1. Introdução
Todo mundo que usa o sistema de monitoramento Zabbix e monitora seu desenvolvimento sabe que, com o lançamento do Zabbix 3.4, temos um ótimo recurso - Itens Dependentes (itens de dados dependentes), sobre os quais já havia uma
postagem de blog
correspondente no Zabbix. No entanto, na forma em que foi introduzido no 3.4, usá-lo "ao máximo" era problemático devido ao fato de que as macros de LLD não eram suportadas para uso em regras de pré-processamento (
ZBXNEXT-4109 ), além de um "pai" Somente um que foi criado pela própria regra de LLD (
ZBXNEXT-4200 ) pôde ser selecionado no item de dados. Em resumo, eu tive que fazer tudo exatamente como descrito no link acima - para trabalhar com suas mãos, o que, com um grande número de métricas, causou muitos inconvenientes. No entanto, com o lançamento do Zabbix 4.0alpha9, tudo mudou.
Um pouco de história
Para mim, a funcionalidade descrita foi importante devido ao fato de nossa empresa usar vários sistemas de armazenamento da HP, como o HP MSA 2040/2050, cujas métricas são removidas por solicitações à API XML usando um
script Python .
No início, quando a tarefa era monitorar o equipamento designado e uma opção foi encontrada usando a API, descobriu-se que, no caso mais simples, para descobrir, por exemplo, o status de integridade de um componente do sistema de armazenamento, era necessário fazer duas consultas:
- Solicitar token de autenticação (chave de sessão);
- A solicitação em si, retornando informações sobre o componente.
Agora imagine que o armazenamento consiste em 24 discos (ou talvez mais), duas fontes de alimentação, um par de controladores, ventiladores, vários conjuntos de discos etc. - multiplicamos tudo isso por 2 e obtemos mais de 50 elementos de dados, o que é igual ao mesmo número de solicitações para API a cada minuto. Se você tentar seguir esse caminho, a API será "estabelecida" rapidamente e, afinal, estamos falando apenas de solicitar a "integridade" dos componentes, sem levar em conta as outras métricas possíveis e interessantes - temperatura, horário de funcionamento de discos rígidos, velocidade do ventilador etc.
A primeira decisão que tomei para descarregar a API, mesmo antes do lançamento do Zabbix versão 3.4, foi criar um cache para o token recebido, cujo valor foi gravado no arquivo e armazenado por N minutos. Isso permitiu reduzir o número de chamadas para a API exatamente duas vezes, no entanto, a situação não mudou muito - era difícil obter algo diferente do estado de saúde. Nessa época, visitei o Zabbix Moscow Meetup 2017, hospedado pelo Badoo, onde aprendi sobre a funcionalidade dos itens de dados dependentes mencionados acima.
O script foi modificado para fornecer objetos JSON detalhados que contêm informações de interesse para nós sobre vários componentes do repositório e sua saída começou a ter algo parecido com isto, em vez de uma sequência única ou valores numéricos:
{"1.1":{"health":"OK","health-num":"0","error":"0","temperature":"24","power-on-hours":"27267"},"1.2":{"health":"OK","health-num":"0","error":"0","temperature":"23","power-on-hours":"27266"},"1.3":{"health":"OK","health-num":"0","error":"0","temperature":"24","power-on-hours":"27336"}, ... }
Este é um exemplo com os dados fornecidos em todos os discos de armazenamento. Para outros componentes, a imagem é semelhante - a chave é o ID do componente e o valor é um objeto JSON que contém as métricas necessárias.
Tudo estava bem, mas as nuances descritas no início do artigo vieram à tona rapidamente - todas as métricas dependentes tiveram que ser criadas e atualizadas manualmente, o que foi bastante doloroso (cerca de 300 métricas por sistema de armazenamento, mais gatilhos e gráficos). O LLD poderia nos salvar, mas aqui, ao criar o protótipo, ele não nos permitiu especificar o que não foi criado pela própria regra como o item pai, e eliminou o hack sujo com a criação de um item fictício via LLD e a substituição do itemid no banco de dados pelo desejado. Servidor Zabbix. Os pedidos de recursos mencionados apareceram rapidamente no rastreador de erros do Zabbix, o que indicava que essa funcionalidade era importante não apenas para mim.
Porque Como todas as operações preparatórias foram concluídas, decidi tolerar e não produzir soluções temporárias, como a geração dinâmica de modelos, e só esperei o fechamento dos ZBXNEXTs indicados no início do artigo e, recentemente, foi feito.
Como está agora
Para demonstrar os novos recursos do Zabbix, tomamos:
- Armazenamento HPE MSA 2040 disponível via HTTP / HTTPS;
- Servidor Zabbix 4.0alpha9 instalado a partir do repositório oficial no CentOS 7.5.1804;
- Um script escrito em Python da terceira versão e fornecendo a capacidade de detectar componentes de armazenamento (LLD) e retornar dados no formato JSON para análise no Zabbix do servidor usando o caminho JSON.
O elemento de dados pai será uma "verificação externa" que chama o script com os argumentos necessários e armazena os dados recebidos como texto.
Preparação
O script Python é instalado de acordo com a
documentação e possui uma biblioteca de "solicitações" nas dependências do Python. Se você possui uma distribuição baseada em RHEL, pode instalá-la usando o gerenciador de pacotes yum:
[root@zabbix]
Ou usando pip:
[root@zabbix]
Você pode testar o script no shell solicitando, por exemplo, dados de LLD sobre discos:
[root@zabbix]
Configuração do host
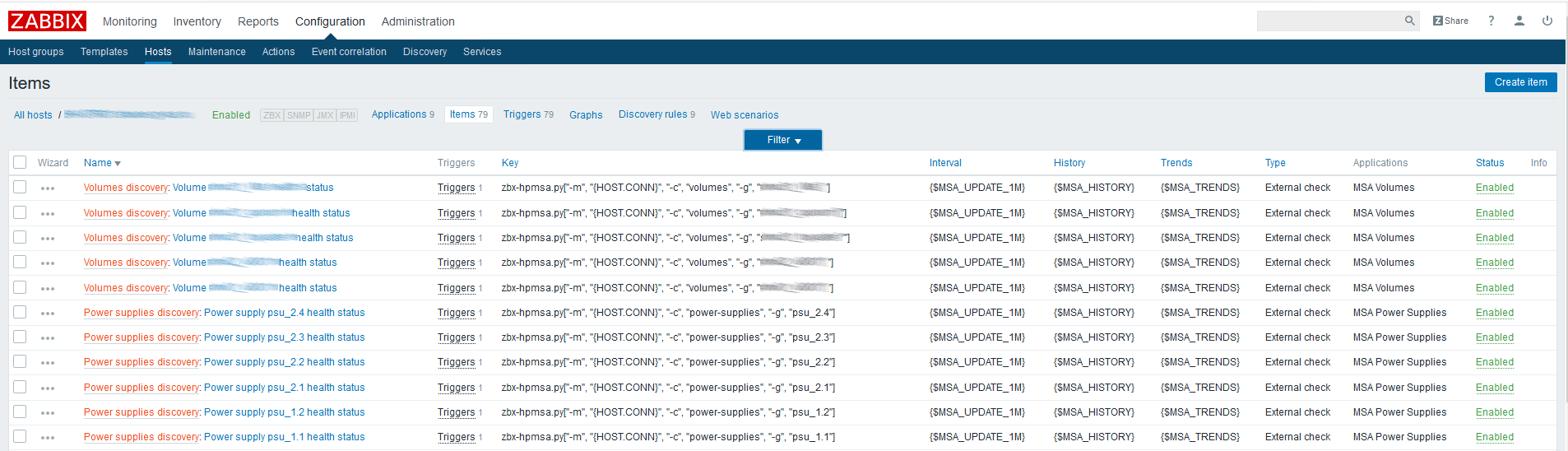
Primeiro, você precisa criar elementos de dados pai que conterão todas as métricas necessárias. Como exemplo, crie esse elemento para discos físicos:
 Nome
Nome - especifique arbitrariamente;
Tipo - verificação externa;
A chave é chamar o script com os parâmetros necessários (consulte a
documentação do
script no GitHub);
Tipo de informação - texto;
Intervalo de atualização - o exemplo usa uma macro personalizada {$ UPDATE} expandindo para o valor "1m";
O período de armazenamento do histórico é de um dia. Eu acho que armazenar o elemento de dados pai não faz mais sentido.
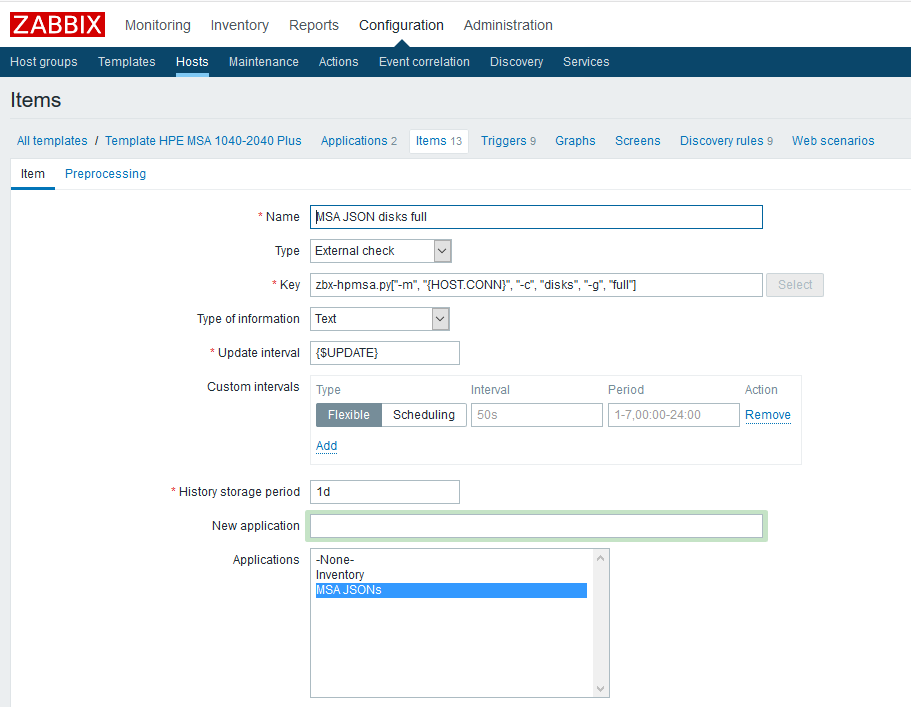
Verifique os dados mais recentes para o elemento criado:
JSON vem, então tudo é feito corretamente.
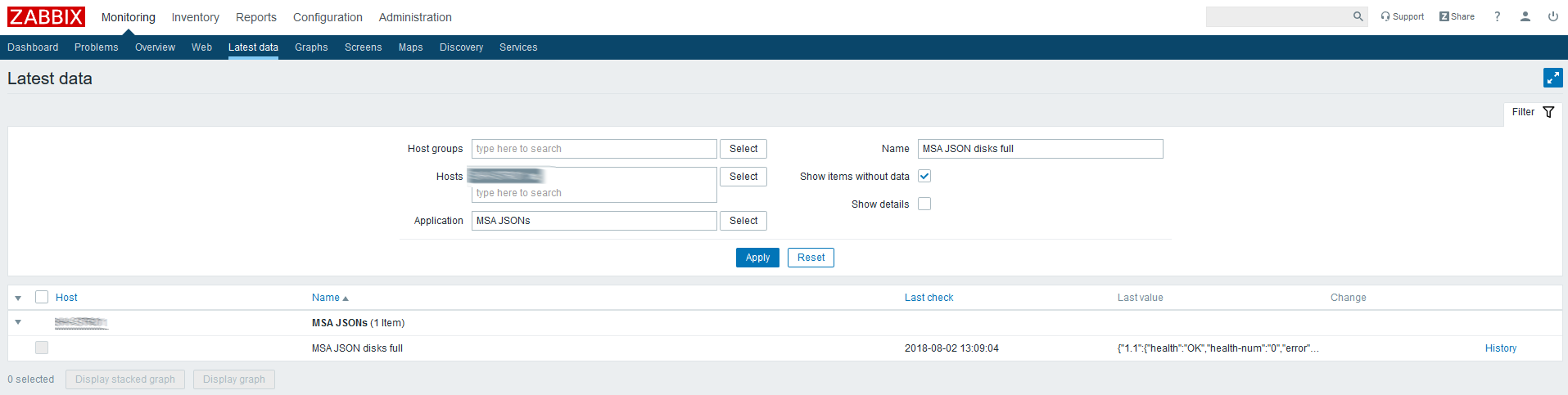
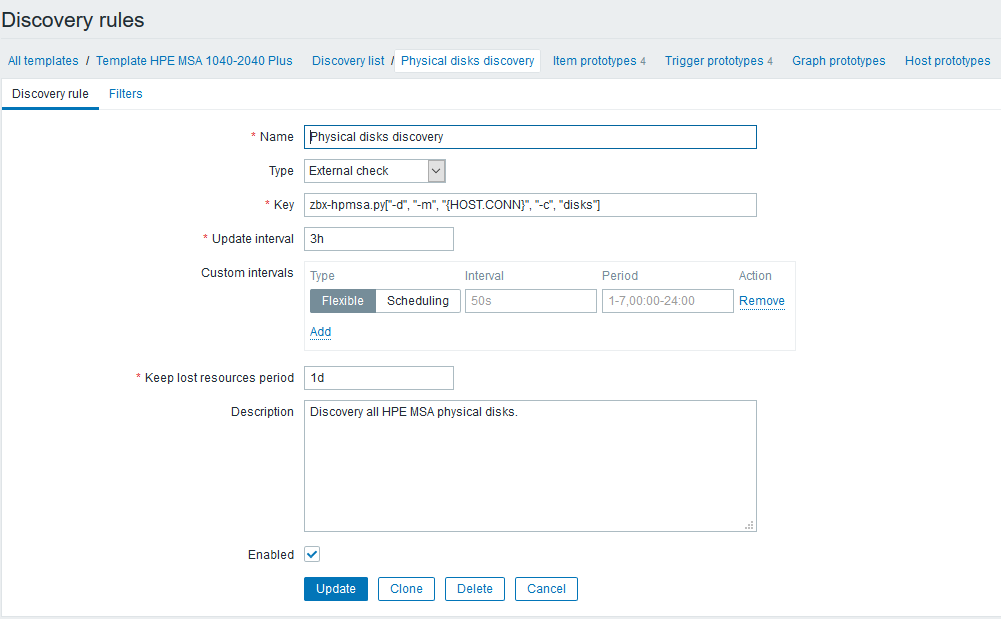
O próximo será a configuração de regras de descoberta que encontrarão todos os componentes disponíveis para monitoramento e criarão itens e gatilhos dependentes. Continuando o exemplo com discos físicos, ficará assim:
Depois de criar a regra de LLD, você precisará criar um protótipo de itens de dados. Vamos criar esse protótipo, usando dados de temperatura como exemplo:
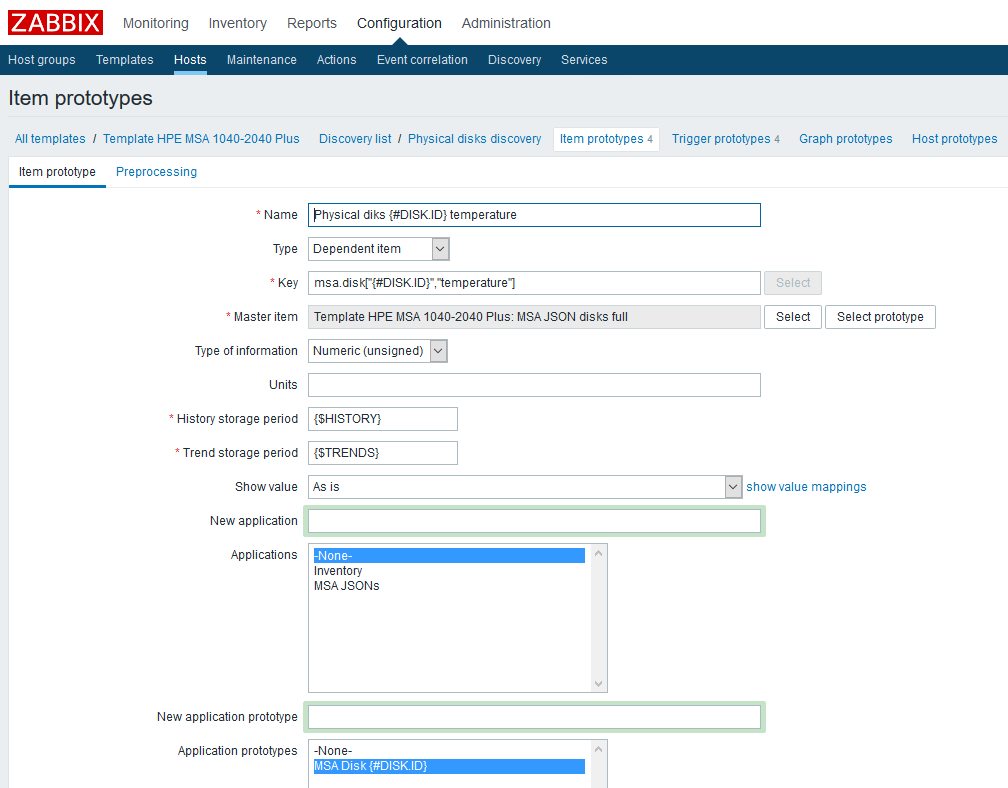 Nome
Nome - especifique arbitrariamente;
O tipo é dependente. Como elemento de dados pai, selecione o elemento correspondente criado anteriormente;
Chave - mostraremos imaginação, mas devemos levar em conta que cada chave deve ser única; portanto, incluiremos a macro LLD nela;
Tipo de informação - neste caso numérico;
Período de armazenamento do histórico - no exemplo, essa é uma macro personalizada, indicada a seu critério;
O período de armazenamento de tendências é, novamente, uma macro personalizada;
Também adicionei um protótipo do "Aplicativo" - você pode vincular convenientemente métricas relacionadas a um componente.
Na guia "Pré-processamento", crie uma etapa do tipo "Caminho JSON" com uma regra que recupera as leituras de temperatura:
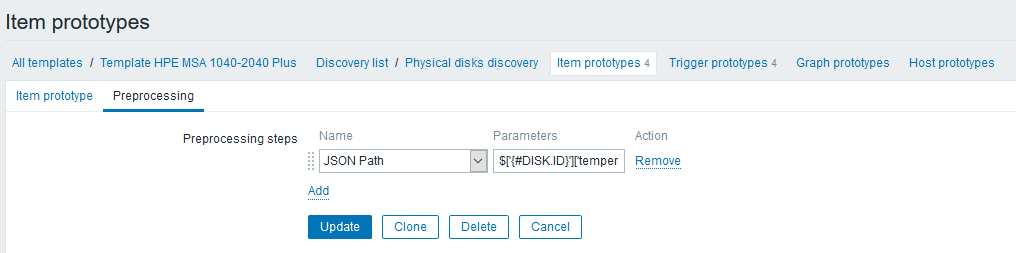
A expressão step aparece assim:
$['{#DISK.ID}']['temperature']Observe que agora você pode usar macros LLD na expressão, o que não apenas simplifica muito o nosso trabalho, mas também facilita bastante essas coisas (você já havia sido enviado à API do Zabbix antes).
Em seguida, por analogia com a temperatura, crie os protótipos restantes dos elementos de dados:

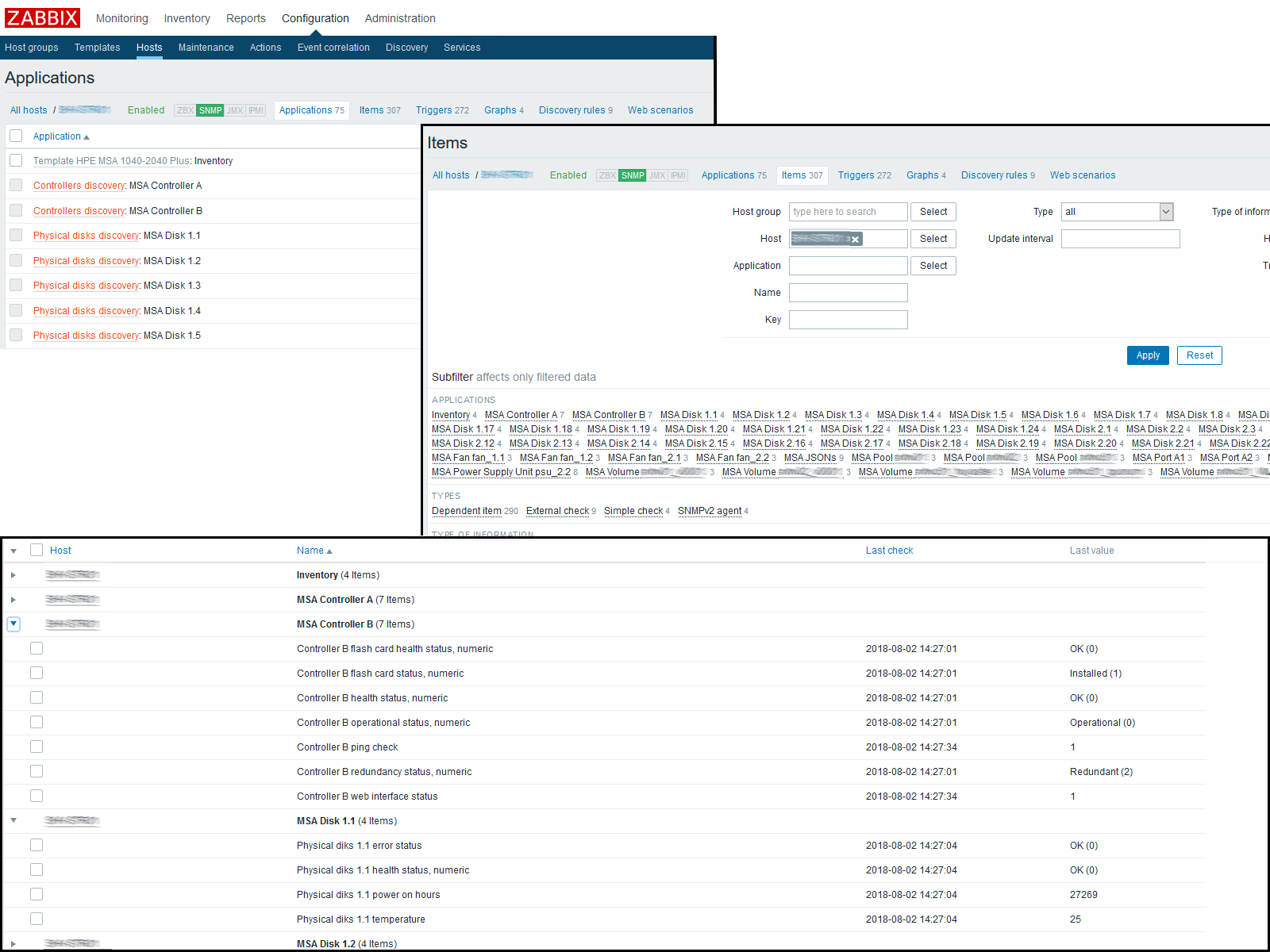
Nesta fase, você pode verificar o resultado, indo para "Dados recentes" no host. Se tudo lhe convier, continuamos a trabalhar mais. Acabei com a seguinte imagem:
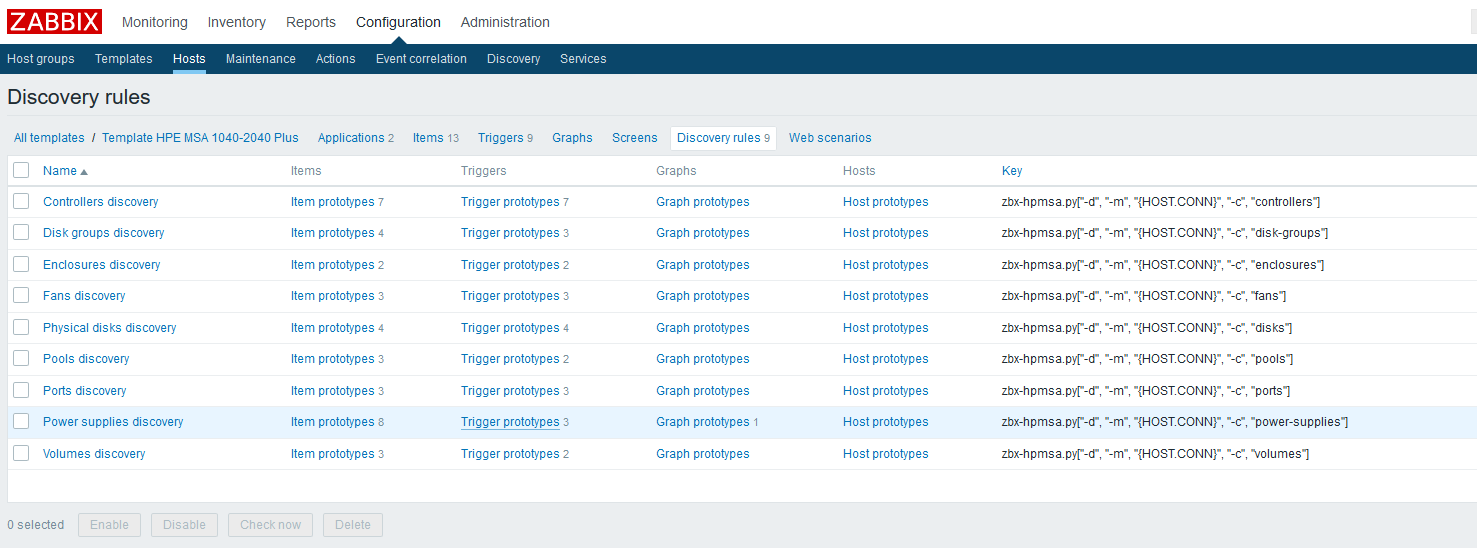
Estamos aguardando a atualização do cache de configuração ou pressionando-o manualmente para atualizar:
[root@zabbix]
Depois disso, você pode usar outro "truque" interessante da versão 4.0 - o botão "Verificar agora" para executar as regras de LLD criadas:
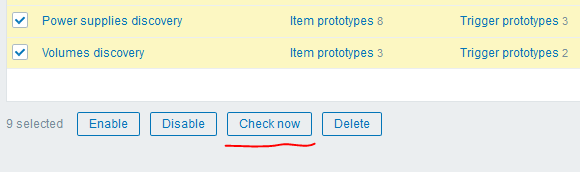
Eu obtive o seguinte resultado:
Conclusão
Como resultado, com apenas nove solicitações para a API XML, conseguimos obter mais de trezentas métricas de um nó da rede, gastando um tempo mínimo nele e obtendo a máxima flexibilidade. O LLD nos permitirá detectar automaticamente novos componentes ou atualizar os antigos.
Obrigado pela leitura, os links para os materiais utilizados e também para o modelo atual do HPE MSA P2000G3 / 2040/2050 podem ser encontrados abaixo.
PS Aliás, na versão 4.0, também é introduzido um novo tipo de verificação - um agente HTTP, que, juntamente com o pré-processamento e o caminho XML, pode potencialmente nos salvar do uso de scripts externos - você só precisa resolver o problema de obter um token de autenticação, que ainda precisa ser atualizado periodicamente. Uma das opções que vejo é o uso de uma macro global com esse token, que pode ser atualizado via API do Zabbix por coroa, incl. as pessoas interessadas podem desenvolver essa idéia. =)
ScriptModelo de compartilhamento do ZabbixItens de dados dependentesCaminho JsonZabbix 4.0alpha9