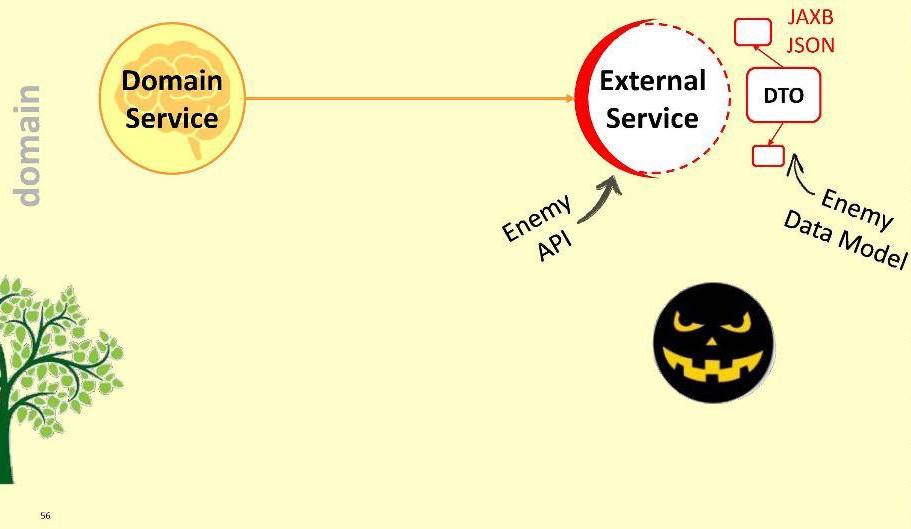 Obviamente, essa é uma opção ruim: é possível que amanhã o serviço externo não atualize para a versão 2.0 e tenhamos que redesenhar nosso domínio. Não deixe o inimigo dentro do domínio!Proponho uma abordagem diferente: criaremos um adaptador especial para interação .
Obviamente, essa é uma opção ruim: é possível que amanhã o serviço externo não atualize para a versão 2.0 e tenhamos que redesenhar nosso domínio. Não deixe o inimigo dentro do domínio!Proponho uma abordagem diferente: criaremos um adaptador especial para interação .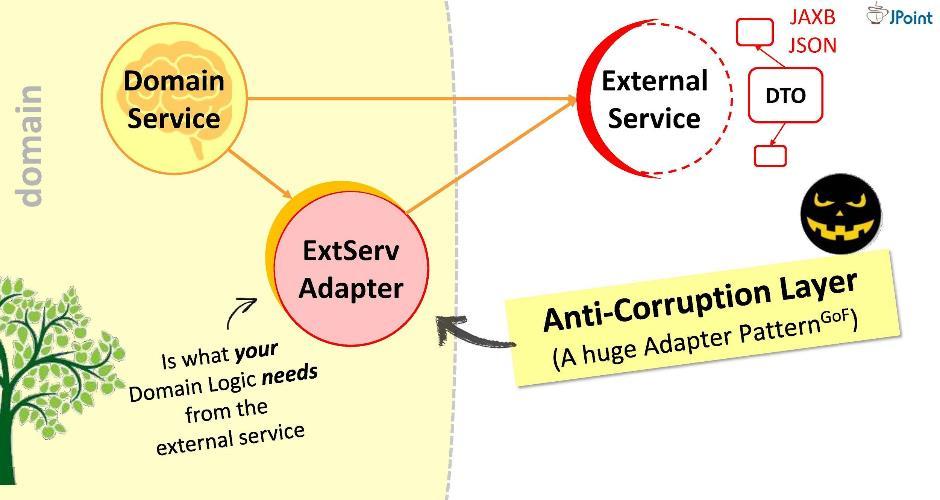 O adaptador receberá dados de um serviço externo, extrairá os dados que nosso domínio precisa e os converterá nos tipos de estruturas necessários. Nesse caso, tudo o que é necessário de nós durante o desenvolvimento é correlacionar as chamadas ao sistema externo com os requisitos do domínio. Pense nisso como um grande adaptador como este . Eu chamo essa camada de "anticorrupção".Por exemplo, podemos precisar executar consultas LDAP de um domínio. Para isso, estamos implementando o "módulo anticorrupção"
O adaptador receberá dados de um serviço externo, extrairá os dados que nosso domínio precisa e os converterá nos tipos de estruturas necessários. Nesse caso, tudo o que é necessário de nós durante o desenvolvimento é correlacionar as chamadas ao sistema externo com os requisitos do domínio. Pense nisso como um grande adaptador como este . Eu chamo essa camada de "anticorrupção".Por exemplo, podemos precisar executar consultas LDAP de um domínio. Para isso, estamos implementando o "módulo anticorrupção" LDAPUserServiceAdapter. No adaptador, podemos:
No adaptador, podemos:- Ocultar chamadas de API feias (no nosso caso, oculte o método que utiliza a matriz Object);
- Embalar exceções em nossas próprias implementações;
- Converta estruturas de dados de outras pessoas em suas próprias (em nossos objetos de domínio);
- Verifique a validade dos dados recebidos.
Esse é o objetivo do adaptador. Bom, na interface com cada sistema externo com o qual você precisa interagir, seu adaptador deve estar instalado. Portanto, o domínio não direcionará a chamada para um serviço externo, mas para o adaptador. Para fazer isso, a dependência correspondente deve ser registrada no domínio (do adaptador ou do módulo de infraestrutura em que está localizado). Mas esse vício é seguro? Se você instalá-lo assim, um DTO de serviço externo pode entrar em nosso domínio. Não devemos permitir isso. Portanto, sugiro outra maneira de modelar dependências.
Portanto, o domínio não direcionará a chamada para um serviço externo, mas para o adaptador. Para fazer isso, a dependência correspondente deve ser registrada no domínio (do adaptador ou do módulo de infraestrutura em que está localizado). Mas esse vício é seguro? Se você instalá-lo assim, um DTO de serviço externo pode entrar em nosso domínio. Não devemos permitir isso. Portanto, sugiro outra maneira de modelar dependências.Princípio de Inversão de Dependência
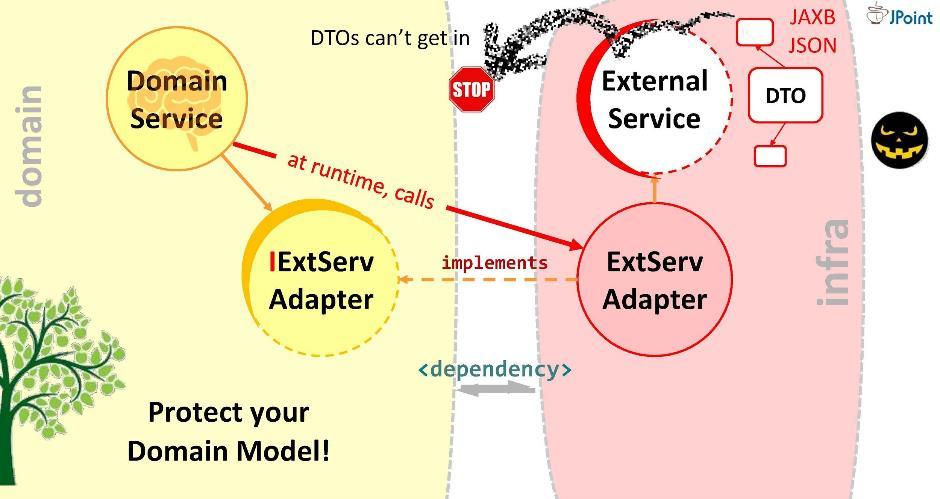 Vamos criar uma interface, escrever nela a assinatura dos métodos necessários e colocá-la dentro do nosso domínio. A tarefa do adaptador é implementar essa interface. Acontece que a interface está dentro do domínio e o adaptador está fora, no módulo de infraestrutura que importa a interface. Assim, viramos a direção da dependência na direção oposta. No tempo de execução, o sistema de domínio chamará qualquer classe por meio de interfaces.Como você pode ver, ao introduzir interfaces na arquitetura, fomos capazes de implantar dependências e, assim, proteger nosso domínio de estruturas e APIs externas que caem nele. Essa abordagem é chamada inversão de dependência .
Vamos criar uma interface, escrever nela a assinatura dos métodos necessários e colocá-la dentro do nosso domínio. A tarefa do adaptador é implementar essa interface. Acontece que a interface está dentro do domínio e o adaptador está fora, no módulo de infraestrutura que importa a interface. Assim, viramos a direção da dependência na direção oposta. No tempo de execução, o sistema de domínio chamará qualquer classe por meio de interfaces.Como você pode ver, ao introduzir interfaces na arquitetura, fomos capazes de implantar dependências e, assim, proteger nosso domínio de estruturas e APIs externas que caem nele. Essa abordagem é chamada inversão de dependência .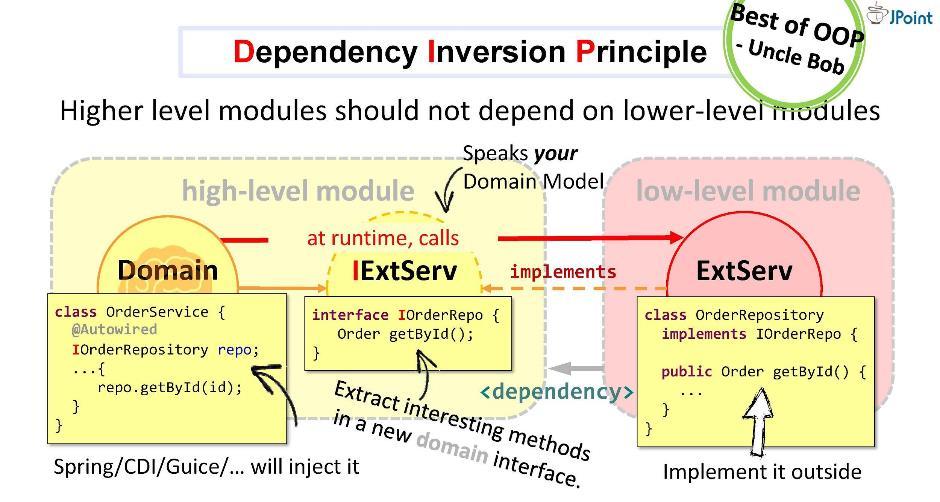 Em geral, a inversão de dependência pressupõe que você coloque os métodos de seu interesse na interface dentro de seu módulo de alto nível (no domínio) e implemente essa interface de fora - em um ou outro módulo feio de baixo nível (infraestrutura).A interface implementada dentro do módulo de domínio deve falar o idioma do domínio, ou seja, operará em suas entidades, parâmetros e tipos de retorno. Em tempo de execução, o domínio chamará qualquer classe por meio de uma chamada polimórfica para a interface. As estruturas de injeção de dependência (como Spring e CDI) nos fornecem uma instância concreta da classe em tempo de execução.Mas o principal é que, durante a compilação, o módulo de domínio não verá o conteúdo do módulo externo. É disso que precisamos. Nenhuma entidade externa deve cair no domínio.Segundo o tio Bob , o princípio da inversão de controle (ou, como ele chama, “arquitetura de plug-in”) é talvez o melhor que o paradigma OOP oferece em geral.
Em geral, a inversão de dependência pressupõe que você coloque os métodos de seu interesse na interface dentro de seu módulo de alto nível (no domínio) e implemente essa interface de fora - em um ou outro módulo feio de baixo nível (infraestrutura).A interface implementada dentro do módulo de domínio deve falar o idioma do domínio, ou seja, operará em suas entidades, parâmetros e tipos de retorno. Em tempo de execução, o domínio chamará qualquer classe por meio de uma chamada polimórfica para a interface. As estruturas de injeção de dependência (como Spring e CDI) nos fornecem uma instância concreta da classe em tempo de execução.Mas o principal é que, durante a compilação, o módulo de domínio não verá o conteúdo do módulo externo. É disso que precisamos. Nenhuma entidade externa deve cair no domínio.Segundo o tio Bob , o princípio da inversão de controle (ou, como ele chama, “arquitetura de plug-in”) é talvez o melhor que o paradigma OOP oferece em geral.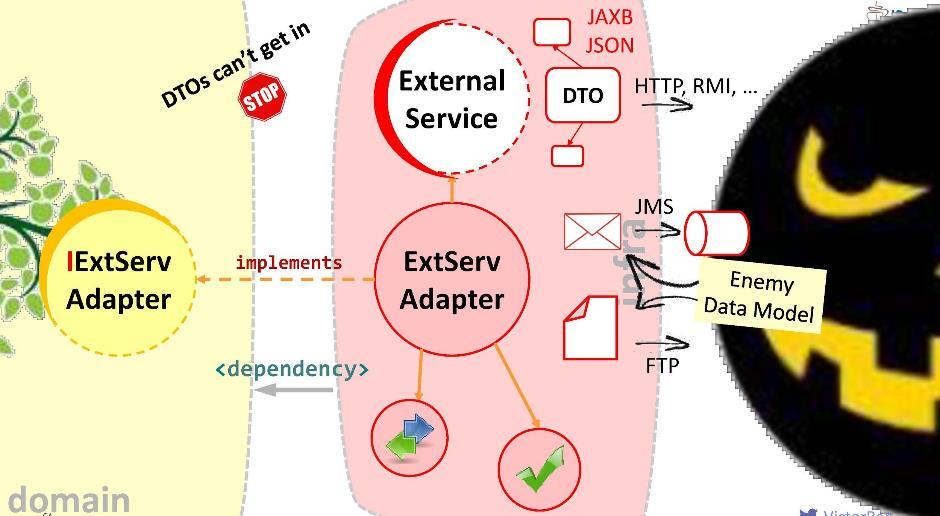 Essa estratégia pode ser usada para integração com qualquer sistema, para chamadas e mensagens síncronas e assíncronas, para envio de arquivos etc.
Essa estratégia pode ser usada para integração com qualquer sistema, para chamadas e mensagens síncronas e assíncronas, para envio de arquivos etc.Visão geral da lâmpada
 Então, decidimos que protegeremos o módulo de domínio. Dentro dele, há um serviço de domínio, entidades, objetos de valor e agora interfaces para serviços externos, além de interfaces para o repositório (para interagir com o banco de dados).A estrutura fica assim:
Então, decidimos que protegeremos o módulo de domínio. Dentro dele, há um serviço de domínio, entidades, objetos de valor e agora interfaces para serviços externos, além de interfaces para o repositório (para interagir com o banco de dados).A estrutura fica assim: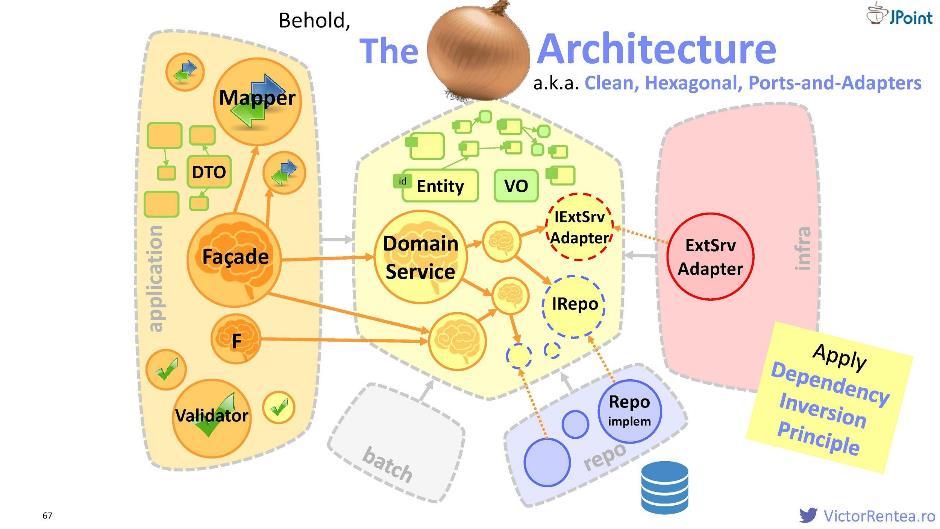 O módulo de aplicativo, o módulo de infraestrutura (por inversão de dependência), o módulo de repositório (também consideramos o banco de dados como um sistema externo), o módulo de lote e, possivelmente, alguns outros módulos são dependências declaradas para o domínio. Essa arquitetura é chamada de "cebola" ; também é chamado de "limpo", "hexagonal" e "portas e adaptadores".
O módulo de aplicativo, o módulo de infraestrutura (por inversão de dependência), o módulo de repositório (também consideramos o banco de dados como um sistema externo), o módulo de lote e, possivelmente, alguns outros módulos são dependências declaradas para o domínio. Essa arquitetura é chamada de "cebola" ; também é chamado de "limpo", "hexagonal" e "portas e adaptadores".Módulo de repositório
Vou falar brevemente sobre o módulo do repositório. A questão de retirá-lo do domínio é uma questão. A tarefa do repositório é tornar a lógica mais limpa, escondendo de nós o horror de trabalhar com dados persistentes. A opção para os veteranos é usar o JDBC para interagir com o banco de dados: você também pode usar o Spring e seu JdbcTemplate:
você também pode usar o Spring e seu JdbcTemplate: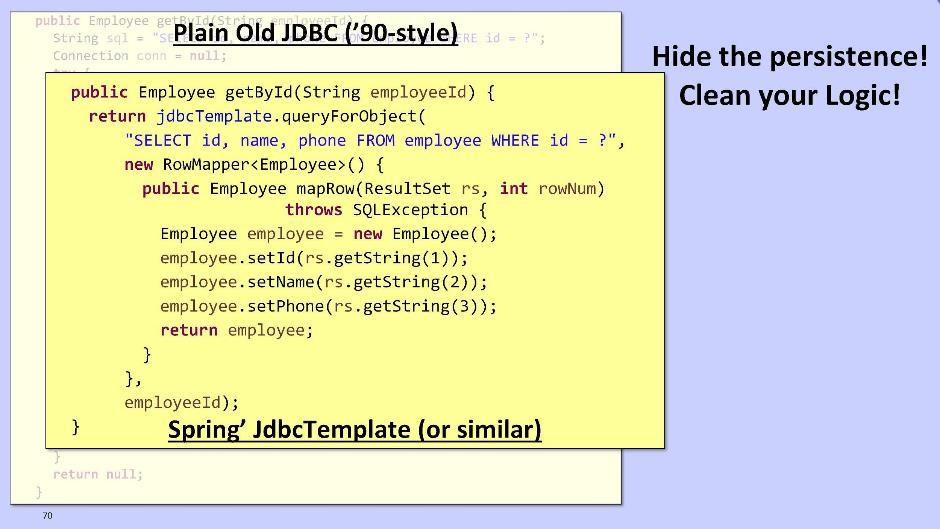 ou MyBatis DataMapper:
ou MyBatis DataMapper: mas é tão complicado e feio que desencoraja qualquer desejo de fazer mais alguma coisa. Portanto, sugiro usar JPA / Hibernate ou Spring Data JPA. Eles nos darão a oportunidade de enviar consultas criadas não no esquema do banco de dados, mas diretamente com base no modelo de nossas entidades.Implementação para JPA / Hibernate:
mas é tão complicado e feio que desencoraja qualquer desejo de fazer mais alguma coisa. Portanto, sugiro usar JPA / Hibernate ou Spring Data JPA. Eles nos darão a oportunidade de enviar consultas criadas não no esquema do banco de dados, mas diretamente com base no modelo de nossas entidades.Implementação para JPA / Hibernate: No caso de Spring Data JPA:
No caso de Spring Data JPA: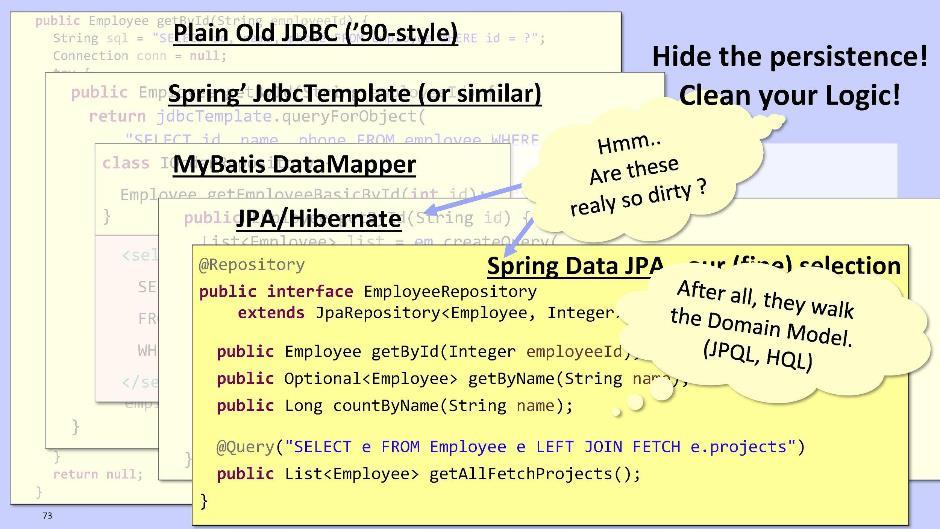 O Spring Data JPA pode gerar métodos automaticamente em tempo de execução, como, por exemplo, getById (), getByName (). Também permite executar consultas JPQL, se necessário - e não no banco de dados, mas no seu próprio modelo de entidade.O código JPA do Hibernate e Spring Data JPA realmente parece muito bom. Precisamos extraí-lo do domínio? Na minha opinião, isso não é tão e necessário. Muito provavelmente, o código será ainda mais limpo se você deixar esse fragmento dentro do domínio. Então, aja sobre a situação.
O Spring Data JPA pode gerar métodos automaticamente em tempo de execução, como, por exemplo, getById (), getByName (). Também permite executar consultas JPQL, se necessário - e não no banco de dados, mas no seu próprio modelo de entidade.O código JPA do Hibernate e Spring Data JPA realmente parece muito bom. Precisamos extraí-lo do domínio? Na minha opinião, isso não é tão e necessário. Muito provavelmente, o código será ainda mais limpo se você deixar esse fragmento dentro do domínio. Então, aja sobre a situação. No entanto, se você criar um módulo de repositório, para a organização de dependências, é melhor usar o princípio de inversão de controle da mesma maneira. Para fazer isso, coloque a interface no domínio e implemente-a no módulo de repositório. Quanto à lógica do repositório, é melhor transferi-lo para o domínio. Isso torna o teste conveniente, pois você pode usar objetos Mock no domínio. Eles permitirão que você teste a lógica rápida e repetidamente.Tradicionalmente, apenas uma entidade é criada para um repositório em um domínio. Eles o quebram em pedaços apenas quando se tornam muito volumosos. Lembre-se de que as classes devem ser compactas.
No entanto, se você criar um módulo de repositório, para a organização de dependências, é melhor usar o princípio de inversão de controle da mesma maneira. Para fazer isso, coloque a interface no domínio e implemente-a no módulo de repositório. Quanto à lógica do repositório, é melhor transferi-lo para o domínio. Isso torna o teste conveniente, pois você pode usar objetos Mock no domínio. Eles permitirão que você teste a lógica rápida e repetidamente.Tradicionalmente, apenas uma entidade é criada para um repositório em um domínio. Eles o quebram em pedaços apenas quando se tornam muito volumosos. Lembre-se de que as classes devem ser compactas.API
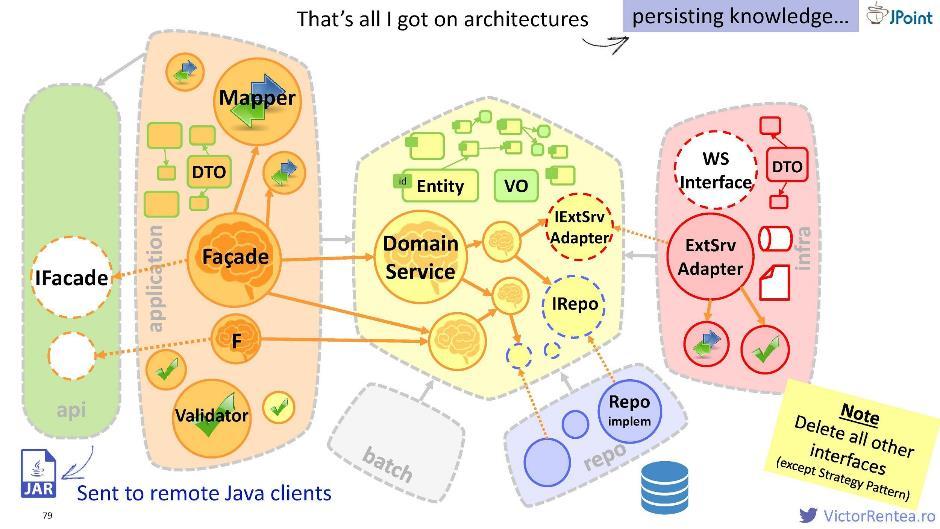 Você pode criar um módulo separado, colocar a interface extraída da fachada e os DTOs que dependem dele, empacotá-lo em um JAR e transferi-lo para seus clientes Java neste formulário. Com esse arquivo, eles poderão enviar solicitações para as fachadas.
Você pode criar um módulo separado, colocar a interface extraída da fachada e os DTOs que dependem dele, empacotá-lo em um JAR e transferi-lo para seus clientes Java neste formulário. Com esse arquivo, eles poderão enviar solicitações para as fachadas.Lâmpada pragmática
Além dos nossos “inimigos” aos quais entregamos funcionalidades, ou seja, clientes, também temos inimigos e, por outro lado, aqueles módulos dos quais dependemos. Também precisamos nos proteger desses módulos. E para isso, ofereço-lhe uma "cebola" levemente modificada - nela toda a infraestrutura é combinada em um módulo.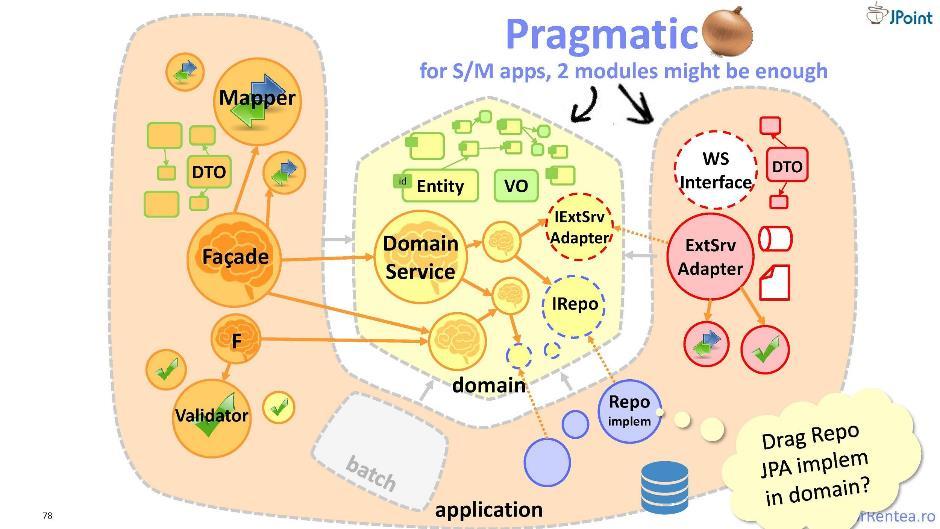 Eu chamo essa arquitetura de "lâmpada pragmática". Aqui, a separação dos componentes é realizada de acordo com o princípio “meu” e “integrável”: separadamente, que se refere ao meu domínio, e separadamente, que se refere à integração com colaboradores externos. Assim, apenas dois módulos são obtidos: o domínio e o aplicativo. Essa arquitetura é muito boa, mas apenas quando o módulo do aplicativo é pequeno. Caso contrário, é melhor você voltar para a cebola tradicional.
Eu chamo essa arquitetura de "lâmpada pragmática". Aqui, a separação dos componentes é realizada de acordo com o princípio “meu” e “integrável”: separadamente, que se refere ao meu domínio, e separadamente, que se refere à integração com colaboradores externos. Assim, apenas dois módulos são obtidos: o domínio e o aplicativo. Essa arquitetura é muito boa, mas apenas quando o módulo do aplicativo é pequeno. Caso contrário, é melhor você voltar para a cebola tradicional.Testes
Como eu disse anteriormente, se todo mundo tem medo do seu aplicativo, considere que ele reabasteceu as fileiras do Legacy.  Mas os testes são bons. Eles nos dão uma sensação de confiança que nos permite continuar refatorando. Infelizmente, porém, essa confiança pode facilmente se tornar injustificada. Eu vou explicar o porquê. O TDD (desenvolvimento por meio de testes) assume que você é o autor do código e o autor dos casos de teste: você lê as especificações, implementa a funcionalidade e imediatamente escreve um conjunto de testes para ele. Testes, digamos, terão sucesso. Mas e se você entendeu mal os requisitos das especificações? Em seguida, os testes não verificarão o que é necessário. Portanto, sua confiança é inútil. E tudo porque você escreveu código e testes sozinho.Mas tente fechar os olhos para isso. Os testes ainda são necessários e, de qualquer forma, eles nos dão confiança. Acima de tudo, é claro, adoramos testes funcionais: eles não implicam efeitos colaterais, não dependem - apenas dados de entrada e saída. Para testar um domínio, você precisa usar objetos simulados: eles permitirão que você teste as classes isoladamente.Quanto às consultas ao banco de dados, testá-las é desagradável. Esses testes são frágeis, exigem que você adicione primeiro dados de teste ao banco de dados - e somente depois disso você poderá prosseguir com o teste da funcionalidade. Mas, como você entende, esses testes também são necessários, mesmo se você usar o JPA.
Mas os testes são bons. Eles nos dão uma sensação de confiança que nos permite continuar refatorando. Infelizmente, porém, essa confiança pode facilmente se tornar injustificada. Eu vou explicar o porquê. O TDD (desenvolvimento por meio de testes) assume que você é o autor do código e o autor dos casos de teste: você lê as especificações, implementa a funcionalidade e imediatamente escreve um conjunto de testes para ele. Testes, digamos, terão sucesso. Mas e se você entendeu mal os requisitos das especificações? Em seguida, os testes não verificarão o que é necessário. Portanto, sua confiança é inútil. E tudo porque você escreveu código e testes sozinho.Mas tente fechar os olhos para isso. Os testes ainda são necessários e, de qualquer forma, eles nos dão confiança. Acima de tudo, é claro, adoramos testes funcionais: eles não implicam efeitos colaterais, não dependem - apenas dados de entrada e saída. Para testar um domínio, você precisa usar objetos simulados: eles permitirão que você teste as classes isoladamente.Quanto às consultas ao banco de dados, testá-las é desagradável. Esses testes são frágeis, exigem que você adicione primeiro dados de teste ao banco de dados - e somente depois disso você poderá prosseguir com o teste da funcionalidade. Mas, como você entende, esses testes também são necessários, mesmo se você usar o JPA.Testes unitários
 Eu diria que o poder dos testes de unidade não está na possibilidade de executá-los, mas no que o processo de escrevê-los abrange. Enquanto você está escrevendo um teste, repensa e trabalha com o código - reduz a conectividade, divide-o em classes - em uma palavra, realiza a próxima refatoração. O código em teste é um código puro; é mais simples, a conexão é reduzida nele; em geral, também é documentado (um teste de unidade bem escrito descreve perfeitamente como a classe funciona). Não é de surpreender que seja difícil escrever testes de unidade, especialmente as primeiras peças.
Eu diria que o poder dos testes de unidade não está na possibilidade de executá-los, mas no que o processo de escrevê-los abrange. Enquanto você está escrevendo um teste, repensa e trabalha com o código - reduz a conectividade, divide-o em classes - em uma palavra, realiza a próxima refatoração. O código em teste é um código puro; é mais simples, a conexão é reduzida nele; em geral, também é documentado (um teste de unidade bem escrito descreve perfeitamente como a classe funciona). Não é de surpreender que seja difícil escrever testes de unidade, especialmente as primeiras peças.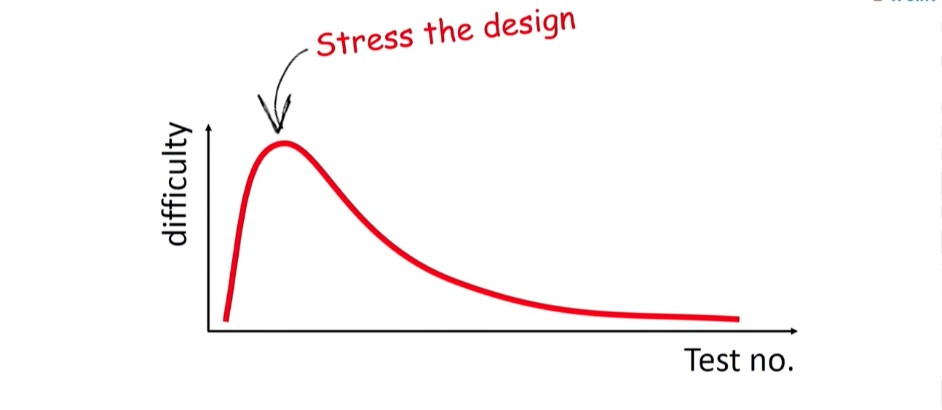 Na fase dos primeiros testes de unidade, muitas pessoas têm realmente medo das perspectivas de que realmente precisam testar alguma coisa. Por que eles recebem tão difícil?Porque esses testes são o primeiro fardo para sua classe. Este é o primeiro golpe no sistema, que talvez mostre que é frágil e frágil. Mas você precisa entender que esses poucos testes são os mais importantes para o seu desenvolvimento. Eles são, em essência, seus melhores amigos, porque dirão tudo sobre a qualidade do seu código. Se você tem medo desse estágio, não vai longe. Você deve executar os testes para o seu sistema. Depois disso, a complexidade diminuirá, os testes serão gravados mais rapidamente. Adicionando-os um por um, você criará uma base de testes de regressão confiável para o seu sistema. E isso é incrivelmente importante para o trabalho futuro de seus desenvolvedores. Será mais fácil para eles refatorar; Eles entenderão que o sistema pode ser testado por regressão a qualquer momento, e é por isso que trabalhar com a base de código é seguro. E, garanto-lhe, eles se empenharão na refatoração com muito mais disposição.
Na fase dos primeiros testes de unidade, muitas pessoas têm realmente medo das perspectivas de que realmente precisam testar alguma coisa. Por que eles recebem tão difícil?Porque esses testes são o primeiro fardo para sua classe. Este é o primeiro golpe no sistema, que talvez mostre que é frágil e frágil. Mas você precisa entender que esses poucos testes são os mais importantes para o seu desenvolvimento. Eles são, em essência, seus melhores amigos, porque dirão tudo sobre a qualidade do seu código. Se você tem medo desse estágio, não vai longe. Você deve executar os testes para o seu sistema. Depois disso, a complexidade diminuirá, os testes serão gravados mais rapidamente. Adicionando-os um por um, você criará uma base de testes de regressão confiável para o seu sistema. E isso é incrivelmente importante para o trabalho futuro de seus desenvolvedores. Será mais fácil para eles refatorar; Eles entenderão que o sistema pode ser testado por regressão a qualquer momento, e é por isso que trabalhar com a base de código é seguro. E, garanto-lhe, eles se empenharão na refatoração com muito mais disposição. Meu conselho para você: se você acha que hoje tem muita força e energia, dedique-se a escrever testes de unidade. E certifique-se de que cada um seja limpo, rápido, tenha seu próprio peso e não repita os outros.
Meu conselho para você: se você acha que hoje tem muita força e energia, dedique-se a escrever testes de unidade. E certifique-se de que cada um seja limpo, rápido, tenha seu próprio peso e não repita os outros.Dicas
Resumindo tudo o que foi dito hoje, gostaria de advertir você com as seguintes dicas:- Mantenha a simplicidade pelo maior tempo possível (e não importa quanto custe) : evite a "reengenharia" e a otimização tardia, não sobrecarregue o aplicativo;
- , , ;
- «» — ;
- , — : ;
- «», , — ;
- Não tenha medo dos testes : dê a eles a oportunidade de derrubar seu sistema, sentir todos os benefícios deles - no final, eles são seus amigos, porque podem apontar problemas honestamente.
Ao fazer essas coisas, você ajudará sua equipe e a si mesmo. E então, quando chegar o dia da entrega do produto, você estará pronto para isso.O que ler

. JPoint — , 19-20 - Joker 2018 — Java-. . .