
Recentemente, o phishing tem sido a maneira mais fácil e popular para os cibercriminosos roubar dinheiro ou informações. Por exemplo, você não precisa ir longe. No ano passado, as principais empresas russas enfrentaram um ataque de escala sem precedentes - os atacantes registraram massivamente recursos falsos, cópias exatas dos sites de fabricantes de fertilizantes e petroquímicos para concluir contratos em seu nome. O dano médio de tal ataque é de 1,5 milhão de rublos, sem mencionar o dano à reputação sofrido pela empresa. Neste artigo, falaremos sobre como detectar efetivamente sites de phishing usando análise de recursos (CSS, imagens JS, etc.) em vez de HTML, e como um especialista em ciência de dados pode resolver esses problemas.
Pavel Slipenchuk, arquiteto de sistemas de aprendizado de máquina, Grupo-IB
A epidemia de phishing
Segundo o Grupo-IB, mais de 900 clientes de vários bancos se tornam vítimas de phishing financeiro sozinho na Rússia todos os dias - esse número é 3 vezes o número diário de vítimas de malware. Os danos causados por um ataque de phishing em um usuário variam de 2.000 a 50.000 rublos. Os fraudadores não apenas copiam o site de uma empresa ou um banco, seus logotipos e cores da empresa, conteúdo, detalhes de contato, registram um nome de domínio semelhante, eles ainda anunciam ativamente seus recursos em redes sociais e mecanismos de busca. Por exemplo, eles tentam trazer links para seus sites de phishing até o topo dos resultados de pesquisa para a solicitação "Transferir dinheiro para um cartão". Na maioria das vezes, sites falsos são criados precisamente para roubar dinheiro ao transferir de cartão para cartão ou com pagamento instantâneo pelos serviços das operadoras de celular.
O phishing (por exemplo, phishing, da pesca - pesca, pesca) é uma forma de fraude na Internet, cujo objetivo é induzir a vítima a fornecer informações confidenciais ao fraudador. Na maioria das vezes, eles roubam senhas de acesso a contas bancárias para roubar dinheiro, contas de mídia social (para extorquir dinheiro ou enviar spam em nome da vítima), inscrever-se em serviços pagos, enviar e-mail ou infectar um computador, tornando-o um link na botnet.
Por métodos de ataque, existem 2 tipos de phishing direcionados a usuários e empresas:
- Sites de phishing que copiam o recurso original da vítima (bancos, companhias aéreas, lojas on-line, empresas, agências governamentais etc.).
- Correspondências de phishing, e-mails, sms, mensagens em redes sociais, etc.
Os indivíduos são frequentemente atacados pelos usuários, e o limiar para entrar neste segmento do negócio criminal é tão baixo que um “investimento” mínimo e conhecimento básico são suficientes para implementá-lo. A disseminação desse tipo de fraude também é facilitada por kits de phishing, programas de criação de sites de phishing que podem ser comprados gratuitamente na Darknet em fóruns de hackers.
Ataques a empresas ou bancos são diferentes. Eles são executados por atacantes tecnicamente mais experientes. Como regra, grandes empresas industriais, lojas on-line, companhias aéreas e, geralmente, bancos, são escolhidas como vítimas. Na maioria dos casos, o phishing se resume ao envio de um email com um arquivo infectado anexado. Para que esse ataque seja bem-sucedido, a "equipe" do grupo precisa ter especialistas em escrever códigos maliciosos, programadores para automatizar suas atividades e pessoas que possam conduzir a inteligência primária da vítima e encontrar fraquezas nela.
Na Rússia, de acordo com nossas estimativas, existem 15 grupos criminosos envolvidos em phishing direcionados a instituições financeiras. A quantidade de dano é sempre pequena (dez vezes menor que a dos Trojans bancários), mas o número de vítimas que atraem para seus sites é estimado em milhares todos os dias. Cerca de 10 a 15% dos visitantes de sites de phishing financeiro inserem seus próprios dados.
Quando uma página de phishing é exibida, a conta sai por horas e, às vezes, até minutos, porque os usuários incorrem em graves prejuízos financeiros e, no caso das empresas, à reputação. Por exemplo, algumas páginas de phishing bem-sucedidas estavam disponíveis por menos de um dia, mas foram capazes de causar danos em quantidades de 1.000.000 de rublos.
Neste artigo, abordaremos o primeiro tipo de phishing: sites de phishing. Os recursos "suspeitos" de phishing podem ser facilmente detectados usando vários meios técnicos: honeypots, crawlers, etc., no entanto, é problemático garantir que eles realmente sejam phishing e identificar a marca atacada. Vamos descobrir como resolver esse problema.
Pesca
Se uma marca não monitora sua reputação, ela se torna um alvo fácil. É necessário aproveitar a iniciativa dos criminosos imediatamente após registrar seus sites falsos. Na prática, a busca por uma página de phishing é dividida em quatro etapas:
- Formação de muitos endereços suspeitos (URLs) para verificações de phishing (rastreador, honeypots etc.).
- A formação de muitos endereços de phishing.
- Classificação dos endereços de phishing já detectados por área de atividade e tecnologia atacada, por exemplo, “RBS :: Sberbank Online” ou “RBS :: Alfa-Bank”.
- Procure uma página de doadores.
A implementação dos parágrafos 2 e 3 recai sobre os ombros de especialistas em ciência de dados.
Depois disso, você já pode executar etapas ativas para bloquear a página de phishing. Em particular:
- colocar na lista negra os produtos do Grupo-IB e produtos de nossos parceiros;
- enviar cartas automática ou manualmente ao proprietário da zona do domínio com uma solicitação para remover o URL de phishing;
- enviar cartas ao serviço de segurança da marca atacada;
- etc.

Métodos de análise HTML
A solução clássica para as tarefas de verificar endereços suspeitos de phishing e detectar automaticamente uma marca afetada são várias maneiras de analisar páginas de origem HTML. A coisa mais simples é escrever expressões regulares. É engraçado, mas esse truque ainda funciona. E hoje, a maioria dos phishers iniciantes simplesmente copia o conteúdo do site original.
Além disso, sistemas anti-phishing muito eficazes podem ser desenvolvidos por pesquisadores de kits de phishing. Mas neste caso, você precisa examinar a página HTML. Além disso, essas soluções não são universais - seu desenvolvimento requer uma base das "baleias". Alguns kits de phishing podem não ser conhecidos pelo pesquisador. E, é claro, a análise de cada nova “baleia” é um processo bastante trabalhoso e caro.
Todos os sistemas de detecção de phishing baseados na análise de página HTML param de funcionar após a ofuscação do HTML. E, em muitos casos, basta alterar o quadro da página HTML.
Segundo o Grupo-IB, no momento não existem mais de 10% desses sites de phishing, mas mesmo a falta de um pode custar muito à vítima.
Portanto, para um pescador ignorar o bloqueio, basta alterar a estrutura HTML com menos frequência - ofuscar a página HTML (confundindo a marcação e / ou carregando o conteúdo via JS).
Declaração do problema. Método Baseado em Recursos
Os métodos baseados na análise dos recursos utilizados são muito mais eficazes e universais para detectar páginas de phishing. Um recurso é qualquer arquivo carregado ao renderizar uma página da web (todas as imagens, CSS (CSS), arquivos JS, fontes etc.).
Nesse caso, você pode criar um gráfico bipartido, em que alguns vértices serão endereços suspeitos de phishing, enquanto outros serão recursos associados a eles.
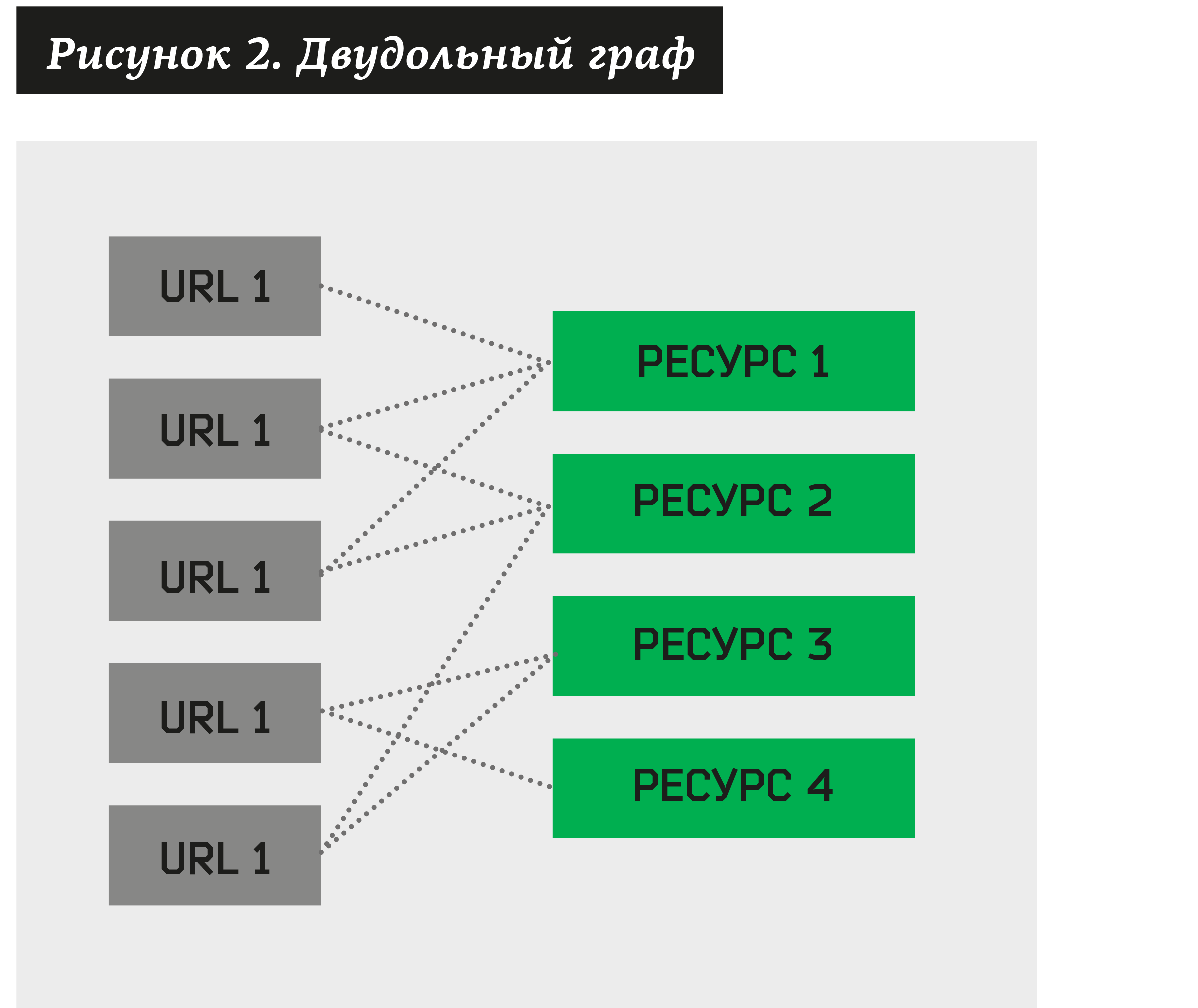
Surge a tarefa de agrupar - encontrar uma coleção desses recursos que possuem um número bastante grande de URLs diferentes. Ao construir esse algoritmo, podemos decompor qualquer gráfico bipartido em clusters.
A hipótese é que, com base em dados reais, com um grau de probabilidade bastante alto, pode-se dizer que o cluster contém uma coleção de URLs que pertencem à mesma marca e são gerados por um kit de phishing. Em seguida, para testar esta hipótese, cada um desses clusters pode ser enviado para verificação manual ao CERT (Centro de Resposta a Incidentes de Segurança da Informação). O analista, por sua vez, atribuiria ao status do cluster: +1 ("aprovado") ou -1 (rejeitado). Um analista também atribuiria uma marca atacada a todos os clusters aprovados. Esse "trabalho manual" termina - o restante do processo é automatizado. Em média, um grupo aprovado é responsável por 152 endereços de phishing (dados de junho de 2018) e, às vezes, clusters de 500 a 1000 endereços são encontrados! O analista gasta cerca de 1 minuto para aprovar ou refutar o cluster.
Em seguida, todos os clusters rejeitados são removidos do sistema e, após algum tempo, todos os seus endereços e recursos são novamente alimentados à entrada do algoritmo de cluster. Como resultado, obtemos novos clusters. E novamente os enviamos para verificação etc.
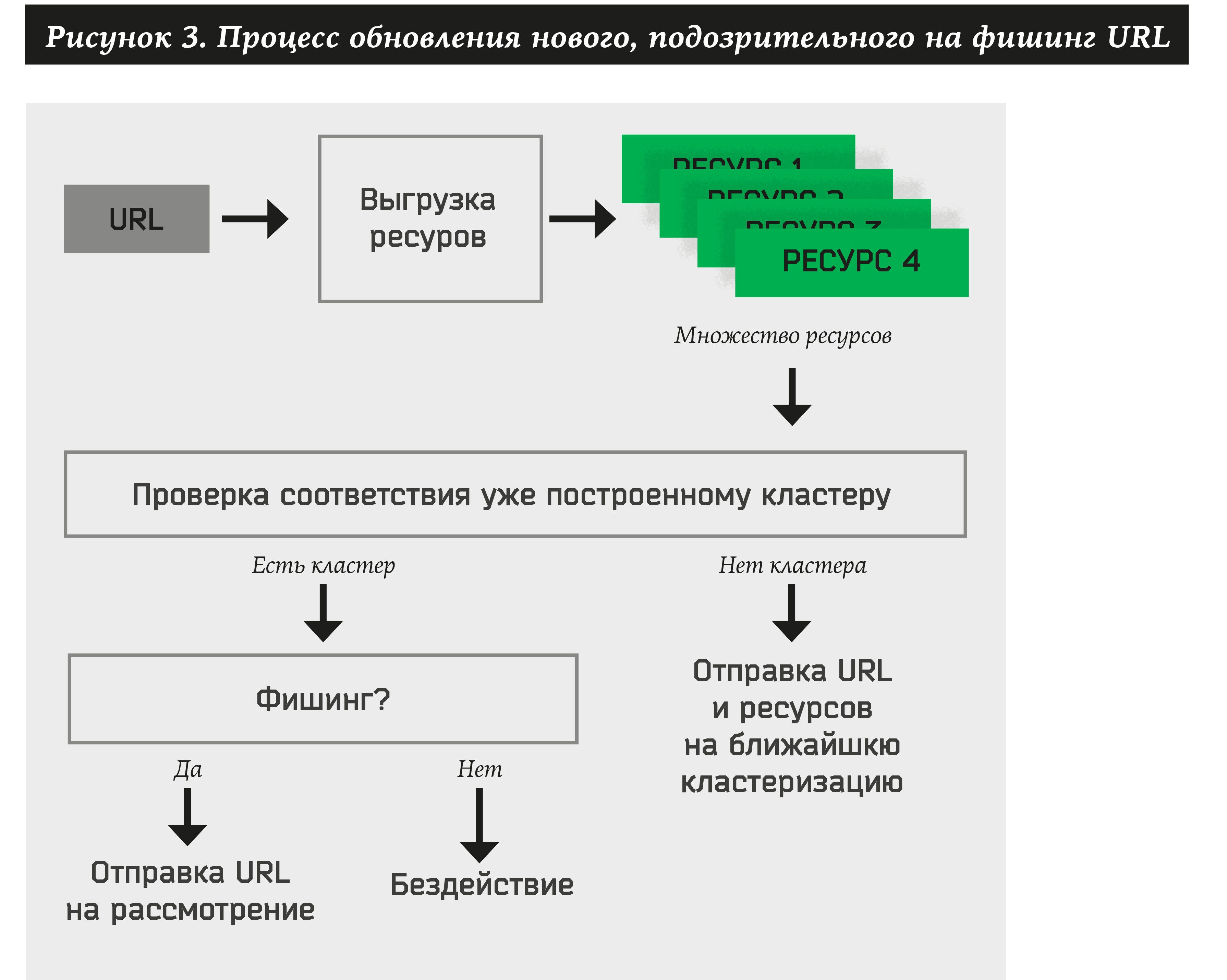
Assim, para cada endereço recém-recebido, o sistema deve fazer o seguinte:
- Extraia muitos dos recursos do site.
- Verifique se há pelo menos um cluster aprovado anteriormente.
- Se o URL pertencer a qualquer cluster, extraia automaticamente o nome da marca e execute uma ação para ele (notifique o cliente, exclua o recurso etc.).
- Se nenhum cluster puder ser atribuído a recursos, adicione o endereço e os recursos ao gráfico bipartido. No futuro, esse URL e recursos participarão da formação de novos clusters.
Algoritmo de Cluster de Recursos Simples
Uma das nuances mais importantes que um especialista em Data Science em segurança da informação deve levar em consideração é o fato de uma pessoa ser seu oponente. Por esse motivo, as condições e os dados para análise mudam muito rapidamente! Uma solução que corrige notavelmente o problema agora, após 2-3 meses, pode parar de funcionar em princípio. Portanto, é importante criar mecanismos universais (desajeitados), se possível, ou os sistemas mais flexíveis que podem ser desenvolvidos rapidamente. O especialista em ciência de dados em segurança da informação não pode resolver o problema de uma vez por todas.
Os métodos de cluster padrão não funcionam devido ao grande número de recursos. Cada recurso pode ser representado como um atributo booleano. No entanto, na prática, obtemos 5.000 endereços de sites diariamente e cada um deles contém uma média de 17,2 recursos (dados de junho de 2018). A maldição da dimensionalidade nem sequer permite carregar dados na memória, muito menos criar qualquer algoritmo de agrupamento.
Outra idéia é tentar agrupar em clusters usando vários algoritmos de filtragem colaborativa. Nesse caso, era necessário criar outro recurso - pertencente a uma marca específica. A tarefa será reduzida ao fato de que o sistema deve prever a presença ou ausência desse sinal para os URLs restantes. O método deu resultados positivos, mas teve duas desvantagens:
- para cada marca era necessário criar sua própria característica para filtragem colaborativa;
- precisava de uma amostra de treinamento.
Recentemente, mais e mais empresas desejam proteger sua marca na Internet e estão pedindo para automatizar a detecção de sites de phishing. Cada nova marca sob proteção adicionaria um novo atributo. E criar uma amostra de treinamento para cada nova marca é um trabalho manual adicional e tempo.
Começamos a procurar uma solução para esse problema. E eles encontraram uma maneira muito simples e eficaz.
Para começar, criaremos pares de recursos usando o seguinte algoritmo:
- Pegue todos os tipos de recursos (os denotamos como a) para os quais há pelo menos endereços N1, denotamos essa relação como # (a) ≥ N1.
- Construímos todos os tipos de pares de recursos (a1, a2) e selecionamos apenas aqueles para os quais haverá pelo menos endereços N2, ou seja, # (a1, a2) ≥ N2.
Da mesma forma, consideramos pares constituídos por pares obtidos no parágrafo anterior. Como resultado, obtemos quatro: (a1, a2) + (a3, a4) → (a1, a2, a3, a4). Além disso, se pelo menos um elemento estiver presente em um dos pares, em vez de quatro, obtemos triplos: (a1, a2) + (a2, a3) → (a1, a2, a3). Do conjunto resultante, deixamos apenas os quatros e triplos que correspondem a pelo menos endereços N3. E assim por diante ...
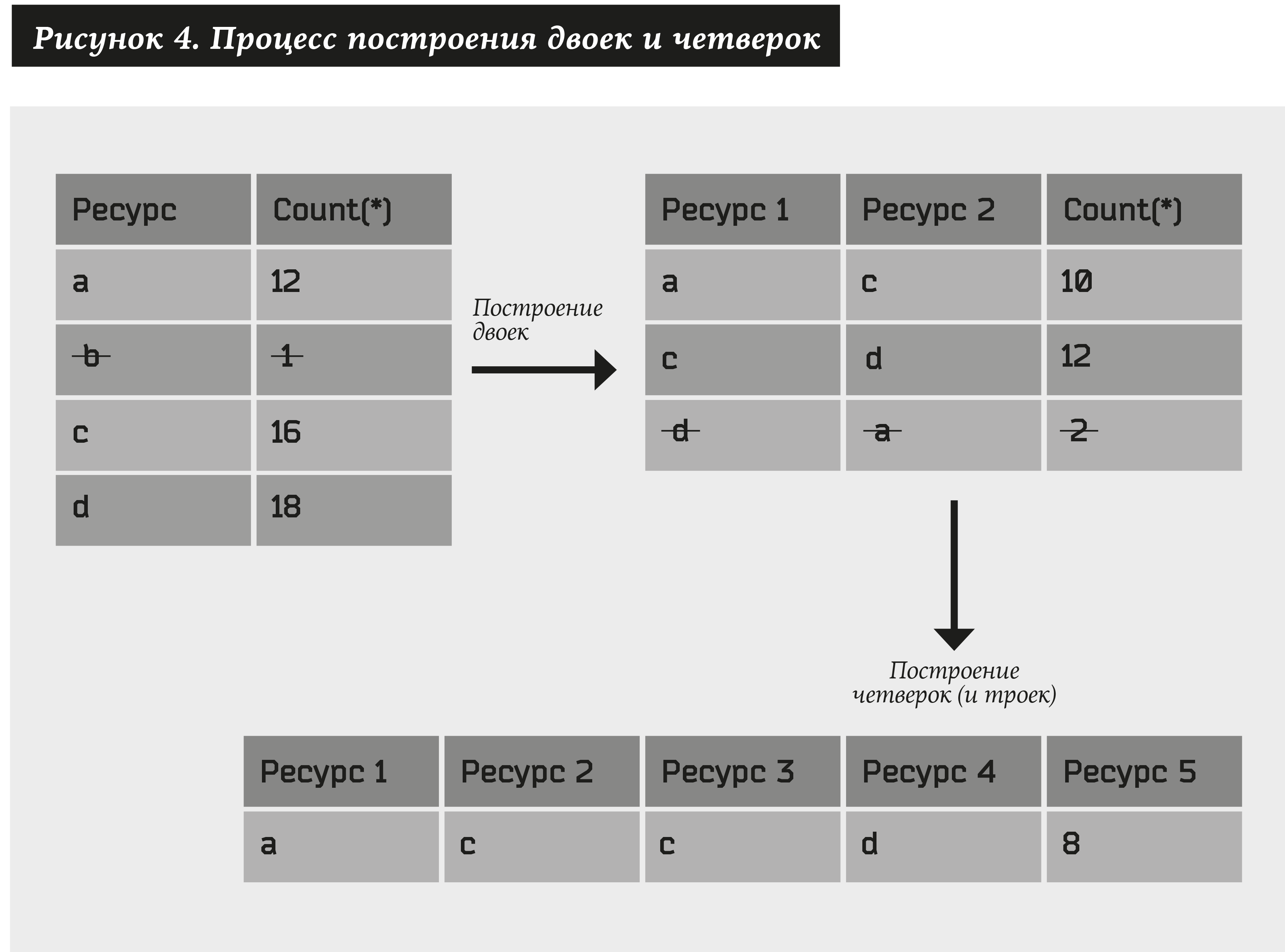
Você pode obter vários recursos de tamanho arbitrário. Limite o número de etapas para U. Então N1, N2 ... NU são os parâmetros do sistema.
Os valores N1, N2 ... NU são os parâmetros do algoritmo, são definidos manualmente. No caso geral, temos pares diferentes CL2, onde L é o número de recursos, ou seja, a dificuldade de construir pares será O (L2). Em seguida, um quad é criado a partir de cada par. E, em teoria, provavelmente obtemos O (L4). No entanto, na prática, esses pares são muito menores e, com um grande número de endereços, a dependência de O (L2log L) foi obtida empiricamente. Além disso, os passos subsequentes (transformar dois em quatro, quadruplicam em oito, etc.) são insignificantes.
Note-se que L é o número de URLs não agrupados em cluster. Todos os URLs que já podem ser atribuídos a qualquer cluster aprovado anteriormente não se enquadram na seleção para cluster.
Na saída, você pode criar muitos clusters que consistem nos maiores conjuntos possíveis de recursos. Por exemplo, se existir (a1, a2, a3, a4, a5) satisfazendo os limites de Ni, deve-se remover do conjunto de clusters (a1, a2, a3) e (a4, a5).
Em seguida, cada cluster recebido é enviado para verificação manual, onde o analista do CERT atribui o status: +1 ("aprovado") ou –1 ("rejeitado") e também indica se os URLs que se enquadram no cluster são sites de phishing ou legítimos.
Quando você adiciona um novo recurso, o número de URLs pode diminuir, permanecer o mesmo, mas nunca aumentar. Portanto, para todos os recursos a1 ... aN, a relação é verdadeira:
# (a1) ≥ # (a1, a2) ≥ # (a1, a2, a3) ≥ ... ≥ # (a1, a2, ..., aN).
Portanto, é aconselhável definir os parâmetros:
N1 ≥ N2 ≥ N3 ≥ ... ≥ NU.
Na saída, distribuímos todos os tipos de grupos para verificação. Na fig. 1 no início do artigo apresenta conjuntos reais para os quais todos os recursos são imagens.
Usando o algoritmo na prática
Observe que agora você não precisa mais explorar kits de phishing! O sistema clusters automaticamente e encontra a página de phishing necessária.
Todos os dias, o sistema recebe de 5.000 páginas de phishing e constrói um total de 3 a 25 novos clusters por dia. Para cada cluster, uma lista de recursos é carregada, muitas capturas de tela são criadas. Este cluster é enviado para a análise CERT para confirmação ou negação.
Na inicialização, a precisão do algoritmo era baixa - apenas 5%. No entanto, após 3 meses, o sistema manteve a precisão de 50 a 85%. De fato, a precisão não importa! O principal é que os analistas têm tempo para visualizar os clusters. Portanto, se o sistema, por exemplo, gerar cerca de 10.000 clusters por dia e você tiver apenas um analista, precisará alterar os parâmetros do sistema. Se não mais de 200 por dia, essa é uma tarefa viável para uma pessoa. Como mostra a prática, a análise visual, em média, leva cerca de 1 minuto.
A integridade do sistema é de cerca de 82%. Os 18% restantes são casos únicos de phishing (portanto, não podem ser agrupados), ou phishing, que possui uma pequena quantidade de recursos (não há nada para agrupar) ou páginas de phishing que ultrapassaram os limites dos parâmetros N1, N2 ... NU.
Um ponto importante: com que frequência iniciar um novo agrupamento em URLs novos e não entregues? Fazemos isso a cada 15 minutos. Além disso, dependendo da quantidade de dados, o tempo de armazenamento em cluster leva de 10 a 15 minutos. Isso significa que, após o aparecimento do URL de phishing, há um atraso de 30 minutos.
Abaixo estão duas capturas de tela do sistema GUI: assinaturas para detecção de phishing nas redes sociais VKontakte e Bank Of America.
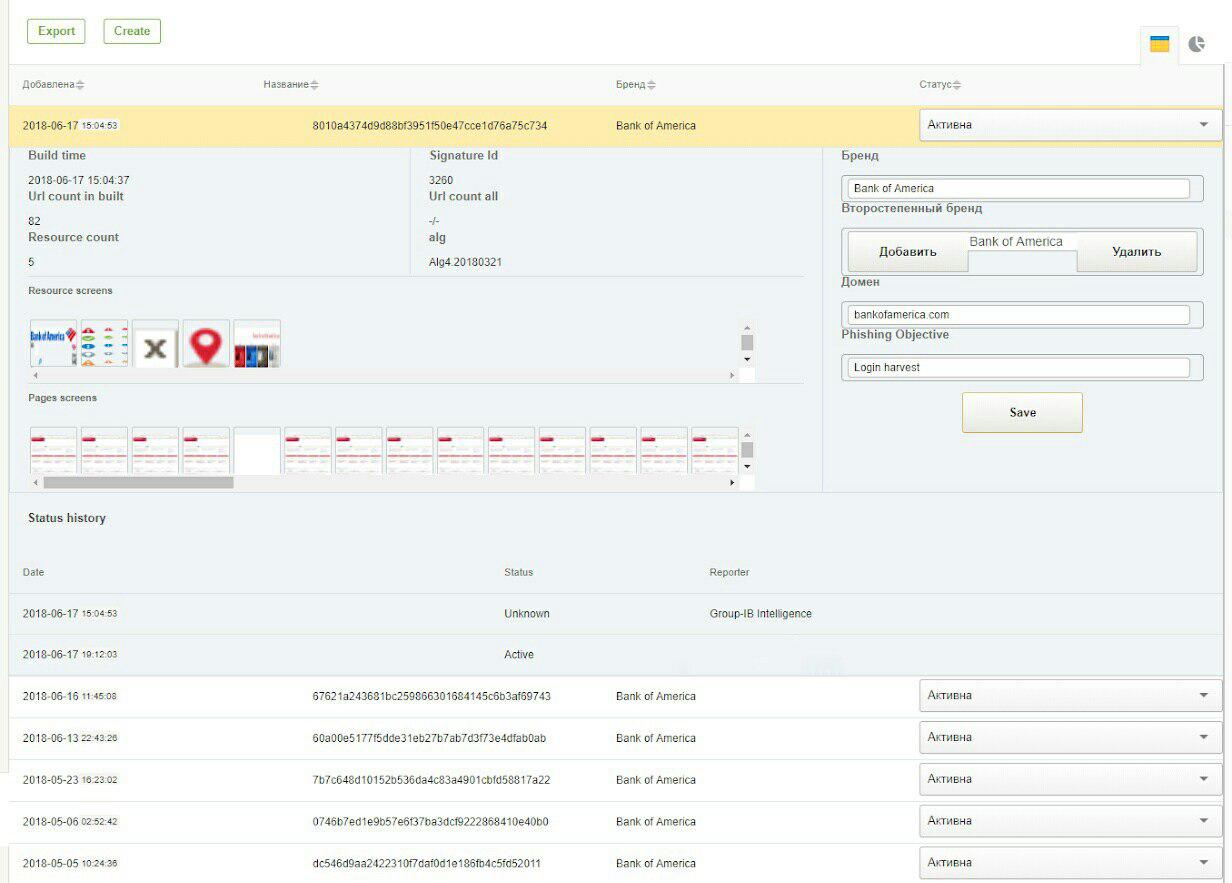
Quando o algoritmo não funciona
Como mencionado acima, o algoritmo não funciona em princípio se os limites especificados pelos parâmetros N1, N2, N3 ... NU não forem atingidos ou se o número de recursos for muito pequeno para formar o cluster necessário.
Um phisher pode ignorar o algoritmo criando recursos exclusivos para cada site de phishing. Por exemplo, em cada imagem você pode alterar um pixel e, para bibliotecas JS e CSS carregadas, usar ofuscamento. Nesse caso, é necessário desenvolver um algoritmo de hash comparável (hash perceptual) para cada tipo de documento carregado. No entanto, esses problemas estão além do escopo deste artigo.
Juntando tudo
Conectamos nosso módulo aos regulares regulares de HTML clássicos, aos dados obtidos da Threat Intelligence (sistema de inteligência cibernética) e obtemos uma plenitude de 99,4%. Obviamente, isso é completo em dados que já foram anteriormente classificados pela Threat Intelligence como suspeitos de phishing.
Ninguém sabe a totalidade de todos os dados possíveis, já que é impossível cobrir todo o Darknet em princípio; no entanto, de acordo com os relatórios do Gartner, IDC e Forrester, o Group-IB é um dos principais fornecedores internacionais de soluções de Inteligência contra Ameaças em seus recursos.
E as páginas de phishing não classificadas? Cerca de 25-50 deles por dia. Eles podem ser verificados manualmente. No geral, sempre há trabalho manual em qualquer tarefa que seja bastante difícil para o Data Sciense no campo da segurança da informação, e qualquer alegação de 100% de automação é uma ficção de marketing. A tarefa de um especialista em Data Sciense é reduzir o trabalho manual em 2-3 ordens de magnitude, tornando o trabalho do analista o mais eficiente possível.
Artigo publicado no
JETINFO