Hoje, um dos principais obstáculos à introdução do aprendizado de máquina nos negócios é a incompatibilidade das métricas e indicadores de ML com os quais a alta administração opera. Analista prevê aumento de lucro? Mas você precisa entender em quais casos o aprendizado de máquina se tornará a causa do aumento e em quais outros fatores. Infelizmente, muitas vezes a melhoria nas métricas de ML não leva ao crescimento do lucro. Além disso, às vezes a complexidade dos dados é tal que até desenvolvedores experientes podem escolher métricas incorretas que não podem ser orientadas.
Vejamos o que são métricas de ML e quando são apropriadas para uso. Analisaremos erros comuns e discutiremos quais opções para definir o problema podem ser adequadas para aprendizado de máquina e negócios.
Métricas de ML: por que existem tantas?
As métricas de aprendizado de máquina são muito específicas e geralmente enganosas, mostrando uma
boa cara em um jogo ruim, um bom resultado para modelos ruins. Para testar modelos e aprimorá-los, você precisa escolher uma métrica que reflita adequadamente a qualidade do modelo e como mensurá-lo. Geralmente, um conjunto de dados de teste separado é usado para avaliar a qualidade do modelo. E, como você sabe, escolher a métrica certa é uma tarefa difícil.
Quais são as tarefas mais frequentemente resolvidas com a ajuda do aprendizado de máquina? Primeiro de tudo, isso é regressão, classificação e agrupamento. Os dois primeiros são o chamado treinamento com o professor: existe um conjunto de dados rotulados, com base em alguma experiência, é necessário prever o valor definido. A regressão é uma previsão de algum valor: por exemplo, quanto o cliente comprará, qual é a resistência ao desgaste do material, quantos quilômetros o carro percorrerá antes da primeira falha.
Clustering é a definição de uma estrutura de dados destacando clusters (por exemplo, categorias de clientes) e não temos suposições sobre esses clusters. Não consideraremos esse tipo de problema.
Os algoritmos de aprendizado de máquina otimizam (calculando a função de perda) a métrica matemática - a diferença entre a previsão do modelo e o valor real. Mas se a métrica for a soma dos desvios, com o mesmo número de desvios em ambas as direções, essa soma será zero e simplesmente não saberemos se há um erro. Portanto, eles geralmente usam o absoluto médio (a soma dos valores absolutos dos desvios) ou o erro quadrático médio (a soma dos quadrados dos desvios em relação ao valor verdadeiro). Às vezes, a fórmula é complicada: pegue o logaritmo ou extraia a raiz quadrada dessas somas. Graças a essas métricas, você pode avaliar a dinâmica da qualidade dos cálculos do modelo, mas para isso é necessário comparar o resultado com algo.
Isso não será difícil se já houver um modelo construído com o qual comparar os resultados. Mas e se a primeira vez que você criou um modelo? Nesse caso, o coeficiente de determinação, ou R2, é frequentemente usado. O coeficiente de determinação é expresso como:
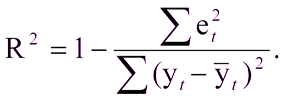
Onde:
R ^ 2 - coeficiente de determinação,
e
t ^ 2 é o erro quadrático médio,
y
t é o valor correto,
y
t com uma capa é o valor médio.
Unidade menos a razão entre o erro quadrado médio do modelo e o erro quadrado médio do valor médio da amostra de teste.Ou seja, o coeficiente de determinação permite avaliar a melhoria da previsão pelo modelo.
Às vezes acontece que um erro em uma direção não é equivalente a um erro na outra. Por exemplo, se um modelo prevê um pedido de mercadorias no armazém de um armazém, é bem possível cometer um erro e pedir um pouco mais, as mercadorias aguardarão o tempo no armazém. E se o modelo cometer um erro de outra maneira e pedir menos, poderá perder clientes. Nesses casos, é utilizado um erro quantil: desvios positivos e negativos do valor real são levados em consideração com pesos diferentes.
No problema de classificação, o modelo de aprendizado de máquina distribui objetos em duas classes: o usuário sai do site ou não sai, a peça está com defeito ou não, etc. A precisão da previsão geralmente é estimada como a razão entre o número de classes definidas corretamente e o número total de previsões. No entanto, essa característica raramente pode ser considerada um parâmetro adequado.
 Fig. 1. Matriz de erro para o problema de previsão de retorno do clienteExemplo
Fig. 1. Matriz de erro para o problema de previsão de retorno do clienteExemplo : se 7 em cada 100 pessoas seguradas solicitarem uma indenização, o modelo que prevê a ausência de um evento segurado terá uma precisão de 93% sem nenhum poder preditivo.
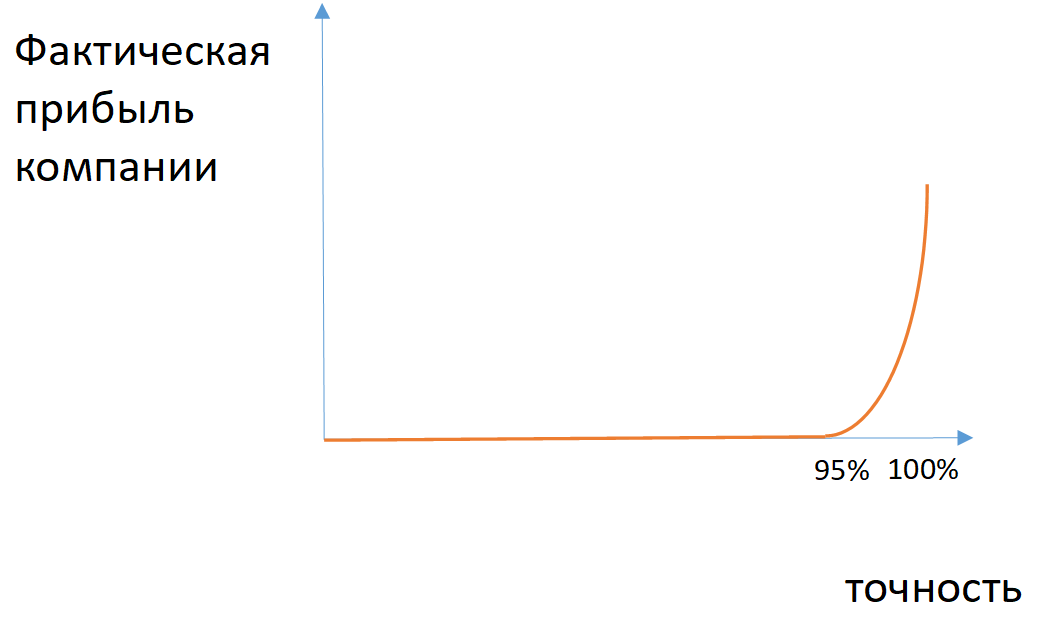 Fig. 2. Um exemplo da dependência do lucro real da empresa na precisão do modelo no caso de classes desequilibradas
Fig. 2. Um exemplo da dependência do lucro real da empresa na precisão do modelo no caso de classes desequilibradasPara algumas tarefas, você pode aplicar as métricas de integridade (o número de objetos definidos corretamente da classe entre todos os objetos desta classe) e precisão (o número de objetos definidos corretamente da classe entre todos os objetos que o modelo atribuiu a essa classe). Se for necessário levar em consideração a integridade e a precisão, aplique a média harmônica entre esses valores (medida F1).
Usando essas métricas, você pode avaliar as classificações executadas. No entanto, muitos modelos prevêem a probabilidade do relacionamento de um modelo com uma classe específica. Desse ponto de vista, é possível alterar o limite de probabilidade com relação ao qual os elementos serão atribuídos a uma ou outra classe (por exemplo, se o cliente sair com uma probabilidade de 60%, então poderá ser considerado restante). Se um limite específico não for definido, para avaliar a eficácia do modelo, é possível construir um gráfico da dependência de métricas em diferentes valores de limite (
curva ROC ou curva PR ), tomando como métrica a área sob a curva selecionada.
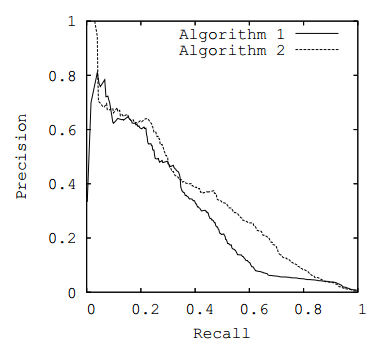 Fig. 3. curva PR
Fig. 3. curva PRMétricas de negócios
Alegoricamente falando, as métricas de negócios são elefantes: elas não podem ser negligenciadas e, em um desses "elefantes", um grande número de "papagaios" de aprendizado de máquina pode ser adequado. A resposta à pergunta sobre quais métricas de ML aumentarão os lucros depende da melhoria. De fato, as métricas de negócios estão de alguma forma ligadas ao aumento dos lucros, mas quase nunca conseguimos associar diretamente os lucros a elas. Métricas intermediárias são comumente usadas, por exemplo:
- a duração das mercadorias em estoque e o número de solicitações de mercadorias quando elas não estão disponíveis;
- a quantidade de dinheiro que os clientes estão prestes a deixar;
- a quantidade de material que é salva no processo de fabricação.
Quando se trata de otimizar um negócio usando o aprendizado de máquina, a criação de dois modelos está sempre implícita: preditivo e otimização.
O primeiro é mais complicado, o segundo usa seus resultados. Os erros no modelo de previsão nos forçam a estabelecer uma margem maior no modelo de otimização, portanto, o valor otimizado é reduzido.
Exemplo : quanto menor a precisão de prever o comportamento do cliente ou a probabilidade de defeitos industriais, menor o número de clientes capazes de manter e menor a quantidade de materiais economizados.
As métricas geralmente aceitas de sucesso nos negócios (EBITDA, etc.) raramente são obtidas ao definir tarefas de ML. Geralmente, é necessário estudar profundamente as especificidades e aplicar as métricas aceitas no campo em que introduzimos o aprendizado de máquina (verificação média, presença, etc.).
Dificuldades de tradução
Ironicamente, é mais conveniente otimizar modelos usando métricas difíceis de entender para os representantes comerciais. Como a área sob a curva ROC no modelo de tonalidade de comentários se relaciona com um tamanho de receita específico? Desse ponto de vista, a empresa enfrenta duas tarefas: como medir e como maximizar o efeito da introdução do aprendizado de máquina?
A primeira tarefa é mais fácil de resolver se você tiver dados retrospectivos e ao mesmo tempo outros fatores puderem ser nivelados ou medidos. Então, nada impede que você compare os valores obtidos com dados retrospectivos semelhantes. Mas há uma complicação: a amostra deve ser representativa e, ao mesmo tempo, semelhante à que testamos o modelo.
Exemplo : você precisa encontrar os clientes mais semelhantes para descobrir se a verificação média aumentou. Mas, ao mesmo tempo, a amostra de clientes deve ser grande o suficiente para evitar picos devido a comportamentos incomuns. Esse problema pode ser resolvido criando-se uma seleção suficientemente grande de clientes semelhantes e usando-o para verificar o resultado de seus esforços.
No entanto, você pode perguntar: como converter a métrica selecionada em uma função de perda (que o modelo está minimizando) para aprendizado de máquina. Essa tarefa não pode ser resolvida imediatamente: os desenvolvedores do modelo terão que se aprofundar nos processos de negócios. Mas se você usar uma métrica que depende dos negócios ao treinar o modelo, a qualidade dos modelos aumentará imediatamente. Digamos, se o modelo predizer quais clientes sairão, na função de uma métrica comercial, você poderá usar um gráfico em que o número de clientes que saem, de acordo com o modelo, seja plotado em um eixo e o valor total de fundos para esses clientes no outro eixo. Com a ajuda desse cronograma, um cliente comercial pode escolher um ponto conveniente para si e trabalhar com ele. Se, usando transformações lineares, reduzirmos o gráfico a uma curva PR (precisão em um eixo, segunda completude), poderemos otimizar a área sob essa curva simultaneamente com a métrica de negócios.
 Fig. 4. Curva de efeito monetário
Fig. 4. Curva de efeito monetárioConclusão
Antes de definir a tarefa de aprendizado de máquina e criar um modelo, você precisa escolher uma métrica razoável. Se você estiver otimizando o modelo, poderá usar uma das métricas padrão como uma função de erro. Certifique-se de coordenar com o cliente a métrica selecionada, seus pesos e outros parâmetros, convertendo métricas de negócios em modelos de ML. Em termos de duração, isso pode ser comparado ao desenvolvimento do modelo em si, mas sem isso não faz sentido começar o trabalho. Se você envolver matemáticos no estudo de processos de negócios, poderá reduzir bastante a probabilidade de erros nas métricas. A otimização efetiva do modelo é impossível sem a compreensão da área de assunto e uma declaração conjunta do problema no nível dos negócios e das estatísticas. E depois de todos os cálculos, você poderá avaliar o lucro (ou economia), dependendo de cada aprimoramento do modelo.
Nikolay Knyazev ( iRumata ), chefe do grupo de aprendizado de máquina, Jet Infosystems