Olá Habr, queremos falar sobre um dos projetos da Escola de Programadores HeadHunter 2018. Abaixo está um artigo de nosso graduado, no qual ele falará sobre a experiência adquirida durante o treinamento.

Olá pessoal. Este ano me formei na hh School of Programmers e neste post vou falar sobre o projeto de treinamento em que participei. Durante o treinamento na escola, e especialmente no projeto, eu não tinha um exemplo de aplicativo de combate (e, melhor ainda, um guia), no qual eu podia ver como separar corretamente a lógica e construir uma arquitetura escalável. Todos os artigos que encontrei foram difíceis de entender para um iniciante, como o IoC foi usado ativamente neles, sem explicações abrangentes sobre como adicionar novos componentes ou modificar os antigos, ou eles eram arcaicos e continham uma tonelada de configurações xml e um front end jsp. Tentei me concentrar no meu nível antes do treino, ou seja, quase zero com algumas ressalvas, portanto, este artigo deve ser útil para futuros alunos da escola, bem como entusiastas autodidatas que decidiram começar a escrever em java.
Dado (declaração do problema)
Equipe - 5 pessoas. O prazo é de 3 meses, no final de cada uma há uma demonstração. O objetivo é criar um aplicativo que ajude o RH a acompanhar os funcionários em um período de teste, automatizando todos os processos que resultam. Na entrada, fomos informados sobre como o período de estágio está organizado: assim que se torna conhecido que um novo funcionário está saindo, o RH começa a chutar o futuro líder para definir tarefas para o PI, e isso precisa ser feito antes do primeiro dia útil. No dia em que o funcionário vai trabalhar, o RH realiza uma reunião de boas-vindas, fala sobre a infraestrutura da empresa e entrega tarefas para IP. Após 1,5 e 3 meses, é realizada uma reunião intermediária e final de RH, líder e funcionário, na qual é discutido o sucesso da passagem e elaborado um formulário de resultados. Se for bem-sucedido, após a reunião final, o funcionário recebe um questionário impresso para um novato (perguntas no estilo de "desfrute do prazer da PI") e recebe uma tarefa de RH para Jira emitir ao funcionário da VHI.
Desenho
Decidimos criar para cada funcionário uma página pessoal na qual as informações gerais serão exibidas (nome, departamento, gerente etc.), um campo para comentários e histórico de alterações, arquivos anexados (tarefas no IP, questionário) e fluxo de trabalho dos funcionários, refletindo nível de passagem do IP. Decidiu-se que o fluxo de trabalho fosse dividido em 8 etapas, a saber:
- Etapa 1 - adição de um funcionário: ele é concluído imediatamente após o registro de um novo funcionário no sistema de RH. Ao mesmo tempo, três calendários são enviados ao RH para um poço, uma reunião intermediária e final.
- 2ª etapa - coordenação das tarefas no IP: um formulário é enviado ao chefe para definir as tarefas no IP, que o RH receberá após o preenchimento. Em seguida, o RH os imprime, assina e marca a conclusão do estágio na interface.
- 3ª etapa - reunião de boas-vindas: o RH realiza uma reunião e pressiona o botão “Etapa concluída”.
- 4ª etapa - reunião provisória: semelhante à terceira etapa
- A 5ª etapa - os resultados de uma reunião provisória: o RH preenche os resultados na página do funcionário e clica em "Avançar".
- 6ª etapa - reunião final: semelhante à terceira etapa
- 7ª etapa - resultados da reunião final: semelhante à quinta etapa
- 8ª etapa - preenchimento do PI: no caso de preenchimento bem-sucedido do PI, o funcionário receberá um link com o formulário do questionário por e-mail e, em jira, será automaticamente criada uma tarefa de registro de seguro médico voluntário (conseguimos a tarefa manualmente).
Todas as etapas têm tempo, após o qual a etapa é considerada expirada e é destacada em vermelho e uma notificação chega pelo correio. O horário de término deve ser editável, por exemplo, caso a reunião provisória caia em um feriado ou por algum motivo a reunião precise ser remarcada.
Infelizmente, os protótipos desenhados em um pedaço de papel / cartão não foram preservados, mas no final haverá capturas de tela do aplicativo finalizado.
Operação
Um dos objetivos da escola é preparar os alunos para o trabalho em grandes projetos, para que o processo de liberação de tarefas seja apropriado para nós.
No final do trabalho, solicitamos a revisão_1 para outro aluno da equipe para corrigir erros óbvios / trocar experiências. Depois vem a review_2 - a tarefa é verificada por dois mentores que garantem que não liberemos o govnokod em par com o revisor_1. Testes adicionais deveriam, mas esse estágio não é muito apropriado, dada a escala do projeto da escola. Então, depois de passar pela revisão, pensamos que a tarefa estava pronta para lançamento.
Agora, algumas palavras sobre a implantação. O aplicativo deve estar disponível o tempo todo na rede em qualquer computador. Para fazer isso, compramos uma máquina virtual barata (por 100 rublos / mês), mas, como descobri mais tarde, tudo pode ser organizado de forma gratuita e elegante na janela de encaixe da AWS . Para integração contínua, escolhemos Travis. Se alguém não souber (eu pessoalmente nunca ouvi falar sobre integração contínua antes da escola), isso é uma coisa tão legal que o seu github irá monitorar e quando um novo commit aparecer (como configurar) coletar o código no jar, enviá-lo ao servidor e reiniciar o aplicativo automaticamente. Como construí-lo é descrito no Travis Jam na raiz do projeto, é bem parecido com o bash, então acho que nenhum comentário é necessário. Também compramos o domínio www.adaptation.host para não registrar um endereço IP feio na barra de endereços da demonstração. Também configuramos o postfix (para envio de email), o apache (não o nginx, porque o apache estava fora da caixa) e o servidor jira (trial). O front-end e o back-end foram criados por dois serviços separados que se comunicarão via http (# 2k18, # microservices). Esta parte do artigo “na HeadHunter School of Programmers” termina sem problemas e passamos ao serviço de descanso java.
Backend
0. Introdução
Usamos as seguintes tecnologias:
- JDK 1.8;
- Maven 3.5.2;
- Postgres 9.6;
- Hibernate 5.2.10;
- Jetty 9.4.8;
- Jersey 2.27.
Como estrutura, utilizamos o NaB 3.5.0 da hh. Primeiro, ele é usado no HeadHunter e, em segundo lugar, contém postgres de jetty, jersey, hibernate e incorporados prontos para uso, escritos no github. Vou esclarecer brevemente para iniciantes: jetty é um servidor da web que identifica clientes e organiza sessões para cada um deles; jersey - uma estrutura que ajuda a criar convenientemente um serviço RESTful; hibernate - ORM para simplificar o trabalho com o banco de dados; maven é um colecionador de projetos java.
Vou mostrar um exemplo simples de como trabalhar com isso. Criei um pequeno repositório de teste , no qual adicionei duas entidades: um usuário e um currículo, além de recursos para criar e recebê-los com o link OneToMany / ManyToOne. Para começar, basta clonar o repositório e executar mvn clean install exec: java na raiz do projeto. Antes de comentar o código, falarei sobre a estrutura de nosso serviço. Parece algo como isto:
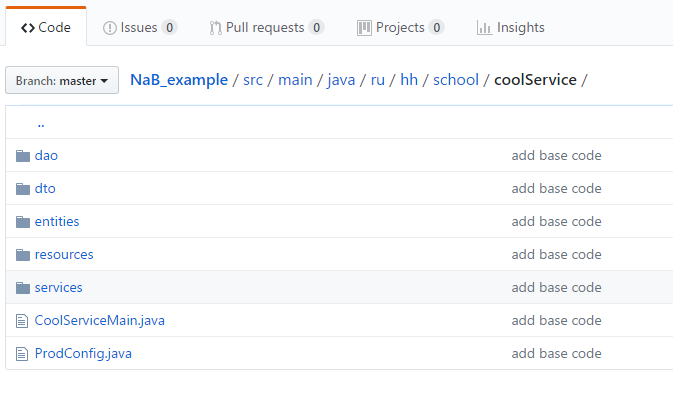
Diretórios principais:
- Serviços - o diretório principal do aplicativo, toda a lógica de negócios é armazenada aqui. Em outros lugares, trabalhar com dados sem uma boa razão não deveria ser.
- Recursos - manipuladores de URL, uma camada entre os serviços e o front-end. A validação dos dados recebidos e a conversão dos dados enviados, mas não a lógica comercial, são permitidas aqui.
- Dao (Data Access Object) - uma camada entre o banco de dados e os serviços. O Tao deve conter apenas operações básicas fundamentais: adicionar, contar, atualizar, excluir uma / todas.
- Entidade - objetos que o ORM troca com o banco de dados. Como regra, eles correspondem diretamente às tabelas e devem conter todos os campos como a entidade no banco de dados com os tipos correspondentes.
- Dto (Data Transfer Object) - um análogo da entidade, apenas para recursos (frente), ajuda a formar json a partir dos dados que queremos enviar / receber.
1. Base
De uma maneira boa, você deve usar o postgres instalado nas proximidades, como no aplicativo principal, mas eu queria que o caso de teste fosse simples e fosse executado com um único comando, então usei o HSQLDB interno. A conexão do banco de dados à nossa infraestrutura é feita adicionando um DataSource ao ProdConfig (lembre-se de informar ao hibernar qual banco de dados você está usando):
@Bean(destroyMethod = "shutdown") DataSource dataSource() { return new EmbeddedDatabaseBuilder() .setType(EmbeddedDatabaseType.HSQL) .addScript("db/sql/create-db.sql") .build(); }
Eu criei o script de criação da tabela no arquivo create-db.sql. Você pode adicionar outros scripts que inicializam o banco de dados. Em nosso exemplo leve de in_memory, poderíamos ficar sem scripts. Se você especificar hibernate.hbm2ddl.auto=create nas configurações hibernate.properties, o próprio hibernate criará tabelas por entidade quando o aplicativo for iniciado. Mas se você precisa ter algo no banco de dados que a entidade não possui, não poderá ficar sem um arquivo. Pessoalmente, estou acostumado a compartilhar o banco de dados e o aplicativo, por isso geralmente não confio na hibernação para fazer essas coisas.
db/sql/create-db.sql :
CREATE TABLE employee ( id INTEGER IDENTITY PRIMARY KEY, first_name VARCHAR(256) NOT NULL, last_name VARCHAR(256) NOT NULL, email VARCHAR(128) NOT NULL ); CREATE TABLE resume ( id INTEGER IDENTITY PRIMARY KEY, employee_id INTEGER NOT NULL, position VARCHAR(128) NOT NULL, about VARCHAR(256) NOT NULL, FOREIGN KEY (employee_id) REFERENCES employee(id) );
2. Entidade
entities/employee :
@Entity @Table(name = "employee") public class Employee { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) @Column(name = "id", nullable = false) private Integer id; @Column(name = "first_name", nullable = false) private String firstName; @Column(name = "last_name", nullable = false) private String lastName; @Column(name = "email", nullable = false) private String email; @OneToMany(mappedBy = "employee") @OrderBy("id") private List<Resume> resumes;
entities/resume :
@Entity @Table(name = "resume") public class Resume { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Integer id; @ManyToOne(fetch = FetchType.LAZY) @JoinColumn(name = "employee_id") private Employee employee; @Column(name = "position", nullable = false) private String position; @Column(name = "about") private String about;
As entidades não se referem umas às outras com o campo da classe, mas com todo o objeto pai / filho. Assim, podemos obter recursão quando tentamos extrair do banco de dados de Funcionários, para o qual são desenhados currículos, para os quais ... Para impedir que isso aconteça, indicamos as anotações @OneToMany(mappedBy = "employee") e @ManyToOne(fetch = FetchType.LAZY) . Eles serão levados em consideração no serviço ao executar uma transação de gravação / leitura a partir do banco de dados. A configuração do FetchType.LAZY é opcional, mas o uso de comunicação lenta facilita a transação. Portanto, se em uma transação obtivermos um resumo do banco de dados e não entrarmos em contato com o proprietário, a entidade do funcionário não será carregada. Você pode verificar isso sozinho: remova o FetchType.LAZY e veja na depuração que ele retorna do serviço junto com o resumo. Mas você deve ter cuidado - se não carregarmos funcionário na transação, o acesso aos campos de funcionários fora da transação poderá causar uma LazyInitializationException .
3. Dao
No nosso caso, EmployeeDao e ResumeDao são quase idênticos, então darei aqui apenas um deles
EmployeeDao :
public class EmployeeDao { private final SessionFactory sessionFactory; @Inject public EmployeeDao(SessionFactory sessionFactory) { this.sessionFactory = sessionFactory; } public void save(Employee employee) { sessionFactory.getCurrentSession().save(employee); } public Employee getById(Integer id) { return sessionFactory.getCurrentSession().get(Employee.class, id); } }
A @Inject significa que, no construtor de nosso dao, a Injeção de Dependência é usada. Na minha vida passada, um físico que parcelou arquivos, construiu gráficos com base nos resultados de números e, no mínimo, descobriu OOP, nos guias java, essas construções pareciam um tanto insanas. E na escola, talvez, este tópico seja o IMHO mais óbvio. Felizmente, há muito material sobre DI na Internet. Se você está com preguiça de ler, no primeiro mês você pode seguir a regra: registre novos recursos / serviços / Tao em nossa context-config , adicione entidades ao mapeamento . Se você precisar usar alguns serviços / outros em outros, precisará adicioná-los no construtor com a injeção de anotação, como mostrado acima, e o spring inicializará tudo para você. Mas então você ainda tem que lidar com o DI.
4. Dto
Dto, como dao, é quase idêntico para funcionário e currículo. Consideramos apenas employeeDto aqui. Vamos precisar de duas classes: EmployeeCreateDto , necessário ao criar um funcionário; EmployeeDto usado no recebimento (contém campos adicionais id e resumes ). O campo id é adicionado para que, no futuro, mediante solicitações externas, possamos trabalhar com o funcionário sem realizar uma pesquisa preliminar da entidade por email . O campo de resumes para receber um funcionário, juntamente com todos os seus currículos em uma solicitação. Seria possível gerenciar com um dto para todas as operações, mas, para a lista de todos os currículos de um funcionário específico, teríamos que criar um recurso adicional, como getResumesByEmployeeEmail, poluir o código com consultas personalizadas ao banco de dados e atravessar todas as comodidades fornecidas pelo ORM.
EmployeeCreateDto :
public class EmployeeCreateDto { public String firstName; public String lastName; public String email; }
EmployeeDto :
public class EmployeeDto { public Integer id; public String firstName; public String lastName; public String email; public List<ResumeDto> resumes; public EmployeeDto(){ } public EmployeeDto(Employee employee){ id = employee.getId(); firstName = employee.getFirstName(); lastName = employee.getLastName(); email = employee.getEmail(); if (employee.getResumes() != null) { resumes = employee.getResumes().stream().map(ResumeDto::new).collect(Collectors.toList()); } } }
Mais uma vez, chamo a atenção para o fato de que escrever lógica no dto é tão indecente que todos os campos são designados como public , para não usar getters e setters.
5. Serviço
EmployeeService :
public class EmployeeService { private EmployeeDao employeeDao; private ResumeDao resumeDao; @Inject public EmployeeService(EmployeeDao employeeDao, ResumeDao resumeDao) { this.employeeDao = employeeDao; this.resumeDao = resumeDao; } @Transactional public EmployeeDto createEmployee(EmployeeCreateDto employeeCreateDto) { Employee employee = new Employee(); employee.setFirstName(employeeCreateDto.firstName); employee.setLastName(employeeCreateDto.lastName); employee.setEmail(employeeCreateDto.email); employeeDao.save(employee); return new EmployeeDto(employee); } @Transactional public ResumeDto createResume(ResumeCreateDto resumeCreateDto) { Resume resume = new Resume(); resume.setEmployee(employeeDao.getById(resumeCreateDto.employeeId)); resume.setPosition(resumeCreateDto.position); resume.setAbout(resumeCreateDto.about); resumeDao.save(resume); return new ResumeDto(resume); } @Transactional(readOnly = true) public EmployeeDto getEmployeeById(Integer id) { return new EmployeeDto(employeeDao.getById(id)); } @Transactional(readOnly = true) public ResumeDto getResumeById(Integer id) { return new ResumeDto(resumeDao.getById(id)); } }
Essas transações que nos protegem de LazyInitializationException (e não apenas). Para entender as transações no hibernate, recomendo um excelente trabalho no hub ( leia mais ... ), o que me ajudou muito no devido tempo.
6. Recursos
Por fim, adicione os recursos para criar e obter nossas entidades:
EmployeeResource
@Path("/") @Singleton public class EmployeeResource { private final EmployeeService employeeService; public EmployeeResource(EmployeeService employeeService) { this.employeeService = employeeService; } @GET @Produces("application/json") @Path("/employee/{id}") @ResponseBody public Response getEmployee(@PathParam("id") Integer id) { return Response.status(Response.Status.OK) .entity(employeeService.getEmployeeById(id)) .build(); } @POST @Produces("application/json") @Path("/employee/create") @ResponseBody public Response createEmployee(@RequestBody EmployeeCreateDto employeeCreateDto){ return Response.status(Response.Status.OK) .entity(employeeService.createEmployee(employeeCreateDto)) .build(); } @GET @Produces("application/json") @Path("/resume/{id}") @ResponseBody public Response getResume(@PathParam("id") Integer id) { return Response.status(Response.Status.OK) .entity(employeeService.getResumeById(id)) .build(); } @POST @Produces("application/json") @Path("/resume/create") @ResponseBody public Response createResume(@RequestBody ResumeCreateDto resumeCreateDto){ return Response.status(Response.Status.OK) .entity(employeeService.createResume(resumeCreateDto)) .build(); } }
Produces(“application/json”) necessário para que json e dto sejam corretamente convertidos um no outro. Requer uma dependência pom.xml:
<dependency> <groupId>org.glassfish.jersey.media</groupId> <artifactId>jersey-media-json-jackson</artifactId> <version>${jersey.version}</version> </dependency>
Outros json-conversores, por algum motivo, expõem um MediaType inválido.
7. Resultado
Execute e verifique o que temos ( mvn clean install exec:java na raiz do projeto). A porta na qual o aplicativo é executado é especificada em service.properties . Crie um usuário e currículo. Faço isso com curl, mas você pode usar o carteiro se desprezar o console.
curl --header "Content-Type: application/json" \ --request POST \ --data '{"firstName": "Jason", "lastName": "Statham", "email": "jasonst@t.ham"}' \ http://localhost:9999/employee/create curl --header "Content-Type: application/json" \ --request POST \ --data '{"employeeId": 0, "position": "Voditel", "about": "Opyt raboty perevozchikom 15 let"}' \ http://localhost:9999/resume/create curl --header "Content-Type: application/json" --request GET http://localhost:9999/employee/0 curl --header "Content-Type: application/json" --request GET http://localhost:9999/employee/0
Tudo funciona bem. Então, nós temos um back-end que fornece API. Agora você pode iniciar o serviço com o frontend e desenhar os formulários correspondentes. Essa é uma boa base para um aplicativo que você pode usar para iniciar seu próprio, configurando vários componentes à medida que o projeto se desenvolve.
Conclusão
O código principal do aplicativo é mantido em ordem de funcionamento no github com instruções para iniciar na guia wiki.
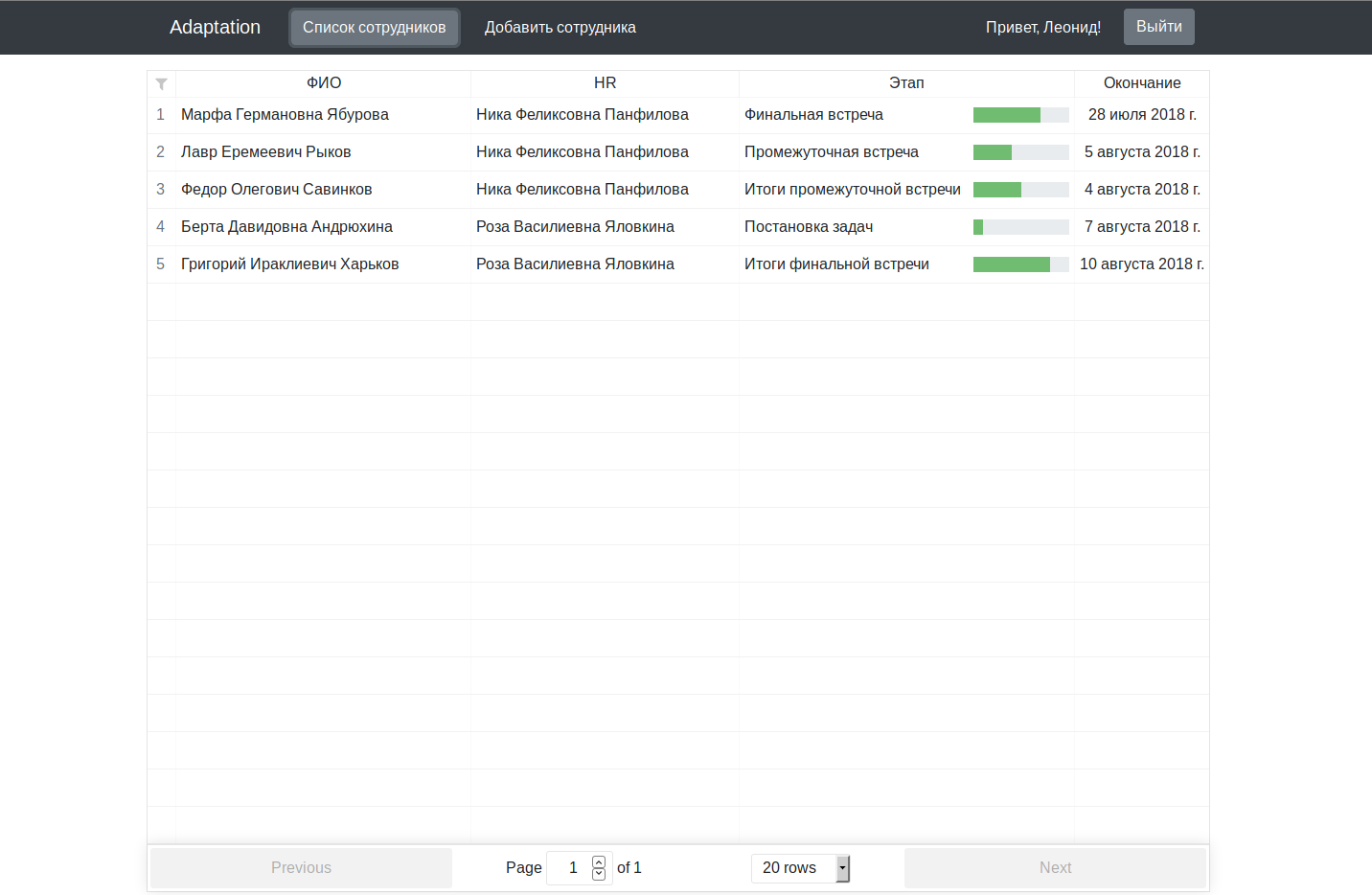
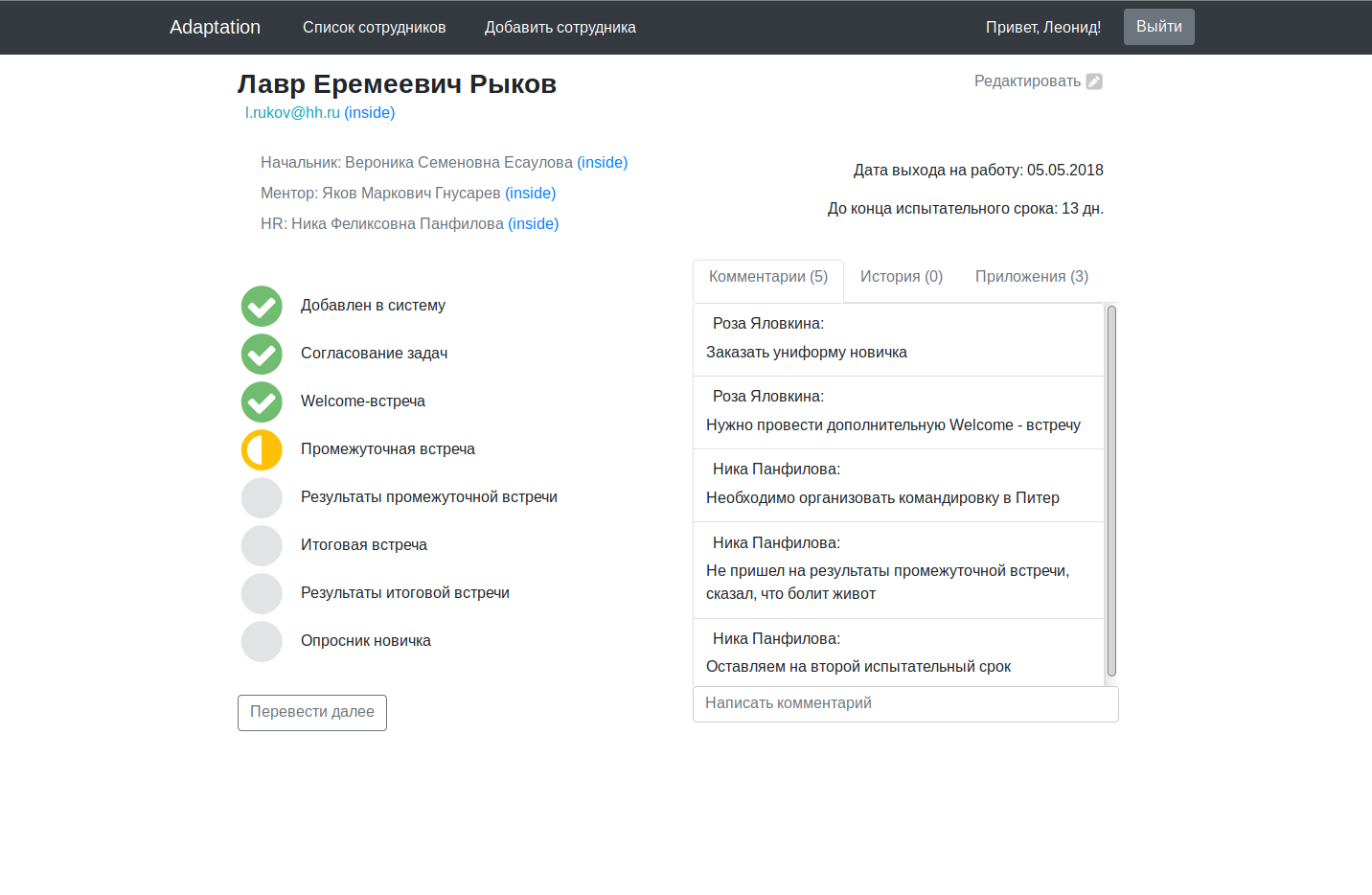
Para um projeto multimilionário, parece um pouco úmido, é claro, mas como uma desculpa, lembro que trabalhamos à noite, depois do trabalho / estudo.
Se o número de pessoas interessadas exceder o número de chinelos, no futuro eu posso transformar isso em uma série de artigos em que falarei sobre frente, dockerização e as nuances que encontramos ao trabalhar com arquivos de correio / gordura / dock.
PS Depois de algum tempo sobrevivendo ao choque da escola, o restante da equipe se reuniu e, após analisar os vôos, decidiu fazer a adaptação 2.0, levando em consideração todos os erros. O principal objetivo do projeto é o mesmo - aprender a criar aplicativos sérios, construir uma arquitetura bem pensada e ser procurado por especialistas do mercado. Você pode seguir o trabalho no mesmo repositório. Pedidos de piscina são bem-vindos. Obrigado por sua atenção e nos deseje boa sorte!
pães
palestra em vídeo hoc ioc