O sucesso em projetos de aprendizado de máquina geralmente está associado não apenas à capacidade de usar bibliotecas diferentes, mas também ao entendimento da área de onde os dados vêm. Um excelente exemplo dessa tese foi a solução proposta pela equipe de Alexei Kayuchenko, Sergey Belov, Alexander Drobotov e Alexey Smirnov na competição do Dia Digital PIK. Eles ficaram em segundo lugar e, depois de algumas semanas, conversaram sobre sua participação e os modelos construídos no próximo
treinamento em Yandex ML .
Alexey Kayuchenko:
Boa tarde! Falaremos sobre a competição do PIK Digital Day da qual participamos. Um pouco sobre a equipe. Éramos quatro de nós. Tudo com um fundo completamente diferente, de diferentes áreas. De fato, nos encontramos na final. A equipe se formou apenas um dia antes da final. Vou falar sobre o curso da competição, a organização do trabalho. Então Serezha será divulgado, ele contará sobre os dados e Sasha contará sobre a submissão, o progresso final do trabalho e como avançamos na tabela de classificação.

Brevemente sobre a competição. A tarefa foi muito aplicada. A PIC organizou essa competição fornecendo dados sobre as vendas de apartamentos. Como conjunto de dados de treinamento, havia uma história com atributos por 2 anos e meio em Moscou e na região de Moscou. A competição consistiu em duas etapas. Era um estágio on-line, onde cada um dos participantes tentava criar seu próprio modelo, e o estágio off-line, não muito longo, era de apenas um dia da manhã à noite. Atingiu os líderes do estágio online.
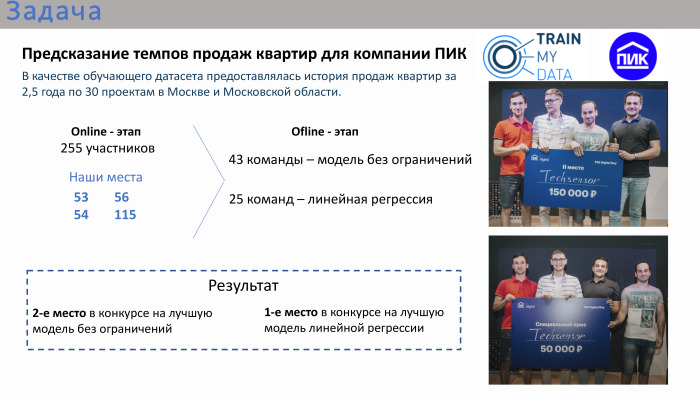
De acordo com os resultados da competição online, nossos lugares não estavam nem entre os 10 melhores nem entre os 20 melhores. Nós estávamos lá em lugares 50+. No final, ou seja, no estágio offline, havia 43 equipes. Havia muitas equipes compostas por uma pessoa, embora fosse possível se unir. Cerca de um terço das equipes tinha mais de uma pessoa. Havia duas competições na final. A primeira competição é um modelo sem restrições. Foi possível usar qualquer algoritmo: aprendizado profundo, aprendizado de máquina. Paralelamente, foi realizado um concurso para a melhor solução de regressão linear. O organizador considerou que a regressão linear também era bastante aplicada, uma vez que a competição em si era muito aplicada como um todo. Ou seja, a tarefa foi feita - era necessário prever o volume de vendas de apartamentos, tendo dados históricos dos 2,5 anos anteriores com atributos.
Nossa equipe ficou em segundo lugar na competição pelo melhor modelo sem restrições e em primeiro lugar na competição pela melhor regressão. Prêmio duplo.

Posso dizer sobre o curso geral da organização que a final foi muito estressante, bastante estressante. Por exemplo, nossa decisão vencedora foi enviada apenas dois minutos antes do jogo final. A decisão anterior nos colocou, em minha opinião, em quarto ou quinto lugar. Ou seja, trabalhamos até o fim, sem relaxar. O PIC organizou tudo muito bem. Havia mesas assim, havia até uma varanda para que você pudesse sentar na rua, respirar ar fresco. Comida, café, tudo foi fornecido. A figura mostra que todos estavam sentados em seus grupos, trabalhando.
Sergey dirá mais sobre os dados.
Sergey Belov:
Obrigado. O PIC nos forneceu vários arquivos de dados. Os dois principais são train.csv e test.csv, nos quais havia cerca de 50 recursos gerados pelo próprio PIC. O trem consistia em aproximadamente 10 mil linhas, teste - de 2 mil.
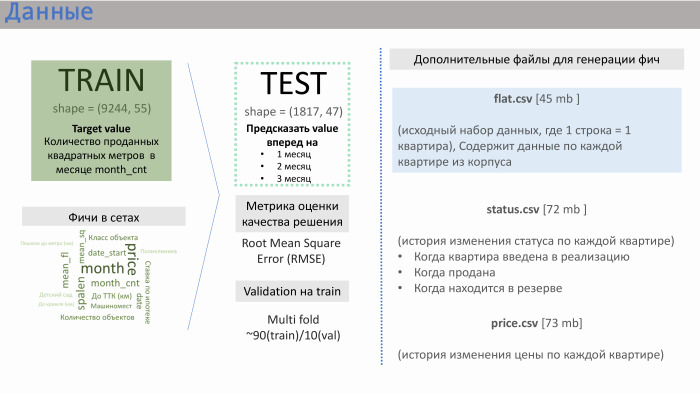
O que a string forneceu? Continha dados de vendas. Ou seja, como valor (nesse caso, meta), tivemos vendas em metros quadrados para apartamentos em média sobre um edifício específico. Havia aproximadamente 10 mil dessas linhas. Os recursos dos conjuntos gerados pelo PIK são mostrados no slide com o significado aproximado que obtivemos.
Fui ajudado aqui pela experiência em empresas de desenvolvimento. Recursos como a distância do apartamento ao Kremlin ou ao anel de transporte, o número de vagas no estacionamento - não afetam muito as vendas. A influência é exercida pela classe do objeto, dormência e, mais importante, o número de apartamentos na implementação no momento. O PIC não gerou esse recurso, mas nos forneceu três arquivos adicionais: flat.csv, status.csv e price.csv. E decidimos dar uma olhada no flat.csv, porque havia apenas dados sobre o número de apartamentos e seu status.
E se alguém se pergunta o que serviu como sucesso de nossa decisão, esse é um trabalho definido em equipe. Desde o início desta competição, trabalhamos muito harmoniosamente. Discutimos imediatamente em algum lugar em cerca de 20 minutos o que faremos. Chegamos à conclusão geral de que a primeira coisa que você precisa para trabalhar com dados é porque qualquer cientista de dados entende que há muitos dados nos dados e, muitas vezes, a vitória se deve a algum recurso que a equipe gerou. Depois de trabalhar com os dados, usamos principalmente vários modelos. Decidimos ver qual resultado nossos recursos geram em cada um desses modelos e, em seguida, focamos no modelo ilimitado e no modelo de regressão linear.
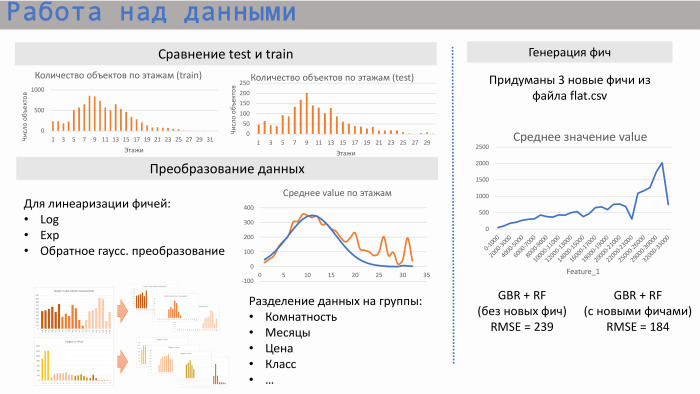
Começamos a trabalhar com dados. Primeiro, analisamos como os testes de conjuntos de trens se relacionam entre si, ou seja, as áreas desses dados se cruzam. Sim, eles se cruzam: no número de apartamentos, na dormência e em um determinado número médio de andares.
Além disso, para regressão linear, começamos a realizar certas transformações. É como os logaritmos padrão de um expoente. Por exemplo, no caso do andar do meio, essa foi a transformação gaussiana inversa para linearização. Também percebemos que, às vezes, é melhor separar os dados em grupos. Se tomarmos, por exemplo, a distância entre o apartamento e o metrô ou sua sala, haverá mercados ligeiramente diferentes, e é melhor dividir, criar modelos diferentes para cada grupo.
Geramos três recursos do arquivo flat.csv. Um deles é apresentado aqui. Pode-se observar que ele possui uma relação linear bastante boa, além desse subsidência. O que era esse recurso? Correspondeu ao número de apartamentos atualmente em implementação. E esse recurso funciona muito bem em valores baixos. Ou seja, não pode haver mais apartamentos vendidos do que o valor da venda. Mas nesses arquivos, de fato, um certo fator humano foi estabelecido, porque eles são frequentemente compilados por seres humanos. Vimos diretamente os pontos que são eliminados dessa área, porque estavam entupidos um pouco incorretamente.
Exemplo do scikit-learn. Um modelo da GBR e da Random Forest sem recursos deu o RMSE 239, e com esses três recursos - 184.
Sasha vai falar sobre os modelos que usamos.
Alexander Drobotov:
- Algumas palavras sobre a nossa abordagem. Como os caras disseram, somos todos diferentes, vindos de diferentes áreas, com diferentes formações. E tivemos abordagens diferentes. Na fase final, Lesha usou mais o XGBoost da Yandex (provavelmente, quero dizer, CatBoost - ed.), Seryozha - a biblioteca de aprendizado de scikit, I - LightGBM e regressão linear.

Modelos XGBoost, regressão linear e Profeta são as três opções que nos mostraram a melhor pontuação. Para regressão linear, tivemos uma mistura de dois modelos e, para a competição geral, XGBoost, e adicionamos um pouco de regressão linear.

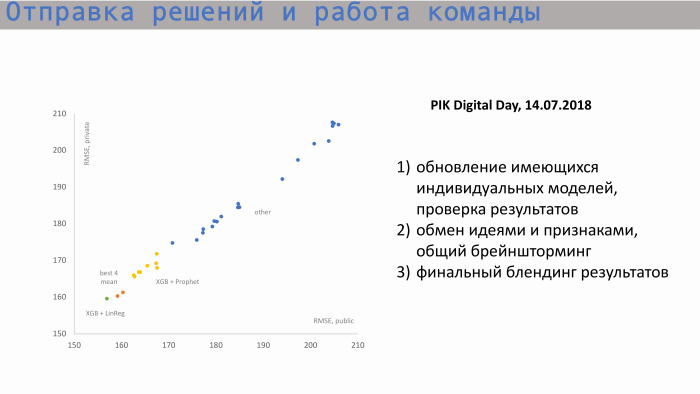
Aqui está o processo de envio de decisões e trabalho em equipe. No gráfico à esquerda, o eixo X é RMSE público, o valor da métrica e o eixo Y é a pontuação privada, RMSE. Começamos a partir dessas posições. Aqui estão modelos individuais de cada um dos participantes. Depois de trocar idéias e criar novos recursos, começamos a aproximar-se da nossa melhor pontuação. Nossos valores para modelos individuais eram aproximadamente os mesmos. O melhor modelo individual é o XGBoost e o Profeta. O Profeta criou uma previsão para as vendas acumuladas. Havia um sinal como quadrado inicial. Ou seja, sabíamos quantos apartamentos possuímos no total, entendíamos qual valor histórico e valor incremental buscavam valor total. O Profeta fez uma previsão para o futuro, emitiu valores nos períodos seguintes e os enviou ao XGBoost.
A combinação de nossa melhor pontuação individual está em algum lugar por aqui, esses dois pontos laranja. Mas essa pontuação não foi suficiente para chegarmos ao topo.
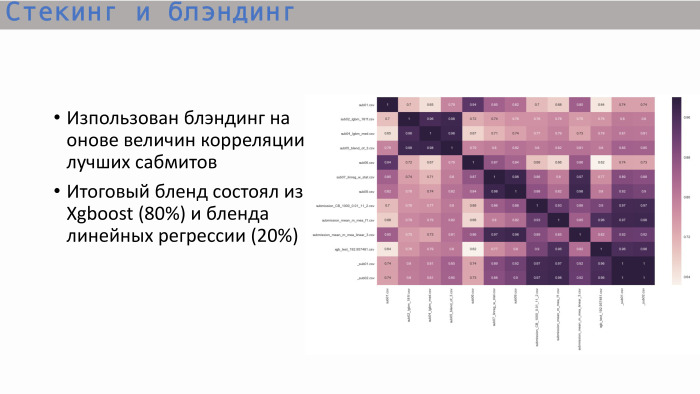
Depois de estudar a matriz de correlação usual das melhores submissões, vimos o seguinte: as árvores - e isso é lógico - mostraram uma correlação próxima da unidade, e a melhor árvore deu o XGBoost. Mostra correlação não tão alta com regressão linear. Decidimos combinar essas duas opções na proporção de 8 para 2. Foi assim que obtivemos a melhor solução final.
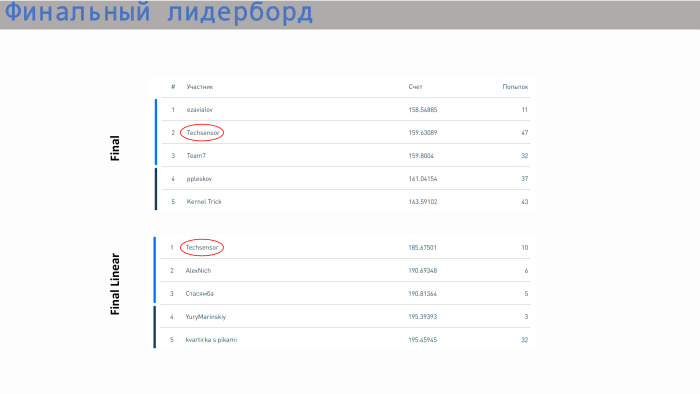
Este é um ranking com resultados. Nossa equipe ficou em segundo lugar em modelos ilimitados e em primeiro lugar em modelos lineares. Quanto à pontuação - aqui todos os valores estão bem próximos. A diferença não é muito grande. Uma regressão linear já está dando um passo na área 5. Temos tudo, obrigado!