Há algum tempo, apareceu no meu feed do Facebook um link para o livro Machine Learning Yearning de Andrew Ng, que pode ser traduzido como paixão pelo aprendizado de máquina ou sede de aprendizado de máquina.

Pessoas interessadas em aprendizado de máquina ou trabalhando nesta área não precisam apresentar Andrew. Para os não iniciados, basta dizer que ele é uma estrela de classe mundial no campo da inteligência artificial. Cientista, engenheiro, empresário, um dos fundadores da Coursera . Ele é o autor de uma excelente introdução ao aprendizado de máquina e aos cursos que compõem a especialização Deep Learning .
Eu tenho um profundo respeito por Andrew, fiz seus cursos, então decidi imediatamente ler o livro publicado. Verificou-se que o livro ainda não foi escrito e é publicado em partes, como é escrito pelo autor. Em geral, este não é nem um livro, mas um rascunho de um livro futuro (se será publicado em papel é desconhecido). Então surgiu a idéia de traduzir os capítulos que estavam sendo publicados. Atualmente traduzido 14 capítulos (este é o primeiro trecho publicado do livro). Eu pretendo continuar este trabalho e traduzir o livro inteiro. Vou publicar capítulos traduzidos no meu blog sobre Habré.
No momento em que escrevi essas linhas, o autor publicou 52 capítulos dos 56 concebidos (uma notificação de prontidão de 52 capítulos chegou ao meu correio em 4 de julho). Todos os capítulos disponíveis no momento podem ser baixados aqui ou encontrados na Internet.
Antes de publicar minha tradução, procurei outras traduções, encontrei esta, também publicada no Habré. É verdade que apenas os sete primeiros capítulos foram traduzidos. Não posso julgar cuja tradução é melhor. Nem eu nem IliaSafonov (como me sinto na leitura) somos tradutores profissionais. Eu gosto mais de algumas partes, Ilya algumas. No prefácio de Ilya, você pode ler detalhes interessantes sobre o livro, que eu omito.
Como publico minha tradução sem revisão, “do forno”, pretendo voltar a alguns lugares e corrigi-la (isso se aplica especialmente à confusão com conjuntos de dados train / dev / test). Ficaria muito grato se os comentários fossem dados sobre o estilo, erros, etc., bem como informativos sobre o texto do autor.
Todas as imagens são originais (de Andrew Eun), sem elas o livro seria mais chato.
Então, para o livro:
Capítulo 1. Por que precisamos de uma estratégia de aprendizado de máquina?
O aprendizado de máquina está no centro de inúmeras aplicações importantes, incluindo pesquisa na web, antispam de e-mail, reconhecimento de fala, recomendações de produtos e outros. Presumo que você ou sua equipe estejam trabalhando em aplicativos de aprendizado de máquina. E que você deseja acelerar seu progresso neste trabalho. Este livro irá ajudá-lo a fazer isso.
Exemplo: Criando uma Inicialização de Reconhecimento de Imagem Felina
Suponha que você esteja trabalhando em uma startup que processe um fluxo interminável de fotos de gatos para os amantes de gatos.

Você usa uma rede neural para construir um sistema de visão por computador para reconhecer gatos em fotografias.
Infelizmente, porém, a qualidade do seu algoritmo de aprendizado ainda não é boa o suficiente e a enorme pressão sobre você é melhorar o seu detector de gatos.
O que fazer
Sua equipe tem muitas idéias, como:
- Obtenha mais dados: colete mais fotos de gatos.
- Colete um conjunto de dados mais heterogêneo. Por exemplo, fotografias de gatos em posições incomuns; fotos de gatos com coloração incomum; fotos com várias configurações da câmera; ...
- Treine o algoritmo por mais tempo aumentando o número de iterações da descida do gradiente
- Tente aumentar a rede neural, com muitas camadas / neurônios / parâmetros ocultos.
- Tente reduzir a rede neural.
- Tente adicionar regularização (como regularização L2)
- Alterar a arquitetura da rede neural (função de ativação, número de neurônios ocultos etc.)
- ...
Se você escolher com sucesso entre essas possíveis direções, criará uma plataforma líder de processamento de imagens para gatos e conduzirá sua empresa ao sucesso. Se sua escolha não der certo, você poderá perder meses de trabalho em vão.
O que fazer?
Este livro lhe dirá como.
A maioria das tarefas de aprendizado de máquina tem dicas que podem lhe dizer o que seria útil tentar e o que é inútil tentar. Se você aprender a ler essas dicas, poderá economizar meses e anos de desenvolvimento.
2. Como usar este livro para ajudar sua equipe a trabalhar
Depois de terminar de ler este livro, você terá um profundo entendimento de como escolher a direção técnica para o projeto de aprendizado de máquina.
Mas pode não estar claro para seus colegas de equipe por que você recomenda uma certa direção. Talvez você queira que sua equipe use uma métrica de um parâmetro para avaliar a qualidade do algoritmo, mas os colegas não têm certeza de que essa é uma boa idéia. Como você os convence?
Foi por isso que abreviei os capítulos: para que você possa imprimi-los e fornecer a seus colegas uma ou duas páginas contendo material com o qual você precisa familiarizar a equipe.
Pequenas mudanças na priorização podem ter um efeito enorme na produtividade da sua equipe. Ajudando com essas pequenas mudanças, espero que você possa se tornar o super-herói do seu time!

3. Antecedentes e observações
Se você concluiu um curso de aprendizado de máquina, como o meu curso de aprendizado de máquina MOOC na Coursera, ou se você tem experiência em ensinar algoritmos com um professor, não será difícil para você entender este texto.
Suponho que você esteja familiarizado com “treinamento de professores”: aprendendo uma função que vincula x a y usando exemplos de treinamento rotulados (x, y). Os algoritmos de aprendizado com um professor incluem regressão linear, regressão logística, redes neurais e outros. Hoje, existem muitas formas e abordagens para o aprendizado de máquina, mas a maioria das abordagens de importância prática é derivada dos algoritmos da classe "aprendendo com um professor".
Costumo me referir a redes neurais (a "aprendizado profundo"). Você precisa apenas de idéias básicas sobre o que elas são para entender este texto.
Se você não estiver familiarizado com os conceitos mencionados aqui, assista ao vídeo das três primeiras semanas do curso Machine Learning em Coursera http://ml-class.org/
4. A barra de progresso no aprendizado de máquina
Muitas idéias para a aprendizagem profunda (redes neurais) existem há décadas. Por que essas idéias surgiram hoje?
Os dois maiores impulsionadores do progresso recente são:
- Disponibilidade de dados Hoje, as pessoas passam muito tempo com dispositivos de computação (laptops, dispositivos móveis). Sua atividade digital gera enormes quantidades de dados que podemos alimentar com nossos algoritmos de aprendizado.
- Poder de computação Apenas alguns anos atrás, tornou-se possível treinar redes neurais de tamanho suficientemente grande, permitindo obter os benefícios do uso dos enormes conjuntos de dados que tínhamos.
Vou esclarecer, mesmo que você acumule muitos dados, geralmente a curva de crescimento da precisão dos algoritmos antigos de aprendizado, como a regressão logística, é "plana". Isso implica que a curva de aprendizado é "achatada" e a qualidade da previsão do algoritmo para de crescer, apesar de você fornecer mais dados para treinamento.
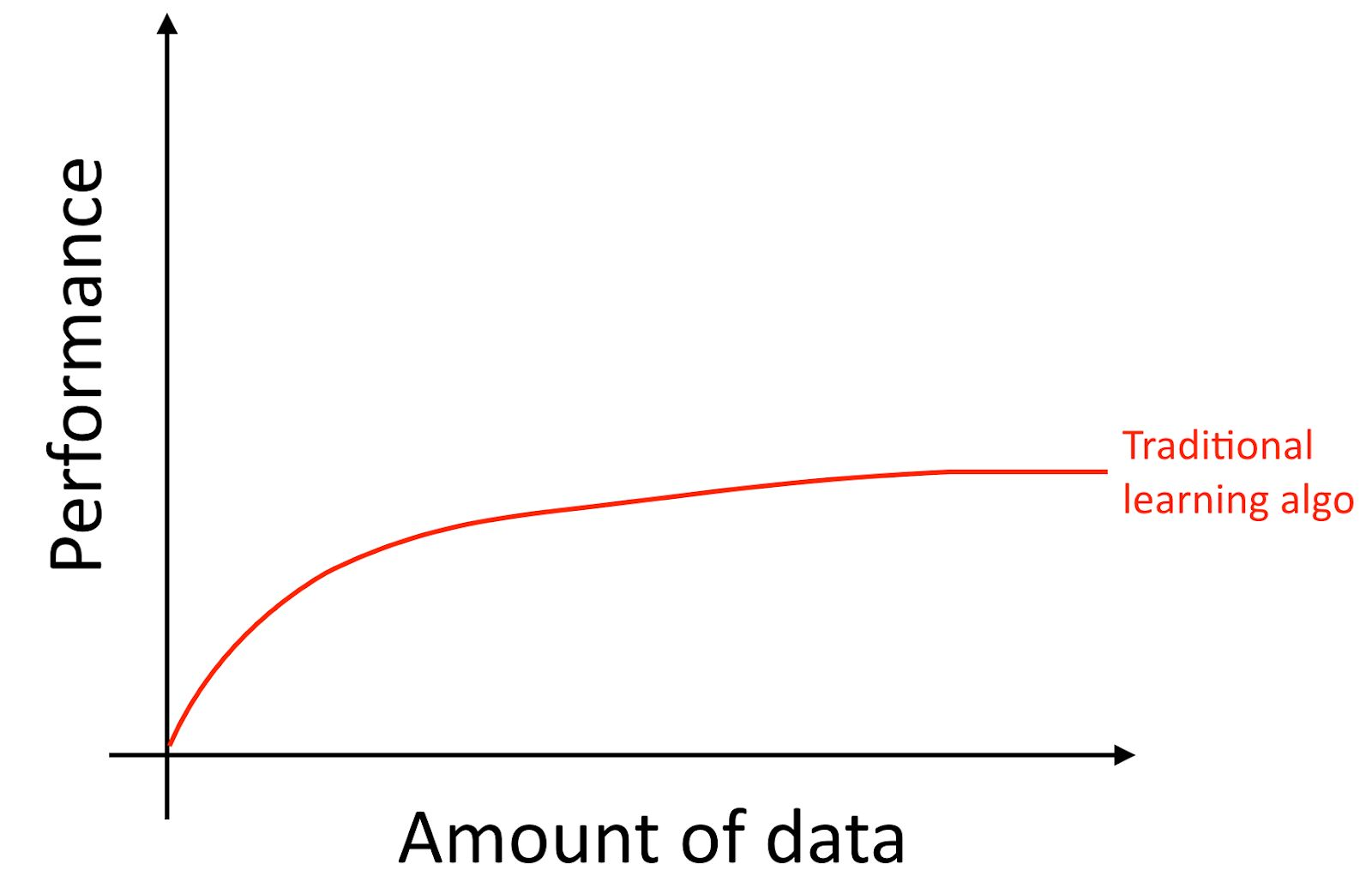
Parece que os algoritmos antigos não sabem o que fazer com todos esses dados que agora estão à nossa disposição.
Se você treinar uma pequena rede neural (NN) para a mesma tarefa "aprender com um professor", poderá obter um resultado um pouco melhor do que os "algoritmos antigos".
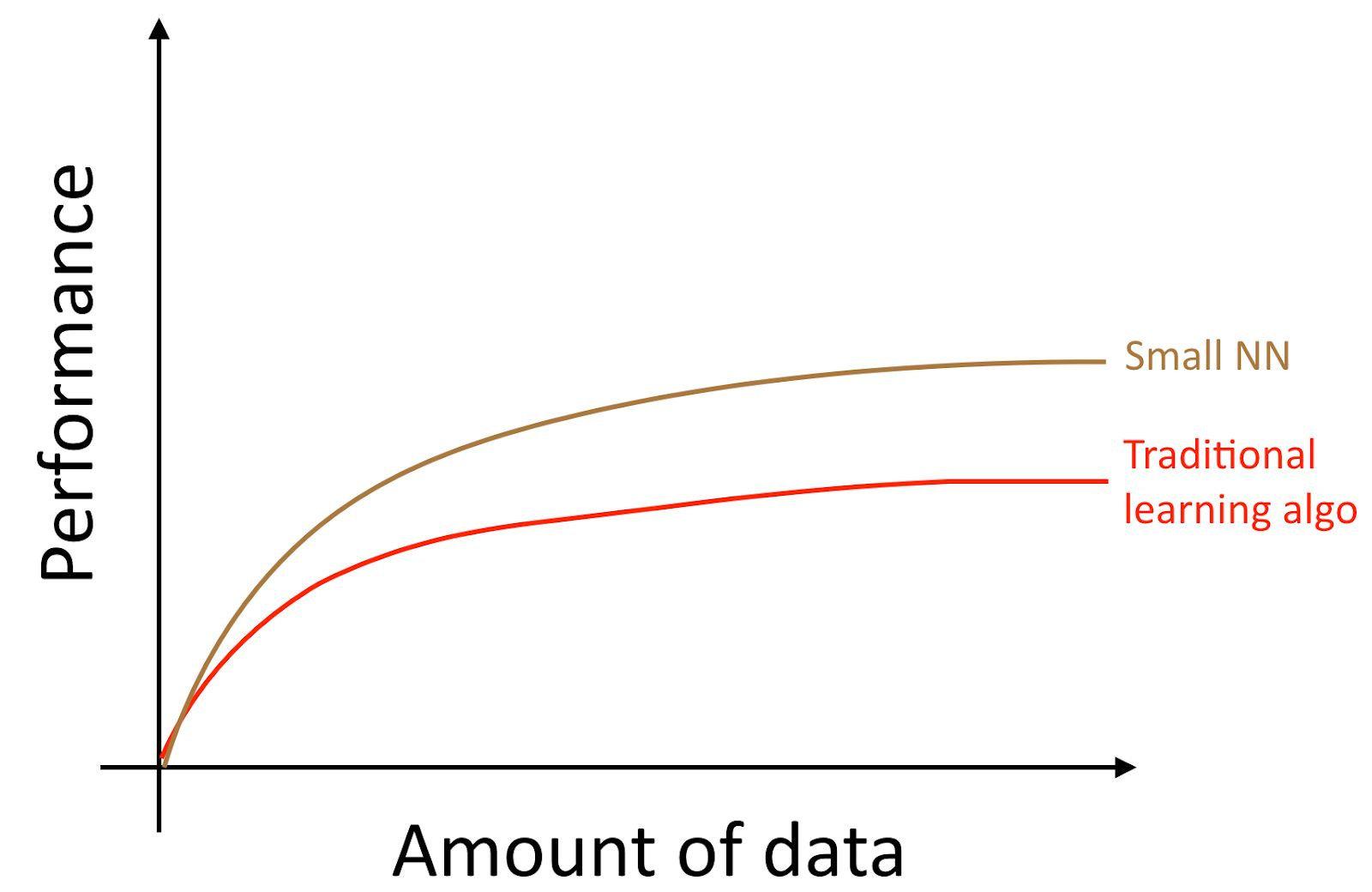
Aqui, por "NN pequeno" queremos dizer uma rede neural com um pequeno número de neurônios / camadas / parâmetros ocultos. Finalmente, se você começar a treinar redes neurais cada vez maiores, poderá obter uma qualidade cada vez maior.
Nota do autor : Este diagrama mostra que as redes neurais têm melhor desempenho no modo de conjunto de dados pequeno. Esse efeito é menos estável do que o efeito de redes neurais que funcionam bem no modo de conjunto de dados enorme. No modo de dados pequenos, dependendo de como os recursos foram processados (dependendo da qualidade da engenharia dos recursos), os algoritmos tradicionais podem funcionar melhor e pior do que as redes neurais. Por exemplo, se você tem 20 exemplos de treinamento, não importa realmente se você usa regressão logística ou uma rede neural; A preparação de recursos tem um efeito maior que a escolha do algoritmo. No entanto, se você tiver 1 milhão de exemplos de treinamento, eu preferiria uma rede neural.

Assim, você obtém a melhor qualidade do algoritmo quando (i) treina uma rede neural muito grande; nesse caso, você está na curva verde na figura acima; (ii) você tem uma enorme quantidade de dados à sua disposição.
Muitos outros detalhes, como a arquitetura de rede neural, também são importantes, e muitas soluções inovadoras foram criadas nessa área. Mas a maneira mais confiável de melhorar a qualidade do algoritmo hoje ainda é (i) aumentando o tamanho da rede neural treinada (ii) obtendo mais dados para treinamento.
O processo de cumprimento conjunto das condições (i) e (ii) na prática é surpreendentemente complexo. Este livro discutirá em detalhes seus detalhes. Começamos com estratégias gerais igualmente úteis para algoritmos tradicionais e redes neurais e, em seguida, estudamos as estratégias mais modernas usadas no design e desenvolvimento de sistemas de aprendizado profundo.
5. Criando amostras para algoritmos de treinamento e teste
Vamos voltar ao nosso exemplo de foto de gato acima: Você lançou um aplicativo móvel e os usuários enviam um grande número de fotos diferentes para o seu aplicativo. Você deseja encontrar automaticamente fotos de gatos.
Sua equipe recebe um grande conjunto de treinamentos baixando fotos de gatos (exemplos positivos) e fotos nas quais não há gatos (exemplos negativos) de vários sites. Eles dividiram o conjunto de dados em treinamento e teste na proporção de 70% a 30%. Usando esses dados, eles criaram um algoritmo que encontra gatos que funcionam bem nos dados de treinamento e teste.
No entanto, quando você introduziu esse classificador em um aplicativo móvel, descobriu que sua qualidade é muito baixa!

O que aconteceu
De repente, você descobre que as fotos que os usuários carregam no seu aplicativo móvel têm uma aparência completamente diferente das fotos dos sites que compõem o conjunto de dados de treinamento: os usuários carregam fotos tiradas com câmeras de celular, que geralmente têm resolução mais baixa, menos nítida e feita com pouca luz. Após o treinamento em suas amostras de treinamento / teste coletadas de fotos de sites, seu algoritmo não conseguiu generalizar qualitativamente os resultados para a distribuição real dos dados relevantes para o seu aplicativo (fotos tiradas com câmeras de celular).
Antes do advento da era moderna do big data, a regra geral do aprendizado de máquina era dividir os dados em dados educacionais e de teste na proporção de 70% a 30%. Apesar de essa abordagem ainda funcionar, será uma má idéia usá-la em mais e mais aplicações em que a distribuição da amostra de treinamento (fotos de sites no exemplo discutido acima) seja diferente da distribuição de dados que serão usados em combate modo do seu aplicativo (fotos da câmera de telefones celulares).
As seguintes definições são comumente usadas:
- Conjunto de treinamento - uma amostra de dados usados para treinar o algoritmo
- Amostragem de validação (conjunto de desenvolvimento (desenvolvimento)) - uma amostragem de dados usada para selecionar parâmetros, selecionar recursos e tomar outras decisões sobre o treinamento do algoritmo. Às vezes, também é chamado de conjunto de validação cruzada de espera.
- Amostra de teste - uma amostra usada para avaliar a qualidade do algoritmo, embora não seja usada para ensinar o algoritmo ou os parâmetros usados neste treinamento.
Observação do tradutor: Andrew Eun usa o conceito de conjunto de desenvolvimento ou conjunto de desenvolvedores, em russo e na terminologia de aprendizado de máquina em idioma russo, tal termo não ocorre. “Design Sample” ou “Design Sample” (tradução direta de palavras em inglês) parece complicado. Portanto, continuarei a usar a frase "seleção de validação" como uma tradução do conjunto de desenvolvedores.
Observação do tradutor 2: DArtN sugeriu traduzir o conjunto de desenvolvedores como "amostragem de depuração"; acho que é uma idéia muito boa, mas eu já usei o termo "amostragem de validação" em um grande volume de texto e agora é trabalhoso substituí-lo. Para ser sincero, observo que o termo "amostra de validação" tem uma vantagem - essa amostra é usada para avaliar a qualidade do algoritmo (para avaliar a qualidade do algoritmo treinado na amostra de treinamento); portanto, de certa forma, é "teste", o termo "validação" em inclui esse aspecto. O adjetivo "depuração" foca nos parâmetros de ajuste. Mas, no geral, esse é um termo muito bom (especialmente do ponto de vista do idioma russo) e, se me ocorresse mais cedo, eu o usaria em vez do termo "amostra de validação".
Escolha a validação e as amostras de teste para que (exceto a seleção (ajuste) dos parâmetros) reflita os dados que você espera receber no futuro e deseje que seu algoritmo funcione bem neles.
Em outras palavras, sua amostra de teste não deve conter apenas 30% dos dados disponíveis, especialmente se você espera que os dados que virão no futuro (fotos de celulares) sejam de natureza diferente do seu conjunto de treinamento (fotos tiradas da Web sites).
Se você ainda não iniciou seu aplicativo móvel, talvez não tenha usuários e, como resultado, talvez não haja dados disponíveis que reflitam dados de combate que seu algoritmo deve manipular. Mas você pode tentar aproximá-los. Por exemplo, peça a seus amigos para tirar fotos de gatos usando telefones celulares e enviá-los para você. Após iniciar o aplicativo, você poderá atualizar sua validação e testar amostras usando os dados atuais do usuário.
Se você não conseguir obter dados que se aproximem dos dados que os usuários enviarão, provavelmente poderá tentar começar a usar fotos de sites. Mas você deve estar ciente de que isso implica o risco de o sistema não funcionar bem com dados de combate (sua capacidade de generalização será insuficiente para eles).
O desenvolvimento de amostras de validação e teste requer uma abordagem séria e uma reflexão aprofundada. Não postule inicialmente que a distribuição do seu conjunto de treinamento corresponda exatamente à distribuição do conjunto de teste. Tente escolher os casos de teste de forma que eles reflitam a distribuição dos dados nos quais você deseja que seu algoritmo funcione bem no final, e não os dados que estavam à sua disposição ao criar a amostra de treinamento.
6. As amostras de validação e teste devem ter a mesma distribuição

Suponha que os dados do seu aplicativo de foto-gato sejam segmentados em quatro regiões correspondentes aos seus maiores mercados: (i) EUA, (ii) China, (iii) Índia, (iv) Outros.
Suponha que tenhamos formado uma amostra de validação de dados obtidos nos mercados americano e indiano, e uma de teste baseada em dados chineses e outros. Em outras palavras, podemos atribuir aleatoriamente dois segmentos para obter uma amostra de validação e outros dois para obter uma amostra de teste. Certo?
Depois de determinar as amostras de validação e teste, sua equipe se concentrará em melhorar a operação do algoritmo na amostra de validação. Assim, a amostra de validação deve refletir as tarefas mais importantes a serem resolvidas - o algoritmo deve funcionar bem em todos os quatro segmentos geográficos, e não apenas em dois.
O segundo problema decorrente das diferentes distribuições das amostras de validação e teste é que é provável que sua equipe desenvolva algo que funcione bem na amostra de validação apenas para descobrir que produz baixa qualidade na amostra de teste. Tenho visto muitas decepções e esforços desperdiçados por causa disso. Evite que isso aconteça com você.
Por exemplo, suponha que sua equipe tenha desenvolvido um sistema que funcione bem em uma amostra validada, mas não em uma amostra de teste. Se suas amostras de validação e teste são obtidas da mesma distribuição, você [obtém um diagnóstico muito claro disso] pode facilmente diagnosticar o que deu errado: seu algoritmo foi treinado novamente na amostra de validação. .
, .
- , . , .
- , , . . .
. , — . , , , .
, , , ( ). , , , . — , . , , , , . .
7. ?
, . , 90.0% 90.1%, , , 100 , 0.1%.
: . ( ), .
— , , -, , , 0.01% , . , 10000, , .
? . 30% . , , 100 10000 . , , , , , . / , , .
8.
: ( ), , , . , 97% , 90%, .
(precision) (recall), . . . :
, .
: (precision) () , , . (recall) () , , . , .
, , , , . . , (accuracy) , .
, , . , . F1 , , .
: F1 , . https://en.wikipedia.org/wiki/F1_score , « » , 2/((1/Precision)+(1/Recall)).
, . .
, , : (i) , (ii) , (iii) (iv) . . , . .
9.
.
, . :
, , [] — 0.5*[] , .
: -, , «». , 100 . , . (satisficing) — , , 100 . .
N , ( - , ), , , N-1 . . . , . (N-) , . , , , .
, , « », ( , ). , Amazon Echo «Alexa»; Apple Siri «Hey Siri»; Android «Okay, Google»; Baidu «Hello Baidu». false-positive — , , false-negative — . false-negative ( ) false positive 24 ( ).
.
10
, . - . , :
- ,
- ( )
- , . ( !) , .
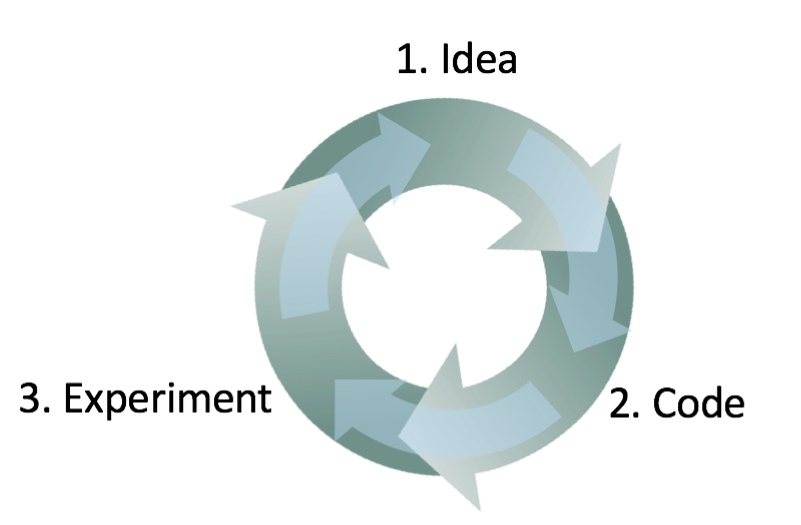
. , . : , , .
, , . , - , , . ! , 95.0% 95.1%, 0.1% () . 0.1%- . , , ( ) , , .
11 Quando você precisar alterar as amostras e métricas de validação e teste (conjuntos de desenvolvimento / teste)
Quando um novo projeto é iniciado, tento selecionar rapidamente amostras de validação e teste que definirão uma meta claramente definida para a equipe.
Normalmente, peço às minhas equipes que obtenham a validação inicial e as amostras de teste e a métrica inicial mais rapidamente do que uma semana desde o início do projeto, raramente mais tempo. É melhor pegar algo imperfeito e avançar rapidamente do que pensar na melhor solução por um longo tempo. No entanto, esse período de uma semana não é adequado para aplicações maduras. Por exemplo, um filtro anti-spam é um aplicativo maduro de aprendizado profundo. Observei equipes trabalhando em sistemas já maduros e gastando meses para obter amostras ainda melhores para testes e desenvolvimento.
Se você decidir posteriormente que suas seleções iniciais de teste / desenvolvimento ou a métrica original não foram selecionadas corretamente, faça todo o esforço para alterá-las rapidamente. Por exemplo, se sua amostra de desenvolvimento + métrica classificar o Classificador A mais alto que o Classificador B e você e sua equipe acharem que o Classificador B é objetivamente melhor para o seu produto, isso pode ser um sinal de que você precisa alterar o desenvolvimento / teste conjuntos de dados ou na alteração de métricas para avaliação da qualidade.
Há três razões possíveis principais pelas quais uma amostra de validação ou métrica de avaliação da qualidade classifica incorretamente o Classificador A acima do Classificador B:
1. A distribuição real a ser aprimorada difere das amostras de desenvolvimento / teste
Imagine que seus conjuntos de dados de desenvolvimento / teste originais contenham principalmente fotos de gatos adultos. Você começa a distribuir seu aplicativo para gatos e descobre que os usuários estão carregando significativamente mais imagens de gatinhos do que o esperado. Portanto, a distribuição dev / test não é representativa; ela não reflete a distribuição real dos objetos cuja qualidade de reconhecimento você precisa melhorar. Nesse caso, atualize suas seleções de desenvolvimento / teste para torná-las mais representativas.

2. Você treina novamente em uma seleção de validação (conjunto de desenvolvedores)
O processo de evolução múltipla de idéias, em um conjunto de validação (conjunto de desenvolvedores), torna seu algoritmo gradualmente treinado. Ao concluir o desenvolvimento, você avalia a qualidade do seu sistema em uma amostra de teste. Se você achar que a qualidade do seu algoritmo no conjunto de validação (conjunto de desenvolvedores) é muito melhor do que no conjunto de testes (conjunto de testes), isso indica que você treinou novamente a amostra de validação. Nesse caso, você precisa obter uma nova amostra de validação.
Se você precisar acompanhar o progresso de sua equipe, também poderá avaliar regularmente a qualidade do seu sistema, digamos, semanalmente ou mensalmente, usando a avaliação da qualidade do algoritmo em uma amostra de teste. No entanto, não use o conjunto de testes para tomar decisões sobre o algoritmo, incluindo se deve retornar à versão anterior do sistema que foi testada na semana passada. Se você começar a usar a amostra de teste para alterar o algoritmo, iniciará a reciclagem da amostra de teste e não poderá mais contar com ela para obter uma avaliação objetiva da qualidade do seu algoritmo (o que você precisa se publicar artigos de pesquisa ou usar essas métricas para tomar importantes decisões de negócios).
3. O Metric avalia algo diferente do que precisa ser otimizado para fins de projeto
Suponha que, no seu aplicativo felino, sua métrica seja a precisão da classificação. Atualmente, essa métrica classifica o Classificador A como um Classificador B. superior. Suponha que você tenha experimentado os dois algoritmos e constatou que imagens pornográficas aleatórias passam pelo Classificador A. Embora o Classificador A seja mais preciso, a fraca impressão deixada pelas imagens pornográficas aleatórias torna sua qualidade insatisfatória. O que você fez de errado?
Nesse caso, a métrica que avalia a qualidade dos algoritmos não pode determinar se o algoritmo B é realmente melhor que o algoritmo A do seu produto. Portanto, você não pode mais confiar na métrica para selecionar o melhor algoritmo. Chegou a hora de alterar a métrica de avaliação da qualidade. Por exemplo, você pode alterar a métrica introduzindo uma penalidade severa no algoritmo por ignorar uma imagem pornográfica. Eu recomendo escolher uma nova métrica e usar essa nova métrica para definir explicitamente uma nova meta para a equipe, em vez de continuar trabalhando por muito tempo com uma métrica não confiável, retornando sempre à seleção manual entre os classificadores.
Essas são abordagens bastante gerais para alterar amostras de desenvolvimento / teste ou alterar a métrica de avaliação da qualidade durante o trabalho em um projeto. Ter as amostras e métricas originais de desenvolvimento / teste permite iniciar rapidamente a iteração do seu projeto. Se você achar que as seleções ou métricas de desenvolvimento / teste selecionadas não mais orientam sua equipe na direção certa, isso realmente não importa! Apenas altere-os e verifique se sua equipe conhece uma nova direção.
12 Recomendações: Preparamos amostras de validação (desenvolvimento) e teste
- Selecione dev e teste amostras de uma distribuição que reflete os dados que você espera receber no futuro e nos quais deseja que seu algoritmo funcione bem. Essas amostras podem não coincidir com a distribuição do seu conjunto de dados de treinamento.
- Selecione conjuntos de teste de desenvolvimento da mesma distribuição, se possível
- Escolha uma métrica de um parâmetro para avaliar a qualidade dos algoritmos de otimização para sua equipe. Se você tem vários objetivos que precisa alcançar ao mesmo tempo, considere combiná-los em uma fórmula (como a métrica do erro médio multiparâmetro) ou defina métricas restritivas e de otimização.
- O aprendizado de máquina é um processo altamente iterativo: você pode tentar muitas idéias antes de encontrar uma que o satisfaça.
- A existência de amostras de desenvolvimento / teste e uma métrica de avaliação de qualidade de um parâmetro ajudarão a avaliar rapidamente os algoritmos e, assim, percorrer mais rapidamente.
- Quando o desenvolvimento de um novo aplicativo for iniciado, tente instalar rapidamente as amostras de desenvolvimento / teste e a métrica de avaliação da qualidade, por exemplo, gaste não mais de uma semana nisso. Para aplicativos maduros, é normal se esse processo demorar significativamente mais.
- A boa e antiga heurística de dividir as amostras de treinamento e teste em 70% a 30% não é aplicável a problemas nos quais há uma grande quantidade de dados; As amostras dev / test podem ser significativamente inferiores a 30% de todos os dados disponíveis.
- Se sua amostra e métrica de desenvolvimento não informarem mais a sua equipe sobre a direção certa, altere-a rapidamente: (i) se seu algoritmo for treinado novamente no conjunto de validação (conjunto de desenvolvedores), adicione mais dados a ele (no conjunto de desenvolvedores). (ii) Se a distribuição de dados reais, a qualidade do algoritmo em que você precisa melhorar, diferir da distribuição de dados na validação e (ou) amostras de teste (conjuntos de desenvolvimento / teste), crie novas amostras para teste e desenvolvimento (conjuntos de desenvolvimento / teste), usando outros dados. (iii) Se sua métrica de avaliação da qualidade não medir mais o que é mais importante para o seu projeto, altere essa métrica.
13 Crie seu primeiro sistema rapidamente e, em seguida, atualize iterativamente
Você deseja criar para criar um novo sistema anti-spam para email. Sua equipe tem várias idéias:
- Colete uma enorme amostra de treinamento que consiste em emails de spam. Por exemplo, configure um engodo: envie intencionalmente endereços de email falsos para spammers conhecidos, para que você possa coletar automaticamente emails de spam que eles enviarão para esses endereços
- Desenvolver sinais para entender o conteúdo textual da carta
- Desenvolver sinais para entender a casca da carta / cabeçalho, sinais mostrando por quais servidores da Internet a carta passou
- e assim por diante
Embora tenha me esforçado bastante em aplicativos anti-spam, ainda será difícil escolher uma dessas áreas. Será ainda mais difícil se você não for um especialista na área para a qual o aplicativo está sendo desenvolvido.
Portanto, não tente construir um sistema ideal desde o início. Em vez disso, crie e treine um sistema simples o mais rápido possível, possivelmente em alguns dias.
Nota do autor: Esta dica é para leitores que desejam desenvolver aplicativos de IA, e não para aqueles cujo objetivo é publicar artigos acadêmicos. Mais tarde, voltarei ao tópico da pesquisa.
Mesmo que um sistema simples esteja longe de ser um sistema "ideal" que você possa construir, será útil estudar como esse sistema simples funciona: você encontrará rapidamente dicas que mostram as áreas mais promissoras em que você deve investir seu tempo. Os próximos capítulos mostrarão como ler essas dicas.
14 Análise de erro: Veja exemplos de conjuntos de desenvolvimento para idéias.

Quando você brincou com seu aplicativo de gato, notou vários exemplos em que o aplicativo confundia cães com gatos. Alguns cães parecem gatos!
Um dos membros da equipe sugeriu a introdução de software de terceiros que melhoraria o desempenho do sistema em fotografias de cães. A implementação das mudanças levará um mês, o membro da equipe que as propôs está entusiasmado. Que decisão você deve tomar?
Antes de investir um mês na solução desse problema, recomendo que você avalie primeiro como sua solução melhorará a qualidade do sistema. Em seguida, você pode decidir mais racionalmente se vale a pena melhorar um mês de desenvolvimento ou se será melhor usar esse tempo para resolver outros problemas.
Especificamente, o que pode ser feito neste caso:
- Reúna uma amostra de 100 exemplos do conjunto de desenvolvedores que seu sistema classificou incorretamente. Ou seja, exemplos nos quais seu sistema cometeu um erro.
- Estude estes exemplos e calcule quanto da imagem do cão é.
O processo de estudar exemplos nos quais o classificador cometeu um erro é chamado "análise de erro". Neste exemplo, suponha que você ache que apenas 5% das imagens classificadas incorretamente são cães; não importa o quanto você melhore o desempenho do seu algoritmo nas imagens de cães, não será possível obter uma qualidade melhor que 5% da sua taxa de erro . Em outras palavras, 5% é o "teto" (implica o número mais alto possível) na medida em que a melhoria esperada possa ajudar. Portanto, se atualmente o seu sistema geral possui uma precisão de 90% (erro de 10%), essa melhoria é possível; na melhor das hipóteses, o resultado será aprimorado para 90,5% de precisão (ou a taxa de erro será de 9,5%, 5% inferior à original). 10% de erros)
Pelo contrário, se você achar que 50% dos erros são cães, pode estar mais confiante de que o projeto proposto para melhorar o sistema terá um grande efeito. Pode aumentar a precisão de 90% para 95% (redução de erro relativo de 50% de 10% para 5%)
Este procedimento simples de avaliação para análise de erros permite avaliar rapidamente os possíveis benefícios da implementação de um software de classificação de imagens de cães de terceiros. Ele fornece uma avaliação quantitativa para decidir sobre a conveniência de investir tempo em sua implementação.
A análise de erros geralmente pode ajudar a entender quão promissoras são as várias direções para trabalhos futuros. Eu observei que muitos engenheiros relutam em analisar erros. Muitas vezes parece mais emocionante simplesmente se apressar em uma idéia do que descobrir se a idéia vale o tempo que levará. Esse é um erro comum: isso pode levar ao fato de que sua equipe passará um mês apenas para entender depois que o resultado é uma melhoria insignificante.
Verificação manual de 100 exemplos da amostra, não é longo. Mesmo se você gastar um minuto na imagem, toda a verificação levará menos de 2 horas. Essas duas horas podem economizar um mês de esforço desperdiçado.
continuação