Hora de reabastecer o cofrinho de bons relatórios em russo sobre Machine Learning! O próprio mealheiro não será reabastecido!
Desta vez, vamos nos familiarizar com
a fascinante história de
Andrei Boyarov sobre reconhecimento de cenas. Andrey é um pesquisador de visão computacional envolvido em visão de máquina no Mail.Ru Group.
O reconhecimento de cena é uma das áreas amplamente usadas da visão de máquina. Essa tarefa é mais complicada do que o reconhecimento estudado de objetos: a cena é um conceito mais complexo e menos formalizado, é mais difícil distinguir características. A tarefa de reconhecer pontos turísticos segue do reconhecimento de cena: você precisa destacar lugares conhecidos na foto, garantindo um baixo nível de falsos positivos.
São
30 minutos de vídeo da conferência Smart Data 2017. O vídeo é conveniente para assistir em casa e em qualquer lugar. Para aqueles que não estão prontos para sentar-se tanto na tela ou que preferem perceber as informações em forma de texto, aplicamos uma descriptografia de texto completo, projetada na forma de habrosta.
Eu faço visão de máquina no Mail.ru. Hoje vou falar sobre como usamos o aprendizado profundo para reconhecer imagens de cenas e atrações.
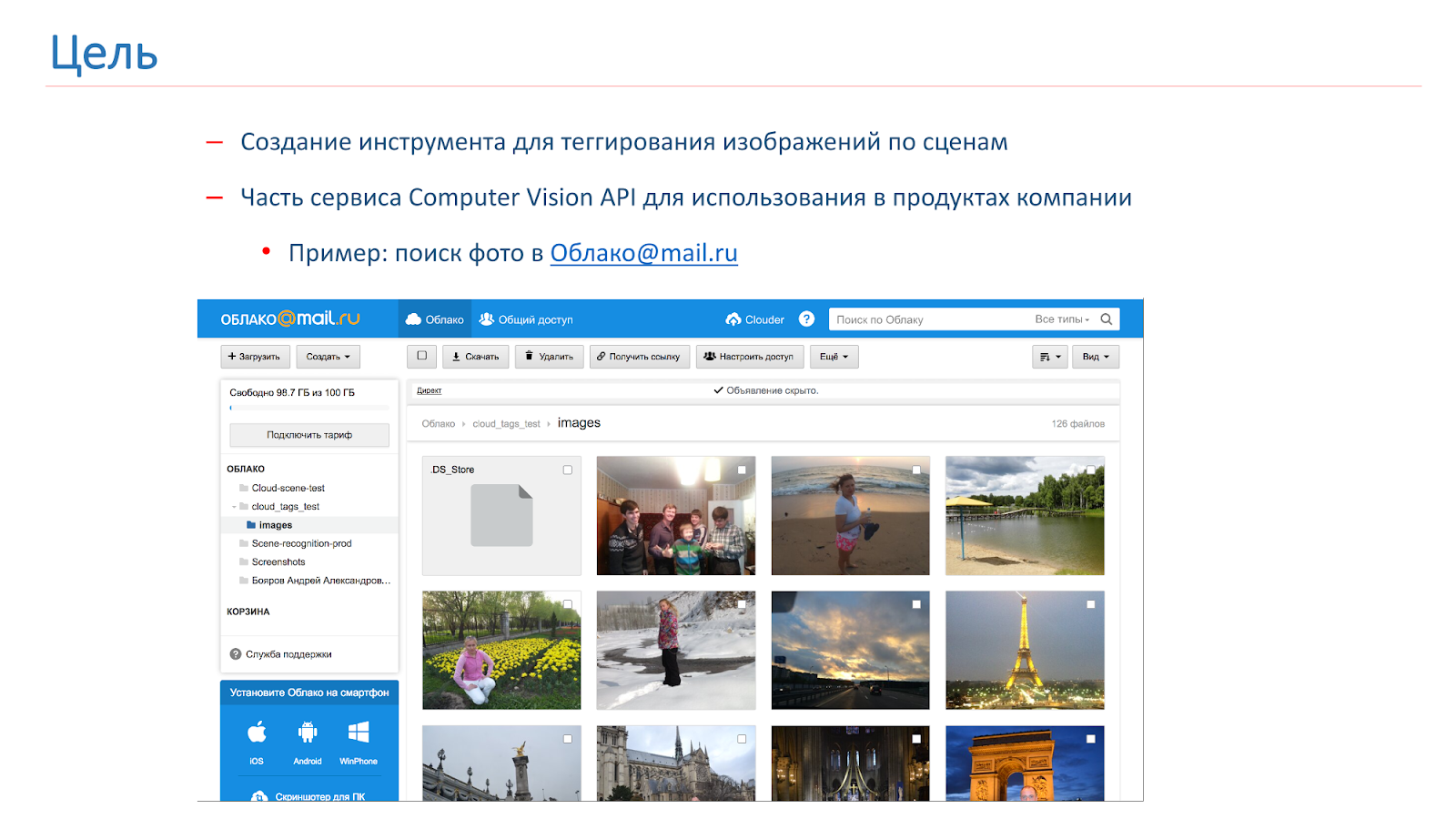
A empresa surgiu com a necessidade de marcar e pesquisar por imagens do usuário e, por isso, decidimos criar nossa própria API do Computer Vision, parte da qual será uma ferramenta de marcação de cenas. Como resultado dessa ferramenta, queremos obter algo como o mostrado na figura abaixo: o usuário faz uma solicitação, por exemplo, “catedral” e recebe todas as suas fotos com catedrais.
Na comunidade Computer Vision, o tópico de reconhecimento de objetos em imagens foi estudado muito bem. Existe um conhecido
concurso ImageNet realizado há vários anos e a parte principal é o reconhecimento de objetos.
Basicamente, precisamos localizar algum objeto e classificá-lo. Nas cenas, a tarefa é um pouco mais complicada, porque a cena é um objeto mais complexo, consiste em um grande número de outros objetos e no contexto que os une, portanto as tarefas são diferentes.

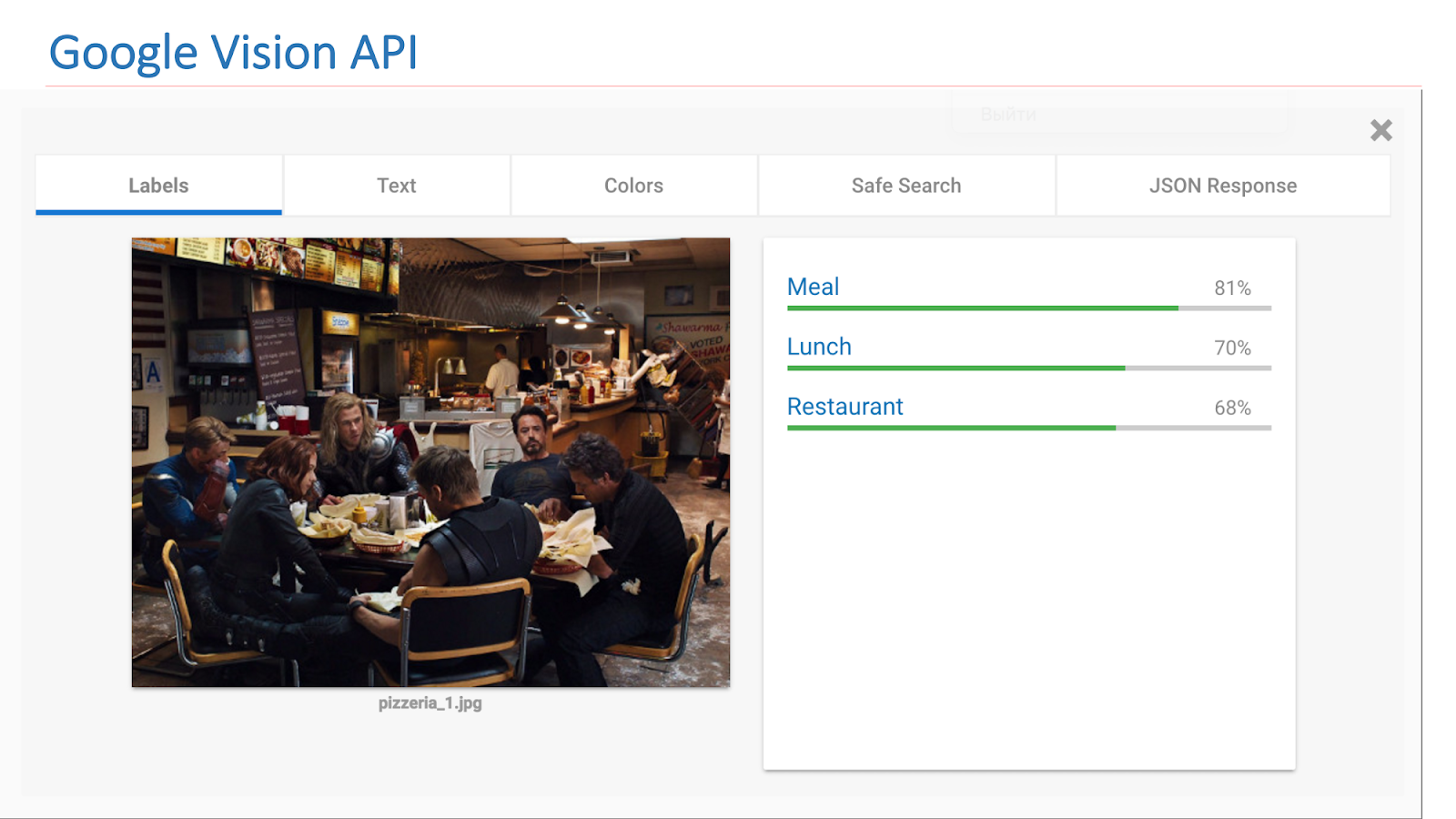
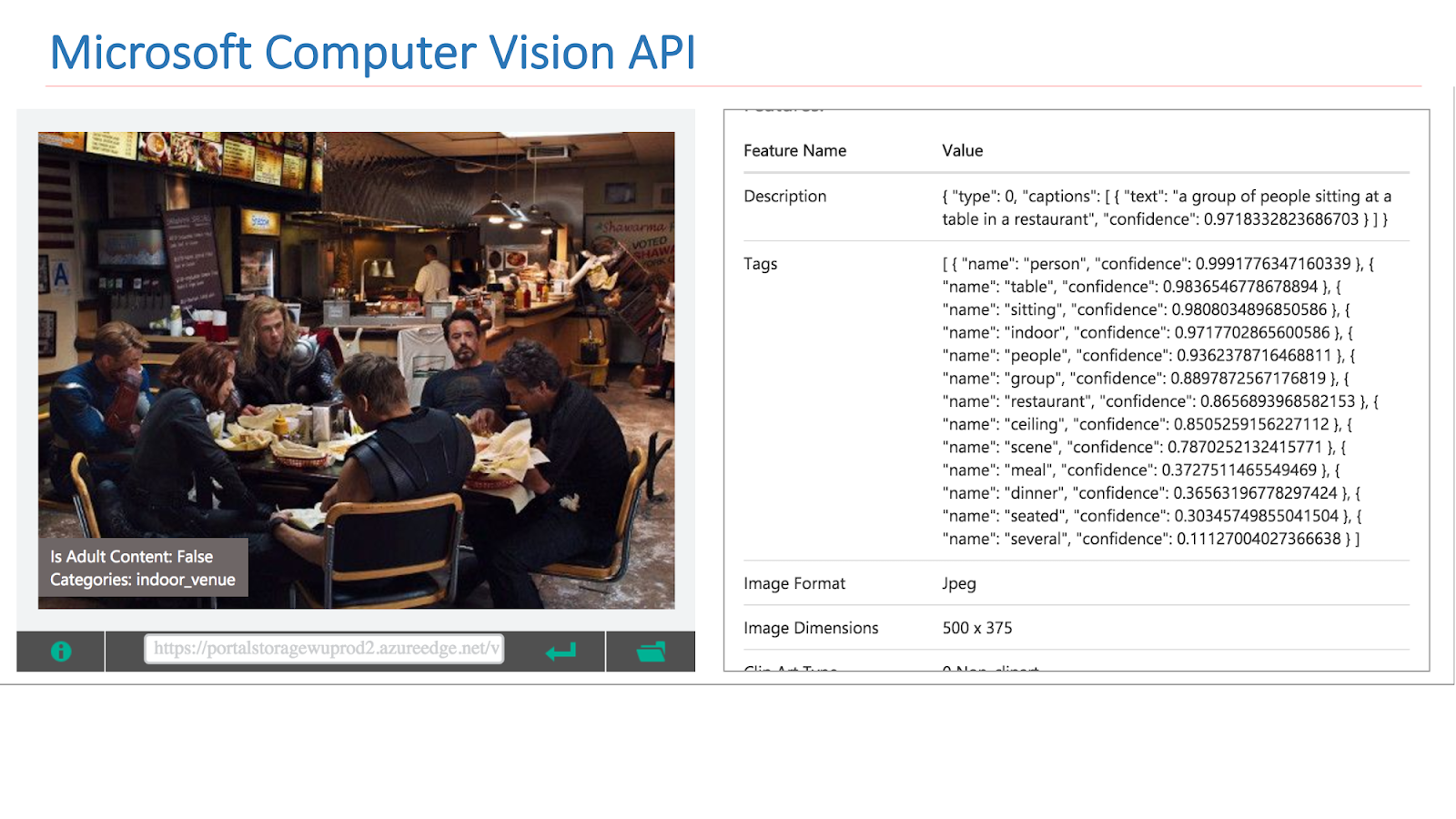
Na Internet, existem serviços disponíveis de outras empresas que implementam essa funcionalidade. Em particular, esta é a API do Google Vision ou da API do Microsoft Computer Vision, que pode encontrar cenas nas imagens.
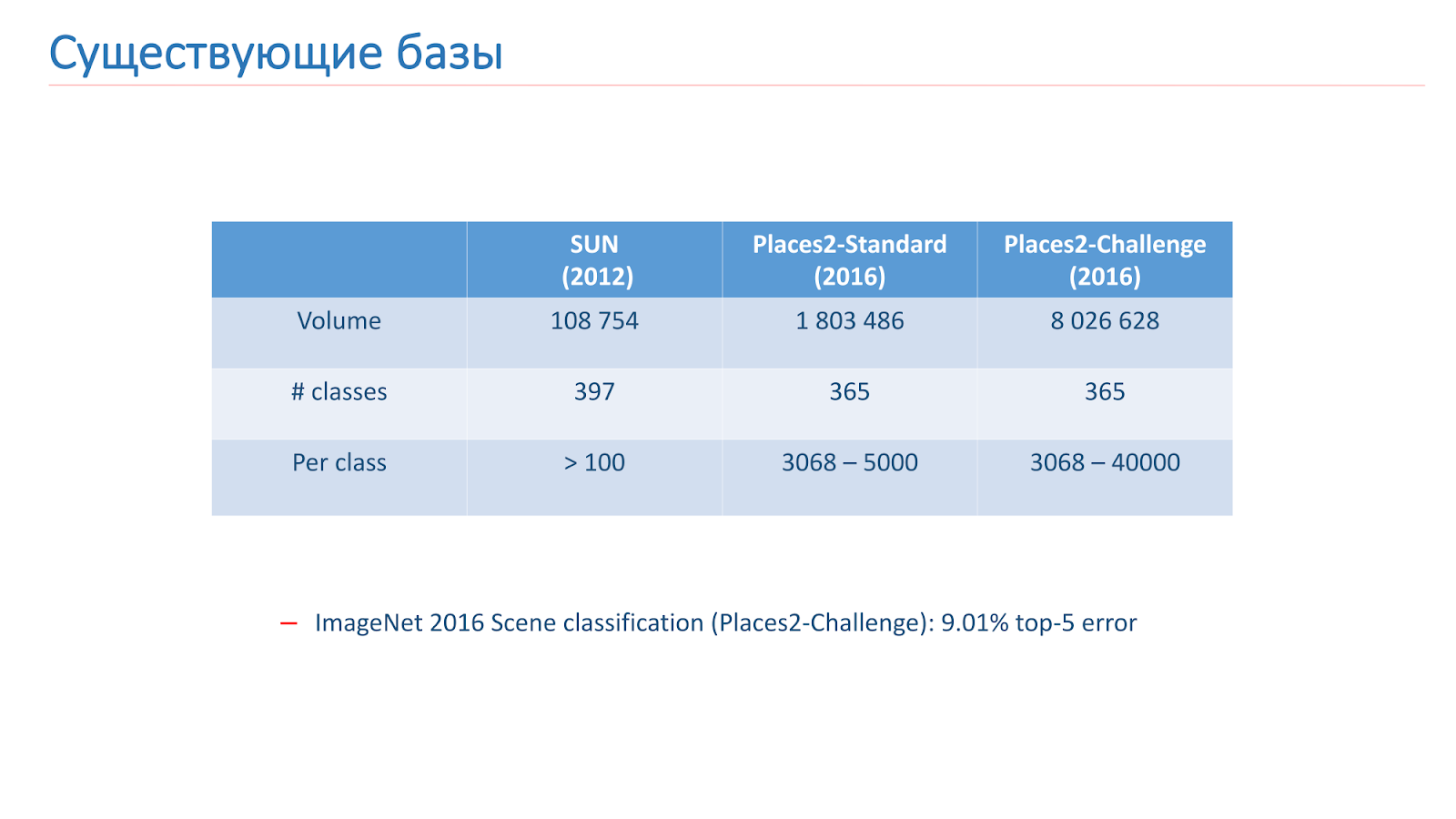
Resolvemos esse problema com a ajuda do aprendizado de máquina, portanto, para isso, precisamos de dados. Existem duas bases principais para o reconhecimento de cenas em acesso aberto agora. O primeiro deles apareceu em 2013 - esta é
a base do
SUN da Universidade de Princeton. Essa base consiste em centenas de milhares de imagens e 397 classes.
A segunda base na qual treinamos é
a base Places2 do MIT. Ela apareceu em 2013 em duas versões. O primeiro é o Places2-Standart, uma base mais equilibrada com 1,8 milhão de imagens e 365 classes. A segunda opção - Places2-Challenge, contém oito milhões de imagens e 365 classes, mas o número de imagens entre as classes não é equilibrado. No concurso ImageNet de 2016, a seção Reconhecimento de cena incluiu o desafio Places2, e o vencedor mostrou o melhor resultado de
erro de classificação entre os 5 melhores, de cerca de 9%.
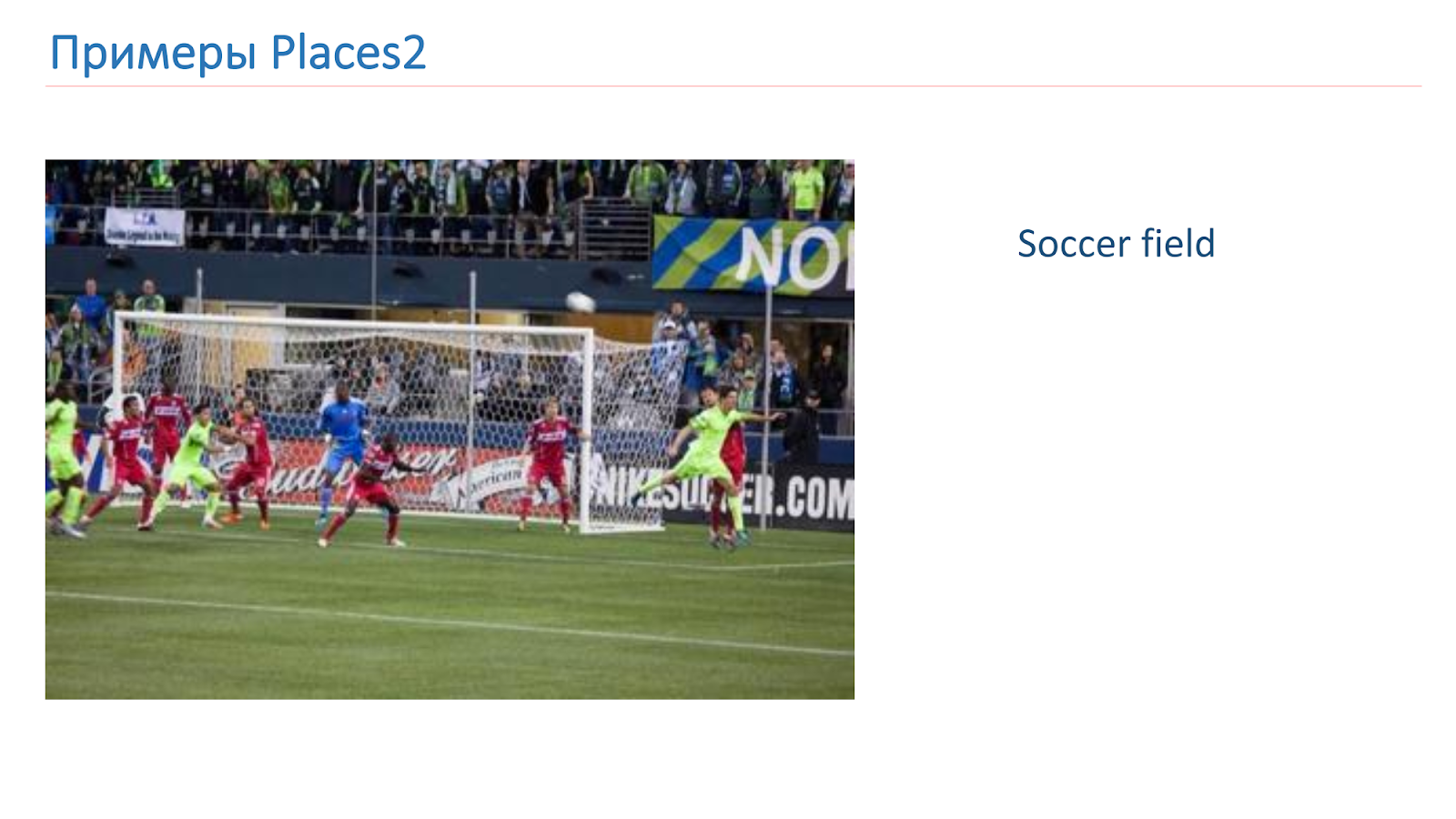
Treinamos com base no Places2. Aqui está um exemplo de imagem de lá: é um canyon, pista, cozinha, campo de futebol. Esses são objetos complexos completamente diferentes sobre os quais precisamos aprender a reconhecer.

Antes de estudar, adaptamos as bases que temos para atender às nossas necessidades. Existe um truque para o reconhecimento de objetos ao experimentar modelos em pequenas bases CIFAR-10 e CIFAR-100 em vez do ImageNet, e somente então os melhores treinam no ImageNet.
Decidimos seguir o mesmo caminho, pegamos o banco de dados SUN, reduzimos, obtivemos 89 aulas, 50 mil imagens no trem e 10 mil imagens na validação. Como resultado, antes do treinamento no Places2, montamos experimentos e testamos nossos modelos com base no SUN. O treinamento leva apenas 6 a 10 horas, ao contrário de vários dias no Places2, o que permitiu realizar muito mais experimentos e torná-lo mais eficaz.
Também analisamos o próprio banco de dados do Places2 e percebemos que não precisávamos de algumas classes. Devido a considerações de produção ou porque há poucos dados sobre elas, cortamos classes como, por exemplo, um aqueduto, uma casa na árvore, uma porta do celeiro.

Como resultado, após todas as manipulações, obtivemos o banco de dados do Places2, que contém 314 classes e meio milhão de imagens (em sua versão padrão), na versão Challenge, cerca de 7,5 milhões de imagens. Construímos treinamento nessas bases.
Além disso, ao visualizar as classes restantes, descobrimos que há muitas delas para produção, elas são muito detalhadas. E, para isso, aplicamos o mecanismo de mapeamento de cena quando algumas classes são combinadas em uma comum. Por exemplo, conectamos tudo o que estava conectado às florestas em uma floresta, tudo conectado aos hospitais - em um hospital, com hotéis - em um hotel.
Usamos o mapeamento de cena apenas para teste e para o usuário final, porque é mais conveniente. No treinamento, usamos todas as 314 classes padrão. Chamamos a base resultante de Peneirar Locais.
Abordagens, Soluções
Agora considere as abordagens que usamos para resolver esse problema. Na verdade, essas tarefas estão relacionadas à abordagem clássica - redes neurais convolucionais profundas.
A imagem abaixo mostra uma das primeiras redes clássicas, mas já contém os principais blocos de construção usados nas redes modernas.

São camadas convolucionais, são camadas de tração, camadas totalmente conectadas. Para determinar a arquitetura, verificamos os topos das competições ImageNet e Places2.

Podemos dizer que as principais arquiteturas líderes podem ser divididas em duas famílias: Inception e a família ResNet (rede residual). No decorrer dos experimentos, descobrimos que a família ResNet é mais adequada para nossa tarefa e realizamos o próximo experimento nessa família.

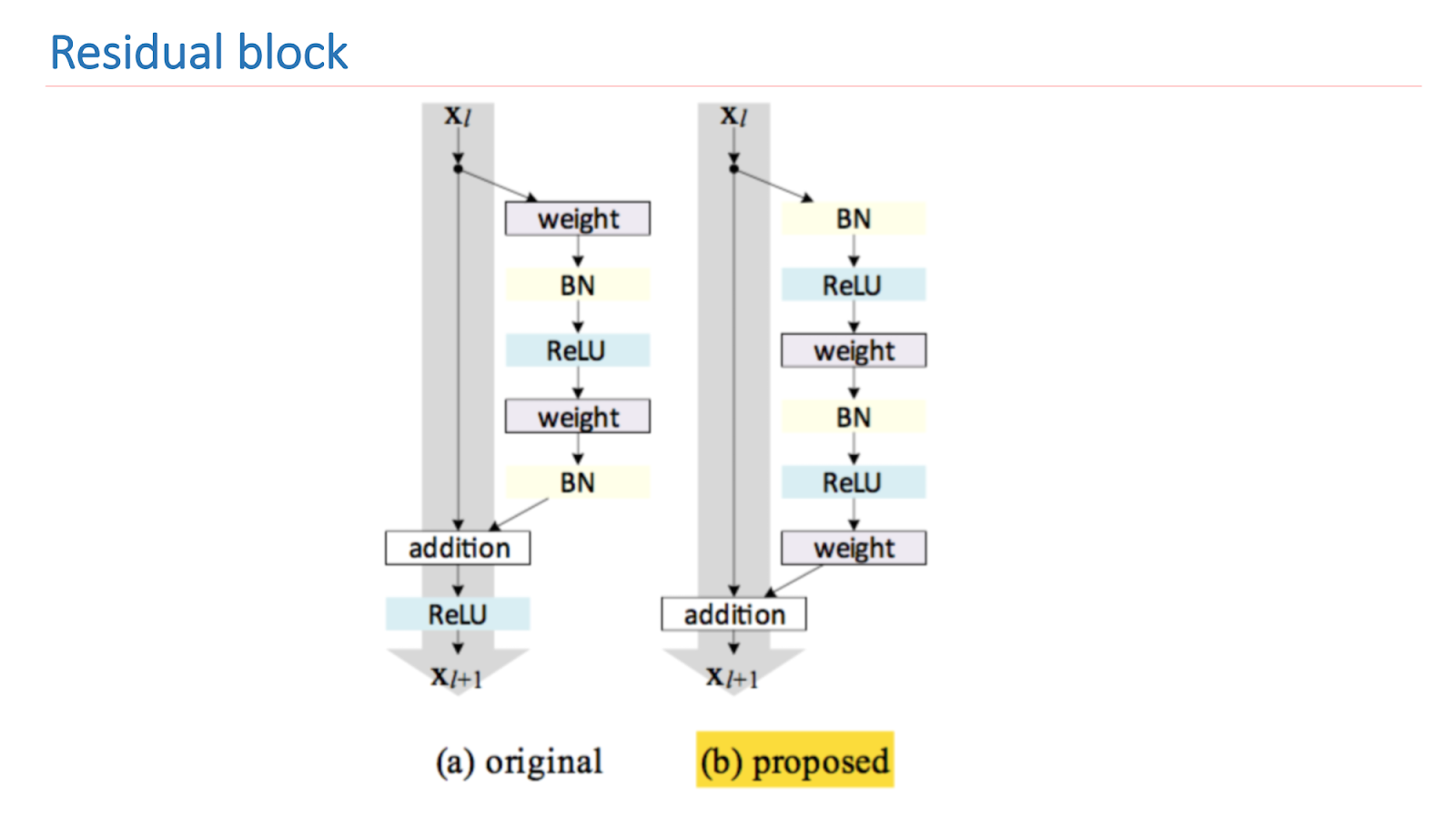
O ResNet é uma rede profunda que consiste em um grande número de blocos residuais. Esse é o seu principal componente básico, que consiste em várias camadas com pesos e conexão de atalho. Como resultado desse projeto, esta unidade aprende quanto o sinal de entrada x difere da saída f (x). Como resultado, podemos construir redes desses blocos e, durante o treinamento, a rede nas últimas camadas pode tornar os pesos próximos a zero.
Assim, podemos dizer que a própria rede decide a profundidade necessária para resolver algumas das tarefas. Graças a essa arquitetura, é possível construir redes de grande profundidade com um número muito grande de camadas. O vencedor do ImageNet 2014 continha apenas 22 camadas, o ResNet excedeu esse resultado e já continha 152 camadas.
A principal pesquisa da ResNet é melhorar e construir adequadamente um bloco residual. A imagem abaixo mostra uma versão empiricamente e matematicamente sólida que oferece o melhor resultado. Essa construção do bloco permite que você lide com um dos problemas fundamentais da aprendizagem profunda - um gradiente gradual.
Para treinar nossas redes, usamos o framework Torch escrito em Lua por causa de sua flexibilidade e velocidade e, para o ResNet, criamos a
implementação do ResNet pelo Facebook . Para validar a qualidade da rede, usamos três testes.
O primeiro teste de valor do Places é a validação de muitos conjuntos do Sift do Places. O segundo teste é Peneirar Locais usando o Mapeamento de Cena e o terceiro é o teste em Nuvem mais próximo da situação de combate. Imagens de funcionários tiradas da nuvem e rotuladas manualmente. Na imagem abaixo, existem dois exemplos de tais imagens.

Começamos a medir e treinar redes, compará-las entre si. O primeiro é o benchmark ResNet-152, que vem com o Places2, o segundo é o ResNet-50, que treinamos no ImageNet e treinamos em nossa base, o resultado já foi melhor. Em seguida, eles fizeram o ResNet-200, também treinado no ImageNet, e mostrou o melhor resultado no final.

Abaixo estão exemplos de trabalho. Este é um benchmark ResNet-152. Previstos são os rótulos originais que a rede distribui. Os rótulos mapeados são os rótulos que vieram após o Mapeamento de cena. Pode-se ver que o resultado não é muito bom. Ou seja, ela parece estar dando algo sobre o caso, mas não muito bem.

O próximo exemplo é a operação do ResNet-200. Já é muito adequado.

Aprimoramento ResNet
Decidimos tentar melhorar nossa rede e, a princípio, apenas tentamos aumentar a profundidade da rede, mas depois disso ficou muito mais difícil treinar. Esse é um problema conhecido. No ano passado, vários artigos foram publicados sobre o assunto, que afirmam que a ResNet é, de fato, um conjunto de um grande número de redes comuns de várias profundidades.
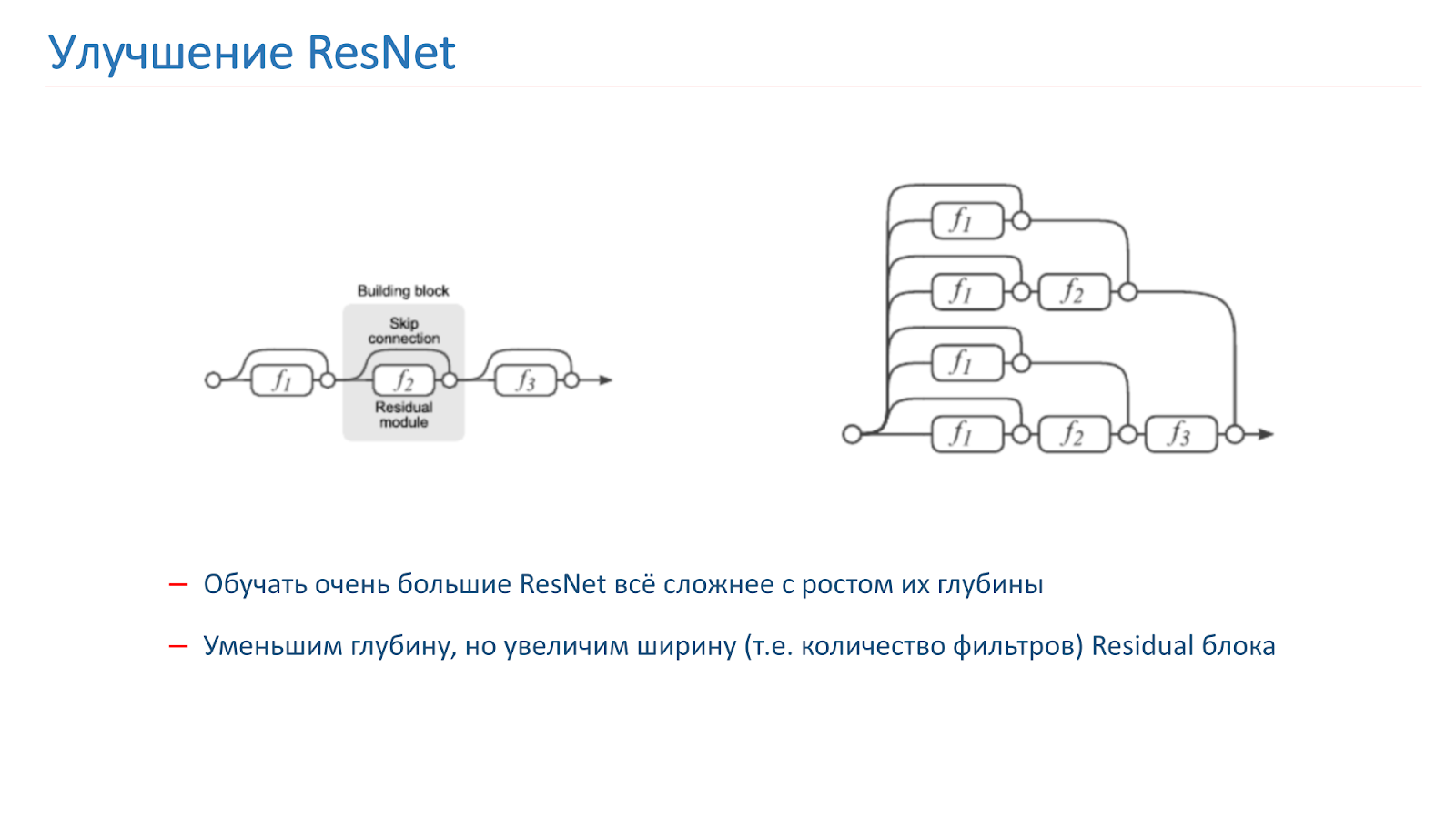
Blocos res, que estão no final da grade, dão uma pequena contribuição para a formação do resultado final. Parece mais promissor aumentar não a profundidade da rede, mas sua largura, ou seja, o número de filtros dentro do bloco Res.
Essa ideia é implementada pela Wide Residual Network, que surgiu em 2016. Acabamos usando o WRN-50-2, que é o ResNet-50 usual, com o dobro do número de filtros na convolução do gargalo interno 3x3.

A rede mostra no ImageNet resultados semelhantes ao ResNet-200, que já usamos, mas, o mais importante, é quase o dobro da velocidade. Aqui estão duas implementações do bloco Residual na tocha; o parâmetro que é dobrado é destacado com intensidade. Este é o número de filtros na convolução interna.

Essas são medidas nos testes do ResNet-200 ImageNet. No começo, pegamos o WRN-22-6, ele mostrou um resultado pior. Então eles pegaram o WRN-50-2-ImageNet, treinaram-no, pegaram o WRN-50-2, treinaram no ImageNet e o treinaram no desafio Places2, e ele mostrou o melhor resultado.
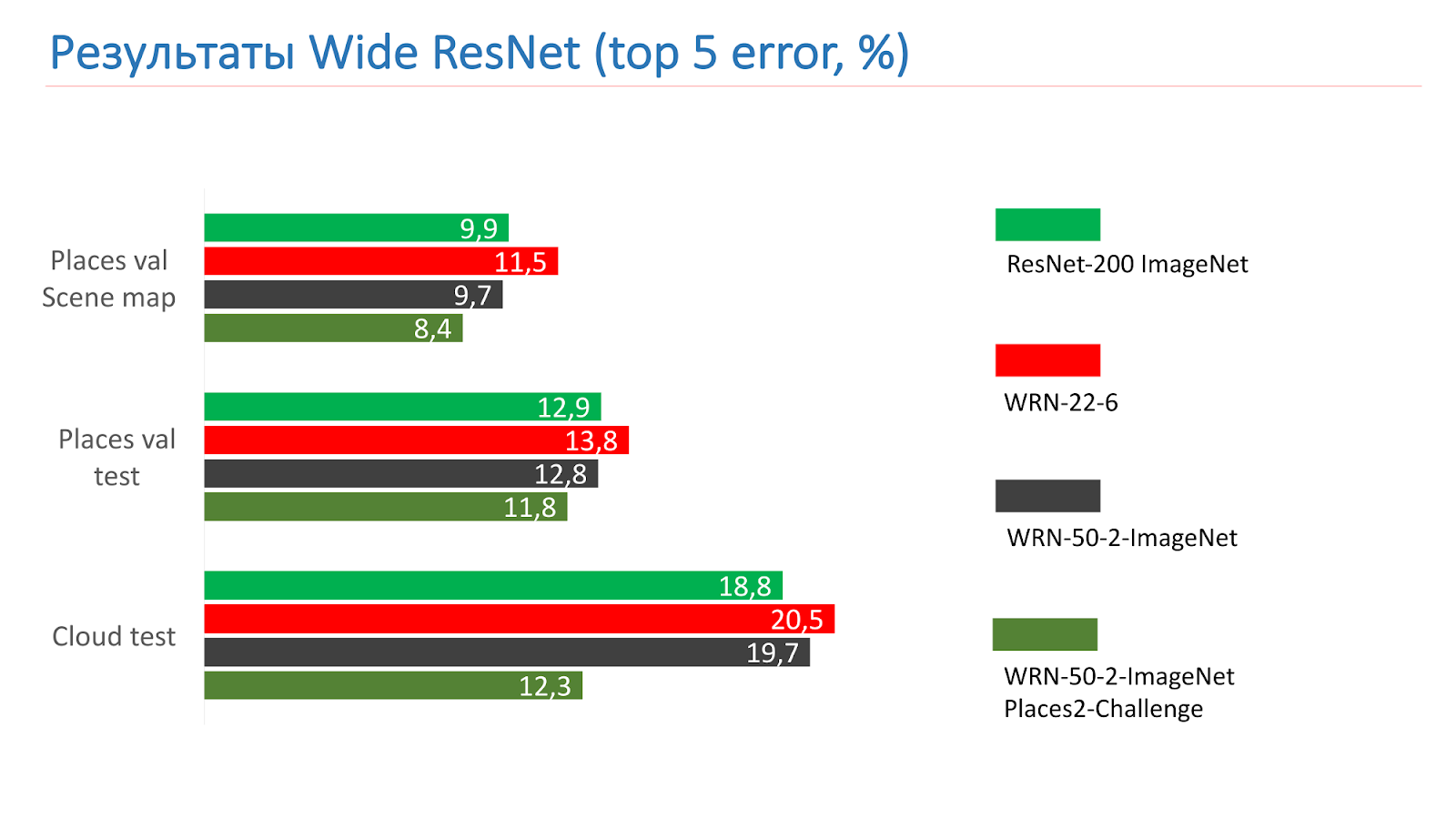
Aqui está um exemplo do WRN-50-2 - um resultado bastante adequado em nossas fotos que você já viu.

E este é um exemplo de trabalho em fotografias de combate, também com sucesso.

Obviamente, não existem obras de muito sucesso. A ponte de Alexandre III em Paris não foi reconhecida como ponte.

Melhoria do modelo
Pensamos em como melhorar esse modelo. A família ResNet continua melhorando, com novos artigos sendo publicados. Em particular, em 2016 foi publicado um artigo interessante PyramidNet, que mostrou resultados promissores no CIFAR-10/100 e ImageNet.
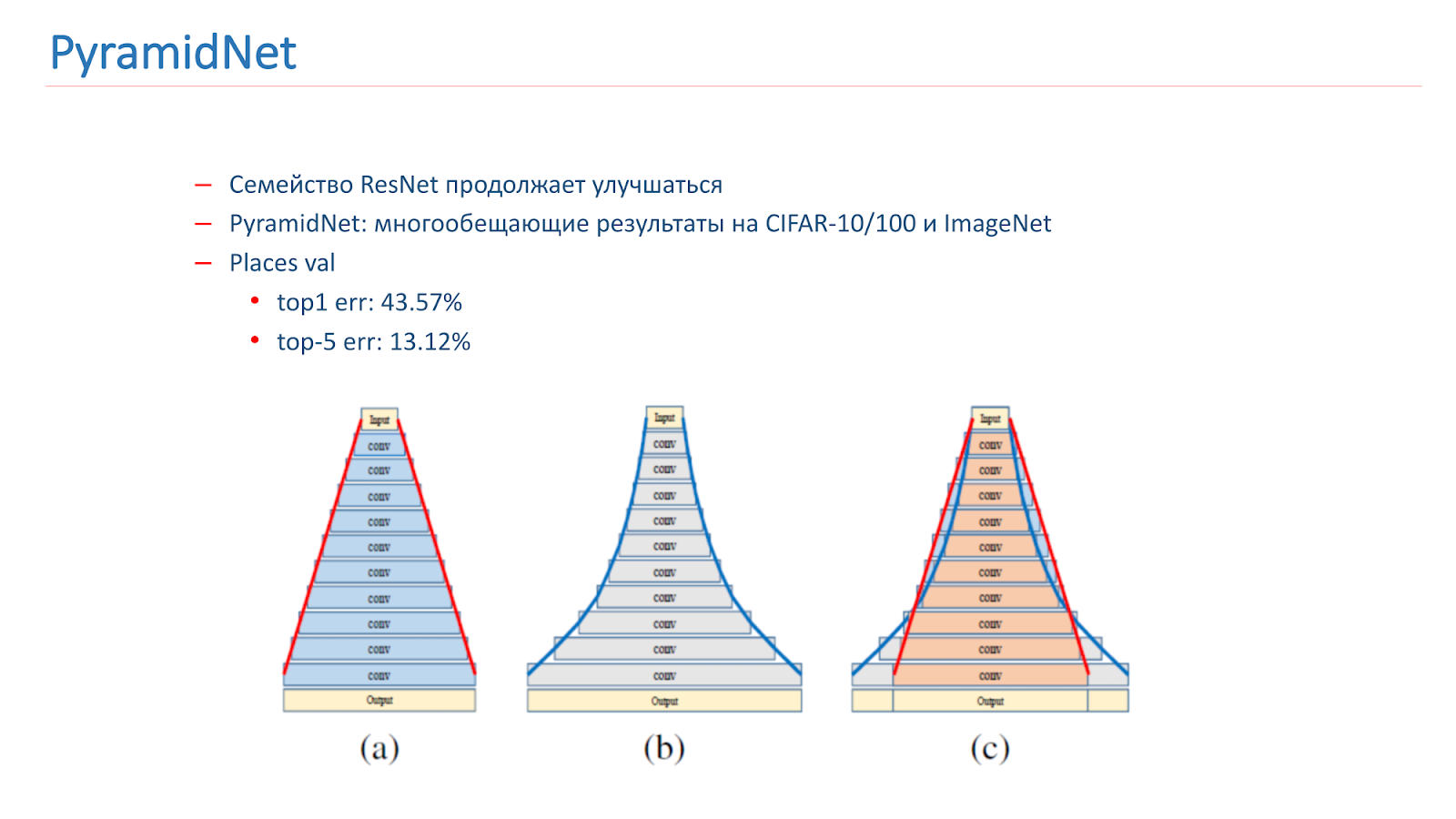
A idéia não é aumentar drasticamente a largura do bloco Residual, mas fazê-lo gradualmente. Treinamos várias opções para essa rede, mas, infelizmente, ela mostrou resultados um pouco piores que o nosso modelo de combate.
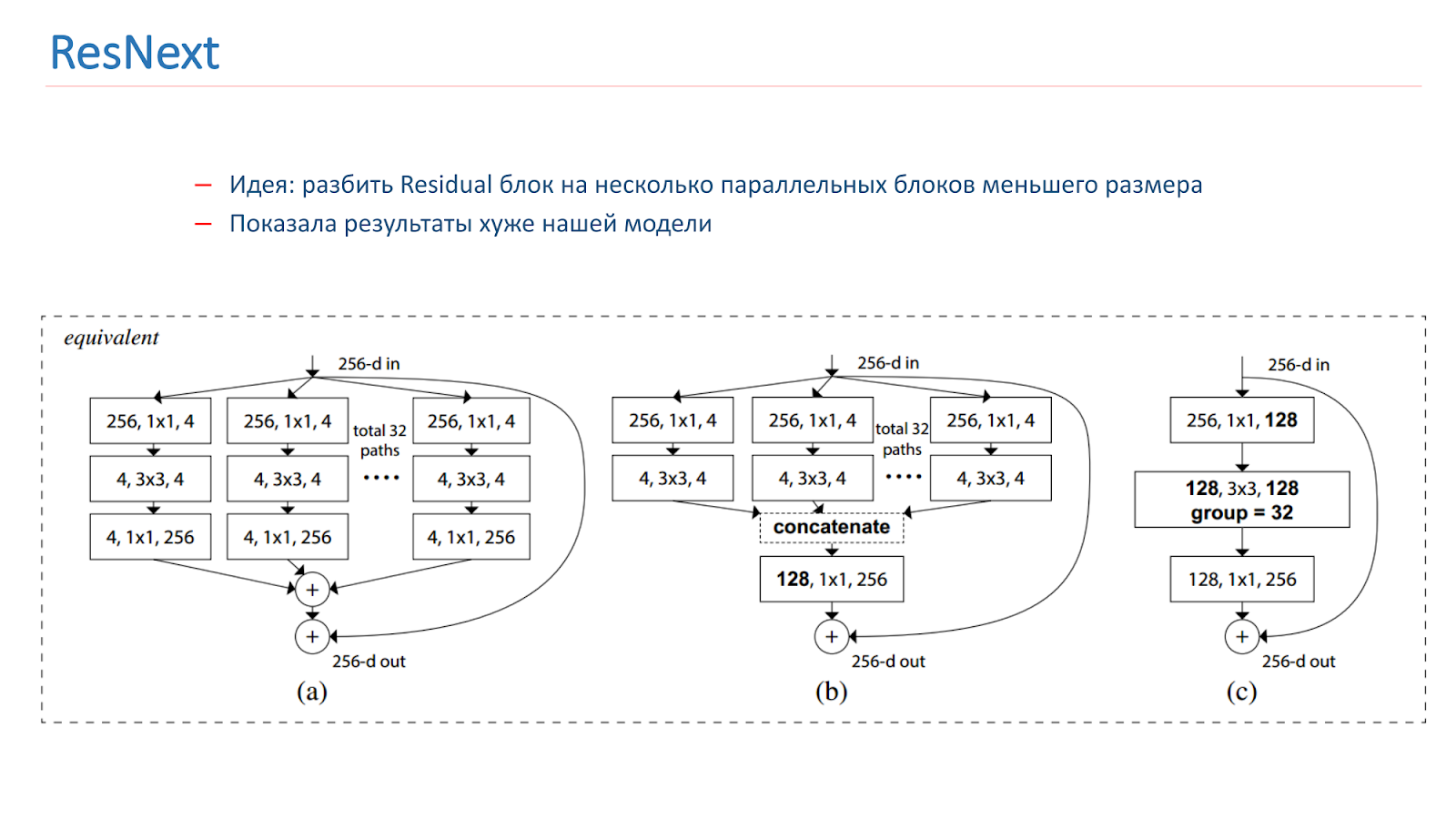
Na primavera de 2018, o modelo ResNext foi lançado, também uma idéia promissora: dividir o bloco Residual em vários blocos paralelos de tamanho menor e largura menor. Isso é semelhante à idéia de Iniciação, também experimentamos. Mas, infelizmente, ela mostrou resultados piores que o nosso modelo.
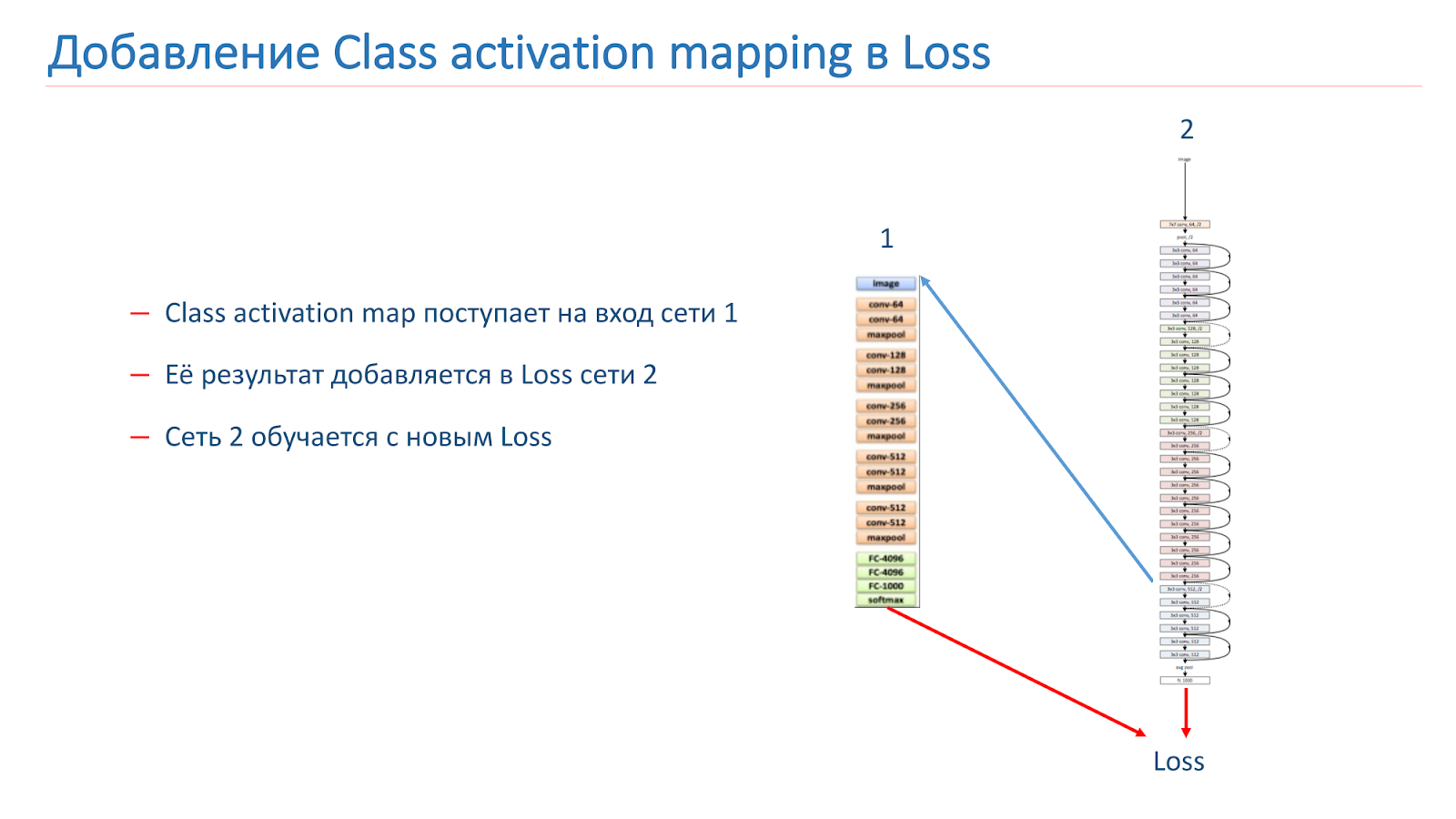
Também experimentamos várias abordagens "criativas" para melhorar nossos modelos. Em particular, tentamos usar o mapeamento de ativação de classe (CAM), ou seja, esses são os objetos que a rede observa quando classifica a imagem.

Nossa idéia era que instâncias da mesma cena deveriam ter objetos iguais ou semelhantes a uma classe CAM. Tentamos usar essa abordagem. No começo eles pegaram duas redes. Um é treinado pela ImageNet, o segundo é o nosso modelo, que queremos melhorar.

Pegamos a imagem, percorremos a rede 2, adicionamos o CAM para a camada e alimentamos a entrada da rede 1. Percorremos a rede 1, adicionamos os resultados à função de perda da rede 2, continuamos com as novas funções de perda.
A segunda opção é executar a imagem pela rede 2, pegar o CAM, alimentá-la com a entrada da rede 1 e, nesses dados, simplesmente treinamos a rede 1 e usamos o conjunto a partir dos resultados da rede 1 e da rede 2.
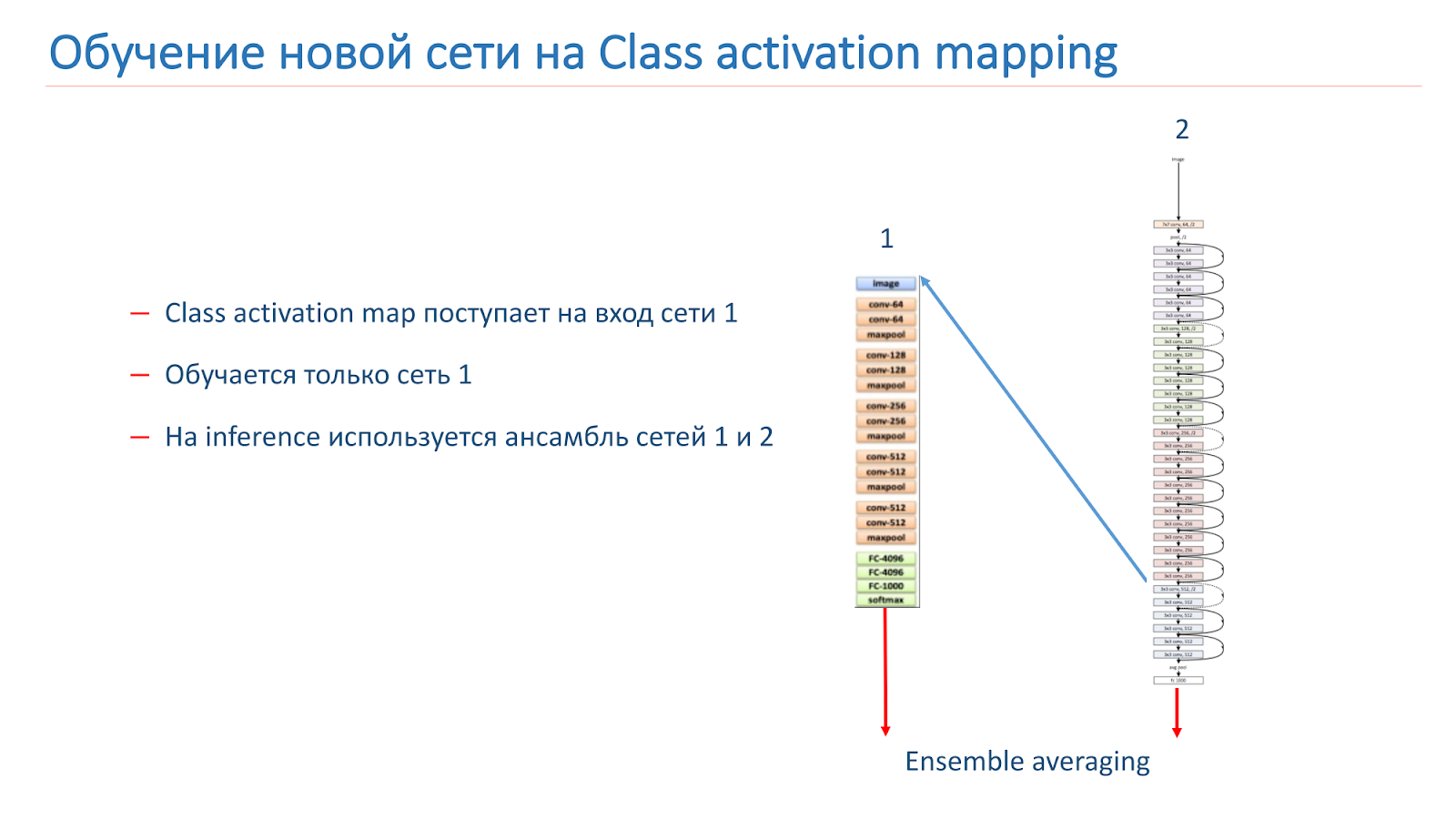
Nós treinamos novamente o nosso modelo no WRN-50-2, pois na rede 1 usamos o ResNet-50 ImageNet, mas não foi possível aumentar de alguma forma significativamente a qualidade do nosso modelo.
Mas continuamos a pesquisar sobre como melhorar nossos resultados: estamos treinando novas arquiteturas da CNN, em particular a família ResNet. Tentamos experimentar o CAM e consideramos várias abordagens com um processamento mais inteligente de patches de imagem - parece-nos que essa abordagem é bastante promissora.
Reconhecimento de Marcos

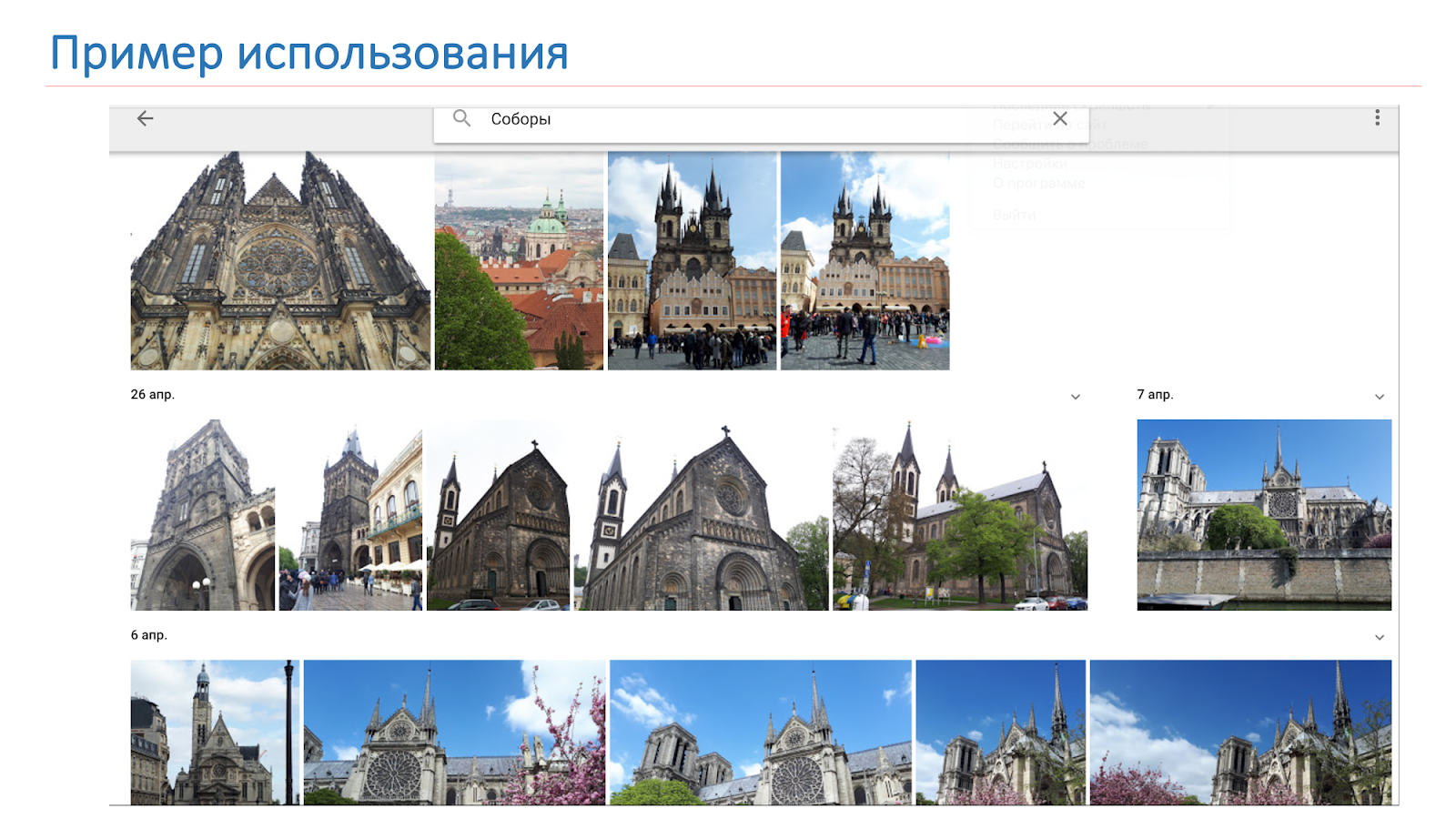
Temos um bom modelo para reconhecer cenas, mas agora queremos descobrir alguns lugares icônicos, ou seja, pontos turísticos. Além disso, os usuários costumam tirar fotos deles ou tirar fotos contra o fundo.
Queremos que o resultado não seja apenas as catedrais, como na imagem do slide, mas o sistema para dizer: "Há Notre Dame de Paris e as catedrais em Praga".
Quando resolvemos esse problema, encontramos algumas dificuldades.
- Praticamente não há estudos sobre esse tópico e não há dados prontos no domínio público.
- Um pequeno número de imagens "limpas" em domínio público para cada atração.
- Não está totalmente claro o que é um marco nos edifícios. Por exemplo, uma casa com torres na praça. Leo Tolstoy, em Petersburgo, o TripAdvisor não considera atrações, mas o Google considera.
Começamos coletando um banco de dados, compilamos uma lista de 100 cidades e usamos a API do Google Places para fazer o download de dados JSON para pontos de interesse dessas cidades.
Os dados foram filtrados e analisados e, de acordo com a lista, baixamos 20 imagens da Pesquisa Google para cada atração. O número 20 é retirado de considerações empíricas. Como resultado, obtivemos uma base de 2827 atrações e cerca de 56 mil imagens. Essa é a base sobre a qual treinamos nosso modelo. Para validar nosso modelo, usamos dois testes.
Teste em nuvem - são imagens de nossos funcionários, rotuladas manualmente. Ele contém 200 fotos em 15 cidades e 10 mil imagens sem atrações. O segundo é o teste de pesquisa. Foi construído usando a pesquisa Mail.ru, que contém de 3 a 10 imagens para cada atração, mas, infelizmente, esse teste está sujo.
Nós treinamos os primeiros modelos, mas eles mostraram resultados ruins no teste Cloud em fotos de combate.
Aqui está um exemplo da imagem em que fomos treinados e um exemplo de fotografia de combate. O problema das pessoas é que elas são frequentemente fotografadas contra o pano de fundo das vistas. Nas imagens que obtivemos da pesquisa, não havia pessoas.
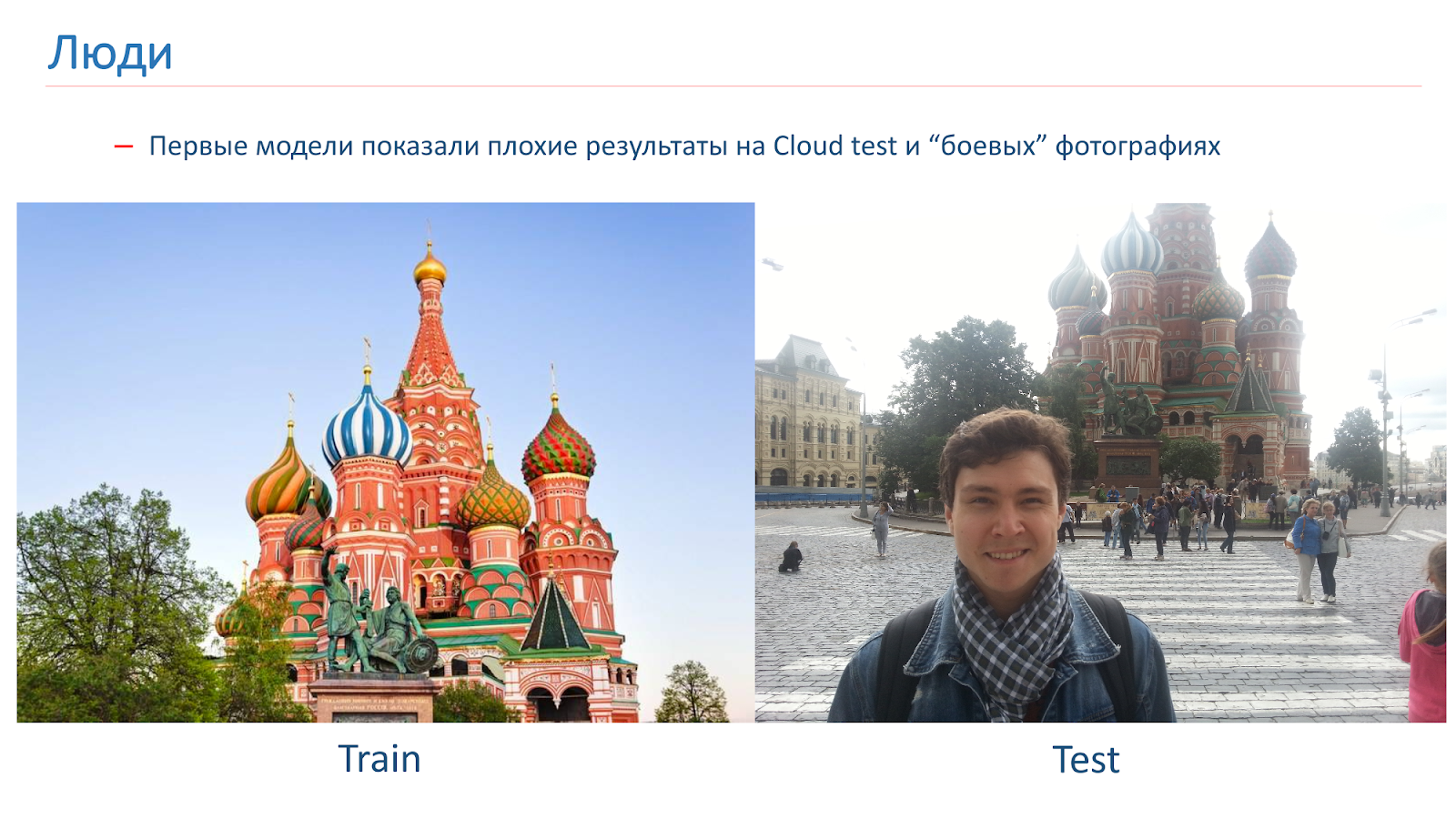
Para combater isso, adicionamos aumento "humano" durante o treinamento. Ou seja, usamos abordagens padrão: rotações aleatórias, corte aleatório de parte da imagem e assim por diante. Mas também no processo de aprendizado, adicionamos pessoas a algumas imagens aleatoriamente.

Essa abordagem nos ajudou a resolver o problema com as pessoas e a obter um modelo de qualidade aceitável.
Modelos de cenas finas
Como treinamos o modelo: existe alguma base de treinamento, mas é bem pequena. Mas sabemos que uma atração turística é um caso especial da cena. E nós temos um bom modelo de cena. Decidimos treiná-la para os pontos turísticos. Para fazer isso, adicionamos várias camadas BN e totalmente conectadas na parte superior da rede, treinamos elas e os três principais blocos residenciais. O restante da rede estava congelado.

Além disso, para treinamento, usamos a função de perda central não padronizada. Durante o treinamento, a perda do Center tenta "separar" representantes de diferentes classes em diferentes grupos, como mostra a figura.

No treinamento, adicionamos outra classe "não é uma atração turística". E a perda de centro não foi aplicada a essa classe. Em uma função de perda mista, foi realizado treinamento.
Depois de treinarmos a rede, cortamos a última camada de classificação e, quando a imagem passa pela rede, ela se transforma em um vetor numérico chamado incorporação.
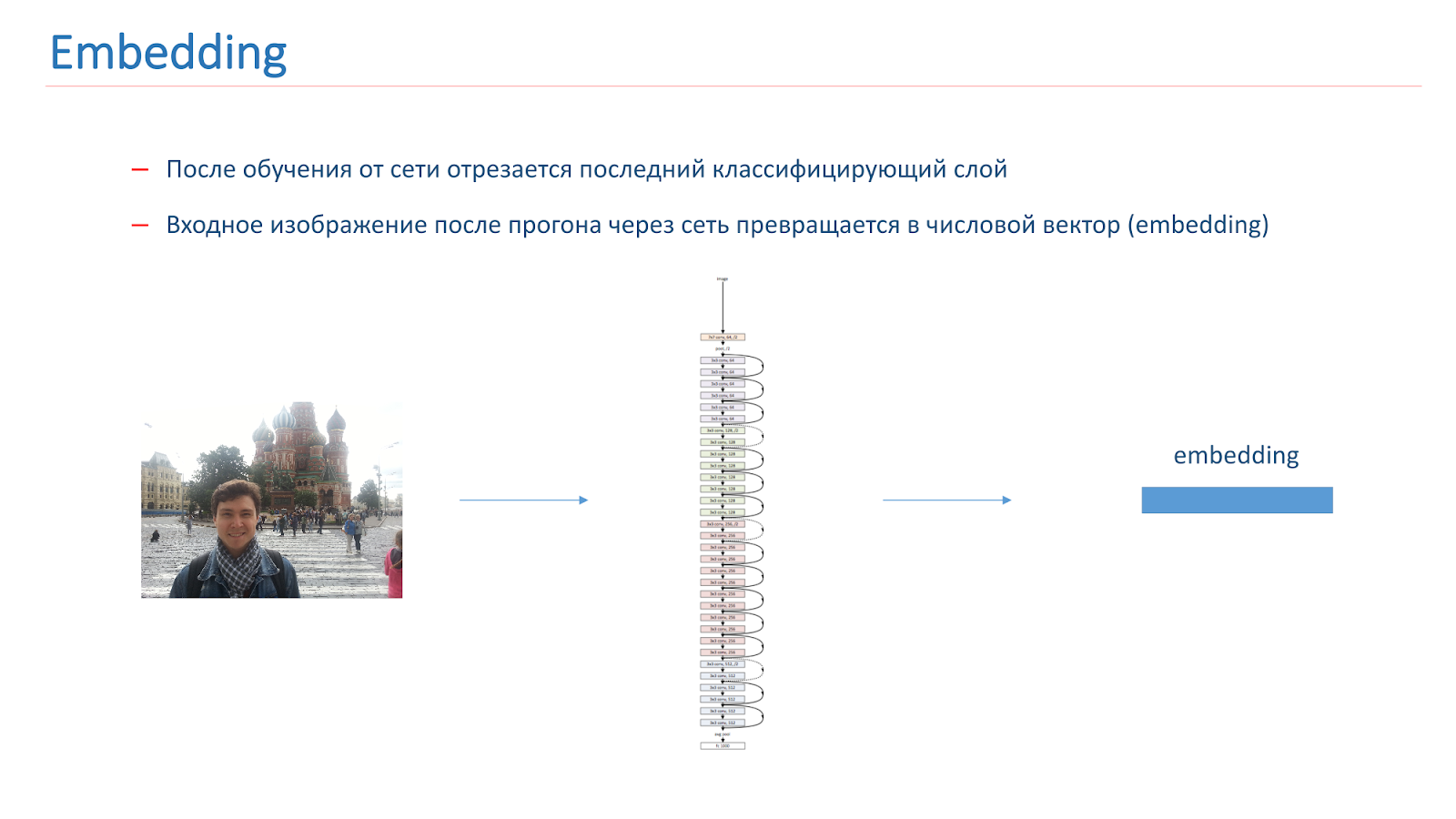
Para construir ainda mais um sistema de reconhecimento de pontos de referência, criamos vetores de referência para cada classe. Pegamos cada classe de atrações da multidão e exibimos as imagens pela rede. Eles se casaram e pegaram o vetor do meio, chamado de vetor de referência da classe.

Para determinar as vistas na foto, executamos a imagem de entrada através da rede e sua incorporação é comparada com o vetor de referência de cada classe. Se o resultado da comparação for menor que o limite, acreditamos que não há ponto de interesse na imagem. Caso contrário, teremos a classe com o maior valor de comparação.
Resultados do teste
- No teste da nuvem, a precisão das imagens foi de 0,616, não das imagens - 0,981
- A precisão média de 0,669 foi obtida no teste de busca e a completude média foi de 0,576.
Na Pesquisa, eles não obtiveram resultados muito bons, mas isso é explicado pelo fato de o primeiro ser bastante "sujo" e o segundo ter características - entre as atrações, existem diferentes jardins botânicos semelhantes em todas as cidades.
Havia uma idéia para o reconhecimento de cena para treinar primeiro a rede, o que determinará a máscara de cena, ou seja, removerá os objetos do primeiro plano e depois o alimentará no próprio modelo, que reconhece cenas de imagem sem essas áreas, onde o fundo é obstruído. Mas não está muito claro o que exatamente precisa ser removido da camada frontal, qual máscara é necessária.
Será algo bastante complicado e inteligente, porque nem todo mundo entende quais objetos pertencem à cena e quais são supérfluos. Por exemplo, pessoas em um restaurante podem ser necessárias. Esta é uma decisão não trivial, tentamos fazer algo semelhante, mas não deu bons resultados.
Aqui está um exemplo de trabalho em fotografias de combate.
Exemplos de trabalhos bem-sucedidos:


Mas o trabalho malsucedido: nenhuma mira foi encontrada. O principal problema do nosso modelo no momento não é que a rede confunda os pontos turísticos, mas que não os encontra na foto.

No futuro, planejamos coletar uma base para um número ainda maior de cidades, encontrar novos métodos para treinar a rede para esta tarefa e determinar as possibilidades de aumentar o número de classes sem treinar novamente a rede.
Conclusões
Hoje nós:
- Vimos quais conjuntos de dados estão disponíveis para reconhecimento de cena;
- Vimos que a Wide Residual Network é o melhor modelo;
- Discutimos outras possibilidades para aumentar a qualidade desse modelo;
- Examinamos a tarefa de reconhecer pontos turísticos, que dificuldades surgem;
- Nós descrevemos o algoritmo para coletar a base e os métodos de ensino do modelo para reconhecer atrações.
Posso dizer que as tarefas são interessantes, mas pouco estudadas na comunidade. É interessante lidar com eles, porque você pode aplicar abordagens não padronizadas que não são aplicadas no reconhecimento usual de objetos.Minuto de publicidade. Se você gostou deste relatório da conferência SmartData, observe que o SmartData 2018 será realizado em São Petersburgo em 15 de outubro, uma conferência para aqueles que estão imersos no mundo do aprendizado de máquina, análise e processamento de dados. O programa terá muitas coisas interessantes, o site já tem seus primeiros oradores e relatórios.