Oi Habr. Eu gostaria de falar sobre uma das abordagens para resolver o problema da diarização de oradores e mostrar como esse método pode ser implementado em python. Para não assustar o leitor, não darei fórmulas matemáticas complexas (em parte porque eu mesmo não sou um soldador de verdade), mas tentarei explicar tudo em linguagem simples e contar tudo de tal maneira que um desenvolvedor que nunca encontrou o aprendizado de máquina o tenha entendido.
Ao me preparar para escrever este artigo, escolhi entre duas opções: para aqueles que já estão familiarizados com a Ciência de Dados e para aqueles que simplesmente programam bem. No final, escolhi a segunda opção, decidindo que essa seria uma boa demonstração dos recursos do DS.
Declaração do problema
Como a Wikipedia nos
diz , a diarização é o processo de dividir um fluxo de áudio recebido em segmentos homogêneos, de acordo com o fato de o fluxo de áudio pertencer a um ou outro orador. Em outras palavras, o registro deve ser dividido em pedaços e numerado: uma pessoa fala nesses lugares e outra nesses lugares. Do ponto de vista do aprendizado de máquina, tarefas desse tipo pertencem à classe de aprendizado sem professor e são chamadas de agrupamento. Você pode ler sobre quais métodos de agrupamento existem
aqui ou
aqui , por exemplo, mas discutirei apenas aqueles que são úteis para nós - este é um Modelo de Mistura Gaussiano e Agrupamento Espectral. Mas sobre eles um pouco mais tarde.
Vamos começar do começo.
Preparação do ambiente
SpoilerEu não tinha certeza se deveria sair desta seção - não queria transformar o artigo em um tutorial muito. Mas no final eu deixei. Quem não precisar, pulará e, para quem fará tudo do zero, esta etapa facilitará o início.
De um modo geral, além de R, python é a principal linguagem para resolver problemas de ciência de dados, e se você ainda não tentou programar, recomendo fazê-lo porque o python permite que você faça muitas coisas com elegância, literalmente em poucas linhas (a propósito, existem mesmo tal meme).
Existem dois ramos do python em desenvolvimento separadamente - versões 2 e 3. Nos meus exemplos, usei a versão 3.6, mas, se desejado, eles podem ser facilmente portados para a versão 2.7. É conveniente implantar qualquer um desses ramos junto com o instalador do
Anaconda , instalando o qual você receberá imediatamente um shell interativo para desenvolvimento - IPython.
Além do próprio ambiente de desenvolvimento, serão necessárias bibliotecas adicionais: librosa (para trabalhar com atributos de extração e áudio), webrtcvad (para segmentação) e pickle (para gravar modelos treinados em um arquivo). Todos eles são instalados por um comando simples no Anaconda Prompt.
pip install [library]
Extração de recursos
Vamos começar com a extração de recursos - dados com os quais os modelos de aprendizado de máquina funcionarão. Em princípio, o próprio sinal sonoro já é um dado, ou seja, um conjunto ordenado de valores de amplitude sonora, ao qual é adicionado um cabeçalho contendo o número de canais, a frequência de amostragem e outras informações. Mas não poderemos analisar esses dados diretamente, pois eles não contêm essas coisas, observando o que nosso modelo pode dizer - sim, essas peças pertencem à mesma pessoa.
Nas tarefas de processamento de fala, existem várias abordagens para extrair recursos. Uma delas é obter coeficientes cefstrais de frequência de mel. Eles
já foram escritos aqui, então vou lembrá-lo apenas um pouco.
O sinal original é cortado em quadros com um comprimento de 16 a 40 ms. Em seguida, aplicando uma janela
Hamming ao quadro, eles fazem uma rápida transformação de Fourier e obtêm a densidade espectral de potência. Então, com um “pente” especial de filtros dispostos uniformemente na escala de giz, é feito um espectrograma de giz, ao qual uma transformada discreta de cosseno (DCT) é aplicada - um algoritmo de compressão de dados amplamente usado. Os coeficientes assim obtidos são uma espécie de característica compactada do quadro e, como os filtros que usamos foram localizados na escala de
giz , os coeficientes carregam mais informações na faixa de percepção do ouvido humano. Normalmente, 13 a 25 MFCC por quadro são usados. Como, além do próprio espectro, a personalidade da voz é formada por velocidade e aceleração, o MFCC é combinado com o primeiro e o segundo derivado.
Em geral, o MFCC é a opção mais comum para trabalhar com fala, mas existem outros sinais além deles - LPC (Linear Predictive Coding) e PLP (Perceptual Linear Prediction), e às vezes você também pode encontrar o LFCC, onde, em vez da escala de giz, o linear é usado.
Vamos ver como extrair o MFCC em python.
import numpy as np import librosa mfcc=librosa.feature.mfcc(y=y, sr=sr, hop_length=int(hop_seconds*sr), n_fft=int(window_seconds*sr), n_mfcc=n_mfcc) mfcc_delta=librosa.feature.delta(mfcc) mfcc_delta2=librosa.feature.delta(mfcc, order=2) stacked=np.vstack((mfcc, mfcc_delta, mfcc_delta2)) features=stacked.T
Como você pode ver, isso é realmente feito em apenas algumas linhas. Agora vamos para o primeiro algoritmo de clustering.
Modelo de Mistura Gaussiana
Um modelo de uma mistura de distribuições gaussianas sugere que nossos dados são uma mistura de distribuições gaussianas multidimensionais com certos parâmetros.
Se desejar, você pode facilmente encontrar uma descrição detalhada do modelo e como o
algoritmo EM que treina esse modelo funciona, mas prometi não incomodar com fórmulas complexas e, portanto, mostrarei exemplos bonitos
deste artigo.
Vamos gerar quatro grupos e desenhá-los.
from sklearn.datasets.samples_generator import make_blobs X, y_true=make_blobs(n_samples=400, centers=4, cluster_std=0.60, random_state=0) plt.scatter(X[:, 0], X[:, 1]);
Vamos criar um modelo, treinar nossos dados e desenhar novamente os pontos, mas levando em consideração o modelo previsto de associação ao cluster.
from sklearn.mixture import GaussianMixture gmm = GaussianMixture(n_components=4) gmm.fit(X) labels=gmm.predict(X) plt.scatter(X[:, 0], X[:, 1], c=labels, s=40, cmap='viridis');
O modelo lidou bem com dados artificiais. Em princípio, ao regular o número de componentes da mistura e o tipo de matriz de covariância (o número de graus de liberdade dos gaussianos), dados bastante complicados podem ser descritos.

Então, sabemos como parametrizar dados e somos capazes de treinar um modelo de uma mistura de distribuições gaussianas. Agora, pode-se tentar agrupar na testa - treinar GMM no MFCC extraído do diálogo. E, provavelmente, em algum diálogo ideal de vácuo esférico, no qual cada falante se encaixa no seu gaussiano, obteremos um bom resultado. É claro que, na realidade, isso nunca vai acontecer. De fato, com a ajuda do GMM, eles não modelam um diálogo, mas cada pessoa em um diálogo - isto é, eles imaginam que a voz de cada falante nos sinais extraídos é descrita por seu próprio conjunto de gaussianos.
Para resumir, estamos chegando lentamente ao tópico principal.
Segmentação
Tradicionalmente, o processo de diarização consiste em três blocos consecutivos - detecção de voz (Voice Activity Detection), segmentação e clustering (existem modelos nos quais as duas últimas etapas são combinadas, consulte
LIA E-HMM ).
No primeiro passo, a fala é separada de vários tipos de ruído. O algoritmo VAD determina se o trecho do arquivo de áudio enviado a ele é um discurso ou, por exemplo, soa uma sirene ou alguém espirra. É claro que, para que esse algoritmo seja de alta qualidade, é necessário treinamento com um professor. E isso, por sua vez, significa que você precisa marcar os dados - em outras palavras, criar um banco de dados com gravações de fala e todos os tipos de ruído. Vamos fazer isso preguiçosamente - leve um
VAD pronto, que não funciona perfeitamente, mas para iniciantes, temos o suficiente.
O segundo bloco corta os dados de fala em segmentos com um alto-falante ativo. A abordagem clássica a esse respeito é o algoritmo para determinar a alteração do alto-falante com base no critério de informação bayesiano -
BIC . A essência desse método é a seguinte - uma janela deslizante percorre as gravações de áudio e, em cada ponto da passagem, elas respondem à pergunta: "Como os dados neste local são melhor descritos - uma distribuição ou duas?" Para responder a esta pergunta, o parâmetro é calculado
, com base no sinal de que é tomada a decisão de alterar o orador. O problema é que esse método não funcionará muito bem em caso de trocas freqüentes de alto-falante e até mesmo na presença de ruído (que é muito característico para gravar uma conversa telefônica).
Uma pequena explicaçãoNo original, trabalhei com gravações telefônicas de um call center com duração média de cerca de 4 minutos. Por razões óbvias, não posso postar essas anotações; portanto, para a demonstração, tirei
uma entrevista de uma estação de rádio. No caso de uma longa entrevista, esse método provavelmente daria um resultado aceitável, mas não funcionou nos meus dados.
Nas condições em que os anunciadores não se interrompem e suas vozes não se sobrepõem, o VAD que usaremos mais ou menos lida com a tarefa de segmentação; portanto, os dois primeiros passos serão assim.
Na realidade, as pessoas certamente falarão ao mesmo tempo. Além disso, o VAD em alguns lugares errou devido ao fato de o registro não estar ativo, mas é uma colagem na qual as pausas são cortadas. Você pode tentar repetir o corte em segmentos, aumentando a agressividade do VAD de 2 para 3.
GMM-UBM
Agora temos segmentos separados e decidimos modelar cada orador usando o GMM. Extraímos os sinais do segmento e, nesses dados, treinamos o modelo. Vamos fazer isso em cada segmento e comparar os modelos resultantes entre si. É justificável esperar que os modelos treinados em segmentos pertencentes à mesma pessoa sejam um pouco semelhantes. Mas aqui nos deparamos com o seguinte problema: ao extrair sinais de um arquivo de áudio com um segundo de duração e uma frequência de amostragem de 8000 Hz com um tamanho de janela de 10 ms, obtemos um conjunto de 800 vetores MFCC. Nosso modelo não poderá aprender com esses dados, porque são insignificantes. Mesmo que não seja um segundo, mas dez, os dados ainda não serão suficientes. E aqui o UBM (Universal Background Model) vem em socorro, também é chamado de independente do alto-falante. A ideia é a seguinte. Treinaremos o GMM em uma grande amostra de dados (no nosso caso, esta é uma gravação completa da entrevista) e obteremos um modelo acústico de um orador generalizado (este será o nosso UBM). E então, usando um algoritmo de adaptação especial (sobre isso abaixo), "encaixaremos" esse modelo nas características extraídas de cada segmento. Essa abordagem é amplamente usada não apenas para diarização, mas também em sistemas de reconhecimento de voz. Para reconhecer uma pessoa por voz, primeiro você precisa treinar um modelo nela e sem o UBM, você teria que ter várias horas gravando o discurso dessa pessoa.
De cada GMM adaptado, extraímos o vetor de coeficientes de cisalhamento
(é também uma expectativa mediana ou mat., se você preferir) e, com base nos dados desses vetores de todos os segmentos, faremos agrupamentos (abaixo, ficará claro por que é o vetor shift).
Adaptação do mapa
O método pelo qual personalizaremos o UBM para cada segmento é chamado de Adaptação A-Posterior Máxima. Em geral, o algoritmo é o seguinte. Primeiro, a probabilidade posterior é calculada com base nos dados de adaptação e em
estatísticas suficientes para o peso, mediana e variância de cada gaussiano. Em seguida, as estatísticas obtidas são combinadas com os parâmetros UBM e os parâmetros do modelo adaptado são obtidos. No nosso caso, adaptaremos apenas as medianas, sem afetar o restante dos parâmetros. Apesar de prometer não aprofundar a matemática, cito três fórmulas, afinal, porque a adaptação do MAP é o ponto principal deste artigo.
Aqui
- probabilidade posterior,
- estatísticas suficientes para
,
- mediana do modelo adaptado,
- coeficiente de adaptação,
- fator de conformidade.
Se tudo isso parece bobagem e causa desânimo - não se desespere. De fato, para entender a operação do algoritmo, não é necessário aprofundar essas fórmulas; sua operação pode ser facilmente demonstrada pelo seguinte exemplo:
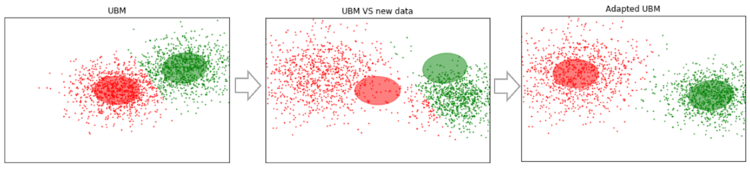
Suponhamos que temos alguns dados grandes o suficiente e treinamos o UBM neles (figura à esquerda, o UBM é uma mistura de dois componentes das distribuições gaussianas). Aparecem novos dados que não se encaixam no nosso modelo (figura ao meio). Usando esse algoritmo, mudaremos os centros dos gaussianos para que eles se encontrem nos novos dados (figura à direita). Aplicando esse algoritmo a dados experimentais, esperaremos que em segmentos com o mesmo alto-falante os gaussianos se desloquem em uma direção, formando grupos. É por isso que usaremos dados de cisalhamento para agrupar segmentos
.
Então, vamos fazer a adaptação do MAP para cada segmento. (Para referência: além da MAP Adaptação, o método MLLR - Regressão Linear de Máxima Verossimilhança e algumas de suas modificações são amplamente utilizadas. Eles também tentam combinar esses dois métodos).
SV = []
Agora que para cada segmento temos dados sobre
, finalmente avançamos para a etapa final.
Cluster espectral
O agrupamento espectral é brevemente descrito no artigo, um link ao qual forneci desde o início. O algoritmo constrói um gráfico completo, onde os vértices são nossos dados e as arestas entre eles são uma medida de similaridade. Nas tarefas de reconhecimento de voz, uma métrica cosseno é usada como medida, uma vez que leva em consideração o ângulo entre os vetores, ignorando sua magnitude (que não carrega informações sobre o falante). Ao construir o gráfico, são calculados os autovetores da matriz Kirchhoff (que é essencialmente uma representação do gráfico resultante) e, em seguida, algum método de agrupamento padrão é usado, por exemplo, o método k-means. Tudo se encaixa em duas linhas de código
N_CLUSTERS = 2 sc = SpectralClustering(n_clusters=N_CLUSTERS, affinity='cosine') labels = sc.fit_predict(SV)
Conclusões e planos futuros
O algoritmo descrito foi testado com vários parâmetros:
- Número MFCC: 7, 13, 20
- MFCC em combinação com LPC
- Tipo e número de misturas no GMM: completo [8, 16, 32], diag [8, 16, 32, 64, 256]
- Métodos de adaptação do UBM: MAP (com covariance_type = 'full') e MLLR (com covariance_type = 'diag')
Como resultado, os parâmetros permaneceram subjetivamente ótimos: MFCC 13, GMM covariance_type = 'full' n_components = 16.
Infelizmente, não tive paciência (comecei a escrever este artigo há mais de um mês) para marcar os segmentos recebidos e calcular o DER (Diariztion Error Rate). Subjetivamente, avalio a operação do algoritmo como "em princípio, não ruim, mas longe do ideal". Agrupando em vetores obtidos dos primeiros cem segmentos (com uma passagem MAP) e selecionando aqueles onde a entrevistadora diz (garota, ela fala muito menos que a convidada), o agrupamento fornece uma lista
isso é 100% atingido. Ao mesmo tempo, os segmentos em que os dois alto-falantes estão presentes (por exemplo, 14) desaparecem, mas isso já pode ser atribuído ao erro VAD. Além disso, esses segmentos começam a ser levados em consideração com um aumento no número de passes de MAP. Um ponto importante. A entrevista com a qual trabalhamos é mais ou menos "limpa". Se várias inserções musicais, ruídos e outras coisas não verbais forem adicionadas, o agrupamento começará a mancar. Portanto, há planos de tentar treinar nosso próprio VAD (porque o webrtcvad, por exemplo, não separa a música da fala).
Devido ao fato de inicialmente ter trabalhado com uma conversa telefônica, não precisei estimar o número de alto-falantes. Mas o número de oradores nem sempre é predeterminado, mesmo que seja uma entrevista. Por exemplo,
nesta entrevista no meio, há um anúncio sobreposto à música e dublado por mais duas pessoas. Portanto, seria interessante tentar o método de estimar o número de falantes especificado no primeiro artigo na seção da lista de referências (com base em uma análise dos autovalores da matriz de Laplace normalizada).
Referências
Além dos materiais localizados nos links no texto e nos laptops Jupyter, as seguintes fontes foram usadas para preparar este artigo:
- Diarização de alto-falante usando supervetor GMM e algoritmos avançados de redução. Nurit spingarn
- Métodos de extração de recursos LPC, PLP e MFCC no reconhecimento de fala. Namrata dave
- Avaliação do MAP para observações de mistura gaussiana mulivariada de cadeias de markov. Jean-Luc Gauvain e Chin-Hui Lee
- Na análise de agrupamento espectral e um algoritmo. Andrew Y. Ng, Michael I. Jordan, Yair Weiss
- Reconhecimento de alto-falante usando o modelo universal de fundo no banco de dados YOHO. Alexandre Majetniak
Também adicionarei alguns projetos de diarização:
- Sidekit e extensão de diarização s4d . Uma biblioteca python para trabalhar com fala. Infelizmente, a documentação é ruim.
- Bob e suas várias partes, como bob.bio , bob.learn.em - uma biblioteca python para processamento de sinais e trabalho com dados biométricos. Windows não é suportado.
- LIUM é uma solução pronta para uso, escrita em Java.
Todo o código é publicado no
github . Por conveniência, fiz vários laptops Jupyter com uma demonstração de algumas coisas - MFCC, GMM, MAP Adaptação e Diarização. Este último é o processo principal. Também estão no repositório os arquivos pickle com alguns modelos pré-treinados e a própria entrevista.