
Meu nome é Yuri Nevinitsin e estou envolvido no sistema de estatísticas internas em OK. Quero falar sobre como transferimos um sistema analítico de 50 terabytes em tempo real, no qual bilhões de eventos são registrados diariamente, do Microsoft SQL para uma base de colunas chamada Druid. E ao mesmo tempo, você aprenderá algumas receitas para usar o
Druid .
Por que precisamos de estatísticas?
Queremos saber tudo sobre o nosso site, para registrar não apenas o comportamento de discos, processadores, etc., mas também toda ação do usuário, toda interação entre subsistemas e todos os processos internos de quase todos os nossos sistemas. O sistema estatístico está intimamente integrado ao processo de desenvolvimento.
Com base nos dados do sistema estatístico, nossos gerentes estabelecem metas para as equipes, acompanham seus resultados e indicadores-chave. Administradores e desenvolvedores monitoram a operação de todos os sistemas, investigam incidentes e anomalias. O monitoramento automático monitora constantemente e, em um estágio inicial, identifica problemas, faz previsões de limites excedentes. Além disso, recursos e experimentos são constantemente lançados, atualizações e alterações são feitas. E monitoramos o efeito de todas essas ações através do sistema de estatísticas. Se ela recusar, não poderemos fazer alterações no site.
Nossas estatísticas são apresentadas principalmente na forma de gráficos. Normalmente, o gráfico é exibido vários dias ao mesmo tempo, para que a dinâmica seja clara. Aqui está um exemplo de minhas experiências com o Druid. Aqui está um gráfico do carregamento de dados (linhas / 5 min).
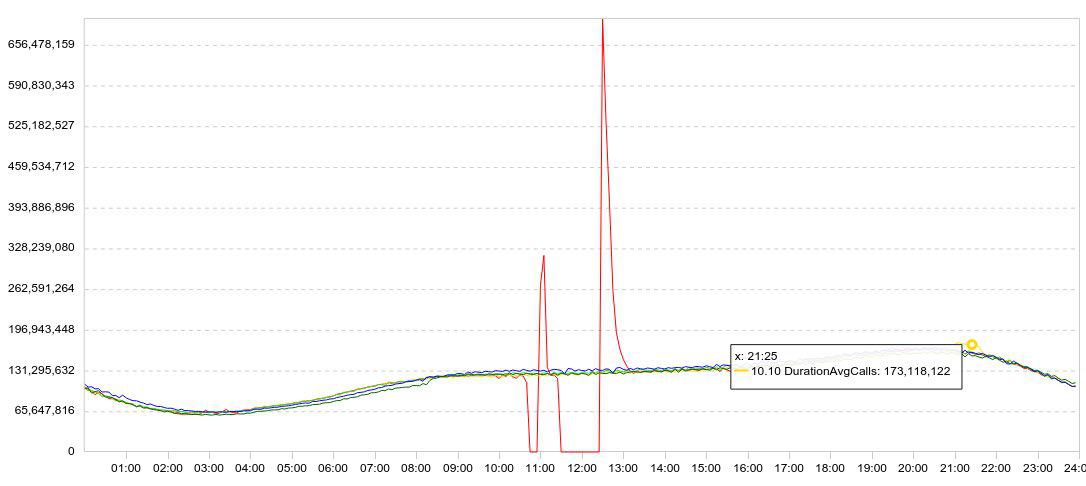
Reduzi a velocidade do download (o gráfico vermelho cai para zero), esperei um pouco, reiniciei o download e observei a rapidez com que o Druid podia carregar os dados acumulados (picos após falhas).
Qualquer programação pode ser expandida por qualquer parâmetro, por exemplo, por host, tabela, operação, etc. Também temos gráficos de longo prazo com dinâmica anual. Por exemplo, abaixo está um gráfico do aumento diário no número de entradas no Druid.
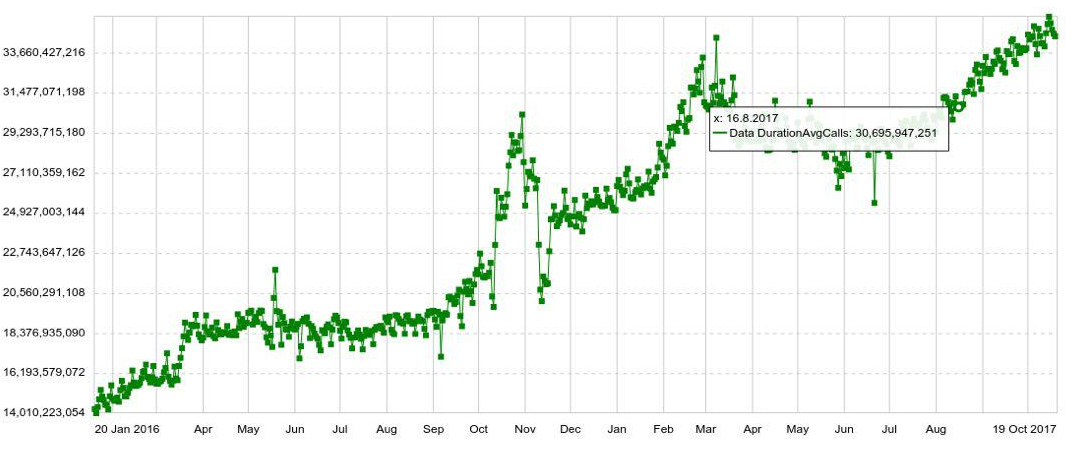
Também podemos combinar vários gráficos em painéis separados (painéis), o que acabou sendo muito conveniente. E mesmo que o usuário precise ver apenas algumas centenas de gráficos, ele ainda os abre não individualmente, mas no painel, o que aumenta a carga no sistema.
O problema
Enquanto o volume de dados era pequeno, lidamos muito bem com o SQL. Mas à medida que o volume de dados aumentou, a produção de gráficos diminuiu. E, no final, as estatísticas na hora do rush começaram a diminuir em meia hora, e o tempo médio de resposta de um gráfico chegou a 6 segundos. Ou seja, alguém recebeu a programação em 2 segundos, alguém em 10-20 e alguém em um minuto. (Você pode ler sobre o desenvolvimento do sistema em SQL
aqui )
Quando você investiga uma anomalia ou incidente, geralmente é necessário abrir e ver uma dúzia de gráficos, cada um dos quais segue o anterior, eles não podem ser abertos ao mesmo tempo. Eu tive que esperar 10 vezes por 10-20 segundos. Foi muito chato.
A migração
Você ainda pode extrair algo do sistema, adicionar servidores ... Mas, ao mesmo tempo, a Microsoft mudou sua política de licenciamento. Se continuássemos usando o SQL Server, teríamos que doar milhões de dólares. Portanto, eles decidiram migrar.
Os requisitos foram os seguintes:
- As estatísticas não devem demorar (mais de 2 minutos).
- O gráfico deve abrir em não mais de 2 segundos.
- O painel inteiro deve abrir em não mais que 10 segundos.
- O sistema deve ser tolerante a falhas, capaz de sobreviver à perda de um data center.
- O sistema deve ser facilmente escalável.
- O sistema deve ser fácil de modificar, por isso, queríamos que fosse em Java.
Tudo isso nos foi oferecido apenas por Druid. Ele também possui agregação preliminar, que permite economizar um pouco mais de volume e indexação durante a inserção de dados. O Druid suporta todos os tipos de consultas necessárias para nossas estatísticas. Portanto, parecia que poderíamos substituir facilmente o Druid pelo SQL Server.
Obviamente, consideramos não apenas o druida o papel de candidato à mudança. Meu primeiro pensamento foi substituir o Microsoft SQL Server pelo PostgreSQL. No entanto, isso apenas resolveria o problema dos custos financeiros, mas não ajudaria na acessibilidade e no dimensionamento.
Também analisamos o Influx, mas verificou-se que a parte responsável pela alta disponibilidade e escalabilidade está fechada. O Prometheus, com todo o devido respeito ao seu desempenho, é mais otimizado para monitoramento e não pode se orgulhar de alta disponibilidade ou simples escalabilidade. O OpenTSDB também é mais adequado para monitoramento, pois não possui índices para todos os campos. Não consideramos a Click House, pois na época ela não estava lá.
Coloque Druida. Terabytes de dados migrados. E imediatamente após a mudança do SQL Server para o Druid, o número de visualizações de gráficos foi aumentado 5 vezes. Então eles começaram a executar estatísticas “pesadas”, que eles tinham medo de executar mais cedo, porque SQL dificilmente lidaria com isso.
Agora, o Druid de 12 nós (40 núcleos, 196 GB de RAM) recebe 500 mil eventos por segundo por hora de pico, enquanto há uma grande margem de segurança (coluna MAX: quase cinco vezes a margem da CPU).
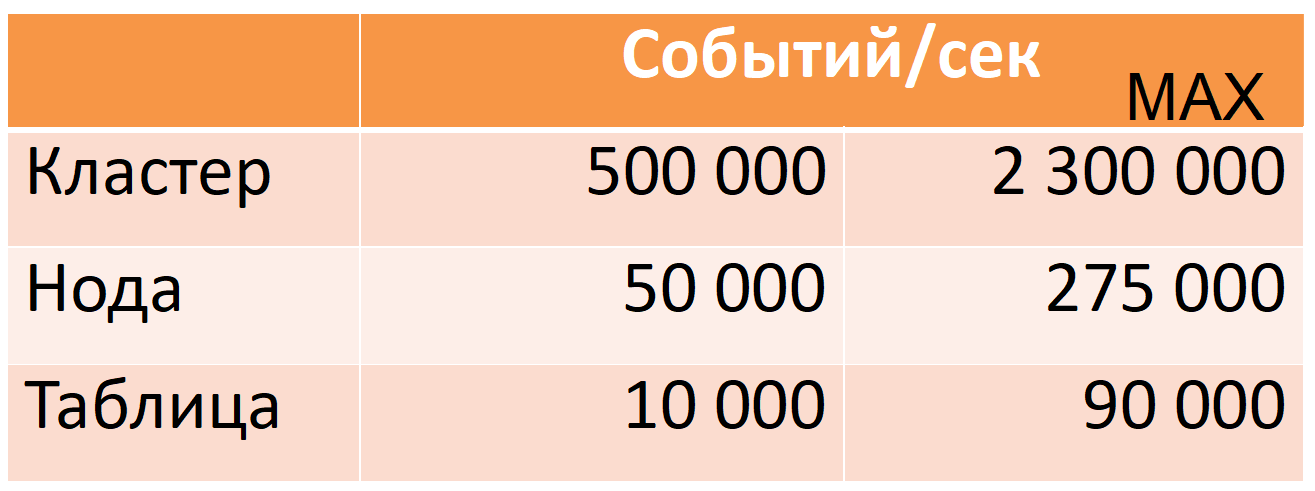
Esses números são baseados em dados de produção. Vou contar como conseguimos isso, mas primeiro descreverei o Druid com mais detalhes.
Druida
Este é um sistema OLAP de séries temporais de colunas distribuídas. Sua documentação não contém os conceitos usuais do mundo SQL para uma tabela (fonte de dados) ou uma string (evento), mas eu os utilizarei para facilitar a descrição.
O Druid é baseado em várias suposições de dados (limitações):
- cada linha de dados tem um carimbo de data / hora que cresce monotonamente (em uma janela de 10 minutos por padrão).
- os dados não mudam, insira apenas (operação de atualização não).
Isso permite que você corte dados nos chamados segmentos de tempo. Um segmento é uma "partição" indivisível e invariável mínima de uma tabela por um determinado período de tempo. Todas as operações de dados, todas as consultas são realizadas segmento por segmento.
Cada segmento é auto-suficiente: além da tabela principal, escrita em forma de coluna, também contém diretórios e índices necessários para a execução da consulta. Podemos dizer que um segmento é um banco de dados somente leitura de coluna pequena (uma descrição mais detalhada do dispositivo de segmento será fornecida abaixo).
Por sua vez, isso resulta em "distribuição": a capacidade de dividir uma grande quantidade de dados em pequenos segmentos para realizar cálculos em paralelo (em uma máquina e em várias ao mesmo tempo).
Se você precisar "atualizar" pelo menos uma linha, precisará recarregar o segmento inteiro novamente. É possível e está tudo pronto para isso. Cada segmento tem uma versão, e um segmento com uma versão mais recente substitui automaticamente o segmento com a versão antiga (no entanto, se a atualização for necessária regularmente, vale a pena reavaliar se o Druid é adequado para essa caso de uso).
Para descrever o segmento do dispositivo, consideramos um exemplo simples na forma tabular usual:
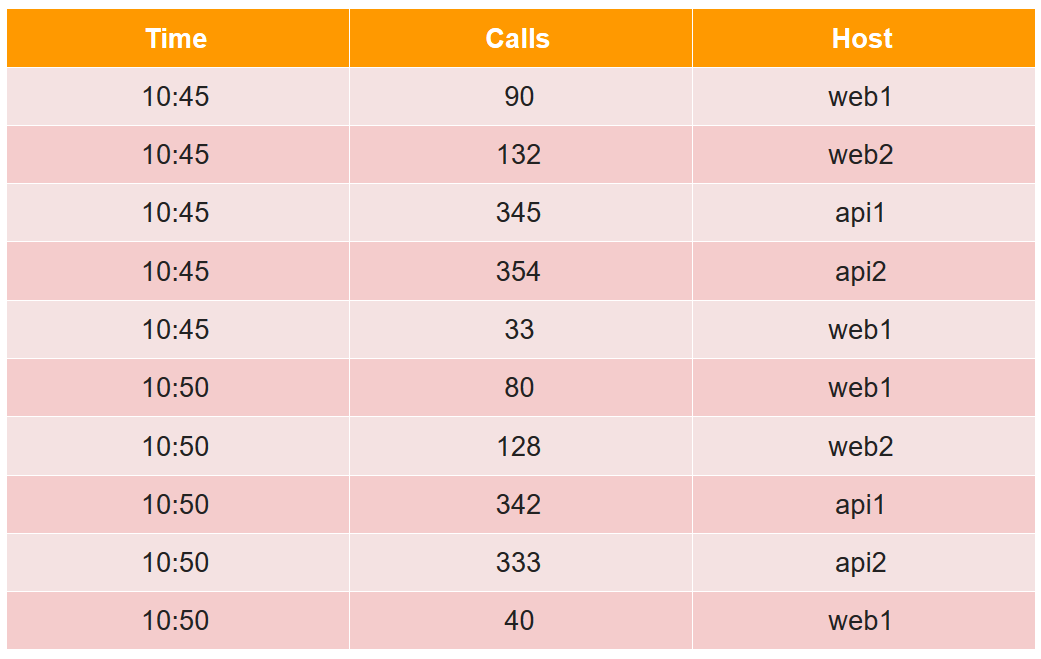
Nesta tabela, o número de chamadas em dois cinco minutos de quatro hosts (observe que, para o host web1, existem duas linhas em cada período de cinco minutos).
Todas as células de dados do ponto de vista do druida são divididas em três tipos:
- registro de data e hora - registro de data e hora UTC em ms (no exemplo, é hora).
- métricas é o que você precisa calcular (soma, min, max, contagem, ...) e precisa conhecê-las com antecedência para cada tabela (no exemplo, são chamadas e calcularemos a soma).
- dimensões - é isso que você pode agrupar e filtrar (você não precisa conhecê-las com antecedência e pode ser alterado rapidamente) (no exemplo, esse é Host).
Ao inserir, todas as linhas são agrupadas pelo conjunto completo de dimensões + registro de data e hora e, se corresponderem a cada uma das métricas, a função de agregação "its" será aplicada (como resultado, não haverá linhas com o mesmo conjunto de dimensões + registro de data e hora). Assim, nosso exemplo após a inserção no druida ficará assim:

O carimbo de data e hora e todas as métricas (no nosso caso, são horas e chamadas) serão gravadas como matrizes de números do tipo long (float e double também são suportados). Para cada uma das dimensões (no nosso caso, é Host), um dicionário será criado - um conjunto classificado de strings (com nomes de host). A própria coluna host será escrita como uma matriz int, indicando os números no dicionário.
Observe que, após a inserção no druida, pares de linhas para o host web1 com o mesmo registro de data e hora foram agregados e a quantidade total foi registrada nas chamadas (é impossível extrair os dados iniciais do druida).
Os índices são necessários para a filtragem rápida de dados, porque pode haver milhões de linhas e milhares de hosts. Os índices são bitmaps, um para cada linha no dicionário.

As unidades indicam os números de linha nos quais esse host participa. Para filtrar dois hosts, você precisa pegar dois bitmaps, combiná-los através de OR e selecionar os números de linha em unidades do bitmap resultante.
Um druida é composto de muitos componentes.
Em primeiro lugar, possui várias dependências externas.

- Armazenamento Lá, o Druid simplesmente armazena os segmentos em uma forma compactada. Pode ser um diretório local, HDFS, Amazon S3. Somente o espaço é usado aqui, nenhum cálculo é feito.
- Meta: um banco de dados para informações meta. Esse banco de dados armazena o mapa de dados completo: quais segmentos são relevantes, quais estão desatualizados, qual caminho está armazenado.
- Usando o ZooKeeper, o sistema realiza a descoberta e anuncia em quais nós do druida quais segmentos estão disponíveis para consulta.
- Cache de solicitações executadas, ele pode ser armazenado em cache ou local armazenado em cache no java.
Em segundo lugar, o próprio Druid consiste em vários tipos de componentes.
- Os nós em tempo real carregam o fluxo de dados atualizados na ordem em que são recebidos e atendem a solicitações.
- Os nós históricos contêm toda a massa de dados e atendem a solicitações. Quando dizemos que temos um cluster de 300 TB, queremos dizer nós históricos.
- O Broker é responsável por distribuir cálculos entre nós históricos e em tempo real.
- O coordenador é responsável pela alocação de segmentos nos nós históricos e pela replicação.
- Serviço de indexação, que permite (re) carregar dados em lotes, por exemplo, para "atualizar" parte dos dados.
Fluxo de dados
 Setas em negrito indicam um fluxo de dados, setas finas indicam um fluxo de metadados.
Setas em negrito indicam um fluxo de dados, setas finas indicam um fluxo de metadados.Um nó em tempo real obtém dados, indexa e corta segmentos por hora, por exemplo, por dia.
Cada novo segmento de um nó em tempo real grava no armazenamento e deixa uma cópia para atender a solicitações. Em seguida, ele registra os metadados que um novo segmento apareceu no repositório ao longo desse caminho.
Esta informação é recebida pelo coordenador, relendo periodicamente a base de metadados. Quando ele encontra um novo segmento, (através do ZooKeeper) solicita vários nós históricos para fazer o download desse segmento. Eles fazem o download e (através do ZooKeeper) anunciam que têm um novo segmento. Quando um nó em tempo real recebe essa mensagem (via ZooKeeper), ele exclui sua cópia para liberar espaço para novos dados.
Processamento de solicitação

Três tipos de nós participam do processamento de solicitações: intermediário, em tempo real e histórico. A solicitação chega ao broker, que sabe em quais nós quais segmentos estão localizados. Ele distribui a solicitação por nós históricos (e em tempo real) que armazenam os segmentos desejados. Os nós históricos também paralelizam os cálculos o máximo possível, enviam os resultados ao intermediário e ele os fornece ao cliente. Ao combinar esse esquema com o armazenamento de dados da coluna, o Druid pode processar grandes quantidades de informações muito rapidamente.
Alta disponibilidade
Como você se lembra, o Druid na lista de dependências tem uma base para metadados, que podem ser MySQL ou PostgreSQL. O Apache Derby também é mencionado, mas este produto não pode ser usado para produção, apenas para desenvolvimento (como eu o entendo, o derby é usado em uma forma incorporada, para não aumentar o mysql / pgsql em um ambiente de virgem).
O que acontecerá se essa base falhar (e / ou armazenamento e / ou o coordenador)? Um nó em tempo real não pode gravar metadados (e / ou segmentos). O coordenador não poderá lê-los novamente e não encontrará um novo segmento. O nó Histórico não fará o download e o nó em tempo real não excluirá sua cópia, mas continuará a baixar os dados mais recentes. Como resultado, os dados começarão a se acumular nos nós em tempo real. Isso não pode continuar indefinidamente. No entanto, sabe-se quais recursos estão disponíveis nos nós em tempo real e que tipo de fluxo de dados temos. Portanto, temos um tempo previsível pelo qual podemos consertar a base com falha (e / ou armazenamento e / ou coordenador).
Como o mysql / pgsql suportado não garante alta disponibilidade imediata, decidimos jogar com segurança e usamos nossa própria solução (pronta) baseada em Cassandra, uma vez que pronta para uso fornece alta disponibilidade (você pode ler mais sobre isso
aqui ).
Além disso, finalizamos os nós em tempo real de forma que, com acumulação excessiva, os dados mais antigos sejam excluídos, liberando espaço para novos. Isso é muito importante para nós, porque a situação em que não podemos aumentar a base com falha (e / ou armazenamento e / ou o coordenador) por um longo tempo e muitos dados acumulados é provavelmente uma consequência de um grande acidente. E, neste momento, os dados mais recentes são mais importantes.
Druida e ZooKeeper
Com o ZooKeeper, tudo fica melhor e pior. Melhor porque o ZooKeeper em si é tolerante a falhas, possui replicação pronta para uso. Parece que isso poderia acontecer?
De um modo geral, este capítulo não é mais relevante. E isso não é uma história de sucesso, é uma dor que (nós e o novo druida) decidimos remover radicalmente quase todos os dados do ZooKeeper, e agora os nós do druida os solicitam diretamente um do outro via HTTP.
O ZooKeeper tem dois tipos de tempos limite. O tempo limite da conexão é um tempo limite da rede simples, após o qual o cliente se reconecta ao ZooKeeper e tenta restaurar sua sessão. E o tempo limite da sessão, após o qual a sessão é excluída e todos os dados
efêmeros criados nessa sessão também são excluídos (pelo próprio ZooKeeper), que é notificado a todos os outros clientes do ZooKeeper.
Com base nisso, a descoberta no druid funciona: na inicialização, cada nó cria uma nova sessão no ZooKeeper e registra dados
efêmeros sobre si: host: porta, tipo de nó (broker / realtime / histórico / ...), registro de data e hora da conexão, etc. ... Outros nós de druida recebem notificações do ZooKeeper e leem esses dados, para saberem que um novo nó de druida aumentou e que tipo de nó é. Se algum nó do druida cair após o tempo limite da sessão, os dados sobre ele serão excluídos pelo ZooKeeper, e os outros nós do druida saberão sobre ele. Para que eles aprendam mais rápido, preferimos colocar um pequeno tempo limite de sessão.
Quando um nó em tempo real ou histórico aumenta, ele, além de dados sobre si mesmo, também grava no ZooKeeper uma lista de segmentos que possui (também são dados
efêmeros ). Mais adiante, segmentos em tempo real e nós históricos são criados, novos e antigos são excluídos, e cada nó reflete isso em sua lista no ZooKeeper. Essa lista pode ser grande e, portanto, é dividida em partes, para que não a lista inteira seja substituída, mas apenas a parte modificada.
O Broker, por sua vez, quando vê um novo nó em tempo real ou histórico, também subtrai sua lista de segmentos do ZooKeeper para distribuir solicitações para esse nó. Os nós em tempo real leem esta lista para remover sua cópia do segmento que apareceu no nó histórico. Como a lista é dividida em partes e é sobrescrita em partes, o ZooKeeper informará qual parte foi alterada, apenas será lida novamente.
Como eu disse, essa lista pode ser longa. Quando há muitos dados no ZooKeeper, verifica-se que ele não é mais tão estável. No nosso caso, problemas óbvios começaram quando o número de segmentos alcançou cerca de 7 milhões, o snapshot do ZooKeeper ocupou 6 GB.
O que acontece se um nó druida perde contato com o ZooKeeper?
O Druid trabalha com o ZooKeeper de tal maneira que, no caso de um tempo limite de sessão, cada nó cria uma nova sessão e grava todos os seus dados lá e relê os dados de outros nós. Como existem muitos dados, o tráfego decola no ZooKeeper. Isso pode levar a um tempo limite em outros nós do druida, e eles também começam a reescrever e reler. Assim, o tráfego cresce como uma avalanche até o ponto em que o ZooKeeper perde a sincronização entre suas instâncias e começa a gerar instantâneos para frente e para trás.
O que o usuário vê neste momento?
Quando um broker perde contato com o ZooKeeper (e ocorre um tempo limite de sessão), ele não sabe mais quais segmentos em que nós históricos estão. E dá respostas vazias. Ou seja, se o ZooKeeper estiver inativo, o Druid não funcionará. É completamente impossível "curá-lo", mas é possível espalhar canudos em alguns lugares.
Em primeiro lugar, você pode excluir dados do ZooKeeper. Tudo bem se eles se perderem: o Druid simplesmente os substituirá. Se o problema com o ZooKeeper já tiver começado, então, para obter a solução mais rápida, é recomendável desativar o ZooKeeper, excluir os dados e aumentá-los vazios, e não espere que ele se resolva.
Agora estamos aumentando o tempo limite da sessão. O que acontece neste caso?
Digamos que o nó histórico não foi reiniciado corretamente e não excluiu a sessão antiga do ZooKeeper, criando um novo e gravando um monte de dados lá. Enquanto a sessão antiga ainda está ativa e o tempo limite não passou, duas cópias dos dados são armazenadas no ZooKeeper. Se houver muitos desses nós reiniciados imediatamente, muitos dados serão duplicados. Portanto, você precisa manter um suprimento de memória para o ZooKeeper para que ele não se esgote e o ZooKeeper não pare de funcionar. Por que não foi possível excluir os dados da sessão antiga?
Pelo mesmo motivo, é necessário concluir corretamente a operação dos nós históricos, pois nesse momento eles excluem seus dados do ZooKeeper e podem fazer isso por um longo tempo. A conclusão dos nós históricos leva cerca de meia hora.
Nós históricos têm mais um recurso. Quando eles iniciam, examinam quais segmentos estão armazenados neles e as informações sobre isso são gravadas no ZooKeeper. E como os dados estão espalhados de maneira mais ou menos uniforme entre os nós históricos, se você os executar ao mesmo tempo, eles começarão a gravar no ZooKeeper aproximadamente ao mesmo tempo. Isso aumenta novamente a probabilidade de crescimento e tempos limite do tráfego semelhante a ondas. Portanto, você precisa executar nós históricos em seqüência para distribuir as sessões de gravação no ZooKeeper no tempo.
Também fizemos mais duas otimizações:
- Nós reprogramamos o trabalho com o ZooKeeper um pouco para que apenas os nós que precisam deles sejam lidos no Druid.E eles são necessários apenas em tempo real, o intermediário e o coordenador, mas não por nós históricos. Eles não precisam saber quais outros nós históricos têm segmentos. Além disso, tudo isso não é necessário para o serviço de indexação e seus funcionários, que podem ser muitos.
- Dos dados gravados no ZooKeeper, eles removeram tudo supérfluo e deixaram apenas o necessário para atender às solicitações. Isso reduziu a quantidade de dados no ZooKeeper de 6 GB para 2 GB (esse é o tamanho do instantâneo).
Como resultado, o volume de tráfego em forte crescimento diminuiu cerca de 8 vezes; assim, minimizamos a probabilidade de tempos limite dos fãs.Carregar no Druid
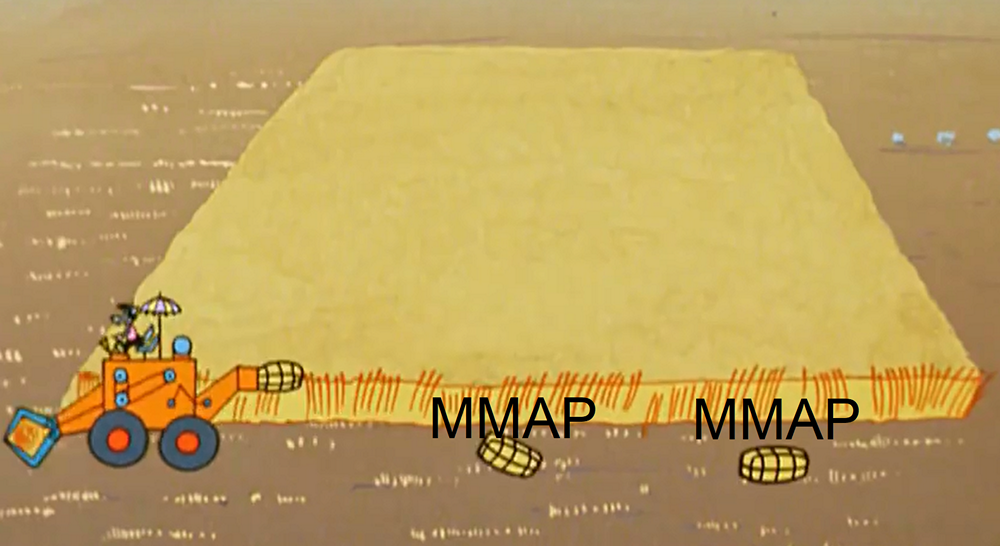 No processo de carregamento de dados em tempo real, o nó periodicamente libera memória liberando dados em partes para o disco. Tecnicamente, essas partes são minissegmentos (cada um possui uma tabela, diretórios, índices). E para processar solicitações com base nesses dados, elas são acessadas usando o MMAP (além de segmentos completos). Ao final do carregamento, um segmento dessas peças está se acumulando bastante. Dois pontos estão conectados com isso.Primeiro, um nó em tempo real pode corromper os dados, não apenas durante uma falha na JVM ou uma reinicialização inesperada do servidor, mas mesmo durante uma reinicialização correta.
No processo de carregamento de dados em tempo real, o nó periodicamente libera memória liberando dados em partes para o disco. Tecnicamente, essas partes são minissegmentos (cada um possui uma tabela, diretórios, índices). E para processar solicitações com base nesses dados, elas são acessadas usando o MMAP (além de segmentos completos). Ao final do carregamento, um segmento dessas peças está se acumulando bastante. Dois pontos estão conectados com isso.Primeiro, um nó em tempo real pode corromper os dados, não apenas durante uma falha na JVM ou uma reinicialização inesperada do servidor, mas mesmo durante uma reinicialização correta. É por isso que isso está acontecendo. O processo de liberação de dados no disco consiste em duas partes: 1) liberação direta de dados e 2) manutenção da posição a partir da qual iniciar após uma reinicialização. Esses dois tipos de dados são gravados de forma completamente independente, eles não sabem nada um do outro. E, claro, não atomicamente. E, dependendo do que exatamente é perdido, temos perda ou duplicação de dados. (No momento, no druida original, isso está sendo reparado ativamente, mas não reparado).Esse problema pode ser resolvido se você não usar nós em tempo real e carregar dados usando o serviço de indexação ou usá-los em pares, porque o serviço de indexação não salva a posição, carrega o segmento inteiro ou descarta o que não foi carregado (por qualquer motivo).O segundo ponto é a degradação do desempenho sob demanda. Quanto mais essas partes se acumulam no disco, especialmente em dados e consultas pesadas, pior.Para entender esse problema, precisamos retornar ao segmento de dispositivo no Druid e nosso exemplo. Como mostrei anteriormente, depois de carregar os dados do exemplo no druida, o segmento resultante parecerá um conjunto de colunas, um dicionário e índices para ele.Agora vamos ver como funciona a consulta neste segmento. Suponha que você precise calcular o número total de chamadas para várias classes de hosts (web%, api%).
É por isso que isso está acontecendo. O processo de liberação de dados no disco consiste em duas partes: 1) liberação direta de dados e 2) manutenção da posição a partir da qual iniciar após uma reinicialização. Esses dois tipos de dados são gravados de forma completamente independente, eles não sabem nada um do outro. E, claro, não atomicamente. E, dependendo do que exatamente é perdido, temos perda ou duplicação de dados. (No momento, no druida original, isso está sendo reparado ativamente, mas não reparado).Esse problema pode ser resolvido se você não usar nós em tempo real e carregar dados usando o serviço de indexação ou usá-los em pares, porque o serviço de indexação não salva a posição, carrega o segmento inteiro ou descarta o que não foi carregado (por qualquer motivo).O segundo ponto é a degradação do desempenho sob demanda. Quanto mais essas partes se acumulam no disco, especialmente em dados e consultas pesadas, pior.Para entender esse problema, precisamos retornar ao segmento de dispositivo no Druid e nosso exemplo. Como mostrei anteriormente, depois de carregar os dados do exemplo no druida, o segmento resultante parecerá um conjunto de colunas, um dicionário e índices para ele.Agora vamos ver como funciona a consulta neste segmento. Suponha que você precise calcular o número total de chamadas para várias classes de hosts (web%, api%).- O Druid primeiro pega o primeiro filtro, uma expressão regular. Com sua ajuda, processa o dicionário inteiro e encontra hosts que correspondem ao filtro.
- Ele pegará os bitmaps apropriados, mesclará e salvará em um bitmap intermediário.
- Então o Druid fará a segunda temporada regular, o segundo filtro, faça o mesmo: percorra o dicionário, pegue os bitmaps, combine, obtenha o segundo bitmap intermediário.
- No final do Druid, o pacote resultante de bitmaps intermediários é combinado em um bitmap final, que mostra de quais linhas precisamos somar as chamadas.
Usando o criador de perfil, descobri que, ao processar uma solicitação, 5% do tempo é gasto no cálculo da quantidade e 95% são gastos na filtragem.Agora vamos ver o que acontece quando um nó em tempo real libera os dados aos poucos no disco no momento da inicialização.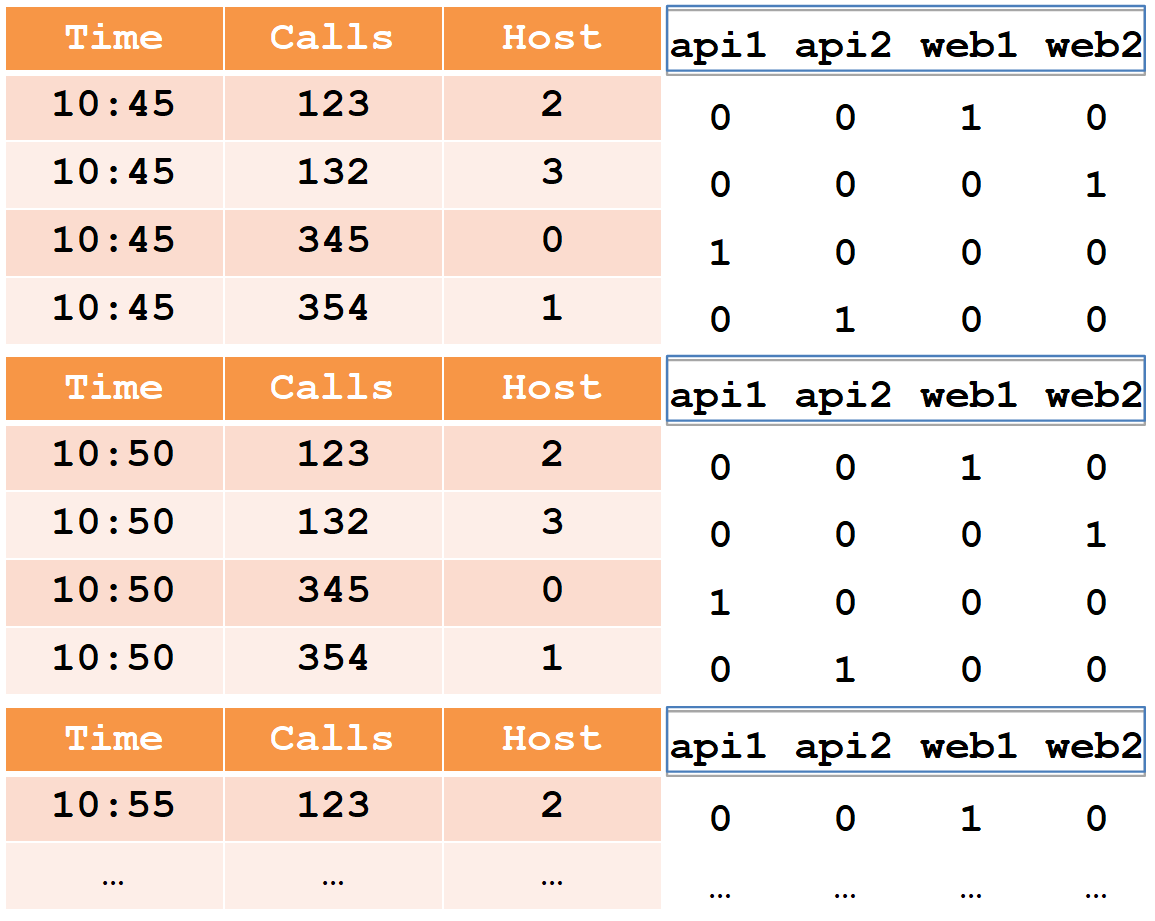 Começamos a baixar dados, despejamos parte (às 10:45) no disco. O resultado foi um mini-segmento com três colunas, um dicionário e índices de bitmap. Fazemos o download adicional, redefinimos a segunda parte (às 10:50) para o disco, novamente temos um mini-segmento.
Começamos a baixar dados, despejamos parte (às 10:45) no disco. O resultado foi um mini-segmento com três colunas, um dicionário e índices de bitmap. Fazemos o download adicional, redefinimos a segunda parte (às 10:50) para o disco, novamente temos um mini-segmento. E assim por diante
Se analisarmos em partes, perceberemos que as colunas "chamadas", "hora" e "host" nessas partes foram cortadas proporcionalmente.Mas com o dicionário e os índices, sai de maneira diferente. Cada host uma vez a cada cinco minutos limpa seus dados, para que todos os hosts sejam "marcados" em cada parte do fluxo para o disco. O dicionário é igualmente grande, não é cortado de forma alguma e existem tantos índices nele. Ao processar uma solicitação, a iteração no dicionário e a combinação de bitmaps (que levam 95% do tempo) precisam ser executadas para cada uma das partes; portanto, a dependência é quase linear: quanto mais partes, mais a solicitação dura. Isso quase não é perceptível enquanto estiver no dicionário até 100 valores e ficará muito perceptível desacelerar quando houver mais de 1000.O que pode ser feito sobre isso? Você pode controlar o número de peças liberadas para o disco. Por exemplo, se você tiver um segmento diário e as consultas estiverem diminuindo a velocidade nos nós em tempo real, reduza-o para hora a hora. Em seguida, o número de partes será reduzido proporcionalmente (já que os dados serão movidos mais rapidamente para os nós históricos e excluídos dos nós em tempo real) e diminuirão proporcionalmente menos.Existem também dois parâmetros que permitem controlar a frequência de liberação dessas peças no disco: o número máximo de linhas na memória e o intervalo de liberação no disco. Por exemplo, você pode redefini-lo não a cada cinco minutos, mas a cada meia hora. E não a cada 100 mil linhas, mas a cada milhão. Então as peças ficarão menores e tudo funcionará muitas vezes mais rápido.Ainda há um ponto importante. Às vezes, 80% do tempo gasto na filtragem leva um dicionário a passar por expressões regulares em vez de combinar bitmaps. Não sabíamos disso e durante a migração todos os filtros foram feitos expressões regulares. Isto não é necessário. Quando filtramos pelo valor exato, devemos usar um filtro do tipo seletor, pois ele encontrará o valor desejado pela pesquisa binária e obterá imediatamente o bitmap. Isso funciona mil vezes mais rápido que o regex.Otimização da faixa de opções
Como você sabe, em qualquer rede social, há um feed de eventos que coleta conteúdo criado por todas as equipes de desenvolvimento. Claro, todas essas equipes querem assistir e escrever estatísticas. Temos estatísticas de fita escritas em um prato, 8 bilhões de linhas por dia. Ela freou mesmo em druida. E o pior é que, quando diminuiu a velocidade, sobrecarregou todo o druida, ou seja, tudo diminuiu para todos. Nestas estatísticas, havia um campo combinado, que consiste em várias palavras conectadas através de um ponto. Algo assim: Podemos apreciar a foto principal, no álbum, no grupo. O mesmo vale para vídeo e música. Também podemos compartilhar fotos, vídeos e músicas na página principal, no álbum e no grupo. E podemos comentar sobre tudo. Um total de 27 combinações de eventos. Assim, o dicionário terá 27 linhas, 27 bitmaps.Queremos calcular quantas curtidas houve. Essa consulta passa por uma expressão regular de 27 valores no dicionário, seleciona 9 deles, obtém 9 bitmaps, combina e passa a contar.Agora vamos cortar em três partes.
Podemos apreciar a foto principal, no álbum, no grupo. O mesmo vale para vídeo e música. Também podemos compartilhar fotos, vídeos e músicas na página principal, no álbum e no grupo. E podemos comentar sobre tudo. Um total de 27 combinações de eventos. Assim, o dicionário terá 27 linhas, 27 bitmaps.Queremos calcular quantas curtidas houve. Essa consulta passa por uma expressão regular de 27 valores no dicionário, seleciona 9 deles, obtém 9 bitmaps, combina e passa a contar.Agora vamos cortar em três partes. A primeira é a ação: curtir, compartilhar, comentar. A segunda parte é um objeto: foto, vídeo, música. A terceira parte é o local: na parte principal, no álbum, no grupo. Em seguida, a consulta entrará em apenas um dicionário - uma ação na qual existem apenas três valores e três bitmaps. Para a pureza do experimento, suponha que essa também seja uma expressão regular. Ou seja, neste caso, haverá três expressões regulares e, no anterior, havia 27. Havia 9 bitmaps, agora existe um. Como resultado, reduzimos a passagem do dicionário e a combinação de bitmaps (que leva 95% do tempo) em 9 vezes. E acabamos de cortar um dicionário de 27 linhas em três.Na realidade, tivemos 14 mil combinações. Assim, em nosso dicionário havia 14 mil valores e 14 mil bitmaps. Como resultado, quando cortamos esse campo em pequenas partes, de acordo com as palavras, a velocidade das estatísticas da fita aumentou 10 vezes e o tamanho dos dados foi reduzido pela metade. Agora tudo funciona rápido.
A primeira é a ação: curtir, compartilhar, comentar. A segunda parte é um objeto: foto, vídeo, música. A terceira parte é o local: na parte principal, no álbum, no grupo. Em seguida, a consulta entrará em apenas um dicionário - uma ação na qual existem apenas três valores e três bitmaps. Para a pureza do experimento, suponha que essa também seja uma expressão regular. Ou seja, neste caso, haverá três expressões regulares e, no anterior, havia 27. Havia 9 bitmaps, agora existe um. Como resultado, reduzimos a passagem do dicionário e a combinação de bitmaps (que leva 95% do tempo) em 9 vezes. E acabamos de cortar um dicionário de 27 linhas em três.Na realidade, tivemos 14 mil combinações. Assim, em nosso dicionário havia 14 mil valores e 14 mil bitmaps. Como resultado, quando cortamos esse campo em pequenas partes, de acordo com as palavras, a velocidade das estatísticas da fita aumentou 10 vezes e o tamanho dos dados foi reduzido pela metade. Agora tudo funciona rápido.Prioridades de solicitação
Mas aqui vem o usuário e quer ver as estatísticas do ano, isto é 2 TB. No nosso cluster, você precisa aumentar 11 GB do disco, isso levará 74 segundos. O usuário sabe que está solicitando dados pesados e está pronto para aguardar. Mas o que os outros usuários farão nesses 74 segundos? Para dizer o mínimo, eles ficarão nervosos e perguntarão por que os gráficos não funcionam.O Druid permite priorizar solicitações. Tentamos diminuir a prioridade para dados pesados, ficou mais fácil, mas ainda diminuiu, porque as prioridades funcionam no nível da fila. Isso significa que, se parte da solicitação pesada já tiver sido processada, todos terão que esperar. Em seguida, solicitações leves e rápidas avançam e, novamente, solicitações pesadas ocupam todos os recursos. Há uma sensação de que o sistema está trabalhando duro, até o limite.Aproveitamos o fato de o Druid ter todas as informações sobre a solicitação e os dados. Eles implementaram uma priorização simples, que define a prioridade para o número (em megabytes) de dados que essa solicitação passará. Ao mesmo tempo, fizemos cinco filas: uma para as solicitações mais difíceis, uma para as mais leves e três intermediárias. Eles espalharam solicitações para a prioridade calculada. Cada fila tem uma prioridade no nível do sistema operacional (definido por meios padrão e configurações de java), portanto, solicitações rápidas excluem as mais pesadas. Agora, finalmente, o Druid ganhou como você espera dele.Sumário
Implementamos um sistema rápido, distribuído e tolerante a falhas, em vez do SQL Server, e não doamos vários milhões de dólares para a Microsoft.Temos fácil escalabilidade horizontal, você só precisa adicionar discos e / ou servidores, conforme necessário.Temos uma grande margem de desempenho para inserir dados e consultas e a capacidade de detalhar nossas estatísticas por uma ordem de magnitude.Atualmente, temos mais de 20 tabelas, cada uma das quais grava mais de um bilhão de linhas por dia, a maior grava 18 bilhões de linhas por dia.Nosso druida é quase totalmente transferido para uma nuvem ( https://habr.com/company/odnoklassniki/blog/346868/ ), o que simplifica ainda mais o processo de dimensionamento.