Todas as organizações que têm pelo menos algo a ver com dados, mais cedo ou mais tarde, enfrentam o problema de armazenar bancos de dados relacionais e não estruturados. Não é fácil encontrar uma abordagem conveniente, eficaz e barata para esse problema ao mesmo tempo. E para garantir que os cientistas de dados possam trabalhar com sucesso com modelos de aprendizado de máquina. Fizemos isso - e, embora eu tivesse que mexer com isso, o lucro final foi ainda mais do que o esperado. Discutiremos todos os detalhes abaixo.

Com o tempo, quantidades incríveis de dados corporativos se acumulam em qualquer banco. Uma quantidade comparável é armazenada apenas em empresas e telecomunicações da Internet. Isso aconteceu devido aos altos requisitos regulatórios. Esses dados não ficam ociosos - os diretores das instituições financeiras descobriram há muito tempo como lucrar com isso.
Todos nós começamos com relatórios gerenciais e financeiros. Com base nesses dados, aprendemos a tomar decisões de negócios. Muitas vezes, havia a necessidade de obter dados de vários sistemas de informação do banco, para os quais criamos bancos de dados e sistemas de relatórios consolidados. A partir disso, gradualmente se formou o que agora é chamado de data warehouse. Logo, com base nesse armazenamento, nossos outros sistemas começaram a funcionar:
- CRM analítico, permitindo oferecer ao cliente produtos mais convenientes para ele;
- transportadores de empréstimos que ajudam você a tomar uma decisão rápida e precisa sobre um empréstimo;
- sistemas de fidelidade que calculam pontos de reembolso ou bônus de acordo com a mecânica de complexidade variável.
Todas essas tarefas são resolvidas por aplicativos analíticos que usam modelos de aprendizado de máquina. Quanto mais modelos de informações puderem extrair do repositório, mais precisamente eles funcionarão. Sua necessidade de dados está crescendo exponencialmente.
Sobre essa situação, chegamos a dois ou três anos atrás. Naquela época, tínhamos um armazenamento baseado no MPP Teradata DBMS usando a ferramenta SAS Data Integration Studio ELT. Construímos este armazém desde 2011 em conjunto com a Glowbyte Consulting. Mais de 15 grandes sistemas bancários foram integrados a ele e, ao mesmo tempo, dados suficientes foram acumulados para a implementação e o desenvolvimento de aplicativos analíticos. A propósito, naquele momento, a quantidade de dados nas camadas principais da loja, devido a muitas tarefas diferentes, começou a crescer de maneira não linear e as análises avançadas de clientes tornaram-se uma das principais direções do desenvolvimento do banco. Sim, e nossos dados Os cientistas estavam ansiosos para apoiá-la. Em geral, para construir a Plataforma de Pesquisa de Dados, as estrelas se formaram como deveriam.
Planejando uma solução
Aqui é necessário explicar: software e servidores industriais são um prazer caro, mesmo para um grande banco. Nem toda organização pode se dar ao luxo de armazenar uma grande quantidade de dados nos principais MPP DBMS. Você sempre precisa escolher entre preço e velocidade, confiabilidade e volume.
Para aproveitar ao máximo as oportunidades disponíveis, decidimos fazer o seguinte:
- A carga do ELT e a parte mais solicitada dos dados históricos do CD devem ser deixadas no DBMS Teradata;
- envie a história completa para o Hadoop, que permite armazenar informações muito mais baratas.
Naquela época, o ecossistema Hadoop tornou-se não apenas elegante, mas também suficientemente confiável, conveniente para uso corporativo. Foi necessário escolher um kit de distribuição. Você pode criar o seu próprio ou usar o Apache Hadoop aberto. Porém, entre as soluções empresariais baseadas no Hadoop, as distribuições prontas de outros fornecedores - Cloudera e Hortonworks - provaram ser mais. Portanto, também decidimos usar uma distribuição pronta.
Como nossa principal tarefa ainda era armazenar big data estruturado, na pilha do Hadoop, estávamos interessados em soluções o mais próximo possível dos DBMSs SQL clássicos. Os líderes aqui são Impala e Hive. A Cloudera desenvolve e integra as soluções Impala, Hortonworks - Hive.
Para um estudo aprofundado, organizamos testes de carga para os dois DBMSs, levando em consideração a carga de perfil para nós. Devo dizer que os mecanismos de processamento de dados no Impala e no Hive são significativamente diferentes - o Hive geralmente apresenta várias opções diferentes. No entanto, a escolha recaiu na Impala - e, consequentemente, na distribuição da Cloudera.
O que eu gostei sobre o Impala
- Alta velocidade de execução de consultas analíticas devido a uma abordagem alternativa em relação ao MapReduce. Os resultados intermediários dos cálculos não dobram no HDFS, o que acelera significativamente o processamento de dados.
- Trabalho eficiente com armazenamento de dados em parquet no Parquet . Para tarefas analíticas, as chamadas tabelas amplas com muitas colunas são frequentemente usadas. Todas as colunas raramente são usadas - a capacidade de aumentar do HDFS apenas as necessárias para o trabalho permite economizar RAM e acelerar significativamente a solicitação.
- Uma solução elegante com filtros de tempo de execução que incluem filtragem de bloom. O Hive e o Impala são significativamente limitados no uso de índices comuns aos DBMSs clássicos devido à natureza do sistema de armazenamento de arquivos HDFS. Portanto, para otimizar a execução da consulta SQL, o mecanismo DBMS deve efetivamente usar o particionamento disponível, mesmo quando não for especificado explicitamente nas condições da consulta. Além disso, ele precisa tentar prever qual quantidade mínima de dados do HDFS precisa ser gerada para garantir o processamento de todas as linhas. Na Impala, isso funciona muito bem.
- A Impala usa o LLVM , um compilador de máquina virtual com instruções semelhantes a RISC, para gerar o código de execução de consulta SQL ideal.
- As interfaces ODBC e JDBC são suportadas. Isso permite integrar os dados do Impala com ferramentas e aplicativos analíticos quase que prontos para uso.
- É possível usar o Kudu para contornar algumas das limitações do HDFS e, em particular, escrever construções UPDATE e DELETE em consultas SQL.
Sqoop e o restante da arquitetura
A próxima ferramenta mais importante na pilha do Hadoop foi o Sqoop para nós. Ele permite transferir dados entre o DBMS relacional (é claro que estávamos interessados no Teradata) e o HDFS em um cluster Hadoop em vários formatos, incluindo o Parquet. Nos testes, o Sqoop mostrou alta flexibilidade e desempenho, por isso decidimos usá-lo - em vez de desenvolver nossas próprias ferramentas para capturar dados através do ODBC / JDBC e salvar no HDFS.
Para modelos de treinamento e tarefas relacionadas à Data Science, que são mais convenientes para executar diretamente no cluster Hadoop, usamos o Apache
Spark . Em seu campo, tornou-se uma solução padrão - e há uma razão:
- Bibliotecas de aprendizado de máquina Spark ML
- suporte para quatro linguagens de programação (Scala, Java, Python, R);
- integração com ferramentas analíticas;
- O processamento de dados na memória oferece excelente desempenho.
O servidor Oracle Big Data Appliance foi adquirido como uma plataforma de hardware. Começamos com seis nós em um circuito produtivo com uma CPU de 2x24 núcleos e 256 GB de memória cada. A configuração atual contém 18 dos mesmos nós com expansão de até 512 GB de memória.
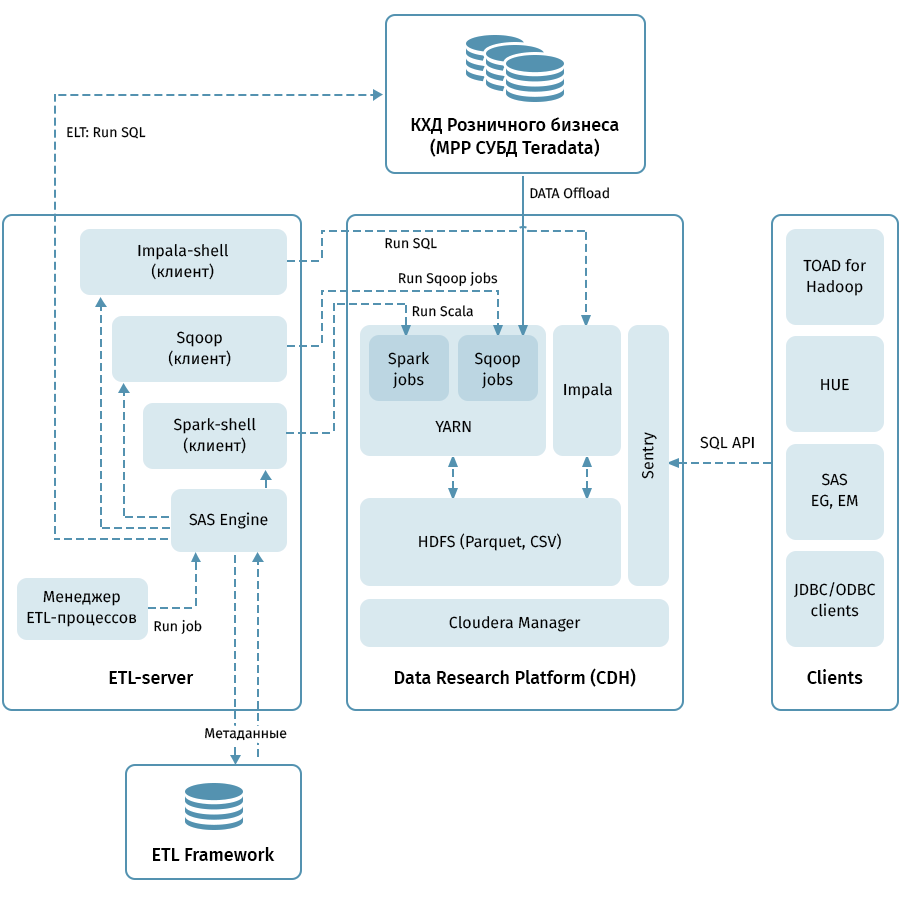
O diagrama mostra a arquitetura de nível superior da Data Research Platform e sistemas relacionados. O link central é o cluster Hadoop com base na distribuição Cloudera (CDH). É usado para receber com Sqoop e armazenar dados QCD em HDFS - no formato parquet, permitindo o uso de codecs para compactação, por exemplo, Snappy. O cluster também processa dados: o Impala é usado para transformações do tipo ELT, Spark - para tarefas de Ciência de Dados. O Sentry é usado para compartilhar o acesso a dados.
A Impala possui interfaces para quase todas as ferramentas modernas de análise corporativa. Além disso, ferramentas arbitrárias que suportam interfaces ODBC / JDBC podem ser conectadas como clientes. Para trabalhar com SQL, consideramos o Hue e o TOAD for Hadoop como os principais clientes.
Um subsistema ETL que consiste em ferramentas SAS (Metadata Server, Data Integration Studio) e uma estrutura ETL gravada com base em scripts SAS e shell usando um banco de dados para armazenar metadados de processos ETL são usados para gerenciar todos os fluxos indicados pelas setas no diagrama. . Guiado pelas regras especificadas nos metadados, o subsistema ETL inicia os processos de processamento de dados no QCD e na Plataforma de Pesquisa de Dados. Como resultado, temos um sistema completo para monitorar e gerenciar fluxos de dados, independentemente do ambiente utilizado (Teradata, Impala, Spark, etc., se necessário).
Através do ancinho para as estrelas
Descarregar o QCD parece ser simples. Na entrada e na saída, o DBMS relacional recebe e transborda dados pelo Sqoop. A julgar pela descrição acima, tudo correu muito bem conosco, mas, é claro, não foi sem aventuras, e essa talvez seja a parte mais interessante de todo o projeto.

Com o nosso volume, não poderíamos esperar transferir todos os dados inteiramente todos os dias. Assim, em cada instalação de armazenamento, foi necessário aprender a distinguir um incremento confiável, o que nem sempre é fácil quando os dados para datas comerciais históricas podem mudar na tabela. Para resolver esse problema, sistematizamos objetos, dependendo dos métodos de carregamento e manutenção do histórico. Em seguida, para cada tipo, foram determinados o predicado correto para Sqoop e o método de carregamento no receptor. E, finalmente, eles escreveram instruções para desenvolvedores de novos objetos.
O Sqoop é uma ferramenta de alta qualidade, mas não em todos os casos e combinações de sistemas, ele funciona de maneira absolutamente confiável. Em nossos volumes, o conector para Teradata não funcionou de maneira ideal. Aproveitamos o código-fonte aberto do Sqoop e fizemos alterações nas bibliotecas de conectores. A estabilidade da conexão ao mover dados aumentou.
Por algum motivo, quando o Sqoop chama Teradata, os predicados não são convertidos corretamente nas condições WHERE. Por esse motivo, o Sqoop às vezes tenta extrair uma tabela enorme e filtrá-la mais tarde. Falhamos em corrigir o conector aqui, mas encontramos outra maneira: criar à força uma tabela temporária com um predicado imposto para cada objeto descarregado e pedir ao Sqoop para preenchê-lo em excesso.
Todo o MPP, e o Teradata em particular, possuem um recurso relacionado ao armazenamento paralelo de dados e à execução de instruções. Se esse recurso não for levado em consideração, pode ser que todo o trabalho seja ocupado por um nó lógico do cluster, o que tornará a execução da consulta muito mais lenta, uma vez em 100-200. Obviamente, não poderíamos permitir isso, portanto, escrevemos um mecanismo especial que usa metadados ETL das tabelas QCD e seleciona o grau ideal de paralelização das tarefas do Sqoop.
O histórico do armazenamento é uma questão delicada, especialmente se você usar o
SCD2 , enquanto o Impala não suporta UPDATE e DELETE. Obviamente, queremos que as tabelas históricas na Data Research Platform sejam exatamente iguais às do Teradata. Isso pode ser alcançado combinando o incremento de recebimento por meio do Sqoop, destacando chaves de negócios atualizadas e excluindo partições no Impala. Para que essa lógica elaborada não precise ser escrita por cada desenvolvedor, compilamos em uma biblioteca especial (no nosso “carregador” de gíria ETL).
Finalmente - uma pergunta com tipos de dados. O Impala é bastante livre para conversão de tipos, portanto, encontramos algumas dificuldades apenas nos tipos TIMESTAMP e CHAR / VARCHAR. Para data e hora, decidimos armazenar dados no Impala no formato de texto (STRING) AAAA-MM-DD HH: MM: SS. Essa abordagem, como se viu, possibilita o uso das funções de transformação de data e hora. Para dados de string de um determinado comprimento, descobriu-se que o armazenamento no formato STRING no Impala não é inferior a eles, portanto, também o usamos.
Normalmente, para organizar o Data Lake, os dados de origem em formatos semiestruturados são copiados para uma área de estágio especial no Hadoop e, usando o Hive ou Impala, eles estabelecem um esquema de desserialização desses dados para uso em consultas SQL. Nós seguimos o mesmo caminho. É importante observar que nem tudo e nem sempre faz sentido arrastar o data warehouse, pois o desenvolvimento de processos de cópia de arquivos e a instalação do esquema são muito mais baratos do que carregar atributos de negócios no modelo QCD usando processos ETL. Quando ainda não está claro quanto, por quanto tempo e com que frequência os dados de origem são necessários, o Data Lake na abordagem descrita é uma solução simples e barata. Agora, carregamos regularmente no Data Lake principalmente fontes que geram eventos do usuário: dados de análise de aplicativos, logs e cenários de transição para discagem automática e secretária eletrônica da Avaya, transações de cartão.
Kit de ferramentas do analista
Não esquecemos outro objetivo de todo o projeto - permitir que os analistas usem toda essa riqueza. Aqui estão os princípios básicos que nos guiaram aqui:
- Conveniência da ferramenta em uso e suporte
- Aplicabilidade em tarefas de ciência de dados
- A possibilidade máxima de usar os recursos de computação do cluster Hadoop, em vez de servidores de aplicativos ou o computador do pesquisador
E aqui está o que paramos:
- Python + Anaconda. O ambiente usado é o iPython / Jupyter
- R + Brilhante. O pesquisador trabalha na versão desktop ou web do R Studio, Shiny, usada para desenvolver aplicativos da web aprimorados pelo uso de algoritmos desenvolvidos em R.
- Spark Para trabalhar com dados, são usadas as interfaces para Python (pyspark) e R, configuradas nos ambientes de desenvolvimento especificados nos parágrafos anteriores. Ambas as interfaces permitem usar a biblioteca Spark ML, o que possibilita o treinamento de modelos ML no cluster Hadoop / Spark.
- Os dados do Impala são acessíveis através do Hue, Spark e de ambientes de desenvolvimento usando a interface ODBC padrão e bibliotecas especiais como implyr
Atualmente, o Data Lake contém cerca de 100 TB de dados do armazenamento de varejo, além de cerca de 50 TB de várias fontes OLTP. O lago é atualizado diariamente de forma incremental. No futuro, aumentaremos a conveniência do usuário, introduziremos uma carga ELT no Impala, aumentaremos o número de fontes carregadas no Data Lake e expandiremos as oportunidades para análises avançadas.
Concluindo, gostaria de dar alguns conselhos gerais aos colegas que estão apenas começando sua jornada na criação de grandes repositórios:
- Use as melhores práticas. Se não tivéssemos um subsistema ETL, metadados, armazenamento com versão e uma arquitetura compreensível, não teríamos dominado essa tarefa. As melhores práticas se pagam, embora não imediatamente.
- Lembre-se da quantidade de dados. O big data pode criar dificuldades técnicas em locais muito inesperados.
- Fique atento às novas tecnologias. Novas soluções aparecem frequentemente, nem todas são úteis, mas às vezes gemas reais são encontradas.
- Experimente mais. Não confie apenas nas descrições de marketing das soluções - tente você mesmo.
A propósito, você pode ler sobre como nossos analistas usaram o aprendizado de máquina e os dados bancários para trabalhar com riscos de crédito em um post separado.