Desde o início de 2017, nossa pequena equipe desenvolve a
biblioteca RESTinio OpenSource para incorporar um servidor HTTP em aplicativos C ++. Para nossa grande surpresa, de tempos em tempos, recebemos perguntas da categoria "E por que um servidor HTTP C ++ incorporado pode ser necessário?" Infelizmente, perguntas simples são as mais difíceis de responder. Às vezes, a melhor resposta é um código de exemplo.
Há alguns meses, iniciamos um pequeno
projeto de demonstração, o Shrimp , que demonstra claramente um cenário típico, sob o qual nossa biblioteca é "afiada". O projeto de demonstração é um serviço da Web simples que recebe solicitações de dimensionamento de imagens armazenadas no servidor e retorna uma imagem do tamanho que o usuário precisa.
Este projeto de demonstração é bom, pois requer, em primeiro lugar, a integração com um código escrito há muito tempo e funcionando corretamente em C ou C ++ (neste caso, ImageMagick). Portanto, deve ficar claro por que faz sentido incorporar o servidor HTTP em um aplicativo C ++.
Além disso, nesse caso, o processamento de solicitações assíncronas é necessário para que o servidor HTTP não bloqueie enquanto a imagem está sendo dimensionada (e isso pode levar centenas de milissegundos ou mesmo segundos). Iniciamos o desenvolvimento do RESTinio precisamente porque não conseguimos encontrar um servidor incorporado C ++ sadio focado especificamente no processamento de solicitações assíncronas.
Construímos o trabalho sobre o Shrimp de forma iterativa: primeiro, a versão mais simples foi criada e
descrita , que apenas ampliava as imagens. Em seguida, corrigimos várias deficiências da primeira versão e
descrevemos isso no segundo artigo . Finalmente, conseguimos expandir a funcionalidade do Shrimp mais uma vez: a conversão de imagens de um formato para outro foi adicionada. Sobre como isso foi feito e será discutido neste artigo.
Suporte ao formato de destino
Portanto, na próxima versão do Shrimp, adicionamos a capacidade de fornecer uma imagem em escala em um formato diferente. Portanto, se você emitir uma solicitação de camarão no formulário:
curl "http://localhost:8080/my_picture.jpg?op=resize&max=1920"
o Shrimp renderizará a imagem no mesmo formato JPG da imagem original.
Mas se você adicionar o parâmetro de formato de destino à URL, o Shrimp converterá a imagem no formato de destino especificado. Por exemplo:
curl "http://localhost:8080/my_picture.jpg?op=resize&max=1920&target-format=webp"
Nesse caso, o Shrimp renderizará a imagem no formato webp.
O Shrimp atualizado suporta cinco formatos de imagem: jpg, png, gif, webp e heic (também conhecido como HEIF). Você pode experimentar vários formatos
em uma página da web especial :
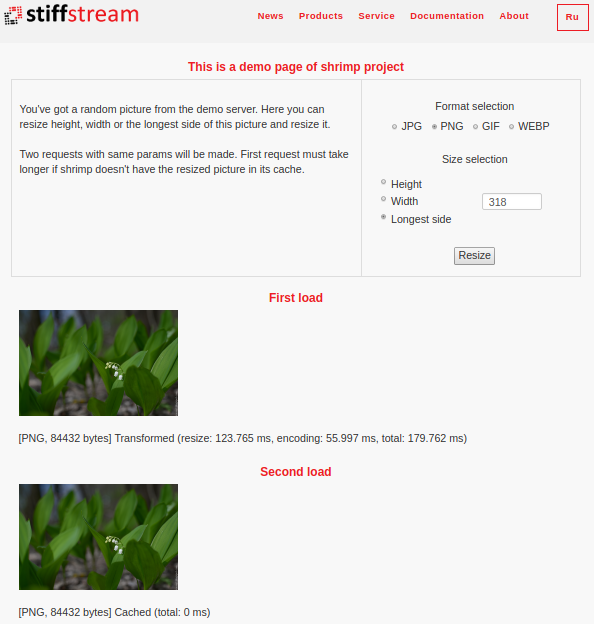
(nesta página, não há como selecionar o formato heic, porque os navegadores comuns da área de trabalho não suportam esse formato por padrão).
Para suportar o formato de destino no Shrimp, foi necessário modificar levemente o código do Shrimp (o que nós mesmos ficamos surpresos, porque realmente havia poucas alterações). Mas, por outro lado, tive que brincar com a montagem do ImageMagick, com a qual ficamos ainda mais surpresos, pois Antes, tivemos que lidar com esta cozinha, por uma feliz coincidência. Mas vamos falar sobre tudo em ordem.
O ImageMagick deve entender diferentes formatos
O ImageMagick usa bibliotecas externas para codificar / decodificar imagens: libjpeg, libpng, libgif, etc. Essas bibliotecas devem ser instaladas no sistema antes que o ImageMagick seja configurado e construído.
O mesmo deve acontecer para o ImageMagick suportar os formatos webp e heic: primeiro você precisa criar e instalar libwebp e libheif, depois configurar e instalar o ImageMagick. E se tudo é simples com a libwebp, então em torno da libhe se eu tivesse que dançar com um pandeiro. Embora, depois de algum tempo, depois que tudo finalmente se reunisse e funcionasse, já não estava claro: por que você teve que recorrer a um pandeiro, tudo parece ser trivial? ;)
Em geral, se alguém quiser fazer amizade com o heic e o ImageMagick, você precisará instalar:
Está nesta ordem (pode ser necessário instalar o
nasm para que o x265 funcione na velocidade máxima). Em seguida, ao emitir o comando
./configure , o ImageMagick poderá encontrar tudo o que precisa para suportar arquivos .heic.
Suporte ao formato de destino na sequência de consultas de solicitações recebidas
Depois de fazer o ImageMagick fazer amizade com os formatos webp e heic, é hora de modificar o código do camarão. Primeiro de tudo, precisamos aprender como reconhecer o argumento do formato de destino nas solicitações HTTP recebidas.
Do ponto de vista do RESTinio, isso não é um problema. Bem, outro argumento apareceu na string de consulta, e daí? Mas, do ponto de vista do Shrimp, a situação acabou sendo um pouco mais complicada, de modo que o código da função responsável pela análise da solicitação HTTP se tornou mais complicado.
O fato é que antes era necessário distinguir apenas duas situações:
- veio uma solicitação no formato "/filename.ext" sem nenhum outro parâmetro. Então você só precisa dar o arquivo "filename.ext" como está;
- Uma solicitação veio no formato "/filename.ext?op=resize & ...". Nesse caso, você precisa dimensionar a imagem a partir do arquivo "filename.ext".
Porém, após adicionar o formato de destino, precisamos distinguir entre quatro situações:
- veio uma solicitação no formato "/filename.ext" sem nenhum outro parâmetro. Então você só precisa dar o arquivo "filename.ext" como está, sem redimensionar e sem transcodificar para outro formato;
- veio uma solicitação no formato "/filename.ext?target-format=fmt" sem nenhum outro parâmetro. Significa pegar uma imagem do arquivo "filename.ext" e transcodificá-la para o formato "fmt", preservando os tamanhos originais;
- uma solicitação veio no formato "/filename.ext?op=resize & ...", mas sem o formato de destino. Nesse caso, você precisa dimensionar a imagem no arquivo “filename.ext” e fornecê-la no formato original;
- Uma solicitação veio no formato "/filename.ext?op=resize&...&target-format=fmt". Nesse caso, você precisa executar a escala e depois transcodificar o resultado no formato "fmt".
Como resultado, a função para determinar os parâmetros da consulta assumiu o
seguinte formato :
void add_transform_op_handler( const app_params_t & app_params, http_req_router_t & router, so_5::mbox_t req_handler_mbox ) { router.http_get( R"(/:path(.*)\.:ext(.{3,4}))", restinio::path2regex::options_t{}.strict( true ), [req_handler_mbox, &app_params]( auto req, auto params ) { if( has_illegal_path_components( req->header().path() ) ) { // . return do_400_response( std::move( req ) ); } // . const auto qp = restinio::parse_query( req->header().query() ); const auto target_format = qp.get_param( "target-format"sv ); // // . target-format, // . target-format // , , // . const auto image_format = try_detect_target_image_format( params[ "ext" ], target_format ); if( !image_format ) { // . . return do_400_response( std::move( req ) ); } if( !qp.size() ) { // , . return serve_as_regular_file( app_params.m_storage.m_root_dir, std::move( req ), *image_format ); } const auto operation = qp.get_param( "op"sv ); if( operation && "resize"sv != *operation ) { // , resize. return do_400_response( std::move( req ) ); } if( !operation && !target_format ) { // op=resize, // target-format=something. return do_400_response( std::move( req ) ); } handle_resize_op_request( req_handler_mbox, *image_format, qp, std::move( req ) ); return restinio::request_accepted(); } ); }
Na versão anterior do Shrimp, onde você não precisava transcodificar a imagem, trabalhar com os parâmetros de solicitação
parecia um pouco mais fácil .
Fila de solicitação e cache de imagem adaptados ao formato de destino
O próximo ponto na implementação do suporte ao formato de destino foi o trabalho na fila de solicitações em espera e um cache de imagens prontas no agente a_transform_manager. Falamos sobre essas coisas
com mais detalhes
no artigo anterior , mas vamos lembrá-lo um pouco do que se tratava.
Quando uma solicitação de conversão de imagem chega, pode ser que a imagem finalizada com esses parâmetros já esteja no cache. Nesse caso, você não precisa fazer nada, basta enviar a imagem do cache em resposta. Se a imagem precisar ser transformada, é possível que não haja trabalhadores livres no momento e você precisará esperar até que ela apareça. Para fazer isso, as informações da solicitação devem estar na fila. Mas, ao mesmo tempo, é necessário verificar a exclusividade das solicitações - se tivermos três solicitações idênticas aguardando processamento (ou seja, precisamos converter a mesma imagem da mesma maneira), devemos processar a imagem apenas uma vez e fornecer o resultado do processamento em resposta para esses três pedidos. I.e. Na fila de espera, solicitações idênticas devem ser agrupadas.
No Shrimp, usamos uma chave composta simples para pesquisar o cache da imagem e a fila de espera: uma
combinação do nome do arquivo original + das opções de redimensionamento da imagem . Agora, dois novos fatores precisavam ser levados em consideração:
- em primeiro lugar, o formato da imagem de destino (ou seja, a imagem original pode estar em jpg e a imagem resultante pode estar em png);
- segundo, o fato de não ser necessário dimensionar a imagem. Isso acontece em uma situação em que o cliente solicita apenas a conversão da imagem de um formato para outro, mas com o tamanho original da imagem preservado.
Devo dizer que aqui seguimos o caminho mais simples, sem tentar otimizar algo. Por exemplo, pode-se tentar fazer dois caches: um armazenaria imagens no formato original, mas redimensionadas para o tamanho desejado e, no segundo, as imagens redimensionadas convertidas para o formato de destino.
Por que esse cache duplo seria necessário? O fato é que, ao transformar imagens, as duas operações mais caras no tempo estão redimensionando e serializando a imagem para o formato de destino. Portanto, se recebemos uma solicitação para dimensionar a imagem example.jpg para um tamanho de 1920 na largura e transformá-la no formato webp, poderíamos armazenar duas imagens em nossa memória: example_1920px_width.jpg e example_1920px_width.webp. Damos uma imagem example_1920px_width.webp quando recebemos uma segunda solicitação. Mas a imagem example_1920px_width.jpg pode ser usada ao receber solicitações para dimensionar example.jpg para um tamanho de 1920 na largura e transformá-lo em formato heic. Poderíamos pular a operação de redimensionamento e fazer apenas a conversão de formato (ou seja, a imagem final example_1920px_width.jpg seria transcodificada para o formato heic).
Outra oportunidade potencial: quando uma solicitação é transcodificar uma imagem para outro formato sem redimensionar, você pode determinar o tamanho real da imagem e usar esse tamanho dentro da chave composta. Por exemplo, deixe exemplo.jpg ter um tamanho de 3000x2000 pixels. Se, em seguida, recebermos uma solicitação para dimensionar example.jpg para 2000 px de altura, poderemos determinar imediatamente que já temos uma imagem desse tamanho.
Em teoria, todas essas considerações merecem atenção. Mas, do ponto de vista prático, não está claro quão alta é a probabilidade de tal desenvolvimento de eventos. I.e. com que frequência receberemos uma solicitação de dimensionamento example.jpg para 1920px com conversão para webp e, em seguida, uma solicitação para o mesmo dimensionamento da mesma imagem, mas com conversão para png? Não ter estatísticas reais é difícil de dizer. Portanto, decidimos não complicar nossas vidas em nosso projeto de demonstração, mas seguir o caminho mais simples. Com a expectativa de que se alguém precisar de esquemas de armazenamento em cache mais avançados, isso poderá ser adicionado posteriormente, a partir de cenários reais, não fictícios, para o uso do Shrimp.
Como resultado, na versão atualizada do Shrimp, expandimos ligeiramente a chave, adicionando a ela também um parâmetro como o formato de destino:
class resize_request_key_t { std::string m_path; image_format_t m_format; resize_params_t m_params; public: resize_request_key_t( std::string path, image_format_t format, resize_params_t params ) : m_path{ std::move(path) } , m_format{ format } , m_params{ params } {} [[nodiscard]] bool operator<(const resize_request_key_t & o ) const noexcept { return std::tie( m_path, m_format, m_params ) < std::tie( o.m_path, o.m_format, o.m_params ); } [[nodiscard]] const std::string & path() const noexcept { return m_path; } [[nodiscard]] image_format_t format() const noexcept { return m_format; } [[nodiscard]] resize_params_t params() const noexcept { return m_params; } };
I.e. solicitação de redimensionamento example.jpg até 1920px com conversão para png difere do mesmo redimensionamento, mas com conversão para webp ou heic.
Mas o foco principal está oculto
na nova implementação da classe resize_params_t , que determina os novos tamanhos da imagem em escala.
Anteriormente, essa classe suportava três opções: apenas a largura era definida, apenas a altura era definida ou o lado longo era definido (a altura ou a largura é determinada pelo tamanho da imagem atual). Assim, o
método resize_params_t :: value () sempre retornava algum valor real (que valor foi determinado pelo
método resize_params_t :: mode () ).
Mas no novo camarão, outro modo foi adicionado - keep_original, o que significa que a escala não é executada e a imagem é renderizada em seu tamanho original. Para suportar esse modo, o resize_params_t precisou fazer algumas alterações. Primeiro, agora o
método resize_params_t :: make () determina se o modo keep_original é usado (considera-se que esse modo é usado se nenhum dos parâmetros width, height e max na cadeia de consulta da solicitação de entrada for especificado). Isso nos permitiu não reescrever a função
handle_resize_op_request () , que empurra a solicitação de dimensionamento da imagem a ser executada.
Em segundo lugar, o
método resize_params_t :: value () agora pode ser chamado nem sempre, mas apenas quando o modo de dimensionamento difere de keep_original.
Mas o mais importante é que
resize_params_t :: operator <() continuou a funcionar como pretendido.
Graças a todas essas alterações no a_transform_manager, o cache de imagem em escala e a fila de solicitações em espera permaneceram os mesmos. Mas agora, informações sobre várias consultas são armazenadas nessas estruturas de dados. Portanto, a chave {"example.jpg", "jpg", keep_original} será diferente da chave {"example.jpg", "png", keep_original} e da chave {"example.jpg", "jpg", width = 1920 px}.
Aconteceu que, com a definição de estruturas de dados simples como resize_params_t e resize_params_key_t, evitamos alterar estruturas mais complexas, como o cache das imagens resultantes e a fila de solicitações em espera.
Suporte para formato de destino no a_transformer
Bem, a etapa final no suporte ao formato de destino é expandir a lógica do agente a_transformer para que a imagem, possivelmente já em escala, seja convertida no formato de destino.
Acabou sendo o mais fácil de fazer isso,
bastava expandir o código do
método a_transform_t :: handle_resize_request () :
[[nodiscard]] a_transform_manager_t::resize_result_t::result_t a_transformer_t::handle_resize_request( const transform::resize_request_key_t & key ) { try { m_logger->trace( "transformation started; request_key={}", key ); auto image = load_image( key.path() ); const auto resize_duration = measure_duration( [&]{ // // keep_original. if( transform::resize_params_t::mode_t::keep_original != key.params().mode() ) { transform::resize( key.params(), total_pixel_count, image ); } } ); m_logger->debug( "resize finished; request_key={}, time={}ms", key, std::chrono::duration_cast<std::chrono::milliseconds>( resize_duration).count() ); image.magick( magick_from_image_format( key.format() ) ); datasizable_blob_shared_ptr_t blob; const auto serialize_duration = measure_duration( [&] { blob = make_blob( image ); } ); m_logger->debug( "serialization finished; request_key={}, time={}ms", key, std::chrono::duration_cast<std::chrono::milliseconds>( serialize_duration).count() ); return a_transform_manager_t::successful_resize_t{ std::move(blob), std::chrono::duration_cast<std::chrono::microseconds>( resize_duration), std::chrono::duration_cast<std::chrono::microseconds>( serialize_duration) }; } catch( const std::exception & x ) { return a_transform_manager_t::failed_resize_t{ x.what() }; } }
Comparado
com a versão anterior, existem duas adições fundamentais.
Primeiro, chamando o método verdadeiramente mágico image.magick () após o redimensionamento. Este método informa ao ImageMagick o formato da imagem resultante. Ao mesmo tempo, a representação da imagem na memória não muda - o ImageMagick continua a armazená-lo da maneira que mais lhe convém. Mas o valor definido pelo método magick () será levado em consideração durante a chamada subsequente para Image :: write ().
Em segundo lugar, a versão atualizada registra o tempo necessário para serializar a imagem no formato especificado. A nova versão do Shrimp agora corrige separadamente o tempo gasto no dimensionamento e o tempo gasto na conversão para o formato de destino.
O restante do agente a_transformer_t não sofreu nenhuma alteração.
Paralelização ImageMagick
Por padrão, o ImageMagic é construído com suporte ao OpenMP. I.e. é possível paralelizar operações nas imagens que o ImageMagick executa. Você pode controlar o número de fluxos de trabalho que o ImageMagick usa nesse caso, usando a variável de ambiente MAGICK_THREAD_LIMIT.
Por exemplo, na minha máquina de teste com o valor MAGICK_THREAD_LIMIT = 1 (ou seja, sem paralelização real), obtenho os seguintes resultados:
curl "http://localhost:8080/DSC08084.jpg?op=resize&max=2400" -v > /dev/null > GET /DSC08084.jpg?op=resize&max=2400 HTTP/1.1 > Host: localhost:8080 > User-Agent: curl/7.47.0 > Accept: */* > < HTTP/1.1 200 OK < Connection: keep-alive < Content-Length: 2043917 < Server: Shrimp draft server < Date: Wed, 15 Aug 2018 11:51:24 GMT < Last-Modified: Wed, 15 Aug 2018 11:51:24 GMT < Access-Control-Allow-Origin: * < Access-Control-Expose-Headers: Shrimp-Processing-Time, Shrimp-Resize-Time, Shrimp-Encoding-Time, Shrimp-Image-Src < Content-Type: image/jpeg < Shrimp-Image-Src: transform < Shrimp-Processing-Time: 1323 < Shrimp-Resize-Time: 1086.72 < Shrimp-Encoding-Time: 236.276
O tempo gasto no redimensionamento é indicado no cabeçalho Shrimp-Resize-Time. Nesse caso, são 1086.72ms.
Mas se você definir MAGICK_THREAD_LIMIT = 3 na mesma máquina e executar o Shrimp, obteremos valores diferentes:
curl "http://localhost:8080/DSC08084.jpg?op=resize&max=2400" -v > /dev/null > GET /DSC08084.jpg?op=resize&max=2400 HTTP/1.1 > Host: localhost:8080 > User-Agent: curl/7.47.0 > Accept: */* > < HTTP/1.1 200 OK < Connection: keep-alive < Content-Length: 2043917 < Server: Shrimp draft server < Date: Wed, 15 Aug 2018 11:53:49 GMT < Last-Modified: Wed, 15 Aug 2018 11:53:49 GMT < Access-Control-Allow-Origin: * < Access-Control-Expose-Headers: Shrimp-Processing-Time, Shrimp-Resize-Time, Shrimp-Encoding-Time, Shrimp-Image-Src < Content-Type: image/jpeg < Shrimp-Image-Src: transform < Shrimp-Processing-Time: 779.901 < Shrimp-Resize-Time: 558.246 < Shrimp-Encoding-Time: 221.655
I.e. o tempo de redimensionamento foi reduzido para 558,25 ms.
Consequentemente, como o ImageMagick oferece a capacidade de paralelizar cálculos, você pode usar esta oportunidade. Mas, ao mesmo tempo, é desejável poder controlar quantos threads de trabalho o Shrimp leva para si. Nas versões anteriores do Shrimp, não era possível influenciar quantos fluxos de trabalho o Shrimp cria. E na versão atualizada do Shrimp, isso pode ser feito. Ou através de variáveis de ambiente, por exemplo:
SHRIMP_IO_THREADS=1 \ SHRIMP_WORKER_THREADS=3 \ MAGICK_THREAD_LIMIT=4 \ shrimp.app -p 8080 -i ...
Ou através de argumentos de linha de comando, por exemplo:
MAGICK_THREAD_LIMIT=4 \ shrimp.app -p 8080 -i ... --io-threads 1 --worker-threads 4
Os valores especificados na linha de comando têm uma prioridade mais alta.
Deve-se enfatizar que MAGICK_THREAD_LIMIT afeta apenas as operações que o ImageMagick executa por si só. Por exemplo, o redimensionamento é feito pelo ImageMagick. Mas a conversão de um formato para outro ImageMagick delega para bibliotecas externas. E como as operações nessas bibliotecas externas são paralelizadas é uma questão separada que não entendemos.
Conclusão
Talvez, nesta versão do Shrimp, tenhamos trazido nosso projeto de demonstração para um estado aceitável. Quem quiser ver e experimentar pode encontrar os textos de origem do Shrimp no
BitBucket ou no
GitHub . Você também pode encontrar o Dockerfile lá para criar camarão para suas experiências.
Em geral, alcançamos nossos objetivos que estabelecemos ao iniciar este projeto de demonstração. Surgiram várias idéias para o desenvolvimento futuro do RESTinio e do SObjectizer, e algumas delas já encontraram sua forma de realização. Portanto, se o camarão se desenvolverá em algum lugar ainda mais completamente depende de perguntas e desejos. Se houver, o camarão pode se expandir. Caso contrário, o Shrimp continuará sendo um projeto de demonstração e um campo de treinamento para experimentar novas versões do RESTinio e SObjectizer.
Concluindo, gostaria de expressar um agradecimento especial à
aensidhe por sua ajuda e conselhos, sem os quais nossas danças com um pandeiro seriam muito mais longas e tristes.