Prefácio
Tudo começou há mais de 2 anos e mudei para o 4º ano da especialidade "Informática para Negócios" da Universidade Estadual de Tomsk de Sistemas de Controle e Radioeletrônica (TUSUR). Não havia muito tempo até o final da universidade, e a perspectiva de escrever um diploma já se aproximava de nossos olhos. A idéia de comprar trabalho acabado não foi considerada. Eu realmente queria fazer algo sozinho. Havia muitas opções para os tópicos dos projetos de diploma: projetos de configuração para automatizar as necessidades de produção da empresa e o projeto para a implementação do Gerenciamento de Documentos por conta própria para 3 unidades territoriais e mais de 500 usuários ativos e a introdução do EDI. Em suma, muito de tudo estava na minha cabeça, mas nada disso inspirou. E essa foi a principal coisa.
Naquela época, eu trabalhava em uma empresa respeitável e, em questões comerciais, conheci um programador legal e geralmente uma boa pessoa. Andrei Shcheglov (Oi Andrei!) E de alguma forma = durante uma conversa, ele me perguntou se eu ouvia algo sobre o OneScript e Linguagem de script Gherkin. À qual recebi uma resposta que não, não ouvi. Naturalmente, a noite google / Yandex e a noite sem dormir levaram à ideia de que aqui está - o mundo do desconhecido. Mas a idéia de que esse poderia ser o assunto de uma tese ainda não surgiu. O círculo rotineiro de tarefas era o trabalho usual no 1C Configurator, como você entende com testes manuais e não lhe permitiu mergulhar completamente em uma nova abordagem no mundo 1C.
Conceitos desconhecidos
A primeira dificuldade que encontrei foi uma quantidade incrível de diferentes terminologias e ferramentas que eu nunca tinha ouvido falar - desde então eu era um "odnosnik típico" (neste momento o holivar começa ...) Especialmente por não conhecer outras linguagens de programação e Além disso, as metodologias da grande TI não eram familiares para mim; eu tive que pular de tópico em tópico para, pelo menos, de alguma forma, preencher meu glossário.
Quase no mesmo momento, eu (nós - e meus colegas) enfrentamos um problema bastante específico. Eles pegaram o módulo de software do contratado, verificaram as cópias. Tudo parece funcionar. Mas como havia muito trabalho, eles assinaram um ato de trabalho concluído e o lançaram no produtivo. Tudo ficou bom por seis meses, até que os dados neste subsistema não excedessem o permitido. E coisas muito estranhas começaram a acontecer. A realização de um documento a partir do módulo começou a ocorrer por 5 a 10 minutos, surgiram vários erros, etc. A visualização do código do programa foi horrível (não pergunte por que isso não foi feito antes ao aceitar ...). O número de ciclos aninhados estava além do razoável. A única solicitação no quarto ciclo e a apelação através de 4 pontos foram insignificantes, repetindo todos os documentos anteriores para preencher o documento atual, copiar e colar 10 vezes do mesmo bloco e muito mais.
Exemplo de aninhamento:

Duplicação de campos no layout:

Além disso, para preencher esses campos, uma cópia de 14 vezes .
Início do ciclo:

E até a variável FF atingir 15:

Bem, e um monte de outras obras de arte igualmente únicas.
De repente, lembrei-me de que, para o OneScript, existe uma biblioteca simples para calcular a "ciclomaticidade" do módulo (1) (a complexidade de um módulo ou método). Encontrado, calculado. Eu obtive um valor de 163 unidades, com um valor válido não superior a 10. E cheguei à conclusão de que o teste de aceitação do código do programa deve ser obrigatório e automático e contínuo. Então eu aprendi sobre a Inspeção Contínua - e, como aconteceu em 2006, a IBM fez (2) uma publicação sobre esse tópico.
Mais ainda. Provavelmente, muitas pessoas que trabalham em grandes empresas encontraram o problema de implantar uma cópia da base de trabalho na máquina local do desenvolvedor. Quando essa base pesa de 5 a 10 gigabytes - isso não é um problema, e quando pesa quase um terabyte apenas no backup, isso já é sério. Como resultado, foram necessárias 5-6 horas de tempo de trabalho para implantar uma nova cópia. Quando me cansei disso, comecei a usar uma ferramenta muito boa 1C-Deploy-and-CopyDB (obrigado Anton!) Então percebi que a automação é legal.
Além disso, havia outras tarefas, por exemplo, atualização regular da base principal e distribuída do armazenamento noturno, teste de formulários, testes de cenário etc. Parte disso foi realizada, mas outras não.
Mas tudo isso era necessário apenas para mim. Ao procurar pessoas afins em sua cidade, ele praticamente falhou. Eles não estão lá. Embora terrivelmente estranho, uma vez que os problemas são típicos. Naquele momento, eu já sabia que queria escrever minha tese sobre esse assunto. Mas eu não sabia o que escrever. Portanto, tive que ingressar na comunidade não apenas como leitura, mas pelo menos escrevendo e fazendo perguntas. Os principais lugares onde você pode fazer perguntas foram
Projetos do Github:
• https://github.com/silverbulleters/add
• https://github.com/oscript-library/opm
• https://github.com/EvilBeaver/OneScript
• https://github.com/silverbulleters/vanessa-runner/
Fórum XDD:
• seção 1Script
Seção de teste
Seção de automação de processos
Bem e como meio de comunicação rápida - grupos de perfis no Gitter
A coleta de material já começou. Como o destino quis , consegui entrar em contato com Alexey Lustin alexey-lustin (Oi Alexey!) E falar sobre minha ideia de diploma no fórum do XDD. Fiquei surpreso ao ouvir um feedback de aprovação e até um convite para me submeter à prática de pré-graduação na Silver Bullet. Já era uma vitória. Por várias horas, chegamos ao tópico e ao conteúdo do diploma. Definimos tarefas para o trabalho prático. Peguei o chefe do projeto de diploma da empresa - Arthur Ayukhanov (Arthur oi!) Como o jovem Padawan teve acesso ao curso de vídeo do engenheiro de lançamento e a capacidade de obter Nikita Gryzlov (Oi Nikita!) Ilimitadamente com suas perguntas, pelas quais ele é muito grato.
Em resumo:
O tópico do diploma é "Gerenciamento automatizado do ciclo de vida de sistemas de informação - engenharia de sistemas e software de soluções na plataforma 1C: Enterprise nas condições de melhoria contínua da qualidade do processo de produção".

O objetivo do trabalho final de qualificação (WRC) é identificar o relacionamento das ferramentas de software e uma descrição do processo de negócios do circuito DevOps na área 1C.
A justificativa teórica do projeto era o padrão para a melhoria contínua da qualidade de serviço do ITIL 3.0, e o objetivo prático era a construção de um loop de integração contínua para a nova solução de aplicativo que desenvolvemos - a conta pessoal do cliente. Para fazer isso, o servidor de origem GitLab e o loop de construção Jenkins foram implantados. Os testes foram executados em um servidor dedicado (Windows Slave). A configuração foi descarregada do repositório 1C usando a biblioteca Gitsync , versão 3.0
(atualmente localizado no ramo de desenvolvimento) já com as realizações de Alexei Khorev (Lech hello!) com uma frequência de 30 minutos no ramo de desenvolvimento. O motivo da escolha dessa versão específica foi a capacidade de conectar-se ao repositório via protocolo tcp, que, infelizmente, não suportava o GitSync 2.x típico naquele momento. Se as alterações foram registradas no GitLab, a execução do loop de integração contínua foi iniciada automaticamente.
Como o orçamento de todo o evento era zero e a capacidade de criar um controle de qualidade completo do código do programa sem a compra de um módulo para o SonarQube era impossível, uma verificação de sintaxe 1C padrão foi usada como uma solução simplificada. Embora uma descarga única tenha sido realizada, os resultados foram obtidos e analisados. Também foram usadas verificações adicionais de ciclicidade e presença de código reutilizável.
Na fase de teste da funcionalidade, duas estruturas Vanessa-Behavior e XUnitFor1C foram usadas em sua versão combinada chamada Vanessa Automation Driven Development (Vanessa ADD). O primeiro foi usado para começar a testar o comportamento esperado, o segundo foi verificar a abertura de formulários (teste de fumaça). A passagem do loop de integração contínua resultou em relatórios gerados automaticamente.
De acordo com os resultados do teste, o engenheiro de liberação tomou a decisão de mesclar as ramificações de desenvolvimento e mestre e lançou (já manualmente) a terceira tarefa - a publicação de alterações no banco de dados produtivo. O banco de dados produtivo não está conectado ao repositório e é completamente fechado de alterações manuais. A atualização é realizada apenas através da entrega e no modo automático.
Para descrever o processo de negócios do circuito, um diagrama IDEF0 foi formado, consistindo em 4 blocos consecutivos que formam a passagem do circuito. Um erro que ocorre ao passar por qualquer um dos estágios interrompe o processo de montagem com uma notificação ao engenheiro de liberação e transfere o controle para o quinto bloco do processo de montagem, onde os relatórios são gerados no formato ALLURE, JUNIT e, claro, em cucumber.json.
Descrição do Modelo IDEF0
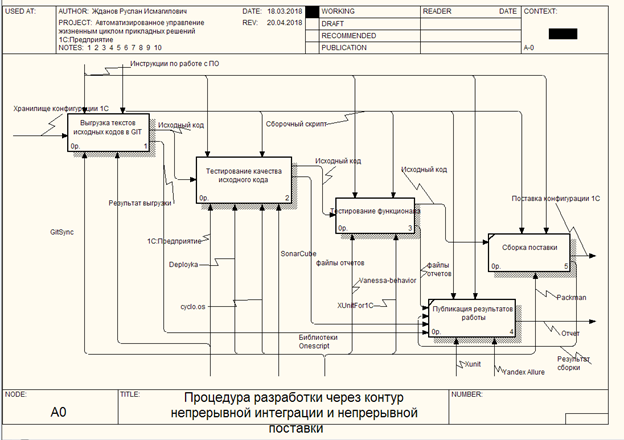
O processo de "Descarregando código fonte no GIT"
Dados de entrada: - Repositório de configuração
Saída (saída): - Código fonte
Controle: Instruções para trabalhar com software, script de montagem
Mecanismo: 1C: Empresa, Gitsync .
Um pré-requisito para a existência do contorno é a presença de arquivos de origem. A partir da versão da plataforma 8.3.6, o 1C forneceu a capacidade de carregar códigos-fonte de configuração em arquivos. Deve-se notar que esse processo pode ter várias opções, dependendo das especificidades do desenvolvimento no departamento de TI. Na versão atual, para simplificar o processo de transição de funcionários para a nova metodologia, foi realizada a integração com o processo de desenvolvimento atual por meio do repositório de configuração e usando o configurador 1C.
No estágio do processo “Descarregando fontes no GIT”, será criado o arquivo, base de informações de serviço 1C; estava conectado ao armazenamento de configuração na conta de serviço; todas as alterações são recebidas no momento atual (ou até o último commit no repositório); os códigos-fonte foram descarregados no diretório do assembly; comprometida com o sistema de armazenamento da versão GIT; as alterações são enviadas para o servidor de origem GitLab
O processo de "testar a qualidade do código fonte"
Dados de entrada: - Código fonte
Saída (saída): - Código fonte
Controle: Instruções para trabalhar com software, script de montagem
Mecanismo: 1C: Enterprise, Deployka , SonarQube , Cyclo.os - (infelizmente não há link)
No início deste processo, o código fonte é armazenado no repositório GitLab. Usando o script de controle (montagem), ele é recebido no diretório de montagem. Por meio da plataforma 1C: Enterprise, com base nesses códigos-fonte, uma base de informações de serviço é implantada. Uma análise de erro é realizada usando as ferramentas da plataforma. Se durante a análise forem detectados erros de código do programa que não permitem montar a configuração, o processo será interrompido. O objetivo desta etapa é eliminar o desperdício de tempo analisando o código do programa de uma configuração inoperante.
Após a verificação de erros, o cálculo da complexidade ciclomática do código do programa é iniciado. Um aumento nesse coeficiente afeta significativamente a depuração e a análise do código do programa. O valor máximo permitido é 10. Se excedido, uma exceção é lançada e o código é retornado para revisão.
A etapa final na análise da qualidade do código do programa é verificar a conformidade com os padrões de desenvolvimento. Para esses propósitos, o esquema proposto usa o serviço SonarQube e o módulo de suporte à sintaxe 1C, desenvolvido por ele pela Silver Bullet. Com base nos resultados da análise, o sistema calcula o valor da dívida técnica para cada funcionário que publicou o código do programa.
Processo de Teste Funcional
Dados de entrada: - Código fonte
Saída (saída): - Código fonte
Controle: Instruções para trabalhar com software, script de montagem
Mecanismo: 1C: Empresa, comportamento Vanessa, XunitFor1C .
Durante o processo de desenvolvimento, podem ocorrer situações em que novas funcionalidades podem interromper a operação dos subsistemas existentes. Isso pode se manifestar tanto na formação de exceções quanto na conclusão do resultado não esperado. Para esses fins, o comportamento esperado do sistema é testado.
Vários métodos de desenvolvimento e teste são aplicáveis a este circuito: TDD (Test Driven Development) e BDD (Behavior Driven Development)
No momento da redação do WRC, a estrutura de comportamento Vanessa era usada para executar testes usando a Metodologia BDD e o XunitFor1C for TDD. Atualmente, eles são mesclados em um produto Vanessa-ADD. O suporte ao desenvolvedor para produtos mais antigos foi descontinuado. Os resultados do teste são enviados para os arquivos de relatório Yandex Allure e Xunit.
Processo "Montagem de entrega"
Dados de entrada: - Código fonte
Dados de saída: - Entrega da configuração
Controle: Instruções para trabalhar com software, script de montagem
Mecanismo: 1C: Empresa, empacotador .
Nesse processo, ocorre a entrega final da entrega da configuração para implantação no sistema de destino. O código-fonte verificado está no ramo de desenvolvimento do repositório de código-fonte do GitLab. Para formar uma entrega, é necessário que as alterações da ramificação revelada apareçam na ramificação mestre . Essa ação pode ocorrer manual e automaticamente e é regulada pelos requisitos do departamento de TI usando o loop CI / CD. Depois de mesclar filiais, o processo de montagem da entrega final é iniciado. Para fazer isso, novamente, no diretório de montagem, com base nas fontes existentes, é criada uma base de informações de serviço e, usando as ferramentas da plataforma 1C: Enterprise, uma entrega de configuração é gerada e arquivada. A entrega da configuração é o produto final do processo de montagem e é entregue ao cliente através dos canais de comunicação estabelecidos ou é instalada diretamente em um sistema de informações produtivas.
Processo de publicação de resultados
Dados de entrada: - Descarregar resultado, arquivos de relatório
Dados de saída: - Relatório
Controle: Instruções para trabalhar com software, script de montagem
Mecanismo: Yandex Allure , Xunit .
Ao executar as etapas do processo, as ferramentas de teste criam arquivos de relatório em determinados formatos como subproduto. A tarefa desse processo é agrupar, transformar e publicar para a conveniência da análise de dados. No caso de uma exceção ser gerada em algum estágio da montagem e com as configurações necessárias, o sistema deve notificar automaticamente o administrador do loop sobre problemas. Essa etapa é realizada no pós-processamento do processo de montagem e deve ser executada independentemente dos resultados dos processos anteriores.
Para feedback, além da lista de discussão, foi utilizada a integração com o gerente corporativo do Slack, onde foram enviadas todas as mensagens de informações sobre o status da compilação, a aparência de novos commits, a formação de backups e o monitoramento do funcionamento dos serviços relacionados ao circuito DevOps e de 1C a inteiro.
Os resultados do meu projeto foram a proteção do WRC no final de maio deste ano com o resultado "excelente". Além disso, as informações metodológicas sobre a formação do contorno foram atualizadas.

Conclusões gerais:
- O efeito econômico é possível apenas a longo prazo. Por experiência, observou-se que, quando o projeto de implementação de práticas de engenharia é lançado, é registrada uma diminuição na produtividade do desenvolvimento em 20 a 30% em relação ao nível atual. Esse período é temporário e, como regra, o desempenho retorna aos seus valores iniciais após três a quatro meses de operação. A diminuição no desempenho deve-se principalmente ao fato de o desenvolvedor precisar se acostumar com os novos requisitos de desenvolvimento: escrever scripts, testes e criar documentação técnica.
- A estabilidade de um sistema produtivo de informações aumentou significativamente devido ao teste do código do programa. A operação garantida de subsistemas críticos é fornecida pela cobertura do teste de cenário. Devido a isso, os riscos da empresa em uma área crítica - a interação operacional com os clientes foi reduzida.
- A exclusão de correções dinâmicas em uma base produtiva de informações tornou possível planejar de forma mais construtiva o desenvolvimento e impedir que o código de software contornasse o ciclo de teste.
- Custos de mão de obra reduzidos para atender a base de informações devido à automação do circuito de montagem.
- O uso de feedback por meio do Slack tornou possível monitorar e corrigir problemas de ciclo de vida do sistema on-line. De acordo com as análises da equipe, usar um messenger é mais conveniente do que enviar por correio (embora também esteja presente).
- O uso da inspeção contínua de código automatizada (Inspeção Contínua) para conformidade com os padrões de desenvolvimento (SonarQube) força os desenvolvedores a aumentar sua competência de forma independente e a correção da dívida técnica identificada diretamente durante o desenvolvimento de um módulo de software é muito mais rápida, pois você não precisa gastar tempo restaurando o contexto da tarefa.
- A ativação da funcionalidade da documentação automática e a geração de instruções em vídeo podem reduzir o número de solicitações do usuário.
- Durante o curso do projeto, foi formado um processo de negócios que descreve o ciclo de vida do desenvolvimento e teste das soluções de aplicativos 1C, que por sua vez influenciaram a formação de um projeto para a implementação de práticas de engenharia . , 1.
, . 90% .
, :
- , " 1. - , , ( 5 ).
- “ 1”. . ( , " ". ).
- CICD 1 , 5.5.0 .
, , 1 , DevOps. , — DevOps 1 .
, DevOps 1. ?