No caso da organização de microsserviços do aplicativo, um trabalho substancial baseia-se nos mecanismos de comunicação de integração de microsserviços. Além disso, essa integração deve ser tolerante a falhas, com um alto grau de disponibilidade.
Em nossas soluções, usamos a integração com Kafka, gRPC e RabbitMQ.
Neste artigo, compartilharemos nossa experiência de agrupar o RabbitMQ, cujos nós estão hospedados no Kubernetes.

Antes do RabbitMQ versão 3.7, agrupá-lo no K8S não era uma tarefa muito trivial, com muitos hacks e soluções não muito bonitas. Na versão 3.6, foi usado um plugin de autocluster da RabbitMQ Community. E em 3.7 o Kubernetes Peer Discovery Backend apareceu. Ele é incorporado pelo plug-in na entrega básica do RabbitMQ e não requer montagem e instalação separadas.
Vamos descrever a configuração final como um todo, enquanto comentamos o que está acontecendo.
Em teoria
O plugin possui um
repositório no github , no qual há
um exemplo de uso básico .
Este exemplo não se destina à Produção, que está claramente indicado em sua descrição e, além disso, algumas das configurações nele são contrárias à lógica de uso no produto. Além disso, no exemplo, a persistência do armazenamento não é mencionada, portanto, em qualquer situação de emergência, nosso cluster se tornará um zilch.
Na prática
Agora, mostraremos o que você enfrentou e como instalar e configurar o RabbitMQ.
Vamos descrever as configurações de todas as partes do RabbitMQ como um serviço nos K8s. Esclareceremos imediatamente que instalamos o RabbitMQ no K8s como um StatefulSet. Em cada nó do cluster K8s, uma instância do RabbitMQ sempre funcionará (um nó na configuração clássica do cluster). Também instalaremos o painel de controle RabbitMQ no K8s e daremos acesso a esse painel fora do cluster.
Direitos e funções:
rabbitmq_rbac.yaml--- apiVersion: v1 kind: ServiceAccount metadata: name: rabbitmq --- kind: Role apiVersion: rbac.authorization.k8s.io/v1beta1 metadata: name: endpoint-reader rules: - apiGroups: [""] resources: ["endpoints"] verbs: ["get"] --- kind: RoleBinding apiVersion: rbac.authorization.k8s.io/v1beta1 metadata: name: endpoint-reader subjects: - kind: ServiceAccount name: rabbitmq roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: endpoint-reader
Os direitos de acesso ao RabbitMQ são retirados inteiramente do exemplo, não são necessárias alterações neles. Criamos uma ServiceAccount para nosso cluster e concedemos permissões de leitura para os Endpoints K8s.
Armazenamento persistente:
rabbitmq_pv.yaml kind: PersistentVolume apiVersion: v1 metadata: name: rabbitmq-data-sigma labels: type: local annotations: volume.alpha.kubernetes.io/storage-class: rabbitmq-data-sigma spec: storageClassName: rabbitmq-data-sigma capacity: storage: 10Gi accessModes: - ReadWriteMany persistentVolumeReclaimPolicy: Recycle hostPath: path: "/opt/rabbitmq-data-sigma"
Aqui consideramos o caso mais simples como o armazenamento persistente - hostPath (uma pasta comum em cada nó do K8s), mas você pode usar qualquer um dos muitos tipos de volumes persistentes suportados pelo K8s.
rabbitmq_pvc.yaml kind: PersistentVolumeClaim apiVersion: v1 metadata: name: rabbitmq-data spec: storageClassName: rabbitmq-data-sigma accessModes: - ReadWriteMany resources: requests: storage: 10Gi
Criar reivindicação de volume no volume criado na etapa anterior. Essa declaração será usada no StatefulSet como um armazenamento de dados persistente.
Serviços:
rabbitmq_service.yaml kind: Service apiVersion: v1 metadata: name: rabbitmq-internal labels: app: rabbitmq spec: clusterIP: None ports: - name: http protocol: TCP port: 15672 - name: amqp protocol: TCP port: 5672 selector: app: rabbitmq
Criamos um serviço interno sem cabeça, através do qual o plugin Peer Discovery funcionará.
rabbitmq_service_ext.yaml kind: Service apiVersion: v1 metadata: name: rabbitmq labels: app: rabbitmq type: LoadBalancer spec: type: NodePort ports: - name: http protocol: TCP port: 15672 targetPort: 15672 nodePort: 31673 - name: amqp protocol: TCP port: 5672 targetPort: 5672 nodePort: 30673 selector: app: rabbitmq
Para aplicativos nos K8s funcionarem com nosso cluster, criamos um serviço de balanceador.
Como precisamos acessar o cluster RabbitMQ fora dos K8s, passamos pelo NodePort. O RabbitMQ estará disponível ao acessar qualquer nó do cluster K8s nas portas 31673 e 30673. No trabalho real, não há grande necessidade disso. A questão da conveniência de usar o painel de administração do RabbitMQ.
Ao criar um serviço com o tipo NodePort no K8s, também é criado implicitamente um serviço com o tipo ClusterIP para atendê-lo. Portanto, aplicativos em K8s que precisam trabalhar com o RabbitMQ poderão acessar o cluster em
amqp: // rabbitmq: 5672Configuração:
rabbitmq_configmap.yaml apiVersion: v1 kind: ConfigMap metadata: name: rabbitmq-config data: enabled_plugins: | [rabbitmq_management,rabbitmq_peer_discovery_k8s]. rabbitmq.conf: | cluster_formation.peer_discovery_backend = rabbit_peer_discovery_k8s cluster_formation.k8s.host = kubernetes.default.svc.cluster.local cluster_formation.k8s.port = 443 ### cluster_formation.k8s.address_type = ip cluster_formation.k8s.address_type = hostname cluster_formation.node_cleanup.interval = 10 cluster_formation.node_cleanup.only_log_warning = true cluster_partition_handling = autoheal queue_master_locator=min-masters cluster_formation.randomized_startup_delay_range.min = 0 cluster_formation.randomized_startup_delay_range.max = 2 cluster_formation.k8s.service_name = rabbitmq-internal cluster_formation.k8s.hostname_suffix = .rabbitmq-internal.our-namespace.svc.cluster.local
Criamos arquivos de configuração do RabbitMQ. A principal magia.
enabled_plugins: | [rabbitmq_management,rabbitmq_peer_discovery_k8s].
Adicione os plugins necessários aos permitidos para download. Agora podemos usar a descoberta automática de pares no K8S.
cluster_formation.peer_discovery_backend = rabbit_peer_discovery_k8s
Nós expomos o plug-in necessário como um back-end para a descoberta de pares.
cluster_formation.k8s.host = kubernetes.default.svc.cluster.local cluster_formation.k8s.port = 443
Especifique o endereço e a porta através da qual você pode acessar o kubernetes apiserver. Aqui você pode especificar o endereço IP diretamente, mas será mais bonito fazê-lo.
No padrão do espaço para nome, geralmente é criado um serviço com o nome kubernetes que leva ao k8-apiserver. Em diferentes opções de instalação do K8S, o namespace, o nome do serviço e a porta podem ser diferentes. Se algo em uma instalação específica for diferente, você precisará corrigi-lo adequadamente.
Por exemplo, somos confrontados com o fato de que em alguns clusters o serviço está na porta 443 e em alguns na 6443. Será possível entender que algo está errado nos logs de inicialização do RabbitMQ, o tempo de conexão com o endereço especificado aqui está claramente destacado.
### cluster_formation.k8s.address_type = ip cluster_formation.k8s.address_type = hostname
Por padrão, o exemplo especificou o tipo de endereço do nó do cluster RabbitMQ pelo endereço IP. Mas quando você reinicia o pod, ele obtém um novo IP sempre. Surpresa! O aglomerado está morrendo em agonia.
Mude o endereçamento para hostname. O StatefulSet nos garante a invariabilidade do nome do host no ciclo de vida de todo o StatefulSet, o que nos convém completamente.
cluster_formation.node_cleanup.interval = 10 cluster_formation.node_cleanup.only_log_warning = true
Como quando perdemos um dos nós, assumimos que ele se recuperará mais cedo ou mais tarde, desabilitamos a exclusão automática por um cluster de nós inacessíveis. Nesse caso, assim que o nó voltar online, ele entrará no cluster sem perder o estado anterior.
cluster_partition_handling = autoheal
Este parâmetro determina as ações do cluster em caso de perda de quorum. Aqui você só precisa ler a
documentação sobre este tópico e entender por si mesmo o que está mais próximo de um caso de uso específico.
queue_master_locator=min-masters
Determine a seleção do assistente para novas filas. Com essa configuração, o assistente selecionará o nó com o menor número de filas, para que as filas sejam distribuídas uniformemente pelos nós do cluster.
cluster_formation.k8s.service_name = rabbitmq-internal
Nomeamos o serviço K8s decapitado (criado por nós anteriormente) através do qual os nós do RabbitMQ se comunicarão.
cluster_formation.k8s.hostname_suffix = .rabbitmq-internal.our-namespace.svc.cluster.local
Uma coisa importante para endereçar em um cluster é o nome do host. O FQDN da lareira do K8s é formado como um nome abreviado (rabbitmq-0, rabbitmq-1) + sufixo (parte do domínio). Aqui indicamos esse sufixo. No K8S, parece
. <Nome do serviço>. <Nome do espaço para nome> .svc.cluster.localO kube-dns resolve nomes no formato rabbitmq-0.rabbitmq-internal.our-namespace.svc.cluster.local no endereço IP de um pod específico sem nenhuma configuração adicional, o que torna possível toda a magia do agrupamento por nome de host.
Configuração StatefulSet RabbitMQ:
rabbitmq_statefulset.yaml apiVersion: apps/v1beta1 kind: StatefulSet metadata: name: rabbitmq spec: serviceName: rabbitmq-internal replicas: 3 template: metadata: labels: app: rabbitmq annotations: scheduler.alpha.kubernetes.io/affinity: > { "podAntiAffinity": { "requiredDuringSchedulingIgnoredDuringExecution": [{ "labelSelector": { "matchExpressions": [{ "key": "app", "operator": "In", "values": ["rabbitmq"] }] }, "topologyKey": "kubernetes.io/hostname" }] } } spec: serviceAccountName: rabbitmq terminationGracePeriodSeconds: 10 containers: - name: rabbitmq-k8s image: rabbitmq:3.7 volumeMounts: - name: config-volume mountPath: /etc/rabbitmq - name: rabbitmq-data mountPath: /var/lib/rabbitmq/mnesia ports: - name: http protocol: TCP containerPort: 15672 - name: amqp protocol: TCP containerPort: 5672 livenessProbe: exec: command: ["rabbitmqctl", "status"] initialDelaySeconds: 60 periodSeconds: 10 timeoutSeconds: 10 readinessProbe: exec: command: ["rabbitmqctl", "status"] initialDelaySeconds: 10 periodSeconds: 10 timeoutSeconds: 10 imagePullPolicy: Always env: - name: MY_POD_IP valueFrom: fieldRef: fieldPath: status.podIP - name: HOSTNAME valueFrom: fieldRef: fieldPath: metadata.name - name: NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace - name: RABBITMQ_USE_LONGNAME value: "true" - name: RABBITMQ_NODENAME value: "rabbit@$(HOSTNAME).rabbitmq-internal.$(NAMESPACE).svc.cluster.local" - name: K8S_SERVICE_NAME value: "rabbitmq-internal" - name: RABBITMQ_ERLANG_COOKIE value: "mycookie" volumes: - name: config-volume configMap: name: rabbitmq-config items: - key: rabbitmq.conf path: rabbitmq.conf - key: enabled_plugins path: enabled_plugins - name: rabbitmq-data persistentVolumeClaim: claimName: rabbitmq-data
Na verdade, StatefulSet. Observamos pontos interessantes.
serviceName: rabbitmq-internal
Escrevemos o nome do serviço decapitado por meio do qual os pods se comunicam no StatefulSet.
replicas: 3
Defina o número de réplicas no cluster. Temos isso igual ao número de nós de trabalho K8s.
annotations: scheduler.alpha.kubernetes.io/affinity: > { "podAntiAffinity": { "requiredDuringSchedulingIgnoredDuringExecution": [{ "labelSelector": { "matchExpressions": [{ "key": "app", "operator": "In", "values": ["rabbitmq"] }] }, "topologyKey": "kubernetes.io/hostname" }] } }
Quando um dos nós K8s cai, o statefulset procura preservar o número de instâncias no conjunto; portanto, ele cria vários lares no mesmo nó K8s. Esse comportamento é completamente indesejável e, em princípio, inútil. Portanto, prescrevemos uma regra anti-afinidade para conjuntos de lareiras a partir de statefulset. Tornamos a regra rígida (Necessária) para que o kube-scheduler não possa quebrá-la ao planejar pods.
A essência é simples: é proibido ao planejador colocar (dentro do espaço de nomes) mais de um pod com a
tag app: rabbitmq em cada nó. Distinguimos os
nós pelo valor do rótulo
kubernetes.io/hostname . Agora, se por algum motivo o número de nós K8S em funcionamento for menor que o número necessário de réplicas no StatefulSet, novas réplicas não serão criadas até que um nó livre apareça novamente.
serviceAccountName: rabbitmq
Registramos a ServiceAccount, na qual nossos pods funcionam.
image: rabbitmq:3.7
A imagem do RabbitMQ é completamente padrão e é tirada do hub do docker, não requer nenhuma reconstrução e revisão de arquivos.
- name: rabbitmq-data mountPath: /var/lib/rabbitmq/mnesia
Dados persistentes do RabbitMQ são armazenados em / var / lib / rabbitmq / mnesia. Aqui, montamos nossa Reivindicação de volume persistente nesta pasta para que, ao reiniciar os lares / nós ou até mesmo todo o StatefulSet, os dados (ambos os serviços, incluindo o cluster montado e os dados do usuário) sejam seguros. Existem alguns exemplos em que toda a pasta / var / lib / rabbitmq / se torna persistente. Chegamos à conclusão de que essa não é a melhor idéia, pois ao mesmo tempo todas as informações definidas pelas configurações do Rabbit começam a ser lembradas. Ou seja, para alterar algo no arquivo de configuração, você precisa limpar o armazenamento persistente, o que é muito inconveniente na operação.
- name: HOSTNAME valueFrom: fieldRef: fieldPath: metadata.name - name: NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace - name: RABBITMQ_USE_LONGNAME value: "true" - name: RABBITMQ_NODENAME value: "rabbit@$(HOSTNAME).rabbitmq-internal.$(NAMESPACE).svc.cluster.local"
Com esse conjunto de variáveis de ambiente, primeiro dizemos ao RabbitMQ para usar o nome do FQDN como um identificador para os membros do cluster e, em segundo lugar, definimos o formato desse nome. O formato foi descrito anteriormente ao analisar a configuração.
- name: K8S_SERVICE_NAME value: "rabbitmq-internal"
O nome do serviço sem cabeçalho para comunicação entre membros do cluster.
- name: RABBITMQ_ERLANG_COOKIE value: "mycookie"
O conteúdo do cookie Erlang deve ser o mesmo em todos os nós do cluster. Você precisa registrar seu próprio valor. Um nó com um cookie diferente não pode entrar no cluster.
volumes: - name: rabbitmq-data persistentVolumeClaim: claimName: rabbitmq-data
Defina o volume mapeado a partir da reivindicação de volume persistente criada anteriormente.
É aqui que terminamos a configuração nos K8s. O resultado é um cluster RabbitMQ, que distribui uniformemente filas entre nós e é resistente a problemas no ambiente de tempo de execução.
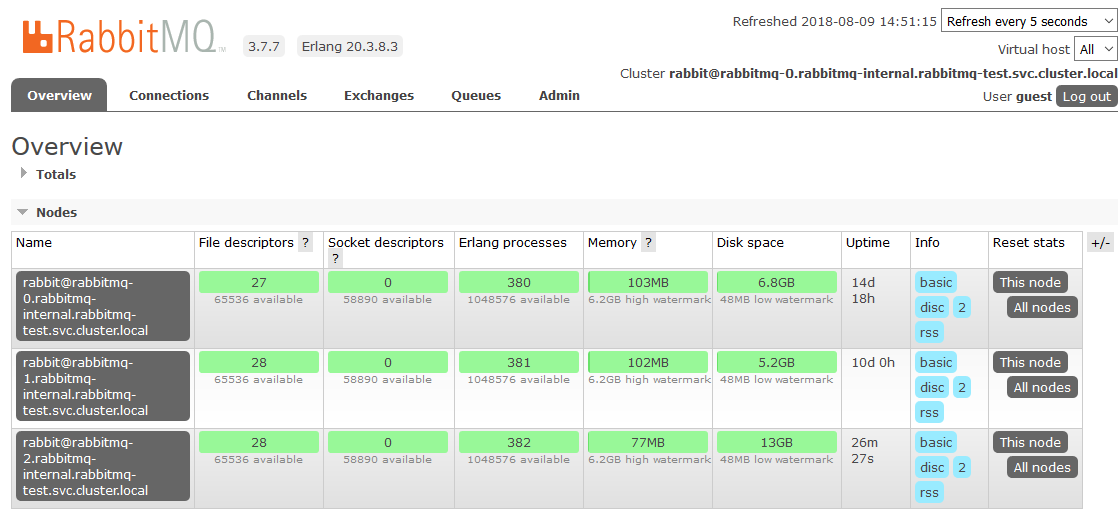
Se um dos nós do cluster não estiver disponível, as filas contidas nele deixarão de ser acessíveis, tudo o mais continuará funcionando. Assim que o nó retornar à operação, ele retornará ao cluster e as filas para as quais era um mestre tornar-se-ão operacionais novamente, preservando todos os dados contidos neles (se o armazenamento persistente não for interrompido, é claro). Todos esses processos são totalmente automáticos e não requerem intervenção.
Bônus: personalizar HA
Um dos projetos foi uma nuance. Os requisitos pareciam um espelhamento completo de todos os dados contidos no cluster. Isso é necessário para que, em uma situação em que pelo menos um nó do cluster esteja operacional, tudo continue funcionando do ponto de vista do aplicativo. Este momento não tem nada a ver com os K8s, nós o descrevemos simplesmente como um mini tutorial.
Para habilitar a HA total, você precisa criar uma Política no painel RabbitMQ na guia
Admin -> Políticas . O nome é arbitrário, o Padrão está vazio (todas as filas), nas Definições, adicione dois parâmetros:
modo ha: todos , modo
ha-sync: automático .
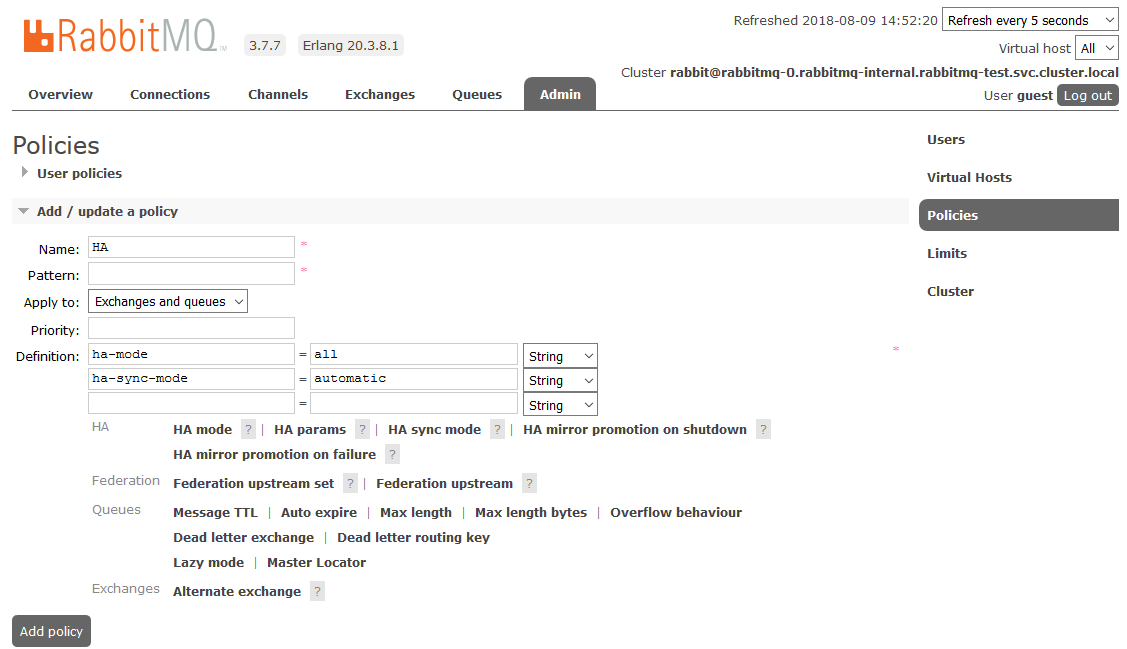
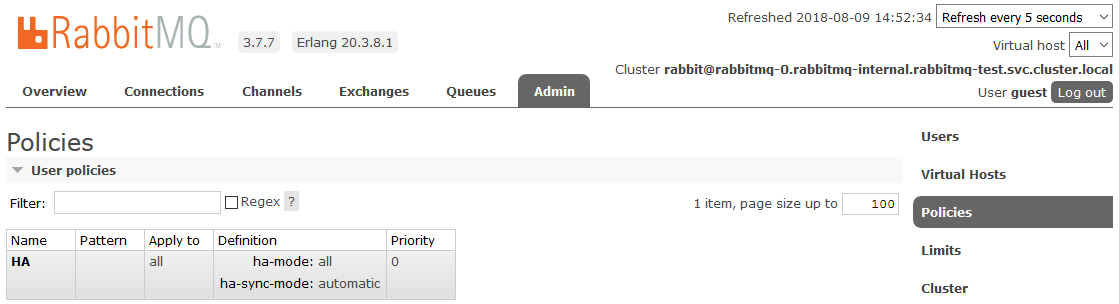
Depois disso, todas as filas criadas no cluster estarão no modo de Alta Disponibilidade: se o nó Mestre estiver indisponível, um dos Escravos será selecionado automaticamente pelo novo assistente. E os dados que entram na fila serão espelhados para todos os nós do cluster. Que, de fato, era necessário para receber.
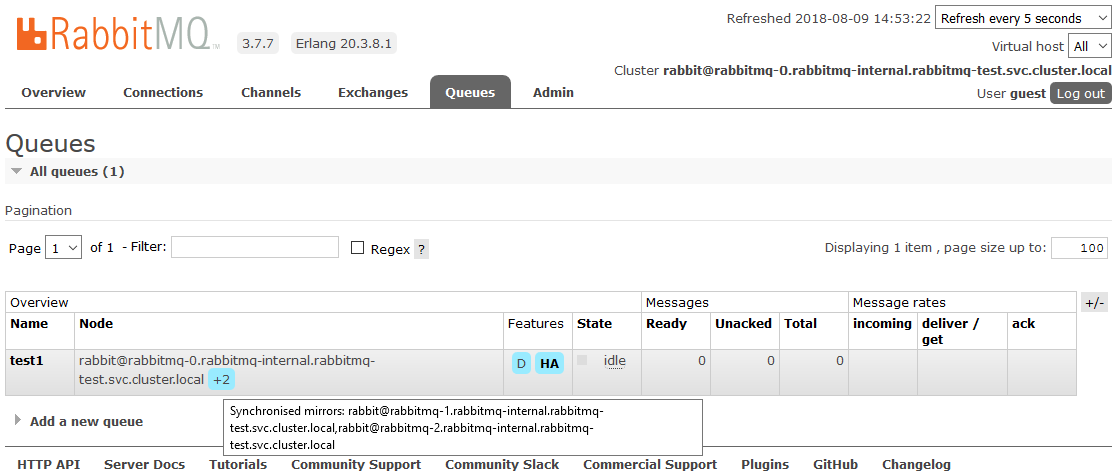
Leia mais sobre HA no RabbitMQ
aquiLiteratura útil:
Boa sorte