
Começamos a atualizar o monitoramento do PgBouncer em nosso serviço e decidimos pentear tudo um pouco. Para ajustar tudo, reunimos as mais famosas metodologias de monitoramento de desempenho: USE (Utilização, Saturação, Erros), de Brendan Gregg, e RED (Solicitações, Erros, Durações), de Tom Wilkie.
Sob a cena, há uma história com gráficos sobre como o pgbouncer funciona, qual configuração lida com ele e como usar USE / RED para escolher as métricas corretas para monitorá-lo.
Primeiro sobre os próprios métodos
Embora esses métodos sejam bastante conhecidos (sobre eles, ele já estava em Habré, embora não em grandes detalhes ), não é que eles sejam difundidos na prática.
UTILIZAÇÃO
Para cada recurso, acompanhe o descarte, a saturação e os erros.
Brendan gregg
Aqui, um recurso é qualquer componente físico separado - uma CPU, disco, barramento, etc. Mas não apenas - o desempenho de alguns recursos de software também pode ser considerado por esse método, em particular recursos virtuais, como containers / cgroups com limites, também é conveniente considerar isso.
U - Descarte : uma porcentagem do tempo (a partir do intervalo de observação) em que o recurso estava ocupado com um trabalho útil. Como, por exemplo, carregar 90% da CPU ou da utilização do disco significa que 90% do tempo foi gasto por algo útil) ou, para recursos como memória, essa é a porcentagem de memória usada.
De qualquer forma, 100% de reciclagem significa que o recurso não pode ser usado mais do que agora. E o trabalho ficará parado aguardando liberação / vá para a fila ou haverá erros. Esses dois cenários são cobertos pelas duas métricas restantes de USE correspondentes:
S - Saturação , também é saturação: uma medida da quantidade de trabalho "adiado" / em fila.
E - Erros : contamos simplesmente o número de falhas. Erros / falhas afetam o desempenho, mas podem não ser percebidos imediatamente devido à recuperação de operações invertidas ou mecanismos de tolerância a falhas com dispositivos de backup, etc.
Vermelho
Tom Wilkie (agora trabalhando na Grafana Labs) ficou frustrado com a metodologia USE, ou melhor, com sua baixa aplicabilidade em alguns casos e inconsistência com a prática. Como, por exemplo, medir a saturação da memória? Ou como medir erros de barramento do sistema na prática?
Acontece que o Linux realmente relata contagens de bugs.
T. Wilkie
Em resumo, para monitorar o desempenho e o comportamento dos microsserviços, ele propôs outro método adequado: medir novamente três indicadores:
Taxa R : O número de solicitações por segundo.
E - Erros : quantas solicitações retornaram um erro.
D - Duração : tempo necessário para processar a solicitação. É latência, "latência" (© Sveta Smirnova :), tempo de resposta, etc.
Em geral, USE é mais adequado para monitorar recursos e RED para serviços e sua carga de trabalho / carga útil.
Pgbouncer
Sendo um serviço, ao mesmo tempo, possui todos os tipos de limites e recursos internos. O mesmo pode ser dito sobre o Postgres, que os clientes acessam através deste PgBouncer. Portanto, para o monitoramento completo nessa situação, os dois métodos são necessários.
Para entender como aplicar esses métodos a um segurança, você precisa entender os detalhes de seu dispositivo. Não basta monitorá-lo como uma caixa preta - "o processo do pgbouncer está ativo" ou "a porta está aberta", porque em caso de problemas, isso não dará uma compreensão do que exatamente e como ele quebrou e o que fazer.
O que geralmente tem a aparência do PgBouncer do ponto de vista do cliente:
- cliente se conecta
- [o cliente faz uma solicitação - recebe uma resposta] x quantas vezes ele precisa
Aqui, desenhei um diagrama dos estados correspondentes do cliente do ponto de vista do PgBoucer:

No processo de login, a autorização pode ocorrer localmente (arquivos, certificados e até PAM e hba de novas versões) e remotamente - ou seja, no próprio banco de dados ao qual a conexão está sendo tentada. Assim, o estado de logon possui um subestado adicional. Vamos chamá-lo de Executing para indicar que o auth_query está auth_query no banco de dados no momento:
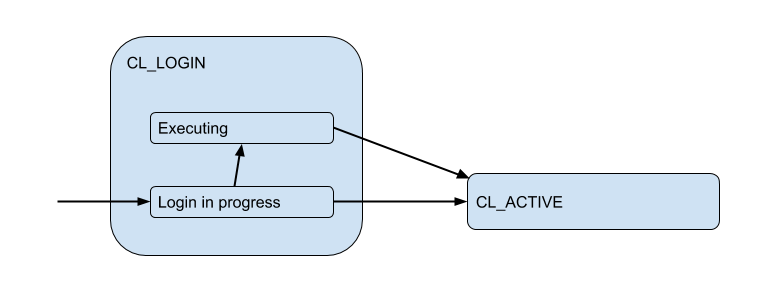
Mas essas conexões do cliente realmente correspondem às conexões de back-end / upstream que o PgBouncer abre no pool e mantém um número limitado. E eles fornecem essa conexão ao cliente apenas durante o tempo - pela duração da sessão, transação ou solicitação, dependendo do tipo de pool (determinado pela configuração pool_mode ). Na maioria das vezes, o pool de transações é usado (discutiremos isso mais tarde) - quando a conexão é emitida para o cliente por uma transação e o resto do tempo o cliente não está conectado ao servidor. Assim, o estado "ativo" do cliente nos diz pouco e vamos dividi-lo em substratos:
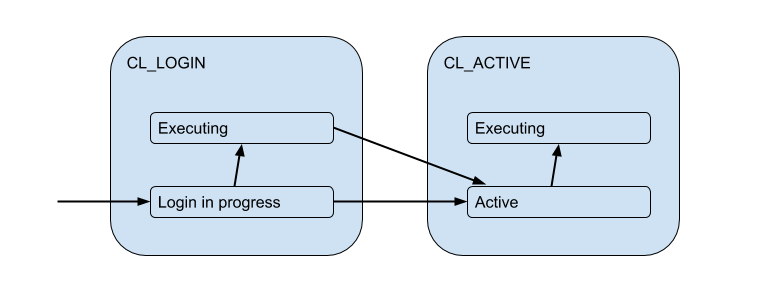
Cada um desses clientes cai em seu próprio conjunto de conexões, que será emitido para uso pela conexão real com o Postgres. Esta é a principal tarefa do PgBouncer - limitar o número de conexões com o Postgres.
Devido às conexões limitadas do servidor, pode surgir uma situação em que o cliente precisa atender diretamente à solicitação, mas não há conexão gratuita agora. Em seguida, o cliente é colocado na fila e sua conexão entra no estado CL_WAITING . Assim, o diagrama de estados deve ser complementado:
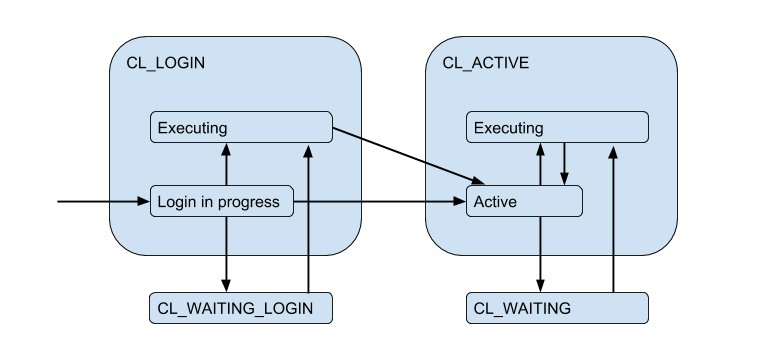
Como isso pode acontecer no caso em que o cliente efetua login apenas e ele precisa executar uma solicitação de autorização, o estado CL_WAITING_LOGIN também CL_WAITING_LOGIN .
Se você agora olha do lado oposto - do lado das conexões do servidor, eles estão em tais estados: quando a autorização ocorre imediatamente após a conexão - SV_LOGIN , emitida e (possivelmente) usada pelo cliente - SV_ACTIVE ou livremente - SV_IDLE .
USE para PgBouncer
Assim, chegamos à utilização (versão ingênua) de um pool específico:
Pool utiliz = /
O PgBouncer possui um banco de dados especial do utilitário pgbouncer, no qual existe um SHOW POOLS que exibe o status atual das conexões de cada pool:

Existem 4 conexões de clientes abertas e todas elas são cl_active . Das 5 conexões do servidor - 4 sv_active e uma no novo estado sv_used .
O que é sv_used realmente sobre as diferentes configurações do pgbouncer não relacionadas ao monitoramentoPortanto, sv_used não significa “a conexão está sendo usada”, como você pode pensar, mas “a conexão foi usada uma vez e não foi usada por um longo tempo”. O fato é que o PgBouncer usa as conexões do servidor no modo LIFO por padrão - ou seja, Primeiro, são usadas as conexões recém-lançadas, depois as usadas recentemente, etc. gradualmente se movendo para compostos usados há muito tempo. Conseqüentemente, as conexões do servidor na parte inferior de uma pilha dessas podem “ficar ruins”. E eles devem ser verificados quanto à disponibilidade antes do uso, o que é feito usando server_check_query , enquanto estão sendo verificados, o estado será sv_tested .
A documentação diz que o LIFO está ativado por padrão, como então "um pequeno número de conexões obtém a maior carga de trabalho. E isso oferece o melhor desempenho quando há um servidor que serve o banco de dados por trás do pgbouncer", ou seja, como se fosse o caso mais típico. Acredito que o aumento potencial de desempenho se deve às economias na troca de desempenho entre vários processos de back-end. Mas não deu certo, porque Esse detalhe de implementação existe há> 12 anos e vai além do histórico de confirmação no github e da profundidade do meu interesse =)
Portanto, parecia estranho e server_check_delay com as realidades atuais que o valor padrão da configuração server_check_delay , que determina que o servidor não foi usado por muito tempo e deve ser verificado antes de ser entregue ao cliente, é de 30 segundos. Isso apesar do fato de, por padrão, tcp_keepalive ser ativado simultaneamente com as configurações padrão - comece a verificar a conexão keep alive com amostras 2 horas após sua inatividade.
Acontece que, em uma situação de intermitência / surto de conexões de clientes que desejam fazer algo no servidor, um atraso adicional é introduzido no server_check_query , que, embora " SELECT 1; ainda pode levar ~ 100 microssegundos, e se server_check_query = ';' então você pode salvar ~ 30 microssegundos =)
Mas a suposição de que trabalhar em apenas algumas conexões = em vários processos "principais" de back-end do postgres será mais eficiente, parece-me duvidoso. O processo do operador do postgres armazena em cache (meta) informações sobre cada tabela que foi acessada nesta conexão. Se você tiver um grande número de tabelas, esse relcache poderá crescer muito e consumir muita memória, até a troca das páginas do processo 0_o. Para contornar isso, use a configuração server_lifetime (o padrão é 1 hora), pela qual a conexão do servidor será fechada para rotação. Mas, por outro lado, há uma configuração server_round_robin que alternará o modo de usar conexões de LIFO para FIFO, espalhando solicitações de clientes em conexões de servidor de maneira mais uniforme.
SHOW POOLS tomar SHOW POOLS métricas de SHOW POOLS (por algum exportador de prometheus), podemos traçar estes estados:
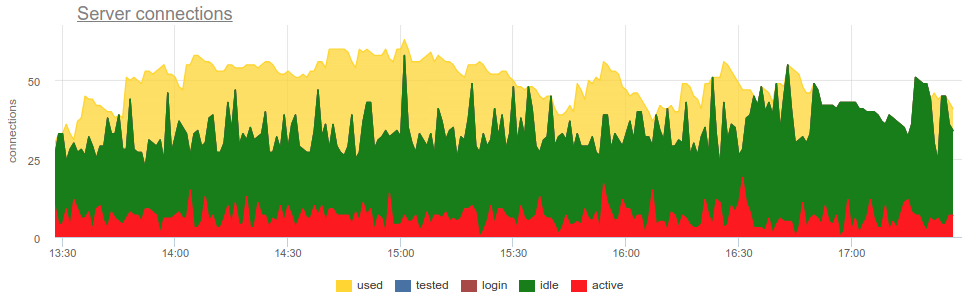
Mas para chegar ao descarte, você precisa responder a algumas perguntas:
- Qual é o tamanho da piscina?
- Como contar quantos compostos são usados? Em piadas ou no tempo, em média ou no pico?
Tamanho da piscina
Tudo é complicado aqui, como na vida. No total, já existem cinco limites de configurações no pbbouncer!
pool_size pode ser definido para cada banco de dados. Um pool separado é criado para cada par DB / usuário, ou seja, de qualquer usuário adicional , você pode criar outros trabalhadores de pool_size backends / Postgres. Porque se pool_size não pool_size definido, ele cai em default_pool_size , cujo padrão é 20, então cada usuário que tem o direito de se conectar ao banco de dados (e trabalha através do pgbouncer) pode criar potencialmente 20 processos do Postgres, o que parece não ser muito. Mas se você tiver muitos usuários diferentes dos bancos de dados ou dos próprios bancos de dados, e os conjuntos não forem registrados com um usuário fixo, ou seja, será criado em tempo real (e excluído por autodb_idle_timeout ), isso pode ser perigoso =)
Pode valer a pena deixar default_pool_size pequeno, apenas para todos os bombeiros.
max_db_connections - apenas necessário para limitar o número total de conexões com um banco de dados, porque caso contrário, os clientes que se comportam mal podem criar muitos processos de back-end / postgres. E por padrão aqui - ilimitado ¯_ (ツ) _ / ¯
Talvez você deva alterar as max_db_connections padrão, por exemplo, você pode se concentrar nas max_connections seu Postgres (por padrão 100). Mas se você tem muitos PgBouncers ...
reserve_pool_size - na verdade, se pool_size usado, o PgBouncer poderá abrir várias outras conexões com a base. Pelo que entendi, isso é feito para lidar com um aumento na carga. Voltaremos a isso.max_user_connections - pelo contrário, é o limite de conexões de um usuário para todos os bancos de dados, ou seja, relevante se você tiver vários bancos de dados e eles estiverem sob os mesmos usuários.max_client_conn - quantas conexões de cliente o PgBouncer aceitará no total. O padrão, como sempre, tem um significado muito estranho - 100. Ou seja, presume-se que, se mais de 100 clientes travarem repentinamente, eles precisarão reset silenciosamente no nível TCP e reset (bem, nos logs, devo admitir, isso será "sem mais conexões permitidas (max_client_conn)").
Pode valer a pena fazer max_client_conn >> SUM ( pool_size' ) , por exemplo, 10 vezes mais.
Além de SHOW POOLS serviço pseudo-base pgbouncer também fornece o SHOW DATABASES , que mostra os limites realmente aplicados a um pool específico:

Conexões do servidor
Mais uma vez - como medir quantos compostos são usados?
Em piadas, em média / no pico / no tempo?
Na prática, é bastante problemático monitorar o uso de piscinas pelo segurança com ferramentas difundidas, como O próprio pgbouncer fornece apenas uma imagem momentânea e, como muitas vezes não fazem uma pesquisa, ainda existe a possibilidade de uma imagem errada devido à amostragem. Aqui está um exemplo real de quando, dependendo de quando o exportador trabalhou - no começo do minuto ou no final - a imagem dos compostos abertos e usados muda fundamentalmente:
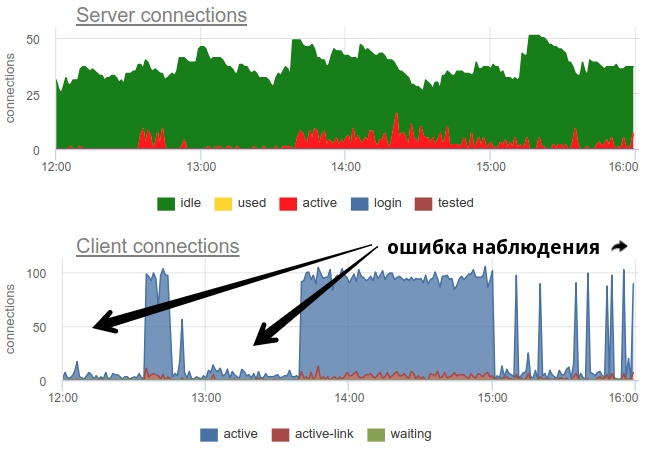
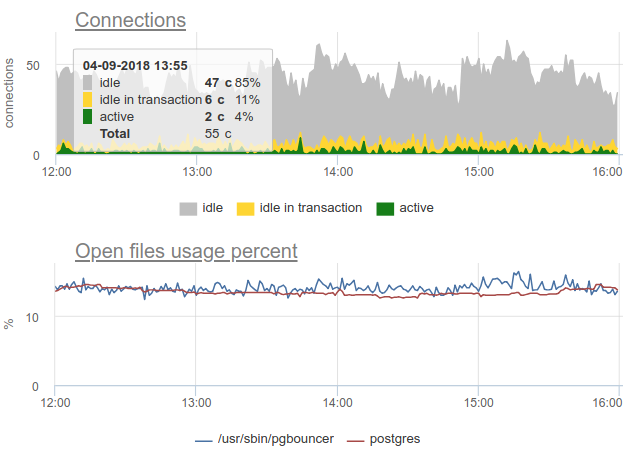
Aqui todas as mudanças no carregamento / uso das conexões são apenas uma ficção, um artefato das reinicializações do coletor de estatísticas. Aqui você pode ver os gráficos de conexão no Postgres durante esse período e os descritores de arquivos do segurança e do PG - sem alterações:
Voltar para a questão do descarte. Decidimos usar uma abordagem combinada em nosso serviço - mostramos SHOW POOLS uma vez por segundo e, a cada minuto, renderizamos o número médio e máximo de conexões em cada classe:
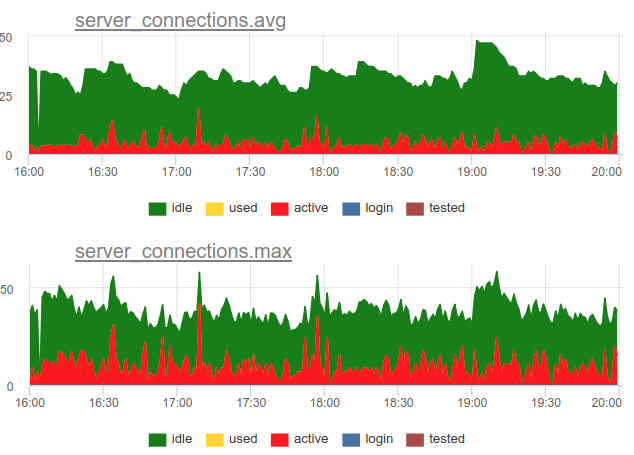
E se dividirmos o número dessas conexões de estado ativo pelo tamanho do pool, obteremos a média e o pico de utilização desse pool e podemos alertar se ele está próximo de 100%.
Além disso, o PgBouncer possui um comando SHOW STATS que mostrará estatísticas de uso para cada banco de dados em proxy:

Estamos mais interessados na coluna total_query_time - o tempo gasto por todas as conexões no processo de execução de consultas no postgres. E a partir da versão 1.8, há também a métrica total_xact_time - o tempo gasto nas transações. Com base nessas métricas, podemos construir a utilização do tempo de conexão do servidor; esse indicador não está sujeito, ao contrário do calculado a partir dos estados da conexão, a problemas de amostragem, porque estes contadores de total_..._time são cumulativos e não passam nada:

Compare
Pode-se observar que a amostragem não mostra todos os momentos de alta utilização de ~ 100%, e o query_time mostra.
Saturação e PgBouncer
Por que você precisa monitorar a saturação, devido à alta utilização, já está claro que tudo está ruim?
O problema é que, independentemente de como você mede a utilização, mesmo os contadores acumulados não podem mostrar a utilização local de 100% dos recursos, se ocorrer apenas em intervalos muito curtos. Por exemplo, você tem coroas ou outros processos síncronos que podem começar simultaneamente a fazer consultas ao banco de dados no comando. Se essas solicitações forem curtas, a utilização, medida na escala de minutos e até segundos, poderá ser baixa, mas, ao mesmo tempo, em algum momento, essas solicitações foram forçadas a aguardar na fila pela execução. Isso é semelhante a uma situação de não uso da CPU de 100% e alta carga média - como o tempo do processador ainda está lá, mas, no entanto, muitos processos estão aguardando na fila pela execução.
Como essa situação pode ser monitorada - bem, novamente, podemos simplesmente contar o número de clientes no estado cl_waiting acordo com SHOW POOLS . Em uma situação normal, há zero e mais de zero significa excesso desse pool:
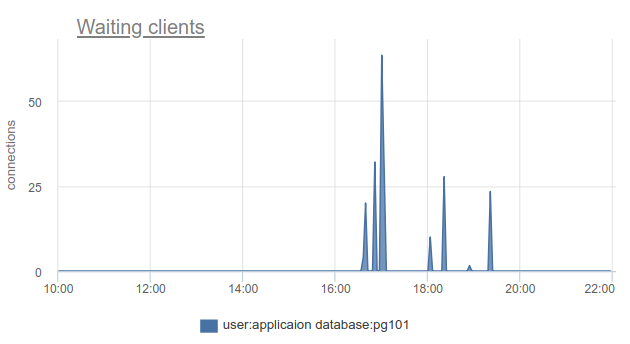
Resta o problema de que o SHOW POOLS só pode ser amostrado e, em uma situação com coroas síncronas ou algo parecido, podemos simplesmente pular e não ver esses clientes em espera.
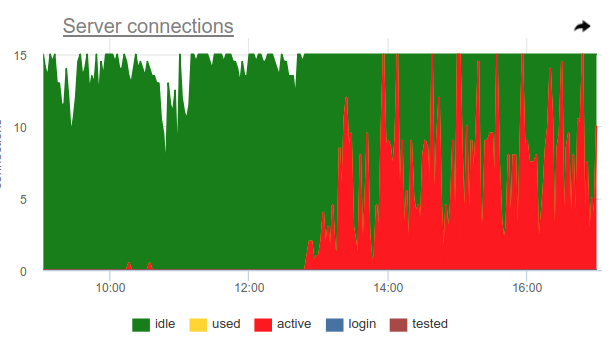
Você pode usar esse truque, o próprio pgbouncer pode detectar 100% de uso do pool e abrir o pool de backup. Duas configurações são responsáveis por isso: reserve_pool_size - por seu tamanho, como eu disse, e reserve_pool_timeout - quantos segundos um cliente deve waiting antes de usar o pool de backup. Portanto, se vemos no gráfico de conexões do servidor que o número de conexões abertas ao Postgres é maior que pool_size, houve uma saturação do pool, assim:

Obviamente, algo como coroas uma vez por hora faz muitos pedidos e ocupa completamente a piscina. E mesmo que não vejamos o momento em que active conexões active excedam o limite pool_size , o pgbouncer ainda foi forçado a abrir conexões adicionais.
Também neste gráfico, as configurações server_idle_timeout funcionam é claramente visível - depois de quanto parar de manter e fechar as conexões que não são usadas. Por padrão, são 10 minutos, o que vemos no gráfico - após os picos active exatamente às 5:00, às 6:00, etc. (de acordo com cron 0 * * * * ), as conexões ficam idle + used mais 10 minutos e fecham.
Se você mora na vanguarda do progresso e atualizou o PgBouncer nos últimos 9 meses, pode encontrar na coluna SHOW STATS total_wait_time , que melhor mostra a saturação, porque cumulativamente considera o tempo gasto pelos clientes em um estado de waiting . Por exemplo, o waiting aqui - em waiting apareceu às 16:30:
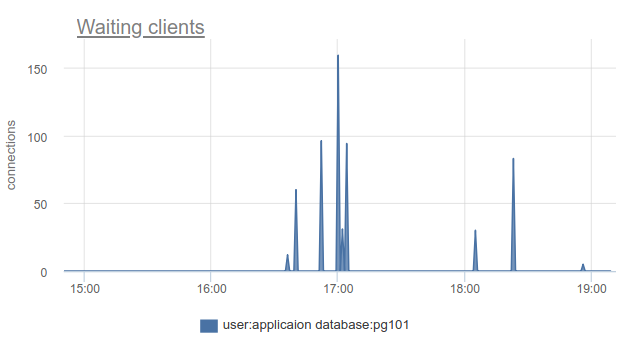
E wait_time , que é comparável e afeta claramente o average query time , pode ser visto das 15:15 às quase 19:

No entanto, o monitoramento do status das conexões do cliente ainda é muito útil, porque ele permite descobrir não apenas o fato de que todas as conexões com esse banco de dados foram gastas e os clientes precisam esperar, mas também porque o SHOW POOLS dividido em pools separados pelos usuários, e o SHOW STATS não, permite descobrir quais clientes usaram todas as conexões para a base especificada - de acordo com a coluna sv_active do pool correspondente. Ou por métrica
sum_by(user, database, metric(name="pgbouncer.clients.count", state="active-link")):
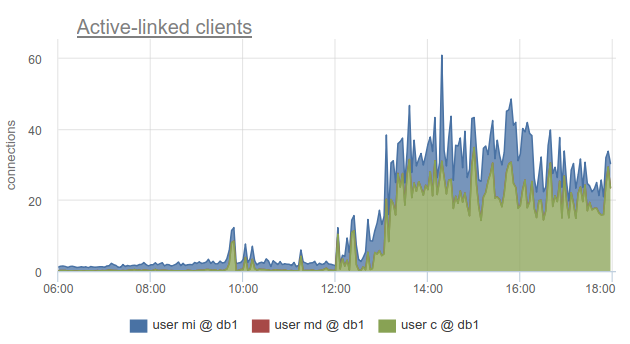
No okmeter, fomos ainda mais longe e adicionamos um detalhamento das conexões usadas pelos endereços IP dos clientes que os abriram e usaram. Isso permite que você entenda exatamente quais instâncias de aplicativos se comportam de maneira diferente:

Aqui vemos IPs de kubernetes específicos de lares com os quais precisamos lidar.
Erros
Não há nada de particularmente complicado aqui: o pgbouncer grava logs nos quais relata erros se o limite de conexões do cliente for atingido, o tempo limite para se conectar ao servidor, etc. Ainda não alcançamos os registros do pgbouncer :(
RED para PgBouncer
Enquanto o USE está mais focado no desempenho, no sentido de gargalos, o RED, na minha opinião, é mais sobre as características do tráfego de entrada e saída em geral, e não sobre gargalos. Ou seja, o RED responde à pergunta - tudo funciona bem e, se não, o USE ajudará a entender qual é o problema.
Exigências
Parece que tudo é bastante simples para o banco de dados SQL e para o extrator de proxy / conexão nesse banco de dados - os clientes executam instruções SQL, que são Solicitações. Em SHOW STATS pegamos total_requests e total_requests sua derivada de tempo
rate(metric(name="pgbouncer.total_requests", database: "*"))

Mas, de fato, existem diferentes modos de puxar, e o mais comum são as transações. A unidade de trabalho para este modo é uma transação, não uma consulta. Assim, a partir da versão 1.8, o Pgbouner já fornece duas outras estatísticas - total_query_count , em vez de total_requests e total_xact_count - o número de transações concluídas.
Agora, a carga de trabalho pode ser caracterizada não apenas em termos do número de solicitações / transações concluídas, mas, por exemplo, você pode observar o número médio de solicitações por transação em diferentes bancos de dados, dividindo-se em outro
rate(metric(name="total_requests", database="*")) / rate(metric(name="total_xact", database="*"))

Aqui vemos mudanças óbvias no perfil de carga, que podem ser o motivo da alteração no desempenho. E se você analisou apenas a taxa de transações ou solicitações, talvez não veja isso.
Erros RED
É claro que RED e USE se cruzam no monitoramento de erros, mas parece-me que os erros no USE são principalmente sobre erros de processamento de solicitação devido à utilização de 100%, ou seja, quando o serviço se recusar a aceitar mais trabalho. E os erros do RED seriam melhores para medir erros precisamente do ponto de vista do cliente, solicitações do cliente. Ou seja, não apenas em uma situação em que o pool no PgBouncer está cheio ou outro limite funcionou, mas também quando solicitações de tempo limite, como "cancelamento de declaração devido ao tempo limite da declaração", cancelamentos e reversões de transações pelo cliente funcionaram, etc. e nível superior, mais próximo dos tipos de erros da lógica de negócios.
Durações
Aqui, novamente, SHOW STATS com contadores cumulativos total_xact_time , total_query_time e total_wait_time nos ajudarão, dividindo-os pelo número de solicitações e transações, respectivamente, obtemos o tempo médio de solicitação, tempo médio de transação e tempo médio de espera por transação. Eu já mostrei um gráfico sobre o primeiro e o terceiro:
O que mais você pode esfriar? O antipadrão conhecido no trabalho com o banco de dados e o Postgres, em particular, quando o aplicativo abre uma transação, faz uma solicitação e depois começa (por um longo tempo) a processar seus resultados, ou pior ainda - vai para outro serviço / banco de dados e faz solicitações lá. Todo esse tempo, a transação "trava" no postgres aberto, o serviço retorna e faz mais algumas solicitações, atualizações no banco de dados e somente depois fecha a transação. Para o postgres, isso é especialmente desagradável, porque pg trabalhadores são caros. Portanto, podemos monitorar quando esse aplicativo está idle in transaction no próprio postgres - de acordo com a coluna state em pg_stat_activity , mas ainda existem os mesmos problemas descritos com a amostragem, porque pg_stat_activity fornece apenas a imagem atual. No PgBouncer, podemos subtrair o tempo gasto pelos clientes nas solicitações total_query_time do tempo gasto nas transações total_xact_time - este será o tempo dessa inatividade. Se o resultado ainda estiver dividido por total_xact_time , ele será normalizado: um valor 1 corresponde a uma situação em que os clientes estão idle in transaction 100% do tempo. E com essa normalização, fica fácil entender como tudo é ruim:
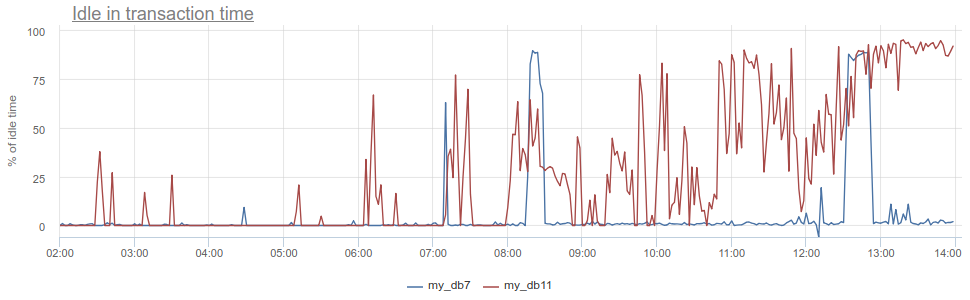
Além disso, retornando à Duração, a métrica total_xact_time - total_query_time pode ser dividida pelo número de transações para ver quanto é o aplicativo inativo médio por transação.
Na minha opinião, os métodos USE / RED são mais úteis para estruturar quais métricas você dispara e por quê. Como estamos envolvidos no monitoramento em tempo integral e precisamos monitorar vários componentes da infraestrutura, esses métodos nos ajudam a obter as métricas corretas, fazer os cronogramas e acionadores certos para nossos clientes.
Um bom monitoramento não pode ser feito imediatamente, é um processo iterativo. No okmeter.io , temos apenas o monitoramento contínuo (há muitas coisas, mas amanhã será melhor e mais detalhado :)