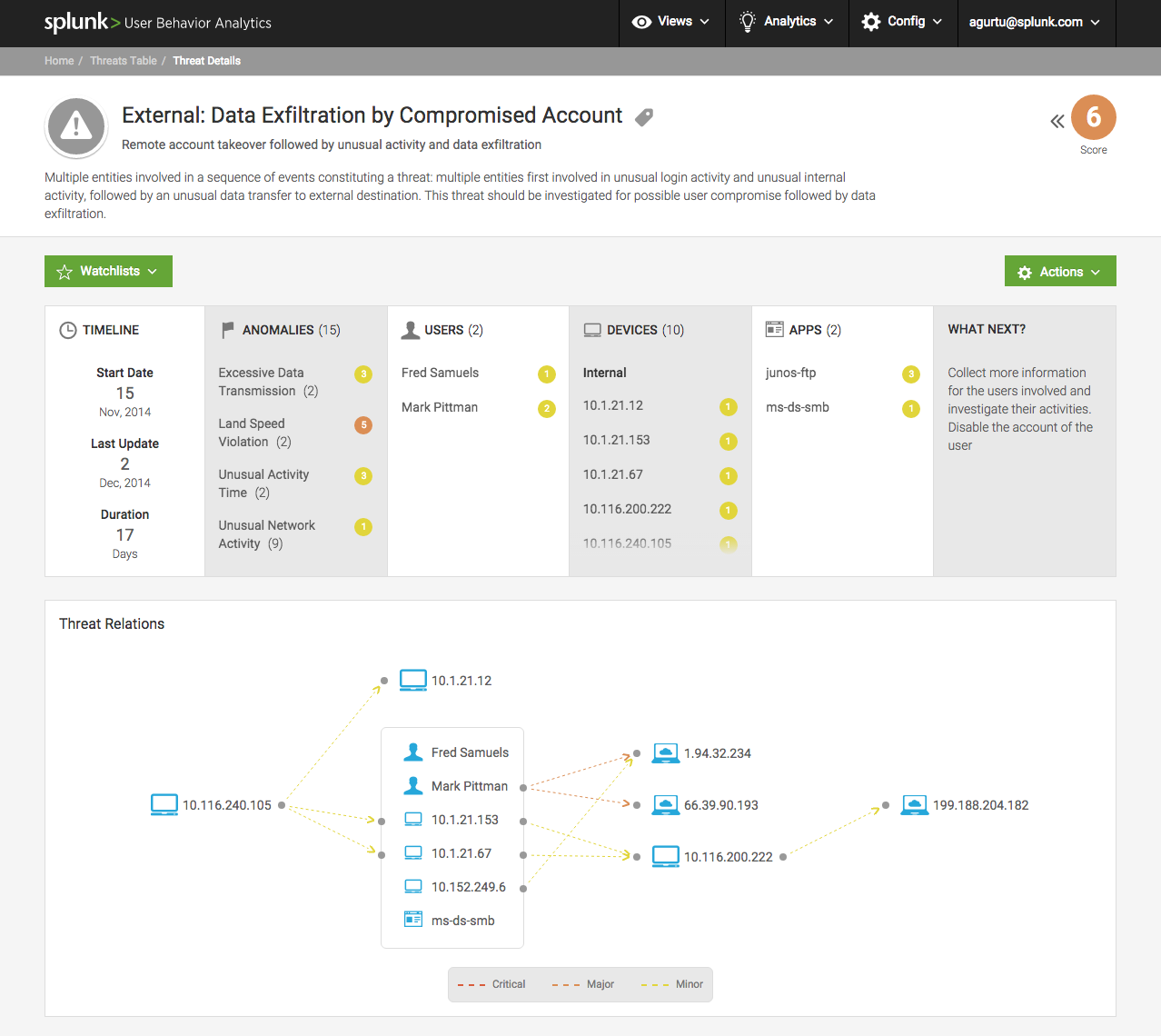
Captura de tela dos dados coletados:
 Os sistemas de segurança modernos são MUITO glutões aos recursos.
Os sistemas de segurança modernos são MUITO glutões aos recursos. Porque Porque eles contam mais do que muitos servidores de produção e sistemas de inteligência de negócios.
O que eles acham? Eu vou explicar agora. Vamos começar com um simples: por convenção, a primeira geração de dispositivos de proteção era muito simples - no nível de "inicialização" e "não inicialização". Por exemplo, um firewall permitia tráfego de acordo com certas regras e não permitia tráfego de acordo com outras. Naturalmente, um poder de computação especial não é necessário para isso.
A próxima geração adquiriu regras mais complexas. Portanto, havia sistemas de reputação que, dependendo de ações estranhas do usuário e mudanças nos processos de negócios, atribuíam a eles uma classificação de confiabilidade de acordo com modelos predefinidos e definiam manualmente os limites de operação.
Agora, os sistemas UBA (User Behavior Analytics) analisam o comportamento do usuário, comparando-o com outros funcionários da empresa, e avaliam a consistência e a correção da ação de cada funcionário. Isso é feito devido aos métodos do Data Lake e ao processamento bastante intensivo de recursos, mas automatizado pelos algoritmos de aprendizado de máquina - principalmente porque são necessários vários milhares de homens-dia para gravar todos os cenários possíveis com as mãos.
SIEM clássico
Até cerca de 2016, a abordagem era considerada progressiva quando todos os eventos de todos os nós da rede eram coletados em um local onde o servidor de análise está localizado. O servidor de análise pode coletar, filtrar eventos e mapeá-los para regras de correlação. Por exemplo, se uma gravação massiva de arquivos iniciar em alguma estação de trabalho, pode ser um sinal de vírus de criptografia ou pode não ser. Mas por precaução, o sistema enviará uma notificação ao administrador. Se houver várias estações, a probabilidade de implantação do malware aumenta. Temos que dar o alarme.
Se um usuário digitou algum domínio estranho registrado há algumas semanas e, após alguns minutos, toda essa música colorida foi lançada, esse é quase certamente um vírus de criptografia. É necessário extinguir a estação de trabalho e isolar o segmento de rede, notificando os administradores.
O SIEM comparou dados de DLP, firewall, antispam e assim por diante, e isso possibilitou responder muito bem a diferentes ameaças. O ponto fraco foram esses padrões e gatilhos - o que considerar uma situação perigosa e o que não. Além disso, como no caso de vírus e vários DDoS complicados, os especialistas do centro SOC começaram a formar suas bases de sinais de ataque. Para cada tipo de ataque, um cenário foi considerado, os sintomas se destacaram, ações adicionais foram atribuídas a eles. Tudo isso exigiu refinamento e ajuste contínuos do sistema no modo 24 por 7.
Funciona - não toque, mas tudo funciona bem!
É por isso que é impossível ficar sem o UBA? O primeiro problema é que é impossível prescrever com as mãos. Porque serviços diferentes se comportam de maneira diferente - e usuários diferentes também. Se você registrar eventos para o usuário médio da empresa, o suporte, a contabilidade, o departamento de propostas e os administradores serão muito distintos. O administrador do ponto de vista de um sistema como esse é claramente um usuário mal-intencionado, porque ele faz muito e rastreia ativamente para ele. O suporte é malicioso porque se conecta a todos. A contabilidade transmite dados através de túneis criptografados. E o departamento de propostas mescla constantemente os dados da empresa ao publicar a documentação.
Conclusão - é necessário prescrever cenários de uso de recursos para cada um. Então mais profundo. Então ainda mais profundo. Então, algo muda nos processos (e isso acontece todos os dias) e deve ser prescrito novamente.
Seria lógico usar algo como uma "média móvel" quando a norma para o usuário for determinada automaticamente. Voltaremos a isso.
O segundo problema foi que os atacantes se tornaram muito mais precisos. Anteriormente, a drenagem de dados, mesmo que você perdesse o momento do hacking, era bastante fácil de detectar - por exemplo, os hackers podiam fazer upload de um arquivo de interesse por correio ou hospedagem de arquivos e, na melhor das hipóteses, criptografá-lo em um arquivo para evitar a detecção pelo sistema DLP.
Agora tudo é mais interessante. É o que vimos em nossos centros de SOC no ano passado.
- Esteganografia através do envio de fotos para o Facebook. O malware registrado no FB e inscrito no grupo. Cada foto publicada no grupo foi equipada com um bloco de dados interno contendo instruções para o malware. Levando em conta as perdas durante a compactação JPEG, acabou transferindo cerca de 100 bytes por foto. Além disso, o próprio malware publicou 2-3 fotos por dia na rede social, o que foi suficiente para transferir logins / senhas mescladas através do mimikatz.
- Preenchendo formulários em sites. O malware executou um simulador de ação do usuário, foi a determinados sites, encontrou formulários de "feedback" e enviou dados através deles, codificando dados binários no BASE64. Isso já detectamos em um sistema de nova geração. No SIEM clássico, sem saber sobre esse método de envio, provavelmente eles nem notariam nada.
- De uma maneira padrão - infelizmente, de uma maneira padrão - eles misturaram dados no tráfego DNS. Existem muitas tecnologias para esteganografia no DNS e geralmente construindo túneis através do DNS, aqui a ênfase não estava na pesquisa de determinados domínios, mas nos tipos de solicitação. O sistema disparou um alarme menor sobre o crescimento do tráfego DNS para o usuário. Os dados foram enviados lentamente e em intervalos diferentes para dificultar a análise com recursos de segurança.
Para penetração, eles geralmente usam vírus estritamente personalizados, criados diretamente sob os usuários da empresa-alvo. Além disso, os ataques geralmente passam por um link intermediário. Por exemplo, no início o contratante fica comprometido e, por meio dele, o malware é inserido na empresa principal.
Os vírus dos últimos anos quase sempre ficam estritamente na RAM e são excluídos na primeira perspectiva - ênfase na ausência de traços. Forense em tais condições é muito difícil.
Resultado geral - o SIEM faz um mau trabalho. Muito do que sai de vista. Algo assim, um lugar vazio apareceu no mercado: para que o sistema não precisasse ser sintonizado com o tipo de ataque, mas ela própria entendeu o que estava errado.
Como ela "se entendeu"?
Os primeiros sistemas de segurança reputacionais foram módulos antifraude para proteção contra lavagem de dinheiro em bancos. Para o banco, o principal é identificar todas as transações fraudulentas. Ou seja, não é uma pena voltar um pouco, o principal é que o operador humano entenda o que deve ser visto primeiro. E ele não ficou impressionado com alarmes muito pequenos.
Os sistemas funcionam assim:
- Eles constroem um perfil de usuário com base em muitos parâmetros. Por exemplo, como ele geralmente gasta dinheiro: o que compra, como compra, com que rapidez ele digita um código de confirmação, de quais dispositivos ele faz etc.
- A camada lógica verifica se é possível obter tempo a partir do ponto em que o pagamento foi feito, para outro ponto no transporte durante o período entre as transações. Se a compra for em outra cidade, é verificado se o usuário viaja frequentemente para outras cidades, se em outro país - se o usuário visita outros países e se uma passagem aérea comprada recentemente aumenta a chance de o alarme não ser necessário.
- Módulo de reputação - se o usuário faz tudo dentro da estrutura de seu comportamento normal, então por suas ações são atribuídos pontos positivos (muito lentamente), e se dentro da estrutura de atípico - negativo.
Vamos falar sobre o último em mais detalhes.
Exemplo 1. Durante toda a sua vida, você comprou uma torta e cola no McDonald's às sextas-feiras e, de repente, comprou 500 rublos na terça-feira de manhã. Menos 2 pontos por um tempo fora do padrão, menos 3 pontos por uma compra fora do padrão. O limite de alarme para você é definido como –20. Nada está acontecendo.
Em cerca de 5-6 dessas compras, você retirará esses pontos para zero, porque o sistema lembrará que é normal você ir ao McDonald's na terça-feira de manhã. Obviamente, simplifico bastante, mas a lógica do trabalho é aproximadamente a mesma.
Exemplo 2. Durante toda a sua vida, você comprou várias coisas pequenas como usuário comum. Você paga na mercearia (o sistema já "sabe" quanto você costuma comer e onde costuma comprar, ou melhor, não sabe, mas simplesmente escreve em seu perfil) e compra um ingresso para o metrô por um mês ou pede algo pequeno através da loja online. E agora você compra um piano em Hong Kong por 8 mil dólares. Poderia? Poderia. Vejamos os pontos: –15 para o que parece ser uma fraude padrão, –10 para um valor fora do padrão, –5 para um local e horário fora do padrão, –5 para outro país sem comprar uma passagem, –7 por não ter usado nada antes eles levaram para o exterior, +5 para o dispositivo padrão, +5 para o que outros usuários do banco compraram lá.
O limite de alarme para você é definido como –20. A transação é "suspensa", um funcionário do IB do banco começa a entender a situação. Este é um caso muito simples. Muito provavelmente, após 5 minutos, ele ligará para você e dirá: "Você realmente decidiu comprar algo em uma loja de música em Hong Kong às 4 da manhã por 8 mil dólares?" Se você responder sim, eles pularão a transação. Os dados cairão no perfil como uma ação concluída e, para ações semelhantes, menos pontos negativos serão dados até que se tornem a norma.
Como eu disse, eu realmente simplifico. Os bancos investem em sistemas de reputação há anos e os aprimoram há anos. Caso contrário, um monte de mulas retiraria dinheiro muito rápido.
Como isso é transferido para a segurança da informação corporativa?
Com base nos algoritmos antifraude e lavagem de dinheiro, os sistemas de análise comportamental são exibidos. Um perfil completo do usuário é coletado: a rapidez com que imprime, quais recursos acessa, com quem interage, qual software ele lança - em geral, tudo o que o usuário faz todos os dias.
Um exemplo O usuário geralmente interage com o 1C e, geralmente, insere os dados lá e, de repente, começa a descarregar todo o banco de dados em dezenas de pequenos relatórios. Seu comportamento vai além do comportamento padrão para esse usuário, mas ele pode ser comparado ao comportamento de perfis semelhantes por tipo (provavelmente, esses serão outros contadores) - é claro que eles têm uma semana de relatórios chegando em determinados horários e todos fazem isso. Os números são os mesmos, não há outras diferenças, o alarme não dispara.
Outro exemplo Um usuário trabalhou com uma bola de arquivos durante toda a sua vida, gravando algumas dezenas de documentos por dia e, de repente, começou a retirar centenas e milhares de arquivos. E outro DLP diz que envia algo importante. Talvez o departamento de licitações tenha começado os preparativos para a competição, talvez o “rato” esteja vazando dados para os concorrentes. O sistema, é claro, não sabe disso, mas simplesmente descreve seu comportamento e alarma os guardas de segurança. Fundamentalmente, o comportamento de um novo funcionário, suporte técnico ou CEO, pode diferir pouco do comportamento do "cossaco maltratado", e a tarefa do pessoal de segurança é dizer ao sistema que esse é um comportamento normal. O perfil seguirá de qualquer maneira e, se a conta do diretor geral for comprometida e a reputação cair em pontos, o alarme disparará.
Os perfis de usuário dão origem a regras para o sistema UBA. Mais precisamente, milhares de heurísticas que mudam regularmente. Cada grupo de usuários tem seus próprios princípios. Por exemplo, usuários desse tipo enviam 100 MB por dia, usuários do outro enviam 1 GB por dia, se não for um fim de semana. E assim por diante Se o primeiro enviar 5 GB, isso é suspeito. E se o segundo - então haverá pontos negativos, mas eles não vão quebrar o limite de alarme. Mas se por perto ele ativou o DNS para novos domínios suspeitos, haverá mais alguns pontos negativos e o alarme já ocorrerá.
A abordagem é que essa não é a regra "se houver consultas DNS estranhas e o tráfego aumentar, então ..." e a regra "se a reputação atingir –20, então ..." - cada fonte individual de pontos para a reputação do usuário ou processo é independente e determinada exclusivamente a norma de seu comportamento. Automaticamente.
Ao mesmo tempo, inicialmente, o departamento de segurança da informação ajuda a treinar o sistema e determinar qual é a norma e o que não é, e depois o sistema se adapta, se treina novamente no tráfego real e nos logs de atividades do usuário.
O que colocamos
Como integrador de sistemas, fornecemos aos nossos clientes um serviço para o gerenciamento operacional da segurança da informação (serviço
SOC CROC gerenciado). Um componente essencial, juntamente com sistemas como Asset Management, Vulnerability Management, Security Testing e Threat Intelligence, disponível em nossa infraestrutura de nuvem, é o elo entre o SIEM clássico e o UBA proativo. Ao mesmo tempo, dependendo da vontade do cliente, para a UBA, podemos usar as soluções industriais de grandes fornecedores e nosso próprio sistema analítico baseado no pacote Hadoop + Hive + Redis + Splunk Analytics for Hadoop (Hunk).
As seguintes soluções estão disponíveis para análise comportamental em nosso SOC CROC na nuvem ou de acordo com o modelo no local:
- Exabeam: talvez o sistema UBA mais amigável que permita investigar rapidamente um incidente por meio da tecnologia User Tracking, que conecta atividades na infraestrutura de TI (por exemplo, logon de banco de dados local na conta SA) a um usuário real. Inclui cerca de 400 modelos de pontuação de risco que adicionam pontos de penalidade ao usuário para cada ação estranha ou suspeita;
- Securonix: um sistema de análise comportamental com muita fome de recursos, mas extremamente eficaz. O sistema é colocado no topo da plataforma Big Data, quase 1000 modelos estão disponíveis imediatamente. A maioria deles usa tecnologia de cluster proprietária para a atividade do usuário. O mecanismo é muito flexível, você pode rastrear e agrupar qualquer campo do formato CEF, começando pelo desvio do número médio de solicitações por dia pelos logs do servidor da web e terminando com a identificação de novas interações de rede para o tráfego do usuário;
- Splunk UBA: Um bom complemento para o Splunk ES. A base de regras pronta para uso é pequena, mas com referência à cadeia de mortes, que permite que você não se distraia com incidentes menores e se concentre em um hacker real. E, é claro, temos à disposição todo o poder do processamento de dados estatísticos no Splunk Machine Learning Toolkit e uma análise retrospectiva de todo o volume de dados acumulados.
E para segmentos críticos, seja um sistema automatizado de controle de processos ou um aplicativo de negócios importante, colocamos sensores adicionais para coletar forenses e hanitopos avançados para desviar a atenção do hacker dos sistemas produtivos.
Por que um mar de recursos?
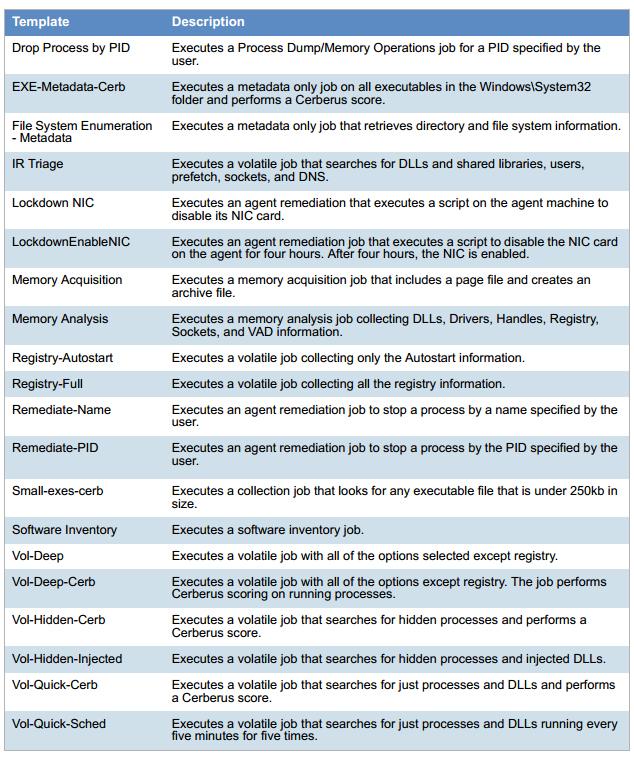
Porque todos os eventos são gravados. É como o Google Analytics, apenas na estação de trabalho local. Na rede local, os eventos são enviados ao Data Lake por meio dos metadados da Internet sobre estatísticas e eventos importantes, mas se o operador do SOC desejar investigar o incidente, também haverá um registro completo registrado. Tudo é coletado: arquivos temporários, chaves de registro, todos os processos em execução e suas somas de verificação, escritos na inicialização, ações, screencast - o que for. Abaixo está um exemplo dos dados coletados.
Lista de parâmetros da estação de trabalho:


Os sistemas em termos de armazenamento e RAM tornam-se muito mais complicados. O SIEM clássico começa com 64 GB de RAM, dois processadores e meio terabyte de armazenamento. O UBA é de um terabyte de RAM e superior. Por exemplo, nossa última implementação foi em 33 servidores físicos (28 nós de computação para processamento de dados + 5 nós de controle para balanceamento de carga), lagos de 150 TB (600 TB em hardware, incluindo cache rápido em instâncias) e 384 GB de RAM cada.
Quem precisa disso?
Antes de tudo, aqueles que estão na “zona de risco” e são constantemente atacados são bancos, instituições financeiras, setor de petróleo e gás, grande varejo e muitos outros.
Para essas empresas, o custo do vazamento ou perda de dados pode chegar a dezenas ou até centenas de milhões de dólares. Mas instalar um sistema UBA custará muito menos. E, é claro, empresas estatais e telecomunicações, porque ninguém quer, em algum momento, os dados de milhões de pacientes ou a correspondência de dezenas de milhões de pessoas flutuando em acesso aberto.
Referências