Inicie o catálogo de inicialização dos
planos de serviço. A empresa está
desenvolvendo uma instalação especial que permitirá gravar um terabyte de dados em 500 trilhões de moléculas de DNA diariamente.
A seguir, falamos sobre a abordagem usada pelo Catálogo e outros desenvolvimentos recentes no campo do DNA.
 / foto Universidade de Michigan CC
/ foto Universidade de Michigan CCDetalhes do projeto
A abordagem clássica para gravar dados no DNA envolve converter uma sequência de bits - zeros e uns - em uma sequência de quatro bases básicas de DNA. Por exemplo, as bases nitrogenadas adenina (A), timina (T), guanina (G) e citosina (C) podem ser representadas da seguinte forma: A = 00, T = 01, G = 10, C = 11.
Usando essa abordagem, em 2016 a Microsoft
conseguiu "perpetuar" 200 MB de texto e vídeo em moléculas de DNA sintético (como já escrevemos em
uma das postagens ). No entanto, esse método não é adequado para gravação de dados em massa, sendo caro.
Em vez de usar milhões de fitas de DNA, os pesquisadores do Catálogo sugerem a geração de um grande número de moléculas de DNA diferentes, consistindo em não mais que 30 pares de bases. Então, devido a
reações enzimáticas, essas “peças” pré-preparadas formam padrões especiais que codificam as informações. Assim, em vez de representar uma única base de nitrogênio, os bits são dispostos em matrizes multidimensionais. E grupos de moléculas refletem a posição dos bits nessas matrizes.
Devin Leake, diretor de pesquisa de catálogo,
cita a seguinte analogia: “Imagine que você tem um livro. Você pode copiá-lo manualmente: letra por letra. Da mesma forma, você pode escrever dados no DNA - molécula por molécula. Essa abordagem foi usada pela Microsoft. Propomos criar um tipo de "prensa de impressão", onde as moléculas de DNA serão um
fone de ouvido . Assim, reorganizando moléculas pré-geradas, trabalhamos imediatamente com palavras inteiras, organizando-as na ordem certa. ”
Usando esse método, os pesquisadores do Catálogo registraram e recuperaram com
sucesso dados no DNA. Para fazer isso, eles usaram o poema
The Road Not Taken (em uma das traduções - “Another Road”), de Robert Frost. Agora a empresa está resolvendo o problema de dimensionar a plataforma para as necessidades de empresas de TI e organizações governamentais.
De acordo
com Hyunjun Park, um dos fundadores do Catálogo, essa abordagem tornará os armazenamentos de DNA em terabytes comercialmente viáveis no início de 2019. No entanto, o custo exato do serviço de armazenamento de dados que a inicialização oferecerá ainda é desconhecido.
Desenvolvimentos semelhantes
Como já observado, os problemas da criação de repositórios de DNA são tratados pela Microsoft. E desde 2016, os pesquisadores da empresa
avançaram em seu desenvolvimento: em fevereiro de 2018, eles criaram uma "biblioteca de
primers " para organizar o acesso aleatório ao DNA. Cada um dos primers é "anexado" a uma cadeia específica; portanto, usando a
reação em cadeia da
polimerase, você pode selecionar qualquer um deles (e obter acesso aos dados gravados).
 / photo Coronel Ford e Natasha de Vere CC
/ photo Coronel Ford e Natasha de Vere CCA empresa espera que essa abordagem, juntamente com um novo algoritmo para escrever e ler dados, menos suscetível a erros, ajude no futuro a criar armazenamentos de DNA com um volume de vários terabytes. A gigante de TI planeja fornecer armazenamento de DNA como um serviço. A empresa
decidiu implementar a ideia até 2020.
DNA e IA ganha-ganha
Não há dificuldade particular em registrar informações em um transportador de DNA: as empresas criaram métodos de automação. Mas o processo de leitura de informações ainda é complicado e demorado. Para resolver esse problema, a Lifebit
planeja usar sistemas de IA. A Lifebit está desenvolvendo a plataforma de nuvem Deploit baseada em algoritmos MO, que automatizarão o processo de leitura de informações de portadores de DNA.
Assim, o aprendizado de máquina contribuirá para a organização dos repositórios de DNA. No entanto, o oposto também é verdadeiro - moléculas de DNA são usadas para criar sistemas de inteligência artificial. Por exemplo, pesquisadores da Caltech
estão trabalhando nessa área.
O princípio de operação de sua rede neural é
baseado em reações químicas, chamadas de
deslocamento de fios (um mecanismo de replicação de DNA conhecido em alguns vírus), quando um fio chamado de entrada desloca uma das cadeias do DNA original. O Sistema Inteligente já foi
ensinado a reconhecer números manuscritos.
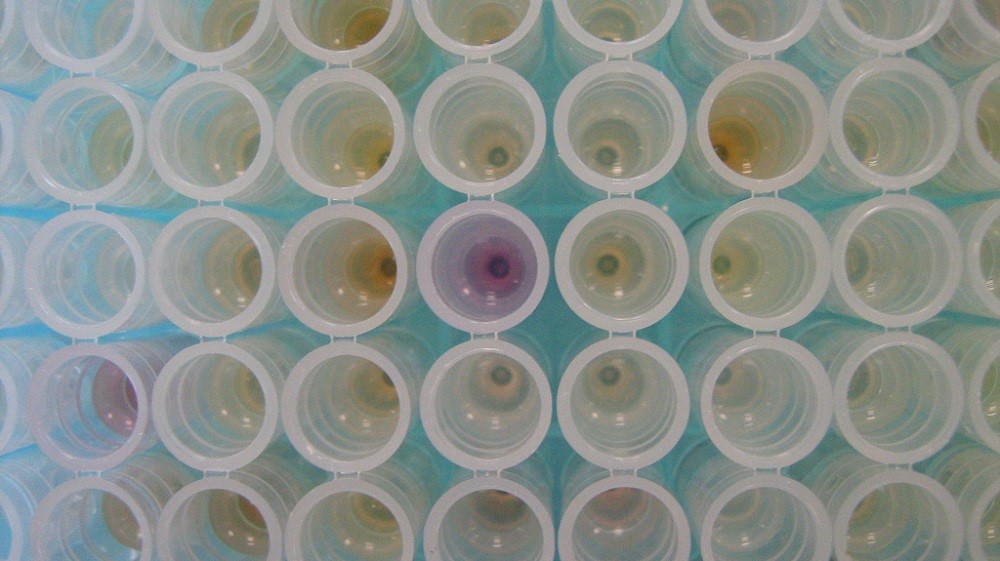
A figura é desenhada em um plano quadrado, dividido em cem células idênticas (10x10) - pixels originais. Cada uma dessas células é representada por uma molécula de DNA que "sabe" se existe um pedaço de um dígito nesse pixel. Depois que todas as moléculas são misturadas em um tubo de ensaio, a rede de DNA dá sua resposta usando sinais fluorescentes. O tubo começa a emitir um brilho cuja cor depende do dígito reconhecido. Por exemplo, verde e amarelo significam cinco e verde e vermelho significam nove.
Os pesquisadores planejam formar um tipo de memória na rede neural para que "se lembre" dos vetores de treinamento e os use para resolver outros problemas.
O catálogo
O Catalog é uma startup americana fundada em 2016, que está desenvolvendo tecnologias para armazenar dados em moléculas de DNA. Sediada em Boston, Massachusetts.
PS Alguns materiais adicionais do Primeiro blog corporativo de IaaS:
A principal direção da nossa atividade é a prestação de serviços em nuvem:
Infraestrutura virtual (IaaS) | Hospedagem PCI DSS | Nuvem FZ-152 | Alugue 1C na nuvem