Na empresa, nossa equipe para combater ataques DDoS é chamada de "conta-gotas de pacotes". Enquanto todas as outras equipes estão fazendo coisas legais com o tráfego que passa pela nossa rede, nos divertimos encontrando novas maneiras de nos livrarmos dele.
 Foto: Brian Evans , CC BY-SA 2.0
Foto: Brian Evans , CC BY-SA 2.0A capacidade de descartar pacotes rapidamente é muito importante na oposição a ataques DDoS.
Os pacotes descartados que chegam aos nossos servidores podem ser executados em vários níveis. Cada método tem seus prós e contras. Sob o corte, olhamos para tudo o que testamos.
Nota do tradutor: na saída de alguns dos comandos apresentados, foram removidos espaços extras para manter a legibilidade.
Site de teste
Para a conveniência de comparar os métodos, forneceremos alguns números, no entanto, não os leve muito literalmente, devido à artificialidade dos testes. Usaremos uma de nossas placas de rede Intel 10Gb / s. As características restantes do servidor não são tão importantes, porque queremos nos concentrar nas limitações do sistema operacional, não no hardware.
Nossos testes terão a seguinte aparência:
- Criamos uma carga enorme de pacotes UDP pequenos, atingindo um valor de 14 milhões de pacotes por segundo;
- Todo esse tráfego é direcionado para um núcleo de processador do servidor selecionado;
- Medimos o número de pacotes processados pelo kernel em um único núcleo do processador.
O tráfego artificial é gerado de forma a criar carga máxima: endereço IP aleatório e porta do remetente são usados. Isto é o que parece no tcpdump:
$ tcpdump -ni vlan100 -c 10 -t udp and dst port 1234 IP 198.18.40.55.32059 > 198.18.0.12.1234: UDP, length 16 IP 198.18.51.16.30852 > 198.18.0.12.1234: UDP, length 16 IP 198.18.35.51.61823 > 198.18.0.12.1234: UDP, length 16 IP 198.18.44.42.30344 > 198.18.0.12.1234: UDP, length 16 IP 198.18.106.227.38592 > 198.18.0.12.1234: UDP, length 16 IP 198.18.48.67.19533 > 198.18.0.12.1234: UDP, length 16 IP 198.18.49.38.40566 > 198.18.0.12.1234: UDP, length 16 IP 198.18.50.73.22989 > 198.18.0.12.1234: UDP, length 16 IP 198.18.43.204.37895 > 198.18.0.12.1234: UDP, length 16 IP 198.18.104.128.1543 > 198.18.0.12.1234: UDP, length 16
No servidor selecionado, todos os pacotes se tornarão em uma fila RX e, portanto, serão processados por um núcleo. Conseguimos isso com o controle de fluxo de hardware:
ethtool -N ext0 flow-type udp4 dst-ip 198.18.0.12 dst-port 1234 action 2
O teste de desempenho é um processo complexo. Quando preparamos os testes, percebemos que a presença de soquetes brutos ativos afeta negativamente o desempenho. Portanto, antes de executar os testes, é necessário garantir que nenhum
tcpdump esteja em execução. Existe uma maneira fácil de verificar se há processos incorretos:
$ ss -A raw,packet_raw -l -p|cat Netid State Recv-Q Send-Q Local Address:Port p_raw UNCONN 525157 0 *:vlan100 users:(("tcpdump",pid=23683,fd=3))
E, finalmente, desligamos o Intel Turbo Boost em nosso servidor:
echo 1 | sudo tee /sys/devices/system/cpu/intel_pstate/no_turbo
Apesar de o Turbo Boost ser excelente e aumentar a taxa de transferência em pelo menos 20%, estraga significativamente o desvio padrão em nossos testes. Com o turbo ligado, o desvio atinge ± 1,5%, enquanto sem ele apenas 0,25%.
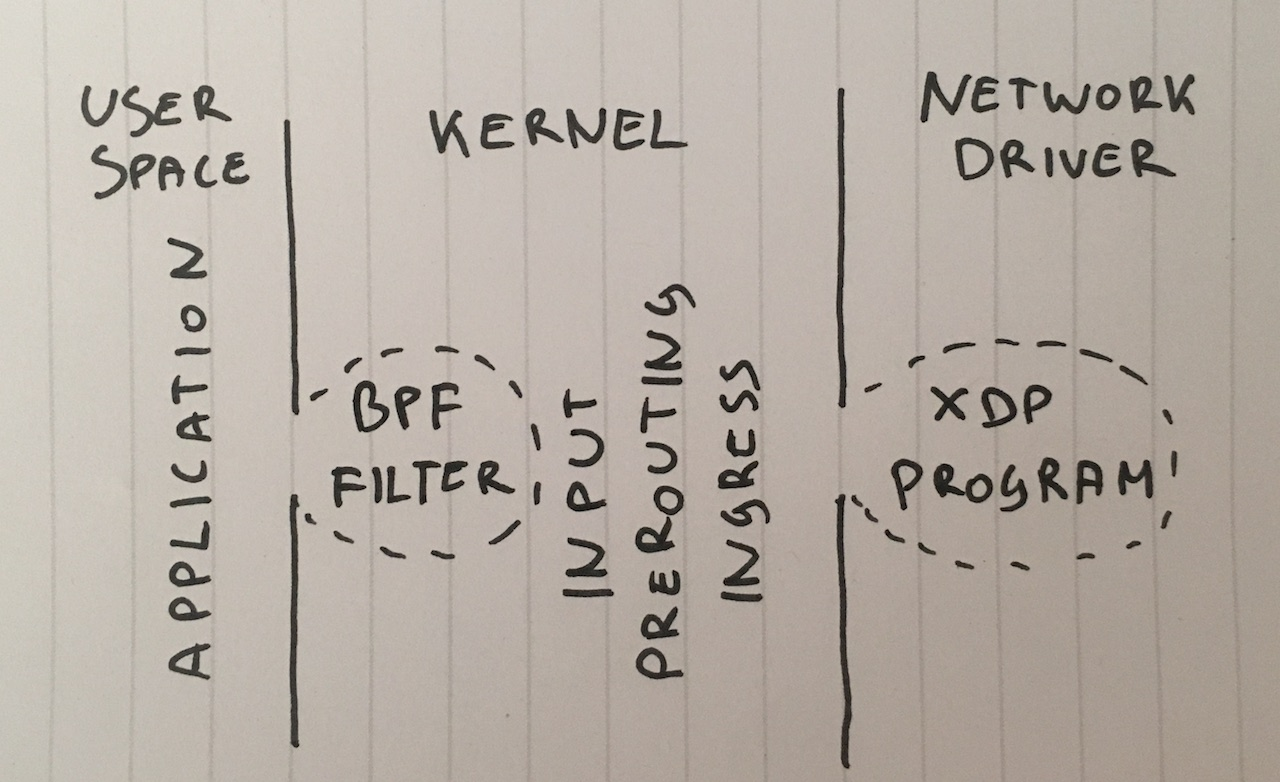
Etapa 1. Solte pacotes no aplicativo
Vamos começar com a idéia de entregar todos os pacotes para o aplicativo e ignorá-los lá. Para a honestidade do experimento, verifique se o iptables não afeta o desempenho de forma alguma:
iptables -I PREROUTING -t mangle -d 198.18.0.12 -p udp --dport 1234 -j ACCEPT iptables -I PREROUTING -t raw -d 198.18.0.12 -p udp --dport 1234 -j ACCEPT iptables -I INPUT -t filter -d 198.18.0.12 -p udp --dport 1234 -j ACCEPT
O aplicativo é um ciclo simples no qual os dados recebidos são descartados imediatamente:
s = socket.socket(AF_INET, SOCK_DGRAM) s.bind(("0.0.0.0", 1234)) while True: s.recvmmsg([...])
Já preparamos o
código , execute:
$ ./dropping-packets/recvmmsg-loop packets=171261 bytes=1940176
Essa solução permite que o kernel retire apenas 175 mil pacotes da fila de hardware, conforme foi medido pelo
ethtool e
mmwatch :
$ mmwatch 'ethtool -S ext0|grep rx_2' rx2_packets: 174.0k/s
Tecnicamente, 14 milhões de pacotes por segundo chegam ao servidor; no entanto, um núcleo de processador não pode lidar com esse volume.
mpstat confirma isso:
$ watch 'mpstat -u -I SUM -P ALL 1 1|egrep -v Aver' 01:32:05 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle 01:32:06 PM 0 0.00 0.00 0.00 2.94 0.00 3.92 0.00 0.00 0.00 93.14 01:32:06 PM 1 2.17 0.00 27.17 0.00 0.00 0.00 0.00 0.00 0.00 70.65 01:32:06 PM 2 0.00 0.00 0.00 0.00 0.00 100.00 0.00 0.00 0.00 0.00 01:32:06 PM 3 0.95 0.00 1.90 0.95 0.00 3.81 0.00 0.00 0.00 92.38
Como podemos ver, o aplicativo não é um gargalo: a CPU nº 1 é usada em 27,17% + 2,17%, enquanto a manipulação de interrupção ocupa 100% na CPU nº 2.
O uso de
recvmessagge(2) desempenha um papel importante. Depois que a vulnerabilidade Spectre foi descoberta, as chamadas do sistema ficaram ainda mais caras devido ao
KPTI e à
retpoline usada no kernel
$ tail -n +1 /sys/devices/system/cpu/vulnerabilities/* ==> /sys/devices/system/cpu/vulnerabilities/meltdown <== Mitigation: PTI ==> /sys/devices/system/cpu/vulnerabilities/spectre_v1 <== Mitigation: __user pointer sanitization ==> /sys/devices/system/cpu/vulnerabilities/spectre_v2 <== Mitigation: Full generic retpoline, IBPB, IBRS_FW
Etapa 2. Matando o conntrack
Realizamos essa carga especificamente com IP e porta remetente diferentes para carregar o conntrack o máximo possível. O número de entradas no conntrack durante o teste tende ao máximo possível e podemos verificar isso:
$ conntrack -C 2095202 $ sysctl net.netfilter.nf_conntrack_max net.netfilter.nf_conntrack_max = 2097152
Além disso, no
dmesg você também pode ver os gritos do conntrack:
[4029612.456673] nf_conntrack: nf_conntrack: table full, dropping packet [4029612.465787] nf_conntrack: nf_conntrack: table full, dropping packet [4029617.175957] net_ratelimit: 5731 callbacks suppressed
Então, vamos desligá-lo:
iptables -t raw -I PREROUTING -d 198.18.0.12 -p udp -m udp --dport 1234 -j NOTRACK
E reinicie os testes:
$ ./dropping-packets/recvmmsg-loop packets=331008 bytes=5296128
Isso nos permitiu atingir a marca de 333 mil pacotes por segundo. Viva!
PS Usando SO_BUSY_POLL, podemos alcançar até 470 mil por segundo; no entanto, este é um tópico para uma postagem separada.
Etapa 3. Filtro de lote de Berkeley
Vamos seguir em frente. Por que precisamos entregar pacotes para o aplicativo? Embora essa não seja uma solução comum, podemos vincular o filtro de pacotes clássico de Berkeley ao soquete chamando
setsockopt(SO_ATTACH_FILTER) e configurar o filtro para
setsockopt(SO_ATTACH_FILTER) pacotes no kernel.
Prepare o
código , execute:
$ ./bpf-drop packets=0 bytes=0
Usando um filtro de pacotes (os filtros clássicos e avançados de Berkeley oferecem desempenho aproximadamente semelhante), chegamos a cerca de 512 mil pacotes por segundo. Além disso, soltar um pacote durante uma interrupção libera o processador de ter que ativar o aplicativo.
Etapa 4. iptables DROP após o roteamento
Agora podemos descartar pacotes adicionando a seguinte regra ao iptables na cadeia INPUT:
iptables -I INPUT -d 198.18.0.12 -p udp --dport 1234 -j DROP
Deixe-me lembrá-lo de que já desativamos o conntrack com a regra
-j NOTRACK . Essas duas regras nos dão 608 mil pacotes por segundo.
Vejamos os números no iptables:
$ mmwatch 'iptables -L -v -n -x | head' Chain INPUT (policy DROP 0 packets, 0 bytes) pkts bytes target prot opt in out source destination 605.9k/s 26.7m/s DROP udp -- * * 0.0.0.0/0 198.18.0.12 udp dpt:1234
Bem, não é ruim, mas podemos fazer melhor.
Etapa 5. iptabes DROP em PREROUTING
Uma técnica mais rápida é descartar pacotes antes de rotear usando esta regra:
iptables -I PREROUTING -t raw -d 198.18.0.12 -p udp --dport 1234 -j DROP
Isso nos permite eliminar 1,68 milhão de pacotes por segundo.
De fato, este é um salto ligeiramente surpreendente no desempenho. Ainda não entendo os motivos, talvez o nosso roteamento seja complicado ou talvez apenas um bug na configuração do servidor.
De qualquer forma, as tabelas de ip brutas são muito mais rápidas.
Etapa 6. nftables DROP
O utilitário iptables agora é um pouco antigo. Ela foi substituída por nftables. Confira
esta explicação em vídeo sobre por que o nftables é o melhor. O Nftables promete ser mais rápido que o iptables acinzentado por vários motivos, incluindo rumores de que as retpolinas desaceleram muito o iptables.
Mas nosso artigo ainda não trata de comparar iptables e nftables, então vamos tentar o mais rápido que pude:
nft add table netdev filter nft -- add chain netdev filter input { type filter hook ingress device vlan100 priority -500 \; policy accept \; } nft add rule netdev filter input ip daddr 198.18.0.0/24 udp dport 1234 counter drop nft add rule netdev filter input ip6 daddr fd00::/64 udp dport 1234 counter drop
Os contadores podem ser vistos assim:
$ mmwatch 'nft --handle list chain netdev filter input' table netdev filter { chain input { type filter hook ingress device vlan100 priority -500; policy accept; ip daddr 198.18.0.0/24 udp dport 1234 counter packets 1.6m/s bytes 69.6m/s drop
O gancho de entrada nftables mostrou valores de cerca de 1,53 milhão de pacotes. Isso é um pouco menos que a cadeia PREROUTING no iptables. Mas há um mistério nisso: teoricamente, o gancho nftables é anterior ao PREROUTING iptables e, portanto, deve ser processado mais rapidamente.
Em nosso teste, o nftables é um pouco mais lento que o iptables, mas o nftables é mais legal de qualquer maneira. : P
Etapa 7. tc DROP
De maneira inesperada, o gancho tc (controle de tráfego) acontece antes do iptables PREROUTING. O tc nos permite selecionar pacotes de acordo com critérios simples e, é claro, descartá-los. A sintaxe é um pouco incomum, por isso sugerimos o uso
desse script para configuração. E precisamos de uma regra bastante complicada que se parece com isso:
tc qdisc add dev vlan100 ingress tc filter add dev vlan100 parent ffff: prio 4 protocol ip u32 match ip protocol 17 0xff match ip dport 1234 0xffff match ip dst 198.18.0.0/24 flowid 1:1 action drop tc filter add dev vlan100 parent ffff: protocol ipv6 u32 match ip6 dport 1234 0xffff match ip6 dst fd00::/64 flowid 1:1 action drop
E podemos verificar em ação:
$ mmwatch 'tc -s filter show dev vlan100 ingress' filter parent ffff: protocol ip pref 4 u32 filter parent ffff: protocol ip pref 4 u32 fh 800: ht divisor 1 filter parent ffff: protocol ip pref 4 u32 fh 800::800 order 2048 key ht 800 bkt 0 flowid 1:1 (rule hit 1.8m/s success 1.8m/s) match 00110000/00ff0000 at 8 (success 1.8m/s ) match 000004d2/0000ffff at 20 (success 1.8m/s ) match c612000c/ffffffff at 16 (success 1.8m/s ) action order 1: gact action drop random type none pass val 0 index 1 ref 1 bind 1 installed 1.0/s sec Action statistics: Sent 79.7m/s bytes 1.8m/s pkt (dropped 1.8m/s, overlimits 0 requeues 0)
O gancho tc nos permitiu lançar até 1,8 milhão de pacotes por segundo em um único núcleo. Isso é ótimo!
Mas podemos fazê-lo ainda mais rápido ...
Etapa 8. XDP_DROP
E, finalmente, a nossa arma mais forte: XDP -
eXpress Data Path . Usando o XDP, podemos executar o código estendido do Berkley Packet Filter (eBPF) diretamente no contexto do driver de rede e, o mais importante, mesmo antes de alocar memória para o
skbuff , o que nos promete um aumento na velocidade.
Normalmente, um projeto XDP consiste em duas partes:
- código eBPF para download
- carregador de inicialização que coloca o código na interface de rede correta
Escrever seu gerenciador de inicialização é uma tarefa difícil, portanto, basta usar o
novo chip iproute2 e carregar o código com um comando simples:
ip link set dev ext0 xdp obj xdp-drop-ebpf.o
Ta Dam!
O código fonte do
programa eBPF para
download está disponível aqui . O programa analisa características de pacotes IP como o protocolo UDP, sub-rede do remetente e porta de destino:
if (h_proto == htons(ETH_P_IP)) { if (iph->protocol == IPPROTO_UDP && (htonl(iph->daddr) & 0xFFFFFF00) == 0xC6120000 // 198.18.0.0/24 && udph->dest == htons(1234)) { return XDP_DROP; } }
O programa XDP deve ser construído usando clang moderno, que pode gerar bytecode BPF. Depois disso, podemos baixar e testar a funcionalidade do programa BFP:
$ ip link show dev ext0 4: ext0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 xdp qdisc fq state UP mode DEFAULT group default qlen 1000 link/ether 24:8a:07:8a:59:8e brd ff:ff:ff:ff:ff:ff prog/xdp id 5 tag aedc195cc0471f51 jited
E então veja as estatísticas no
ethtool :
$ mmwatch 'ethtool -S ext0|egrep "rx"|egrep -v ": 0"|egrep -v "cache|csum"' rx_out_of_buffer: 4.4m/s rx_xdp_drop: 10.1m/s rx2_xdp_drop: 10.1m/s
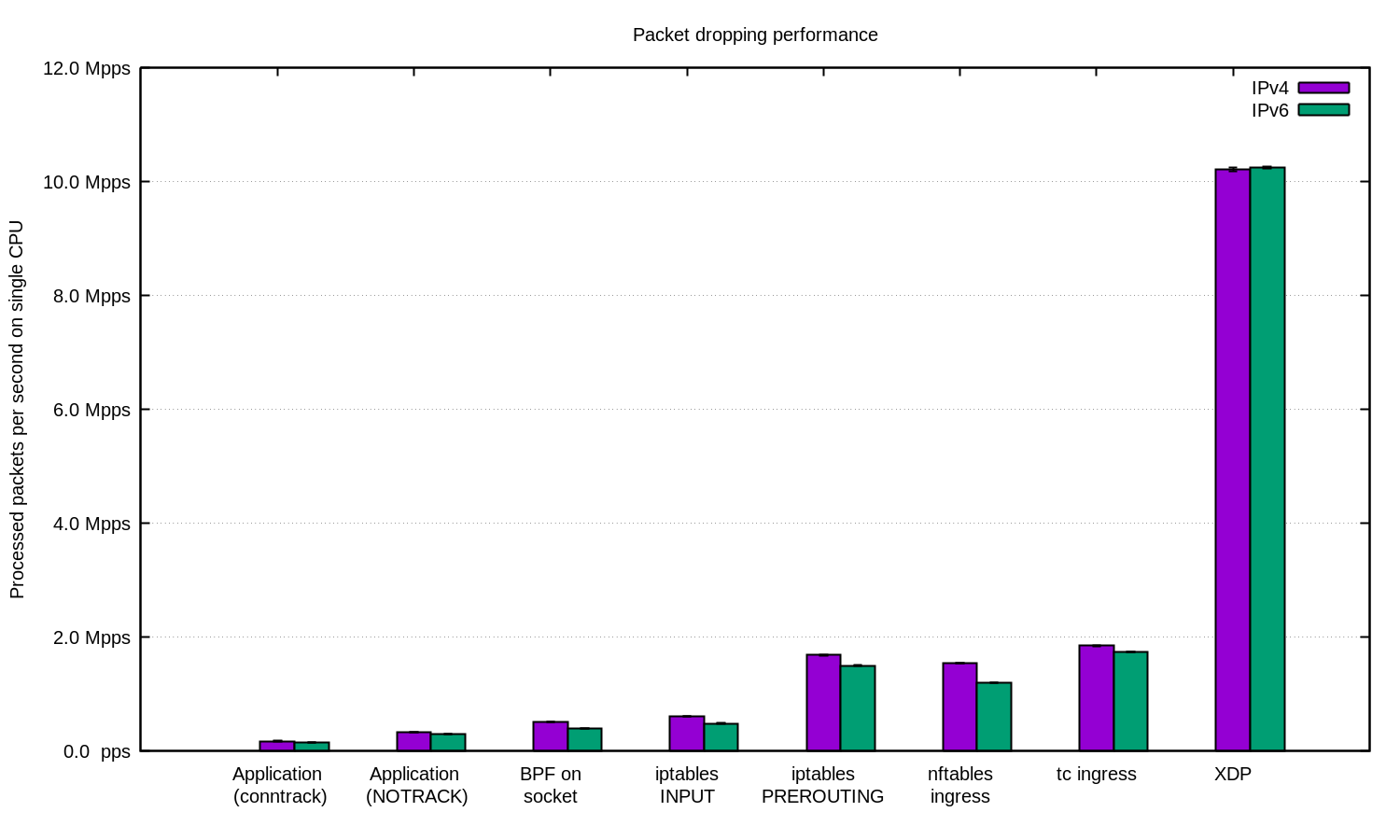
Yoo hoo! Com o XDP, podemos perder até 10 milhões de pacotes por segundo!
 Foto: Andrew Filer , CC BY-SA 2.0
Foto: Andrew Filer , CC BY-SA 2.0Conclusões
Repetimos o experimento para IPv4 e IPv6 e preparamos este diagrama:
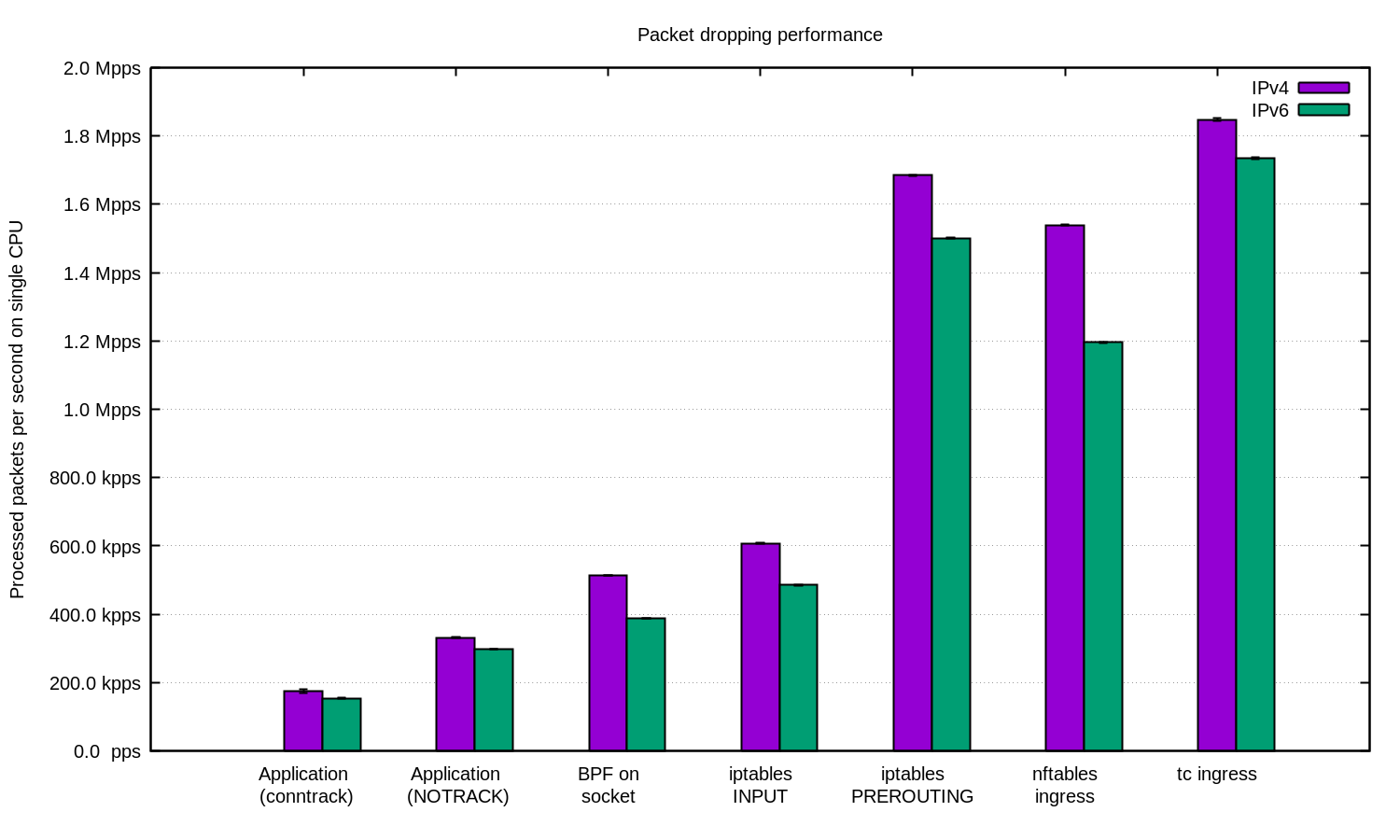
Em geral, pode-se argumentar que nossa configuração para o IPv6 é um pouco mais lenta. Mas como os pacotes IPv6 são um pouco maiores, é esperada a diferença de velocidade.
O Linux tem muitas maneiras de filtrar pacotes, cada um com sua própria velocidade e complexidade.
Para se proteger contra DDoS, é bastante razoável dar pacotes ao aplicativo e processá-los lá. Um aplicativo bem ajustado pode mostrar bons resultados.
Para ataques DDoS com IP aleatório ou falsificado, pode ser útil desativar o conntrack para obter um pequeno aumento na velocidade, mas tenha cuidado: há ataques contra os quais o conntrack é muito útil.
Em outros casos, faz sentido adicionar o firewall do Linux como uma das maneiras de mitigar o ataque DDoS. Em alguns casos, é melhor usar a tabela "-t raw PREROUTING", pois é muito mais rápida que a tabela de filtros.
Para os casos mais avançados, sempre usamos XDP. E sim, isso é uma coisa muito poderosa. Aqui está um gráfico como acima, apenas com XDP:
Se você deseja repetir o experimento, aqui está o
README, no qual documentamos tudo .
Nós da CloudFlare usamos ... quase todas essas técnicas. Alguns truques no espaço do usuário são integrados aos nossos aplicativos. A técnica iptables é encontrada em nosso
Gatebot . Finalmente, substituímos nossa própria solução principal por XDP.
Muito obrigado a
Jesper Dangaard Brouer por sua ajuda.