Na continuação da “
discussão ” com o HighLoad ++ 2017, preparamos uma breve revisão dos cinco melhores (de acordo com os participantes da conferência) relatórios em inglês.
As principais notas foram atribuídas aos tópicos relacionados ao uso do ProxySQL (no TOP 5 havia dois relatórios sobre essa ferramenta), teste de aplicativos na nuvem pública da Amazon, bem como os princípios de log em uma escala quando isso se torna um problema e monitoramento do Apache Kafka.
Acabamos de publicar vídeos de todos os relatórios do HighLoad ++ 2017 para acesso gratuito. Uma lista completa de 150 relatórios em nosso canal do YouTube nesta lista de reprodução .
Além desta lista de reprodução, o canal possui várias centenas de vídeos em bancos de dados, arquiteturas, dimensionamento, filas, aprendizado de máquina e outras informações importantes :)
Medindo a variabilidade de desempenho de EC2
Henrik Ingo (arquiteto de soluções MongoDB e agora engenheiro de produtividade líder no Mongo DB).O primeiro relatório, observado pelos participantes, argumenta que a nuvem pública pode realmente ser usada para testar seus próprios produtos, incluindo testes de carga. Nesse caso, o DBMS do MongoDB, que está sendo testado usando a nuvem da Amazon, foi o "experimental". No total, cerca de 400 mil horas são gastas nessa tarefa por mês, cerca de 5% desse tempo são apenas testes de desempenho, cuja principal tarefa nem é fornecer otimização e não permitir "subsidência" como resultado de algumas melhorias.
A principal questão da apresentação é como obter resultados de testes reproduzíveis na nuvem pública.
O relatório é construído com base no princípio da análise de hipóteses. Inicialmente, Henrik Ingo faz suposições sobre quais fatores devem influenciar o nível de "ruído" nos testes (o próprio conceito de "ruído" no relatório tem uma definição muito específica). Por exemplo, a equipe de teste sugeriu que, em testes "pesados", o principal "ruído" vem do disco rígido ou na nuvem, ao distribuir recursos, você pode encontrar bons (totalmente alocados) ou ruins (compartilhados com por alguém) instâncias que afetam os resultados do teste.
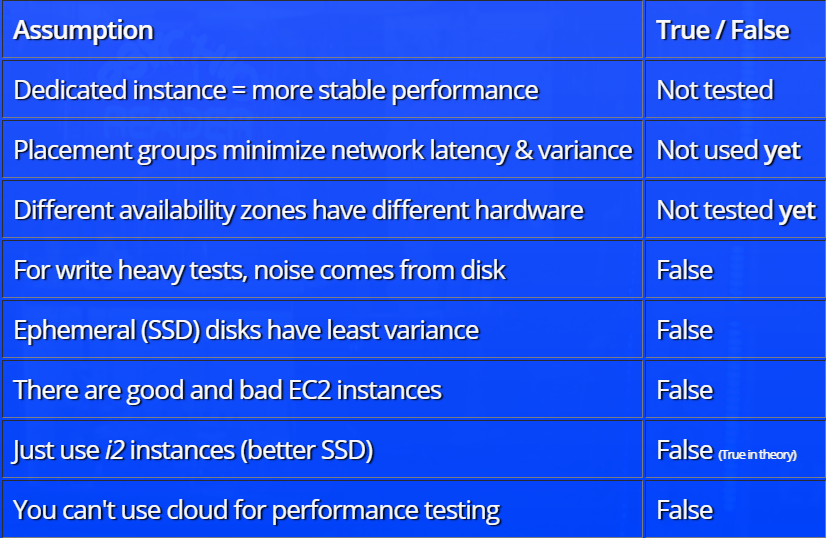
Depois disso, são analisados os resultados de testar cada uma das teorias com uma demonstração de algumas dependências interessantes. Por exemplo, aqui está um gráfico da dependência do nível de "ruído" (na terminologia do relatório) na configuração da instância selecionada:
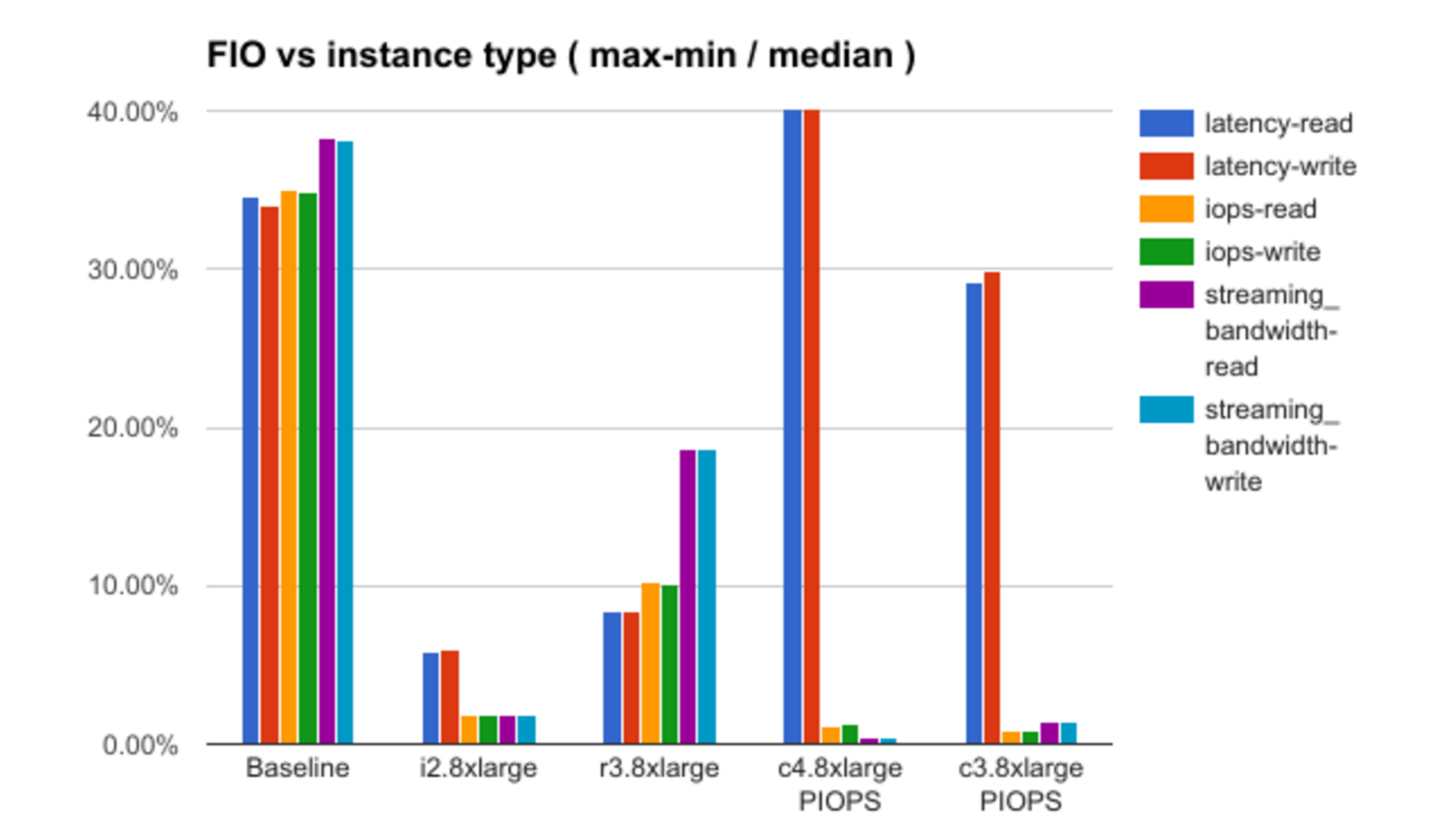
Por falta de informações sobre os detalhes da infraestrutura da Amazon, o relatório não responde a todas as perguntas, em alguns casos fazendo apenas suposições, mas há algo em que pensar.
Registro e discursos
Vytis Valentinavičius (Lamoda, chefe de operações)O próximo relatório interessante é o pensamento de um especialista em uma grande loja online da Lamoda sobre o registro e como deve ser para que os desenvolvedores, por um lado, recebam os dados necessários na íntegra e, por outro lado, não se afogem em gigabytes de informações recebidas. E o orador sabe do que está falando. O problema que começou a criar o trabalho com logs no Lamoda é a perda de 5% dos relatórios enviados pelos usuários via UDP (em alguns casos, esse compartilhamento chegou a 100%). Isso distorceu seriamente todas as métricas que poderiam ser construídas com base.
O relatório diz como não desvendar essa situação, mas como evitá-la, em princípio, dado que muitas soluções óbvias têm suas armadilhas.
Vytis Valentinavičius se concentra no fato de que o log deve ter uma estrutura. Mas, ao mesmo tempo, não pode ser inflado. Deve haver um objetivo de coletar e armazenar cada campo, pois qualquer dado coletado é dinheiro. Um exemplo de Lamoda são 25 mil mensagens de log de depuração por segundo (32 TB de informações por semana, para as quais o armazenamento custa apenas US $ 12 mil).
Além disso, é importante rastrear eventos, não erros específicos. Eles precisam ser agregados, métricas identificadas e baseadas em suas análises para criar eventos mais complexos para agregação futura.
Além de considerações teóricas, o relatório descreve alguns dos truques que Lamoda usou na produção para trabalhar com toras.
Métricas não são suficientes: monitorando o Apache Kafka
Gwen Shapira (Confluent, gerente de produtos)O próximo relatório é sobre o monitoramento do Apache Kafka, ou melhor, quais métricas devem ser selecionadas a partir da abundância de parâmetros disponíveis para análise para entender o status do intermediário de mensagens a qualquer momento.
A palestrante começou sua história com uma piada, na qual, como eles dizem, há apenas uma fração da piada: "Mesmo que você não consiga se lembrar do conteúdo de todo o relatório, lembre-se de uma coisa: se o Kafka é usado na produção, ele precisa ser monitorado" (bom, a API correspondente é fornecida para isso). )
É necessário monitorar tudo? Depende da tarefa. É a partir deles que Gwen Shapira repele, analisando as métricas recomendadas. O palestrante descreve casos operacionais padrão e recomenda parâmetros que devem ser adicionados ao painel para responder ao que está acontecendo a tempo e como não agravar a situação. Em particular, mais uma vez lembra que não é necessário reiniciar o broker na primeira alteração de métricas, porque leva muito tempo e, às vezes (devido a erros conhecidos), pode levar a consequências mais graves. Por fim, as métricas são apenas dados iniciais. E para tomar decisões, é preciso ter hipóteses baseadas nesses dados.

Graças à vasta experiência de Gwen Shapira como consultora, toda a apresentação é acompanhada de exemplos vívidos da vida.
Cenários de casos de uso do ProxySQL
Alkin Tezuysal (Percona, equipe global de DBA)Dois relatórios imediatamente, que, de acordo com as estimativas dos participantes, estavam no TOP 5, referem-se ao ProxySQL, um meio de proxy de consultas SQL ao MySQL (e, mais recentemente, ao ClickHouse).
O primeiro relatório é geralmente sobre cenários para o uso dessa ferramenta.
O ProxySQL é uma solução de código aberto, até agora não encontramos uma quintessência de experiência. Sim, muitas empresas baixam essa solução, mas mesmo o fabricante nem sempre entende quem o usará e em que escala. Os cenários coletados neste relatório foram identificados como resultado da comunicação com os usuários do ProxySQL e da análise de seus casos.
Em geral, o ProxySQL permite resolver um grande número de tarefas, desde consultas de balanceamento de carga e reescrita (que serão discutidas no próximo relatório da nossa lista) até a fila de consultas e o aquecimento do cache, que não está no MySQL. Cada uma das opções da Alkin Tezuysal analisa em detalhes, mencionando as vantagens e desvantagens da solução, bem como casos especiais em que pode ser útil.
Aqui mencionamos apenas dois exemplos relacionados à otimização do banco de dados.
Exemplo 1 - usando o ProxySQL para reduzir o número de solicitações para estabelecer uma conexão de aplicativo ao banco de dados. A ideia é refletida graficamente no gráfico fornecido no relatório:
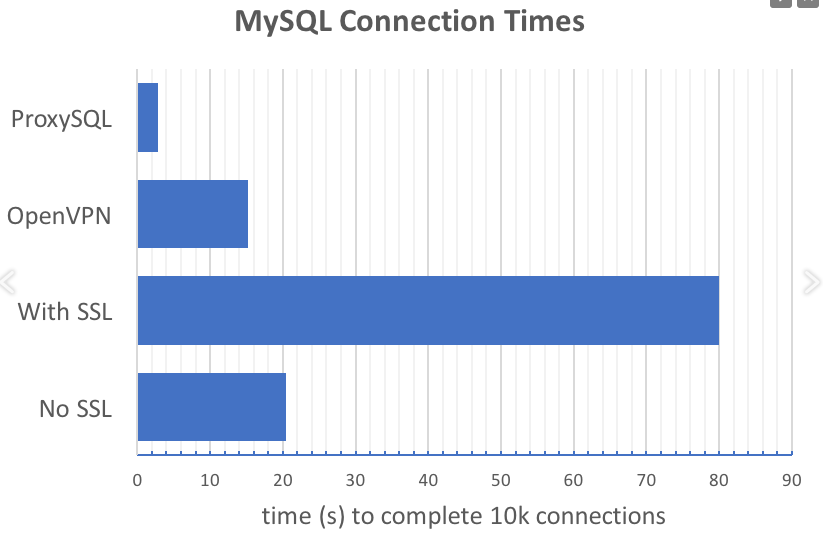
O ProxySQL reduz drasticamente o número de solicitações de conexão, especialmente ao usar SSL.
Exemplo 2 - filtrando consultas inúteis (como SELECT 1, manifestadas em aplicativos de larga escala) que diminuem a velocidade do banco de dados. Aqui, o resultado também é melhor avaliado graficamente:

Máscaras de dados baratas para MySQL com ProxySQL - anonimização de dados para desenvolvedores
Rene Cannao (fundador e proprietário do produto ProxySQL)O segundo relatório em inglês do ProxySQL, que entrou no TOP-5, é dedicado à solução de um problema muito específico - mascaramento de dados.
Após uma breve introdução ao ProxySQL para aqueles que não viram o primeiro relatório, o palestrante mergulha nos recursos da ferramenta com relação à solução de um problema específico - ocultar (substituir por asteriscos) parte do nome ou substituir o valor real da receita por um falso.
Como o orador observa, esse problema pode ser resolvido usando seus próprios meios dos mesmos produtos MySQL ou de terceiros. Entre os terceiros, o ProxySQL está longe de ser a única ferramenta. No entanto, embora não exista uma solução ideal no mercado, e o ProxySQL não seja pior que muitos, permitindo que os desenvolvedores obtenham dados válidos para testes que não contêm informações pessoais reais. Além disso, possui código-fonte aberto.
Se a primeira história sobre o ProxySQL foi mais teórica, então aqui está uma prática contínua. Até as regras configuradas usando expressões regulares são listadas.

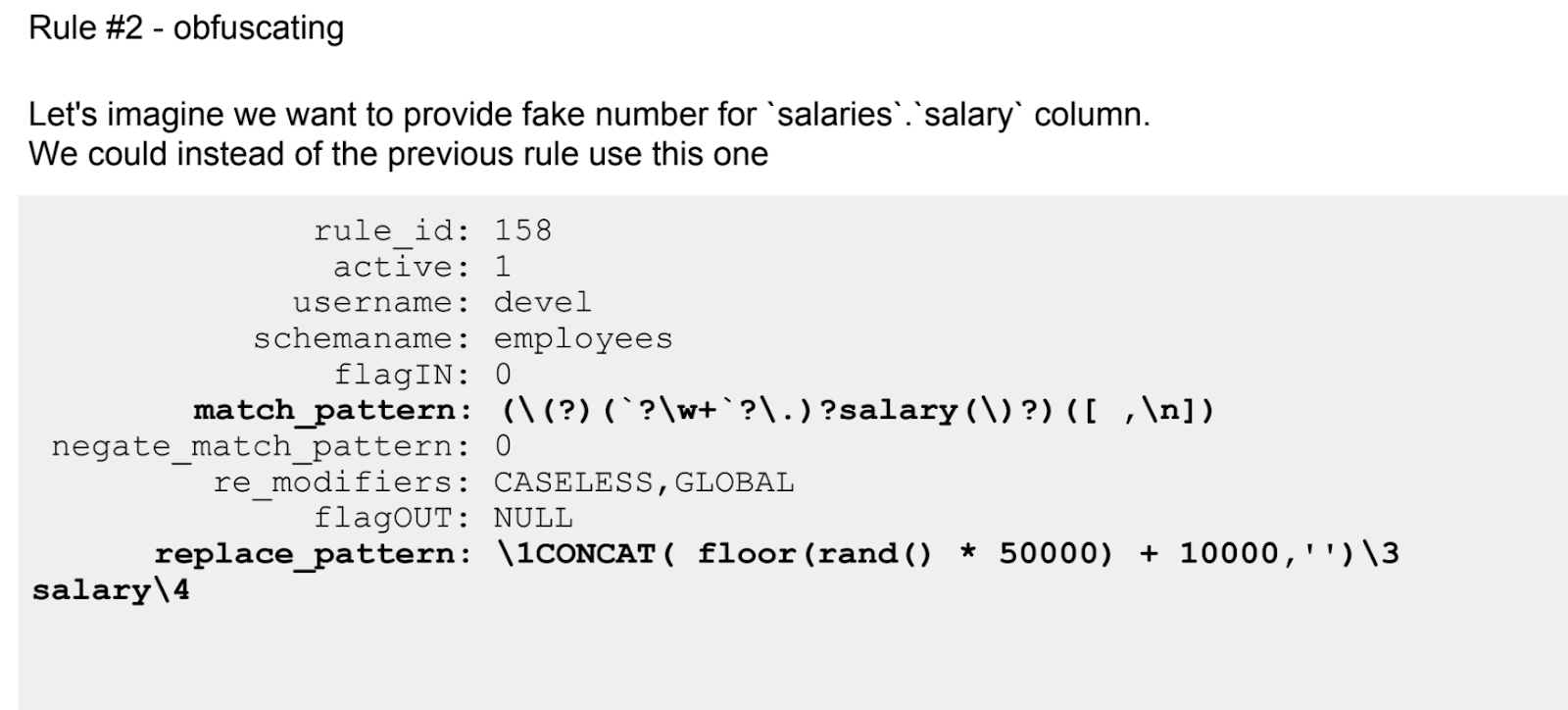
Como qualquer ferramenta proxySQL tem suas limitações. Isso também será discutido. Em particular, essa não é a melhor abordagem para transformações complexas.
O relatório terminou com uma seção completa de perguntas e respostas, com a qual você também pode aprender muitas coisas úteis e interessantes.
Obviamente, esses cinco falantes de inglês são apenas a ponta do iceberg que estava no HighLoad ++ 2017. Portanto, lembramos que acabamos de publicar vídeos de todos os relatórios da conferência que podem ser encontrados
nesta lista de reprodução .
O HighLoad ++ 2018 será realizado nos dias 8 e 9 de novembro em Moscou, em Skolkovo. O trabalho no programa já está em andamento, mas o relatório pode ser enviado antes de 1º de setembro.