
Hoje, é difícil imaginar o desenvolvimento de software de alta qualidade sem o uso de
métodos estáticos de análise de código . A análise estática do código do programa pode ser incorporada ao ambiente de desenvolvimento (por métodos padrão ou usando plug-ins), pode ser realizada por software especializado antes que o código seja colocado em operação comercial ou "manualmente" por um especialista regular ou externo.
Costuma-se argumentar que
a análise dinâmica de código ou os
testes de penetração podem substituir a análise estática, pois esses métodos de verificação revelam problemas reais e não há falsos positivos. No entanto, esse é um ponto discutível, porque a análise dinâmica, ao contrário da análise estática, não verifica todo o código, mas apenas a resistência do software a um conjunto de ataques que imitam as ações de um invasor. Um invasor pode ser mais inventivo que o verificador, independentemente de quem realiza a verificação: uma pessoa ou uma máquina.
A análise dinâmica será concluída apenas se for realizada em uma cobertura de teste completa, que, quando aplicada a aplicativos reais, é uma tarefa difícil. A prova da completude da cobertura do teste é um problema algoritmicamente insolúvel.
A análise estática obrigatória do código do programa é uma das etapas necessárias ao comissionar software com requisitos maiores de segurança da informação.
No momento, existem muitos analisadores de código estático diferentes no mercado, e mais e mais novos estão aparecendo constantemente. Na prática, há casos em que vários analisadores estáticos são usados juntos para melhorar a qualidade da verificação, uma vez que diferentes analisadores procuram defeitos diferentes.
Por que não existe um analisador estático universal que verifique completamente qualquer código e encontre todos os defeitos nele sem falsos positivos e, ao mesmo tempo, trabalhe rapidamente e não exija muitos recursos (tempo e memória da CPU)?
Um pouco sobre a arquitetura dos analisadores estáticos
A resposta para essa pergunta está na arquitetura dos analisadores estáticos. Quase todos os analisadores estáticos são de alguma forma construídos com base no princípio dos compiladores, ou seja, em seu trabalho há estágios de conversão de código-fonte - os mesmos que os realizados pelo compilador.
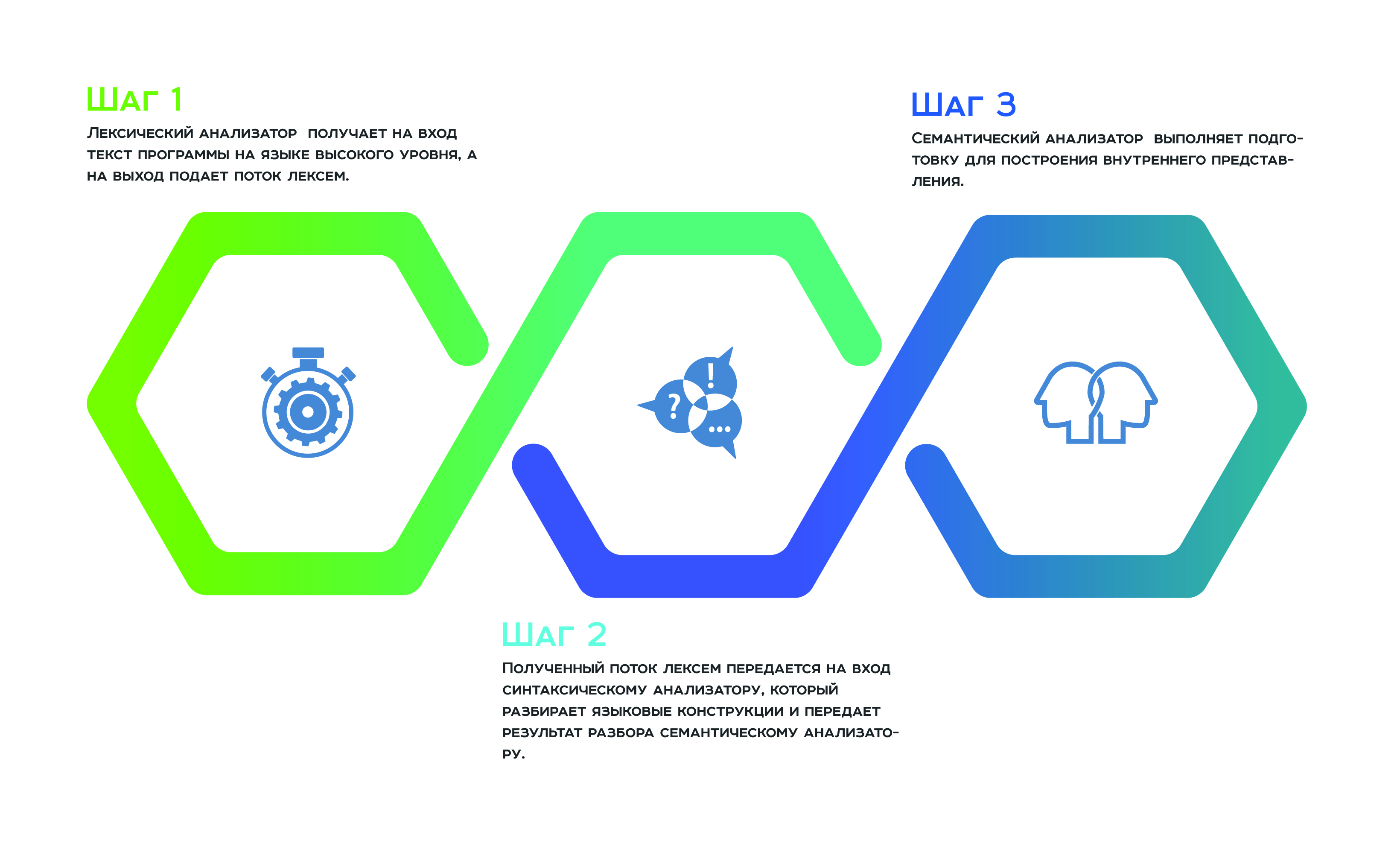
Tudo começa com uma
análise lexical , que recebe o texto do programa em um idioma de alto nível como entrada e um fluxo de tokens para a saída. Em seguida, o fluxo de token recebido é transmitido à entrada
para o analisador , que analisa as construções de linguagem e passa o resultado da análise para o
analisador semântico , que, como resultado de seu trabalho, se prepara para construir a representação interna. Essa representação interna é um recurso de todo analisador estático. A eficiência do analisador depende de quão bem-sucedido é.
Muitos fabricantes de analisadores estáticos afirmam usar uma representação interna universal para todas as linguagens de programação suportadas pelo analisador. Assim, eles podem analisar o código do programa desenvolvido em várias linguagens como um todo, e não como componentes separados. Uma “abordagem holística” da análise permite evitar a omissão de defeitos que surgem na interface entre os componentes individuais de um produto de software.
Em teoria, isso é verdade, mas, na prática, uma representação interna universal para todas as linguagens de programação é difícil e ineficiente. Cada linguagem de programação é especial. Uma visão interna é geralmente uma árvore cujos vértices armazenam atributos. Ao atravessar uma árvore, o analisador coleta e converte informações. Portanto, cada vértice da árvore deve conter um conjunto uniforme de atributos. Como cada idioma é único, a uniformidade de atributos só pode ser suportada pela redundância de componentes. As linguagens de programação mais heterogêneas, os componentes mais heterogêneos nas características de cada vértice e, portanto, a representação interna é ineficiente da memória. Um grande número de características heterogêneas também afeta a complexidade dos caminhantes, o que significa que leva a ineficiências no desempenho.
Conversões de otimização para analisadores estáticos
Para que o analisador estático funcione eficientemente na memória e no tempo, é necessário ter uma representação interna universal compacta, e isso pode ser alcançado pelo fato de a representação interna ser dividida em várias árvores, cada uma delas projetada para linguagens de programação relacionadas.
O trabalho de otimização não se limita a dividir a representação interna em linguagens de programação relacionadas. Além disso, os fabricantes usam várias transformações de otimização - o mesmo que nas tecnologias de compilador, em particular,
transformações de otimização de ciclos . O fato é que o objetivo da análise estática é idealmente promover a promoção de dados no programa para avaliar sua transformação durante a execução do programa. Portanto, os dados devem ser "avançados" a cada volta do ciclo. Portanto, se você economizar nessas mesmas curvas e torná-las muito menores, obteremos benefícios significativos na memória e no desempenho. É para esse fim que tais transformações são ativamente usadas que, com alguma probabilidade, executam a extrapolação da transformação de dados para todas as voltas do ciclo com o número mínimo de passes.
Você também pode economizar nas ramificações calculando a probabilidade de o programa continuar em uma ou outra ramificação. Se a probabilidade de passagem ao longo de uma ramificação for menor que isso, essa ramificação do programa não será considerada.
Obviamente, cada uma dessas transformações "perde" os defeitos que o analisador deve detectar, mas essa é uma "taxa" pela eficiência e desempenho da memória.
O que um analisador de código estático está procurando?
Condicionalmente, os defeitos que estão de alguma forma interessados em invasores e, portanto, auditores, podem ser divididos nos seguintes grupos:
- erros de validação
- erros de vazamento de informações,
- erros de autenticação.
Os erros de validação ocorrem como resultado do fato de os dados de entrada não serem adequadamente verificados quanto à correção. Um invasor pode usar como entrada o que não é o que o programa espera e, assim, obter acesso não autorizado ao controle. Os erros mais comuns de validação de dados são injeções e
XSS . Em vez de dados válidos, o invasor envia ao programa dados especialmente preparados que carregam um programa pequeno. Este programa, sendo processado, é executado. O resultado de sua implementação pode ser a transferência de controle para outro programa, corrupção de dados e muito, muito mais. Além disso, como resultado de erros de validação, o site com o qual o usuário está trabalhando pode ser substituído. Erros de validação podem ser detectados qualitativamente por métodos de análise de código estático.
Erros de
vazamento de informações são erros relacionados ao fato de que informações confidenciais do usuário como resultado do processamento foram interceptadas e transmitidas ao invasor. Pode ser vice-versa: informações confidenciais armazenadas no sistema são interceptadas e transmitidas ao invasor à medida que elas se movem para o usuário.
Tais vulnerabilidades são tão difíceis de detectar quanto erros de validação. A detecção desse tipo de erro requer rastrear nas estatísticas o progresso e a conversão de dados em todo o código do programa. Isso requer a implementação de métodos como
análise de contaminação e
análise de dados interprocedural . A precisão da análise depende em grande parte de quão bem esses métodos são desenvolvidos, ou seja, minimizando falsos positivos e erros perdidos.
A biblioteca de regras para detectar defeitos, em particular o formato para descrever essas regras, também desempenha um papel significativo na precisão do analisador estático. Tudo isso é uma vantagem competitiva de cada analisador e é cuidadosamente protegido dos concorrentes.
Erros de autenticação são os
erros mais interessantes para um invasor, pois são difíceis de detectar porque surgem na junção de componentes e são difíceis de formalizar. Os invasores exploram esse tipo de erro para aumentar os direitos de acesso. Os erros de autenticação não são detectados automaticamente, pois não está claro o que procurar - esses são erros na lógica da criação do programa.
Erros de memória
Eles são difíceis de detectar porque a identificação precisa requer a solução de um sistema complicado de equações, que é caro tanto na memória quanto no desempenho. Portanto, o sistema de equações é reduzido, o que significa que a precisão é perdida.
Os erros de memória típicos incluem
desreferência de uso após livre ,
dupla e sem ponteiro nulo e suas variedades, por exemplo,
Leitura fora dos limites e Gravação fora dos limites .
Quando o próximo analisador falhou em detectar um vazamento de memória, você pode ouvir que esses defeitos são difíceis de explorar. Um invasor deve ser altamente qualificado e aplicar muita habilidade para, em primeiro lugar, descobrir a presença de um defeito no código e, em segundo lugar, fazer uma exploração. Bem, o argumento continua: “Você tem certeza de que seu produto de software é interessante para um guru desse nível?” ... No entanto, a história conhece casos em que erros de memória foram explorados com sucesso e causaram danos consideráveis. Como exemplos, você pode citar situações conhecidas como:
- CVE-2014-0160 - um erro na biblioteca openssl - um comprometimento potencial de chaves privadas exigia uma reemissão de todos os certificados e regeneração de senha.
- CVE-2015-2712 - bug na implementação do js no mozilla firefox - verificação de limites.
- CVE-2010-1117 - use gratuitamente no Internet Explorer - explorável remotamente.
- CVE-2018-4913 - use gratuitamente no Acrobat Reader - execução de código.
Além disso, os invasores gostam de explorar defeitos associados à sincronização inadequada de threads ou processos. Tais defeitos são difíceis de identificar na estática, porque simular o estado de uma máquina sem o conceito de "tempo" não é uma tarefa fácil. Isso se refere a erros como
condição de corrida . E hoje, a simultaneidade é usada em qualquer lugar, mesmo em aplicativos muito pequenos.
Resumindo o exposto, note-se que um analisador estático é útil no processo de desenvolvimento, se for usado corretamente. Durante a operação, é necessário entender o que esperar dele e o que fazer com os defeitos que o analisador estático não pode identificar em princípio. Se eles dizem que um analisador estático não é necessário durante o processo de desenvolvimento, significa que eles simplesmente não sabem como operá-lo.
Como operar corretamente o analisador estático, para trabalhar de maneira correta e eficiente com as informações que ele fornece, leia em nosso blog.