Olá Habr! Apresento a você a tradução do artigo "
Detectando o sarcasmo com redes neurais profundas e convolucionais ", de Elvis Saravia.
Um dos principais problemas no processamento de linguagem natural é a detecção de sarcasmo. Detectar o sarcasmo é importante em outras áreas, como computação emocional e análise de humor, pois isso pode refletir a polaridade da sentença.
Este artigo mostra como detectar sarcasmo e também fornece um link para um
detector de sarcasmo de rede neural .
O sarcasmo pode ser visto como uma expressão de zombaria ou ironia. Exemplos de sarcasmo: "Trabalho 40 horas por semana para permanecer pobre" ou "Se o paciente realmente quer viver, os médicos são impotentes".
Para entender e detectar o sarcasmo, é importante entender os fatos associados ao evento. Isso revela uma contradição entre a polaridade objetiva (geralmente negativa) e as características sarcásticas transmitidas pelo autor (geralmente positivas).
Considere o exemplo: "Gosto da dor da separação".
É difícil entender o significado se houver sarcasmo nessa afirmação. Neste exemplo, "eu gosto de dor" fornece conhecimento dos sentimentos expressos pelo autor (neste caso, positivo) e "separar" descreve o sentimento contraditório (negativo).
Outros problemas que existem no entendimento de declarações sarcásticas são uma referência a vários eventos e a necessidade de extrair um grande número de fatos, bom senso e raciocínio lógico.
Modelo
Uma "mudança de humor" está frequentemente presente na comunicação onde há sarcasmo; assim, propõe-se preparar primeiro um modelo de humor (baseado na CNN) para extrair os sinais de humor. O modelo seleciona recursos locais nas primeiras camadas, que são transformadas em recursos globais em níveis mais altos. Expressões sarcásticas são específicas do usuário - alguns usuários usam mais sarcasmo que outros.
No modelo proposto para a detecção de sarcasmo são utilizados traços de personalidade, sinais de humor e sinais baseados em emoções. Um conjunto de detectores é uma estrutura projetada para detectar sarcasmo. Cada conjunto de atributos é estudado por modelos pré-treinados separados.
Quadro da CNN
As CNNs são eficazes na modelagem da hierarquia de recursos locais para destacar os recursos globais, o que é necessário para examinar o contexto. Os dados de entrada são apresentados como vetores de palavras. Para o processamento inicial dos dados de entrada, o word2vec do Google é usado. Os parâmetros dos vetores são obtidos na fase de treinamento. A união máxima é então aplicada aos mapas de funções para criar funções. Após a camada totalmente ligada, existe uma camada softmax para obter a previsão final.
A arquitetura é mostrada na figura abaixo.
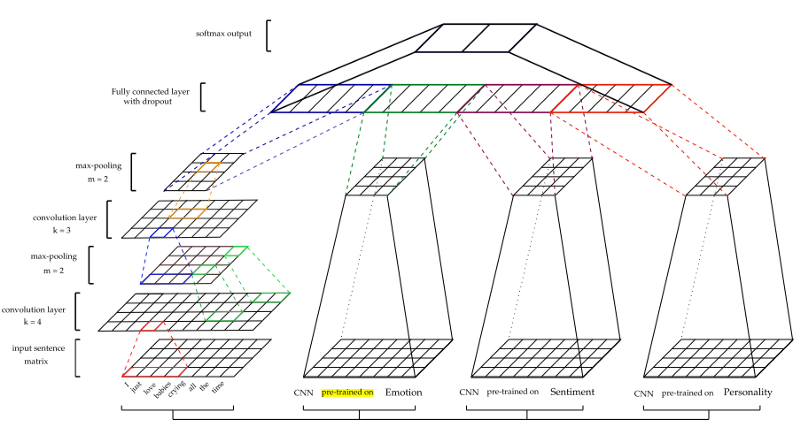
Para obter outros recursos - modelos de humor (S), emoção (E) e personalidade (P) - CNN passam por treinamento preliminar e são usados para extrair traços de conjuntos de dados de sarcasmo. Para o treinamento de cada modelo, diferentes conjuntos de dados de treinamento foram usados. (Para mais detalhes, consulte o documento)
Dois classificadores são testados - o classificador CNN puro (CNN) e as características extraídas por CNN são passados para o classificador SVM (CNN-SVM).
Um classificador básico separado (B) também é treinado, consistindo apenas no modelo da CNN sem a inclusão de outros modelos (por exemplo, emoções e humor).
Os experimentos
Dados. Conjuntos de dados balanceados e não balanceados foram obtidos de (Ptacek et al., 2014) e de
um detector de sarcasmo . Nomes de usuários, URLs e tags de hash são removidos e o tokenizer do Twitter NLTK é aplicado.
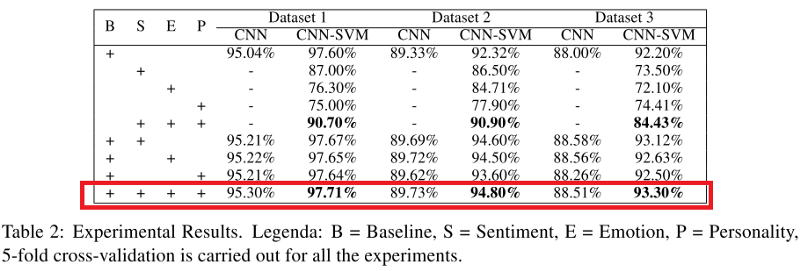
As métricas do classificador CNN e CNN-SVM aplicadas a todos os conjuntos de dados são mostradas na tabela abaixo. Você pode perceber que quando um modelo (em particular, CNN-SVM) combina os sinais de sarcasmo, os sinais de emoções, sentimentos e traços de caráter, ele ultrapassa todos os outros modelos, com exceção do modelo base (B).
As possibilidades de generalização dos modelos foram testadas, e a principal conclusão foi que, se os conjuntos de dados eram de natureza diferente, isso influenciou significativamente o resultado, como é mostrado na figura abaixo. Por exemplo, o treinamento foi realizado no conjunto de dados 1 e testado no conjunto de dados 2; O escore F1 do modelo foi de 33,05%.