
Para nossa grande surpresa, não havia um único material sobre a maravilhosa ferramenta Open Source para backup de dados -
Borg (não confunda com o progenitor de mesmo nome Kubernetes!) . Como o usamos na produção há mais de um ano, neste artigo, compartilharei as "impressões" que obtivemos sobre a Borg.
Antecedentes: Experiência com Bacula e Bareos
Em 2017, estávamos cansados de Bacula e Bareos, que usamos desde o início de nossa atividade (ou seja, cerca de 9 anos de produção na época). Porque Durante a operação, acumulamos muito descontentamento:
- O SD (Daemon de Armazenamento) congela. Se você configurou o paralelismo, a manutenção do SD se tornará mais complicada e seu congelamento bloqueará outros backups dentro do cronograma e a possibilidade de recuperação.
- É necessário gerar configurações para o cliente e o diretor. Mesmo se automatizarmos isso (no nosso caso, Chef, Ansible e nosso próprio desenvolvimento foram usados em momentos diferentes), precisamos monitorar que o diretor, após sua recarga, realmente pegou a configuração. Isso é rastreado apenas na saída do comando reload e na chamada de mensagens após (para obter o próprio texto do erro).
- Agende backups. Os desenvolvedores do Bacula decidiram seguir seu próprio caminho e escreveram seu próprio formato de programação, que você não pode simplesmente analisar ou converter para outro. Aqui estão exemplos de agendamentos de backup padrão em nossas instalações antigas:
- Backup completo diário às quartas-feiras e incremental em outros dias:
Run = Level=Full Pool="Foobar-low7" wed at 18:00
Run = Level=Incremental Pool="Foobar-low7" at 18:00 - Backup completo de arquivos wal 2 vezes por mês e incremento a cada hora:
Run = Level=Full FullPool=CustomerWALPool 1st fri at 01:45
Run = Level=Full FullPool=CustomerWALPool 3rd fri at 01:45
Run = Level=Incremental FullPool=CustomerWALPool IncrementalPool=CustomerWALPool on hourly - O
schedule gerado para todas as ocasiões (em diferentes dias da semana a cada 2 horas) chegamos a 1665 ... por causa do que Bacula / Bareos periodicamente enlouquecia.
- O Bacula-fd (e bareos-fd) possui diretórios com muitos dados (por exemplo, 40 TB, dos quais 35 TB contêm arquivos grandes [100 + MB], e os 5 TB restantes contêm arquivos pequenos [1 KB a 100 MB ]) começa um vazamento lento de memória, o que é uma situação muito desagradável na produção.
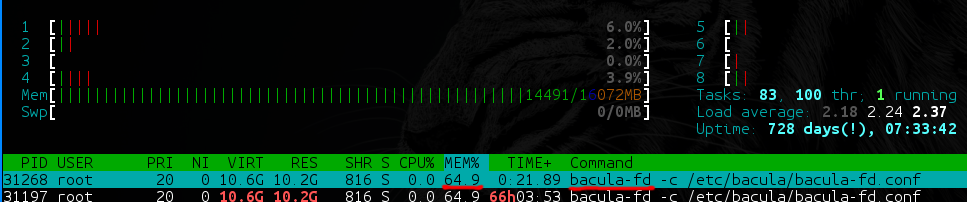
- Em backups com um grande número de arquivos, o Bacula e o Bareos dependem muito do desempenho do DBMS usado. Que unidades possui? Com que habilidade você sabe como ajustá-la a essas necessidades específicas? E no banco de dados, a propósito, uma (!) Tabela não particionável é criada com uma lista de todos os arquivos em todos os backups e a segunda - com uma lista de todos os caminhos em todos os backups. Se você não estiver pronto para alocar pelo menos 8 GB de RAM para a base + 40 GB de SSD para o servidor de backup - prepare-se imediatamente para os freios.
- A dependência do banco de dados merece mais um ponto. Bacula / Bareos para cada arquivo pergunta ao diretor se já existe um arquivo. O diretor, é claro, rastreia o banco de dados, as tabelas muito grandes ... Acontece que o backup pode ser bloqueado simplesmente pelo fato de vários backups pesados terem iniciado ao mesmo tempo - mesmo que o diff tenha vários megabytes.
Seria injusto dizer que nenhum problema foi resolvido, mas chegamos ao ponto em que estávamos realmente cansados de várias soluções alternativas e queríamos uma solução confiável "aqui e agora".
Bacula / Bareos funcionam muito bem com um pequeno número (10 a 30) de trabalhos uniformes. Alguma coisa quebrou uma vez por semana? Está tudo bem: eles deram a tarefa ao oficial de serviço (ou outro engenheiro) - eles a consertaram. No entanto, temos projetos em que o número de trabalhos é de centenas e o número de arquivos neles é de centenas de milhares. Como resultado, 5 minutos por semana para corrigir o backup (sem contar várias horas de configurações antes disso) começaram a se multiplicar. Tudo isso levou ao fato de que 2 horas por dia eram necessárias para corrigir backups em todos os projetos, porque literalmente em todos os lugares havia algo insignificante ou seriamente danificado.
Alguém pode pensar que um engenheiro dedicado dedicado a isso deve fazer backups. Certamente, ele será o mais barbudo e severo possível e, pelo seu olhar, os backups são reparados instantaneamente, enquanto ele bebe calmamente o café. E essa idéia pode ser verdadeira de alguma forma ... Mas sempre existe um mas. Nem todos podem se dar ao luxo de reparar e monitorar backups 24 horas por dia, e mais ainda - um engenheiro alocado para esses fins. Temos certeza de que é melhor gastar essas 2 horas por dia em algo mais produtivo e útil. Portanto, passamos à busca de soluções alternativas que “simplesmente funcionem”.
Borg como uma nova maneira
A busca por outras opções de código aberto foi espalhada ao longo do tempo, por isso é difícil estimar os custos totais, mas em um ponto (no ano passado), nossa atenção se voltou para o "
herói da ocasião" -
BorgBackup (ou simplesmente Borg). Em parte, isso foi facilitado pela experiência real de seu uso por um de nossos engenheiros (no local de trabalho anterior).
O Borg é escrito em Python (versão> = 3.4.0 é necessária) e código exigente de desempenho (compactação, criptografia, etc.) é implementado em C / Cython. Distribuído sob uma licença BSD gratuita (3 cláusulas). Ele suporta muitas plataformas, incluindo Linux, * BSD, macOS, bem como no nível experimental Cygwin e Linux Subsystem do Windows 10. Para instalar o BorgBackup, os pacotes estão disponíveis para distribuições populares do Linux e outros sistemas operacionais, bem como códigos-fonte, que também podem ser instalados via pip, - informações mais detalhadas sobre isso podem ser encontradas na
documentação do
projeto .
Por que Borg nos subornou tanto? Aqui estão suas principais vantagens:
A transição para Borg começou lentamente em pequenos projetos. No início, eram scripts cron simples que faziam seu trabalho todos os dias. Isso durou cerca de seis meses. Durante esse período, tivemos que fazer backups várias vezes ... e acabou que o Borg não precisou ser reparado literalmente! Porque Como o princípio simples funciona aqui: "Quanto mais simples o mecanismo, menos lugares onde ele se romperá".
Prática: como fazer backup com o Borg?
Considere um exemplo simples de criação de um backup:
- Faça o download do binário da versão mais recente no servidor de backup e na máquina que iremos fazer backup no repositório oficial :
sudo wget https://github.com/borgbackup/borg/releases/download/1.1.6/borg-linux64 -O /usr/local/bin/borg sudo chmod +x /usr/local/bin/borg
Nota : Se você usar uma máquina local para o teste como fonte e como receptor, toda a diferença estará apenas no URI, que passaremos adiante, mas lembramos que o backup precisa ser armazenado separadamente e não na mesma máquina. - No servidor de backup, crie o usuário
borg :
sudo useradd -m borg
Simples: sem grupos e com um shell padrão, mas sempre com um diretório inicial. - Uma chave SSH é gerada no cliente:
ssh-keygen
- No servidor, adicione a chave gerada ao usuário
borg :
mkdir ~borg/.ssh echo 'command="/usr/local/bin/borg serve" ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDNdaDfqUUf/XmSVWfF7PfjGlbKW00MJ63zal/E/mxm+vJIJRBw7GZofe1PeTpKcEUTiBBEsW9XUmTctnWE6p21gU/JNU0jITLx+vg4IlVP62cac71tkx1VJFMYQN6EulT0alYxagNwEs7s5cBlykeKk/QmteOOclzx684t9d6BhMvFE9w9r+c76aVBIdbEyrkloiYd+vzt79nRkFE4CoxkpvptMgrAgbx563fRmNSPH8H5dEad44/Xb5uARiYhdlIl45QuNSpAdcOadp46ftDeQCGLc4CgjMxessam+9ujYcUCjhFDNOoEa4YxVhXF9Tcv8Ttxolece6y+IQM7fbDR' > ~borg/.ssh/authorized_keys chown -R borg:borg ~borg/.ssh / bin local / Borg servir" ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDNdaDfqUUf / XmSVWfF7PfjGlbKW00MJ63zal / E / mxm + vJIJRBw7GZofe1PeTpKcEUTiBBEsW9XUmTctnWE6p21gU / JNU0jITLx + vg4IlVP62cac71tkx1VJFMYQN6EulT0alYxagNwEs7s5cBlykeKk / QmteOOclzx684t9d6BhMvFE9w9r + c76aVBIdbEyrkloiYd + vzt79nRkFE4CoxkpvptMgrAgbx563fRmNSPH8H5dEad44 / Xb5uARiYhdlIl45QuNSpAdcOadp46ftDeQCGLc4CgjMxessam + 9ujYcUCjhFDNOoEa4YxVhXF9Tcv8Ttxolece6y + IQM7fbDR'> ~ Borg / .ssh mkdir ~borg/.ssh echo 'command="/usr/local/bin/borg serve" ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDNdaDfqUUf/XmSVWfF7PfjGlbKW00MJ63zal/E/mxm+vJIJRBw7GZofe1PeTpKcEUTiBBEsW9XUmTctnWE6p21gU/JNU0jITLx+vg4IlVP62cac71tkx1VJFMYQN6EulT0alYxagNwEs7s5cBlykeKk/QmteOOclzx684t9d6BhMvFE9w9r+c76aVBIdbEyrkloiYd+vzt79nRkFE4CoxkpvptMgrAgbx563fRmNSPH8H5dEad44/Xb5uARiYhdlIl45QuNSpAdcOadp46ftDeQCGLc4CgjMxessam+9ujYcUCjhFDNOoEa4YxVhXF9Tcv8Ttxolece6y+IQM7fbDR' > ~borg/.ssh/authorized_keys chown -R borg:borg ~borg/.ssh
- Inicializamos o repositório borg no servidor a partir do cliente:
ssh borg@172.17.0.3 hostname
A opção -e é usada para selecionar o método de criptografia para o repositório (sim, você também pode criptografar cada repositório com sua senha!). Nesse caso, porque este é um exemplo, não usamos criptografia. MyBorgRepo é o nome do diretório em que o borg repo estará (você não precisa criá-lo com antecedência - o Borg fará tudo sozinho). - Inicie o primeiro backup usando o Borg:
borg create --stats --list borg@172.17.0.3:MyBorgRepo::"MyFirstBackup-{now:%Y-%m-%d_%H:%M:%S}" /etc /root
Sobre as teclas:
--stats e --list nos fornecem estatísticas sobre backup e arquivos que entraram nele;borg@172.17.0.3:MyBorgRepo - tudo está claro aqui, este é o nosso servidor e diretório. E o que vem pela mágica? ..::"MyFirstBackup-{now:%Y-%m-%d_%H:%M:%S}" é o nome do arquivo dentro do repositório. É arbitrário, mas seguimos o formato _-timestamp (timestamp no formato Python).
O que vem a seguir? Obviamente, veja o que aconteceu com nosso backup! Lista de arquivos dentro do repositório:
borg@b3e51b9ed2c2:~$ borg list MyBorgRepo/ Warning: Attempting to access a previously unknown unencrypted repository! Do you want to continue? [yN] y MyFirstBackup-2018-08-04_16:55:53 Sat, 2018-08-04 16:55:54 [89f7b5bccfb1ed2d72c8b84b1baf477a8220955c72e7fcf0ecc6cd5a9943d78d]
Vemos um backup com um carimbo de data e hora e como Borg nos pergunta se realmente queremos acessar um repositório não criptografado em que nunca estivemos antes.
Nós olhamos para a lista de arquivos:
borg list MyBorgRepo::MyFirstBackup-2018-08-04_16:55:53
Nós obtemos o arquivo do backup (você também pode todo o diretório):
borg@b3e51b9ed2c2:~$ borg extract MyBorgRepo::MyFirstBackup-2018-08-04_16:55:53 etc/hostname borg@b3e51b9ed2c2:~$ ll etc/hostname -rw-r--r-- 1 borg borg 13 Aug 4 16:27 etc/hostname
Parabéns, seu primeiro backup da Borg está pronto!
Prática: automatize isso [com o GitLab]!
Depois de agrupar tudo isso em scripts, configuramos backups manualmente de maneira semelhante em aproximadamente 40 hosts. Percebendo que Borg realmente funciona, eles começaram a transferir projetos cada vez maiores ...
E aqui estamos diante do que está em Bareos, mas não no Borg! A saber: WebUI ou algum tipo de local centralizado para configurar backups. E realmente esperamos que este seja um fenômeno temporário, mas até agora tivemos que resolver alguma coisa. Pesquisando as ferramentas prontas e reunindo-nos em uma videoconferência, começamos a trabalhar. Havia uma ótima idéia de integrar o Borg aos nossos serviços internos, como fizemos anteriormente com o Bacula (o próprio Bacula retirou a lista de trabalhos de nossa API centralizada, na qual tínhamos nossa própria interface integrada com outras configurações do projeto). Pensamos em como fazê-lo, esboçamos um plano de como e onde construí-lo, mas ... Agora são necessários backups normais, mas não há lugares para se fazer planos de tempo grandiosos. O que fazer
As perguntas e os requisitos foram aproximadamente os seguintes:
- O que usar como gerenciamento de backup centralizado?
- O que qualquer administrador Linux pode fazer?
- O que um gerente que mostra uma programação de backup para os clientes pode entender e configurar?
- O que uma tarefa agendada faz no seu sistema todos os dias?
- O que não será difícil de configurar e não quebrará?
A resposta foi óbvia: esse é o bom e velho crond, que heroicamente cumpre seu dever todos os dias. Simples. Não congela. Até o gerente que é do Unix para “você” pode consertar isso.
Então crontab, mas onde você guarda tudo isso? É sempre o momento de ir para a máquina do projeto e editar o arquivo com as mãos? Claro que não. Podemos colocar nossa programação no repositório Git e configurar o GitLab Runner, que por commit o atualizará no host.
Nota : Foi o GitLab que foi escolhido como uma ferramenta de automação, porque é conveniente para a tarefa e, no nosso caso, está em quase todos os lugares. Mas devo dizer que ele não é de forma alguma uma necessidade.Você pode expandir o crontab para backups por uma ferramenta de automação familiar ou geralmente manualmente (em pequenos projetos ou instalações domésticas).
Então, aqui está o que você precisa para automação simples:
1.
GitLab e um repositório , no qual, para começar, haverá dois arquivos:
schedule - agenda de backupborg_backup_files.sh - um script simples para fazer backup de arquivos (como no exemplo acima).
Exemplo de
schedule :
As variáveis de IC são usadas para verificar se a atualização do crontab foi bem-sucedida e
CI_PROJECT_DIR é o diretório no qual o repositório estará após a clonagem do corredor. A última linha indica que o backup é realizado todos os dias à meia-noite.
Exemplo
borg_backup_files.sh :
O primeiro argumento aqui é o nome do backup e o
segundo é a lista de diretórios para o backup, separados por vírgulas. A rigor, uma lista também pode ser um conjunto de arquivos separados.
2.
GitLab Runner , executando na máquina que precisa ser copiada e bloqueado apenas para as tarefas deste repositório.
3.
O próprio script de IC , implementado pelo
.gitlab-ci.yml :
stages: - deploy Deploy: stage: deploy script: - export TIMESTAMP=$(date '+%Y.%m.%d %H:%M:%S') - cat schedule | envsubst | crontab - tags: - borg-backup
4. A
chave SSH para o usuário
gitlab-runner com acesso ao servidor de
gitlab-runner (no exemplo, é 10.100.1.1). Por padrão, ele deve estar no diretório inicial do
.ssh/id_rsa (
gitlab-runner ).
5.
O usuário borg no mesmo 10.100.1.1 com acesso apenas ao comando
borg serve :
$ cat .ssh/authorized_keys command="/usr/bin/borg serve" ssh-rsa AAAAB3NzaC1yc2EAA...
Agora, quando você se comprometer com o repositório Runner, ele preencherá o conteúdo do crontab. E quando chegar o tempo de resposta do cron, será realizado um backup dos diretórios
/etc e
/opt , que estará no servidor de backup no diretório
MyHostname-SYSTEM do servidor 10.100.1.1.

Em vez de uma conclusão: o que mais você pode fazer?
O uso de Borg nisso, é claro, não termina aí. Aqui estão algumas idéias para futuras implementações, algumas das quais já implementamos em casa:
- Adicione scripts universais para diferentes backups, que no final da execução executam
borg_backup_files.sh , direcionados ao diretório com o resultado de seu trabalho. Por exemplo, você pode fazer backup de PostgreSQL (pg_basebackup), MySQL (innobackupex), GitLab (trabalho de rake interno, criando um arquivo morto). - Host central com agendamento para backup . Não configurar em cada host GitLab Runner? Deixe-o sozinho no servidor de backup e o crontab na inicialização transfere o script de backup para a máquina e o executa lá. Para isso, é claro, você precisará do usuário
borg na máquina cliente e no ssh-agent , para não colocar a chave do servidor de backup em cada máquina. - Monitoramento Onde sem ele! Os alertas sobre um backup concluído incorretamente devem ser.
- Limpando o repositório borg de arquivos antigos. Apesar da boa desduplicação, os backups antigos ainda precisam ser limpos. Para fazer isso, você pode fazer uma chamada para
borg prune no final do script de backup. - Interface da Web para o agendamento. Será útil se editar o crontab manualmente ou na interface da Web não parecer sólido / desconfortável para você.
- Gráficos de pizza . Alguns gráficos para uma representação visual da porcentagem de backups concluídos com sucesso, seu tempo de execução e a largura do canal "comido". Não é à toa que escrevi que não há WebUI suficiente, como no Bareos ...
- Ações simples que eu gostaria de receber por um botão: iniciar um backup sob demanda, restaurar em uma máquina etc.
E no final, gostaria de adicionar um exemplo da eficácia da desduplicação em um backup real de trabalho dos arquivos WAL do PostgreSQL em um ambiente de produção:
borg@backup ~ $ borg info PROJECT-PG-WAL Repository ID: 177eeb28056a60487bdfce96cfb33af1c186cb2a337226bc3d5380a78a6aeeb6 Location: /mnt/borg/PROJECT-PG-WAL Encrypted: No Cache: /mnt/borg/.cache/borg/177eeb28056a60487bdfce96cfb33af1c186cb2a337226bc3d5380a78a6aeeb6 Security dir: /mnt/borg/.config/borg/security/177eeb28056a60487bdfce96cfb33af1c186cb2a337226bc3d5380a78a6aeeb6 ------------------------------------------------------------------------------ Original size Compressed size Deduplicated size All archives: 6.68 TB 6.70 TB 19.74 GB Unique chunks Total chunks Chunk index: 11708 3230099
São 65 dias de backup dos arquivos WAL que são feitos a cada hora. Ao usar Bacula / Bareos, ou seja, sem desduplicação, obteríamos 6,7 TB de dados. Basta pensar: podemos armazenar quase 7 terabytes de dados passados pelo PostgreSQL, apenas 20 GB de espaço ocupado.
PS
Leia também em nosso blog: