O desenvolvimento de software é considerado um processo pouco mensurável e parece que, para gerenciá-lo efetivamente, você precisa de um toque especial. E se a intuição com inteligência emocional não for muito desenvolvida, inevitavelmente os termos mudarão, a qualidade do produto diminuirá e a velocidade de entrega diminuirá.
 Sergei Semenov
Sergei Semenov acredita que isso acontece principalmente por duas razões.
- Não há ferramentas e padrões para avaliar o trabalho dos programadores. Os gerentes precisam recorrer à avaliação subjetiva, que por sua vez leva a erros.
- Nenhum meio de controle automático dos processos na equipe é usado. Sem o controle adequado, os processos nas equipes de desenvolvimento deixam de cumprir suas funções, pois começam a ser parcialmente executados ou simplesmente ignorados.
E oferece uma abordagem para a avaliação e controle de processos com base em dados objetivos.
Abaixo está uma versão em vídeo e texto do relatório de Sergey, que, de acordo com os resultados da votação da platéia, ficou em segundo lugar no
Saint TeamLead Conf .
Sobre o palestrante: Sergey Semenov ( sss0791 ) trabalha com TI há 9 anos, foi desenvolvedor, líder de equipe, gerente de produtos, agora CEO da GitLean. O GitLean é um produto analítico para gerentes, diretores técnicos e líderes de equipe, projetado para tomar decisões objetivas de gerenciamento. A maioria dos exemplos nesta história é baseada não apenas na experiência pessoal, mas também na experiência de empresas clientes com equipe de desenvolvimento de 6 a 200 pessoas.Já com meu colega Alexander Kiselev, falamos sobre a
avaliação de desenvolvedores em fevereiro no TeamLead Conf anterior. Não vou me debruçar sobre isso em detalhes, mas vou me referir a um artigo sobre algumas métricas. Hoje falaremos sobre processos e como controlá-los e medi-los.
Fontes de dados
Se estamos falando de medições, seria bom entender onde obter os dados. Primeiro de tudo, temos:
- Git com informações de código;
- Jira ou qualquer outro rastreador de tarefas com informações sobre tarefas;
- GitHub , Bitbucket, Gitlab com informações de revisão de código.
Além disso, existe um mecanismo tão interessante quanto a coleta de várias avaliações subjetivas. Farei uma reserva de que deve ser usada sistematicamente se quisermos confiar nesses dados.

Obviamente, sujeira e dor esperam por você nos dados - não há nada que você possa fazer sobre isso, mas isso não é tão assustador. O mais desagradável é que pode simplesmente não haver dados sobre o trabalho de seus processos nessas fontes. Isso pode ocorrer porque os processos foram construídos para que eles não deixem nenhum artefato nos dados.
A primeira regra que recomendamos seguir ao projetar e construir processos é fazê-los para que eles deixem artefatos nos dados. Você precisa criar não apenas o Agile, mas torná-lo
ágil mensurável.
Vou contar a história de horror que encontramos com um dos clientes que nos procurou com uma solicitação para melhorar a qualidade do produto. Para fazer você entender a escala, cerca de 30 a 40 erros de produção voaram para uma equipe de 15 desenvolvedores por semana. Eles começaram a entender os motivos e descobriram que 30% das tarefas não se enquadravam no status de "teste". Inicialmente, pensávamos que era apenas um erro de dados ou que os testadores não atualizavam o status da tarefa. Mas acabou que realmente 30% das tarefas simplesmente não são testadas. Houve um problema na infraestrutura, por causa do qual 1-2 tarefas na iteração não foram testadas. Então todos se esqueceram desse problema, os testadores pararam de falar sobre ele e, com o tempo, ele cresceu para 30%. Como resultado, isso levou a mais problemas globais.
Portanto, a primeira métrica importante para qualquer processo é deixar dados. Certifique-se de seguir isso.

Às vezes, por uma questão de mensurabilidade, você precisa sacrificar parte dos princípios do Agile e, por exemplo, em algum lugar prefere a comunicação escrita ao invés da oral.
A prática de vencimento, que implementamos em várias equipes para melhorar a previsibilidade, provou ser muito boa. Sua essência é a seguinte: quando o desenvolvedor pega a tarefa e a arrasta para "em andamento", ele deve definir a data de vencimento em que a tarefa será lançada ou pronta para lançamento. Essa prática ensina o desenvolvedor a ser um gerente condicional de microprojetos de suas próprias tarefas, ou seja, leva em conta dependências externas e entende que a tarefa está pronta apenas quando o cliente pode usar seu resultado.
Para que o treinamento ocorra, após a data de vencimento, o desenvolvedor precisa ir a Jira e definir uma nova data de vencimento e deixar comentários em um formulário específico, por que isso aconteceu. Parece por que essa burocracia é necessária. Mas, de fato, após duas semanas dessa prática, descarregamos todos esses comentários de Jira com um script simples e conduzimos uma retrospectiva com essa textura. Acontece muitas idéias sobre por que os prazos estão quebrados. Funciona muito bem, eu recomendo usá-lo.
Abordagem do problema
Na medição de processos, professamos a seguinte abordagem: precisamos proceder a partir de problemas. Imaginamos algumas práticas e processos ideais e depois somos criativos de que maneira eles podem não funcionar.
É necessário monitorar a violação de processos , e não como seguimos alguma prática. Os processos geralmente não funcionam, não porque as pessoas os violam maliciosamente, mas porque o desenvolvedor e o gerente não têm controle e memória suficientes para acompanhar todos eles. Ao rastrear violações de regulamentos, podemos lembrar automaticamente as pessoas do que precisa ser feito e obtemos controles automáticos.
Para entender quais processos e práticas você precisa implementar, você precisa entender por que fazer isso na equipe de desenvolvimento, o que os negócios precisam do desenvolvimento. Todo mundo entende que não é preciso tanto:
- que o produto é entregue por um período de previsão adequado;
- que o produto era de qualidade adequada, não necessariamente perfeito;
- para que tudo isso seja rápido o suficiente.
Ou seja,
previsibilidade, qualidade e velocidade são importantes. Portanto, analisaremos todos os problemas e métricas levando em consideração precisamente como eles afetam a previsibilidade e a qualidade. Dificilmente discutiremos a velocidade, por causa das quase 50 equipes com as quais trabalhamos de uma maneira ou de outra, apenas duas poderiam trabalhar com velocidade. Para aumentar a velocidade, você precisa ser capaz de medi-la, e para que seja pelo menos um pouco previsível, e isso é previsibilidade e qualidade.
Além de previsibilidade e qualidade, apresentamos uma direção como
disciplina . Chamaremos de disciplina tudo o que garantir o funcionamento básico dos processos e a coleta de dados, com base nos quais é realizada uma análise de problemas com previsibilidade e qualidade.
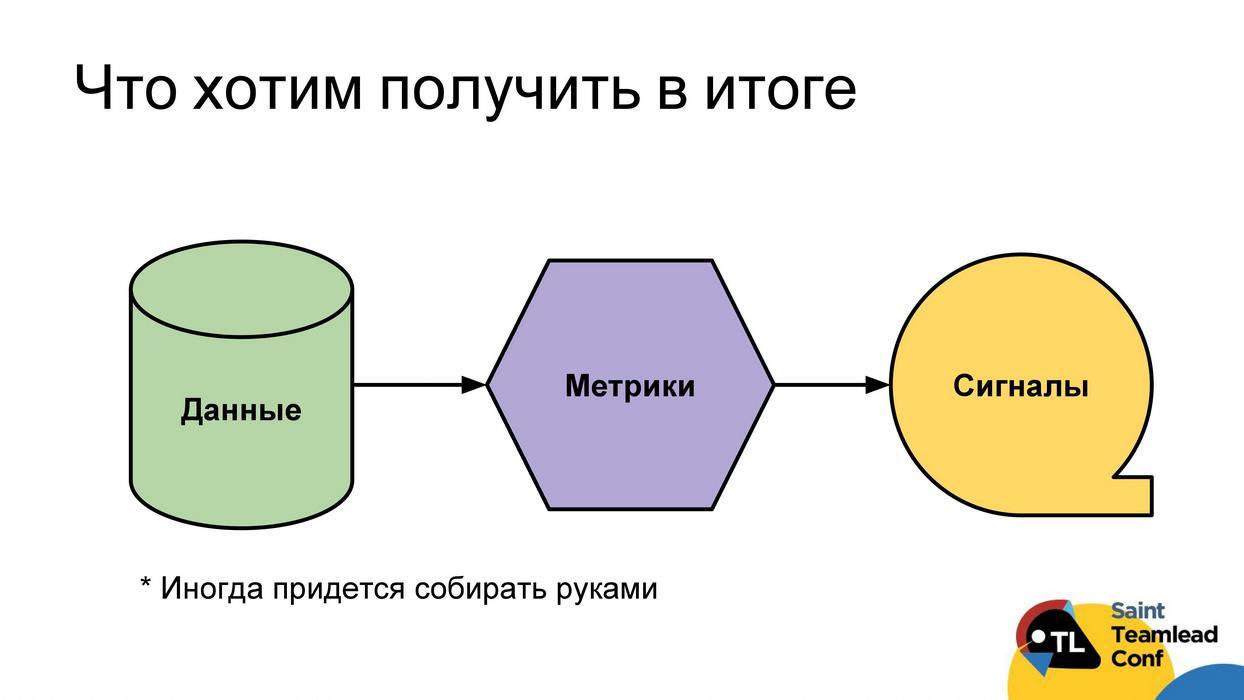
Idealmente, queremos criar o seguinte esquema de trabalho: para que tenhamos a coleta automática de dados; a partir desses dados, podemos construir métricas; Usando métricas para encontrar problemas Relate os problemas diretamente ao desenvolvedor, líder da equipe ou equipe. Todos poderão responder a eles em tempo hábil e lidar com os problemas encontrados. Devo dizer imediatamente que nem sempre é possível obter sinais compreensíveis. Às vezes, as métricas permanecerão apenas métricas que precisarão ser analisadas, ver valores, tendências e assim por diante. Mesmo com os dados, às vezes haverá um problema, às vezes eles não podem ser coletados automaticamente e você deve fazer isso manualmente (vou esclarecer esses casos separadamente).
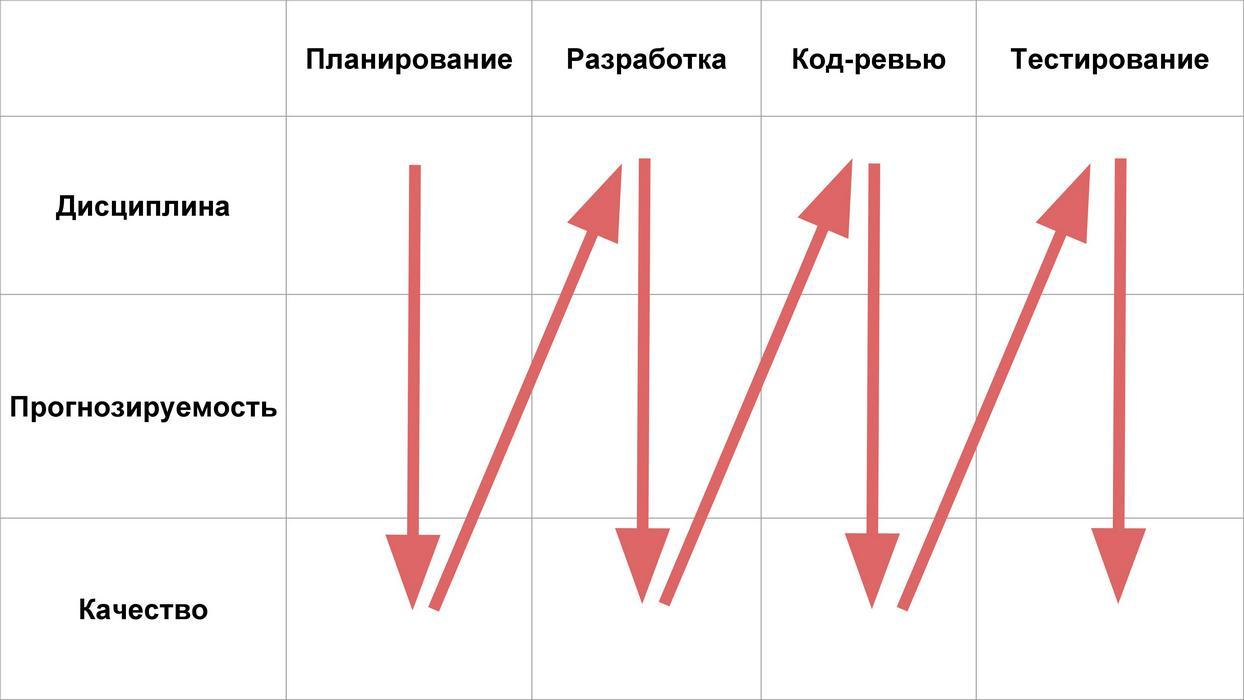
A seguir, consideramos quatro estágios da vida útil dos recursos:
E analisaremos quais problemas de disciplina, previsibilidade e qualidade podem estar em cada um desses estágios.
Problemas com a disciplina na fase de planejamento
Há muita informação, mas presto atenção aos pontos mais básicos. Eles podem parecer bastante simples, mas são confrontados com um número muito grande de equipes.

O primeiro problema que costuma surgir durante o planejamento é um
problema organizacional trivial - nem todo mundo que deveria estar presente está presente na reunião de planejamento.
Exemplo: uma equipe reclama que um testador está testando algo errado. Acontece que os testadores dessa equipe nunca vão ao planejamento. Ou, em vez de sentar e planejar algo, a equipe procura freneticamente um lugar para sentar, porque se esqueceu de reservar uma sala de reunião.
Métricas e sinais não precisam ser configurados, apenas verifique se você não tem esses problemas. A reunião foi marcada no calendário, todos foram convidados, o local foi escolhido. Não importa o quão engraçado possa parecer, isso é encontrado em diferentes equipes.
Agora discutiremos situações em que sinais e métricas são necessários. No estágio de planejamento, a maioria dos sinais sobre os quais falarei deve ser enviada à equipe cerca de uma hora após o término da reunião de planejamento, para não distrair a equipe no processo, mas ainda assim manter o foco.
O primeiro problema disciplinar é
que as tarefas não têm descrição ou são mal descritas. Isso é controlado elementarmente. Existe um formato ao qual as tarefas devem corresponder - verificamos se é assim. Por exemplo, seguimos que os critérios de aceitação estão definidos ou, para tarefas de front-end, há um link para o layout. Você também precisa acompanhar os componentes colocados, porque o formato da descrição geralmente está vinculado ao componente. Para uma tarefa de back-end, uma descrição é relevante; para uma tarefa de front-end, outra.

O próximo problema comum é que as
prioridades são faladas oralmente ou não são faladas e não são refletidas nos dados . Como resultado, ao final da iteração, as tarefas mais importantes não foram executadas. É necessário garantir que a equipe use prioridades e as use adequadamente. Se uma equipe tem 90% das tarefas na iteração, tem alta prioridade, é o mesmo que nenhuma prioridade.
Tentamos chegar a essa distribuição: 20% de tarefas de alta prioridade (você não pode deixar de descarregar); 60% - prioridade média; 20% - baixa prioridade (não é assustador se não a liberarmos). Penduramos sinais em tudo isso.

O último problema com a disciplina, que acontece no estágio de planejamento -
não há dados suficientes , inclusive para métricas subsequentes. Básicos: as tarefas não têm classificações (um sinal deve ser feito) ou os tipos de tarefas são inadequados. Ou seja, os bugs iniciam como tarefas, e as tarefas da dívida técnica não podem ser rastreadas. Infelizmente, não é possível controlar automaticamente o segundo tipo de problemas. Aconselhamos apenas uma vez a cada dois meses, especialmente se você é CTO e tem várias equipes, analisa o backlog e garante que as pessoas iniciem bugs como bugs, histórias como histórias, tarefas de dívida técnica como as de dívida técnica.
Problemas de previsibilidade no estágio de planejamento
Nos voltamos para problemas com previsibilidade.

O problema básico é
que não caímos nos prazos e nas estimativas; Infelizmente, é impossível encontrar algum tipo de sinal mágico ou métrica que resolva esse problema. A única maneira é incentivar a equipe a aprender melhor, analisar as causas dos erros com uma ou outra avaliação usando exemplos. E esse processo de aprendizado pode ser facilitado por meios automáticos.
A primeira coisa que pode ser feita é lidar com tarefas obviamente problemáticas com uma estimativa alta do tempo de execução. Desligamos o SLA e controlamos que todas as tarefas sejam bem decompostas o suficiente. Recomendamos no máximo dois dias para a execução começar e, em seguida, você pode passar para um dia.
O próximo parágrafo pode facilitar a coleta de artefatos, nos quais será possível realizar treinamento e analisar com a equipe por que ocorreu um erro na avaliação. Recomendamos o uso da prática da data de vencimento para isso. Ela provou ser muito legal aqui.
Outra maneira é uma métrica chamada código de rotatividade como parte da tarefa. Sua essência é que analisamos qual porcentagem do código na estrutura da tarefa foi escrita, mas não correspondeu à versão anterior (mais no último
relatório ). Essa métrica mostra como as tarefas são bem pensadas. Assim, seria bom prestar atenção aos problemas com os saltos de Churn e entendê-los, o que não levamos em consideração e por que cometemos um erro na avaliação.

A seguinte história é padrão: a equipe planejou algo, o sprint foi preenchido, mas no final
não fez nada do que havia planejado . Você pode configurar sinais para preencher, alterar prioridades, mas para a maioria das equipes com as quais fizemos isso, eles eram irrelevantes. Freqüentemente, essas são operações legais do gerente de produto para lançar algo no sprint, alterar a prioridade, para que haja muitos falsos positivos.
O que pode ser feito aqui? Calcule métricas básicas bastante padronizadas: fechamento do escoteiro inicial, número de lances no sprint, fechamento dos lances, mudança de prioridades, ver a estrutura dos lances. Depois disso, avalie quantas tarefas e erros você costuma lançar na iteração. Além disso, usando um sinal para controlar que você
está colocando essa cota no estágio de planejamento .
Problemas de qualidade na fase de planejamento
O primeiro problema: a
equipe não pensa na funcionalidade dos recursos lançados . Vou falar sobre qualidade em um sentido geral - um problema de qualidade é se o cliente disser que existe. Pode ser algum tipo de falha na mercearia, ou pode ser coisas técnicas.
Em relação às falhas de alimentos, uma métrica como o
churn de três semanas funciona bem , revelando que três semanas após o lançamento da tarefa de churn estão acima do normal. A essência é simples: a tarefa não foi lançada e, em três semanas, uma porcentagem suficientemente alta de seu código foi excluída. Aparentemente, a tarefa não foi muito bem implementada. Pegamos e analisamos esses casos com a equipe.

A segunda métrica é necessária para equipes que têm problemas com bugs, falhas e qualidade. Propomos construir um
gráfico do equilíbrio de bugs e travamentos: quantos bugs existem no momento, quantos chegaram ontem, quantos chegaram ontem. Você pode pendurar um
monitor em
tempo real na frente da equipe para que ela o veja todos os dias. Esse ótimo enfoca a equipe em questões de qualidade. As duas equipes e eu fizemos isso, e elas realmente começaram a pensar melhor nas tarefas.

O próximo problema muito comum é
que a equipe não tem tempo para dívidas técnicas . Essa história é facilmente monitorada se você seguir o trabalho com tipos, ou seja, tarefas de dívida técnica são avaliadas e iniciadas no Jira como tarefas de dívida técnica. Podemos calcular qual cota de alocação de tempo foi dada à equipe de dívida técnica durante o trimestre. Se concordarmos com o negócio de que eram 20% e gastamos apenas 10%, isso pode ser levado em consideração e, no próximo trimestre, dedicar mais tempo à dívida técnica.
Problemas com a disciplina em desenvolvimento
Agora vamos para o estágio de desenvolvimento. Quais são os problemas com a disciplina?
Infelizmente, acontece que os
desenvolvedores não fazem nada ou não conseguimos entender se estão fazendo alguma coisa. É fácil rastrear isso por dois sinais banais:
- frequência de confirmações - pelo menos uma vez ao dia;
- pelo menos uma tarefa ativa em Jira.
Caso contrário, não é fato que você precisa vencer as mãos do desenvolvedor, mas precisa saber sobre isso.
O segundo problema que pode derrubar até as pessoas mais poderosas e o cérebro de um desenvolvedor muito bacana é o
processamento constante . Seria bom se você, como líder de equipe, soubesse que uma pessoa processa: escreve um código ou faz uma revisão de código após o expediente.
Várias regras do Git também
podem ser violadas . A primeira coisa que instamos a todos os comandos a seguir é especificar prefixos de tarefas do rastreador em mensagens de confirmação, porque somente nesse caso podemos vincular a tarefa e o código a ela. Aqui é melhor nem criar sinais, mas configurar diretamente o git hook. Para quaisquer regras git adicionais que você possui, por exemplo, você não pode confirmar no master, também configuramos ganchos git.
O mesmo se aplica às práticas acordadas. No estágio de desenvolvimento, existem muitas práticas que um desenvolvedor deve seguir. Por exemplo, no caso da data de vencimento, haverá três sinais:
- tarefas para as quais a data de vencimento não está definida;
- tarefas que expiraram na data de vencimento;
- tarefas para as quais a data de vencimento foi alterada, mas nenhum comentário.
Os sinais são ajustados para tudo isso. Coisas semelhantes também podem ser configuradas para qualquer outra prática.
Problemas de previsibilidade no estágio de desenvolvimento
Muitas coisas podem dar errado nas previsões no estágio de desenvolvimento.
Uma tarefa pode travar no desenvolvimento por um longo tempo. Já tentamos resolver esse problema no estágio de planejamento - decomponha as tarefas bastante bem. Infelizmente, isso nem sempre ajuda, e
há tarefas que congelam . Para iniciantes, recomendamos simplesmente definir o SLA como "em andamento" para que haja um sinal de que esse SLA está sendo violado. Isso não permitirá que você comece a liberar tarefas mais rapidamente no momento, mas também permitirá que você colete faturas, responda a isso e discuta com a equipe o que aconteceu, por que a tarefa trava por muito tempo.
A previsibilidade pode sofrer se
houver muitas tarefas em um desenvolvedor . É recomendável verificar o número de tarefas paralelas que o desenvolvedor executa por código, e não por Jira, porque nem sempre o Jira reflete informações relevantes. Somos todos humanos, e se fizermos muitas tarefas paralelas, aumenta o risco de algo dar errado em algum lugar.

O desenvolvedor pode ter alguns problemas dos quais ele não fala, mas que são fáceis de identificar com base nos dados. Por exemplo, ontem o desenvolvedor teve pouca atividade de código. Isso não significa necessariamente que há um problema, mas você, como líder de equipe, pode aparecer e descobrir. Ele pode estar preso e precisar de ajuda, mas fica com vergonha de perguntar a ela.
Outro exemplo, o desenvolvedor, pelo contrário, tem algum tipo de grande tarefa que continua crescendo e crescendo em código. Isso também pode ser detectado e possivelmente decomposto, para que no final não haja problemas no estágio de revisão ou teste de código.
, . , , . .
. , , .
.
«» : , ; «»; «»; , bug fix. , , , , , — « ».
, , , , . , - , .
, , ,
, «» . , . ,
Legacy Refactoring , , , .
, —
SLA high-priority- . , . , , : high-priority critical .
, —
. -, . -, , . , .
-
Code review. ? , , — pull requests. -, pull request, . , , «in review», , Jira. , . , 2-3 , .

, , , pull request, . — , pull request ticket Jira .

, , , . pull requests, . , , : «, , - ». , . pull requests , , Jira.
pull request, , — , , - , - , , . .
, , — , , , , . : , « , ». , .

, , linter. , , - linter, - - , .
-
, SLA , , . , , .
SLA , "
- " — . , -. pull request .

,
- , . , CTO , , , . -. - , 6 50% - . , , 50%, CTO . , CTO - , 100%.
, — , - . :
, -.
-
, -. , .
100 . - 10 , - 1-2 . , .
— , , . , , , .

, , , , .
—
, - , . — churn -, .. pull request , .
,
- , , , . , commit, , -.

, - ( pull request ), - . , commit, . , .
. , — Jira. Jira. , «testing». task-tracker. , , - .

SLA . SLA , .
-, , , — . . , , ,
.

pipeline test- — , , , . build' , , — , . , 1-2 , , . , .
— . , . , , «» , , , , , .
, , ,
. . , , , , . , , , . : , , , .

, «» , , . , , , .

, —
- . , , . , , .
Nós conversamos sobre métricas, e agora a pergunta é - como trabalhar com tudo isso? Eu contei apenas as coisas mais básicas, mas muitas delas. O que fazer com tudo isso e como usá-lo?
Recomendamos que você automatize esse processo ao máximo e envie todos os sinais para a equipe por meio de um bot em mensagens instantâneas. Tentamos diferentes canais de comunicação: email e painel - não funciona muito bem. O bot provou ser o melhor. Você pode escrever um bot, pode pegar o OpenSource de alguém, pode comprar conosco.
O ponto aqui é muito simples: a equipe reage com muito mais calma aos sinais do bot do que ao gerente, que indica problemas. Se possível, entregue a maioria dos sinais diretamente ao desenvolvedor primeiro e depois à equipe, se o desenvolvedor não responder, por exemplo, dentro de um a dois dias.

Não é necessário tentar criar todos os sinais de uma só vez. A maioria deles simplesmente não funcionará, porque você não terá dados devido a problemas triviais com a disciplina. Portanto, primeiro estabelecemos disciplina e estabelecemos sinais para práticas disciplinares. De acordo com a experiência das equipes com as quais conversamos, levou um ano e meio para simplesmente criar disciplina na equipe de desenvolvimento sem automação. Com a automação, com a ajuda de sinais constantes, a equipe começa a trabalhar normalmente de maneira disciplinada em algum lugar após alguns meses, ou seja, muito mais rápido.
Qualquer sinal que você torne público ou direcione diretamente ao desenvolvedor, em nenhum caso você pode simplesmente captar e ligar. Primeiro você precisa coordenar isso com o desenvolvedor, conversar com ele e a equipe. É recomendável inserir todos os valores limite em um Contrato de equipe por escrito, os motivos pelos quais você está fazendo isso, quais serão as próximas etapas e assim por diante.

Deve-se ter em mente que todos os processos têm exceções e levam isso em consideração no estágio de design.
Não estamos construindo um campo de concentração para desenvolvedores, onde é impossível dar um passo à direita, um passo à esquerda. Todos os processos têm uma exceção, apenas queremos saber sobre eles. Se o bot jura constantemente sobre alguma tarefa que realmente não pode ser decomposta e que leva 5 dias para trabalhar, você precisa colocar uma marca de "não rastreamento" para que o bot leve isso em consideração. Você, como gerente, pode monitorar separadamente o número dessas tarefas "sem rastreamento" e, assim, entender o quão bons são esses processos e os sinais que você cria. Se o número de tarefas rotuladas como "sem rastreamento" cresce constantemente, isso significa que, infelizmente, os sinais e processos que você inventou são difíceis para a equipe, eles não podem segui-los e é mais fácil contorná-los.
 O controle manual ainda permanece
O controle manual ainda permanece . Não vai funcionar para ligar o bot e sair em algum lugar de Bali - você ainda tem que lidar com todas as situações. Você recebeu algum tipo de sinal, a pessoa não respondeu - você precisará descobrir o motivo em um ou dois dias, discutir o problema e encontrar uma solução.
Para otimizar esse processo, recomendamos a introdução de uma prática como um
atendente de processo . Esta é uma posição de transição de uma pessoa (uma vez por semana) que entende os problemas que o bot sinaliza. E você, como líder de equipe, ajuda o atendente a lidar com esses problemas, ou seja, a supervisioná-lo. Assim, o desenvolvedor aumenta a motivação para trabalhar com este produto. Ele entende seus benefícios, porque vê como esses problemas podem ser resolvidos e como reagir a eles. Assim, você reduz sua singularidade à equipe e
aproxima o momento em que a equipe se torna autônoma , e você ainda pode ir para Bali.
ConclusõesReúna dados. Crie processos para que você tenha dados coletados. Mesmo se você não quiser criar métricas e sinais agora, poderá fazer uma análise retrospectiva interessante no futuro se começar a coletá-las agora.
Controlar processos automaticamente. Ao projetar processos, sempre pense em como você pode invadi-los e como reconhecer esses hacks a partir dos dados.
Quando os sinais são poucos por várias semanas - muito bem! Fomos confrontados com o fato de que, quando a equipe vê que há menos sinais e parece que a situação está melhorando, ela começa a surgir freneticamente com outras práticas, começa a implementar algo para ver esses pacotes de sinais novamente. Isso nem sempre é necessário, talvez se houver menos sinais - tudo está bem com você, a equipe começou a trabalhar da maneira que você queria desde o início, e você está pronto :)
Venha compartilhar suas descobertas de Timlid no TeamLead Conf . A conferência de fevereiro será realizada em Moscou e a Chamada de Trabalhos já está aberta .
Deseja experimentar a experiência de outras pessoas? Assine nossa newsletter de gerenciamento para receber notícias sobre o programa e não perca tempo para negociar ingressos para a conferência.