
Uma das principais conferências de ciência de dados do ano começou hoje em Londres. Tentarei falar rapidamente sobre o que era interessante ouvir.
O começo parecia nervoso: na mesma manhã, uma reunião em massa das Testemunhas de Jeová foi organizada no mesmo centro, por isso não foi fácil encontrar o balcão de registro da KDD e, quando finalmente o encontrei, a linha tinha 150-200 metros. No entanto, após ~ 20 minutos de espera, ele recebeu um distintivo cobiçado e foi para uma aula de mestre.
Privacidade na análise de dados
O primeiro workshop foi dedicado a manter a privacidade na análise de dados. No começo, eu estava atrasado, mas, aparentemente, não perdi muito - eles conversaram sobre o quão importante é a privacidade e como os atacantes podem fazer mau uso das informações privadas divulgadas. By the way, pessoas bastante respeitáveis do Google, LinkedIn e Apple dizem. Como a aula principal deixou uma impressão muito positiva, os slides estão disponíveis
aqui .
Acontece que o conceito de
Privacidade Diferencial existe há muito tempo, cuja idéia é adicionar ruído que dificulta o estabelecimento de verdadeiros valores individuais, mas mantém a capacidade de restaurar distribuições comuns. Na verdade, existem dois parâmetros:
e - quão difícil é divulgar os dados
d - quão distorcidas são as respostas.
O conceito original sugere que existe algum tipo de vínculo intermediário entre o analista e os dados - o “Curador”, é ele quem processa todas as solicitações e gera respostas para que o ruído oculte os dados privados. Na realidade, o modelo de privacidade diferencial local é frequentemente usado, no qual os dados do usuário permanecem no dispositivo do usuário (por exemplo, um telefone celular ou PC); no entanto, ao responder às solicitações do desenvolvedor, o aplicativo envia um pacote de dados do dispositivo pessoal que não permite descobrir exatamente o que Este usuário em particular respondeu. Embora, ao combinar respostas de um grande número de usuários, você possa restaurar a imagem geral com alta precisão.
Um bom exemplo é a pesquisa "Você já fez um aborto"? Se você realizar uma pesquisa "na testa", ninguém dirá a verdade. Mas se você organizar a pesquisa da seguinte maneira: "jogue uma moeda, se houver uma águia, jogue-a novamente e diga" sim "para a águia, mas" não "para a coroa, caso contrário responda a verdade", é fácil restaurar a verdadeira distribuição, mantendo a privacidade individual. O desenvolvimento dessa idéia foi o mecanismo de coleta de estatísticas
sigilosas Google RAPPOR (Relatório Ordinal de Preservação da Privacidade da RA), que foi usado para coletar dados sobre o uso do Chrome e seus garfos.
Imediatamente após o lançamento do Chrome em código aberto, apareceu um número bastante grande de pessoas que desejavam criar seu próprio navegador com uma página inicial, um mecanismo de pesquisa, seus próprios dados publicitários, etc. Naturalmente, os usuários e o Google não estavam entusiasmados com isso. Outras ações são geralmente compreensíveis: para descobrir as substituições mais comuns e esmagar administrativamente, mas o inesperado saiu ... A política de privacidade do Chrome não permitiu que o Google capturasse informações sobre a configuração da página inicial e do mecanismo de pesquisa do usuário :(
Para superar essa limitação e criou o RAPPOR, que funciona da seguinte maneira:
- Os dados na página inicial são registrados em um pequeno filtro de bloom de 128 bits.
- Ruído branco permanente é adicionado a este filtro de bloom. Permanente = o mesmo para este usuário, sem economizar ruído, várias solicitações podem revelar dados do usuário.
- Além do ruído constante, o ruído individual gerado para cada solicitação é sobreposto.
- O vetor de bits resultante é enviado ao Google, onde começa a descriptografia da imagem geral.
- Primeiro, por métodos estatísticos, subtraímos o efeito do ruído da imagem geral.
- Em seguida, criamos vetores de bits candidatos (os sites / mecanismos de pesquisa mais populares em princípio).
- Utilizando os vetores obtidos como base, construímos uma regressão linear para reconstruir a imagem.
- Combine a regressão linear com o LASSO para suprimir candidatos irrelevantes.
Esquematicamente, a construção do filtro é assim:

A experiência de implementar o RAPPOR acabou sendo muito positiva, e o número de estatísticas privadas coletadas com sua ajuda está crescendo rapidamente. Entre os principais fatores de sucesso, os autores identificaram:
- Simplicidade e clareza do modelo.
- Abertura e documentação do código.
- A presença nos gráficos finais dos limites dos erros.
No entanto, essa abordagem tem uma limitação significativa: é necessário ter listas de respostas dos candidatos para descriptografia (e é por isso que O - Ordinal). Quando a Apple começou a coletar estatísticas sobre as palavras e emoticons usados nas mensagens de texto, ficou claro que essa abordagem não era boa. Como resultado, na conferência WDC-2016, um dos principais novos recursos anunciados no iOS foi a adição de privacidade diferencial. Uma combinação de uma estrutura de esboço com ruído adicional também foi usada como base, no entanto, muitos problemas técnicos tiveram que ser resolvidos:
- O cliente (telefone) deve ser capaz de criar e armazenar esta resposta em um tempo razoável.
- Além disso, essa resposta deve ser compactada em uma mensagem de rede de tamanho limitado.
- No lado da Apple, tudo isso deve ser agregado em um período de tempo razoável.
Como resultado, criamos um esquema usando
count-min-sketch para codificar palavras e, em seguida, selecionamos aleatoriamente a resposta de apenas uma das funções de hash (mas, ao fixar a escolha do par usuário / palavra), o vetor foi convertido usando a
transformação Hadamard e enviado apenas ao servidor um "bit" significativo para a função de hash selecionada.
Para restaurar o resultado no servidor, também foi necessário revisar as hipóteses de candidatos. Porém, com um tamanho de dicionário grande, é muito complicado mesmo para um cluster. Era necessário, de alguma maneira, selecionar heuristicamente as áreas de pesquisa mais promissoras. O experimento com o uso de bigrams como ponto de partida, a partir do qual você pode montar o mosaico, não teve êxito - todos os bigrams eram igualmente populares. A abordagem de hash bigram + word resolveu o problema, mas levou a uma violação da privacidade. Como resultado, decidimos por árvores de prefixo: as estatísticas foram coletadas nas partes iniciais da palavra e depois na palavra inteira.
No entanto, uma análise do algoritmo de privacidade usado pela Apple pela comunidade de pesquisa mostrou que a privacidade ainda pode
ser comprometida com estatísticas de longo prazo.
O LinkedIn estava em uma situação mais difícil com seu estudo da distribuição dos salários dos usuários. O fato é que a privacidade diferencial funciona bem quando temos um número muito grande de medições; caso contrário, não é possível subtrair com segurança o ruído. Na pesquisa salarial, o número de relatórios é limitado e o LinkedIn decidiu seguir um caminho diferente: combinar ferramentas técnicas de criptografia e cibersegurança com o conceito de
k-anonimato : os dados do usuário são considerados suficientemente disfarçados se você enviá-los em um pacote em que existem respostas k com os mesmos atributos de entrada (por exemplo, localização e profissão) que diferem apenas na variável alvo (salário).
Como resultado, foi construído um transportador complexo no qual diferentes serviços transmitem partes de dados entre si, criptografando constantemente para que uma única máquina não possa abri-las completamente. Como resultado, os usuários são divididos por atributos em coortes e, quando a coorte atinge o tamanho mínimo, suas estatísticas vão para o HDFS para análise.
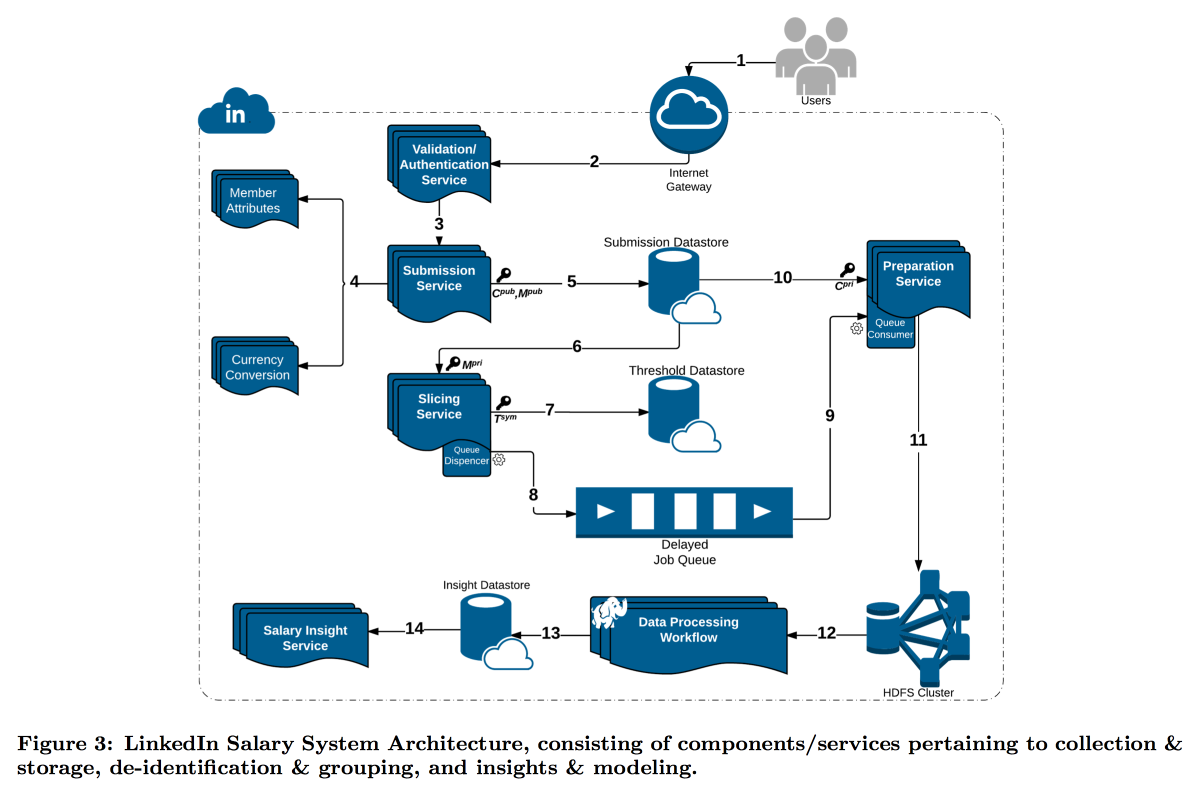
O carimbo de data / hora merece atenção especial: ele também precisa ser anonimizado; caso contrário, você poderá descobrir quem é a resposta no log de chamadas. Mas não quero perder tempo, porque é interessante acompanhar a dinâmica. Como resultado, decidimos adicionar um carimbo de data / hora aos atributos pelos quais a coorte é construída e calcular a média de seu valor.
O resultado é um recurso premium interessante e algumas perguntas abertas interessantes:
O GDPR sugere que, mediante solicitação, poderemos excluir todos os dados do usuário, mas tentamos ocultá-los para que agora não possamos encontrar de quem são esses dados. Tendo dados sobre um grande número de diferentes fatias / coortes, você pode isolar correspondências e expandir a lista de atributos abertos
Essa abordagem funciona para dados grandes, mas não funciona com dados contínuos. A prática mostra que simplesmente amostrar dados não é uma boa ideia, mas a Microsoft no NIPS2017
propôs uma solução sobre como trabalhar com eles. Infelizmente, os detalhes não tiveram tempo de divulgar.
Análise de Grandes Gráficos
O segundo workshop sobre a análise de grandes gráficos começou à tarde. Apesar do fato de que ele também era liderado pelos caras do Google, e havia mais expectativas dele, ele gostava muito menos - eles falavam sobre suas tecnologias fechadas, depois caíam no banalismo e na filosofia geral, depois mergulhavam em detalhes malucos, sem sequer ter tempo para formular a tarefa. No entanto, pude captar alguns aspectos interessantes. Slides podem ser encontrados
aqui .
Em primeiro lugar, gostei do esquema chamado
agrupamento de redes do ego , acho que é possível criar soluções interessantes em sua base. A ideia é muito simples:
- Consideramos o gráfico local do ponto de vista de um usuário específico, MAS menos ele próprio.
- Agrupamos este gráfico.
- Em seguida, “clonamos” a parte superior do usuário, adicionando uma instância a cada cluster e não conectando-as por arestas.
Em um gráfico transformado semelhante, muitos problemas são resolvidos mais facilmente e os algoritmos de classificação funcionam de maneira mais limpa. Por exemplo, é muito mais fácil particionar esse gráfico de maneira equilibrada e, ao classificar por recomendação de amigos, os nós da ponte são muito menos barulhentos. Foi para esta tarefa que as recomendações dos amigos da ENC foram consideradas / promovidas.
Mas, em geral, a ENC era apenas um exemplo: no Google, todo um departamento está envolvido no desenvolvimento de algoritmos em gráficos e no fornecimento a outros departamentos como uma biblioteca. A funcionalidade declarada da biblioteca é impressionante: uma biblioteca de sonhos para o SNA, mas tudo está fechado. Na melhor das hipóteses, pode-se tentar reproduzir blocos individuais por artigos. Alega-se que a biblioteca possui centenas de implementações dentro do Google, inclusive em gráficos com mais de um trilhão de arestas.
Houve cerca de 20 minutos de promoção do modelo MapReduce, como se não soubéssemos o quão legal foi. Depois disso, os caras mostraram que muitos problemas complexos podem ser resolvidos (aproximadamente) usando o modelo Random Sets Composable Core Sets. A idéia principal é que os dados sobre as bordas sejam aleatoriamente dispersos em N nós, onde eles são puxados para a memória e o problema seja resolvido localmente, após o qual os resultados da solução são transferidos para a máquina central e agregados. Argumenta-se que, dessa maneira, você pode obter boas aproximações baratas para muitos problemas: componentes de conectividade, floresta de abrangência mínima, correspondência máxima, cobertura máxima, etc. Em alguns casos, ao mesmo tempo, o mapeador e o redutor resolvem o mesmo problema, mas podem ser um pouco diferentes. Um bom exemplo de como nomear de maneira inteligente uma solução simples para que as pessoas acreditem nela.
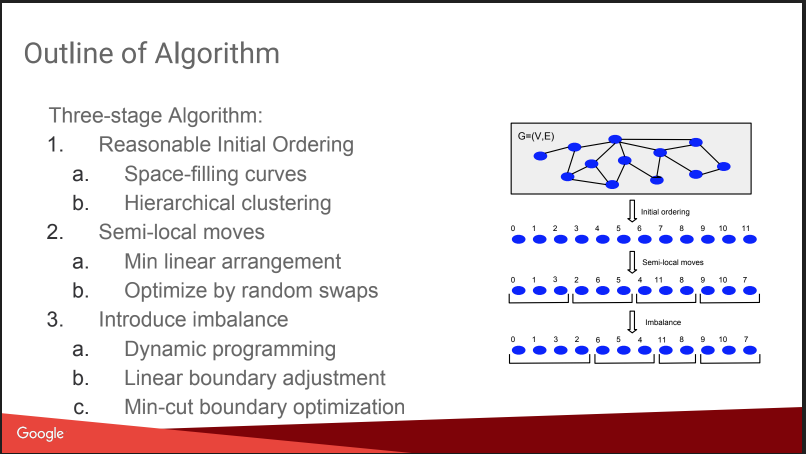
Houve uma conversa sobre o que eu estava fazendo aqui: Particionamento de gráficos balanceados. I.e. como cortar um gráfico em N partes para que as partes sejam aproximadamente iguais em tamanho e o número de ligações dentro das partes seja significativamente maior que o número de ligações externas. Se você conseguir resolver bem esse problema, muitos algoritmos se tornarão mais fáceis, e mesmo os testes A / B poderão ser executados com mais eficiência, com compensação pelo efeito viral. Mas a história um pouco decepcionada, tudo parecia um "plano gnômico": atribuir números com base em agrupamentos hierárquicos de afins, mover, adicionar desequilíbrio. Sem detalhes. Sobre isso no KDD, haverá um relatório separado deles mais tarde, vou tentar ir. Além disso, há uma
postagem no blog .
No entanto, eles fizeram uma comparação com alguns concorrentes, alguns deles estão abertos:
Spinner ,
UB13 da FB,
Funcho da Microsoft,
Metis . Você pode olhar para eles também.
Depois conversamos um pouco sobre detalhes técnicos. Eles usam vários paradigmas para trabalhar com gráficos:
- MapReduce em cima do Flume. Eu não sabia que isso era possível - o Flume não está muito escrito na Internet para coletar, mas não para analisar dados. Eu acho que isso é uma perversão intra-google. UPD: Descobri que esse é realmente um produto interno do Google, não tem nada a ver com o Apache Flume, existe uma ersatz na nuvem chamada dataflow
- Tabela de hash distribuído MapReduce +. Eles dizem que isso ajuda a reduzir significativamente o número de rodadas de MP, mas na Internet não há muito escrito sobre essa técnica, por exemplo, aqui
- Pregel - eles dizem que ele morrerá em breve.
- A Passagem de mensagens assíncrona é a mais legal, a mais rápida e a mais promissora.
A idéia do ASYMP é muito semelhante ao Pregel:
- os nós são distribuídos, mantêm seu estado e podem enviar uma mensagem aos vizinhos;
- uma fila é construída na máquina com prioridades, o que enviar (a ordem pode ser diferente da ordem de adição);
- tendo recebido uma mensagem, o nó pode ou não alterar o estado; ao mudar, enviamos uma mensagem aos vizinhos;
- terminar quando todas as filas estiverem vazias.
Por exemplo, ao procurar componentes conectados, inicializamos todos os vértices com pesos aleatórios U [0,1], após o qual começamos a enviar pelo menos vizinhos um para o outro. Assim, tendo recebido seus mínimos dos vizinhos, procuramos um mínimo para eles, etc., até que o mínimo seja estabilizado. Eles observam um ponto importante para otimização: recolher as mensagens de um nó (esta é a vez), deixando apenas o último. Eles também falam sobre como é fácil recuperar-se de falhas enquanto mantém o estado dos nós.
Eles dizem que constroem algoritmos muito rápidos, sem problemas, parece verdade - o conceito é simples e racional. Existem
publicações .
Como resultado, a conclusão sugere-se: é triste contar histórias sobre tecnologias fechadas, mas alguns bits úteis podem ser capturados.