Olá, Habr. Meu nome é Vitaliy Kotov, trabalho no departamento de testes do Badoo. Escrevo muitos testes automáticos de interface do usuário, mas trabalho ainda mais com aqueles que fazem isso há pouco tempo e ainda não conseguiram pisar em todos os ancinhos.
Então, depois de adicionar minha própria experiência e observações de outros caras, decidi preparar para você uma coleção de "como escrever testes não vale a pena". Apoiei cada exemplo com uma descrição detalhada, exemplos de código e capturas de tela.
O artigo será interessante para autores iniciantes de testes de interface do usuário, mas os veteranos deste tópico provavelmente aprenderão algo novo, ou apenas sorrirão, lembrando-se "da juventude". :)
Vamos lá!

Conteúdo
Localizadores sem atributos
Vamos começar com um exemplo simples. Como estamos falando de testes de interface do usuário, os localizadores desempenham um papel importante neles. Um localizador é uma linha composta de acordo com uma certa regra e descreve um ou mais elementos XML (em particular HTML).
Existem vários tipos de localizadores. Por exemplo,
localizadores css são usados para folhas de estilos em cascata.
Os localizadores XPath são usados para trabalhar com documentos XML. E assim por diante
Uma lista completa dos tipos de localizadores usados pelo
Selenium pode ser encontrada em
seleniumhq.imtqy.com .
Nos testes de interface do usuário, os localizadores são usados para descrever os elementos com os quais o driver deve interagir.
Em quase qualquer inspetor de navegador, é possível selecionar o elemento de interesse para nós e copiar seu XPath. Parece algo como isto:
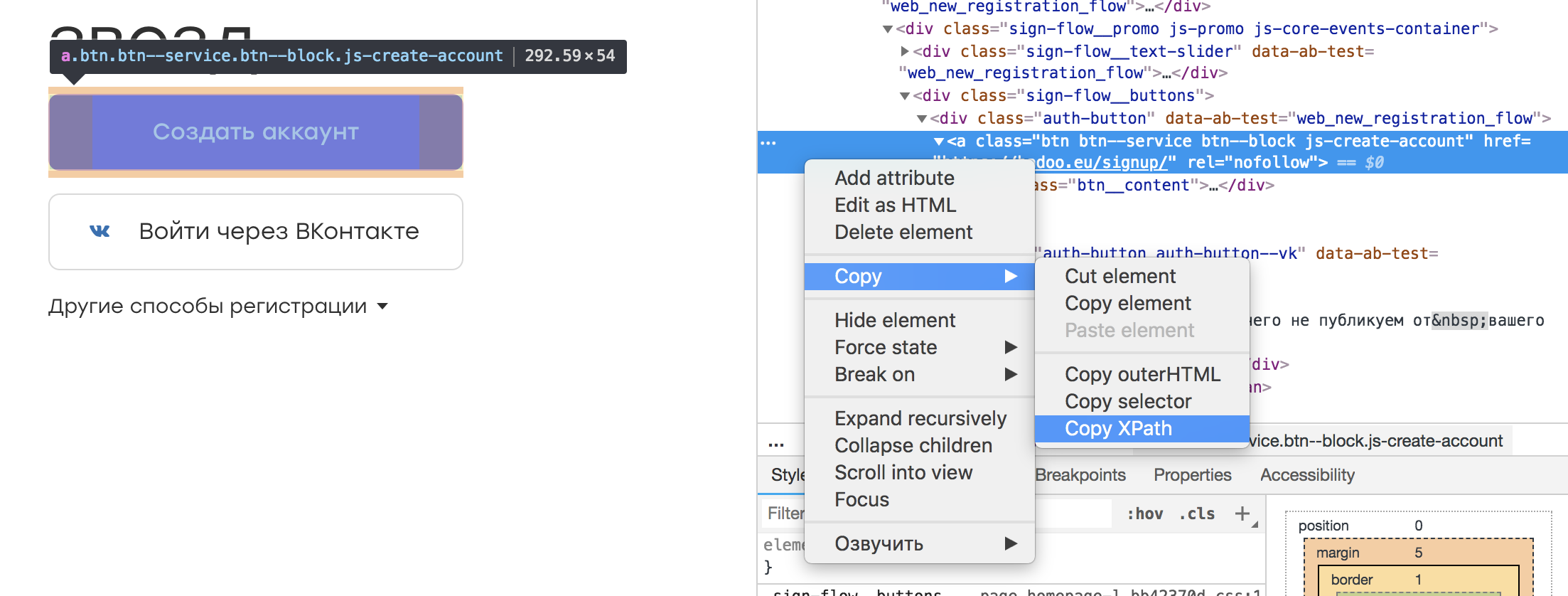
Acontece que esse localizador:
/html/body/div[3]/div[1]/div[2]/div/div/div[2]/div[1]/a
Parece que não há nada de errado com esse localizador. Afinal, podemos salvá-lo em alguma constante ou campo da classe, que por seu nome transmitirá a essência do elemento:
@FindBy(xpath = "/html/body/div[3]/div[1]/div[2]/div/div/div[2]/div[1]/a") public WebElement createAccountButton;
E envolva o texto de erro correspondente, caso o elemento não seja encontrado:
public void waitForCreateAccountButton() { By by = By.xpath(this.createAccountButton); WebDriverWait wait = new WebDriverWait(driver, timeoutInSeconds); wait .withMessage(“Cannot find Create Account button.”) .until( ExpectedConditions.presenceOfElementLocated(by) ); }
Essa abordagem tem uma vantagem: não há necessidade de aprender XPath.
No entanto, existem várias desvantagens. Em primeiro lugar, ao alterar o layout, não há garantia de que o elemento em um localizador permaneça o mesmo. É possível que outro ocupe o seu lugar, o que levará a circunstâncias imprevistas. Em segundo lugar, a tarefa dos autotestes é procurar bugs e não monitorar as alterações no layout. Portanto, a adição de algum invólucro ou de outros elementos mais altos na árvore não deve afetar nossos testes. Caso contrário, levaremos muito tempo para atualizar os localizadores.
Conclusão: você deve criar localizadores que descrevam corretamente o elemento e sejam resistentes a alterações de layouts fora da parte testada de nossa aplicação. Por exemplo, você pode ligar a um ou mais atributos de um elemento:
//a[@rel=”createAccount”]
Um localizador desse tipo é mais fácil de perceber no código e será interrompido apenas se "rel" desaparecer.
Outra vantagem desse localizador é a capacidade de procurar no repositório de modelos com o atributo especificado. Mas o que procurar se o localizador se parecer no exemplo original? :)
Se inicialmente no aplicativo os elementos não tiverem nenhum atributo ou forem definidos automaticamente (por exemplo, devido à
ofuscação de classes), vale a pena discutir com os desenvolvedores. Eles não devem estar menos interessados em automatizar os testes de produtos e certamente o encontrarão e oferecerão uma solução.
Verifique se há itens ausentes
Cada usuário do Badoo tem seu próprio perfil. Ele contém informações sobre o usuário: (nome, idade, fotos) e informações sobre com quem o usuário deseja conversar. Além disso, é possível indicar seus interesses.
Suponha que já tivemos um bug (embora, é claro, não seja assim :)). O usuário em seu perfil escolheu interesses. Não encontrando um interesse adequado na lista, ele decidiu clicar em "Mais" para atualizar a lista.
Comportamento esperado: interesses antigos devem desaparecer, novos devem aparecer. Mas, em vez disso, um "Erro inesperado" apareceu:
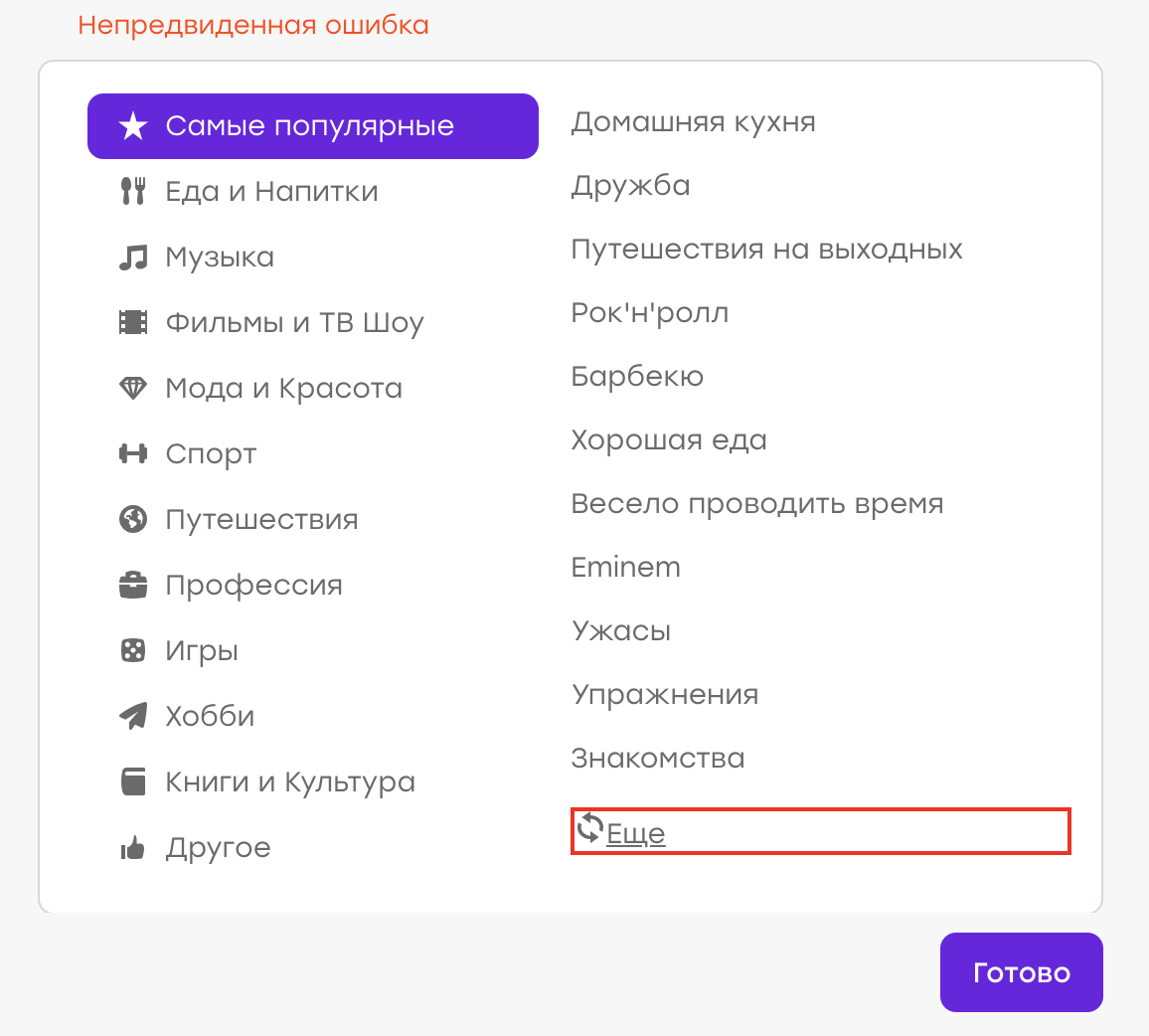
Verificou-se que havia um problema no lado do servidor, a resposta não era a mesma e o cliente processou esse problema mostrando uma notificação.
Nossa tarefa é escrever um autoteste que verifique esse caso.
Escrevemos aproximadamente o seguinte script:
- Abrir perfil
- Abrir lista de interesses
- Clique no botão "Mais"
- Verifique se o erro não apareceu (por exemplo, não há elemento div.error)
Nós executamos esse teste. No entanto, acontece o seguinte: após alguns dias / meses / anos, o bug reaparece, embora o teste não capte nada. Porque
Tudo é bem simples: durante a aprovação bem-sucedida do teste, o localizador do elemento pelo qual procuramos o texto do erro foi alterado. Houve uma refatoração dos modelos e, em vez da classe "error", obtivemos a classe "error_new".
Durante a refatoração, o teste continuou a funcionar como esperado. O elemento div.error não apareceu; não havia motivo para a queda. Mas agora o elemento “div.error” não existe mais - portanto, o teste nunca falha, não importa o que aconteça no aplicativo.
Conclusão: é melhor testar a operacionalidade da interface com verificações positivas. Em nosso exemplo, devemos esperar que a lista de interesses tenha mudado.
Há situações em que um teste negativo não pode ser substituído por um teste positivo. Por exemplo, ao interagir com algum elemento, nada acontece em uma situação "boa" e um erro aparece em uma situação "ruim". Nesse caso, você deve criar uma maneira de simular um cenário "ruim" e também escrever um autoteste nele. Assim, verificamos que o elemento de erro aparece no caso negativo e, assim, monitoramos a relevância do localizador.
Verifique se há um item
Como garantir que a interação do teste com a interface tenha êxito e que tudo funcione? Isso é visto com mais frequência nas alterações que ocorreram nessa interface.
Considere um exemplo. Você precisa garantir que, ao enviar uma mensagem, ela apareça no chat:
O script é mais ou menos assim:
- Abrir perfil de usuário
- Abra o bate-papo com ele
- Escreva uma mensagem
- Enviar
- Aguarde a mensagem aparecer.
Descrevemos esse cenário em nosso teste. Suponha que uma mensagem de bate-papo corresponda a um localizador:
p.message_text
É assim que verificamos se o elemento aparece:
this.waitForPresence(By.css('p.message_text'), "Cannot find sent message.");
Se a nossa espera funcionar, tudo está em ordem: as mensagens de bate-papo são desenhadas.
Como você deve ter adivinhado, depois de um tempo, o envio de mensagens de bate-papo é interrompido, mas nosso teste continua a funcionar sem interrupções. Vamos acertar.
Acontece que um dia antes de um novo elemento aparecer no bate-papo: algum texto que solicita ao usuário que destaque a mensagem se de repente passar despercebida:
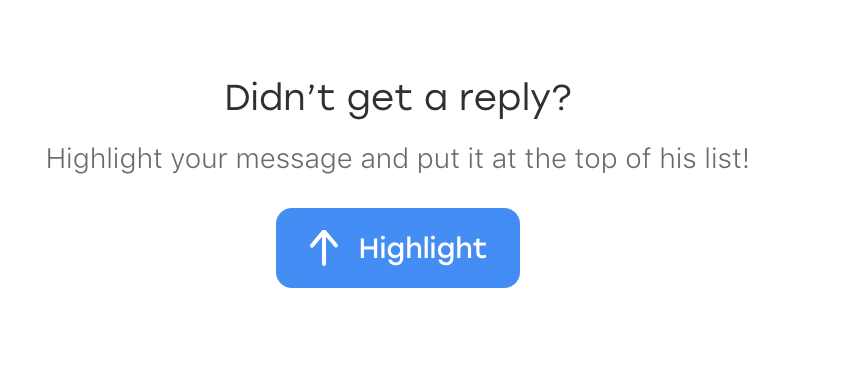
E, o mais engraçado, também cai sob o nosso localizador. Somente ele possui uma classe adicional que o distingue das mensagens enviadas:
p.message_text.highlight
Nosso teste não foi interrompido quando esse bloco apareceu, mas a verificação "aguardar a exibição da mensagem" deixou de ser relevante. O elemento que foi um indicador de um evento bem-sucedido agora está sempre lá.
Conclusão: se a lógica do teste é baseada na verificação da aparência de algum elemento, é necessário verificar se esse elemento não existe antes de nossa interação com a interface do usuário.
- Abrir perfil de usuário
- Abra o bate-papo com ele
- Verifique se não há mensagens enviadas
- Escreva uma mensagem
- Enviar
- Aguarde a mensagem aparecer.
Dados aleatórios
Frequentemente, os testes de interface do usuário funcionam com formulários nos quais eles inserem dados. Por exemplo, temos um formulário de registro:
Os dados para esses testes podem ser armazenados em configurações ou codificados em um teste. Mas às vezes o pensamento vem à mente: por que não randomizar os dados? Isso é bom, vamos cobrir mais casos!
Meu conselho: não. E agora vou lhe dizer o porquê.
Suponha que nosso teste esteja registrado no Badoo. Decidimos que escolheremos o sexo do usuário aleatoriamente. No momento da redação do teste, o fluxo de registro para a menina e o menino não é diferente, portanto, nosso teste é aprovado com êxito.
Agora imagine que depois de um tempo o fluxo de registro se torne diferente. Por exemplo, damos bônus à menina imediatamente após o registro, sobre os quais a notificamos com uma cobertura especial.
No teste, não há lógica para fechar a sobreposição, mas, por sua vez, interfere em quaisquer outras ações prescritas no teste. Temos um teste que cai em 50% dos casos. Qualquer ferramenta de automação confirmará que os testes de interface do usuário não são inerentemente estáveis por natureza. E isso é normal, é preciso conviver com ele, constantemente enfrentando a lógica redundante "para todas as ocasiões" (que estraga visivelmente a legibilidade do código e complica seu suporte) e essa instabilidade em si.
Da próxima vez, quando o teste cair, talvez não tenhamos tempo para lidar com isso. Nós apenas o reiniciamos e vemos que já passou. Decidimos que, em nossa aplicação, tudo funciona como deveria e a coisa é um teste instável. E acalme-se.
Agora vamos seguir em frente. E se essa sobreposição quebrar? O teste continuará a ser aprovado em 50% dos casos, o que atrasa significativamente a localização do problema.
E é bom quando, devido à randomização dos dados, criamos uma situação "50 por 50". Mas isso acontece de maneira diferente. Por exemplo, antes de se registrar, uma senha era considerada aceitável com pelo menos três caracteres. Nós escrevemos um código que vem com uma senha aleatória não inferior a três caracteres (às vezes três caracteres e às vezes mais). E então a regra muda - e a senha já deve conter pelo menos quatro caracteres. Qual é a probabilidade de uma queda neste caso? E, se o nosso teste detectar um erro real, com que rapidez descobriremos?
É especialmente difícil trabalhar com testes nos quais muitos dados aleatórios são inseridos: nome, sexo, senha e assim por diante ... Nesse caso, também existem muitas combinações diferentes e, se ocorrer um erro em alguma delas, geralmente é difícil perceber.
Conclusão Como escrevi acima, randomizar dados é ruim. É melhor cobrir mais casos às custas dos provedores de dados, sem esquecer as
classes de equivalência , é claro. Passar nos testes levará mais tempo, mas você pode combatê-lo. Mas teremos certeza de que, se houver um problema, ele será detectado.
Atomicidade dos ensaios (parte 1)
Vejamos o exemplo a seguir. Estamos escrevendo um teste que verifica o contador de usuários no rodapé.

O cenário é simples:
- Abrir aplicação
- Localizar contador de rodapé
- Verifique se está visível
Chamamos esse teste de testFooterCounter e o executamos. Então, é necessário verificar se o contador não mostra zero. Adicionamos esse teste a um teste existente, por que não?
Porém, torna-se necessário verificar se no rodapé existe um link para a descrição do projeto (o link "Quem Somos"). Escrever um novo teste ou adicionar a um existente? No caso de um novo teste, teremos que aumentar novamente o aplicativo, preparar o usuário (se verificarmos o rodapé na página autorizada), efetuar login - em geral, gastar um tempo precioso. Em tal situação, renomear o teste para testFooterCounterAndLinks parece uma boa idéia.
Por um lado, essa abordagem tem vantagens: economizando tempo, armazenando todas as verificações de alguma parte de nosso aplicativo (neste caso, rodapé) em um único local.
Mas há um sinal de menos. Se o teste falhar no primeiro teste, não verificaremos o restante do componente. Suponha que um teste trava em algum ramo, não por instabilidade, mas por um erro. O que fazer Retornar uma tarefa que descreve apenas esse problema? Em seguida, corremos o risco de obter uma tarefa com uma correção apenas desse bug, executamos um teste e descobrimos que o componente também está quebrado, em outro local. E pode haver muitas dessas iterações. Chutar um ticket para frente e para trás neste caso levará muito tempo e será ineficaz.
Conclusão: se possível, atomize as verificações. Nesse caso, mesmo tendo um problema em um caso, verificaremos todos os outros. E, se você precisar devolver o ticket, podemos descrever imediatamente todas as áreas problemáticas.
Atomicidade dos ensaios (parte 2)
Considere outro exemplo. Estamos escrevendo um teste de bate-papo que verifica a seguinte lógica. Se os usuários tiverem simpatia mútua, o seguinte promoblock aparecerá no bate-papo:

O cenário é o seguinte:
- Votar pelo usuário A para o usuário B
- Votar pelo usuário B para o usuário A
- Usuário A bate-papo aberto com o usuário B
- Confirme se a unidade está no lugar
Por algum tempo, o teste funciona com êxito, mas acontece o seguinte ... Não, desta vez o teste não perde nenhum bug. :)
Depois de algum tempo, descobrimos que há outro erro não relacionado ao nosso teste: se você abrir um bate-papo, feche-o imediatamente e abra-o novamente, o bloqueio desaparecerá. Não é o caso mais óbvio, e no teste, é claro, não o previmos. Mas decidimos que precisamos cobri-lo também.
Surge a mesma pergunta: escreva outro teste ou insira um teste em um já existente? Escrever um novo parece inapropriado, porque 99% das vezes ele faz o mesmo que o existente. E decidimos adicionar o teste ao teste que já está lá:
- Votar pelo usuário A para o usuário B
- Votar pelo usuário B para o usuário A
- Usuário A bate-papo aberto com o usuário B
- Confirme se a unidade está no lugar
- Fechar bate-papo
- Chat aberto
- Confirme se a unidade está no lugar
Um problema pode surgir quando, por exemplo, refatoramos um teste após um longo período de tempo. Por exemplo, um novo design acontecerá em um projeto - e você terá que reescrever muitos testes.
Vamos abrir o teste e tentar lembrar o que ele verifica. Por exemplo, um teste é chamado testPromoAfterMutualAttraction. Entendemos por que a abertura e o encerramento do bate-papo estão escritos no final? Provavelmente não. Especialmente se este teste não foi escrito por nós. Vamos deixar esta peça? Talvez sim, mas se houver algum problema com ele, é provável que simplesmente o excluamos. E a verificação será perdida simplesmente porque seu significado não será óbvio.
Eu vejo duas soluções aqui. Primeiro: ainda faça o segundo teste e chame-o de testCheckBlockPresentAfterOpenAndCloseChat. Com esse nome, ficará claro que não estamos apenas realizando um determinado conjunto de ações, mas realizando uma verificação muito consciente, porque houve uma experiência negativa. A segunda solução é escrever um comentário detalhado no código sobre por que estamos fazendo esse teste neste teste específico. Também é aconselhável indicar o número do bug no comentário.
Erro ao clicar em um item existente
O exemplo a seguir me jogou
bbidox , pelo qual ele é uma grande vantagem no karma!
Há uma situação muito interessante quando o código de teste já se torna ... uma estrutura. Suponha que tenhamos um método como este:
public void clickSomeButton() { WebElement button_element = this.waitForButtonToAppear(); button_element.click(); }
Em algum momento, algo estranho começa a acontecer com esse método: o teste falha quando você tenta clicar em um botão. Abrimos a captura de tela feita no momento em que o teste falhou e vemos que há um botão na captura de tela e o método waitForButtonToAppear funcionou com êxito. Pergunta: o que há de errado com o clique?
A parte mais difícil nessa situação é que o teste às vezes pode ser bem-sucedido. :)
Vamos acertar. Suponha que o botão considerado no exemplo esteja localizado em uma sobreposição:
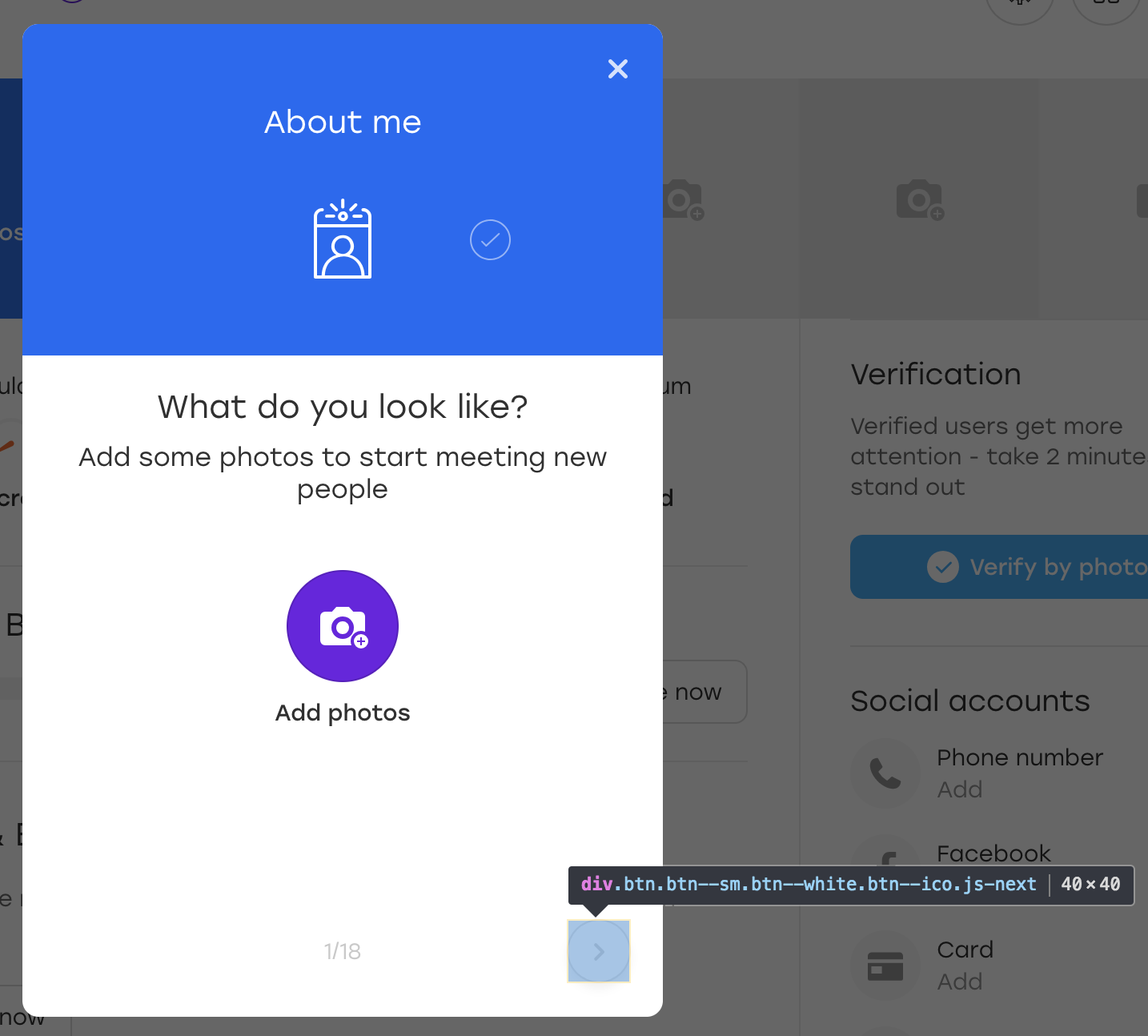
Esta é uma sobreposição especial através da qual um usuário em nosso site pode preencher informações sobre si mesmo. Quando você clica no botão de sobreposição destacado, o próximo bloco aparece para preencher.
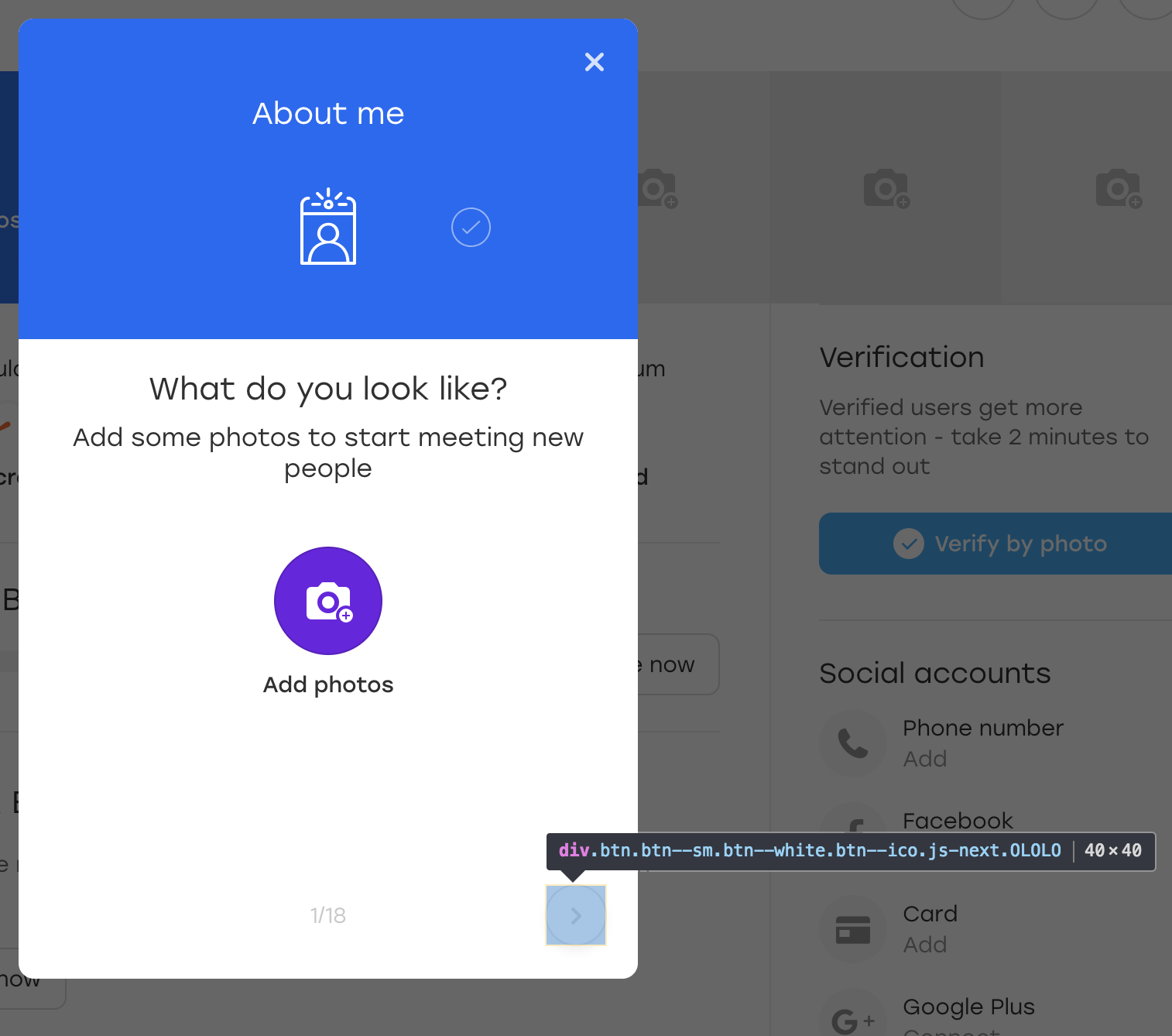
Por diversão, vamos adicionar uma classe OLOLO extra para este botão:
Depois disso, clicamos neste botão. Visualmente, nada mudou, mas o próprio botão permaneceu no lugar:
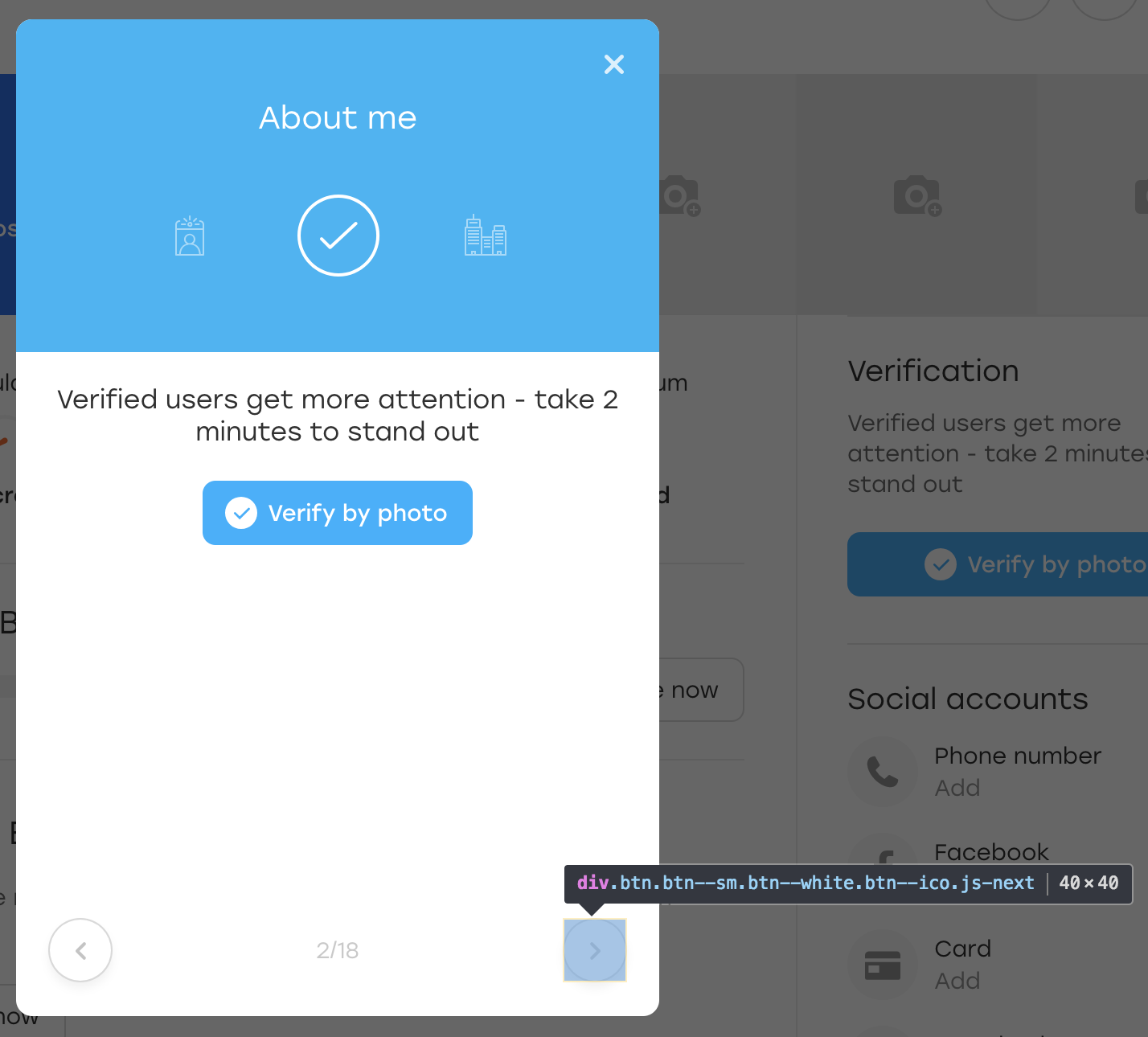
O que aconteceu? De fato, quando JS redesenhou o bloco para nós, ele redesenhou o botão também. Ainda está disponível no mesmo localizador, mas este é outro botão. Isso é evidenciado pela falta da classe OLOLO que adicionamos.
No código acima, armazenamos o elemento na variável $ element. Se um elemento for regenerado durante esse período, ele poderá não estar visível visualmente, mas você não poderá mais clicar nele - o método click () falhará.
Existem várias soluções:
- Quebrar clique no bloco try e no elemento catch reconstruir
- Adicione um botão a um atributo para sinalizar que ele foi alterado
Texto de erro
Finalmente, um ponto simples, mas não menos importante.
Este exemplo se aplica não apenas aos testes da interface do usuário, mas também ocorre com muita frequência neles. Geralmente, quando você escreve um teste, está no contexto do que está acontecendo: descreve a verificação após a verificação e entende seu significado. E você escreve textos de erro no mesmo contexto:
WebElement element = this.waitForPresence(By.css("a.link"), "Cannot find button");
O que pode ser incompreensível neste código? O teste espera a aparência de um botão e, se não estiver lá, cai naturalmente.
Agora imagine que o autor do teste está de licença médica e seu colega está cuidando dos testes. E então ele descarta o teste testQuestionsOnProfile e escreve esta mensagem: "Não é possível encontrar o botão". Um colega precisa entender o que está acontecendo o mais rápido possível, porque o lançamento está chegando.
O que ele terá que fazer?
Não faz sentido abrir a página na qual o teste caiu e verificar o localizador "a.link" - não há elemento. Portanto, você deve estudar cuidadosamente o teste e descobrir o que ele verifica.
Seria muito mais simples com um texto de erro mais detalhado: "Não é possível encontrar o botão enviar na sobreposição de perguntas". Com esse erro, você pode abrir imediatamente a sobreposição e ver para onde foi o botão.
Saída dois. Em primeiro lugar, vale a pena passar o texto do erro para qualquer método da sua estrutura de teste e é um parâmetro necessário para que não haja tentação de esquecê-lo. Em segundo lugar, o texto do erro deve ser detalhado. Isso nem sempre significa que deve ser longo, basta esclarecer o que deu errado no teste.
Como entender que o texto do erro está bem escrito? Muito simples Imagine que seu aplicativo quebrou e você precisa ir até os desenvolvedores e explicar o que e onde quebrou. Se você contar apenas o que está escrito no texto do erro, eles entenderão?
Sumário
Escrever um script de teste geralmente é uma atividade interessante. Ao mesmo tempo, buscamos muitos objetivos. Nossos testes devem:
- cobrir o maior número possível de casos
- trabalhe o mais rápido possível
- ser entendido
- apenas expanda
- fácil de manter
- pedir pizza
- e assim por diante ...
É especialmente interessante trabalhar com testes em um projeto em constante evolução e mudança, onde eles precisam ser atualizados constantemente: adicione algo e corte algo. É por isso que vale a pena pensar sobre alguns pontos com antecedência e nem sempre se apressar nas decisões. :)
Espero que minhas dicas o ajudem a evitar alguns problemas e a torná-lo mais atencioso nos estudos de caso. Se o público gostar do artigo, tentarei coletar alguns exemplos mais chatos. Enquanto isso - tchau!