SDSM-15. Sobre QoS. Agora com a possibilidade de
solicitações pull .
E assim chegamos ao tópico de QoS.
Você sabe por que apenas agora e por que será o artigo final de todo o curso SDSM? Porque a QoS é extraordinariamente complexa. A coisa mais difícil que foi antes no ciclo.
Este não é um tipo de arquivador mágico que inteligentemente comprime o tráfego em tempo real e empurra seu gigabit em um uplink de cem megabits. QoS é sobre como sacrificar algo desnecessário, empurrando o não comestível para dentro da estrutura do permitido.
A QoS está tão emaranhada com a aura de xamanismo e inacessibilidade que todos os jovens engenheiros (e não apenas) tentam ignorar cuidadosamente sua existência, acreditando que basta lançar problemas com dinheiro e expandir os vínculos infinitamente. É verdade, até que eles percebam que, com essa abordagem, o fracasso os aguardará inevitavelmente. Ou a empresa começará a fazer perguntas desconfortáveis ou haverá muitos problemas que quase não estão relacionados à largura do canal, mas dependem diretamente da eficiência de seu uso. Sim, o VoIP está agitando ativamente uma caneta nos bastidores, e o tráfego multicast lhe dá um golpe malicioso nas costas.
Portanto, vamos apenas perceber que a QoS é obrigatória, você precisará conhecê-la de uma maneira ou de outra e, por algum motivo, não comece agora, em um ambiente descontraído.

Conteúdo
1.
O que determina a QoS?2.
Três modelos de QoS- Melhores efeitos
- Serviços integrados
- Serviços diferenciados
3.
Mecanismos DiffServ4.
Classificação e rotulagem- Agregação de comportamento
- Campo múltiplo
- Baseado em interface
5.
Filas6.
Evitar Congestionamentos- Cauda da cauda e queda da cabeça
- Vermelho
- Wred
7.
Gerenciamento de congestionamentos- Primeiro a entrar, primeiro a sair
- Fila prioritária
- Filas justas
- Pisco de peito vermelho redondo
8.
limite de velocidade- Moldar
- Policiamento
- Balde com vazamento e balde de tokens
9.
Implementação de QoS por hardware
Antes que o leitor mergulhe nesse buraco, colocarei três configurações nele:
- Nem todos os problemas podem ser resolvidos expandindo a banda.
- QoS não expande a banda.
- QoS sobre o gerenciamento de recursos limitados.
1. O que determina a QoS?
A empresa espera que a pilha de rede execute sua função simples sem problemas - para fornecer um fluxo de bits de um host para outro: sem perdas e em um tempo previsível.
A partir desta frase curta, todas as métricas de qualidade de rede podem ser derivadas:
Essas três características determinam a
qualidade da rede, independentemente de sua natureza: pacote, canal, IP, MPLS, rádio,
pombos .
Perda
Essa métrica informa quantos pacotes enviados pela fonte chegaram ao destino.
A causa da perda pode ser um problema na interface / cabo, congestionamento da rede, erros de bits que bloqueiam as regras da ACL.
O que fazer em caso de perda é decidido pelo aplicativo. Ele pode ignorá-los, como no caso de uma conversa telefônica, onde um pacote atrasado não é mais necessário ou reenviá-lo - é isso que o TCP faz para garantir a entrega precisa dos dados de origem.

Como gerenciar perdas, se inevitáveis, no capítulo Gerenciamento de congestionamentos.
Como aproveitar as perdas no capítulo Prevenção de congestionamentos.
Atrasos
Esse é o tempo que os dados precisam chegar da origem ao destino.

O atraso cumulativo consiste nos seguintes componentes.
- Atraso de serialização - o tempo que leva para um nó decompor um pacote em bits e colocar um link para o próximo nó. É determinado pela velocidade da interface. Assim, por exemplo, a transferência de um pacote de 1500 bytes de tamanho por meio de uma interface de 100 Mb / s levará 0,0001 se, por 56 Kb / s - 0,2 s.
- Atraso na propagação é o resultado da limitação infame da velocidade de propagação das ondas eletromagnéticas. A física não permite que você vá de Nova York a Tomsk na superfície do planeta mais rapidamente do que em 30 ms (na verdade, cerca de 70 ms).
- Os atrasos introduzidos pela QoS são o definhamento de pacotes nas filas ( Atraso na fila ) e as consequências da modelagem ( Atraso na modelagem). Hoje falaremos muito sobre isso no capítulo Controle de velocidade.
- Atraso no processamento de pacotes ( Processing Delay ) - o tempo para decidir o que fazer com o pacote: pesquisa, ACL, NAT, DPI - e entregá-lo da interface de entrada para a saída. Mas no dia em que a Juniper separou o Control and Data Plane em seu M40, os atrasos no processamento poderiam ser negligenciados.
Atrasos não são tão ruins para aplicativos onde não há necessidade de pressa: compartilhamento de arquivos, navegação, VoD, estações de rádio na Internet, etc. Por outro lado, eles são críticos para os interativos: 200ms já é desagradável de ouvido durante uma conversa telefônica.
Um termo relacionado a atraso que não é sinônimo de
RTT (
Round Trip Time ) é a ida e volta. Ao executar o ping e o rastreamento, você vê exatamente o RTT, e não um atraso unidirecional, embora os valores tenham uma correlação.
Jitter
A diferença de atraso entre a entrega de pacotes consecutivos é chamada de instabilidade.
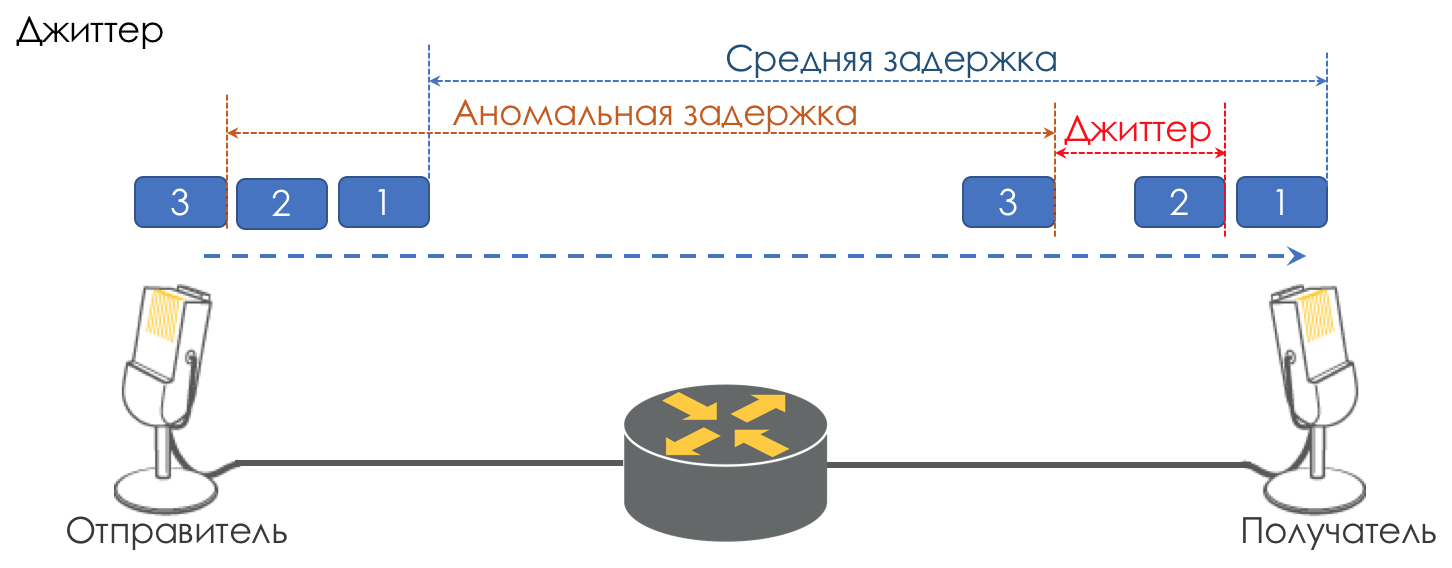
Como a latência, o jitter não importa para muitos aplicativos. E até, ao que parece, qual é a diferença - o pacote foi entregue, e daí?
No entanto, para serviços interativos, é importante.
Tome a mesma telefonia como exemplo. De fato, é uma digitalização de sinais analógicos com uma divisão em blocos de dados separados. A saída é um fluxo de pacotes bastante uniforme. No lado receptor, há um pequeno buffer de tamanho fixo no qual os pacotes que chegam sequencialmente se encaixam. Para restaurar o sinal analógico, é necessário um certo número deles. Em condições de atrasos flutuantes, o próximo bloco de dados pode não chegar a tempo, o que equivale a uma perda, e o sinal não pode ser restaurado.
A maior contribuição para a variabilidade do atraso é feita apenas pela QoS. Isso também é muito tedioso nos mesmos capítulos Limite de velocidade.
Essas são as três principais características da qualidade da rede, mas há outras que também desempenham um papel importante.
Entrega aleatória
Vários aplicativos, como telefonia,
NAS ,
CES, são extremamente sensíveis à entrega aleatória de pacotes quando chegam ao destinatário na ordem errada em que foram enviados. Isso pode levar à perda de conectividade, erros, danos ao sistema de arquivos.
Embora a entrega aleatória não seja um recurso formal de QoS, ela definitivamente se refere à qualidade da rede.
Mesmo com o TCP tolerante a esse tipo de problema, ocorrem ACKs e retransmissões duplicadas.

Largura de banda
Não se distingue como uma métrica da qualidade da rede, pois de fato sua desvantagem resulta nos três acima. No entanto, em nossas realidades, quando deve ser garantido para algumas aplicações ou, pelo contrário, deve ser limitado por contrato, por exemplo, a MPLS TE reserva-a em todo o LSP, vale a pena mencionar, pelo menos como uma métrica fraca.
Os mecanismos de controle de velocidade serão discutidos nos capítulos Limite de velocidade.
Por que as especificações podem ficar ruins?
Então, começamos com uma idéia muito primitiva de que um dispositivo de rede (seja um switch, roteador, firewall, seja o que for) é apenas mais um pedaço de tubo chamado canal de comunicação, o mesmo que um fio de cobre ou um cabo óptico.

Todos os pacotes voam na mesma ordem em que chegaram e não sofrem atrasos adicionais - não há lugar para ficar.
Mas, de fato, cada roteador restaura bits e pacotes do sinal, faz algo com eles (ainda não pensamos nisso) e depois converte os pacotes novamente em um sinal.
Um atraso de serialização aparece. Mas, em geral, isso não é assustador, porque é constante. Não é assustador, desde que a largura da interface de saída seja maior que a entrada.
Por exemplo, na entrada do dispositivo há uma porta gigabit e na saída há uma linha de relé de rádio de 620 Mb / s conectada à mesma porta gigabit?
Ninguém proibirá a bala através do tráfego de gigabit de link formalmente gigabit.
Não há nada a ser feito - 380 Mb / s cairão no chão.
Aqui estão elas - perdas.
Mas, ao mesmo tempo, eu gostaria muito da pior parte a ser derramada - um vídeo do youtube, e a conversa telefônica do diretor executivo com o diretor da fábrica não interrompeu nem mesmo coaxou.
Eu gostaria que a voz tivesse uma linha dedicada.
Ou há cinco interfaces de entrada, mas uma saída e, ao mesmo tempo, cinco nós começaram a tentar injetar tráfego em um destinatário.
Adicione uma pitada da teoria do VoIP (um artigo sobre o qual ninguém escreveu) - é muito sensível a atrasos e suas variações.
Se para um fluxo de vídeo TCP do youtube (no momento da redação do artigo
QUIC - ainda permanece um experimento) atrasos, mesmo em segundos, são completamente inúteis devido ao buffer, o diretor após a primeira conversa com Kamchatka chamará o chefe do departamento técnico.
Nos tempos antigos, quando o autor do ciclo ainda fazia sua lição de casa à noite, o problema era especialmente grave. As conexões de modem tinham uma
velocidade de 56k .
E quando um pacote de 1,5K entrou nessa conexão, ele ocupou toda a linha por 200 ms. Ninguém mais poderia passar neste momento. Uma voz? Não, eu não ouvi.
Portanto, a questão da MTU é muito importante - o pacote não deve ocupar a interface por muito tempo. Quanto menor a velocidade, menor a MTU é necessária.
Aqui estão eles - atrasos.
Agora o canal está livre e o atraso está baixo, depois de um segundo alguém começou a baixar um arquivo grande e os atrasos aumentaram. Aqui está ele - nervosismo.
Portanto, é necessário que os pacotes de voz voem através do canal com atrasos mínimos e o youtube espere.
620 Mb / s disponíveis devem ser usados para voz, vídeo e clientes B2B que compram VPNs. Gostaria que um tráfego não oprimisse o outro, por isso precisamos de uma garantia de banda.
Todas as características acima são universais em relação à natureza da rede. No entanto, existem três abordagens diferentes para sua provisão.
2. Três modelos de QoS
- Melhor esforço - sem garantia de qualidade. Todos são iguais.
- O IntServ é uma garantia de qualidade para cada fluxo. Reservando recursos da origem ao destino.
- DiffServ - Não há reserva. Cada nó em si determina como garantir a qualidade certa.
Melhor Esforço (BE)
Sem garantias.A abordagem mais simples para implementar a QoS, a partir da qual as redes IP começaram e ainda são praticadas até hoje - às vezes porque é suficiente, mas mais frequentemente porque ninguém pensou em QoS.
A propósito, quando você envia tráfego para a Internet, ele será processado como BestEffort. Portanto, por meio de uma VPN rolada na Internet (em oposição a uma VPN fornecida pelo provedor), tráfego importante, como uma conversa telefônica, pode não ser muito confiante.
No caso de BE, todas as categorias de tráfego são iguais; nenhuma preferência é dada a nenhuma. Portanto, não há garantia de atraso / instabilidade ou banda.
Essa abordagem tem um nome um tanto contra-intuitivo - Melhor Esforço, que o recém-chegado engana com a palavra "melhor".
No entanto, a frase "farei o meu melhor" significa que o orador tentará fazer tudo o que puder, mas não garante nada.
Nada é necessário para implementar o BE - este é o comportamento padrão. É barato fabricar, a equipe não precisa de conhecimentos específicos profundos; nesse caso, a QoS não pode ser personalizada.
No entanto, essa simplicidade e estática não levam ao fato de que a abordagem de melhor esforço não é usada em nenhum lugar. Ele encontra aplicação em redes com alta largura de banda e ausência de congestionamentos e explosões.
Por exemplo, em linhas transcontinentais ou nas redes de alguns data centers em que não há excesso de assinaturas.
Em outras palavras, em redes sem congestionamento e onde não há necessidade de se relacionar com nenhum tráfego (por exemplo, telefonia) de uma maneira especial, o BE é bastante apropriado.
Interv
Reserva antecipada de recursos para o fluxo desde a origem até o destino.Os pais das redes MIT, Xerox e ISI decidiram adicionar o elemento de previsibilidade à crescente Internet aleatória, mantendo sua operabilidade e flexibilidade.
Assim, em 1994, a ideia do IntServ nasceu em resposta ao rápido crescimento do tráfego em tempo real e ao desenvolvimento do multicast. Foi então reduzido para IS.
O nome reflete o desejo na mesma rede de fornecer serviços simultaneamente para tipos de tráfego em tempo real e não em tempo real, fornecendo a primeira prioridade de direito de usar recursos através da reserva da banda. A capacidade de reutilizar a banda na qual todos ganham dinheiro, e graças à qual o IP disparou, foi preservada.
A missão de backup foi atribuída ao protocolo RSVP, que para
cada fluxo reserva uma banda em
cada dispositivo de rede.
Grosso modo, antes de configurar uma sessão Single Rate Three Color MarkerP ou iniciar a troca de dados, os hosts finais enviam o caminho RSVP com a largura de banda necessária. E se ambos retornaram RSVP Resv - eles podem começar a se comunicar. Ao mesmo tempo, se não houver recursos disponíveis, o RSVP retornará um erro e os hosts não poderão se comunicar ou seguir o BE.
Agora, os mais bravos leitores imaginam que um canal será sinalizado antecipadamente para
qualquer fluxo na Internet hoje. Considerando que isso requer custos de CPU e memória diferentes de zero em
cada nó de trânsito, adia a interação real por algum tempo, fica claro por que o IntServ acabou sendo uma ideia praticamente natimortal - escalabilidade zero.
Em certo sentido, a encarnação moderna do IntServ é o MPLS TE com uma versão de rotulagem adaptada do RSVP - RSVP TE. Embora aqui, é claro, não seja de ponta a ponta e nem por fluxo.
O IntServ é descrito na
RFC 1633 .
O documento é, em princípio, curioso para avaliar o quão ingênuo você pode ser nas previsões.
Diffserv
DiffServ é complicado.Quando ficou claro, no final dos anos 90, que a abordagem IP IntServ de ponta a ponta falhou, a IETF convocou o grupo de trabalho Serviços diferenciados em 1997, que desenvolveu os seguintes requisitos para o novo modelo de QoS:
- Sem sinalização (Adjos, confirma!).
- Com base na classificação de tráfego agregado, em vez de focar nos fluxos, clientes, etc.
- Possui um conjunto limitado e determinístico de ações para processar o tráfego de dados das classes.
Como resultado, o marco
RFC 2474 (
definição do campo de serviços diferenciados (campo DS) nos cabeçalhos IPv4 e IPv6 ) e o
RFC 2475 (
uma arquitetura para serviços diferenciados ) nasceu em 1998.
E mais adiante, falaremos apenas sobre o DiffServ.
Vale ressaltar que o nome DiffServ não é a antítese do IntServ. Isso reflete que diferenciamos os serviços fornecidos por vários aplicativos, ou melhor, o tráfego deles, ou seja, compartilhamos / diferenciamos esses tipos de tráfego.
O IntServ faz o mesmo - ele distingue entre os tipos de tráfego BE e Real-Time, transmitidos na mesma rede. Ambos: e IntServ e DiffServ - referem-se a maneiras de diferenciar serviços.
3. Mecanismos DiffServ
O que é o DiffServ e por que ele vence o IntServ?
Se for muito simples, o tráfego será dividido em classes. Um pacote na entrada de cada nó é classificado e um conjunto de ferramentas é aplicado a ele, que processa pacotes de diferentes classes de maneiras diferentes, fornecendo-lhes um nível de serviço diferente.
Mas simplesmente
não será .
No coração do DiffServ está o conceito ideal de IP IP
PHB - Comportamento por salto . Cada nó no caminho de tráfego toma uma decisão independente sobre como se comportar em relação ao pacote recebido, com base em seus cabeçalhos.
As ações do roteador de pacotes serão chamadas de modelo de comportamento. O número de tais modelos é determinístico e limitado. Em dispositivos diferentes, os modelos de comportamento em relação ao mesmo tráfego
podem ser diferentes, portanto, são por salto.
Os conceitos de comportamento e PHB usarei no artigo como sinônimos.Há uma ligeira confusão. PHB é, por um lado, o conceito geral de comportamento independente de cada nó e, por outro, um modelo específico em um nó específico. Com isso, vamos descobrir.

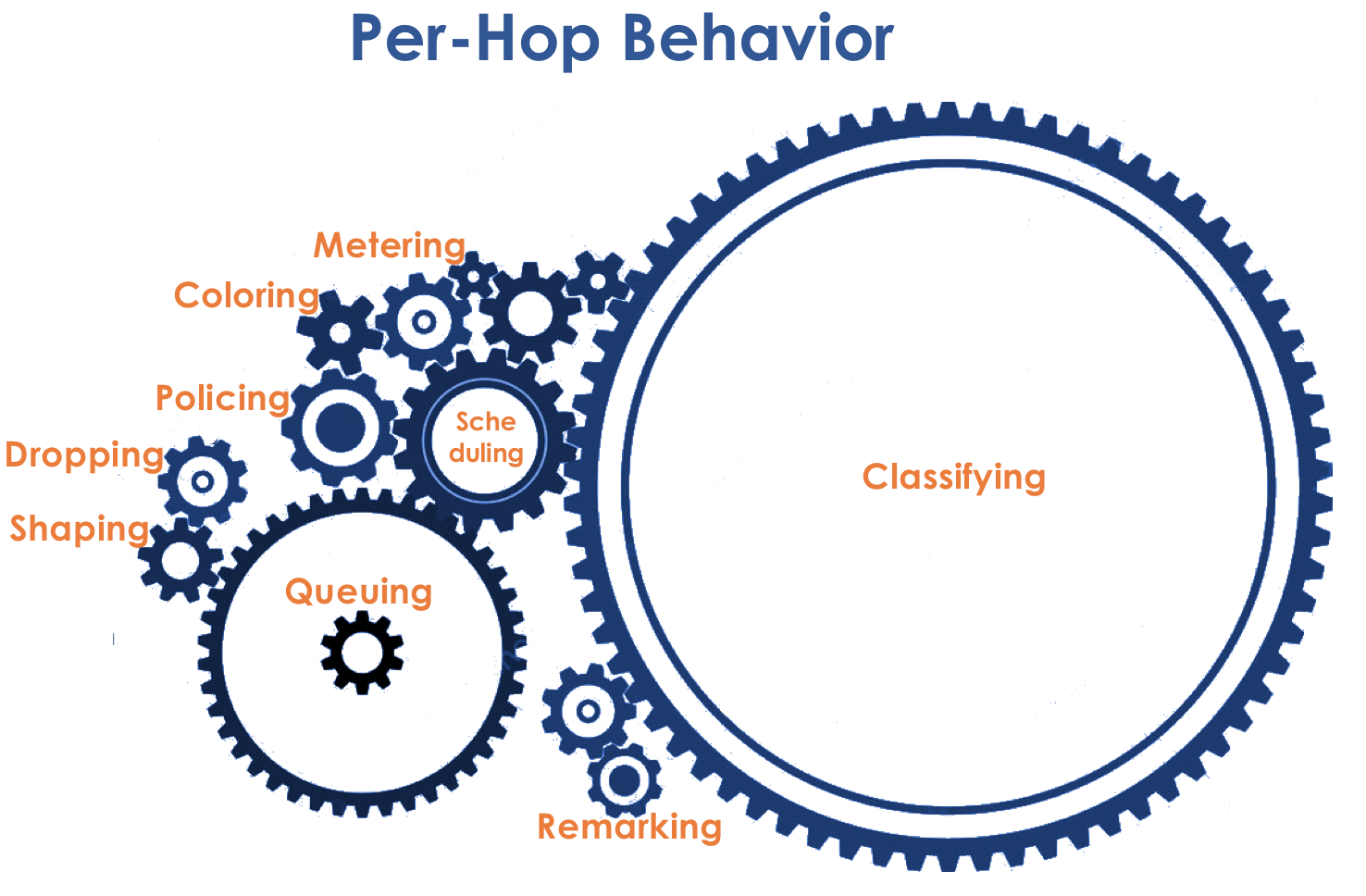
O modelo de comportamento é determinado por um conjunto de ferramentas e seus parâmetros: policiamento, descarte, enfileiramento, agendamento e modelagem.
Usando os modelos de comportamento disponíveis, a rede pode fornecer várias classes de serviço (
Classe de Serviço ).
Ou seja, diferentes categorias de tráfego podem receber diferentes níveis de serviço na rede aplicando PHBs diferentes a eles.
Portanto, primeiro, você precisa determinar a qual classe de tráfego de serviço se refere -
Classificação .
Cada nó classifica independentemente os pacotes recebidos.

Após a classificação, ocorre uma medição (
Medição ) - quantos bits / bytes de tráfego dessa classe chegaram ao roteador.
Com base nos resultados, as embalagens podem ser pintadas (
Coloração ): verde (dentro do limite estabelecido), amarelo (fora do limite), vermelho (seduziu completamente a costa).
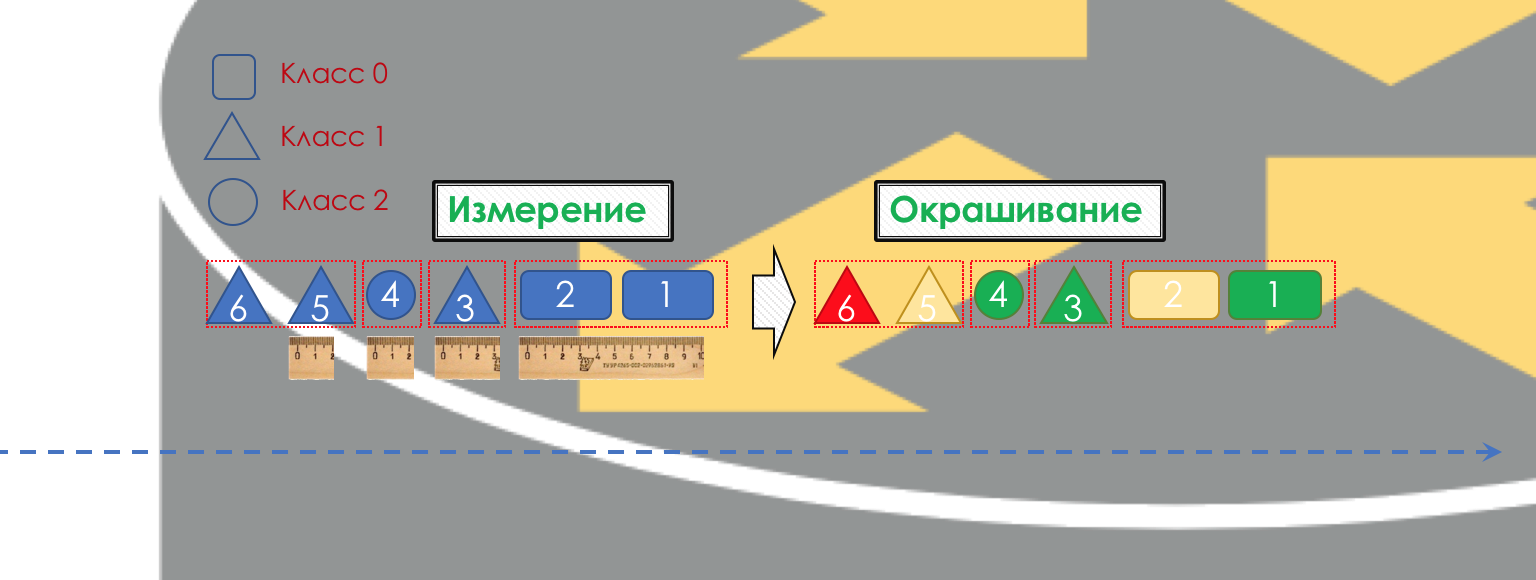
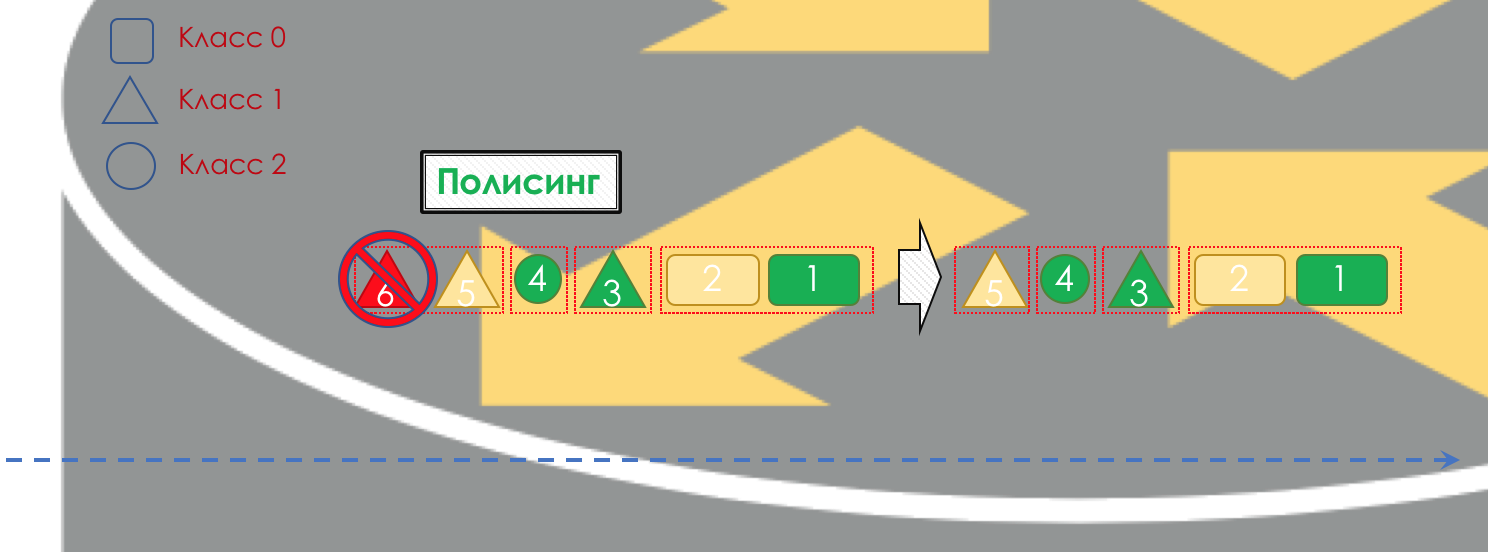
Se necessário, ocorre o
policiamento (desculpe-me por esse papel vegetal, existe uma opção melhor - escreva, vou mudar). Um polidor com base na cor de um pacote atribui uma ação ao pacote - transmitir, descartar ou marcar novamente.
Depois disso, o pacote deve cair em uma das filas (
Enfileiramento ). Uma fila separada é alocada para cada classe de serviço, o que permite que sejam diferenciadas usando PHBs diferentes.
Porém, mesmo antes do pacote entrar na fila, ele pode ser descartado (
Dropper ) se a fila estiver cheia.
Se estiver verde, ele passará, se estiver amarelo, provavelmente será descartado se a linha estiver cheia e se vermelho for um bom ataque suicida. Condicionalmente, a probabilidade de queda depende da cor do pacote e da plenitude da fila onde ela vai chegar.
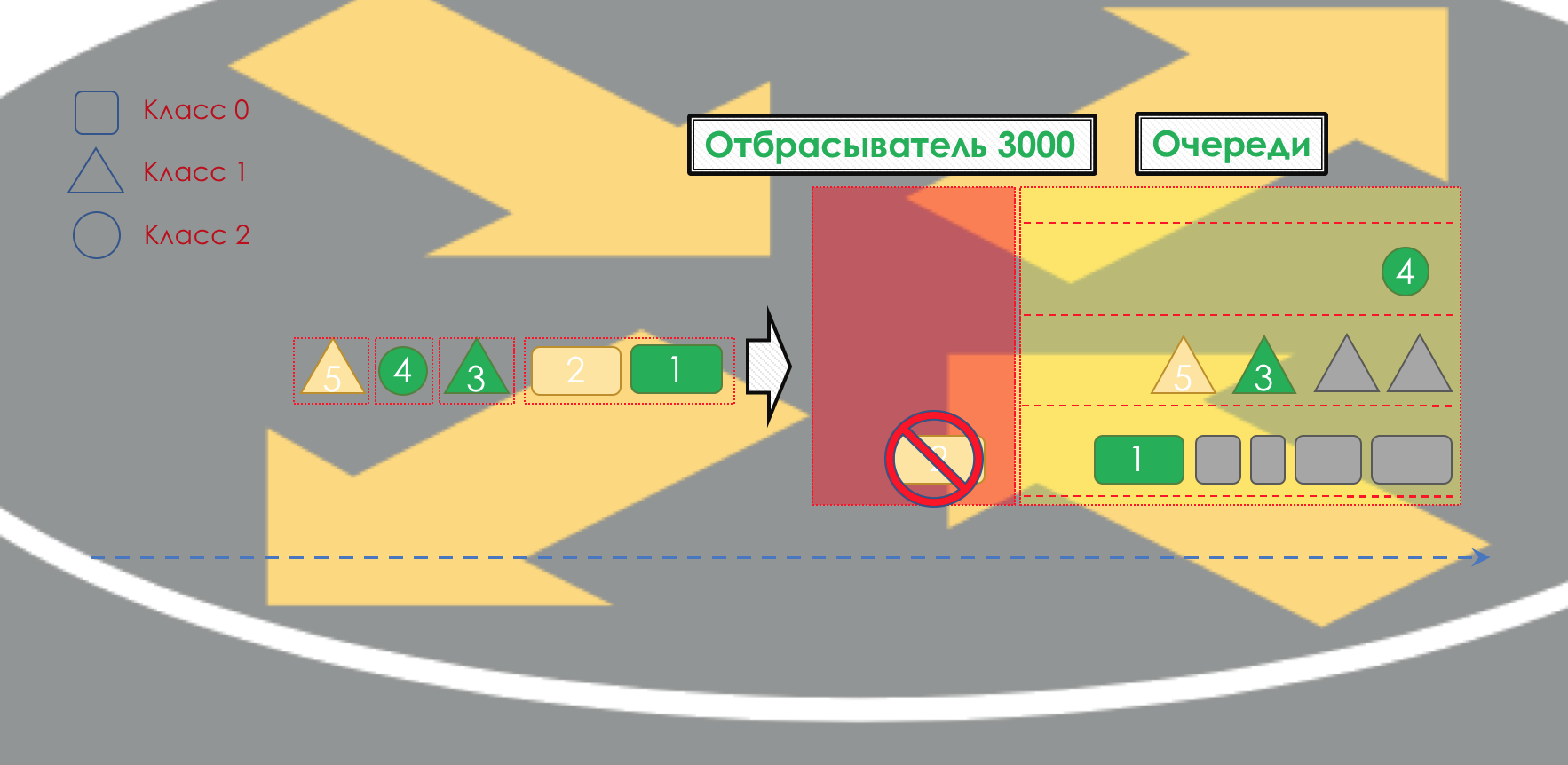
Na saída da fila, um
Shaper funciona, cuja tarefa é muito semelhante à tarefa do polisador - limitar o tráfego a um determinado valor.
Você pode configurar shapers arbitrários para filas individuais ou mesmo dentro de filas.
Sobre a diferença entre um modelador e um poliser no capítulo Limite de velocidade.
Todas as filas devem eventualmente se fundir em uma única interface de saída.
Lembre-se da situação em que, na estrada, 8 faixas se fundem em 3. Sem um controlador de tráfego, isso se transforma em caos. A separação por turnos não faria sentido se tivéssemos a mesma saída que a entrada.
Portanto, existe um despachante especial (
Agendador ), que retira ciclicamente pacotes de diferentes filas e os envia para a interface (
Agendamento ).
De fato, uma combinação de um conjunto de filas e um despachante é o mecanismo de QoS mais importante que permite aplicar regras diferentes a diferentes classes de tráfego, uma fornecendo uma ampla largura de banda, a outra baixa latência e a terceira falta de descargas.
Então os pacotes já vão para a interface, onde os pacotes são convertidos em um fluxo de bits - serialização (
serialização ) e depois no sinal do ambiente.
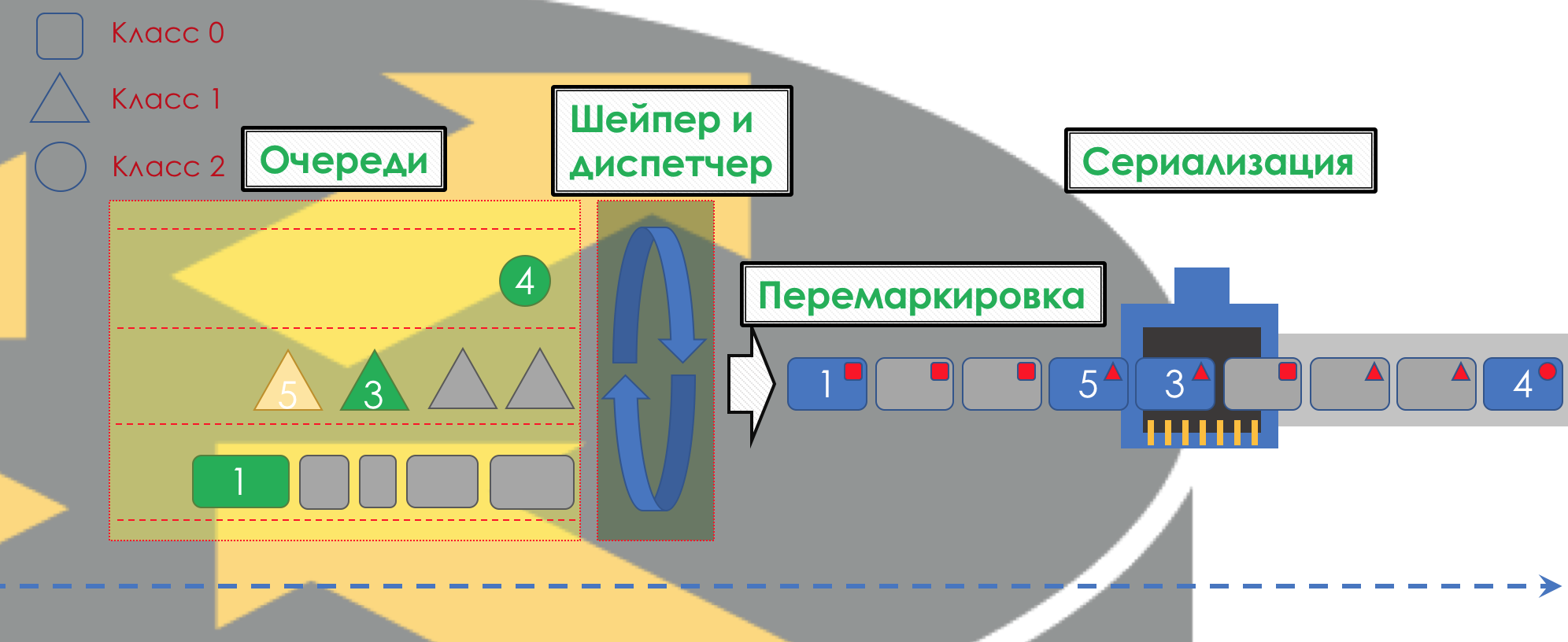
No DiffServ, o comportamento de cada nó é independente dos outros; não há protocolos de sinalização que indiquem qual política de QoS está na rede. Ao mesmo tempo, na rede, eu gostaria que o tráfego fosse tratado da mesma maneira. Se apenas um nó se comportar de maneira diferente, toda a política de QoS estará no ralo.
Para fazer isso, primeiro, em todos os roteadores, as mesmas classes e PHB são configuradas para eles; segundo, é usada a
marcação do pacote - sua pertença a uma classe específica é registrada no cabeçalho (IP, MPLS, 802.1q).
E a beleza do DiffServ é que o próximo nó pode contar com esse rótulo para classificação.
Essa zona de confiança, na qual as mesmas regras de classificação de tráfego e os mesmos comportamentos se aplicam, é chamada de domínio
DiffServ (
DiffServ-Domain ).

Assim, na entrada do domínio DiffServ, podemos classificar um pacote com base em 5 tuplas ou em uma interface, marcá-lo (
Observação / Reescrever ) de acordo com as regras do domínio, e outros nós confiarão nessa marcação e não farão uma classificação complexa.
Ou seja, não há sinalização explícita no DiffServ, mas o nó pode dizer a todos os seguintes que classe esse pacote precisa ser fornecido, esperando que seja confiável.
Nas junções entre domínios DiffServ, você precisa negociar políticas de QoS (ou não).
A imagem inteira será mais ou menos assim:
Para deixar claro, darei um análogo da vida real.
Vôo de avião (não vitória).
Existem três classes de serviço (CoS): Economia, Negócios, Primeiro.
Ao comprar um bilhete, a Classificação ocorre - o passageiro recebe uma determinada classe de serviço com base no preço.
No aeroporto, há uma marcação (Observação) - um bilhete é emitido indicando a classe.
Existem dois comportamentos (PHBs): Melhor Esforço e Prêmio.
Existem mecanismos que implementam comportamentos: uma sala de espera comum ou VIP Lounge, um microônibus ou um ônibus compartilhado, assentos grandes confortáveis ou filas estreitas, número de passageiros por comissário de bordo, capacidade de pedir álcool.
Dependendo da classe, os modelos de comportamento são atribuídos - à economia de Melhor Esforço, aos Negócios - Premium básico e ao Primeiro - SUPER-POWER-NINJA-TURBO-NEO-ULTRA-HIPER-MEGA-MULTI-ALFA-META-EXTRA-UBER-PREFIX!
Ao mesmo tempo, dois prêmios diferem no fato de que, em um, eles dão um copo de meio-doce e, no outro, têm Bacardi ilimitado.
Então, ao chegar ao aeroporto, todos passam por uma porta. Aqueles que tentaram trazer armas com eles ou não possuem ingresso não são permitidos (Drop). Negócios e economia entram em diferentes salas de espera e diferentes transportes (filas). Primeiro, eles deixam a Primeira Classe a bordo, depois os negócios, depois a Economia (Programação), mas depois todos voam para o seu destino com um avião (interface).
No mesmo exemplo, um voo em um avião é um atraso de propagação, o pouso é um atraso de serialização, a espera de um avião nos corredores é na fila e o controle de passaporte é em processamento. Observe que aqui o atraso no processamento geralmente é insignificante em termos de tempo total.
O próximo aeroporto pode lidar com passageiros de uma maneira completamente diferente - seu PHB é diferente. Mas, ao mesmo tempo, se o passageiro não mudar de companhia aérea, provavelmente a atitude em relação a ele não mudará, porque uma empresa é um domínio DiffServ.
Como você deve ter notado, o DiffServ é extremamente (ou infinitamente) complexo. Mas vamos analisar tudo descrito acima. Ao mesmo tempo, no artigo, não abordarei as nuances da implementação física (elas podem diferir mesmo em duas placas do mesmo roteador), não falarei sobre HQoS e MPLS DS-TE.
O limite para entrar no círculo de engenheiros que entendem a tecnologia para QoS é muito maior do que para protocolos de roteamento, MPLS ou, desculpe-me, Radya, STP.
Apesar disso, o DiffServ ganhou reconhecimento e implementação em redes em todo o mundo, porque, como eles dizem, são altamente escaláveis.
No restante deste artigo, analisarei apenas o DiffServ.
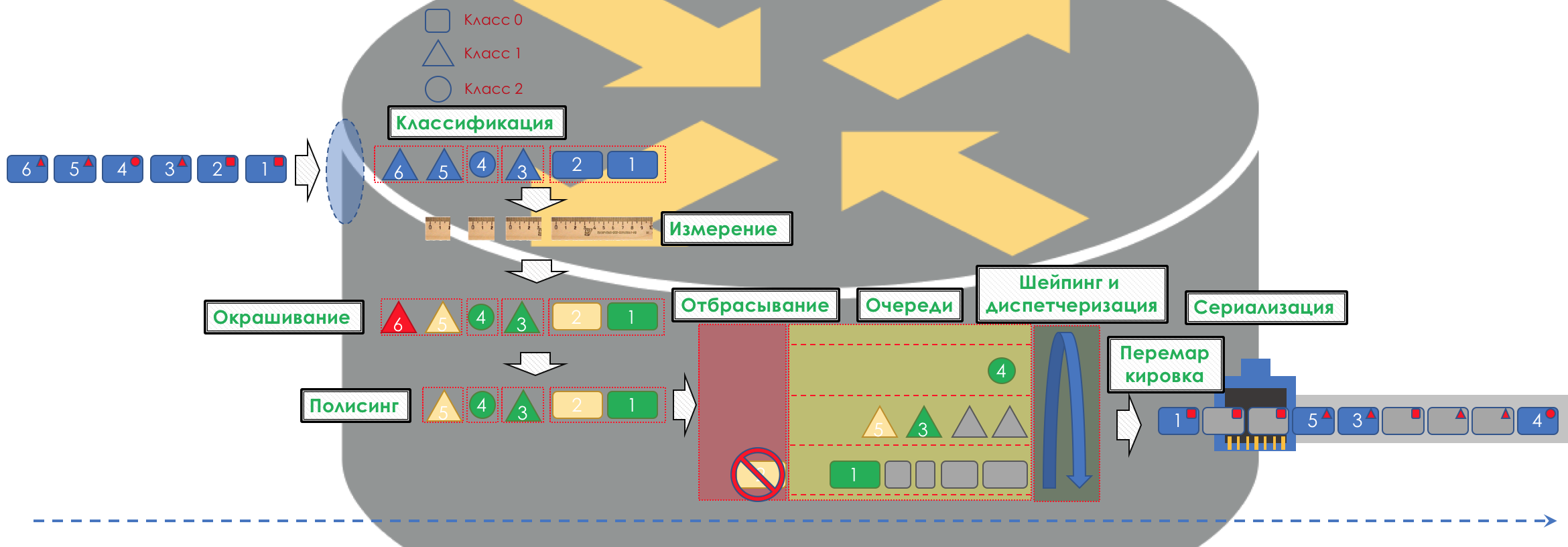
A seguir, analisaremos todas as ferramentas e processos indicados na ilustração.
No decorrer da expansão do tópico, mostrarei algumas coisas na prática.
Trabalharemos com essa rede:
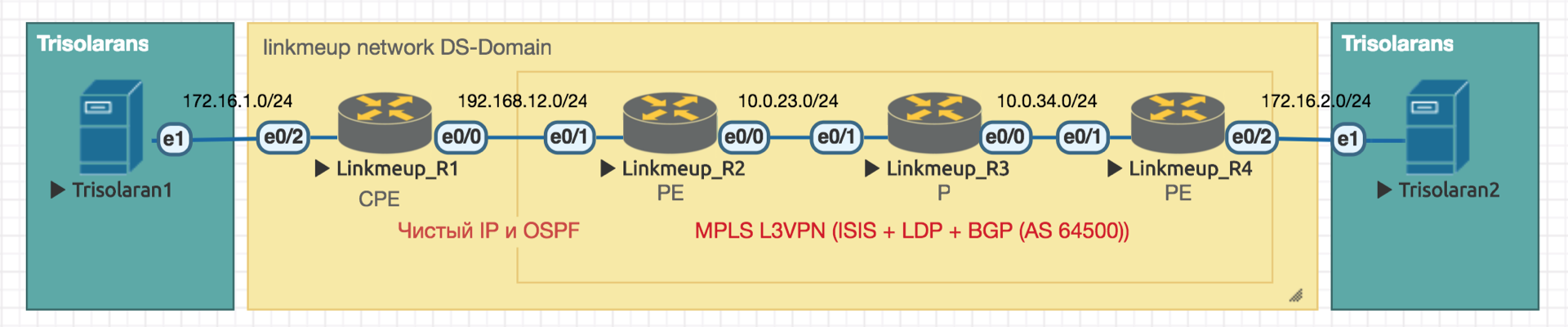
Trisolarans é um cliente provedor de linkmeup com dois pontos de conexão.
A área amarela é o domínio DiffServ da rede linkmeup, onde uma única política de QoS está em vigor.
Linkmeup_R1 é um dispositivo CPE que é gerenciado pelo provedor e, portanto, em uma zona confiável. O OSPF é criado com ele e a interação ocorre através de um IP limpo.
Dentro do núcleo da rede estão MPLS + LDP + MP-BGP com L3VPN, estendido de Linkmeup_R2 para Linkmeup_R4.
Farei todos os outros comentários, se necessário.
O arquivo de configuração inicial .
4. Classificação e rotulagem
Dentro de sua rede, o administrador define as classes de serviço que ele pode fornecer tráfego.
Portanto, a primeira coisa que cada nó faz quando recebe um pacote é classificá-lo.
Existem três maneiras:
- Agregado de comportamento ( BA )
Apenas confie no rótulo do pacote existente em seu cabeçalho. Por exemplo, o campo IP DSCP.
É chamado assim porque, sob o mesmo rótulo no campo DSCP, são agregadas várias categorias de tráfego que esperam o mesmo comportamento em relação a si mesmas. Por exemplo, todas as sessões SIP serão agregadas em uma classe.
O número de possíveis classes de serviço e, portanto, padrões de comportamento, é limitado. Portanto, é impossível para cada categoria (ou mais ainda para o fluxo) separar uma classe separada - é necessário agregar. - Baseado em interface
Tudo o que chega a uma interface específica deve ser colocado em uma classe de tráfego. Por exemplo, sabemos com certeza que o servidor de banco de dados está conectado a essa porta e nada mais. E em outra estação de trabalho dos funcionários. - MultiField ( MF )
Analise os campos do cabeçalho do pacote - endereços IP, portas, endereços MAC. De um modo geral, campos arbitrários.
Por exemplo, todo o tráfego que vai para a sub-rede 10.127.721.0/24 na porta 5000 precisa ser marcado como tráfego, exigindo condicionalmente a 5ª classe de serviço.
O administrador determina o conjunto de classes de serviço que a rede pode fornecer e mapeia algum valor digital.
Na entrada do domínio DS, não confiamos em ninguém, portanto a classificação é realizada da segunda ou terceira maneira: com base nos endereços, protocolos ou interfaces, a classe de serviço e o valor digital correspondente são determinados.
Na saída do primeiro nó, esse dígito é codificado no campo DSCP do cabeçalho IP (ou outro campo da Classe de tráfego: Classe de tráfego MPLS, Classe de tráfego IPv6, Ethernet 802.1p) - ocorre uma observação.
É habitual confiar nessa rotulagem no domínio DS, portanto, os nós de trânsito usam o primeiro método de classificação (BA) - o mais simples. Nenhuma análise de título complicada, basta olhar para o número gravado.
Na junção de dois domínios, você pode classificar com base em uma interface ou MF, conforme descrito acima, ou pode confiar na marcação BA com reservas.
Por exemplo, confie em todos os valores, exceto 6 e 7, e reatribua 6 e 7 a 5.
Essa situação é possível quando o provedor conecta uma entidade legal que possui sua própria política de rotulagem. O provedor não se importa em salvá-lo, mas não deseja que o tráfego caia na classe em que recebe pacotes de protocolo de rede.
Agregação de comportamento
BA usa uma classificação muito simples - vejo um número - entendo a classe.
Então, qual é a figura? E em que campo está registrado?
- Classe de tráfego IPv6
- Classe de tráfego MPLS
- Ethernet 802.1p
A classificação é baseada principalmente no cabeçalho da comutação.
Eu chamo um cabeçalho pendular com base no qual o dispositivo determina para onde enviar o pacote para que fique mais próximo do destinatário.Ou seja, se um pacote IP chegar ao roteador, o cabeçalho IP e o campo DSCP serão analisados. Se o MPLS chegar, ele será analisado - MPLS Traffic Class.
Se um pacote Ethernet + VLAN + MPLS + IP chegou a um comutador L2 comum, o 802.1p será analisado (embora isso possa ser alterado).
Termos de Serviço IPv4
O campo QoS nos acompanha exatamente tanto quanto o IP. O campo TOS de oito bits - Tipo de serviço - deveria ter a prioridade do pacote.
Mesmo antes do advento do DiffServ, o
RFC 791 (
INTERNET PROTOCOL ) descreveu o campo da seguinte maneira:
Precedência de IP (IPP) + DTR + 00.
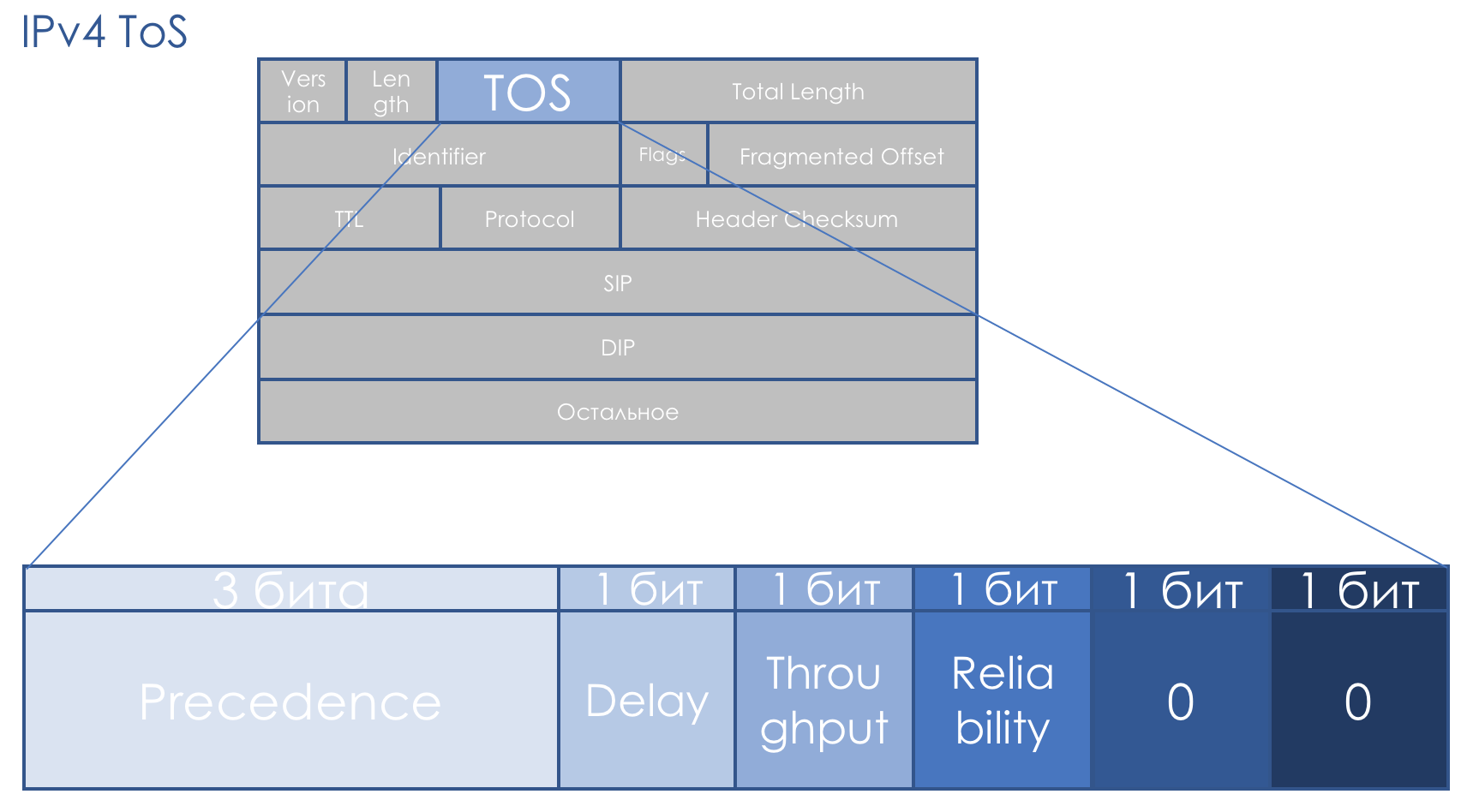
Ou seja, a prioridade do pacote vai, então os bits de exatidão para Atraso, Taxa de transferência, Confiabilidade (0 - sem requisitos, 1 - com requisitos).
Os dois últimos bits devem ser zero.
A prioridade determinou os seguintes valores ...111 - Controle de Rede
110 - Controle de rede
101 - CRITIC / ECP
100 - Substituição do Flash
011 - Flash
010 - Imediato
001 - Prioridade
000 - Rotina
Posteriormente na
RFC 1349 (
Tipo de serviço no Internet Protocol Suite ), o campo TOS foi ligeiramente redefinido:
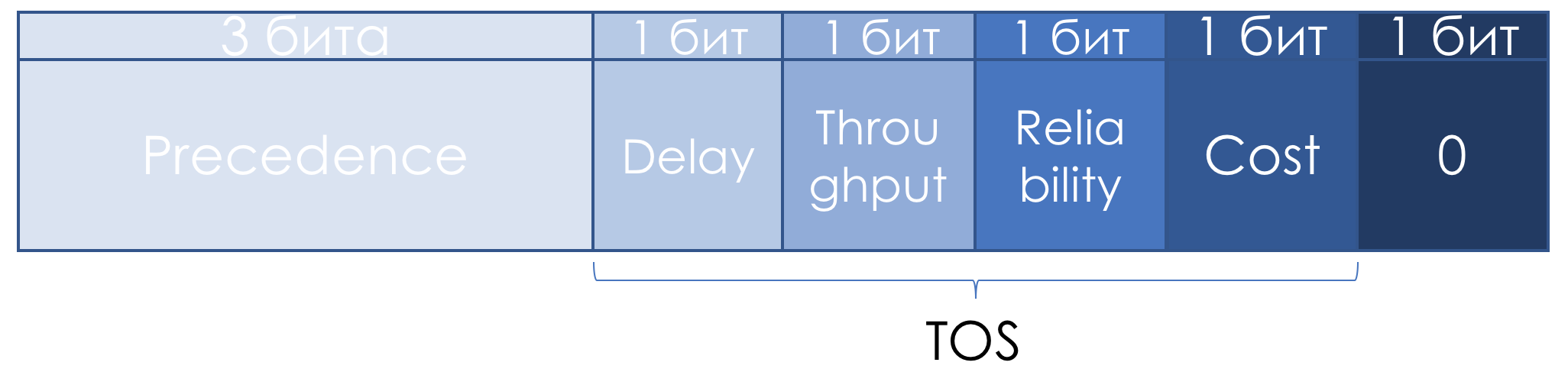
Os três bits à esquerda permaneceram Precedência de IP, os quatro seguintes se transformaram em TOS após adicionar o bit de custo.
Veja como ler as unidades nesses bits TOS:
- D - "minimizar atrasos",
- T - "maximizar a taxa de transferência",
- R - "maximizar a confiabilidade",
- C - "minimizar custos".
Descrições obscuras não contribuíram para a popularidade dessa abordagem.
Não havia uma abordagem sistemática da QoS ao longo de todo o caminho, não havia recomendações claras sobre como usar o campo prioritário, a descrição dos bits de atraso, taxa de transferência e confiabilidade era extremamente vaga.
Portanto, no contexto do DiffServ, o campo TOS foi novamente redefinido no
RFC 2474 (
Definição do campo de serviços diferenciados (campo DS) nos cabeçalhos IPv4 e IPv6 ):

Em vez dos bits IPP e DTRC, o campo de seis bits DSCP -
Ponto de Código de Serviços Diferenciados foi introduzido, os dois bits corretos não foram utilizados.
A partir desse momento, era o campo DSCP que deveria ter se tornado a principal marcação do DiffServ: um certo valor (código) é gravado nele, o qual no domínio DS caracteriza a classe específica de serviço exigida pelo pacote e sua prioridade de queda. Esta é a mesma figura.
O administrador pode usar todos os 6 bits do DSCP como desejar, compartilhando até um máximo de 64 classes de serviço.
No entanto, por uma questão de compatibilidade com a Precedência de IP, eles mantiveram o papel de Seletor de Classe nos três primeiros bits.
Ou seja, como no IPP, 3 bits do Class Selector permitem definir 8 classes.

No entanto, isso ainda não passa de um acordo que, dentro dos limites de seu domínio DS, o administrador pode facilmente ignorar e usar todos os 6 bits a seu critério.
Além disso, também observo que, de acordo com as recomendações da IETF, quanto maior o valor registrado no CS, mais exigente é esse tráfego para o serviço.
Mas isso não deve ser tomado como uma verdade inegável.
Se os três primeiros bits definirem a classe de tráfego, os próximos três serão usados para indicar a prioridade de queda de pacotes (
Precedência de queda ou
Prioridade de perda de pacote - PLP ).
Oito aulas - é muito ou pouco? À primeira vista, não basta - afinal, há um tráfego diferente na rede que se deseja distinguir cada protocolo por classe. No entanto, oito são suficientes para todos os cenários possíveis.
Para cada classe, você precisa definir um PHB que o manipule de maneira diferente de outras classes.
E com um aumento no divisor, o dividendo (recurso) não aumenta.
Não estou deliberadamente falando sobre os valores exatos de qual classe de tráfego eles descrevem, pois não há padrões e você pode usá-los formalmente a seu critério. Abaixo, mostrarei quais classes e seus valores correspondentes são recomendados.
Bits ECN ...O campo ECN de dois bits apareceu apenas no
RFC 3168 (
notificação explícita de congestionamento ). O campo foi definido com o bom propósito de informar explicitamente aos hosts finais que alguém estava enfrentando congestionamento ao longo do caminho.
Por exemplo, quando os pacotes ficam atrasados nas filas do roteador por um longo tempo e os preenchem, por exemplo, em 85%, ele altera o valor do ECN, informando ao host final o que precisa ser mais lento - algo como Pause Frames on Ethernet.
Nesse caso, o remetente deve reduzir a taxa de transmissão e reduzir a carga no nó afetado.
Ao mesmo tempo, teoricamente, o suporte desse campo por todos os nós de trânsito não é necessário. Ou seja, o uso do ECN não interrompe a rede que não o suporta.
O objetivo é bom, mas antes da aplicação na vida, o ECN não é particularmente encontrado. Atualmente, mega e hiperescalas olham para esses dois bits com
novo interesse .
O ECN é um dos mecanismos de prevenção de congestionamento descritos abaixo.
Prática de classificação DSCP
Não dói um pouco de prática.
O esquema é o mesmo.
Para começar, basta enviar uma solicitação ICMP:
Linkmeup_R1#ping ip 172.16.2.2 source 172.16.1.1 Type escape sequence to abort. Sending 5, 100-byte ICMP Echos to 172.16.2.2, timeout is 2 seconds: Packet sent with a source address of 172.16.1.1 !!!!! Success rate is 100 percent (5/5), round-trip min/avg/max = 1/1/1 ms
Linkmeup_R1. E0 / 0. pcapng
pcapngE agora com o valor DSCP definido.
Linkmeup_R1#ping ip 172.16.2.2 source 172.16.1.1 tos 184 Type escape sequence to abort. Sending 5, 100-byte ICMP Echos to 172.16.2.2, timeout is 2 seconds: Packet sent with a source address of 172.16.1.1 !!!!! Success rate is 100 percent (5/5), round-trip min/avg/max = 1/1/1 ms
O valor 184 é a representação decimal do binário 10111000. Desses, os primeiros 6 bits são 101110, ou seja, decimal 46, e essa é a classe EF.
Tabela de valores TOS padrão para popingushki conveniente ...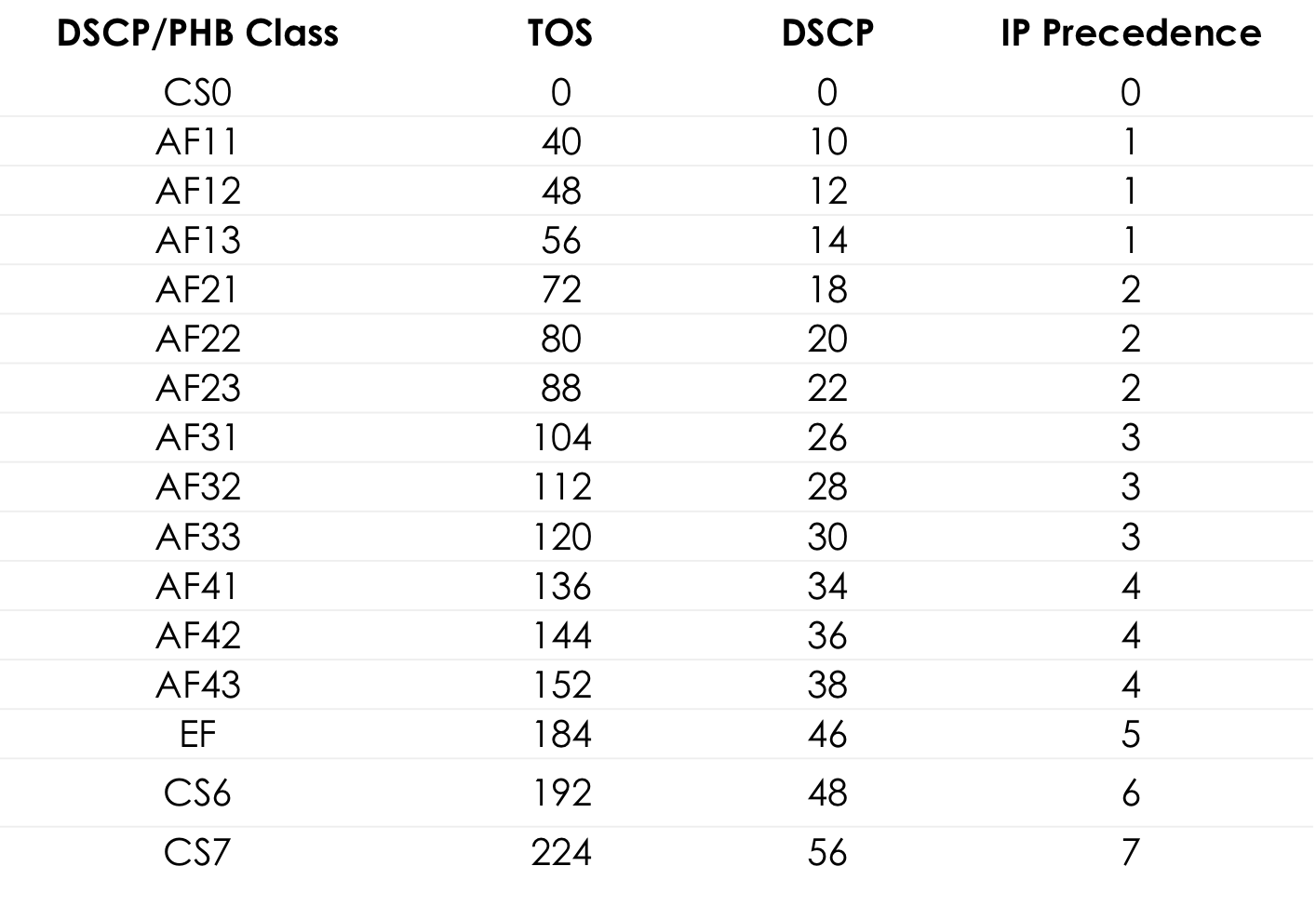 Mais detalhes
Mais detalhesAbaixo no texto no capítulo da
Recomendação da
IETF, vou lhe dizer de onde vieram esses números e nomes.
Linkmeup_R2. E0 / 0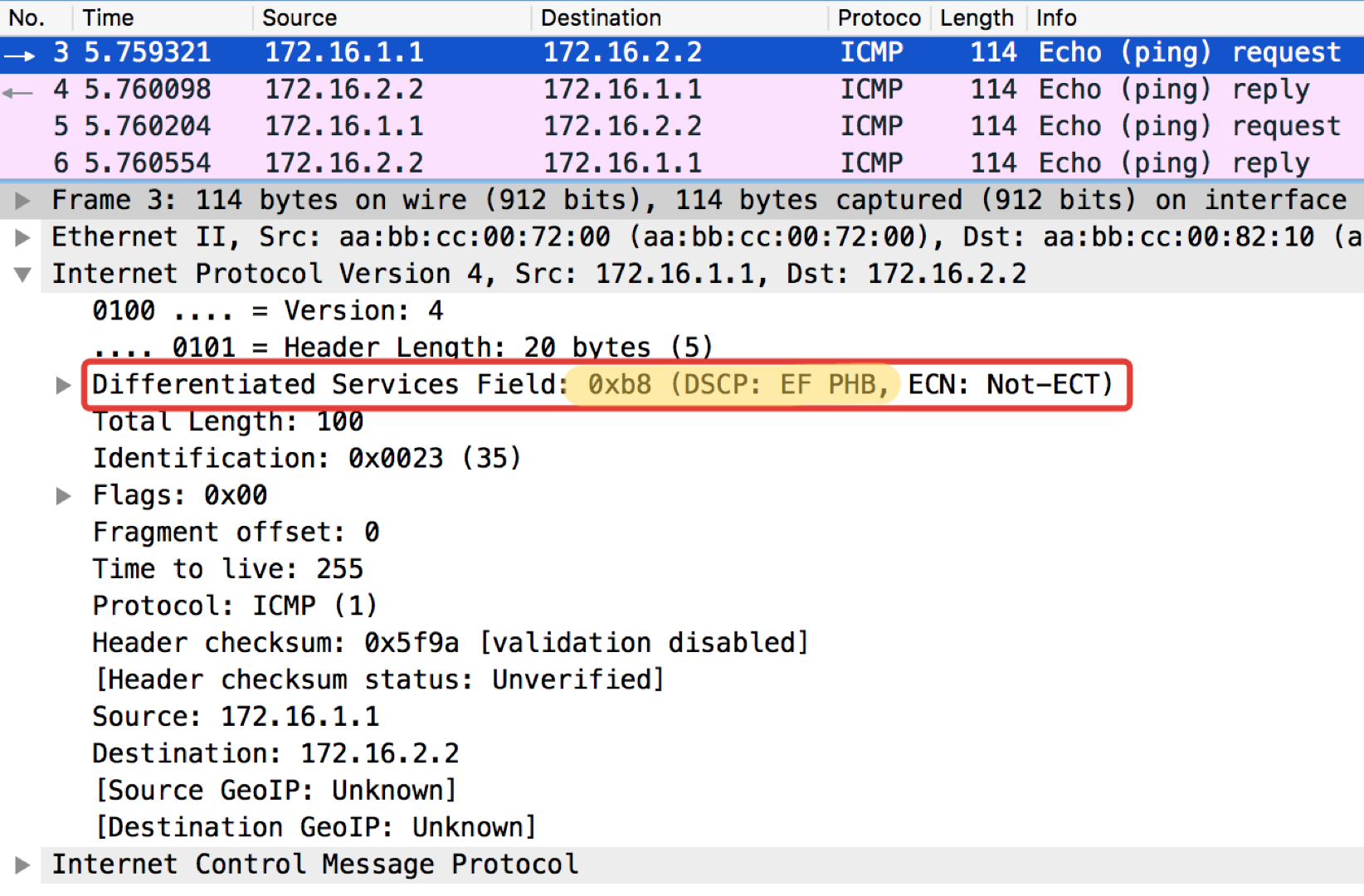 pcapng
pcapngUma observação curiosa: o destino de pingushka na resposta de eco do ICMP define o mesmo valor de classe que estava na solicitação de eco. Isso é lógico - se o remetente enviou um pacote com um certo nível de importância, obviamente ele deseja recebê-lo com garantia.
Linkmeup_R2. E0 / 0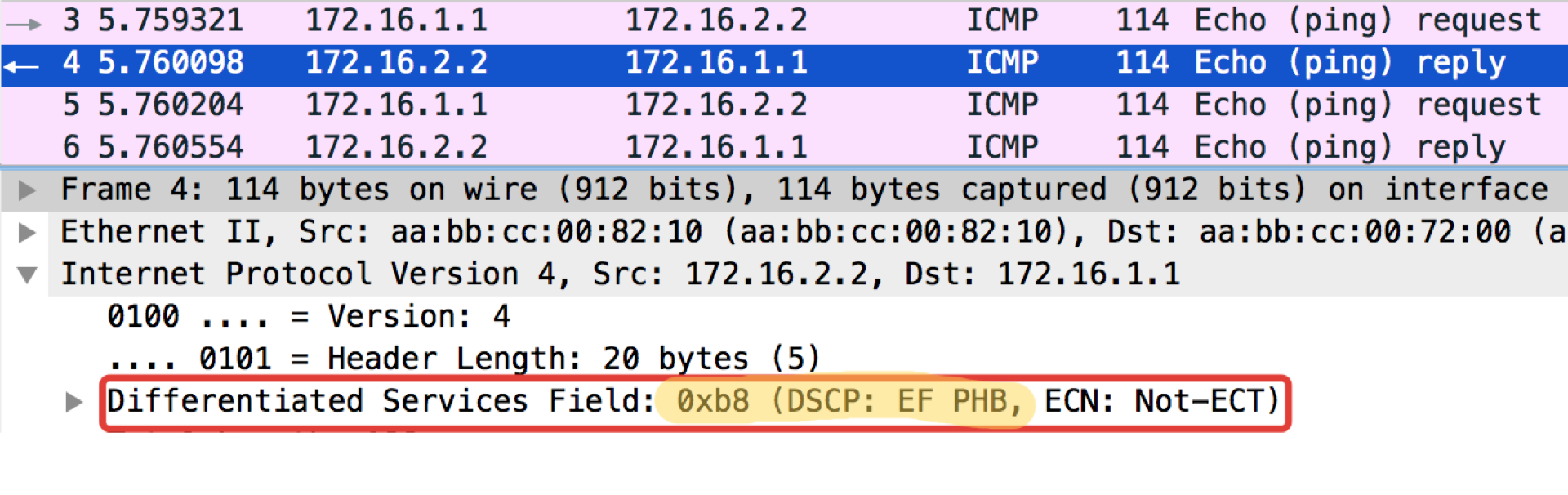 Arquivo de configuração de classificação DSCP.
Arquivo de configuração de classificação DSCP.Classe de tráfego IPv6
O IPv6 não é muito diferente em termos de QoS do que o IPv4. O campo de oito bits, chamado de classe de tráfego, também é dividido em duas partes. Os primeiros 6 bits - DSCP - desempenham exatamente o mesmo papel.

Sim, o Flow Label apareceu. Eles dizem que poderia ser usado para diferenciação adicional de classes. Mas essa idéia ainda não foi aplicada na vida.
Classe de tráfego MPLS
O conceito de DiffServ foi focado em redes IP com roteamento de cabeçalho IP. Isso é apenas azar - após 3 anos, eles publicaram a
RFC 3031 (
Multiprotocol Label Switching Architecture ). E o MPLS começou a assumir os provedores de rede.
DiffServ não pôde ser estendido a ele.
Por uma coincidência de sorte, um campo EXP de três bits foi colocado no MPLS para qualquer caso experimental. E, apesar de há muito tempo atrás na
RFC 5462 (
campo "EXP" renomeado para campo "Classe de tráfego" ) se tornar oficialmente o campo Classe de tráfego, por inércia é chamado IExPi.
Há um problema: o comprimento é de três bits, o que limita o número de valores possíveis a 9. Não é apenas pequeno, é três ordens binárias a menos que o DSCP.

Como a classe de tráfego MPLS geralmente é herdada do pacote IP do DSCP, temos um arquivamento com perda. Ou ... Não, você não quer saber disso ...
L-LSP . Usa uma combinação de classe de tráfego + valor do rótulo.
Geralmente, a situação é estranha - o MPLS foi projetado como um auxílio de IP para tomada de decisão rápida - o rótulo MPLS é instantaneamente detectado no CAM pelo Full Match, em vez do tradicional Longest Prefix Match. Ou seja, eles sabiam sobre IP e participavam da comutação, mas não previam um campo de prioridade normal.
De fato, já vimos acima que apenas os três primeiros bits do DSCP são usados para determinar a classe de tráfego, e os outros três bits são Precedência de descarte (ou PLP - Packet Loss Priority).
Portanto, em termos de classes de serviço, ainda temos uma correspondência 1: 1, perdendo apenas informações sobre a Precedência de descarte.
No caso do MPLS, a classificação como no IP pode ser baseada na interface, MF, IP DSCP ou MPLS da classe de tráfego.
Rotular significa escrever um valor no campo Classe de Tráfego do cabeçalho MPLS.
Um pacote pode conter vários cabeçalhos MPLS. Para fins DiffServ, apenas a parte superior é usada.
Há três cenários diferentes de remarcação ao mover um pacote de um segmento IP puro para outro pelo domínio MPLS: (este é apenas um trecho do
artigo ).
- Modo uniforme
- Modo de tubo
- Modo de tubo curto
Modos de Operação ...Modo uniforme
Este é um modelo completo de ponta a ponta.
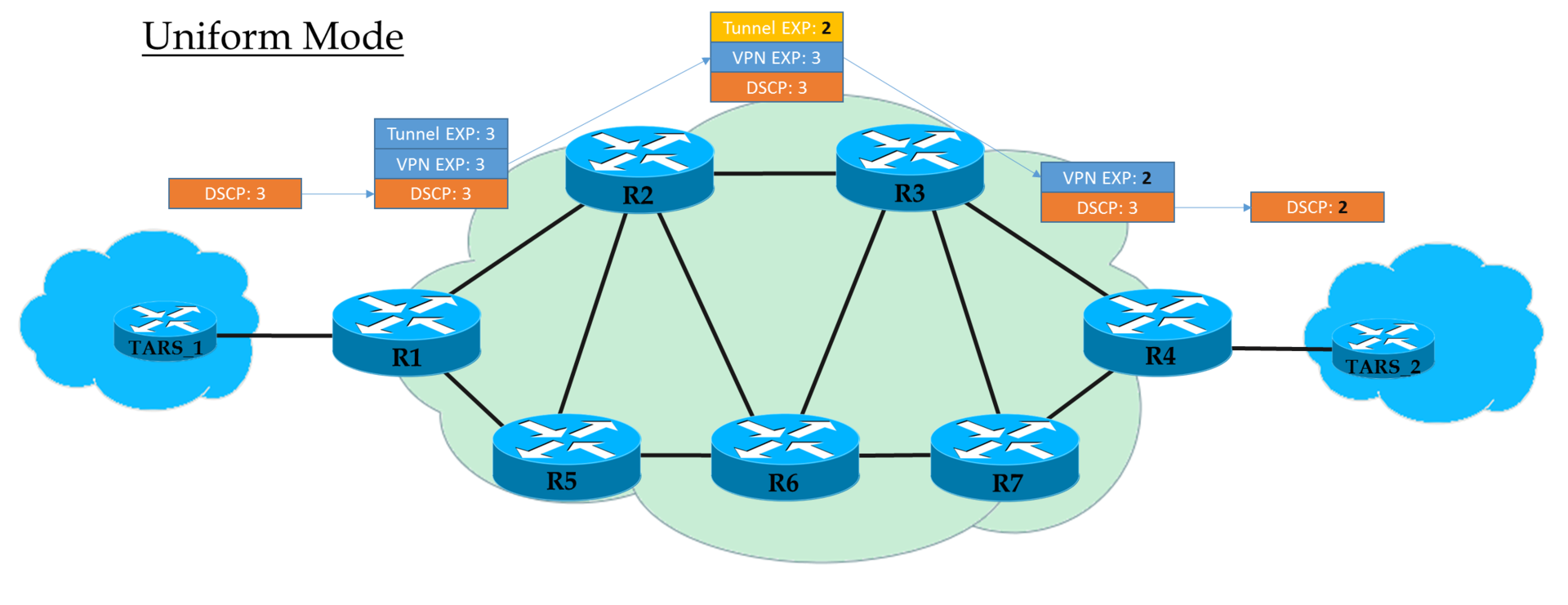
No Ingress PE, confiamos no IP DSCP e copiamos (
estritamente falando, exibição, mas por simplicidade diremos "copiar" ) seu valor no MPLS EXP (cabeçalhos de túnel e VPN). Na saída do Ingress PE, o pacote já é processado de acordo com o valor do campo EXP do cabeçalho MPLS superior.
Cada trânsito P também processa pacotes com base na EXP superior. Mas, ao mesmo tempo, ele pode alterá-lo se o operador desejar.
O penúltimo nó remove o rótulo de transporte (PHP) e copia o valor EXP para o cabeçalho da VPN. Não importa o que estava lá - no modo Uniforme, a cópia ocorre.
O PE de saída, removendo o rótulo da VPN, também copia o valor EXP para o IP DSCP, mesmo que algo mais esteja escrito lá.
Ou seja, se em algum lugar no meio o valor do rótulo EXP no cabeçalho do túnel tiver sido alterado, essa alteração será herdada pelo pacote IP.
Modo de tubo
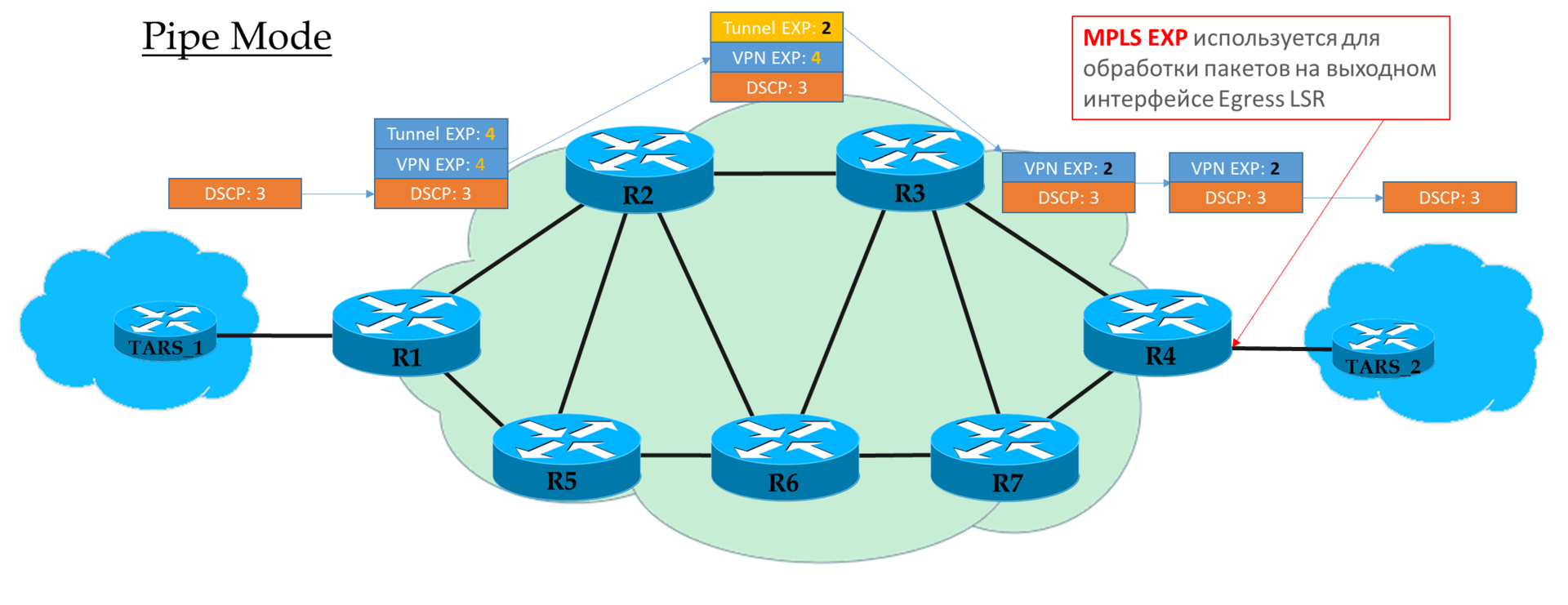
Se no Ingress PE decidirmos não confiar no valor DSCP, o valor EXP desejado pelo operador será inserido nos cabeçalhos MPLS.
Mas é aceitável copiar aqueles que estavam no DSCP. Por exemplo, você pode redefinir valores - copiar tudo até EF e mapear CS6 e CS7 para EF.
Cada trânsito P olha apenas para a EXP do cabeçalho MPLS superior.
O penúltimo nó remove o rótulo de transporte (PHP) e
copia o valor EXP para o cabeçalho da VPN.
O PE de saída processa primeiro o pacote com base no campo EXP no cabeçalho MPLS e somente o remove,
sem copiar o valor no DSCP.
Ou seja, independentemente do que aconteceu com o campo EXP nos cabeçalhos MPLS, o IP DSCP permanece inalterado.
Esse cenário pode ser usado quando o operador possui seu próprio domínio Diff-Serv e não deseja que o tráfego do cliente o influencie de alguma forma.
Modo de tubo curto
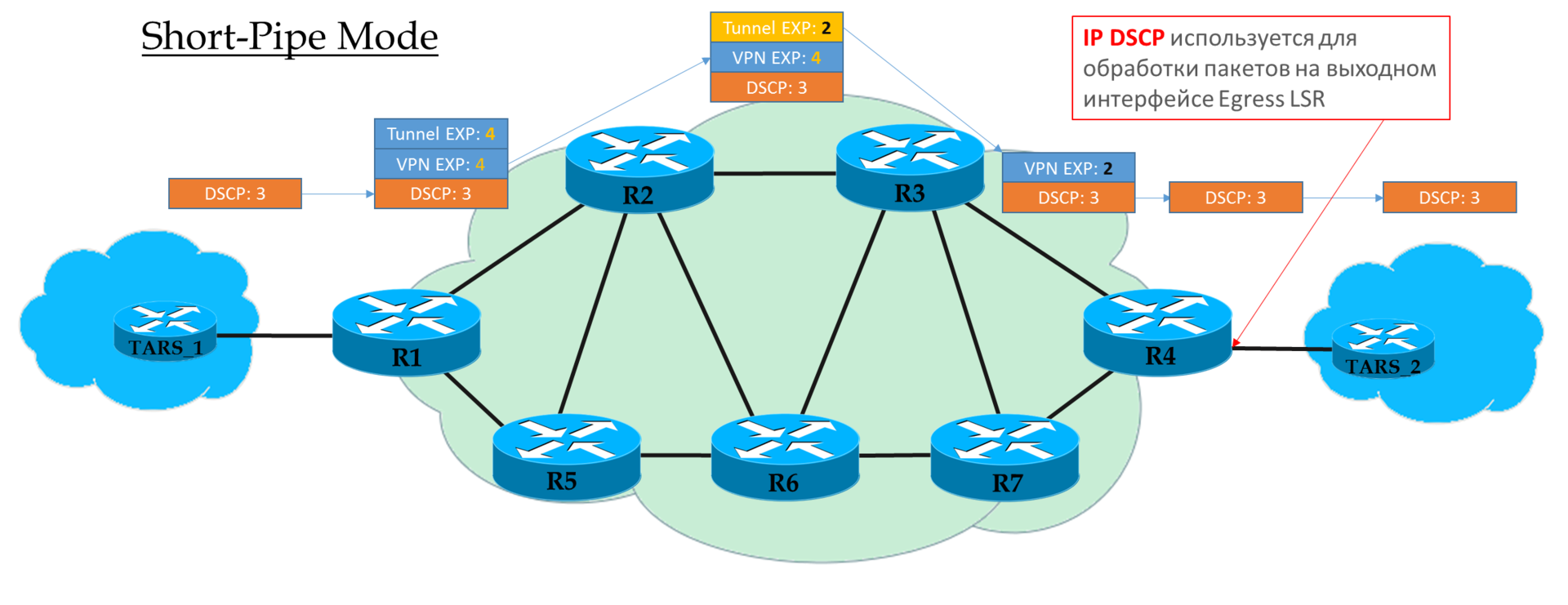
Você pode considerar esse modo como uma variação do modo Pipe. A única diferença é que, na saída da rede MPLS, o pacote é processado de acordo com seu campo IP DSCP, não MPLS EXP.
Isso significa que a prioridade do pacote na saída é determinada pelo cliente, não pelo operador.
O Ingress PE não confia nos pacotes de entrada IP DSCP
O Transit Ps olha no campo EXP do cabeçalho superior.
O penúltimo P remove o rótulo de transporte e copia o valor no rótulo da VPN.
O PE de saída remove primeiro o rótulo MPLS e depois processa o pacote nas filas.
Explicação do
Cisco .
Prática de classificação MPLS Traffic Class
O esquema é o mesmo:
O arquivo de configuração é o mesmo.No diagrama da rede linkmeup, há uma transição de IP para MPLS para Linkmeup_R2.
Vamos ver o que acontece com a marcação quando o ping faz
ping no ip 172.16.2.2 source 172.16.1.1 to 184 .
Linkmeup_R2. E0 / 0. pcapng
pcapngPortanto, vemos que o rótulo EF original no IP DSCP foi transformado no valor 5 do campo EXP MPLS (também é a classe de tráfego, lembre-se disso) do cabeçalho da VPN e do cabeçalho de transporte.
Aqui estamos testemunhando o modo uniforme de operação.
Ethernet 802.1p
A falta de um campo prioritário no 802.3 (Ethernet) é explicada pelo fato de o Ethernet ter sido originalmente planejado exclusivamente como uma solução para o segmento de LAN. Por um dinheiro modesto, você pode obter largura de banda excessiva, e o uplink sempre será um gargalo - não há nada com o que se preocupar em priorizar.
No entanto, logo ficou claro que a atratividade financeira do Ethernet + IP leva esse pacote aos níveis de backbone e WAN. E a coabitação em um segmento de LAN de torrents e telefonia precisa ser resolvida.
Felizmente, o 802.1q (VLAN) chegou a tempo para isso, no qual um campo de 3 bits (novamente) foi alocado para prioridades.
No plano DiffServ, este campo permite definir as mesmas 8 classes de tráfego.
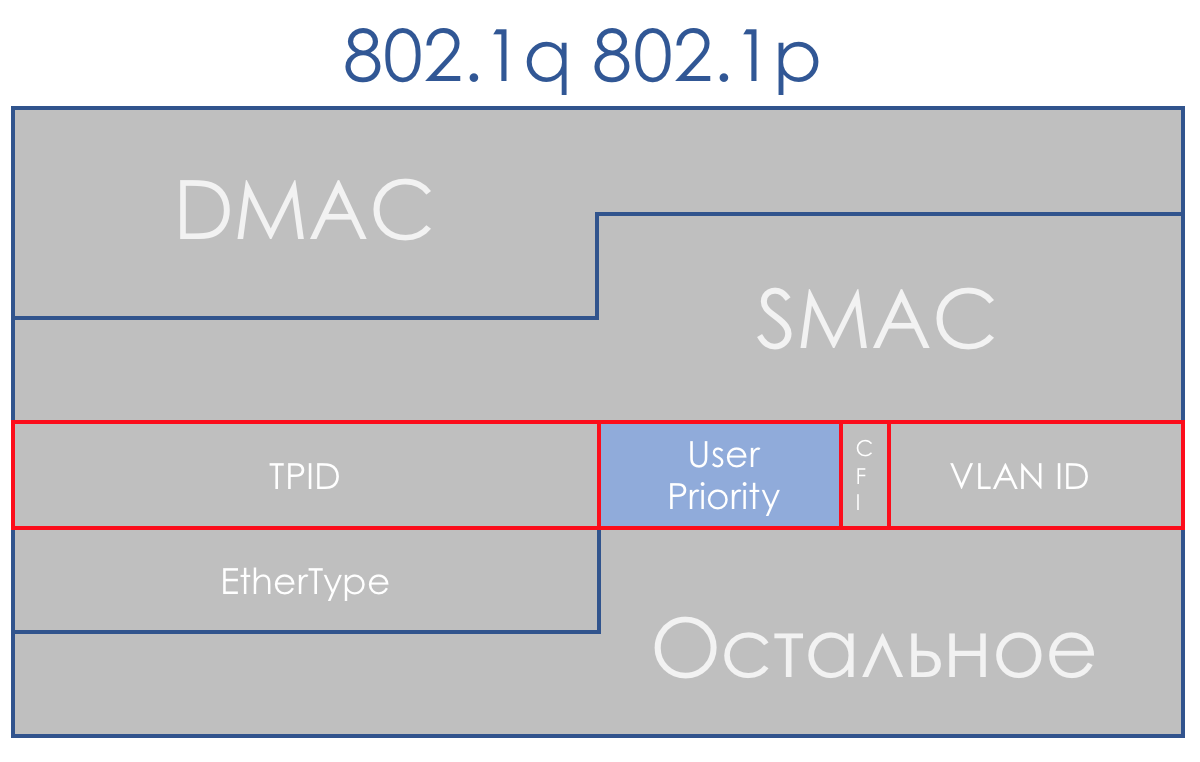
Ao receber um pacote, o dispositivo de rede do domínio DS, na maioria dos casos, leva em consideração o cabeçalho que ele usa para alternar:
- Comutador Ethernet - 802.1p
- Nó MPLS - Classe de tráfego MPLS
- Roteador IP - IP DSCP
Embora esse comportamento possa ser alterado: Classificação baseada em interface e campos múltiplos. E às vezes você pode até dizer explicitamente no campo CoS qual cabeçalho procurar.
Baseado em interface
Essa é a maneira mais fácil de classificar pacotes na testa. Tudo o que é derramado na interface especificada é marcado com uma determinada classe.
Em alguns casos, essa granularidade é suficiente, portanto, a interface é usada na vida.
Prática de classificação baseada em interface
O esquema é o mesmo:
A configuração de políticas de QoS no equipamento da maioria dos fornecedores é dividida em estágios.
- Primeiro, um classificador é definido:
class-map match-all TRISOLARANS_INTERFACE_CM
match input-interface Ethernet0/2
Tudo o que vem à interface Ethernet0 / 2.
- Em seguida, é criada uma política na qual o classificador e a ação necessária estão associados.
policy-map TRISOLARANS_REMARK class TRISOLARANS_INTERFACE_CM set ip dscp cs7
Se o pacote atender ao classificador TRISOLARANS_INTERFACE_CM, escreva CS7 no campo DSCP.
Aqui estou à frente de mim mesmo usando CS7 obscuro e depois EF, AF. Abaixo, você pode ler sobre essas abreviações e acordos aceitos. Enquanto isso, basta saber que existem classes diferentes com diferentes níveis de serviço.
- E o último passo é aplicar a política à interface:
interface Ethernet0/2 service-policy input TRISOLARANS_REMARK
Aqui, o classificador é um pouco redundante, o que verificará se o pacote chegou à interface e0 / 2, onde aplicamos a política. Pode-se escrever como qualquer:
class-map match-all TRISOLARANS_INTERFACE_CM match any
No entanto, a política pode realmente ser aplicada no vlanif ou na interface de saída, portanto é possível.
Execute o ping usual em 172.16.2.2 (Trisolaran2) com Trisolaran1:
E no dump entre Linkmeup_R1 e Linkmeup_R2, veremos o seguinte:
 pcapngClassificação baseada em interface do arquivo de configuração.
pcapngClassificação baseada em interface do arquivo de configuração.Campo múltiplo
O tipo mais comum de classificação na entrada do domínio DS. Não confiamos na rotulagem existente e, com base nos cabeçalhos dos pacotes, atribuímos uma classe.
Geralmente, essa é uma maneira de "ativar" a QoS, no caso em que os remetentes não marcam.
Uma ferramenta bastante flexível, mas ao mesmo tempo complicada - você precisa criar regras difíceis para cada classe. Portanto, dentro do domínio DS, BA é mais relevante.
Prática de classificação MF
O esquema é o mesmo:
A partir dos exemplos práticos acima, pode-se ver que os dispositivos de rede, por padrão, confiam na rotulagem dos pacotes recebidos.
Isso é bom dentro do domínio do DS, mas não é aceitável no ponto de entrada.
E agora não vamos confiar cegamente? No
Linkmeup_R2, o ICMP será rotulado como EF (apenas por exemplo), TCP como AF12 e todo o resto é CS0.
Essa será a classificação MF (Multi-Field).
- O procedimento é o mesmo, mas agora faremos a correspondência de ACLs que desengatam as categorias de tráfego necessárias; portanto, primeiro as criamos.
No Linkmeup_R2:
ip access-list extended TRISOLARANS_ICMP_ACL permit icmp any any ip access-list extended TRISOLARANS_TCP_ACL permit tcp any any ip access-list extended TRISOLARANS_OTHER_ACL permit ip any any
- Em seguida, definimos os classificadores:
class-map match-all TRISOLARANS_TCP_CM match access-group name TRISOLARANS_TCP_ACL class-map match-all TRISOLARANS_OTHER_CM match access-group name TRISOLARANS_OTHER_ACL class-map match-all TRISOLARANS_ICMP_CM match access-group name TRISOLARANS_ICMP_ACL
- E agora definimos as regras de observação na política:
policy-map TRISOLARANS_ADMISSION_CONTROL class TRISOLARANS_ICMP_CM set ip dscp ef class TRISOLARANS_TCP_CM set ip dscp af11 class TRISOLARANS_OTHER_CM set ip dscp default
- E penduramos a política na interface. Na entrada, respectivamente, porque a decisão deve ser tomada na entrada da rede.
interface Ethernet0/1 service-policy input TRISOLARANS_ADMISSION_CONTROL
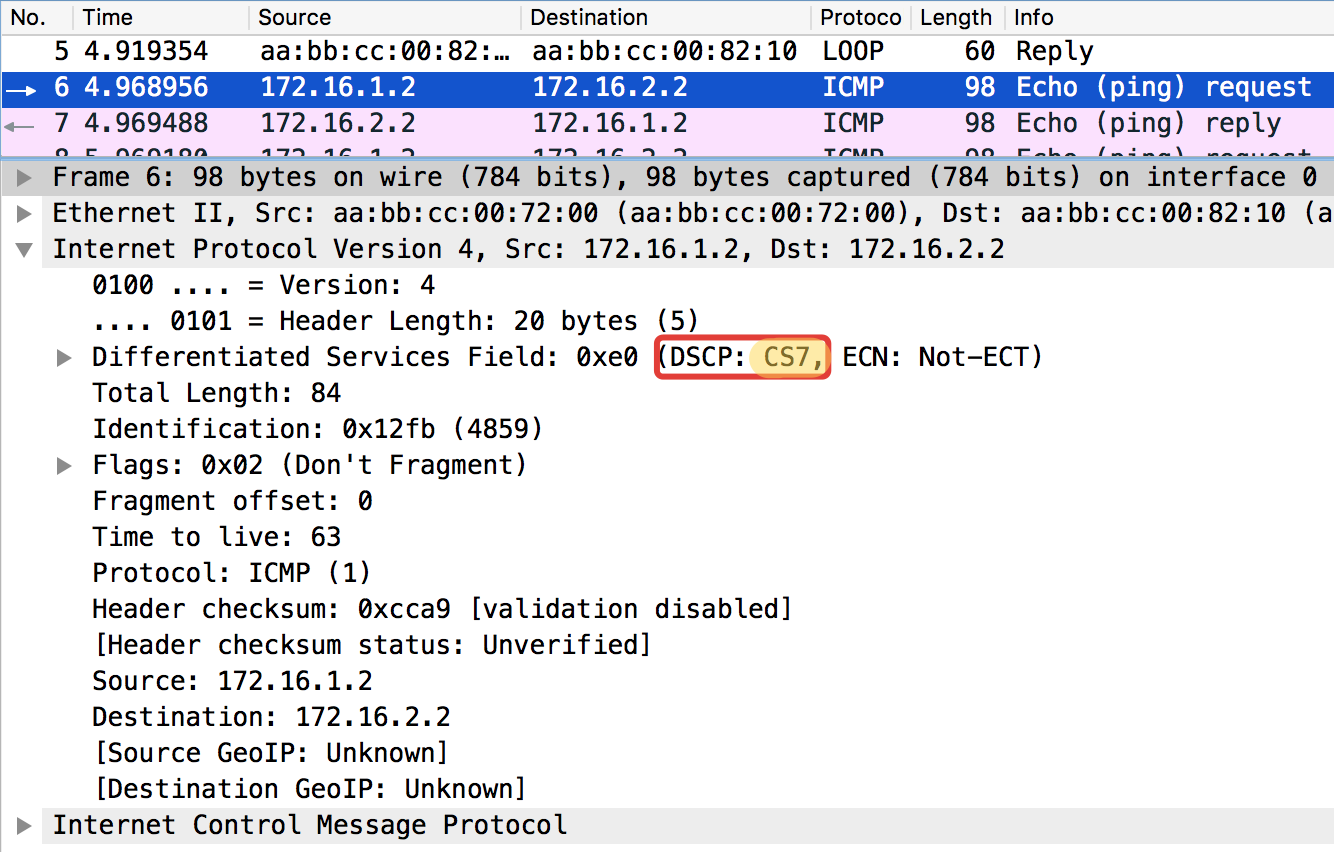
Teste de ICMP do hospedeiro final Trisolaran1. Não especificamos conscientemente a classe - o padrão é 0.
Já removi a política com o Linkmeup_R1, portanto o tráfego vem com a marcação CS0, não CS7.
Aqui estão dois dumps nas proximidades, com Linkmeup_R1 e Linkmeup_R2:
Linkmeup_R1. E0 / 0.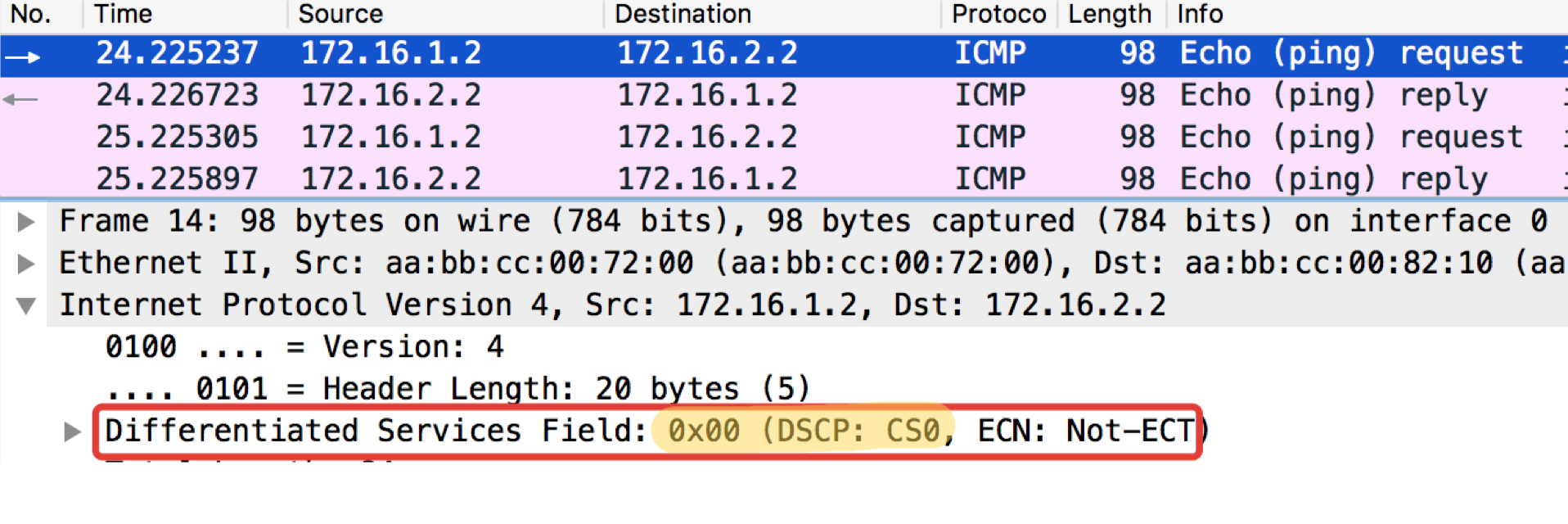 pcapngLinkmeup_R2. E0 / 0.
pcapngLinkmeup_R2. E0 / 0.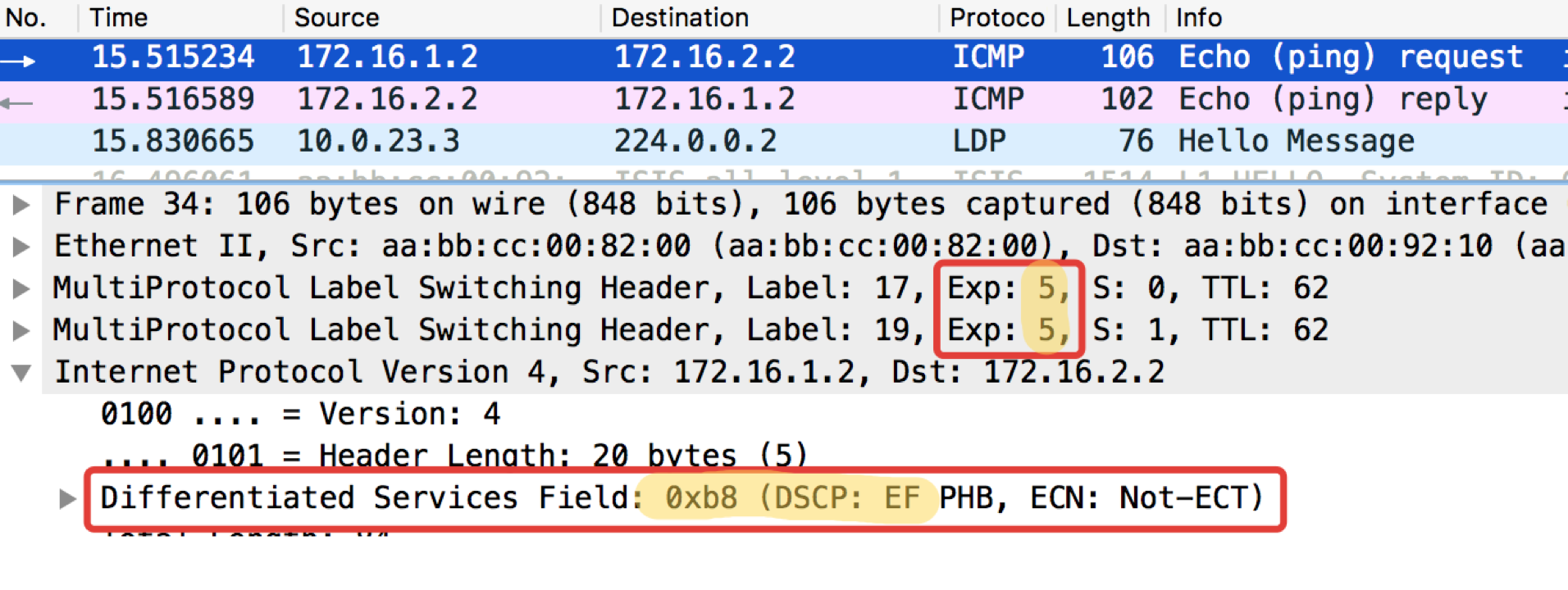 pcapng
pcapngPode-se observar que, após os classificadores e a nova identificação no Linkmeup_R2 nos pacotes ICMP, não apenas o DSCP mudou para EF, mas a MPLS Traffic Class tornou-se igual a 5.
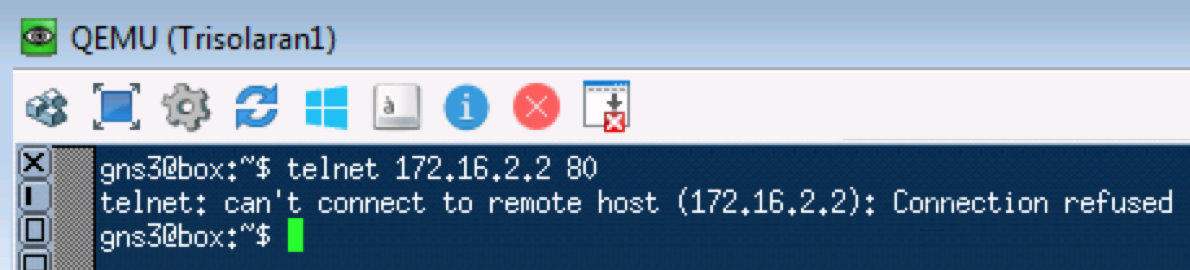
Um teste semelhante com o telnet 172.16.2.2. 80 - então verifique o TCP:
 Linkmeup_R1. E0 / 0.
Linkmeup_R1. E0 / 0. pcapngLinkmeup_R2. E0 / 0.
pcapngLinkmeup_R2. E0 / 0.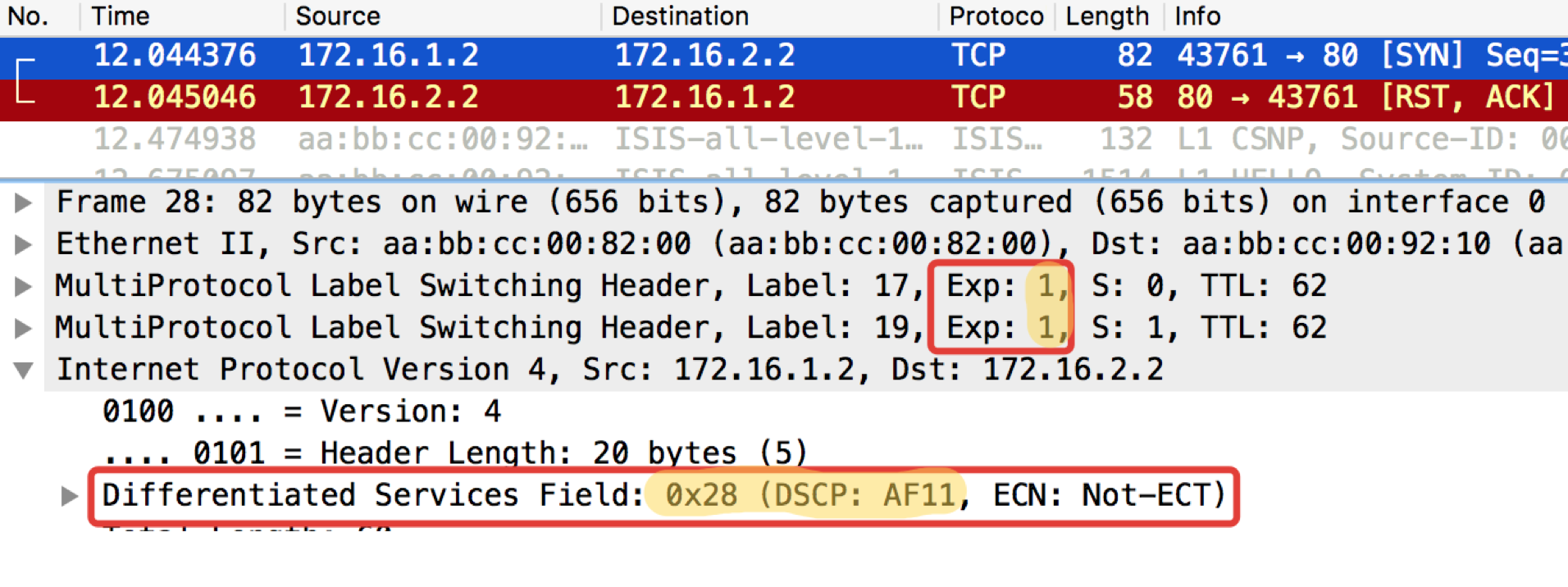 pcapng
pcapngLEIA - O que é necessário esperar. O TCP é transmitido como AF11.
O próximo teste testará o UDP, que deve passar para CS0 de acordo com nossos classificadores. Usaremos o iperf para isso (leve-o para o Linux Tiny Core via Apps). No lado remoto
iperf3 -s - inicie o servidor, no local
iperf3 -c -u -t1 - cliente (
-c ), protocolo UDP (
-u ), teste por 1 segundo (
-t1 ).
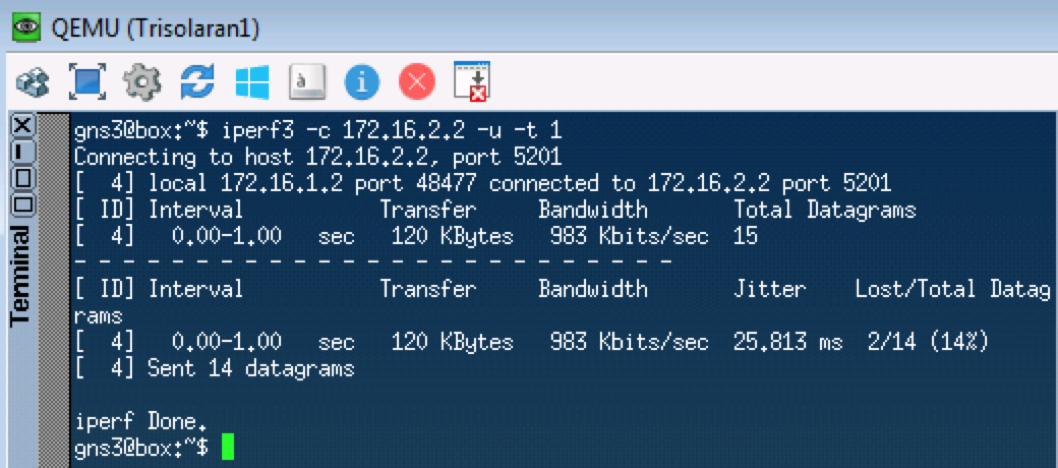 Linkmeup_R1. E0 / 0.
Linkmeup_R1. E0 / 0.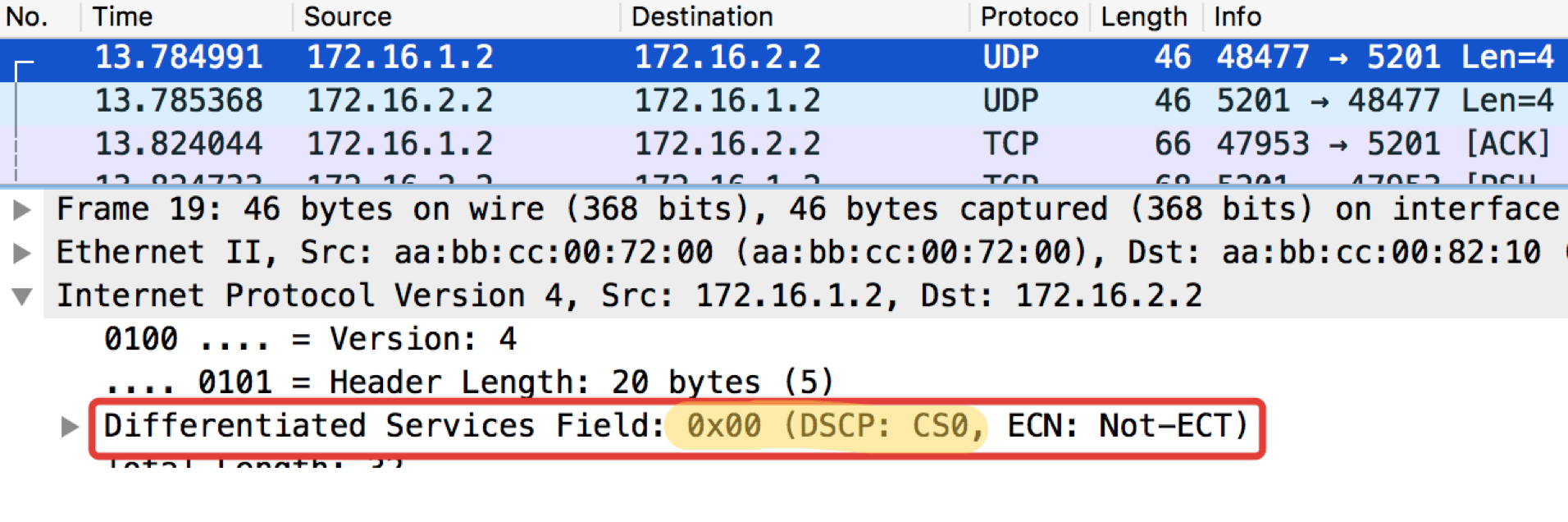 pcapngLinkmeup_R2. E0 / 0
pcapngLinkmeup_R2. E0 / 0 pcapng
pcapngA partir de agora, tudo o que vier a essa interface será classificado de acordo com as regras configuradas.
Marcando dentro do dispositivo
Mais uma vez: na entrada para a classificação do domínio DS pode ocorrer MF, Interface-based ou BA.
Entre os nós do domínio DS, o pacote no cabeçalho carrega um sinal sobre a classe de serviço necessária e é classificado pela BA.
Independentemente do método de classificação, depois dele, o pacote recebe uma classe interna no dispositivo, de acordo com o qual é processado. O cabeçalho é removido e o pacote vazio (sem) viaja para a saída.
E na saída, a classe interna é convertida no campo CoS do novo cabeçalho.
Ou seja, Título 1 ⇒ Classificação ⇒ Classe interna de serviço ⇒ Título 2.
Em alguns casos, você precisa exibir o campo de cabeçalho de um protocolo no campo de cabeçalho de outro, por exemplo, DSCP na classe de tráfego.
Isso acontece apenas através da marcação interna intermediária.
Por exemplo, DSCP Header ⇒ Classificação ⇒ Internal Service Class ⇒ Traffic Class Header.
Formalmente, as classes internas podem ser chamadas como você quiser, ou simplesmente numeradas, e elas possuem apenas uma determinada fila atribuída a elas.
Na profundidade em que mergulhamos neste artigo, não importa como eles são chamados, é importante que um modelo de comportamento específico seja associado a valores específicos de campos de QoS.
Se estamos falando de implementações específicas de QoS, o número de classes de serviço que o dispositivo pode fornecer não passa do número de filas disponíveis. Freqüentemente, existem oito deles (sob a influência do IPP ou, às vezes, por acordo não escrito). No entanto, dependendo do fornecedor, dispositivo, placa, eles podem ser mais ou menos.
Ou seja, se houver quatro filas, as classes de serviço simplesmente não fazem sentido para fazer mais do que quatro.
Vamos falar sobre isso com mais detalhes no capítulo hardware.
Se você realmente quer um pouco de especificidade ...As tabelas abaixo podem parecer convenientes à primeira vista no relacionamento entre os campos de QoS e as classes internas, mas são um tanto enganosas ao chamar os nomes das classes PHB. Ainda assim, PHB é o tipo de modelo de comportamento atribuído ao tráfego de uma determinada classe, cujo nome, grosso modo, é arbitrário.
Portanto, consulte as tabelas abaixo com uma parcela de ceticismo (portanto, abaixo do spoiler).
No exemplo da Huawei . Aqui, Service-Class é a classe muito interna do pacote.
Ou seja, se BA for classificado na entrada, os valores DSCP serão convertidos nos valores correspondentes de Classe de serviço e Cor.

Vale a pena prestar atenção ao fato de que muitos valores DSCP não são usados e os pacotes com essas marcações são realmente processados como BE.
Aqui está uma tabela de correspondência reversa que mostra quais valores de DSCP serão definidos para o tráfego quando a saída for remarcada.

Observe que apenas o AF tem uma gradação de cores. BE, EF, CS6, CS7 - tudo apenas verde.
Esta é uma tabela para converter os campos IPP, MPLS Traffic Class e 802.1p Ethernet em classes de serviço internas.

E de volta.

Observe que qualquer informação sobre prioridade de descarte geralmente é perdida aqui.
Deve ser repetido - este é apenas um exemplo específico de correspondências padrão do fornecedor selecionado
aleatoriamente . Para outros, isso pode ser diferente. Os administradores podem configurar completamente diferentes classes de serviços e PHBs em suas redes.
Em termos de PHB, não há absolutamente nenhuma diferença no que é usado para classificação - DSCP, Traffic Class, 802.1p.
Dentro do dispositivo, eles se transformam em classes de tráfego definidas pelo administrador da rede.
Ou seja, todas essas marcações são uma maneira de dizer aos vizinhos qual classe de serviço eles devem atribuir a este pacote. É como a Comunidade BGP, que não significa nada por si só, até que a política para interpretá-los seja definida na rede.
Recomendações da IETF (categorias de tráfego, classes de serviço e comportamentos)
Os padrões não padronizam em absoluto quais classes de serviço específicas devem existir, como classificá-las e rotulá-las e qual PHB aplicar a elas.
Isso está à mercê de fornecedores e administradores de rede.
Temos apenas 3 bits - usamos como queremos.
Isso é bom:
- Cada peça de ferro (fornecedor) escolhe independentemente quais mecanismos usar para PHB - sem sinalização, sem problemas de compatibilidade.
- O administrador de cada rede pode distribuir de forma flexível o tráfego entre diferentes classes, escolher as próprias classes e o PHB correspondente.
Isso é ruim:
- Nos limites dos domínios do DS, surgem problemas de conversão.
- Em condições de total liberdade de ação - alguns estão na floresta, outros são demônios.
Portanto, a IETF em 2006 publicou um manual de treinamento sobre como abordar a diferenciação de serviço:
RFC 4594 (
Diretrizes de configuração para as classes de serviço DiffServ ).
A seguir, é apresentado um breve resumo desta RFC.
Modelos de comportamento (PHB)
DF - Encaminhamento padrãoRemessa padrão.Se um modelo de tráfego não receber um modelo de comportamento específico, ele será processado usando o encaminhamento padrão.
Este é o melhor esforço - o dispositivo fará todo o possível, mas não garante nada. Quedas, desordens, atrasos imprevisíveis e instabilidade flutuante são possíveis, mas isso não é exato.
Este modelo é adequado para aplicativos pouco exigentes, como downloads de correio ou arquivo.
A propósito, há PHB e ainda menos definido -
um esforço menor .
AF - Encaminhamento garantidoExpedição garantida.Este é um BE melhorado. Algumas garantias aparecem aqui, por exemplo, bandas. Quedas e atrasos flutuantes ainda são possíveis, mas em uma extensão muito menor.
O modelo é adequado para multimídia: streaming, videoconferência, jogos online.
RFC 2597 (
Grupo PHB de Encaminhamento Assegurado ).
EF - Encaminhamento aceleradoRemessa de emergência.Todos os recursos e prioridades correm aqui. Este é um modelo para aplicativos que não precisam de perdas, pequenos atrasos, instabilidade estável, mas não são gananciosos para a banda. Como, por exemplo, telefonia ou serviço de emulação de fio (CES - Circuit Emulation Service).
Perdas, desordens e atrasos flutuantes na FE são extremamente improváveis.
RFC 3246 (
um PHB de encaminhamento acelerado ).
CS - Seletor de ClassesEsses são comportamentos projetados para manter a compatibilidade com a precedência de IP em redes capazes de DS.
As seguintes classes existem no IPP: CS0, CS1, CS2, CS3, CS4, CS5, CS6, CS7.
Nem sempre para todos eles existe um PHB separado, geralmente existem dois ou três, e o restante é simplesmente traduzido para a classe DSCP mais próxima e obtém o PHB correspondente.
Por exemplo, um pacote rotulado CS 011000 pode ser classificado como 011010.
Do CS, certamente apenas CS6, CS7, que são recomendados para o NCP - Network Control Protocol e requerem um PHB separado, são preservados no equipamento.
Assim como a EF, o PHB CS6.7 foi desenvolvido para classes com requisitos de latência e perda muito altos, mas que são tolerantes à discriminação de banda.
A tarefa do PHB para CS6.7 é fornecer um nível de serviço que elimine quedas e atrasos, mesmo em caso de sobrecarga extrema da interface, chip e filas.
É importante entender que o PHB é um conceito abstrato - e, de fato, eles são implementados através de mecanismos disponíveis em equipamentos reais.
Assim, o mesmo PHB definido no domínio DS pode diferir no Juniper e na Huawei.
Além disso, um único PHB não é um conjunto estático de ações; por exemplo, um PHB AF pode consistir em várias opções que diferem no nível de garantias (banda, atrasos aceitáveis).
Classes de serviço
A IETF cuidou dos administradores e identificou as principais categorias de aplicativos e suas classes de serviço.
Não estarei detalhado aqui, basta inserir algumas placas desta RFC de orientação.Categorias de aplicativos: Requisitos para características da rede:
Requisitos para características da rede: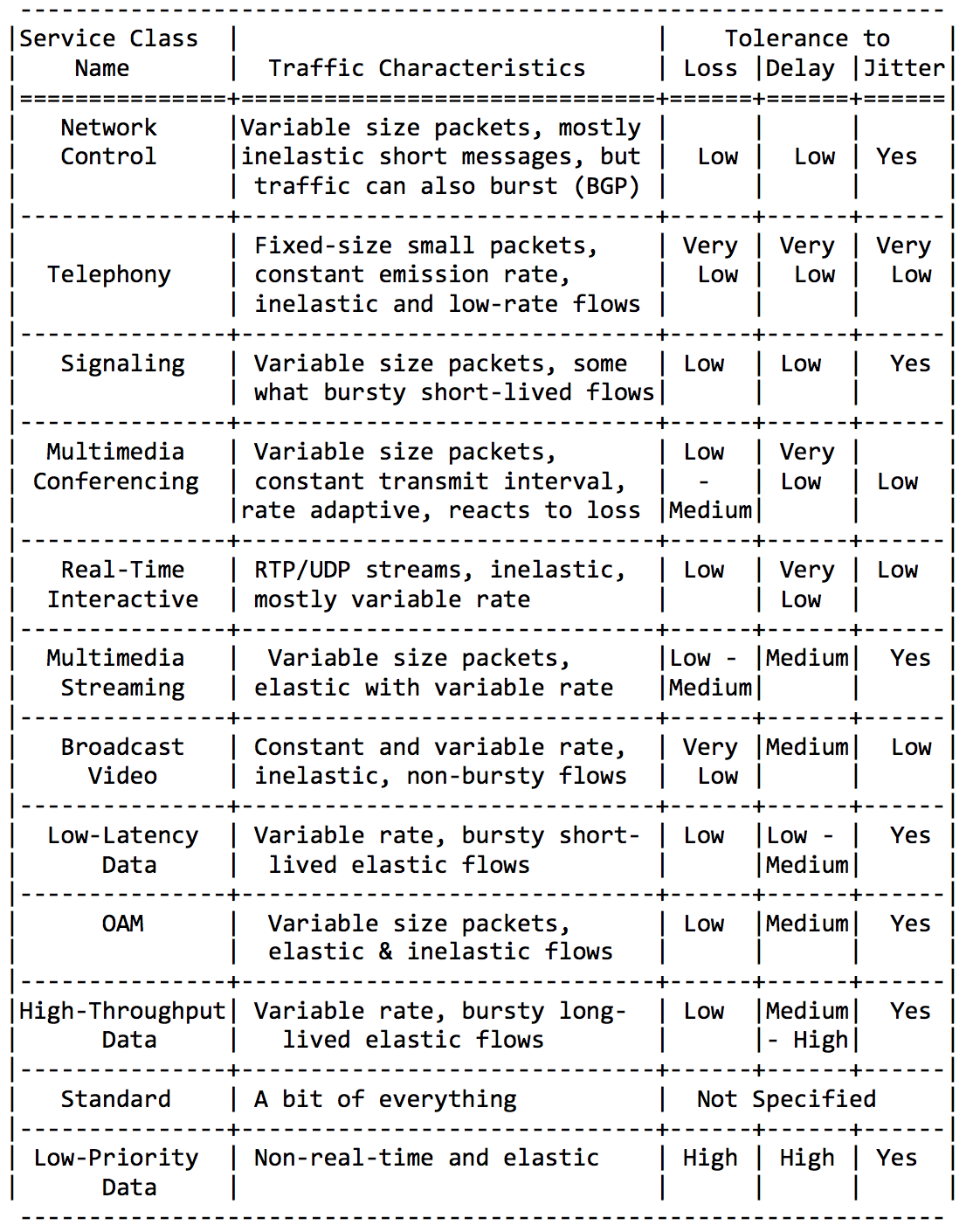 e, finalmente, nomes de classes recomendados e valores DSCP correspondentes:
e, finalmente, nomes de classes recomendados e valores DSCP correspondentes: combinando as classes acima de maneiras diferentes (para se ajustarem às 8 disponíveis), você pode obter soluções de QoS para redes diferentes.Talvez o mais comum seja o seguinte: a
combinando as classes acima de maneiras diferentes (para se ajustarem às 8 disponíveis), você pode obter soluções de QoS para redes diferentes.Talvez o mais comum seja o seguinte: a classe DF (ou BE) marca tráfego absolutamente pouco exigente - recebe atenção residual.O PHB AF atende às classes AF1, AF2, AF3, AF4. Todos eles precisam fornecer uma faixa, em detrimento de atrasos e perdas. As perdas são controladas pelos bits de Drop Precedence, e é por isso que são chamados AFxy, onde x é a classe de serviço e y é Drop Precedence.A EF precisa de algum tipo de garantia mínima de banda, mas mais importante - uma garantia de atrasos, instabilidade e nenhuma perda.O CS6, o CS7 exigem ainda menos largura de banda, porque esse é um conjunto de pacotes de serviços nos quais ainda são possíveis explosões (atualização do BGP, por exemplo), mas perdas e atrasos são inaceitáveis - qual é o uso do BFD com um temporizador de 10 ms se o Hello travar Filas de 100 ms?Ou seja, 4 das 8 aulas disponíveis foram ministradas sob AF.E, apesar de geralmente fazerem exatamente isso, repito que essas são apenas recomendações e nada impede que três classes no seu domínio DS atribuam EF e apenas duas à AF.
classe DF (ou BE) marca tráfego absolutamente pouco exigente - recebe atenção residual.O PHB AF atende às classes AF1, AF2, AF3, AF4. Todos eles precisam fornecer uma faixa, em detrimento de atrasos e perdas. As perdas são controladas pelos bits de Drop Precedence, e é por isso que são chamados AFxy, onde x é a classe de serviço e y é Drop Precedence.A EF precisa de algum tipo de garantia mínima de banda, mas mais importante - uma garantia de atrasos, instabilidade e nenhuma perda.O CS6, o CS7 exigem ainda menos largura de banda, porque esse é um conjunto de pacotes de serviços nos quais ainda são possíveis explosões (atualização do BGP, por exemplo), mas perdas e atrasos são inaceitáveis - qual é o uso do BFD com um temporizador de 10 ms se o Hello travar Filas de 100 ms?Ou seja, 4 das 8 aulas disponíveis foram ministradas sob AF.E, apesar de geralmente fazerem exatamente isso, repito que essas são apenas recomendações e nada impede que três classes no seu domínio DS atribuam EF e apenas duas à AF.
Resumo da Classificação
Na entrada de um nó, um pacote é classificado com base em uma interface, MF ou sua rotulagem (BA).Rotular é o valor dos campos DSCP no IPv4, na Classe de Tráfego no IPv6 e no MPLS ou 802.1p no 802.1q.Existem 8 classes de serviço que agregam várias categorias de tráfego. Cada classe recebe seu próprio PHB, atendendo aos requisitos da classe.De acordo com as recomendações da IETF, são distinguidas as seguintes classes de serviço: CS1, CS0, AF11, AF12, AF13, AF21, CS2, AF22, AF23, CS3, AF31, AF32, AF33, CS33, CS41, AF41, AF42, AF43, CS5, EF, CS6, CS7 na crescente importância do tráfego.Nelas, você pode escolher uma combinação de 8, que pode realmente ser codificada nos campos CoS.A combinação mais comum: CS0, AF1, AF2, AF3, AF4, EF, CS6, CS7 com 3 gradações de cores para AF.A cada classe é atribuído um PHB, dos quais existem 3 - Encaminhamento padrão, Encaminhamento garantido, Encaminhamento acelerado em ordem crescente de gravidade. Um pouco à parte é o seletor de classe PHB. Cada PHB pode variar de acordo com os parâmetros da ferramenta, mas mais sobre isso posteriormente.
Em uma rede descarregada, a QoS não é necessária, disseram eles. Quaisquer problemas de QoS são resolvidos expandindo os links, disseram eles. Com Ethernet e DWDM, nunca enfrentamos congestionamentos de linha, disseram eles.Eles são aqueles que não entendem o que é QoS.Mas a realidade atinge a VPN no ILV.- Nem em todo lugar há óptica. RRL é a nossa realidade. Às vezes, no momento do acidente (e não apenas) no estreito link de rádio, deseja rastrear todo o tráfego da rede.
- Explosões de tráfego são a nossa realidade. Explosões de tráfego a curto prazo enfileiram-se facilmente, forçando a queda dos pacotes muito necessários.
- Telefonia, videoconferência, jogos online são a nossa realidade. Se a fila estiver pelo menos um pouco ocupada, os atrasos começarão a dançar.
Na minha prática, houve exemplos em que a telefonia se transformou em código Morse em uma rede carregada em não mais de 40%. Apenas marcá-lo novamente na EF resolveu o problema momentaneamente.
É hora de lidar com ferramentas que permitem fornecer serviços diferentes para diferentes classes.
Ferramentas PHB
Na verdade, existem apenas três grupos de ferramentas de QoS que manipulam ativamente os pacotes:- Prevenção de congestionamento - o que fazer para não ser ruim.
- Gerenciamento de congestionamento - o que fazer quando já estiver ruim.
- Limite de taxa - como não colocar mais na rede do que deveria ser e não liberar o máximo que não pode aceitar.
Mas todos, em geral, seriam inúteis se não fosse a fila.5. Filas
No parque de diversões, você não pode dar prioridade a alguém se não organizar uma fila separada para quem pagou mais.A mesma situação nas redes.Se todo o tráfego estiver em uma fila, você não poderá extrair pacotes importantes do meio para dar prioridade a eles.É por isso que, após a classificação, os pacotes são colocados na fila correspondente a esta classe.E então uma fila (com dados de voz) se moverá rapidamente, mas com uma banda limitada, outra mais lenta (streaming), mas com uma banda larga, e alguns recursos seguirão o princípio residual.Mas dentro dos limites de cada fila separada, a mesma regra se aplica - você não pode extrair um pacote do meio - apenas a partir da cabeça.Cada fila tem um certo comprimento limitado. Por um lado, isso é ditado pelas limitações de hardware e, por outro lado, não faz sentido manter os pacotes na fila por muito tempo. Um pacote VoIP não é necessário se houver atraso de 200 ms. O TCP solicitará o encaminhamento, condicionalmente, após o término do RTT (configurado em sysctl). Portanto, largar nem sempre é ruim.Os desenvolvedores e designers de equipamentos de rede precisam encontrar um compromisso entre as tentativas de salvar o pacote o máximo possível e, pelo contrário, evitar desperdiçar largura de banda, tentando entregar o pacote que não é mais necessário.Em uma situação normal, quando a interface / chip não está sobrecarregada, a utilização do buffer é próxima de zero. Eles absorvem rajadas de curto prazo, mas isso não causa seu enchimento prolongado.Se houver mais tráfego do que o chip de comutação ou a interface de saída pode suportar, as filas começarão a se encher. E a utilização crônica acima de 20 a 30% já é uma situação que precisa ser tratada.
6. Evitar Congestionamentos
Na vida de qualquer roteador, chega um momento em que a fila está cheia. Onde colocar o pacote, se definitivamente não houver lugar para colocá-lo - isso é tudo, o buffer acabou e ele não estará lá, mesmo que seja bom visual, mesmo que você pague extra.Há duas maneiras: descartar este pacote ou aquelas que já marcaram o turno.Se eles já estiverem na fila, considere o que está faltando.E se este, então considere que ele não veio.Essas duas abordagens são chamadas de Drop Tail e Head Drop .Cauda da cauda e queda da cabeça
Tail Drop - o mecanismo mais simples de gerenciamento de filas - descarte todos os pacotes recém-chegados que não cabem no buffer. O Head Drop descarta pacotes que estão na fila há muito tempo. É melhor jogá-los fora do que economizar, porque eles provavelmente são inúteis. Mas os pacotes mais relevantes que chegaram ao final da fila terão mais chances de chegar a tempo. Além disso, o Head Drop permite que você não carregue a rede com pacotes desnecessários. Naturalmente, os pacotes mais antigos são aqueles que estão no início da fila, daí o nome da abordagem.
O Head Drop descarta pacotes que estão na fila há muito tempo. É melhor jogá-los fora do que economizar, porque eles provavelmente são inúteis. Mas os pacotes mais relevantes que chegaram ao final da fila terão mais chances de chegar a tempo. Além disso, o Head Drop permite que você não carregue a rede com pacotes desnecessários. Naturalmente, os pacotes mais antigos são aqueles que estão no início da fila, daí o nome da abordagem. O Head Drop tem outra vantagem não óbvia - se você soltar o pacote no início da fila, o destinatário descobrirá rapidamente o congestionamento na rede e informará o remetente. No caso de Tail Drop, as informações sobre o pacote descartado chegarão, possivelmente, centenas de milissegundos depois - até que ele chegue do final da linha até a cabeça dela.Ambos os mecanismos trabalham com diferenciação por sua vez. Na verdade, não é necessário que todo o buffer esteja cheio. Se a segunda fila estiver vazia e a zero nos globos oculares, somente os pacotes do zero serão descartados.
O Head Drop tem outra vantagem não óbvia - se você soltar o pacote no início da fila, o destinatário descobrirá rapidamente o congestionamento na rede e informará o remetente. No caso de Tail Drop, as informações sobre o pacote descartado chegarão, possivelmente, centenas de milissegundos depois - até que ele chegue do final da linha até a cabeça dela.Ambos os mecanismos trabalham com diferenciação por sua vez. Na verdade, não é necessário que todo o buffer esteja cheio. Se a segunda fila estiver vazia e a zero nos globos oculares, somente os pacotes do zero serão descartados. Tail Drop e Head Drop podem funcionar simultaneamente.
Tail Drop e Head Drop podem funcionar simultaneamente.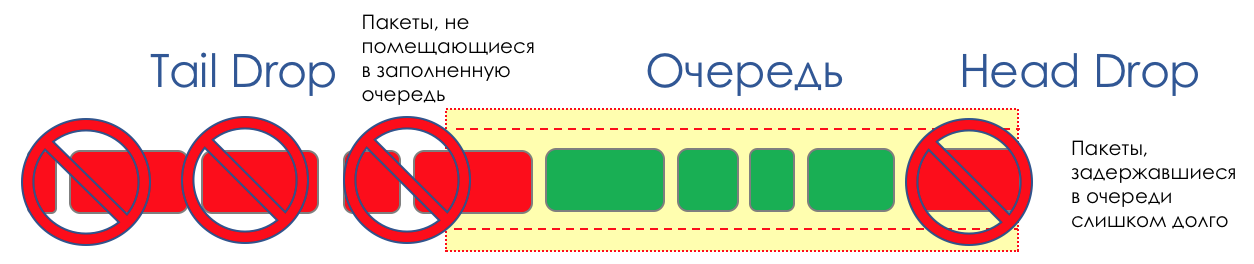
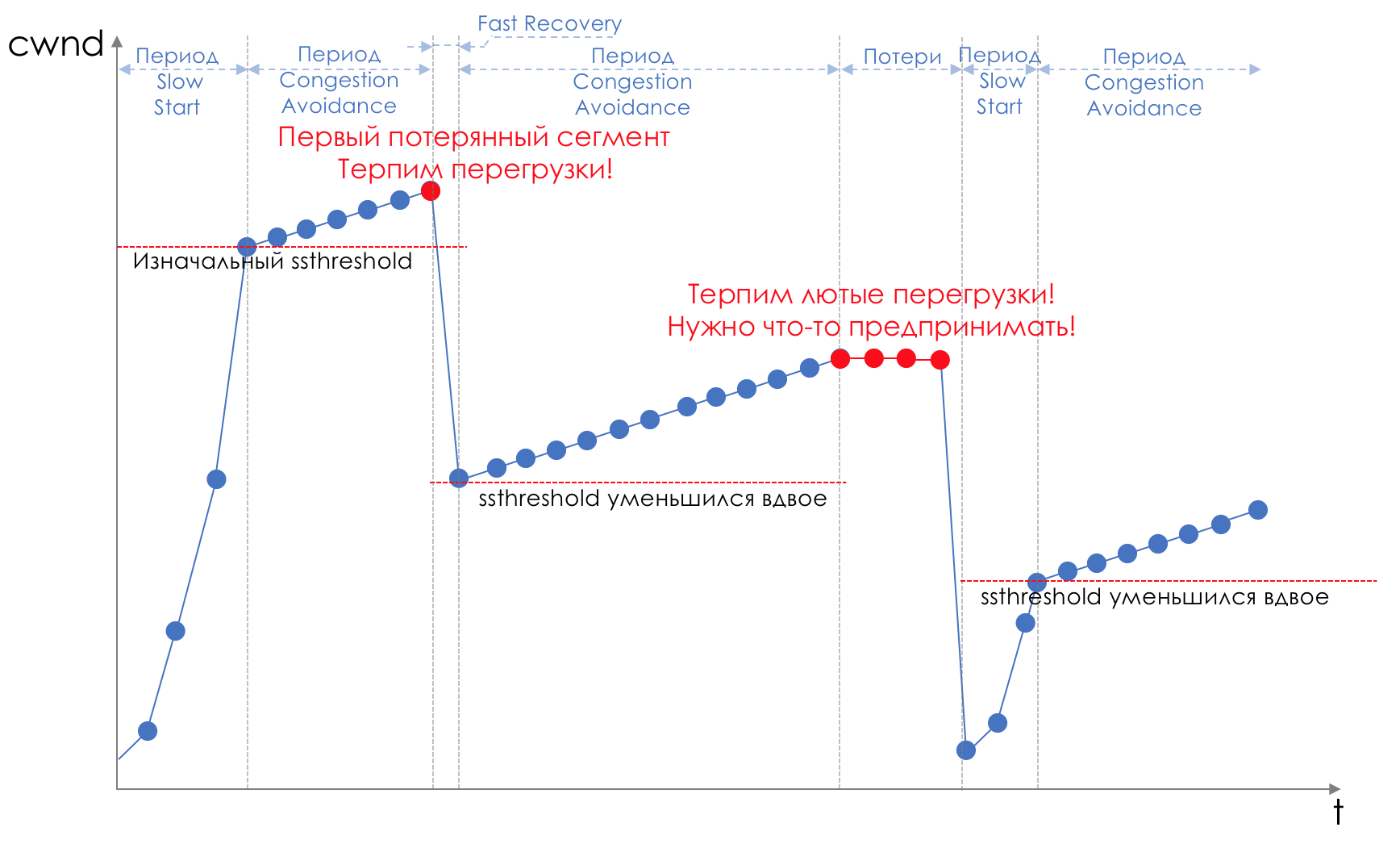
Cauda e queda da cabeça são “testa” para evitar congestionamentos. Você pode até dizer - essa é a ausência dele.Não fazemos nada até que a fila esteja 100% cheia. E depois disso, começamos a descartar todos os pacotes recém-chegados (ou atrasados por um longo tempo).Se você não precisa fazer nada para atingir a meta, em algum lugar há uma nuance.E essa nuance é o TCP.Lembre-se (de forma mais profunda e extremamente profunda ) de como o TCP funciona - estamos falando de implementações modernas.Existe uma janela deslizante (janela deslizante ou rwnd - janela anunciada do destinatário), que o destinatário controla, informando ao remetente quanto pode ser enviado.E há uma janela de sobrecarga ( CWND - Janela de congestionamento), que responde a problemas de rede e é controlado pelo remetente.O processo de transferência de dados começa com um início lento ( Slow Start ) com um aumento exponencial no CWND. Com cada segmento confirmado, 1 tamanho de MSS é adicionado ao CWND, ou seja, ele dobra em um tempo igual ao RTT (dados lá, ACK de volta) (Discurso sobre Reno / NewReno).Por exemplo
 O crescimento exponencial continua até um valor chamado ssthreshold (Slow Start Threshold), especificado na configuração de TCP no host.Em seguida, um crescimento linear de 1 / CWND começa para cada segmento confirmado até que repouse contra o RWND ou o início das perdas (a perda é confirmada por re-confirmação (ACK duplicada) ou nenhuma confirmação).Assim que uma perda de segmento é detectada, ocorre o TCP Backoff - o TCP reduz drasticamente a janela, na verdade reduzindo a velocidade de envio - e o mecanismo de recuperação rápida é iniciado :
O crescimento exponencial continua até um valor chamado ssthreshold (Slow Start Threshold), especificado na configuração de TCP no host.Em seguida, um crescimento linear de 1 / CWND começa para cada segmento confirmado até que repouse contra o RWND ou o início das perdas (a perda é confirmada por re-confirmação (ACK duplicada) ou nenhuma confirmação).Assim que uma perda de segmento é detectada, ocorre o TCP Backoff - o TCP reduz drasticamente a janela, na verdade reduzindo a velocidade de envio - e o mecanismo de recuperação rápida é iniciado :- enviar segmentos perdidos (retransmissão rápida),
- a janela é dobrada para baixo,
- O valor ssthreshold também se torna igual à metade da janela alcançada,
- o crescimento linear recomeça até a primeira perda,
- Repita.
 Perda pode significar o colapso completo de um segmento de rede e, em seguida, considerar que está perdido, ou congestionamento na linha (leia o estouro do buffer e descartar um segmento desta sessão).Este é o método do TCP de maximizar a utilização da largura de banda disponível e lidar com o congestionamento. E é bastante eficaz.No entanto, o que leva o Tail Drop?
Perda pode significar o colapso completo de um segmento de rede e, em seguida, considerar que está perdido, ou congestionamento na linha (leia o estouro do buffer e descartar um segmento desta sessão).Este é o método do TCP de maximizar a utilização da largura de banda disponível e lidar com o congestionamento. E é bastante eficaz.No entanto, o que leva o Tail Drop?- Digamos que através de um roteador esteja o caminho de milhares de sessões TCP. Em algum momento, o tráfego da sessão atingiu 1,1 Gb / s, velocidade da interface de saída - 1 Gb / s.
- Tráfego vem mais rápido do que as folhas, os buffers são preenchidos vsklyan .
- O Drop Drop é ativado até o expedidor extrair alguns pacotes da fila.
- Fast Recovery ( Slow Start).
- , , Tail Drop .
- TCP- , .
- .
- Fast Recovery/Slow Start.
- .
Saiba mais sobre as alterações nos mecanismos TCP no RFC 2001 ( início lento do TCP, prevenção de congestionamentos, retransmissão rápida e algoritmos de recuperação rápida ).Esta é uma ilustração típica de uma situação chamada Sincronização Global de TCP : Global, porque muitas sessões estabelecidas através deste nó sofrem.Sincronização , porque eles sofrem ao mesmo tempo. E a situação será repetida até que haja uma sobrecarga.TCP - porque o UDP, que não possui mecanismos de controle de congestionamento, não é afetado por ele.Nada de ruim teria acontecido nessa situação se não tivesse causado o uso subótimo da tira - os espaços entre os dentes da serra - o dinheiro desperdiçado.O segundo problema é TCP Starvation - esgotamento de TCP. Enquanto o TCP diminui a velocidade para reduzir a carga (não sejamos astutos - antes de tudo, para transmitir com segurança nossos dados), o UDP, todo esse sofrimento moral em geral pelo datagrama - envia o máximo possível.Portanto, a quantidade de tráfego TCP é reduzida e o UDP está aumentando (possivelmente), o próximo ciclo de Recuperação Perda - Rápida acontece em um limite mais baixo. O UDP ocupa espaço. A quantidade total de tráfego TCP cai.Como resolver o problema, é melhor evitá-lo. Vamos tentar reduzir a carga antes que ela preencha a fila usando o Fast Recovery / Slow Start, que acaba de ser contra nós.
Global, porque muitas sessões estabelecidas através deste nó sofrem.Sincronização , porque eles sofrem ao mesmo tempo. E a situação será repetida até que haja uma sobrecarga.TCP - porque o UDP, que não possui mecanismos de controle de congestionamento, não é afetado por ele.Nada de ruim teria acontecido nessa situação se não tivesse causado o uso subótimo da tira - os espaços entre os dentes da serra - o dinheiro desperdiçado.O segundo problema é TCP Starvation - esgotamento de TCP. Enquanto o TCP diminui a velocidade para reduzir a carga (não sejamos astutos - antes de tudo, para transmitir com segurança nossos dados), o UDP, todo esse sofrimento moral em geral pelo datagrama - envia o máximo possível.Portanto, a quantidade de tráfego TCP é reduzida e o UDP está aumentando (possivelmente), o próximo ciclo de Recuperação Perda - Rápida acontece em um limite mais baixo. O UDP ocupa espaço. A quantidade total de tráfego TCP cai.Como resolver o problema, é melhor evitá-lo. Vamos tentar reduzir a carga antes que ela preencha a fila usando o Fast Recovery / Slow Start, que acaba de ser contra nós.RED - Detecção Precoce Aleatória
Mas e se pegarmos e espalharmos gotas em alguma parte do buffer?Em termos relativos, comece a descartar pacotes aleatórios quando a fila estiver 80% cheia, forçando algumas sessões TCP a reduzir a janela e, consequentemente, a velocidade.E se a fila estiver 90% cheia, começamos a eliminar aleatoriamente 50% dos pacotes.90% - a probabilidade aumenta para Tail Drop (100% dos novos pacotes são descartados).Os mecanismos que implementam esse gerenciamento de filas são chamados AQM - Gerenciamento de Filas Adaptativo (ou Ativo) .Éassim que o RED funciona .Detecção Antecipada - corrige sobrecarga potencial;Aleatório - descarte pacotes aleatoriamente.Às vezes, eles decodificam o RED (na minha opinião, semanticamente mais corretamente), como o Random Early Discard.Graficamente, fica assim: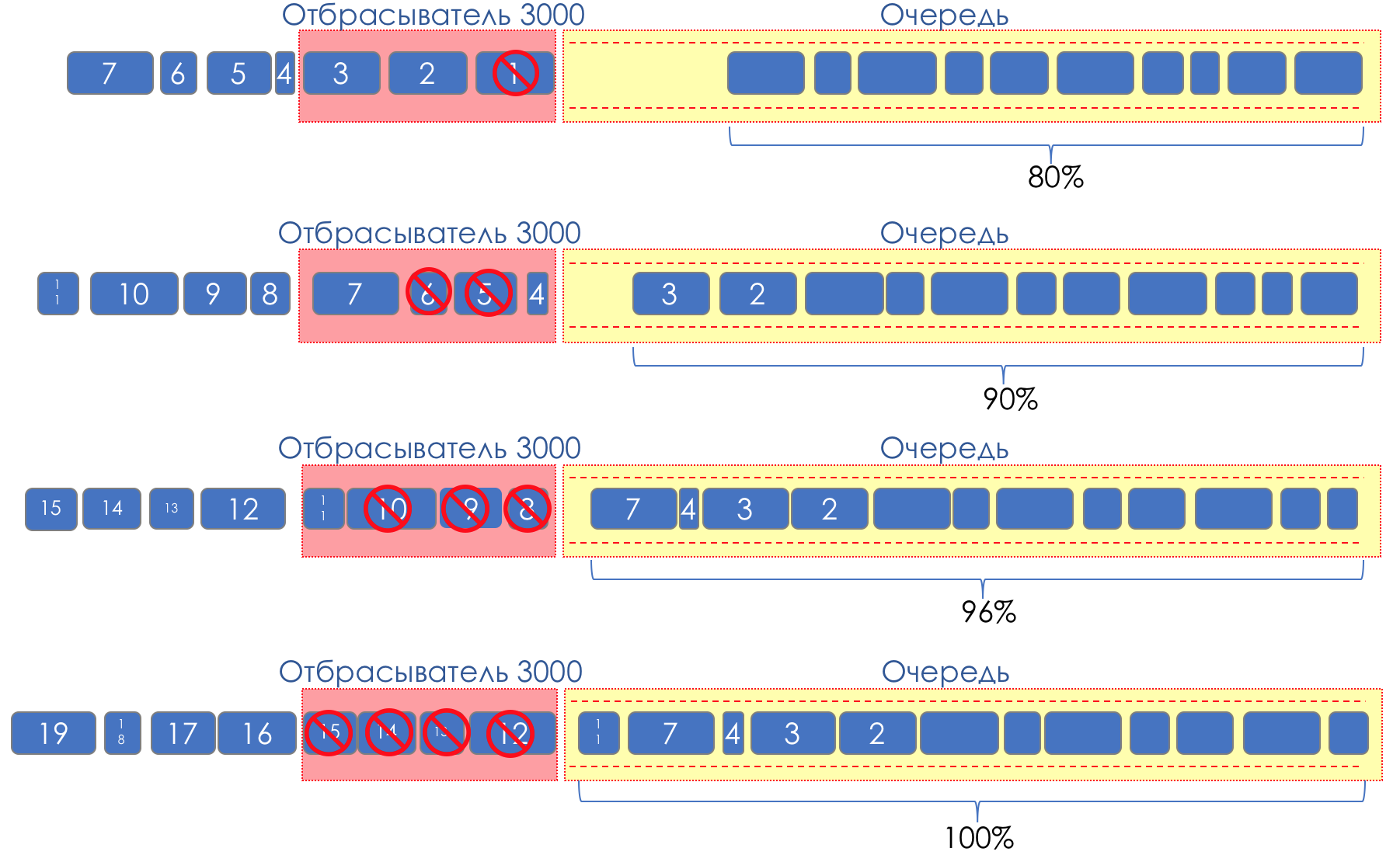
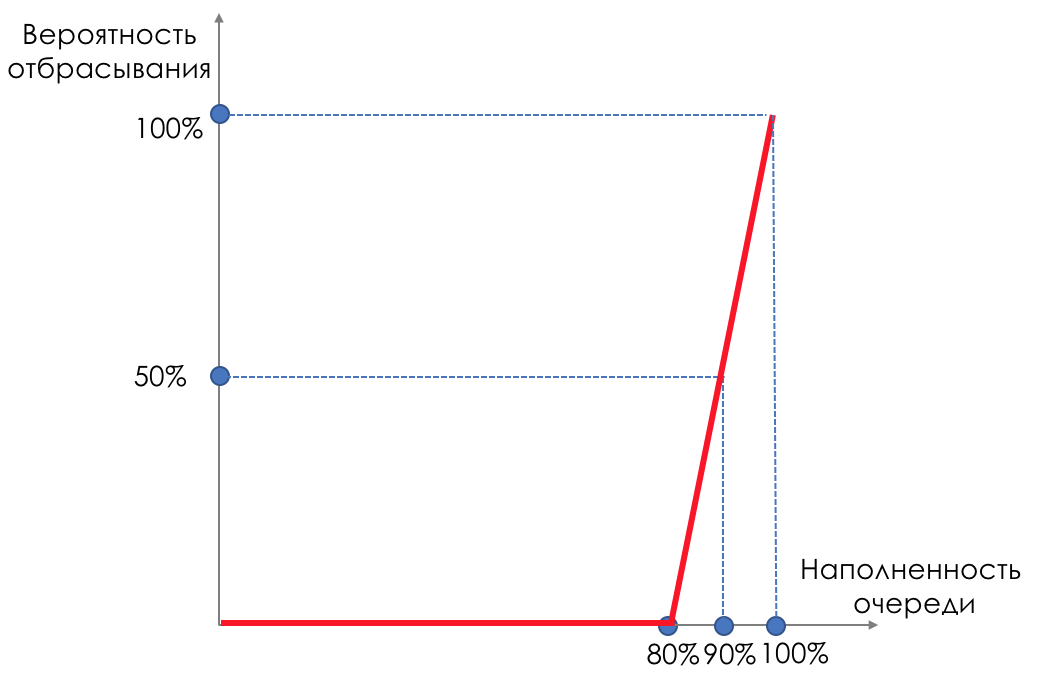 Até que o buffer esteja 80% cheio, os pacotes não são descartados - a probabilidade é de 0%.De 80 a 100 pacotes começam a ser descartados e, quanto mais, maior o preenchimento da fila.Portanto, a porcentagem cresce de 0 a 30.Um efeito colateral do RED é que as sessões TCP agressivas são mais propensas a desacelerar, simplesmente porque há muitos pacotes e é mais provável que sejam descartadas.A ineficiência do uso da tira RED resolve entorpecendo uma parte muito menor das sessões sem causar um rebaixamento tão sério entre os dentes.Exatamente pelo mesmo motivo, o UDP não pode ocupar tudo.
Até que o buffer esteja 80% cheio, os pacotes não são descartados - a probabilidade é de 0%.De 80 a 100 pacotes começam a ser descartados e, quanto mais, maior o preenchimento da fila.Portanto, a porcentagem cresce de 0 a 30.Um efeito colateral do RED é que as sessões TCP agressivas são mais propensas a desacelerar, simplesmente porque há muitos pacotes e é mais provável que sejam descartadas.A ineficiência do uso da tira RED resolve entorpecendo uma parte muito menor das sessões sem causar um rebaixamento tão sério entre os dentes.Exatamente pelo mesmo motivo, o UDP não pode ocupar tudo.WRED - Detecção precoce aleatória ponderada
Mas na audiência de todos, provavelmente, ainda WRED . O astuto leitor do linkmeup já sugeriu que este é o mesmo RED, mas que pesa em turnos. E ele não estava certo.O RED opera dentro da mesma fila. Não faz sentido olhar para a EF se o BE estiver cheio. Consequentemente, pesar em turnos não trará nada.Aqui Drop Precedence simplesmente funciona.E dentro da mesma fila, pacotes com prioridade de queda diferente terão curvas diferentes. Quanto menor a prioridade, maior a probabilidade de ser atingida. Existem três curvas aqui:Vermelho - tráfego com menos prioridade (em termos de queda), amarelo - mais, verde - máximo.O tráfego vermelho começa a ser descartado quando o buffer está 20% cheio, de 20 a 40 cai para 20% e depois o Tail Drop.O amarelo começa mais tarde - de 30 a 50 é descartado em até 10%, depois - Tail Drop.O verde é o menos suscetível: de 50 a 100 cresce suavemente para 5%. Em seguida é Tail Drop.No caso do DSCP, pode ser AF11, AF12 e AF13, respectivamente verde, amarelo e vermelho.
Existem três curvas aqui:Vermelho - tráfego com menos prioridade (em termos de queda), amarelo - mais, verde - máximo.O tráfego vermelho começa a ser descartado quando o buffer está 20% cheio, de 20 a 40 cai para 20% e depois o Tail Drop.O amarelo começa mais tarde - de 30 a 50 é descartado em até 10%, depois - Tail Drop.O verde é o menos suscetível: de 50 a 100 cresce suavemente para 5%. Em seguida é Tail Drop.No caso do DSCP, pode ser AF11, AF12 e AF13, respectivamente verde, amarelo e vermelho. É muito importante aqui que ele funcione com o TCP e não seja absolutamente aplicável ao UDP.Ou um aplicativo usando UDP ignora perdas, como no caso de telefonia ou streaming de vídeo, e isso afeta negativamente o que o usuário vê.Ou o próprio aplicativo controla a entrega e solicita que você reenvie o mesmo pacote. No entanto, ele não precisa pedir à fonte para baixar a taxa de transmissão. E, em vez de reduzir a carga, um aumento é devido às retransmissões.É por isso que apenas Tail Drop é usado para EF.Para CS6, CS7, o Tail Drop também é usado, pois não há altas velocidades assumidas e o WRED não resolverá nada.Para AF, WRED é aplicado. AFxy, em que x é a classe do serviço, ou seja, a fila na qual ele cai e y é a prioridade de descarte - da mesma cor.Para o BE, a decisão é tomada com base no tráfego prevalecente nessa fila.Dentro de um único roteador, é usada a rotulagem interna especial de pacotes, diferente daquela que carrega os cabeçalhos. Portanto, MPLS e 802.1q, onde não é possível codificar a Precedência de descarte, podem ser processados em filas com prioridades de descarte diferentes.Por exemplo, um pacote MPLS chegou a um nó, não possui rotulagem de Precedência da gota, no entanto, de acordo com os resultados do polimento, ficou amarelo e pode ser descartado antes de ser colocado na fila (que pode ser determinada pelo campo Classe de tráfego).Vale lembrar que todo esse arco-íris existe apenas dentro do nó. Não há conceito de cor na linha entre vizinhos.Embora seja possível, é claro, codificar cores na parte Precedência de descarte do DSCP.
É muito importante aqui que ele funcione com o TCP e não seja absolutamente aplicável ao UDP.Ou um aplicativo usando UDP ignora perdas, como no caso de telefonia ou streaming de vídeo, e isso afeta negativamente o que o usuário vê.Ou o próprio aplicativo controla a entrega e solicita que você reenvie o mesmo pacote. No entanto, ele não precisa pedir à fonte para baixar a taxa de transmissão. E, em vez de reduzir a carga, um aumento é devido às retransmissões.É por isso que apenas Tail Drop é usado para EF.Para CS6, CS7, o Tail Drop também é usado, pois não há altas velocidades assumidas e o WRED não resolverá nada.Para AF, WRED é aplicado. AFxy, em que x é a classe do serviço, ou seja, a fila na qual ele cai e y é a prioridade de descarte - da mesma cor.Para o BE, a decisão é tomada com base no tráfego prevalecente nessa fila.Dentro de um único roteador, é usada a rotulagem interna especial de pacotes, diferente daquela que carrega os cabeçalhos. Portanto, MPLS e 802.1q, onde não é possível codificar a Precedência de descarte, podem ser processados em filas com prioridades de descarte diferentes.Por exemplo, um pacote MPLS chegou a um nó, não possui rotulagem de Precedência da gota, no entanto, de acordo com os resultados do polimento, ficou amarelo e pode ser descartado antes de ser colocado na fila (que pode ser determinada pelo campo Classe de tráfego).Vale lembrar que todo esse arco-íris existe apenas dentro do nó. Não há conceito de cor na linha entre vizinhos.Embora seja possível, é claro, codificar cores na parte Precedência de descarte do DSCP.As gotas também podem aparecer em uma rede descarregada, onde parece que não deve haver excesso de fila. Como
A razão para isso pode ser rajadas curtas - rajadas - de tráfego. O exemplo mais simples - 5 aplicativos ao mesmo tempo decidiram transferir tráfego para um host final.
Um exemplo é mais complicado - o remetente é conectado via interface de 10 Gb / se o receptor é de 1 Gb / s. O próprio ambiente permite criar pacotes mais rapidamente no remetente. O controle de fluxo Ethernet do receptor solicita que o host mais próximo desacelere e os pacotes começam a se acumular nos buffers.
Bem, o que fazer quando tudo piorar?7. Gerenciamento de congestionamentos
Quando tudo está ruim, a prioridade do processamento deve ser dada ao tráfego mais importante. A importância de cada pacote é determinada na fase de classificação.Mas o que é ruim?Nem todos os buffers precisam estar obstruídos para que os aplicativos comecem a ter problemas.O exemplo mais simples são os pacotes de voz, que se aglomeram em pacotes grandes de pacotes grandes de um aplicativo que estão baixando um arquivo.Isso aumentará o atraso, arruinará a instabilidade e possivelmente causará quedas.Ou seja, temos problemas em fornecer serviços de qualidade na ausência de congestionamento real.Esse problema foi projetado para resolver o mecanismo de gerenciamento de congestionamentos.O tráfego de diferentes aplicativos é dividido em filas, como vimos acima.Mas somente como resultado, tudo deve se fundir novamente em uma interface. A serialização ainda acontece sequencialmente.Como filas diferentes conseguem fornecer diferentes níveis de serviços?Remova pacotes de diferentes filas de maneiras diferentes.O expedidor está envolvido nisso.Hoje consideraremos a maioria dos despachantes, começando pelo mais simples:- FIFO - apenas uma linha, tudo em BE, C - injustiça.
- PQ - o caminho para os oligarcas, lacaios ceder.
- FQ - todos são iguais.
- DWRR - todos são iguais, mas alguns são mais uniformes.
FIFO - Primeiro a entrar, primeiro a sair
O caso mais simples, de fato a ausência de QoS, é que todo o tráfego é tratado da mesma maneira - em uma fila.Os pacotes deixam a fila exatamente na ordem em que chegaram, daí o nome: primeiro inserido - primeiro e esquerdo .O FIFO não é um despachante no sentido completo da palavra, nem um mecanismo DiffServ em geral, uma vez que na verdade não separa classes.Se a fila começar a encher, os atrasos e a instabilidade começarem a aumentar, você não poderá gerenciá-los, porque não poderá extrair um pacote importante do meio da fila.Sessões agressivas de TCP com um tamanho de pacote de 1.500 bytes podem ocupar a fila inteira, causando pequenos pacotes de voz.No FIFO, todas as classes são mescladas no CS0. No entanto, apesar de todas essas deficiências, é assim que a Internet agora funciona.A maioria dos fornecedores FIFO agora é o despachante padrão com uma fila para todo o tráfego de trânsito e mais um para pacotes de serviços gerados localmente.É simples, é extremamente barato. Se os canais são amplos e há pouco tráfego, tudo está bem.A quintessência da idéia de que a QoS - para os pobres - expande a banda, e os clientes ficam satisfeitos, e seu salário aumentará em vários.Somente assim os equipamentos de rede funcionavam uma vez.Mas muito em breve o mundo se viu diante do fato de que simplesmente não daria certo.Com a tendência de redes convergentes, ficou claro que diferentes tipos de tráfego (serviço, voz, multimídia, navegação na Internet, compartilhamento de arquivos) têm requisitos de rede fundamentalmente diferentes.O FIFO não era suficiente, então eles criaram várias filas e começaram a produzir esquemas de agendamento de tráfego.No entanto, o FIFO nunca sai de nossas vidas: dentro de cada uma das filas, os pacotes são sempre processados de acordo com o princípio do FIFO.
No entanto, apesar de todas essas deficiências, é assim que a Internet agora funciona.A maioria dos fornecedores FIFO agora é o despachante padrão com uma fila para todo o tráfego de trânsito e mais um para pacotes de serviços gerados localmente.É simples, é extremamente barato. Se os canais são amplos e há pouco tráfego, tudo está bem.A quintessência da idéia de que a QoS - para os pobres - expande a banda, e os clientes ficam satisfeitos, e seu salário aumentará em vários.Somente assim os equipamentos de rede funcionavam uma vez.Mas muito em breve o mundo se viu diante do fato de que simplesmente não daria certo.Com a tendência de redes convergentes, ficou claro que diferentes tipos de tráfego (serviço, voz, multimídia, navegação na Internet, compartilhamento de arquivos) têm requisitos de rede fundamentalmente diferentes.O FIFO não era suficiente, então eles criaram várias filas e começaram a produzir esquemas de agendamento de tráfego.No entanto, o FIFO nunca sai de nossas vidas: dentro de cada uma das filas, os pacotes são sempre processados de acordo com o princípio do FIFO.PQ - Enfileiramento prioritário
O segundo mecanismo mais complicado e a tentativa de dividir o serviço em classes é uma fila de prioridade .O tráfego agora está disposto em várias filas de acordo com sua prioridade de classe (por exemplo, embora não necessariamente, o mesmo BE, AF1-4, EF, CS6-7). O expedidor passa por uma fila após a outra.Primeiro, ele pula todos os pacotes da fila de maior prioridade, depois de menos e depois de menos. E assim em um círculo.
O expedidor não começa a recuperar pacotes de baixa prioridade até que a fila de alta prioridade esteja vazia. Se, no momento do processamento de pacotes de baixa prioridade, um pacote chegar em uma fila de prioridade mais alta, o despachante muda para ele e somente após o esvaziamento retorna aos outros.
Se, no momento do processamento de pacotes de baixa prioridade, um pacote chegar em uma fila de prioridade mais alta, o despachante muda para ele e somente após o esvaziamento retorna aos outros. O PQ funciona quase tão bem quanto o FIFO.É ótimo para tipos de tráfego como pacotes de protocolo e voz, onde os atrasos são críticos e o volume total não é muito grande.Bem, você deve admitir que não deve manter o BFD Hello devido ao fato de vários vídeos grandes do YouTube terem chegado?Mas aqui está a falta de PQ - se a fila de prioridade estiver carregada com tráfego, o despachante nunca mudará para outros.E se algum Doutor Mal, em busca de métodos para conquistar o mundo, decide marcar todo o seu tráfico de vilões com a maior marca negra, todos os outros esperam obedientemente e depois são descartados.Também não é necessário falar sobre uma faixa garantida para cada linha.As filas de alta prioridade podem ser cortadas pela velocidade do tráfego processado nelas. Então outros não morrerão de fome. No entanto, controlar isso não é fácil.
O PQ funciona quase tão bem quanto o FIFO.É ótimo para tipos de tráfego como pacotes de protocolo e voz, onde os atrasos são críticos e o volume total não é muito grande.Bem, você deve admitir que não deve manter o BFD Hello devido ao fato de vários vídeos grandes do YouTube terem chegado?Mas aqui está a falta de PQ - se a fila de prioridade estiver carregada com tráfego, o despachante nunca mudará para outros.E se algum Doutor Mal, em busca de métodos para conquistar o mundo, decide marcar todo o seu tráfico de vilões com a maior marca negra, todos os outros esperam obedientemente e depois são descartados.Também não é necessário falar sobre uma faixa garantida para cada linha.As filas de alta prioridade podem ser cortadas pela velocidade do tráfego processado nelas. Então outros não morrerão de fome. No entanto, controlar isso não é fácil.
Os mecanismos a seguir passam por todas as filas, retirando uma certa quantidade de dados, proporcionando condições mais honestas. Mas eles fazem isso de maneira diferente.FQ-Fair Queuing
O próximo candidato ao papel de despachante ideal são os mecanismos justos de enfileiramento .FQ - Fila justa
Sua história começou em 1985, quando John Nagle sugeriu a criação de uma fila para cada fluxo de dados. Em espírito, isso se aproxima da abordagem do IntServ e é facilmente explicado pelo fato de que a idéia de classes de serviço, como o DiffServ, não existia na época.O FQ extraiu a mesma quantidade de dados de cada fila em ordem.Honestidade reside no fato de que o expedidor não opera com o número de pacotes, mas com o número de bits que podem ser transmitidos de cada fila.Portanto, um fluxo TCP agressivo não pode inundar a interface e todos obtêm oportunidades iguais.Em teoria. O FQ nunca foi implementado na prática como um mecanismo para despachar filas em equipamentos de rede.Existem três desvantagens:O primeiro - óbvio - é muito caro - iniciar uma fila para cada fluxo, contar o peso de cada pacote e sempre se preocupar com os bits a serem ignorados e o tamanho do pacote.O segundo - menos óbvio - todos os threads obtêm oportunidades iguais em termos de largura de banda. E se eu quero desigual?A terceira honestidade - não óbvia - do QF é absoluta: todo mundo tem atrasos iguais, mas existem tópicos que são mais importantes que o atraso do que a banda.Por exemplo, entre os 256 fluxos, existem os de voz, o que significa que cada um deles alcançará apenas 256 segmentos.E o que fazer com eles não é claro. Aqui você pode ver que, devido ao grande tamanho do pacote no terceiro estágio, nos dois primeiros ciclos processamos um pacote dos dois primeiros.A descrição dos mecanismos bit a bit de Round Robin e GPS já está além do escopo deste artigo e refiro o leitor a um estudo independente .
Aqui você pode ver que, devido ao grande tamanho do pacote no terceiro estágio, nos dois primeiros ciclos processamos um pacote dos dois primeiros.A descrição dos mecanismos bit a bit de Round Robin e GPS já está além do escopo deste artigo e refiro o leitor a um estudo independente .WFQ - Fila justa ponderada
A segunda e parte terceira falhas do QF tentaram encerrá-lo, publicado em 1989.Cada fila era dotada de peso e, consequentemente, do direito de distribuir tráfego em múltiplos de peso por um ciclo.O peso foi calculado com base em dois parâmetros: ainda relevante, em seguida, IP Precedence e o comprimento do pacote.No contexto do WFQ, quanto mais peso, pior.Portanto, quanto maior a Precedência de IP, menor o peso do pacote.Quanto menor o tamanho da embalagem, menor o seu peso.Assim, pacotes pequenos de alta prioridade obtêm mais recursos, enquanto gigantes de baixa prioridade estão esperando.Na ilustração abaixo, os pacotes receberam tais pesos que, no primeiro, um pacote da primeira fila é ignorado, depois dois do segundo, novamente do primeiro e somente então o terceiro é processado. Assim, por exemplo, isso poderia acontecer se o tamanho dos pacotes no segundo estágio for relativamente pequeno. Sobre a dura engenharia do WFQ, com o tempo de término dos pacotes, o tempo virtual e o Teorema de Wig, você pode ler em um curioso documento colorido .No entanto, isso não resolveu o primeiro e o terceiro problemas. A abordagem baseada em fluxo foi igualmente inconveniente e os fluxos que precisavam de pequenos atrasos e instabilidade estável não os receberam.Isso, no entanto, não impediu o uso do WFQ em alguns dispositivos da Cisco (principalmente antigos). Havia até 256 filas nas quais os threads foram colocados com base no hash de seus cabeçalhos. Um compromisso entre o paradigma baseado em fluxo e os recursos limitados.
Sobre a dura engenharia do WFQ, com o tempo de término dos pacotes, o tempo virtual e o Teorema de Wig, você pode ler em um curioso documento colorido .No entanto, isso não resolveu o primeiro e o terceiro problemas. A abordagem baseada em fluxo foi igualmente inconveniente e os fluxos que precisavam de pequenos atrasos e instabilidade estável não os receberam.Isso, no entanto, não impediu o uso do WFQ em alguns dispositivos da Cisco (principalmente antigos). Havia até 256 filas nas quais os threads foram colocados com base no hash de seus cabeçalhos. Um compromisso entre o paradigma baseado em fluxo e os recursos limitados.CBWFQ - WFQ baseado em classe
O CBWFQ fez a abordagem do problema de complexidade com o advento do DiffServ. O Behavior Aggregate classificou todas as categorias de tráfego em 8 classes e, consequentemente, em filas. Isso deu a ele um nome e uma fila bastante simplificada.O peso no CBWFQ adquiriu um significado diferente. O peso foi atribuído às classes (não threads) manualmente na configuração, a pedido do administrador, porque o campo DSCP já foi usado para classificação.Ou seja, o DSCP determinou em qual fila colocar e o peso configurado - quantas faixas estão disponíveis para essa fila.Mais importante, isso indiretamente tornou a vida um pouco mais fácil e os fluxos de baixa latência, que agora eram agregados em uma (duas a três ...) filas e recebiam seus pontos altos com muito mais frequência. A vida melhorou, mas ainda não é boa - não há garantias - em geral, no WFQ tudo ainda é igual em termos de atrasos.E a necessidade de monitoramento constante do tamanho dos pacotes, sua fragmentação e desfragmentação, não desapareceu.CBWFQ + LLQ - Fila de baixa latência
A abordagem final, o culminar de uma abordagem bit a bit, é a união do CBWFQ com o PQ.Uma das filas se torna o chamado LLQ (fila de baixa latência) e, enquanto todas as outras filas são processadas pelo gerente CBWFQ, o gerente PQ está em execução entre os LLQs e o restante.Ou seja, enquanto existem pacotes no LLQ, as filas restantes estão aguardando, seus atrasos estão aumentando. Assim que os pacotes no LLQ acabaram, fomos processar o restante. Os pacotes apareceram no LLQ - eles esqueceram o resto e retornaram a ele.O FIFO também funciona no LLQ, portanto você não deve empurrar tudo sem chegar lá, aumentando a utilização do buffer e o atraso ao mesmo tempo.No entanto, para que as filas não prioritárias não passem fome, vale a pena definir um limite de largura de banda no LLQ. Então as ovelhas estão cheias e os lobos estão seguros.
Então as ovelhas estão cheias e os lobos estão seguros.RR - Round-Robin
De mãos dadas com FQ andou e RR .Um era honesto, mas não simples. O outro é exatamente o oposto. O RR passou pelas filas, extraindo um número igual de pacotes delas. A abordagem é mais primitiva que a QF e, portanto, desonesta em relação a vários fluxos. Fontes agressivas podem facilmente inundar a faixa com pacotes de 1500 bytes de tamanho.No entanto, foi muito simples de implementar - você não precisa saber o tamanho do pacote na fila, fragmentá-lo e coletá-lo novamente.No entanto, sua injustiça na alocação da faixa bloqueou seu caminho para o mundo - no mundo das redes, o Round-Robin puro não foi implementado.
O RR passou pelas filas, extraindo um número igual de pacotes delas. A abordagem é mais primitiva que a QF e, portanto, desonesta em relação a vários fluxos. Fontes agressivas podem facilmente inundar a faixa com pacotes de 1500 bytes de tamanho.No entanto, foi muito simples de implementar - você não precisa saber o tamanho do pacote na fila, fragmentá-lo e coletá-lo novamente.No entanto, sua injustiça na alocação da faixa bloqueou seu caminho para o mundo - no mundo das redes, o Round-Robin puro não foi implementado.WRR - Robin Redondo Ponderado
O mesmo destino ocorre com o WRR, que adicionou peso às filas com base na Precedência de IP. No WRR, não foi retirado um número igual de pacotes, mas um múltiplo do peso da fila.Seria possível atribuir mais peso às filas com pacotes menores, mas fazer isso dinamicamente não era possível.
DWRR - Robin Redondo Ponderado pelo Déficit
E de repente, uma abordagem extremamente curiosa em 1995 foi proposta por M. Shreedhar e G. Varghese.Cada linha tem uma linha de crédito separada em bits.Ao passar da fila, são emitidos tantos pacotes quanto há crédito suficiente.O tamanho do pacote no início da fila é deduzido do valor do empréstimo.Se a diferença for maior que zero, esse pacote será removido e o próximo será verificado. Então, até que a diferença seja menor que zero.Se mesmo o primeiro pacote não tem crédito suficiente, bem, infelizmente, os fluxos de lama, ele permanece na fila.Antes do próximo passe, o crédito de cada linha é aumentado em uma certa quantia, chamada quantum .Para filas diferentes, o quantum é diferente - quanto maior a banda que você precisa fornecer, maior o quantum.Assim, todas as filas recebem uma largura de banda garantida, independentemente do tamanho dos pacotes nela.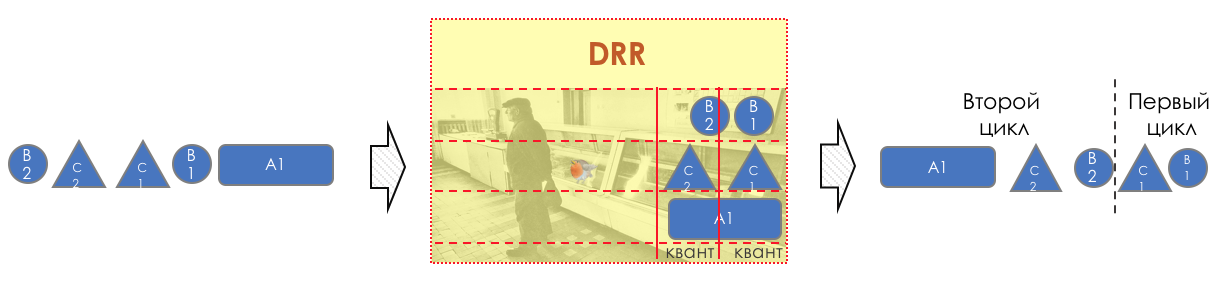 Pela explicação acima, não ficaria claro para mim como isso funciona.
Pela explicação acima, não ficaria claro para mim como isso funciona.Vamos desenhar os passos ...:
- DRR ( W),
- 4 ,
- 0- 500 ,
- 1- — 1000,
- 2- 1500,
- 3- 4000,
- — 1600 .

1
1. 0, 1600 ()
0- . :
— (1600 — 500 = 1100).
— — (1100 — 500 = 600).
— — (600 — 500 = 100).
— (100 — 500 = -400). .
— 100 .
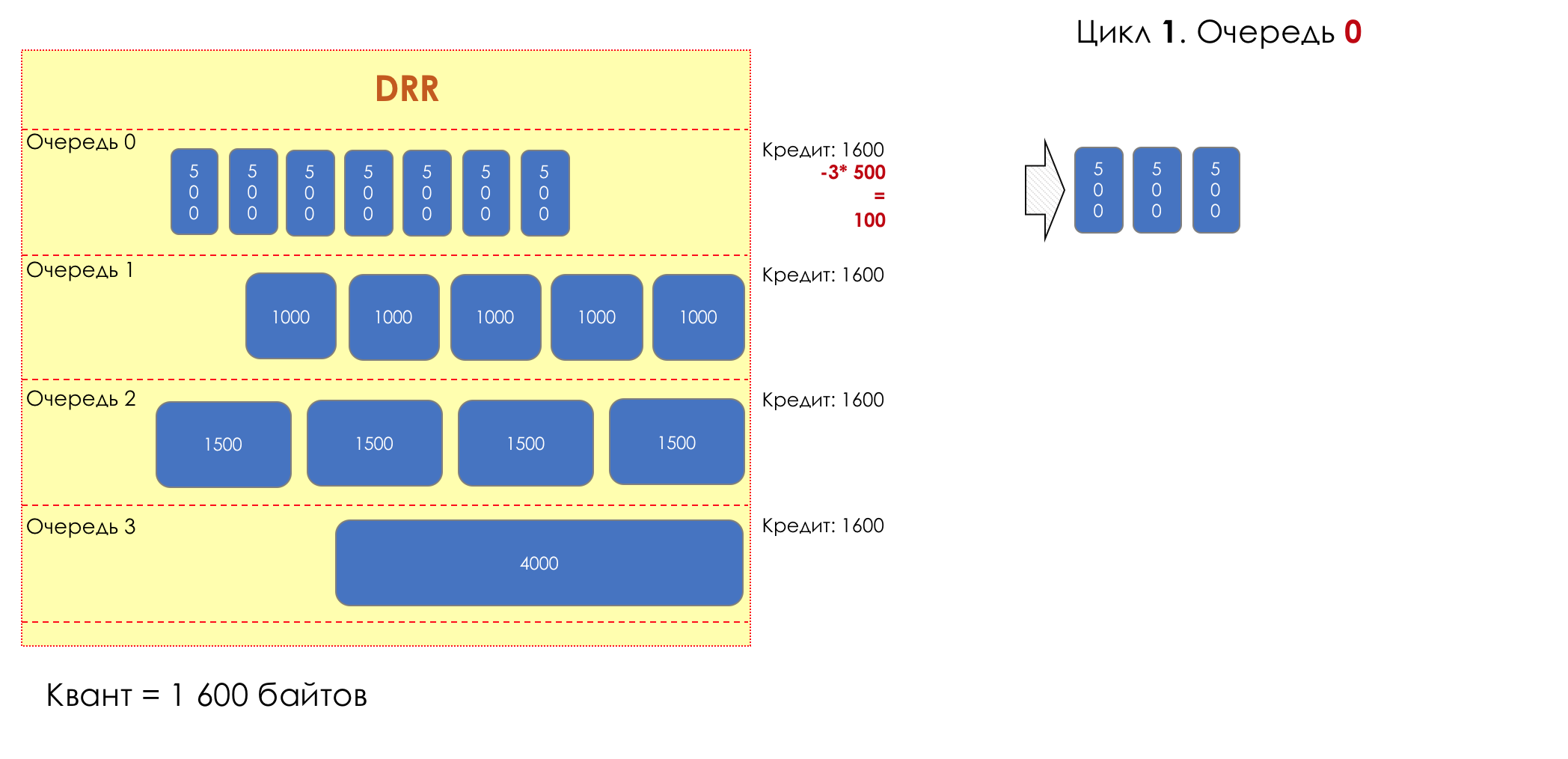 1. 1
1. 1— (1600 — 1000 = 600).
(600 — 1000 = -400). .
— 600 .
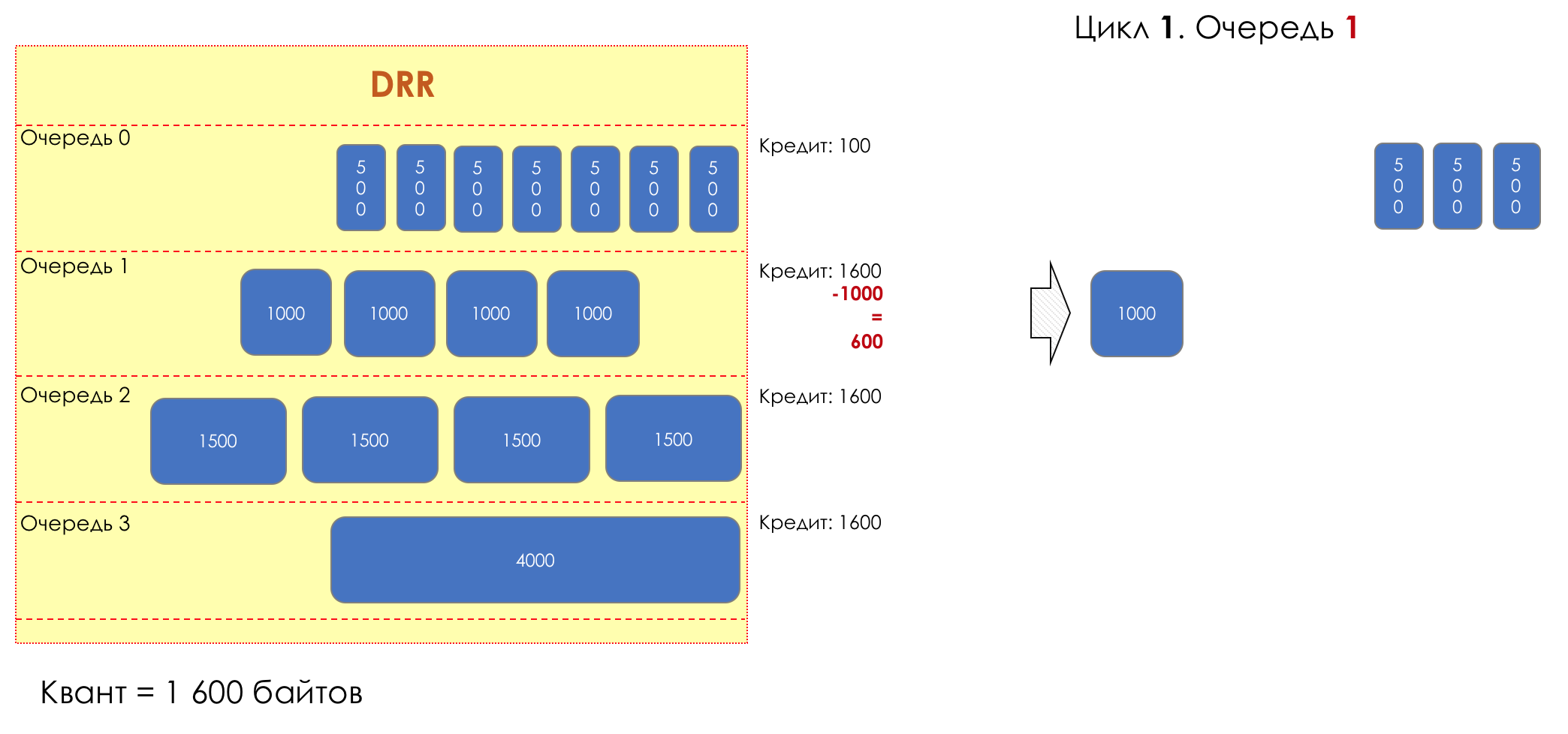 1. 2
1. 2— (1600 — 1500 = 100).
(100 — 1000 = -900). .
— 100 .
 1. 3
1. 3. (1600 — 4000 = -2400).
.
— 1600 .
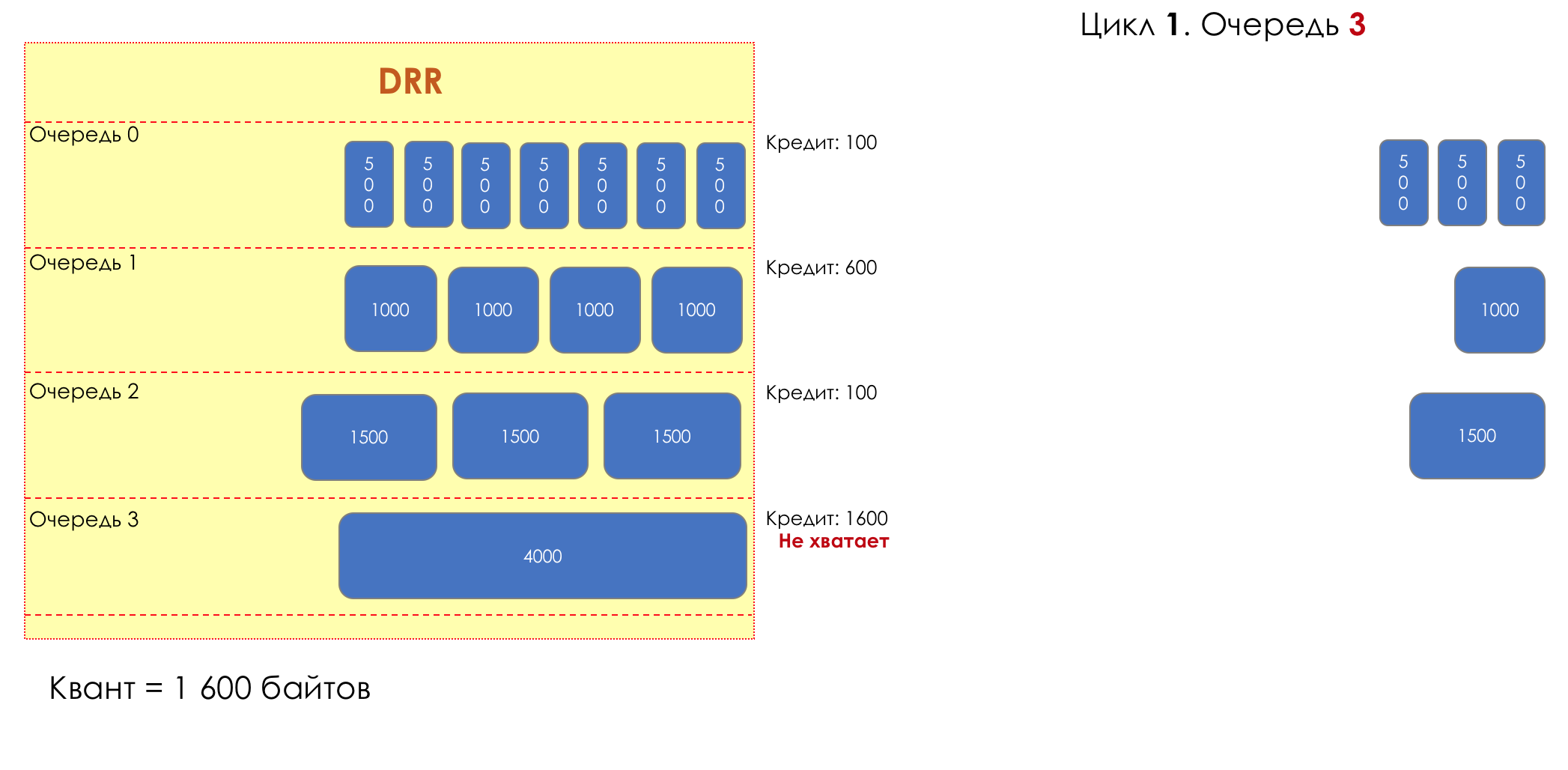
, :
- 0 — 1500
- 1 — 1000
- 2 — 1500
- 3 — 0
:
- 0 — 100
- 1 — 600
- 2 — 100
- 3 — 1600
2
— 1600 .
2. 01700 (100 + 1600).
— (1700 — 3*500 = 200).
.
— 200 .
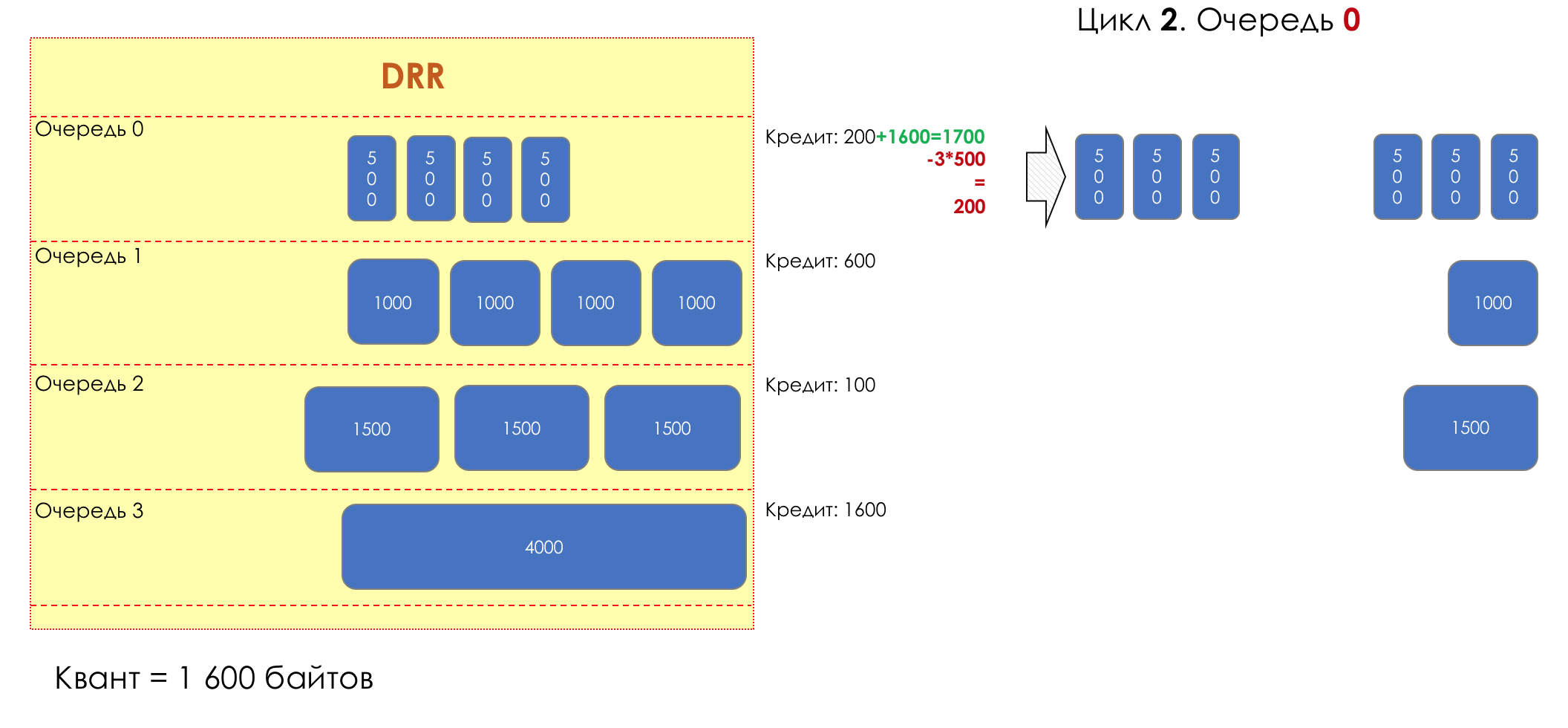 2. 1
2. 12200 (600 + 1600).
— (2200 — 2*1000 = 200).
.
— 200 .
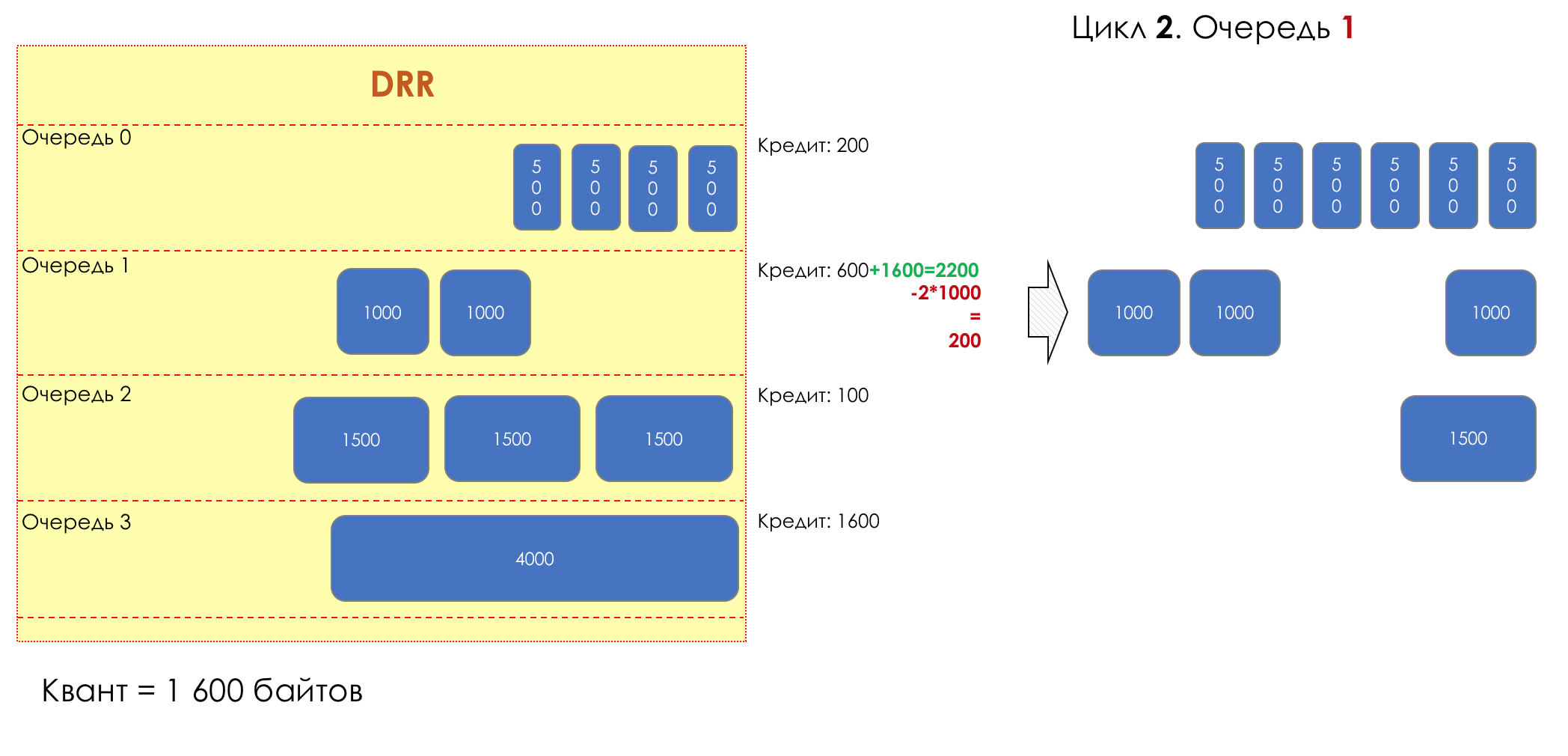 2. 2
2. 21700 (100 + 1600).
— (2200 — 1500 = 200).
— .
— 200 .
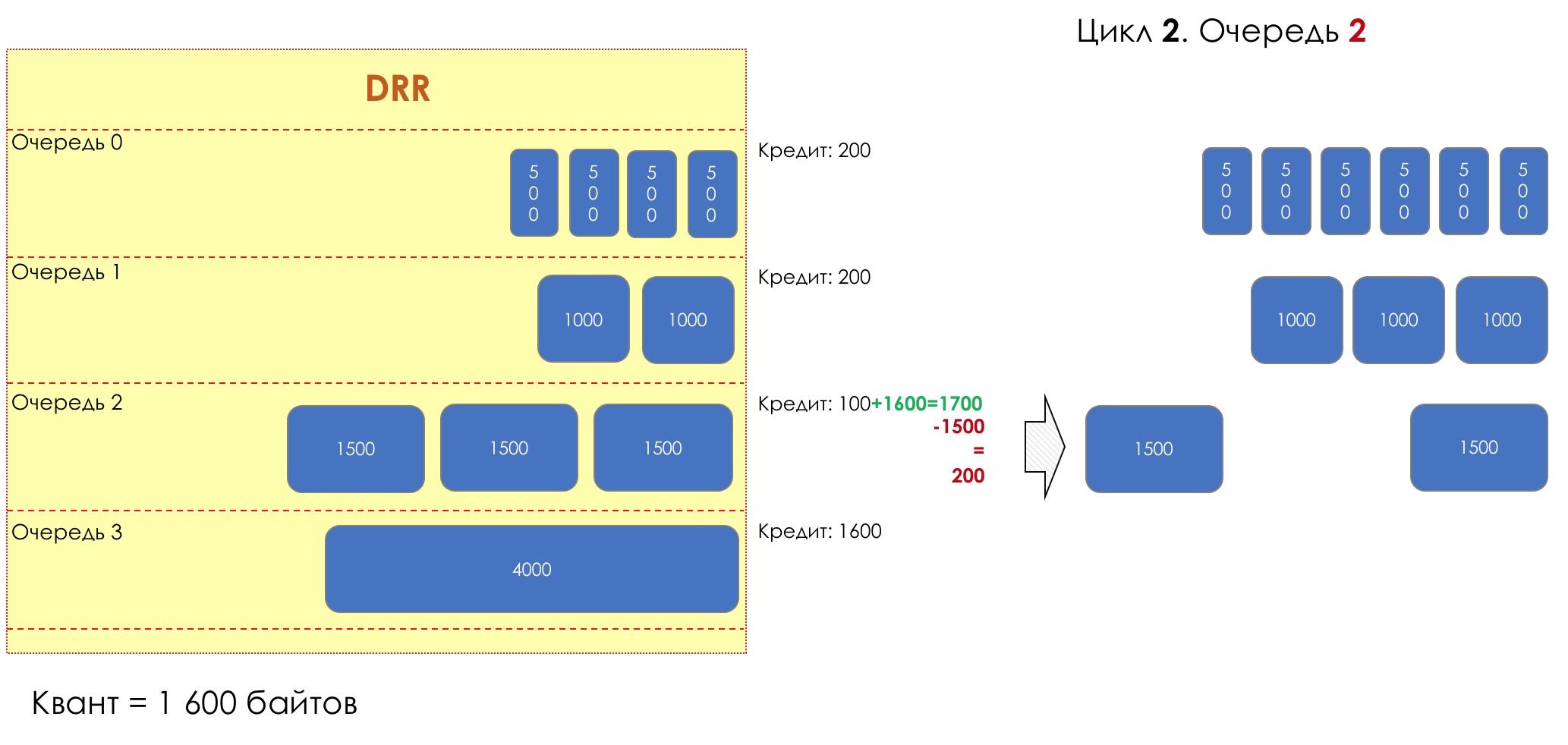 2. 3
2. 33200 (1600 + 1600).
(3200 — 4000 = -800)
— 3200 .
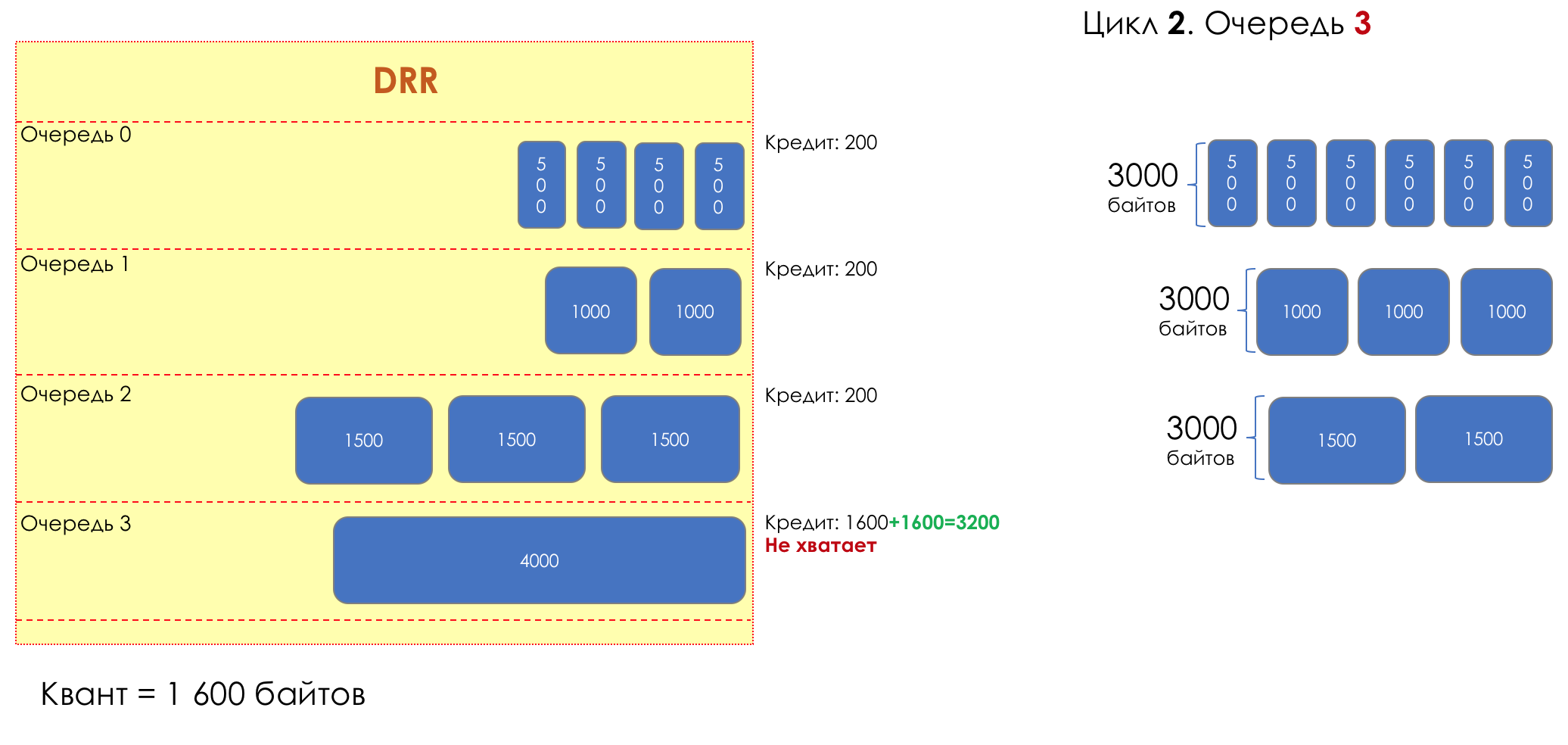
, :
- 0 — 3000
- 1 — 3000
- 2 — 3000
- 3 — 0
:
- 0 — 200
- 1 — 200
- 2 — 200
- 3 — 3200
3
— 1600 .
3. 01800 (200 + 1600).
— (1800 — 3*500 = 300).
.
— 300 .
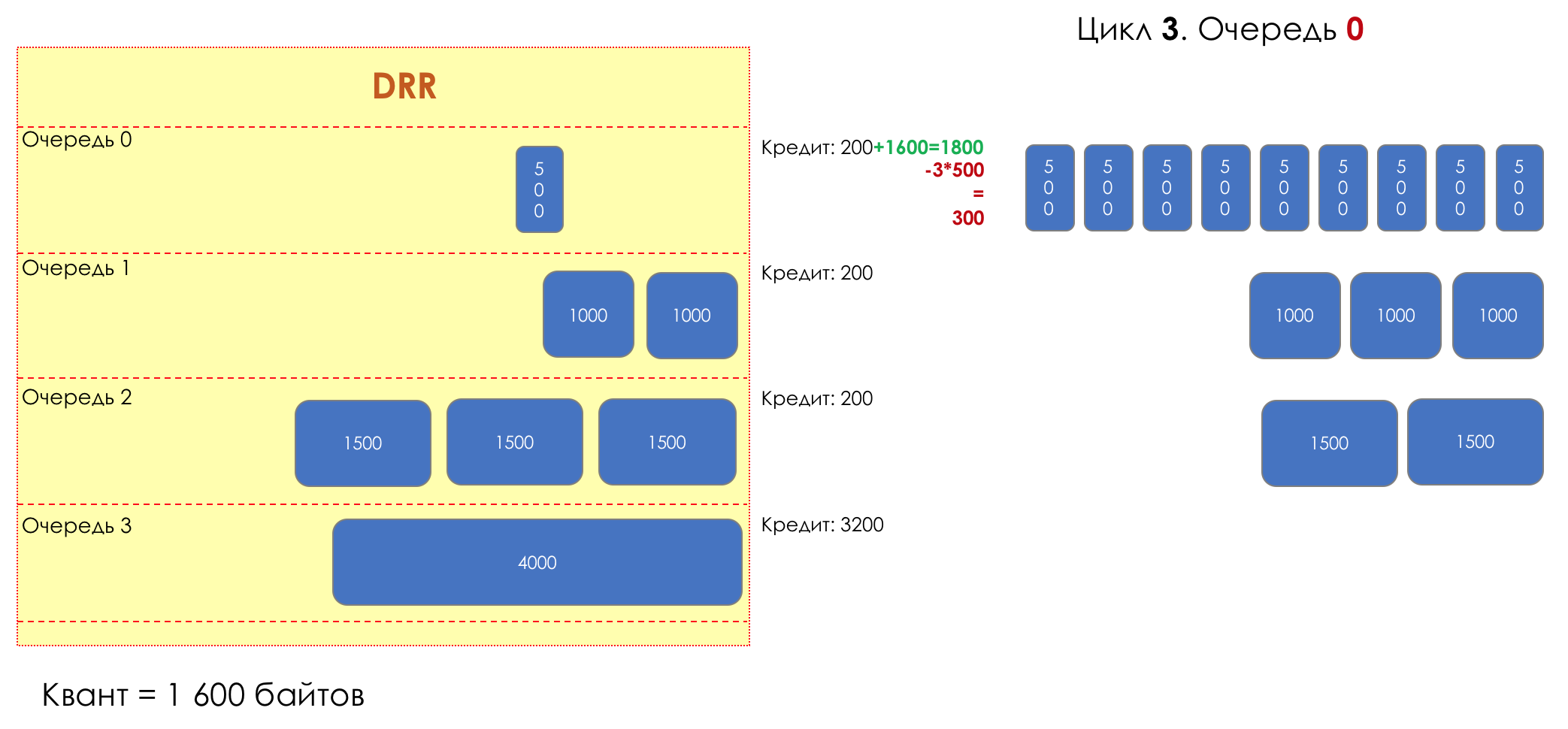 3. 1
3. 11800 (200 + 1600).
— (1800 — 1000 = 800).
— 800 .
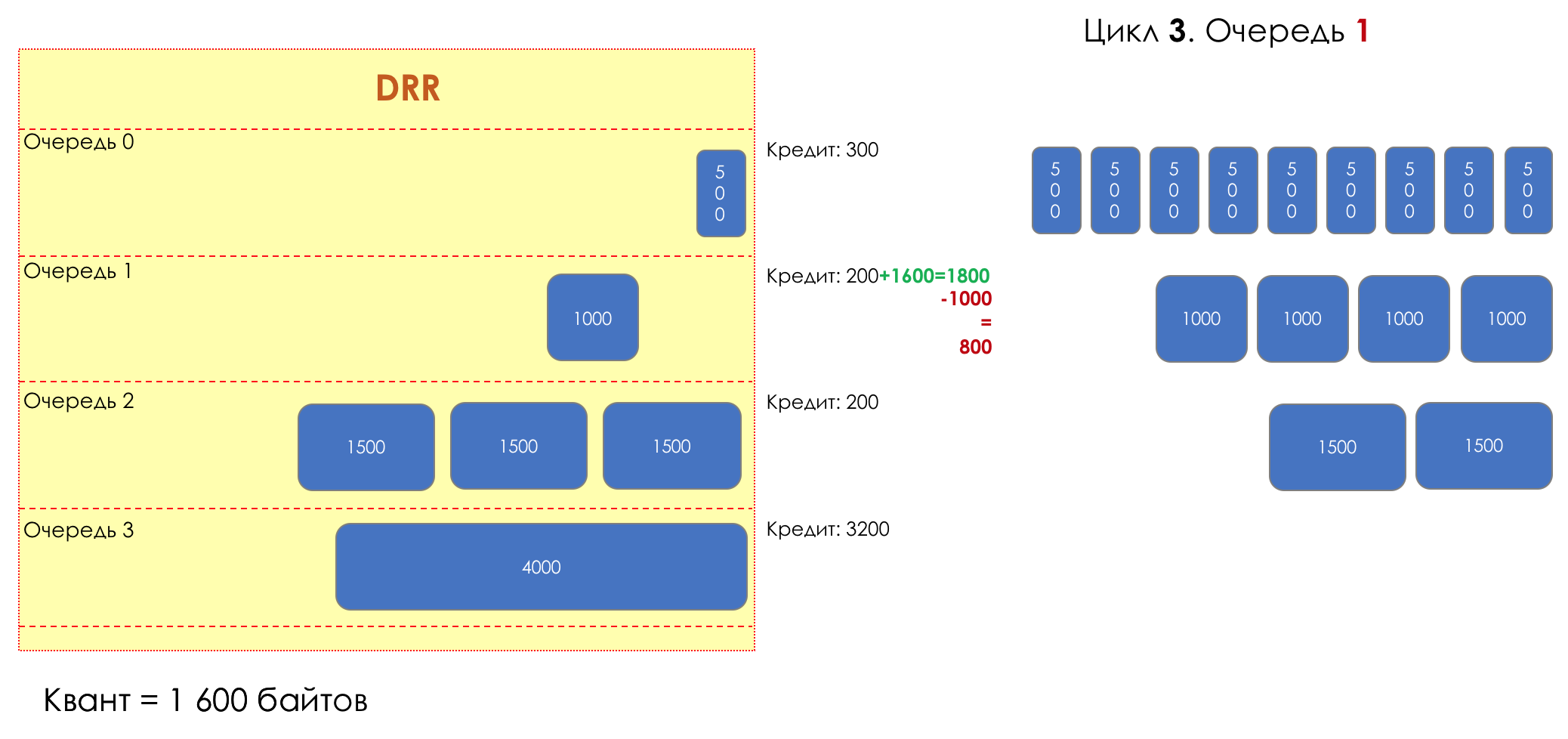 3. 2
3. 21800 (200 + 1600).
— (1800 — 1500 = 300).
— 300 .
 3. 3
3. 33- !
4800 (3200 + 1600).
— (4800 — 4000 = 800).
— 800 .
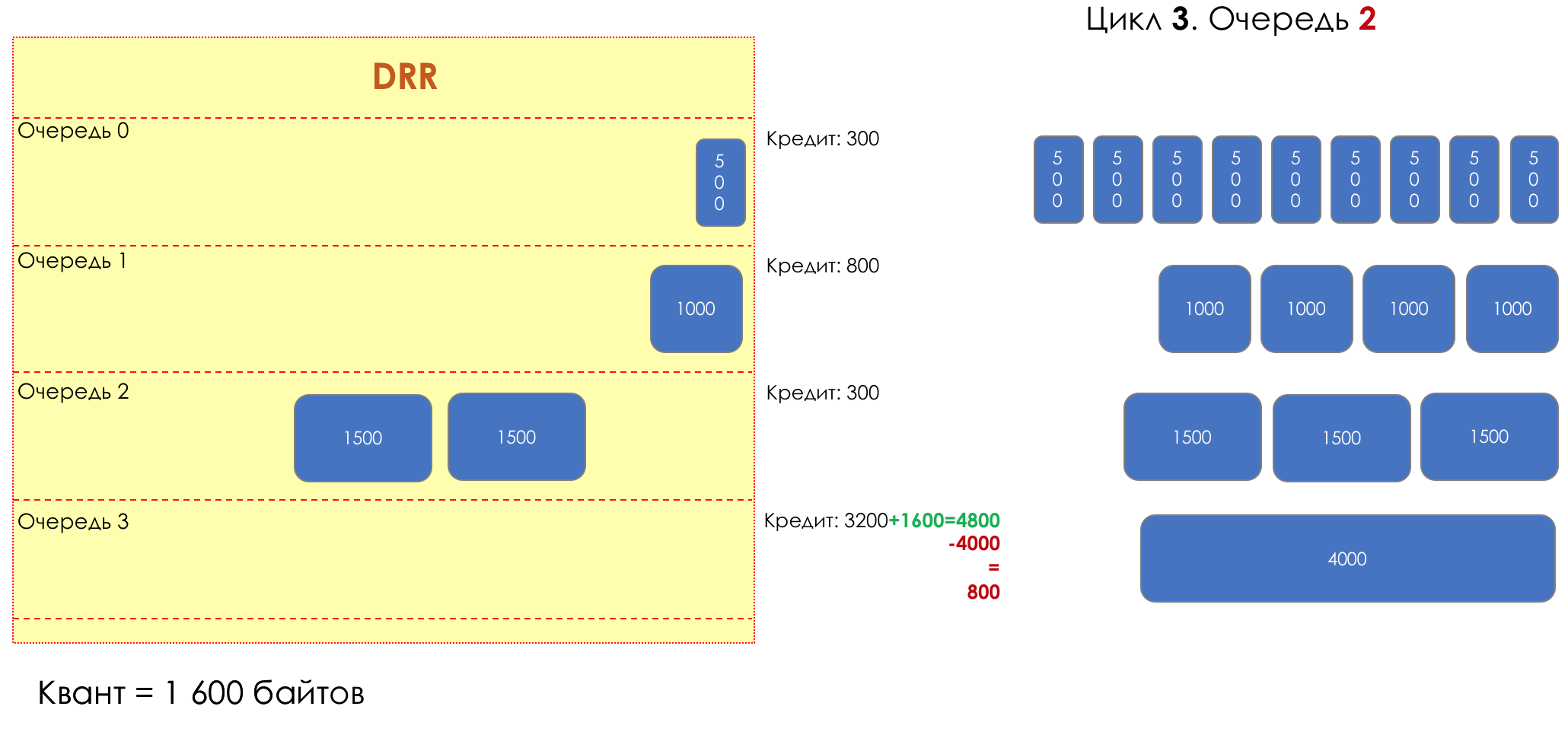
, :
- 0 — 4500
- 1 — 4000
- 2 — 4500
- 3 — 4000
:
- 0 — 300
- 1 — 800
- 2 — 300
- 3 — 800
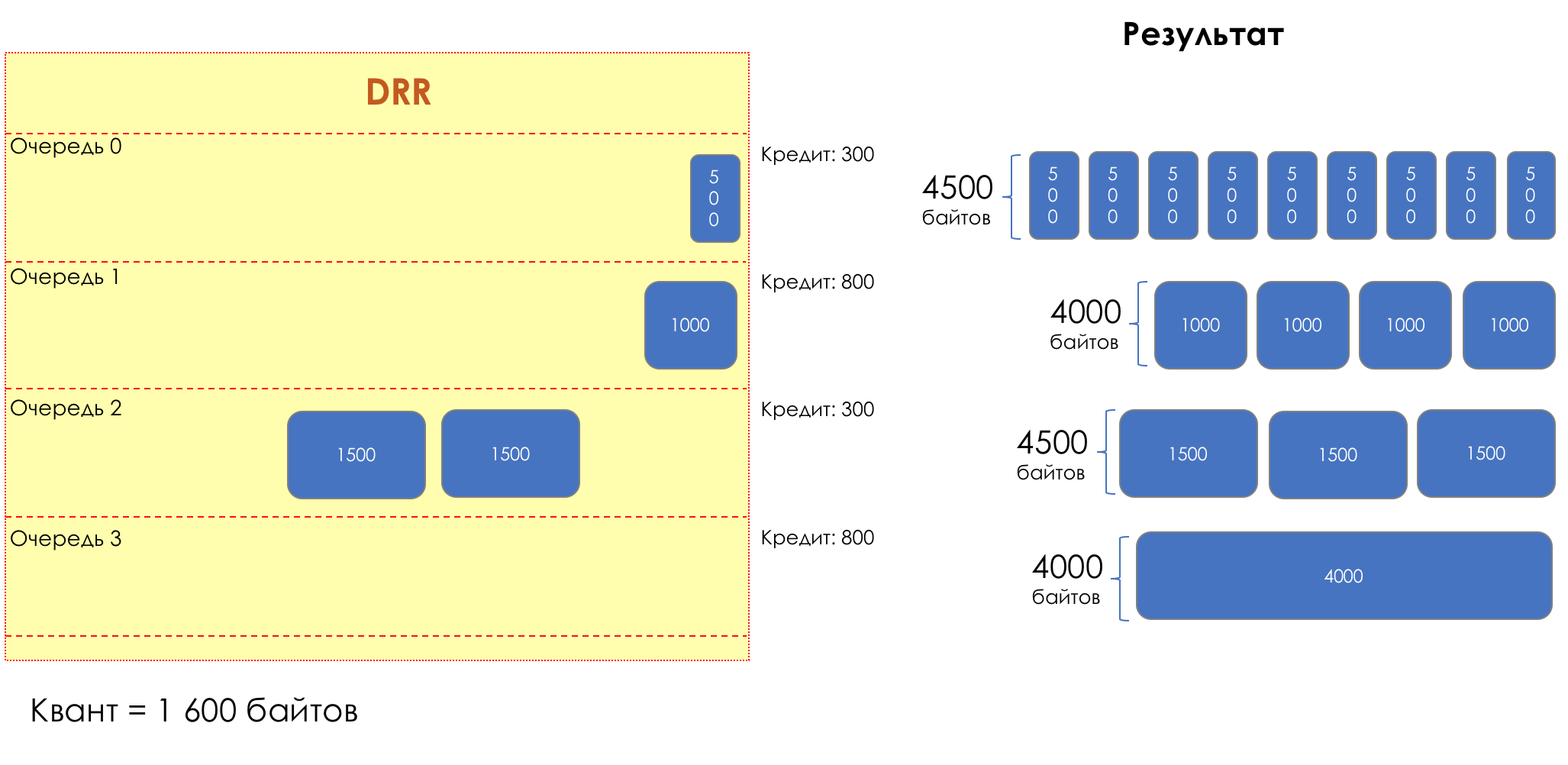
DRR. .
, .
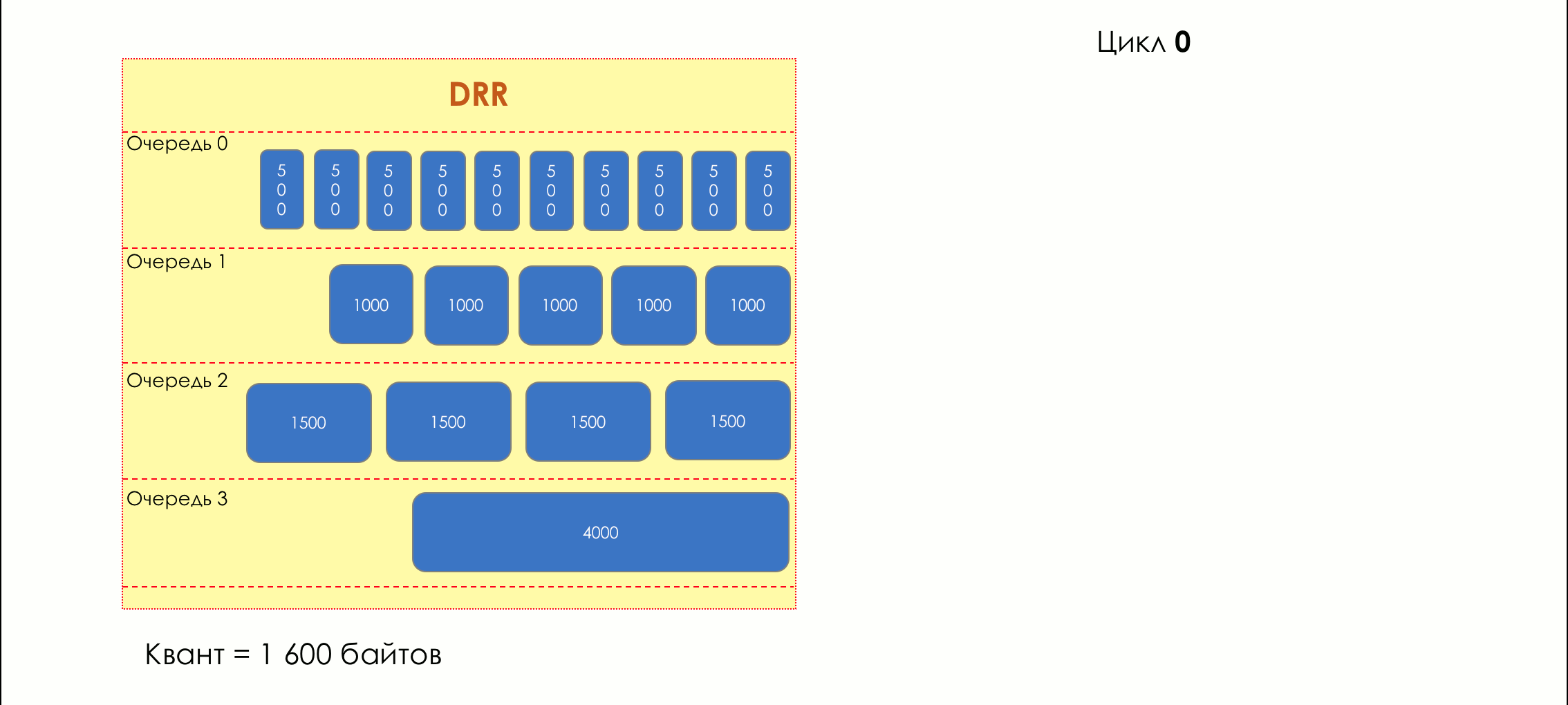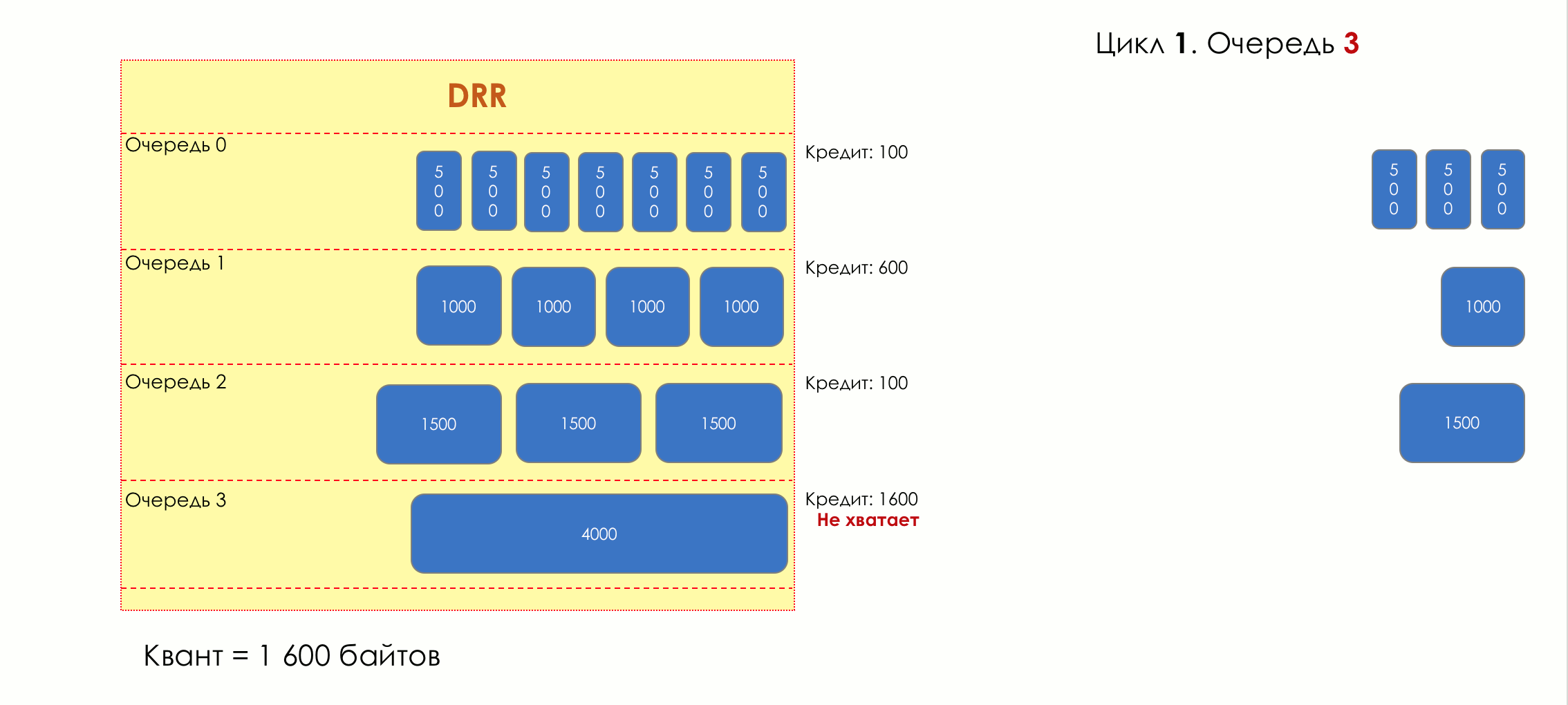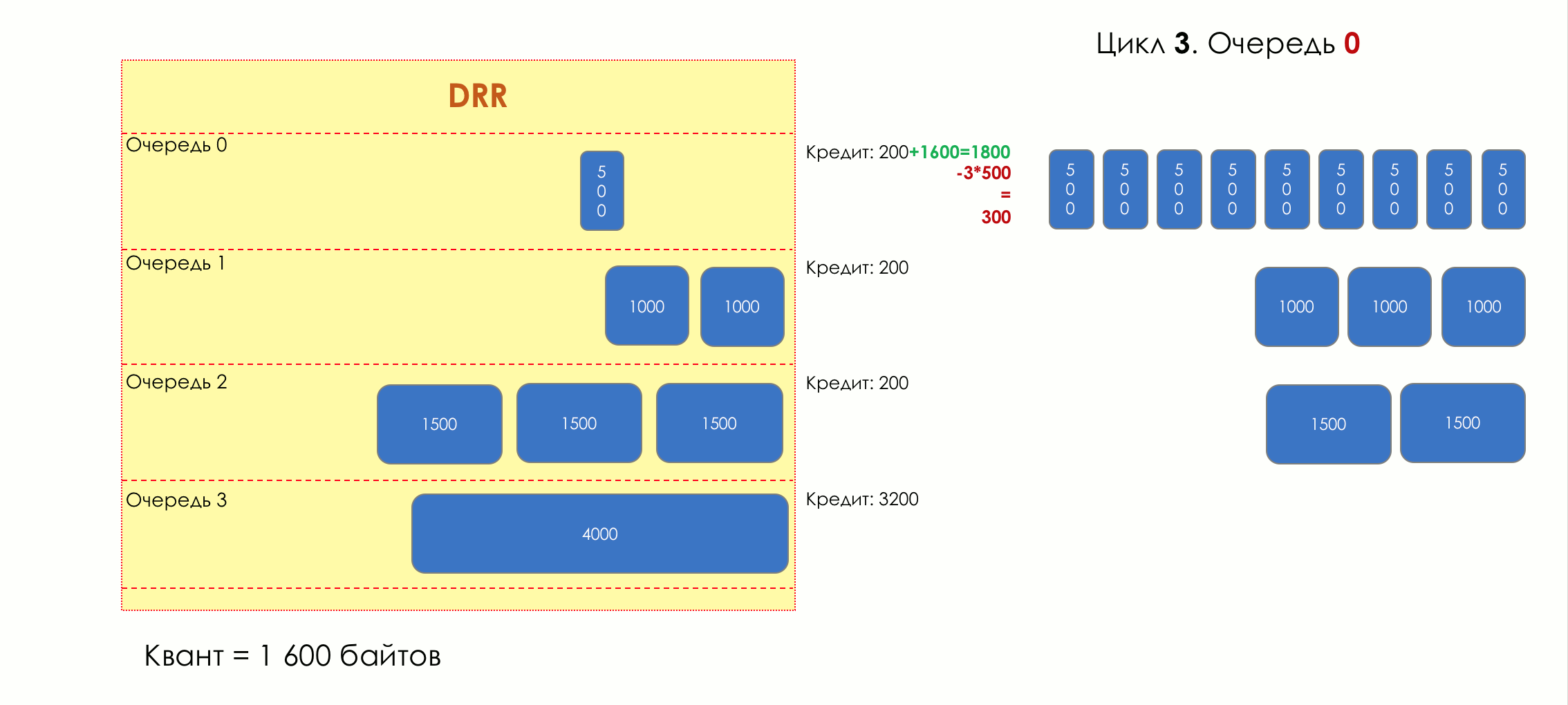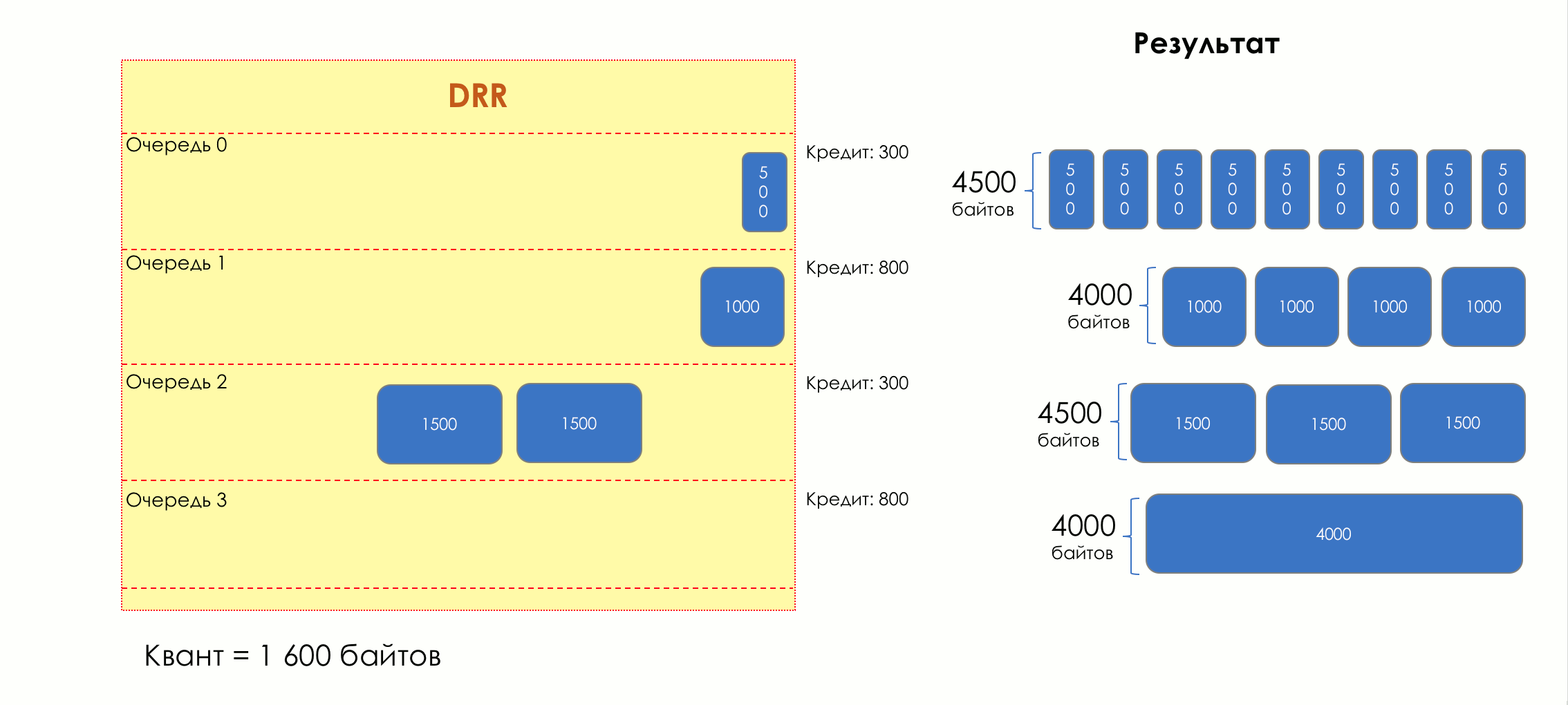
DWRR DRR , , , .
DRR, — , .
: , . .
Com o DWRR, a questão permanece com a garantia de atrasos e instabilidade - o peso não resolve de maneira alguma.Teoricamente, você pode fazer o mesmo que com o CB-WFQ, adicionando o LLQ.No entanto, este é apenas um dos cenários possíveis da crescente popularidade de hoje.PB-DWRR - DWRR baseado em prioridade
Atualmente, o mainstream hoje está se tornando PB-DWRR - Robin Rodada Ponderada por Déficit Baseado em Prioridade.Este é o mesmo DWRR mal antigo, no qual outra fila é adicionada - prioridade, na qual os pacotes são processados com uma prioridade mais alta. Isso não significa que ela recebe uma faixa maior, mas que os pacotes serão retirados de lá com mais frequência.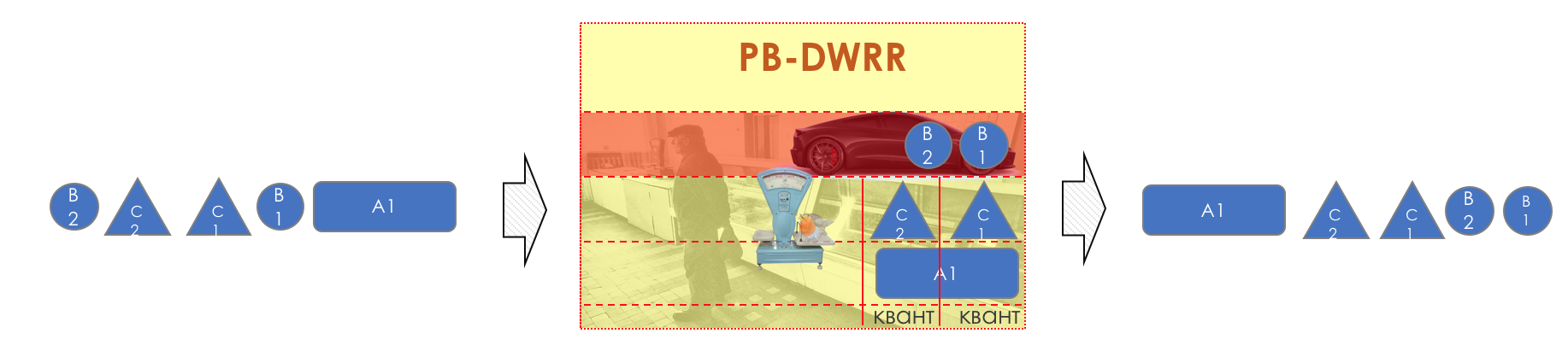 Existem várias abordagens para implementar o PB-DWRR. Em alguns deles, como no PQ, qualquer pacote que chega na fila de prioridade é removido imediatamente. Em outros, ele é acessado toda vez que o expedidor se move entre filas. Em terceiro lugar, um crédito e um quantum são introduzidos para ele, para que a fila de prioridade não possa espremer toda a faixa.Claro, não vamos analisá-los.
Existem várias abordagens para implementar o PB-DWRR. Em alguns deles, como no PQ, qualquer pacote que chega na fila de prioridade é removido imediatamente. Em outros, ele é acessado toda vez que o expedidor se move entre filas. Em terceiro lugar, um crédito e um quantum são introduzidos para ele, para que a fila de prioridade não possa espremer toda a faixa.Claro, não vamos analisá-los.Um breve resumo sobre mecanismos de envio
Por décadas, a humanidade vem tentando resolver o problema mais difícil de garantir o nível certo de serviço e a distribuição justa da banda. As filas eram a ferramenta principal; a única questão era como obter pacotes das filas, tentando colocá-los em uma única interface.Começando com o FIFO, ele inventou o PQ - a voz era capaz de coexistir com o surf, mas não havia como garantir a banda.Apareceram vários QF monstruosos, WFQ, que funcionavam se não por fluxo, então quase assim. O CB-WFQ chegou à sociedade de classes, mas não ficou mais fácil.Como alternativa, ele desenvolveu RR. Tornou-se um WRR e, em seguida, um DWRR.E nas profundezas de cada um dos despachantes vive o FIFO.No entanto, como você pode ver, não existe um expedidor universal que lide com todas as classes conforme necessário. É sempre uma combinação de despachantes, um dos quais resolve o problema de garantir atrasos, instabilidade e falta de perdas, e o outro aloca uma banda.CBWFQ + LLQ ou PB-WDRR ou WDRR + PQ.Em equipamentos reais, você pode especificar quais filas processar com qual despachante.CBWFQ, WDRR e seus derivados são os favoritos de hoje.PQ, FQ, WFQ, RR, WRR - não lamentamos e não lembramos (a menos que, é claro, estamos nos preparando para o CCIE Clipper).
Portanto, os despachantes são capazes de garantir velocidade, mas como limitá-la de cima?8. limite de velocidade
A necessidade de limitar a velocidade do tráfego à primeira vista é óbvia - não deixe o cliente fora de sua banda de acordo com o contrato.Sim Mas não é só isso.
Suponha que exista um RRL de 620 Mb / s de largura conectado por uma porta de 1 Gb / s. Se você colocar o gigabit inteiro nele, então, em algum lugar do RRL, que, provavelmente, não tem idéia de filas e QoS, serão iniciadas quedas monstruosas de natureza aleatória, não ligadas às prioridades reais do tráfego.No entanto, se você habilitar a modelagem de até 600 Mb / s no roteador, EF, CS6, CS7 não serão descartados e, em BE, AFx, a banda e as descargas serão distribuídas de acordo com seus pesos. O RRL alcançará 600 Mb / se obteremos uma imagem previsível.Outro exemplo é o Controle de Admissão. Por exemplo, dois operadores concordaram em confiar nas marcações um do outro, exceto no CS7 - se algo vier no CS7 - o descarte. Para CS6 e EF - forneça uma fila separada com garantia de atraso e sem perda.Mas e se o parceiro astuto começasse a despejar torrents nessas linhas? Adeus telefonia. E os protocolos provavelmente irão desmoronar.É lógico neste caso concordar com um parceiro sobre a tira. Tudo o que se encaixa no contrato é ignorado. O que não cabe - descarte ou transfira para outra fila - BE, por exemplo. Assim, protegemos nossa rede e nossos serviços.Existem duas abordagens fundamentalmente diferentes para a limitação de velocidade: polimento e modelagem. Eles resolvem um problema, mas de maneiras diferentes.Considere a diferença usando um exemplo desse perfil de tráfego:
Policiamento de trânsito
O policiamento limita a velocidade eliminando o excesso de tráfego.Tudo o que excede o valor definido, o polisador corta e joga fora. O que é cortado é esquecido. A imagem mostra que o pacote vermelho não está em trânsito após o polyser.E aqui está a aparência do perfil selecionado após o polisador:
O que é cortado é esquecido. A imagem mostra que o pacote vermelho não está em trânsito após o polyser.E aqui está a aparência do perfil selecionado após o polisador: devido à gravidade das medidas tomadas, isso é chamado de policiamento rígido .No entanto, existem outras ações possíveis.O vigilante geralmente trabalha em conjunto com um medidor de tráfego. O medidor colore as malas, como você se lembra, em verde, amarelo ou vermelho.E com base nessa cor já, o polisador pode não descartar o pacote, mas colocá-lo em outra classe. Essas são medidas suaves - Policiamento suave .Pode ser aplicado ao tráfego de entrada e ao tráfego de saída.Uma característica distintiva do polisador é a capacidade de absorver rajadas de tráfego e determinar a velocidade máxima permitida graças ao mecanismo Token Bucket.Isto é, de fato, tudo o que não está acima do valor definido não é cortado - é permitido ir um pouco além dele - pequenas explosões ou pequenos excessos da banda alocada são ignorados.O nome "policiamento" é ditado pela proporção bastante rígida da ferramenta em relação ao excesso de tráfego - descarte ou rebaixamento para uma classe baixa.
devido à gravidade das medidas tomadas, isso é chamado de policiamento rígido .No entanto, existem outras ações possíveis.O vigilante geralmente trabalha em conjunto com um medidor de tráfego. O medidor colore as malas, como você se lembra, em verde, amarelo ou vermelho.E com base nessa cor já, o polisador pode não descartar o pacote, mas colocá-lo em outra classe. Essas são medidas suaves - Policiamento suave .Pode ser aplicado ao tráfego de entrada e ao tráfego de saída.Uma característica distintiva do polisador é a capacidade de absorver rajadas de tráfego e determinar a velocidade máxima permitida graças ao mecanismo Token Bucket.Isto é, de fato, tudo o que não está acima do valor definido não é cortado - é permitido ir um pouco além dele - pequenas explosões ou pequenos excessos da banda alocada são ignorados.O nome "policiamento" é ditado pela proporção bastante rígida da ferramenta em relação ao excesso de tráfego - descarte ou rebaixamento para uma classe baixa.Modelagem de tráfego
A modelagem limita a velocidade protegendo o excesso de tráfego.Todo o tráfego recebido passa pelo buffer. Um shaper remove pacotes desse buffer a uma velocidade constante.Se a taxa de chegada de pacotes ao buffer for menor que a saída, eles não atrasam no buffer - eles passam direto.E se a taxa de chegada for maior que a produção, eles começarão a se acumular.A velocidade de saída é sempre a mesma.Assim, rajadas de tráfego são adicionadas ao buffer e serão enviadas quando atingirem a fila.Portanto, juntamente com o agendamento nas filas, a modelagem é a segunda ferramenta que contribui para o atraso total .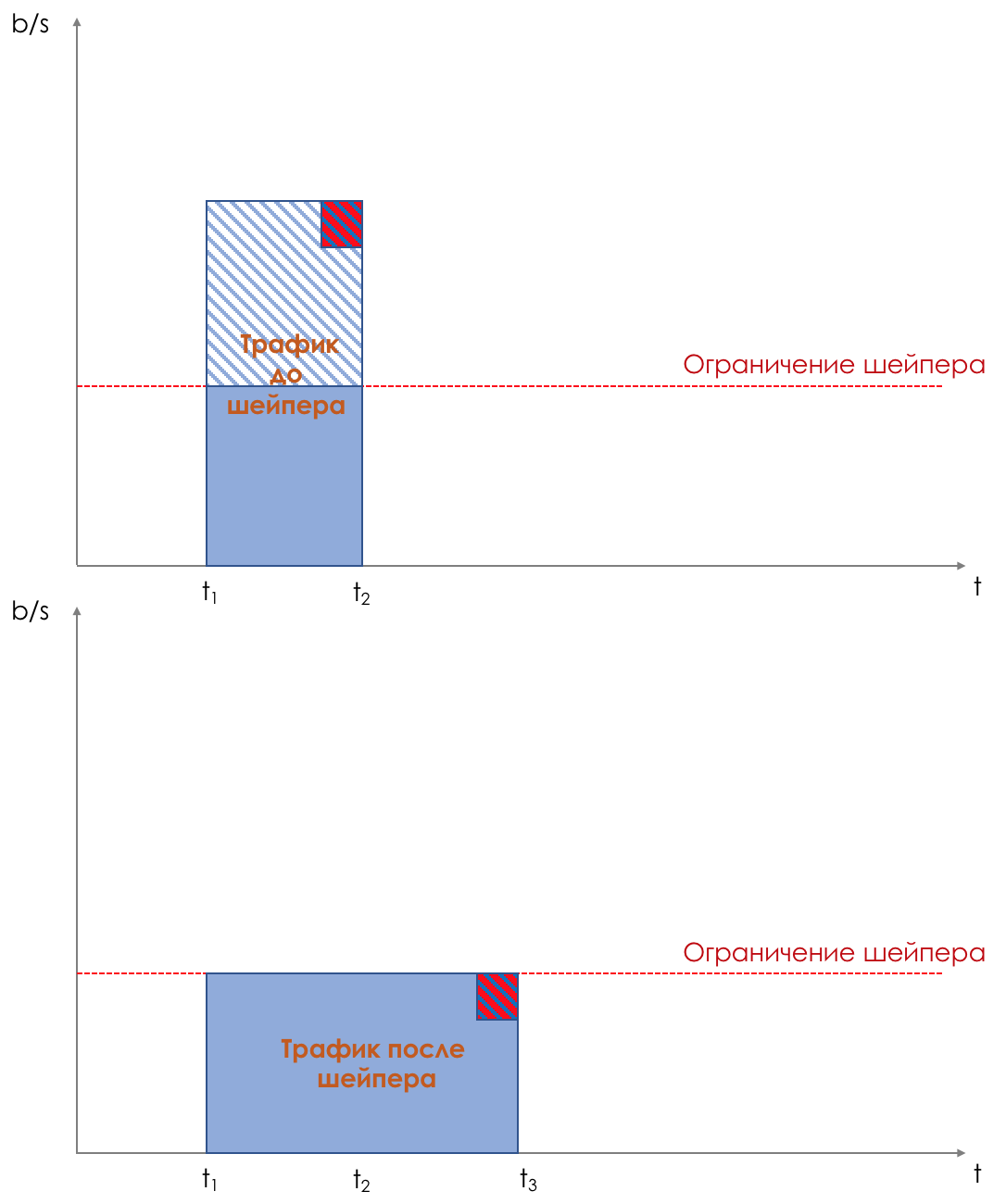 A ilustração mostra claramente como o pacote que chega no momento em que o buffer t2 chega no momento t3 na saída. t3-t2 é o atraso introduzido pelo modelador.Shaper é geralmente aplicado ao tráfego de saída.É assim que o perfil cuida do modelador.
A ilustração mostra claramente como o pacote que chega no momento em que o buffer t2 chega no momento t3 na saída. t3-t2 é o atraso introduzido pelo modelador.Shaper é geralmente aplicado ao tráfego de saída.É assim que o perfil cuida do modelador.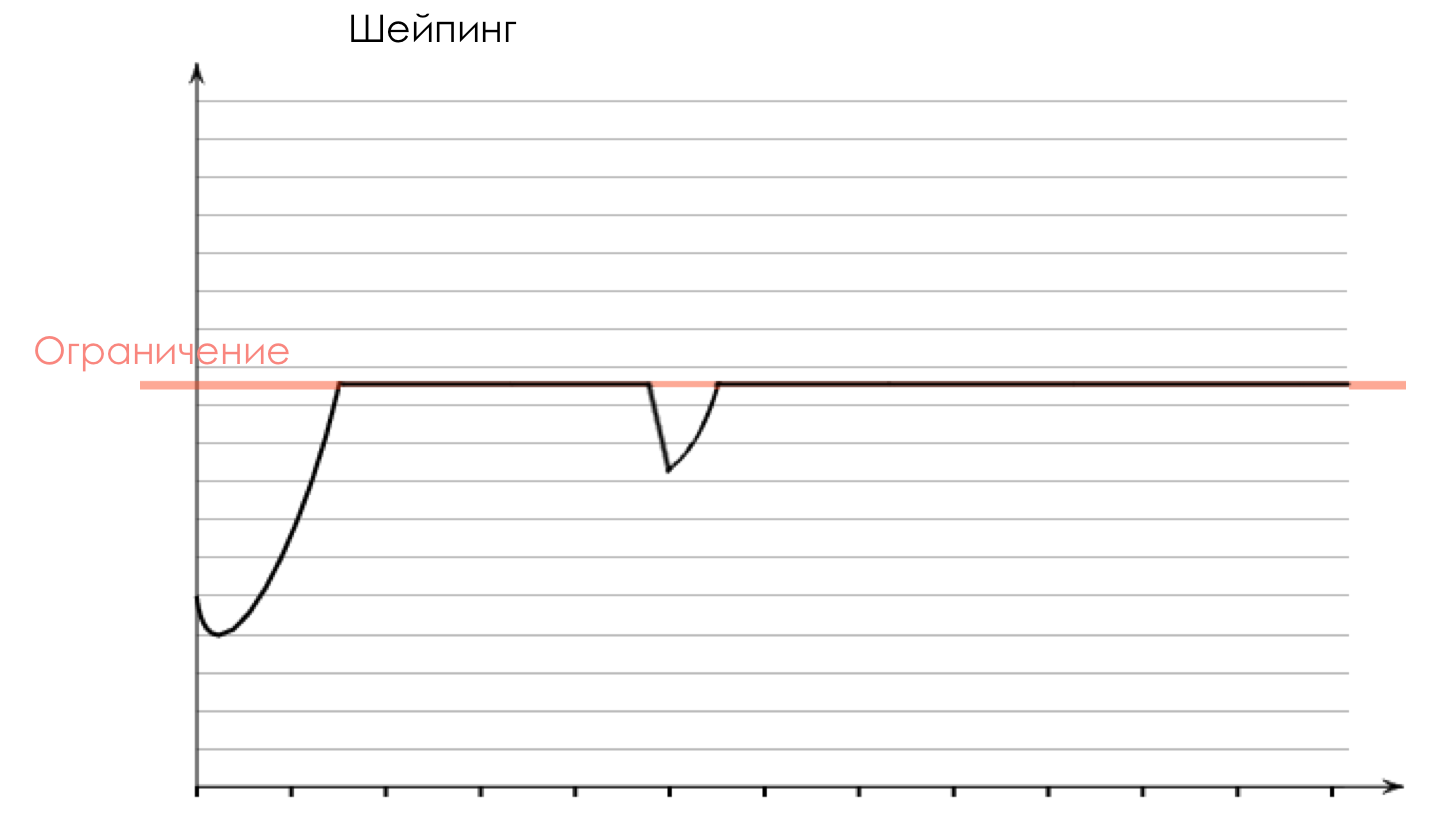 O nome "Shaping" indica que a ferramenta dá uma forma ao perfil de tráfego, suavizando-o.A principal vantagem dessa abordagem é o uso ideal da banda existente - em vez de diminuir o tráfego excessivo, adiamos.A principal desvantagem é um atraso imprevisível - quando o buffer estiver cheio, os pacotes permanecerão nele por um longo tempo. Portanto, a modelagem não é adequada para todos os tipos de tráfego.A modelagem usa o mecanismo Leaky Bucket.
O nome "Shaping" indica que a ferramenta dá uma forma ao perfil de tráfego, suavizando-o.A principal vantagem dessa abordagem é o uso ideal da banda existente - em vez de diminuir o tráfego excessivo, adiamos.A principal desvantagem é um atraso imprevisível - quando o buffer estiver cheio, os pacotes permanecerão nele por um longo tempo. Portanto, a modelagem não é adequada para todos os tipos de tráfego.A modelagem usa o mecanismo Leaky Bucket.Modelagem versus polimento
O trabalho do polisador é semelhante a uma faca que, movendo-se ao longo da superfície do óleo, corta o lado afiado do tubérculo.O trabalho de um modelador é semelhante a um rolo, que suaviza os tubérculos, distribuindo-os uniformemente sobre a superfície.O Shaper tenta não descartar pacotes enquanto eles são armazenados em buffer ao custo de um atraso maior.O polidor não introduz atrasos, mas descarta mais prontamente os pacotes.Os aplicativos que não são sensíveis a atrasos, mas cuja perda é indesejável, devem ser limitados a um modelador.Para aqueles para quem um pacote atrasado é igual a um pacote perdido, é melhor descartá-lo imediatamente - e depois polisar.Um modelador não afeta os cabeçalhos de pacotes e seu destino fora do nó, enquanto, após o polimento, o dispositivo pode reclassificar a classe no cabeçalho. Por exemplo, na entrada, o pacote tinha a classe AF11, a medição o pintou de amarelo dentro do dispositivo, na saída remarcou sua classe no AF12 - no próximo nó, ele terá uma maior probabilidade de queda.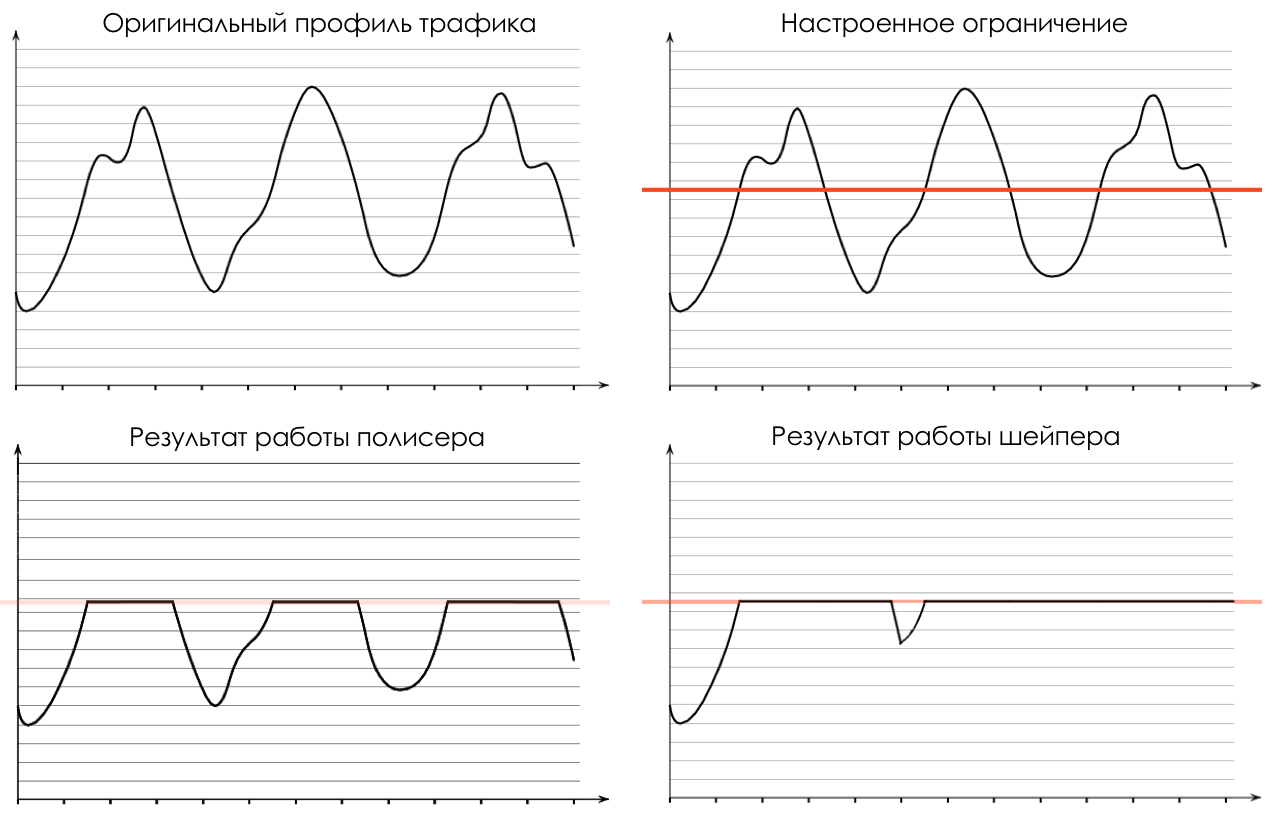
Prática de polimento e modelagem
O esquema é o mesmo:arquivo de configuração.Observamos esta imagem sem aplicar restrições: Vamos proceder da seguinte forma:
Vamos proceder da seguinte forma:- Na interface de entrada Linkmeup_R2 (e0 / 1), configuraremos o polimento - este será o controle de entrada. Nos termos do contrato, damos 10 Mb / s.
- Na interface de saída Linkmeup_R4 (e0 / 2), configure o shaping em 20 Mb / s.
Vamos começar com o shaper no Linkmeup_R4 .Combine tudo: class-map match-all TRISOLARANS_ALL_CM match any
Forma até 20Mb / s: policy-map TRISOLARANS_SHAPING class TRISOLARANS_ALL_CM shape average 20000000
Aplique à interface de saída: interface Ethernet0/2 service-policy output TRISOLARANS_SHAPING
Tudo o que deve sair (de saída) da interface Ethernet0 / 2 é de até 20 Mb / s.Arquivo de configuração do shaper.E aqui está o resultado: resulta uma linha bastante plana de taxa de transferência total e gráficos rasgados para cada fluxo individual.O fato é que restringimos o modelador à banda geral. No entanto, dependendo da plataforma, os fluxos individuais também podem ser modelados individualmente, ganhando oportunidades iguais.
resulta uma linha bastante plana de taxa de transferência total e gráficos rasgados para cada fluxo individual.O fato é que restringimos o modelador à banda geral. No entanto, dependendo da plataforma, os fluxos individuais também podem ser modelados individualmente, ganhando oportunidades iguais.
Agora configure o polimento no Linkmeup_R2.Adicionaremos um polyser à política existente. policy-map TRISOLARANS_ADMISSION_CONTROL class TRISOLARANS_TCP_CM police cir 10000000 bc 1875000 conform-action transmit exceed-action drop
A política já foi aplicada à interface: interface Ethernet0/1 service-policy input TRISOLARANS_ADMISSION_CONTROL
Aqui, indicamos a velocidade média permitida CIR (10 Mb / s) e o burst permitido Bc (1.875.000 bytes, cerca de 14,6 MB).Mais tarde, explicando como o polisador funciona, vou lhe dizer o que são CIR e Bc e como determinar esses valores.Arquivo de configuração do Polyser.Esta imagem é observada com polysing. Mudanças repentinas no nível de velocidade são imediatamente aparentes:
Mas uma imagem tão interessante é obtida se tornarmos o tamanho permitido de burst muito pequeno, por exemplo, 10.000 bytes. police cir 10000000 bc 10000 conform-action transmit exceed-action drop
 A velocidade geral caiu imediatamente para cerca de 2Mb / s.Tenha cuidado com a configuração de rajadas :)Tabela de teste.
A velocidade geral caiu imediatamente para cerca de 2Mb / s.Tenha cuidado com a configuração de rajadas :)Tabela de teste.
Balde com vazamento e balde de tokens
Parece fácil e claro. Mas como funciona na prática e é implementado em hardware?Um exemplo
O limite de 400 Mb / s é muito (ou pouco)? Em média, um cliente usa apenas 320. Mas às vezes sobe para 410 por 5 minutos. E às vezes até 460 por minuto. E às vezes até 500 por meio segundo.Como o linkmeup do fornecedor contratual pode dizer - 400 e é isso! Se você quiser mais, conecte-se à tarifa de 1Gb / s + 27 canais de anime.E podemos aumentar a fidelidade do cliente se isso não interferir com os outros, permitindo tais surtos.Como permitir 460 Mb / s por apenas um minuto, e não 30 ou para sempre?Como permitir 500 Mb / s, se a banda é gratuita, e pressionar 400, se outros consumidores aparecerem?Agora faça uma pausa, despeje um balde de forte.Vamos começar com o mecanismo mais simples usado pelo shaper - um balde com vazamento.Algoritmo de bucket com vazamento
Balde com vazamento é um balde com vazamento. Temos um balde com um buraco de um determinado tamanho na parte inferior. Os sacos são derramados / derramados neste balde de cima. E de baixo, eles fluem a uma taxa de bits constante.Quando o balde está cheio, novos pacotes começam a ser descartados.O tamanho do furo é determinado pelo limite de velocidade especificado, que para o Leaky Bucket é medido em bits por segundo.O volume do balde, sua plenitude e velocidade de saída determinam o atraso introduzido pelo modelador.Por conveniência, o volume da caçamba é geralmente medido em ms ou μs.Em termos de implementação, o Leaky Bucket é um buffer regular baseado em SD-RAM.Mesmo se a modelagem não estiver configurada explicitamente, na presença de rajadas que não passam na interface, os pacotes são temporariamente armazenados em buffer e transmitidos quando a interface é liberada. Isso também está moldando.O balde com vazamento é usado apenas para modelar e não é adequado para polimento.
Temos um balde com um buraco de um determinado tamanho na parte inferior. Os sacos são derramados / derramados neste balde de cima. E de baixo, eles fluem a uma taxa de bits constante.Quando o balde está cheio, novos pacotes começam a ser descartados.O tamanho do furo é determinado pelo limite de velocidade especificado, que para o Leaky Bucket é medido em bits por segundo.O volume do balde, sua plenitude e velocidade de saída determinam o atraso introduzido pelo modelador.Por conveniência, o volume da caçamba é geralmente medido em ms ou μs.Em termos de implementação, o Leaky Bucket é um buffer regular baseado em SD-RAM.Mesmo se a modelagem não estiver configurada explicitamente, na presença de rajadas que não passam na interface, os pacotes são temporariamente armazenados em buffer e transmitidos quando a interface é liberada. Isso também está moldando.O balde com vazamento é usado apenas para modelar e não é adequado para polimento.Algoritmo de bucket de token
Muitas pessoas pensam que Token Bucket e Leaking Bucket são a mesma coisa. Apenas Einstein estava muito mais enganado, acrescentando uma constante cosmológica.Os chips de comutação não entendem realmente a que horas são, eles ficam ainda piores quantos bits eles transmitiram por unidade de tempo. O trabalho deles é trilhar.Esse bit se aproxima outro 400.000.000 de bits por segundo, ou já 400.000 001? Os desenvolvedores do ASIC tiveram um desafio de engenharia não trivial.Foi dividido em duas subtarefas:
Os desenvolvedores do ASIC tiveram um desafio de engenharia não trivial.Foi dividido em duas subtarefas:- Na verdade, limitando a velocidade descartando pacotes desnecessários com base em uma condição muito simples. Realizado na troca de chips.
- Criando essa condição simples, que lida com um chip mais complexo (mais especializado), acompanhando o tempo.
O algoritmo que resolve o segundo problema é chamado de Token Bucket. Sua ideia é elegante e simples (não).A tarefa do Token Bucket é passar o tráfego se estiver dentro da restrição e descartar / pintar em vermelho, se não estiver.É importante permitir rajadas de tráfego, pois isso é normal.E se, no Leaky Bucket, as explosões foram armazenadas em buffer, o Token Bucket não armazena em buffer nada.Taxa única - marcação de duas cores
Por enquanto, não preste atenção ao nome =)Temos um balde no qual as moedas caem a uma velocidade constante - 400 megamonets por segundo, por exemplo.O volume do balde é de 600 milhões de moedas. Ou seja, é preenchido em um segundo e meio.Perto há duas correias transportadoras: uma entrega pacotes e a segunda leva embora.Para chegar ao transportador, o pacote deve pagar.Para isso, ele pega moedas de um balde de acordo com seu tamanho. Grosso modo - quantos bits - tantas moedas.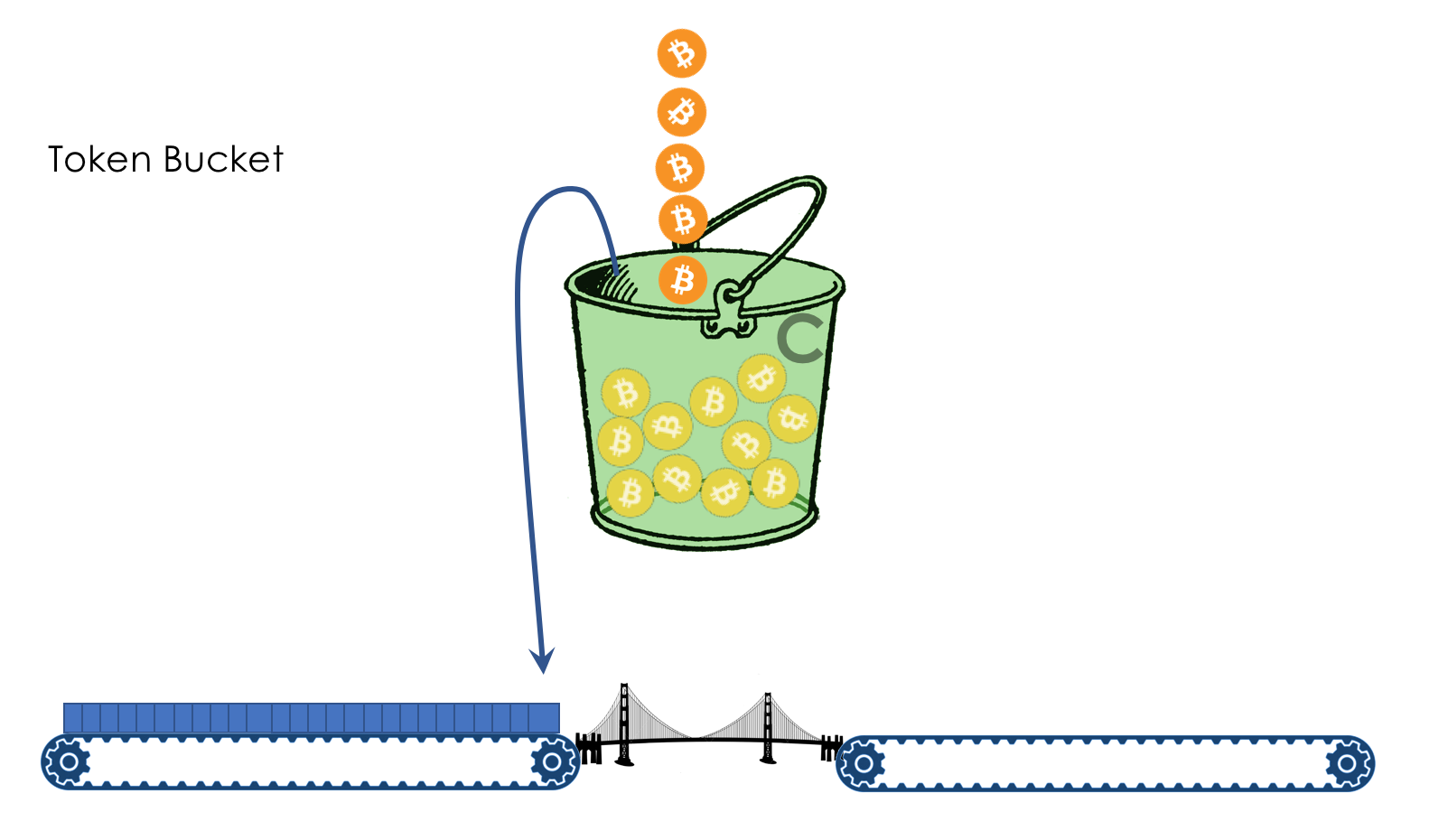
 Se o balde estiver vazio e não houver moedas suficientes na sacola, ele será pintado na cor vermelha do sinal e descartado. Infelizmente, Selyava. Nesse caso, as moedas não são removidas do balde.
Se o balde estiver vazio e não houver moedas suficientes na sacola, ele será pintado na cor vermelha do sinal e descartado. Infelizmente, Selyava. Nesse caso, as moedas não são removidas do balde.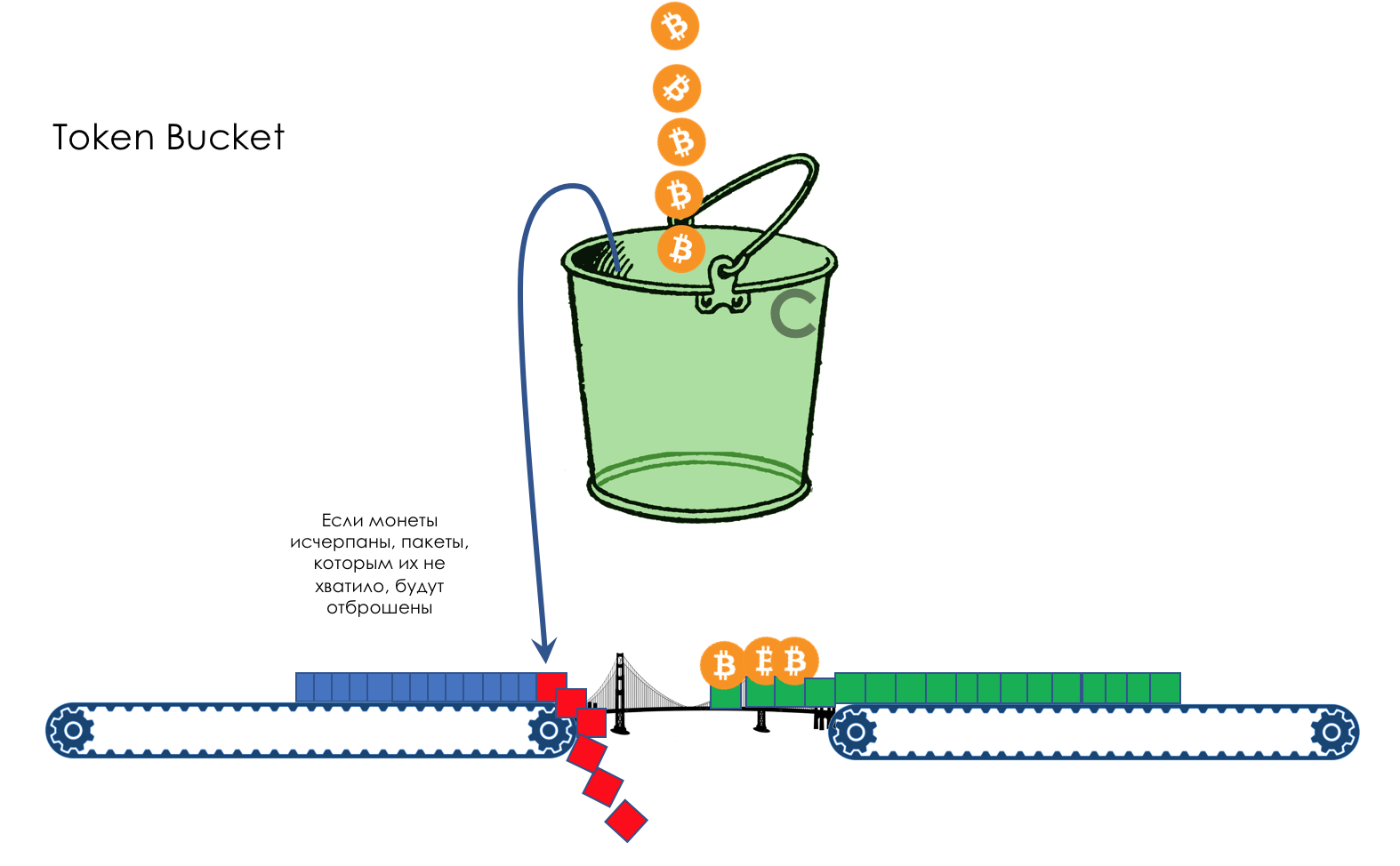 O próximo pacote de moedas já pode ser suficiente - primeiro, o pacote pode ser menor e, segundo, ataca mais moedas durante esse período.Se o balde já estiver cheio, todas as novas moedas serão jogadas fora.
O próximo pacote de moedas já pode ser suficiente - primeiro, o pacote pode ser menor e, segundo, ataca mais moedas durante esse período.Se o balde já estiver cheio, todas as novas moedas serão jogadas fora.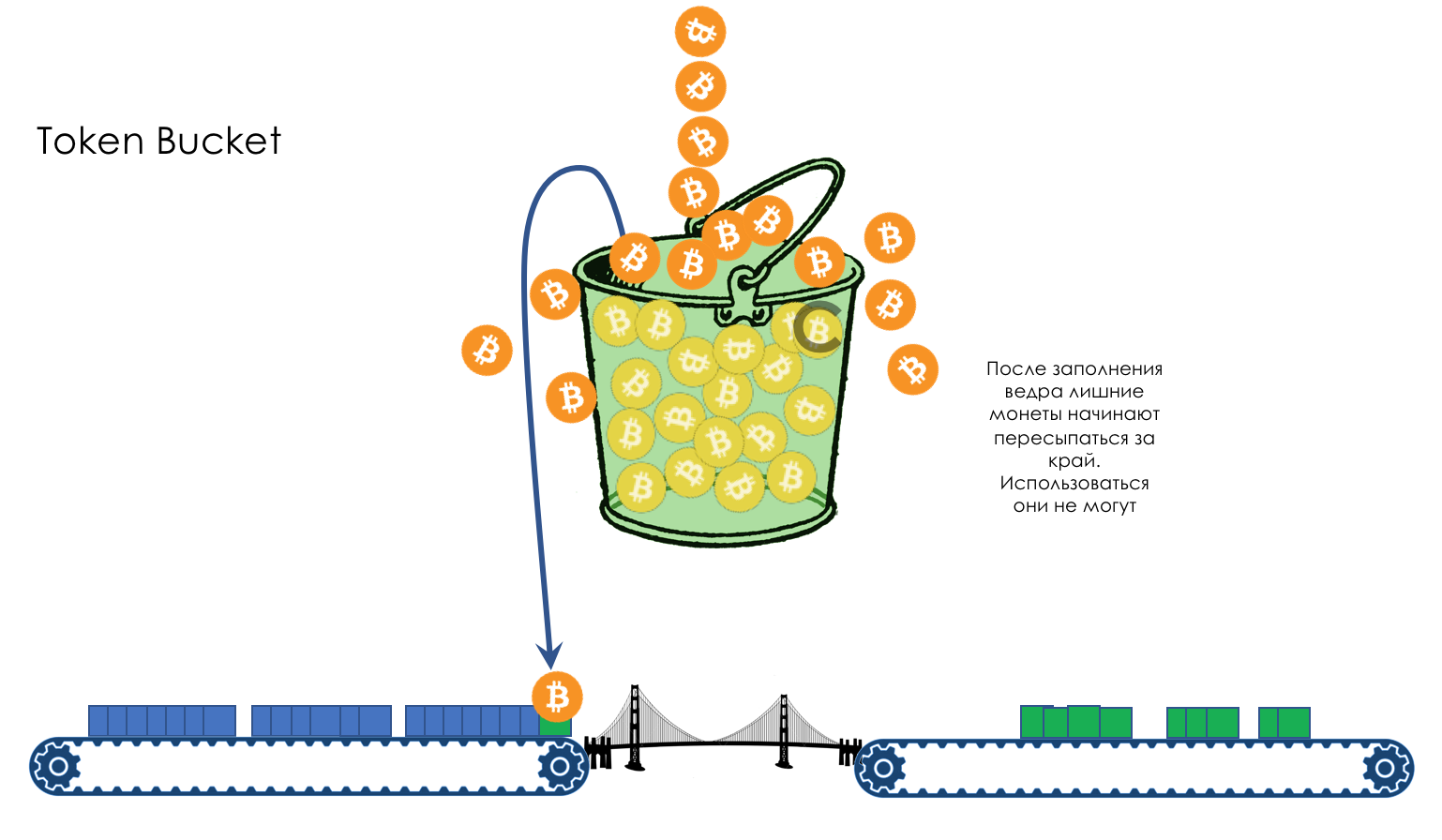 Tudo depende da taxa de chegada de pacotes e do seu tamanho.Se for estável ou inferior a 400 MB por segundo, sempre haverá moedas suficientes.Se superior, alguns dos pacotes serão perdidos.
Tudo depende da taxa de chegada de pacotes e do seu tamanho.Se for estável ou inferior a 400 MB por segundo, sempre haverá moedas suficientes.Se superior, alguns dos pacotes serão perdidos.Um exemplo mais específico com gifs, como todos gostamos.
- Há um balde com capacidade de 2500 bytes. No momento inicial, ele contém 550 tokens.
Existem três pacotes de 1000 bytes no pipeline que desejam ser enviados para a interface.
Em cada intervalo de tempo, 500 bytes caem no intervalo (500 * 8 = 4.000 bits / intervalo de tempo - limite de poliser). - 500 . . 1000 , 1050 — . . 1000 .
50 . - 500 — 550. — 1000 — .
, . - 500 — 1050. — 1000 — .
, .
2500 , 2500 — . MTU , , , 1,5-2 .
:
CBS = CIR ( )*1,5 ()/8 ( )
, (Bc), , (1 875 000 ) . (10 000 ), , MTU, .
Por que o volume da caçamba? O fluxo de bits nem sempre é uniforme, isso é óbvio. Um limite de 400 Mb / s não é uma assíntota - o tráfego pode ultrapassá-lo. O volume de moedas armazenadas permite que pequenas rajadas voem sem serem descartadas, mas mantenha a velocidade média em 400 Mb / s.Por exemplo, um fluxo estável de 399 Mb / s em 600 segundos permitirá que o balde seja preenchido até a borda.Além disso, o tráfego pode subir para 1000Mb / se permanecer nesse nível por 1 segundo - 600 Mm (Megamonet) de estoque e banda garantida de 400 Mm / s.Ou o tráfego pode subir para 410 Mb / se permanecer assim por 60 segundos.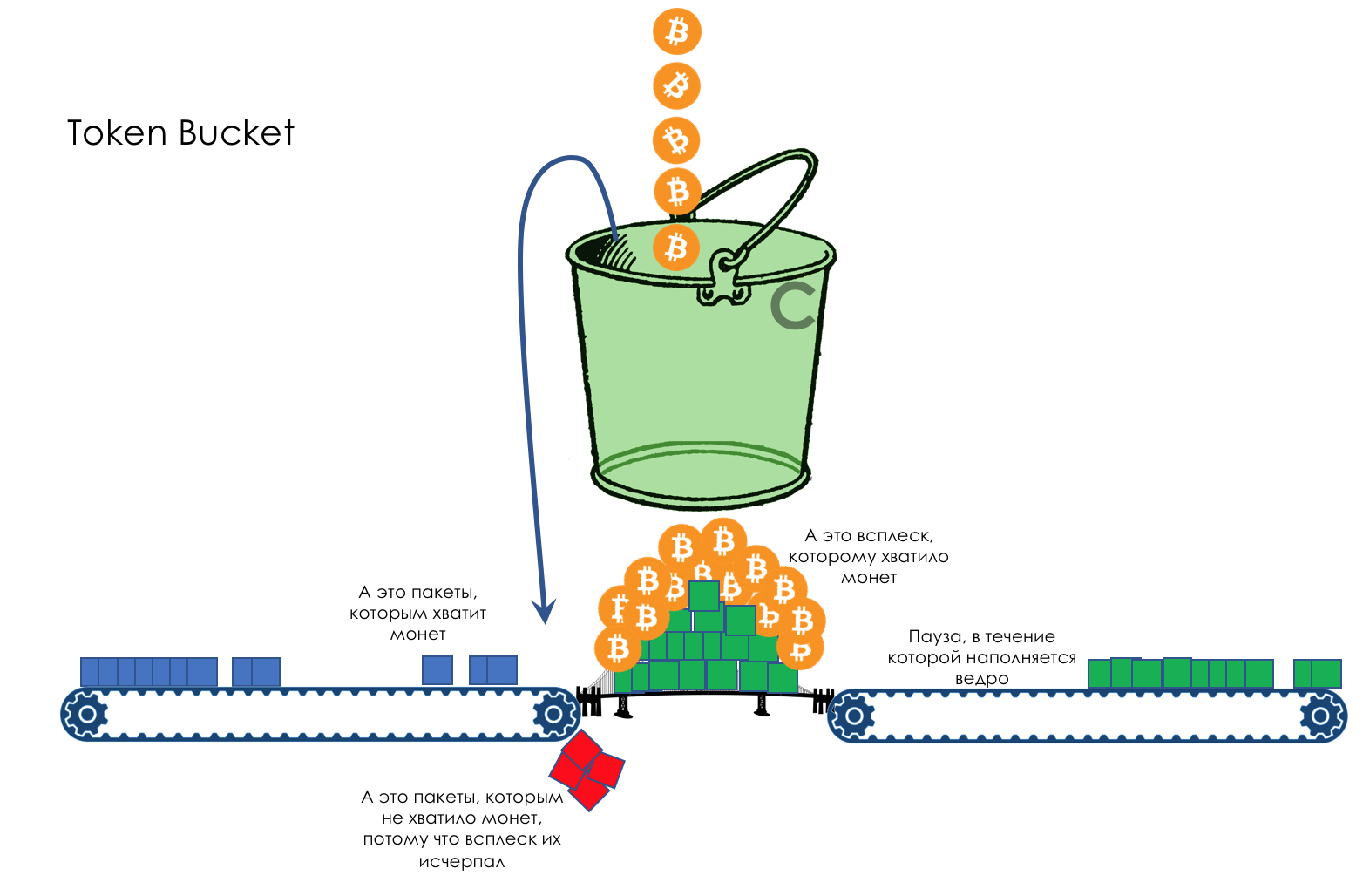 Ou seja, o suprimento de moedas permite que você vá um pouco além da restrição por um longo período de tempo ou jogue uma onda curta, mas alta.Agora, para a terminologia.A taxa de recebimento de moedas no balde - CIR - Committed Information Rate (velocidade média garantida). Medido em bits por segundo.O número de moedas que podem ser armazenadas no balde - CBS - Tamanho de Burst Confirmado . Tamanho máximo permitido de rajada. Medido em bytes. Às vezes, como você deve ter notado, é chamado de Bc .Tc - O número de moedas (token) no balde C (CBS) no momento.
Ou seja, o suprimento de moedas permite que você vá um pouco além da restrição por um longo período de tempo ou jogue uma onda curta, mas alta.Agora, para a terminologia.A taxa de recebimento de moedas no balde - CIR - Committed Information Rate (velocidade média garantida). Medido em bits por segundo.O número de moedas que podem ser armazenadas no balde - CBS - Tamanho de Burst Confirmado . Tamanho máximo permitido de rajada. Medido em bytes. Às vezes, como você deve ter notado, é chamado de Bc .Tc - O número de moedas (token) no balde C (CBS) no momento.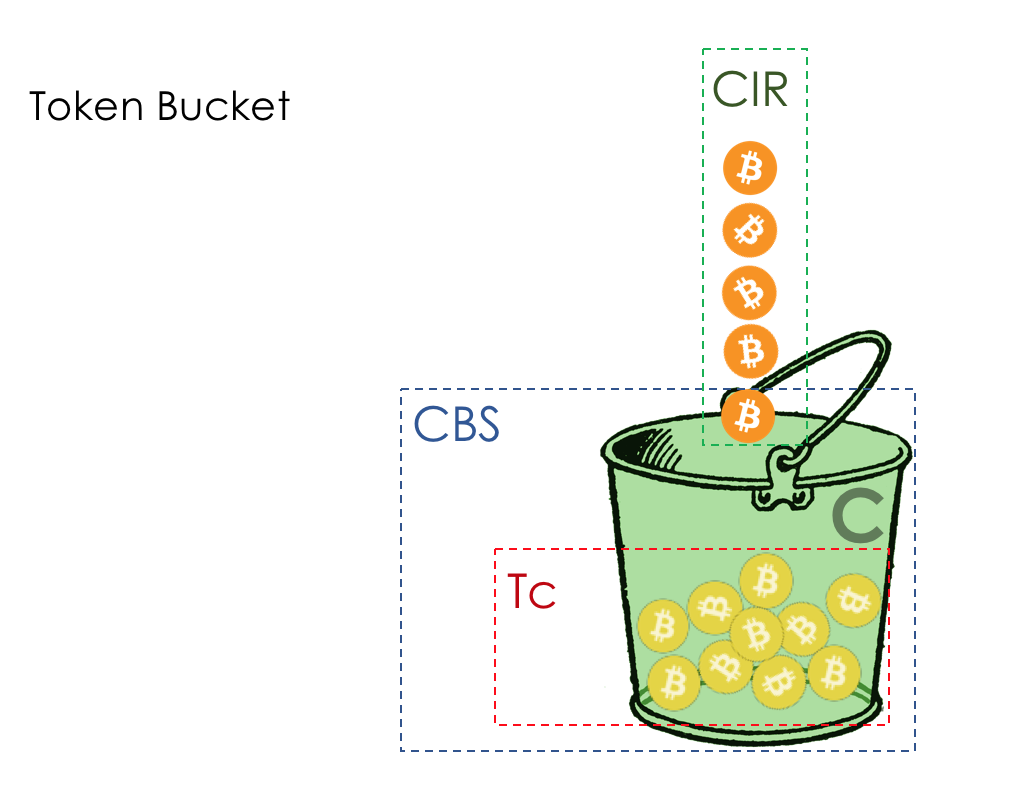
" Tc ", , RFC 2697 ( A Single Rate Three Color Marker ).
Tc, , .
.
, , Token Bucket, TDM (Time-Division Multiplexing) — .
— , , .
CIR . .
, — , — , — .
, .
( Cisco) Tc , — Bc . Bc = CIR*Tc .
Tc Bc .
Este é o cenário mais simples. É chamado Taxa Única - Duas Cores .Taxa única significa que existe apenas uma velocidade média permitida e Duas cores - que você pode colorir o tráfego em uma das duas cores: verde ou vermelho.- Se o número de moedas (bits) disponíveis no balde C for maior que o número de bits que precisam ser ignorados no momento, o pacote será colorido em verde - uma baixa probabilidade de queda no futuro. As moedas são removidas do balde.
- Caso contrário, a embalagem é pintada de vermelho - uma alta probabilidade de queda (ou, mais frequentemente, queda momentânea). Moedas assim baldes C é retirado .
Usado para polir no PHB CS e EF, onde a velocidade não é esperada, mas se ocorrer, é melhor descartá-lo imediatamente.Além disso, consideraremos mais difícil: Taxa Única - Três Cores.Taxa única - marcação de três cores
A desvantagem do esquema anterior é que existem apenas duas cores. E se não queremos deixar tudo acima da velocidade média permitida, mas queremos ser ainda mais fiéis?o TCM-sr ( taxa única - a Três a A marcação a cores ) entra no segundo segmento em - E . Neste momento, as moedas não são colocados num balde cheio com o C , são vertida em E . O EBS é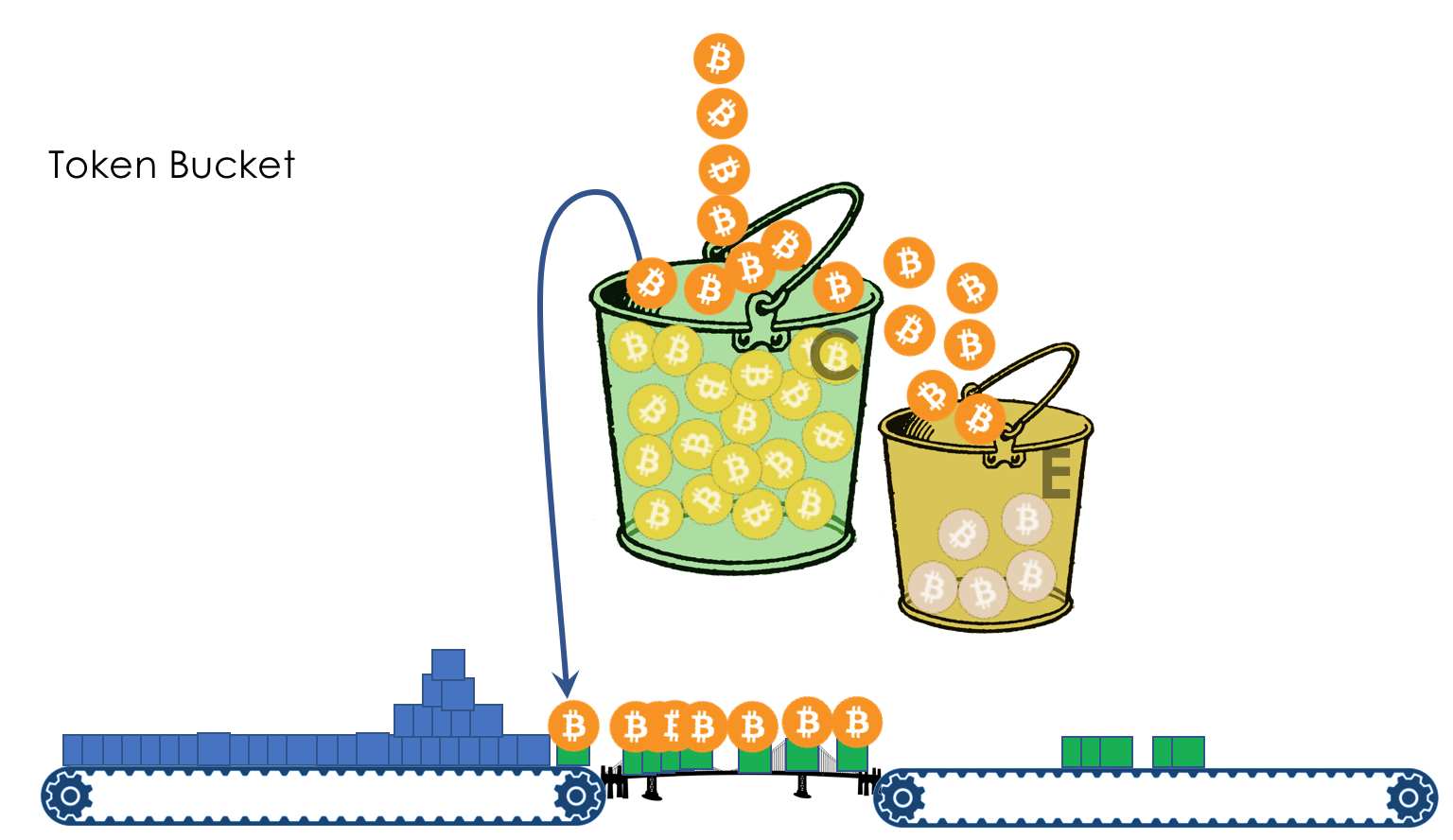 adicionado ao CIR e CBS - Excesso de tamanho de rajada - tamanho permitido de rajada durante picos. Te - o número de moedas em um balde E .
adicionado ao CIR e CBS - Excesso de tamanho de rajada - tamanho permitido de rajada durante picos. Te - o número de moedas em um balde E . Digamos que um pacote de tamanho B veio ao longo do pipeline.
Digamos que um pacote de tamanho B veio ao longo do pipeline. Então
- C , . C B (: Tc — B).
- C , E . , ( ), E B .

- E , , .

Observe que, para um pacote específico, Tc e Te não são cumulativos .Ou seja, o tamanho do pacote de 8000 bytes não vai funcionar, mesmo em um balde C é de 3.000 moedas, e E - 7000. O C não é suficiente, na E não é o suficiente - nós colocar um selo vermelho - shuruy aqui.Este é um design muito elegante. Todo o tráfego que cai dentro da restrição CIR + CBS média (o autor sabe que é impossível adicionar bits / se bytes tão diretamente) fica verde. Nos horários de pico, quando o cliente fica sem moedas no balde C , ele ainda mantém o estoque de Te no balde E acumulado durante o tempo de inatividade .Ou seja, você pode pular um pouco mais, mas no caso de congestionamento, é mais provável que eles sejam descartados.sr-TCM é descrito na RFC 2697 .Usado para polir no PHB AF.Bem, o último sistema é o mais flexível e, portanto, complexo - Duas taxas - Três cores.Marcação de duas taxas - três cores
O modelo Tr-TCM nasceu da ideia de que não é em detrimento de outros usuários e tipos de tráfego, por que não dar ao cliente oportunidades um pouco mais agradáveis ou vender melhor.Vamos dizer a ele que ele tem garantia de 400 Mb / s e, se houver recursos gratuitos, 500. Você está pronto para pagar mais 30 rublos?Outro balde P é adicionado .Assim:CIR - velocidade média garantida.CBS é o mesmo tamanho de respingo permitido (volume C da caçamba ).PIR - Peak Information Rate - velocidade média máxima.EBS - tamanho permitido de rajada durante picos (Volume da caçamba P ).Diferentemente do sr-TCM, no tr-TCM, as moedas agora são entregues de forma independente nos dois baldes. Em C - com a velocidade do CIR, em P - PIR.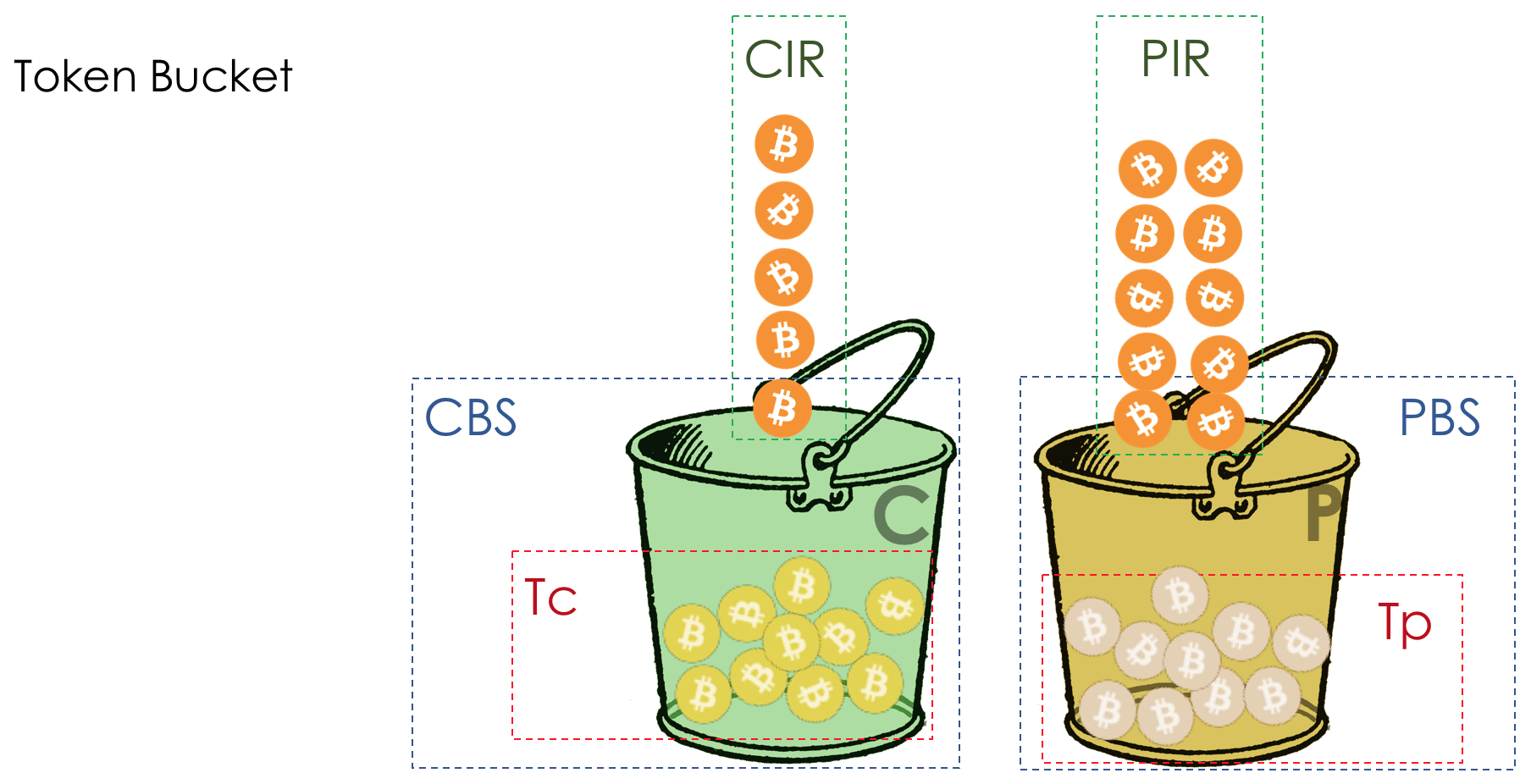 Quais são as regras?Um pacote de tamanho B bytes chega .
Quais são as regras?Um pacote de tamanho B bytes chega .- Se não houver moedas suficientes no balde P , o pacote será marcado em vermelho. As moedas não são retiradas . Caso contrário:
- Se não houver moedas suficientes no balde C , o pacote será marcado em amarelo e as moedas B serão retiradas do balde P. Caso contrário:
- O pacote está marcado em verde e as moedas B são retiradas dos dois baldes .
 Ou seja, as regras no tr-TCM são diferentes.Enquanto o tráfego estiver dentro da velocidade garantida, as moedas serão removidas dos dois baldes. Devido a isso, quando as moedas acabarem no balde C , elas permanecerão em P , mas apenas para não exceder o PIR (se removidas apenas de C , então P se encheria mais e daria uma velocidade muito mais rápida).Assim, se estiver acima do garantido, mas abaixo do pico, as moedas são removidas apenas de P , porque em C já não há nada.O tr-TCM monitora não apenas rajadas, mas também uma velocidade de pico constante.O tr-TCM é descrito na RFC 2698 .Também usado para polimento em PHB AF.
Ou seja, as regras no tr-TCM são diferentes.Enquanto o tráfego estiver dentro da velocidade garantida, as moedas serão removidas dos dois baldes. Devido a isso, quando as moedas acabarem no balde C , elas permanecerão em P , mas apenas para não exceder o PIR (se removidas apenas de C , então P se encheria mais e daria uma velocidade muito mais rápida).Assim, se estiver acima do garantido, mas abaixo do pico, as moedas são removidas apenas de P , porque em C já não há nada.O tr-TCM monitora não apenas rajadas, mas também uma velocidade de pico constante.O tr-TCM é descrito na RFC 2698 .Também usado para polimento em PHB AF.
Resumo do limite de velocidade
Enquanto moldar adia o tráfego quando excedido, o polimento o descarta.A modelagem não é adequada para aplicativos sensíveis à latência e instabilidade.Para implementar o polimento em hardware, o algoritmo Token Bucket é usado para modelar - Leaky Bucket.O Token Bucket pode ser:- Com um balde - Taxa única - Marcação de duas cores. Permite rajadas válidas.
- Com duas caçambas - Taxa única - Marcação de três cores (sr-TCM). O excedente do balde C (CBS) é derramado no balde E. Permite picos permitidos e redundantes.
- Com duas caçambas - Marcação de duas taxas - três cores (tr-TCM). As caçambas C e P (PBS) reabastecem independentemente em diferentes velocidades. Permite velocidade máxima e rajadas permitidas e excessivas.
O sr-TCM concentra-se na quantidade de tráfego acima do limite. tr-TCM - na velocidade com que chega.O polimento pode ser usado na entrada e na saída do dispositivo. A modelagem é predominantemente na saída.Para PHB CS e EF, é usada a marcação de taxa única de duas cores.Para AF, sr-TCM ou tr-TCM.Para uma melhor compreensão, recomendo consultar a RFC original ou ler aqui .Token Bucket . , , , , .
, — , . , , , — .
, . — . .
Acima, descrevi todos os mecanismos básicos da QoS, se não aprofundar na QoS hierárquica. Um sistema sofisticado com muitas partes móveis.Tudo estava bem (certo?) Soou até agora, mas o que está acontecendo sob o painel externo de baunilha do roteador?Ao longo dos anos, os fornecedores adicionaram mais e mais contornos, desenvolveram chips sofisticados, buffers expandidos, por um lado, para acompanhar o crescente volume de tráfego e suas novas categorias e, por outro, para resolver os problemas crescentes causados pelo primeiro parágrafo.A corrida em andamento. Os pacotes não devem ser perdidos se o competidor não os perder. Você não pode recusar a funcionalidade se um oponente estiver ao lado dele sob as portas do cliente.Ida para o covil de propriedade!9. Implementação de QoS por hardware
Neste capítulo, assumo a tarefa ingrata. Se você o descrever da maneira mais simples possível, sempre haverá quem diga que nem tudo é assim na realidade.Se você o descrever como está, o leitor descartará o artigo, porque ele se tornará um desenho de um submarino, mais precisamente, desenhos de três barcos com lápis de cores diferentes em uma folha.Em geral, declaro que, na realidade, tudo não é o mesmo que na realidade, e irei de acordo com a versão de uma apresentação simples.Perdoe-me, meu perfeccionista.O que controla o comportamento do nó e aciona os mecanismos apropriados em relação ao pacote? A prioridade que ele tem em um dos títulos? Sim e não Como mencionado acima, dentro de um dispositivo de rede, o cabeçalho de comutação padrão geralmente deixa de existir.
Como mencionado acima, dentro de um dispositivo de rede, o cabeçalho de comutação padrão geralmente deixa de existir. Assim que um pacote chega ao chip de comutação, os cabeçalhos são removidos e enviados para análise, e a carga útil permanece em algum tipo de buffer temporário.Com base nos cabeçalhos, ocorre uma classificação (BA ou MF) e é tomada uma decisão sobre o encaminhamento.Após um momento, um cabeçalho interno com metadados sobre o pacote fica pendurado no pacote.Esses metadados carregam muitas informações importantes - o endereço do remetente e do receptor, o chip de saída, o número de série da célula, se houve fragmentação de pacotes e a marcação de classe (CoS) e Precedência de queda são obrigatórias. Somente marcação no formato interno - pode coincidir com o DSCP ou não.Em princípio, dentro da caixa, você pode definir um comprimento de marcação arbitrário sem estar vinculado aos padrões e definir ações muito flexíveis com o pacote.Na Cisco, a marcação interna é chamada QoS Group, na Juniper - Forwarding Class, a Huawei não decidiu: em algum lugar chama prioridades internas, em algum lugar prioridades locais, em algum lugar Service-Class e em algum lugar apenas CoS. Adicione nomes para outros fornecedores nos comentários - adicionarei.Essa marcação interna é atribuída com base na classificação que o nó executou.É importante que, a menos que seja indicado de outra forma, a rotulagem interna funcione apenas dentro do nó, mas não apareça na rotulagem nos cabeçalhos do pacote que será enviado a partir do nó - permanecerá o mesmo.No entanto, na entrada do domínio DS após a classificação, geralmente há uma nova marcação em uma determinada classe de serviço aceita nesta rede. Em seguida, a rotulagem interna é convertida no valor aceito para esta classe na rede e é registrada no cabeçalho do pacote que está sendo enviado.Os rótulos internos CoS e Drop Precedence definem o comportamento apenas dentro de um determinado nó e não são explicitamente repassados aos vizinhos, exceto pela re-rotulagem dos cabeçalhos.CoS e Precedência de Queda definem o PHB, seus mecanismos e parâmetros: prevenção de congestionamentos, gerenciamento de congestionamentos, programação e remarcação.
Assim que um pacote chega ao chip de comutação, os cabeçalhos são removidos e enviados para análise, e a carga útil permanece em algum tipo de buffer temporário.Com base nos cabeçalhos, ocorre uma classificação (BA ou MF) e é tomada uma decisão sobre o encaminhamento.Após um momento, um cabeçalho interno com metadados sobre o pacote fica pendurado no pacote.Esses metadados carregam muitas informações importantes - o endereço do remetente e do receptor, o chip de saída, o número de série da célula, se houve fragmentação de pacotes e a marcação de classe (CoS) e Precedência de queda são obrigatórias. Somente marcação no formato interno - pode coincidir com o DSCP ou não.Em princípio, dentro da caixa, você pode definir um comprimento de marcação arbitrário sem estar vinculado aos padrões e definir ações muito flexíveis com o pacote.Na Cisco, a marcação interna é chamada QoS Group, na Juniper - Forwarding Class, a Huawei não decidiu: em algum lugar chama prioridades internas, em algum lugar prioridades locais, em algum lugar Service-Class e em algum lugar apenas CoS. Adicione nomes para outros fornecedores nos comentários - adicionarei.Essa marcação interna é atribuída com base na classificação que o nó executou.É importante que, a menos que seja indicado de outra forma, a rotulagem interna funcione apenas dentro do nó, mas não apareça na rotulagem nos cabeçalhos do pacote que será enviado a partir do nó - permanecerá o mesmo.No entanto, na entrada do domínio DS após a classificação, geralmente há uma nova marcação em uma determinada classe de serviço aceita nesta rede. Em seguida, a rotulagem interna é convertida no valor aceito para esta classe na rede e é registrada no cabeçalho do pacote que está sendo enviado.Os rótulos internos CoS e Drop Precedence definem o comportamento apenas dentro de um determinado nó e não são explicitamente repassados aos vizinhos, exceto pela re-rotulagem dos cabeçalhos.CoS e Precedência de Queda definem o PHB, seus mecanismos e parâmetros: prevenção de congestionamentos, gerenciamento de congestionamentos, programação e remarcação.
Quais círculos passam os pacotes entre as interfaces de entrada e saída? Analisei em um artigo anterior . Na verdade, acabou sendo programado, já que em algum momento ficou óbvio que, sem entender a arquitetura, era prematuro falar sobre QoS.No entanto, vamos repetir.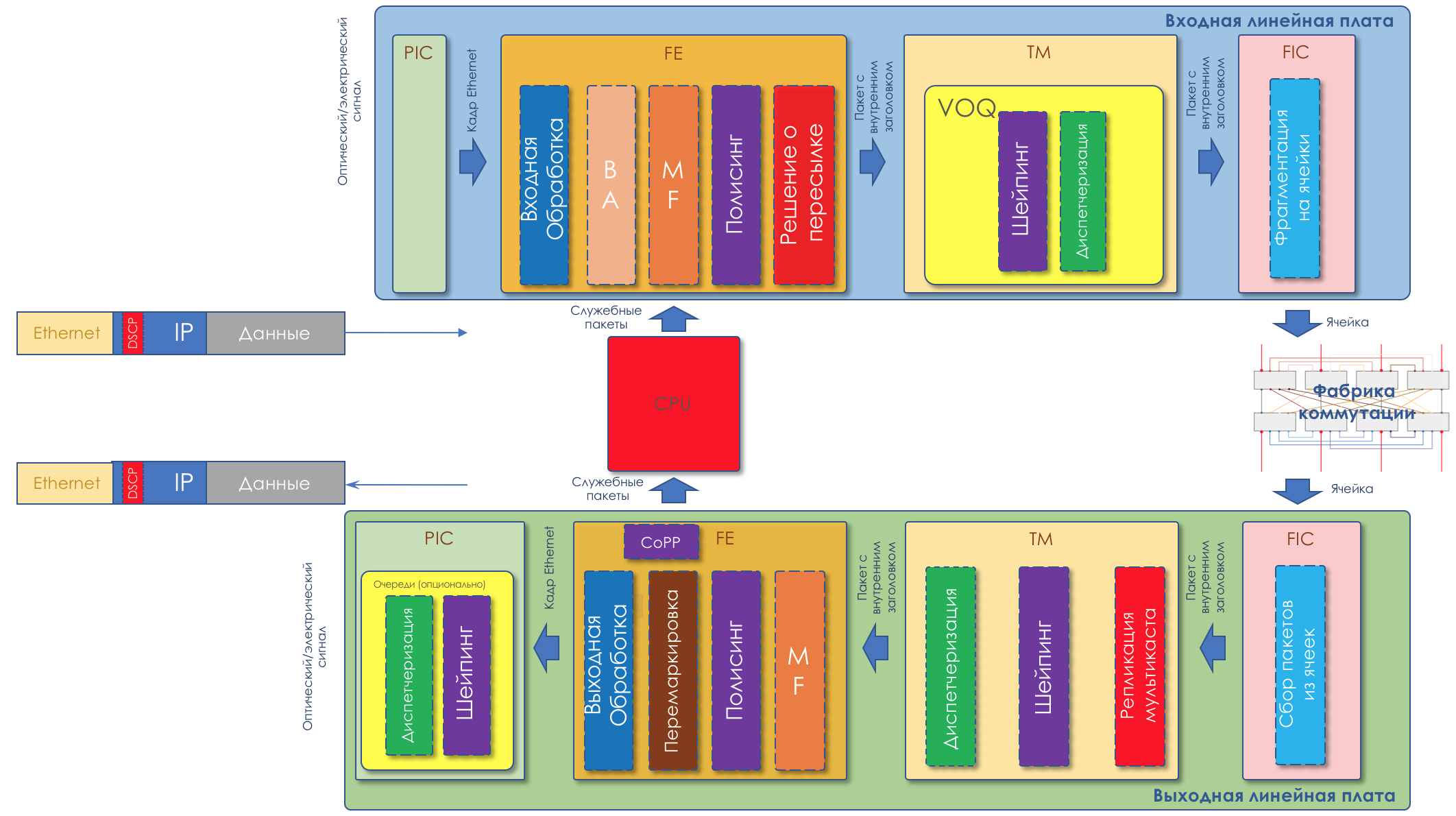
- O sinal atinge a interface de entrada física e seu chip (PIC). Um fluxo de bits flui dele e, em seguida, um pacote com todos os cabeçalhos.
- Ao lado do chip de comutação de entrada (FE), onde os cabeçalhos são separados do corpo do pacote. A classificação ocorre e é determinado para onde o pacote precisa ser enviado mais adiante.
- Ao lado da fila de entrada (TM / VOQ). Já aqui os pacotes estão dispostos em diferentes filas com base em sua classe.
- Além da fábrica de comutação (se houver).
- Ao lado da fila de saída (TM).
- (FE), .
- (, ) (PIC).
Nesse caso, o roteador deve resolver uma equação complexa.Expanda tudo em classes, forneça a alguém uma banda larga, alguém com baixa latência, alguém que não garanta perdas.E, ao mesmo tempo, tenha tempo para pular todo o tráfego, se possível.Além disso, você precisa fazer a modelagem, possivelmente polindo. Se ocorrer uma sobrecarga repentina, lide com ela.E isso não está contando as pesquisas, processamento ACL, contagem de estatísticas.Compartilhamento não invejável. Mas robôs injetam, não um homem.De fato, existem apenas dois locais onde os mecanismos de QoS funcionam - um chip de comutação e um chip / fila de Gerenciamento de Tráfego.Ao mesmo tempo, ocorrem operações no chip de comutação que requerem análise ou ações com cabeçalhos.- Classificação
- Polimento
- Remarcação
A TM cuida do resto. Basicamente, são operações de rotina com um algoritmo predefinido e parâmetros personalizados:- Prevenção de congestionamento
- Gerenciamento de congestionamento
- Moldar
O TM é um buffer inteligente, geralmente baseado em SD-RAM.Ele é inteligente porque, a) programável, b) ele pode fazer todo tipo de coisas complicadas com filas.Ele é frequentemente distribuído - os chips SD-RAM estão localizados em cada placa de interface e, juntos, são combinados no VOQ (Virtual Output Queue), que resolve o problema de bloqueio de chefe de linha.O fato é que, se o chip de comutação ou a interface de saída for bloqueada, eles pedem que o chip de entrada diminua a velocidade e não envie tráfego por algum tempo. Se houver apenas uma fila em todas as direções, é muito decepcionante que todos os outros sofram de uma interface de saída. Este é o chefe da linha de bloqueio.O VOQ, na placa da interface de entrada, cria várias filas de saída virtual para cada interface de saída existente.Além disso, essas linhas de equipamentos modernos levam em consideração a rotulagem da embalagem.Sobre o VOQ é descrito em detalhes suficientes em uma série de notas aqui .A propósito, eles são realmente colocados na fila, estão sendo promovidos, não são os próprios pacotes que são retirados deles, mas apenas os registros sobre eles. Não faz sentido fazer tantos gestos com grandes matrizes de bits. Enquanto a QoS está sendo ridicularizada nos registros, os pacotes estão perfeitamente em sua memória e são recuperados de lá no endereço.VOQ é uma fila de software (o termo inglês Fila de software é mais preciso). Depois disso, imediatamente antes da interface, há também uma fila de hardware, que sempre funciona estritamente de acordo com o FIFO. É quase impossível controlar qualquer um de seus parâmetros (por exemplo, a Cisco permite configurar apenas a profundidade com o comando tx-ring-limit).Entre as filas de software e hardware, você pode executar expedidores arbitrários. É na fila do programa que o Head / Tail-drop e AQM, polindo e modelando, funcionam.O tamanho da fila de hardware é muito pequeno (unidades de pacotes), porque o expedidor faz todo o trabalho de empilhar a taxa de linha.Infelizmente, aqui você pode fazer muitas reservas e, de fato, riscar tudo com uma caneta vermelha e dizer "o fornecedor X não é assim".
Gostaria de fazer mais um comentário sobre os pacotes de serviços. Eles são tratados de maneira diferente dos pacotes de usuário em trânsito.Sendo gerados localmente, eles não são verificados quanto à conformidade com as regras da ACL e os limites de velocidade.Os pacotes externos destinados à CPU do chip de comutação de saída caem em outras filas - para a CPU - com base no tipo de protocolo.Por exemplo, o BFD tem a prioridade mais alta, o OSPF pode esperar mais e o ICMP geralmente não é assustador. Ou seja, quanto mais importante for o pacote para a rede funcionar, maior será sua classe de serviço ao enviar para a CPU. É por isso que é normal observar atrasos variados no salto de trânsito no ping ou no rastreamento - o ICMP não é um tráfego prioritário para a CPU.Além disso, pacotes de protocolo são aplicadosCoPP - Control Plane Protection (ou Policing) - limites de velocidade para evitar alta utilização da CPU - novamente, quedas mais previsíveis nas filas de baixa prioridade antes do início dos problemas.O CoPP ajudará tanto no DoS direcionado quanto no comportamento anormal da rede (por exemplo, loops) quando muito tráfego de broadcast começar a chegar ao dispositivo.
Links úteis
- O melhor livro sobre a teoria e a filosofia da QoS: redes habilitadas para QOS: ferramentas e fundações .
Alguns trechos podem ser lidos aqui , mas eu recomendaria a leitura de e para, sem troca. - QoS Huawei: Special Edition QoS(v6.0) . PHB .
- sr-TCM tr-TCM : Understanding Single-Rate and Dual-Rate Traffic Policing .
- VOQ: What is VOQ and why you should care?
- QoS MPLS: MPLS and Quality of Service .
- QoS Juniper: Juniper CoS notes .
- QoS TCP UDP. : The TCP/IP Guide
- , , : TCP .
- , FQ: Queuing and Scheduling .
, , An Introduction to Computer Networks , , Introduction, . .
- WFQ , , , , , : Weighted Fair Queueing: a packetized approximation for FFS/GP.
- Também há o mecanismo LFI, no qual não toquei, porque também é difícil em nossas realidades de interfaces de cem gigabytes, mas pode ser interessante se familiarizar com: Fragmentação e intercalação de links .
E, claro, a suíte RFC ... Conclusão
Esta versão teve muitos revisores.Obrigada
Alexander Fatin ( LoxmatiyMamont ), por uma palavra introdutória e conselhos valiosos sobre a expressividade e clareza do texto.Alexander Clipper (@ metallicat20) por sua revisão por pares.Alexander Klimenko (@ v00lk) pelas críticas duras e pelas mudanças mais maciças dos últimos dias.Andrey Glazkov (@glazgoo) por comentários sobre estrutura, terminologia e vírgulas.Artyom Chernobay para KDPV.Anton Klochkov (@NAT_GTX) para contatos com Miran.Miran (miran.ru) por organizar um servidor com Eva e transmitir. Tradicionalmente, minha família, que, no entanto, desta vez sofreu menos por causa de sua ausência nos momentos mais difíceis.