
Neste artigo, construiremos um modelo básico de uma rede neural convolucional capaz de realizar o
reconhecimento de emoções nas imagens. O reconhecimento de emoções, no nosso caso, é uma tarefa de classificação binária, cujo objetivo é dividir as imagens em positivas e negativas.
Todo o código, documentos de notebook e outros materiais, incluindo o Dockerfile, podem ser encontrados
aqui .
Dados
O primeiro passo em praticamente todas as tarefas de aprendizado de máquina é entender os dados. Vamos fazer isso.
Estrutura do conjunto de dados
Os dados brutos podem ser baixados
aqui (no documento
Baseline.ipynb , todas as ações nesta seção são executadas automaticamente). Inicialmente, os dados estão no arquivo do formato Zip *. Descompacte-o e familiarize-se com a estrutura dos arquivos recebidos.
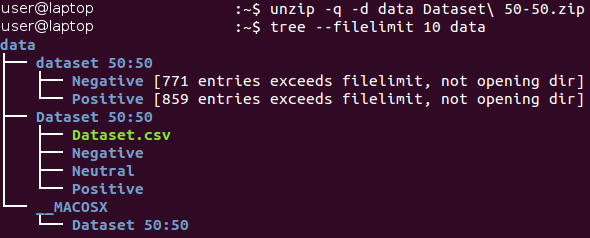
Todas as imagens são armazenadas no catálogo “conjunto de dados 50:50” e distribuídas entre seus dois subdiretórios, cujo nome corresponde à sua classe - Negativo e Positivo. Observe que a tarefa é um pouco
desequilibrada - 53% das imagens são positivas e apenas 47% são negativas. Normalmente, os dados nos problemas de classificação são considerados desequilibrados se o número de exemplos em diferentes classes variar muito significativamente. Existem
várias maneiras de trabalhar com dados desequilibrados - por exemplo, superamostragem, superamostragem, alteração dos fatores de ponderação dos dados etc. No nosso caso, o desequilíbrio é insignificante e não deve afetar drasticamente o processo de aprendizado. É necessário apenas lembrar que o classificador ingênuo, sempre produzindo o valor "positivo", fornecerá um valor de precisão de aproximadamente 53% para esse conjunto de dados.
Vejamos algumas imagens de cada classe.
Negativo

 Positivo
Positivo


À primeira vista, imagens de diferentes classes são realmente diferentes umas das outras. No entanto, vamos fazer um estudo mais profundo e tentar encontrar exemplos ruins - imagens semelhantes pertencentes a diferentes classes.
Por exemplo, temos cerca de 90 imagens de cobras rotuladas como negativas e cerca de 40 imagens muito semelhantes de cobras rotuladas como positivas.
Imagem positiva de uma cobra Imagem negativa de uma cobra
Imagem negativa de uma cobra
A mesma dualidade ocorre com aranhas (130 imagens negativas e 20 positivas), nudez (15 imagens negativas e 45 positivas) e algumas outras classes. Ficamos com a sensação de que a marcação das imagens foi realizada por pessoas diferentes, e sua percepção da mesma imagem pode ser diferente. Portanto, a rotulagem contém sua inconsistência inerente. Essas duas imagens de cobras são quase idênticas, enquanto diferentes especialistas as atribuem a diferentes classes. Assim, podemos concluir que dificilmente é possível garantir 100% de precisão ao trabalhar com essa tarefa devido à sua natureza. Acreditamos que uma estimativa mais realista da precisão seria um valor de 80% - esse valor é baseado na proporção de imagens semelhantes encontradas em diferentes classes durante uma verificação visual preliminar.
Separação do processo de treinamento / verificação
Nós sempre nos esforçamos para criar o melhor modelo possível. No entanto, qual é o significado desse conceito? Existem muitos critérios diferentes para isso, como: qualidade, lead time (aprendizado + obtenção de resultados) e consumo de memória. Alguns deles podem ser medidos de maneira fácil e objetiva (por exemplo, tempo e tamanho da memória), enquanto outros (qualidade) são muito mais difíceis de determinar. Por exemplo, seu modelo pode demonstrar 100% de precisão ao aprender com exemplos que foram usados muitas vezes, mas falham em trabalhar com novos exemplos. Esse problema é chamado de
super adaptação e é um dos mais importantes no aprendizado de máquina. Há também o problema de ter um
ajuste insuficiente : nesse caso, o modelo não pode aprender com os dados apresentados e mostra previsões ruins, mesmo ao usar um conjunto de dados de treinamento fixo.
Para resolver o problema do sobreajuste,
é utilizada a chamada técnica de
reter parte das amostras . Sua idéia principal é dividir os dados de origem em duas partes:
- Um conjunto de treinamento , que geralmente compõe a maior parte do conjunto de dados e é usado para treinar o modelo.
- O conjunto de testes geralmente é uma pequena parte dos dados de origem, divididos em duas partes antes de executar todos os procedimentos de treinamento. Este conjunto não é usado de maneira alguma no treinamento e é considerado como novos exemplos para testar o modelo após a conclusão do treinamento.
Usando esse método, podemos observar o quão
generalizado nosso modelo (ou seja, funciona com exemplos desconhecidos anteriormente).
Este artigo usará uma proporção de 4/1 para os conjuntos de treinamento e teste. Outra técnica que usamos é a chamada
estratificação . Este termo refere-se ao particionamento de cada classe independentemente de todas as outras classes. Essa abordagem permite manter o mesmo equilíbrio entre os tamanhos das turmas nos conjuntos de treinamento e teste. A estratificação usa implicitamente a suposição de que a distribuição de exemplos não muda quando os dados de origem são alterados e permanece a mesma ao usar novos exemplos.
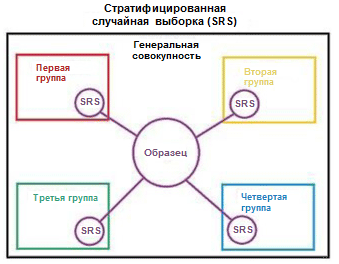
Ilustramos o conceito de estratificação com um exemplo simples. Suponha que tenhamos quatro grupos / classes de dados com um número apropriado de objetos: crianças (5), adolescentes (10), adultos (80) e idosos (5); veja a imagem à direita (da
Wikipedia ). Agora precisamos dividir esses dados em dois conjuntos de amostras na proporção de 3/2. Ao utilizar a estratificação dos exemplos, a seleção dos objetos será feita independentemente de cada grupo: 2 objetos do grupo de crianças, 4 objetos do grupo de adolescentes, 32 objetos do grupo de adultos e 2 objetos do grupo de idosos. O novo conjunto de dados contém 40 objetos, que são exatamente 2/5 dos dados originais. Ao mesmo tempo, o saldo entre as classes no novo conjunto de dados corresponde ao saldo nos dados de origem.
Todas as ações acima são implementadas em uma função, chamada de
prepare_data ; Essa função pode ser encontrada no arquivo Python
utils.py . Essa função carrega os dados, os divide em conjuntos de treinamento e teste usando um número aleatório fixo (para reprodução posterior) e distribui os dados de acordo com os diretórios do disco rígido para uso posterior.
Pré-tratamento e Aumento
Em um dos artigos anteriores, foram descritas ações de pré-processamento e possíveis razões para seu uso na forma de aumento de dados. As redes neurais convolucionais são modelos bastante complexos e são necessárias grandes quantidades de dados para treiná-las. No nosso caso, existem apenas 1600 exemplos - isso, é claro, não é suficiente.
Portanto, queremos expandir o conjunto de dados usados pelo
aumento de dados. De acordo com as informações contidas no artigo sobre pré-processamento de dados, a biblioteca Keras * oferece a capacidade de aumentar os dados rapidamente ao lê-los no disco rígido. Isso pode ser feito através da classe
ImageDataGenerator .
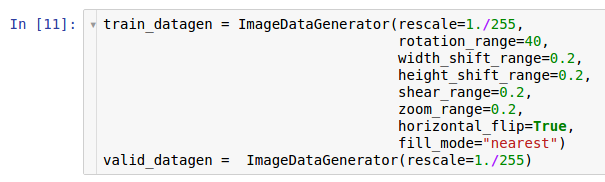
Duas instâncias dos geradores são criadas aqui. A primeira instância é para treinamento e usa muitas transformações aleatórias - como rotação, deslocamento, convolução, dimensionamento e rotação horizontal - enquanto lê dados do disco e os transfere para o modelo. Como resultado, o modelo recebe os exemplos convertidos e cada exemplo recebido pelo modelo é exclusivo devido à natureza aleatória dessa conversão. A segunda cópia é para verificação e apenas amplia as imagens. Os geradores de aprendizado e teste têm apenas uma transformação comum - o zoom. Para garantir a estabilidade computacional do modelo, é necessário usar o intervalo [0; 1] em vez de [0; 255]
Arquitetura de modelo
Após estudar e preparar os dados iniciais, segue o estágio de criação do modelo. Como uma pequena quantidade de dados está disponível, construiremos um modelo relativamente simples para poder treiná-lo adequadamente e eliminar a situação de sobreajuste. Vamos tentar a
arquitetura de estilo
VGG , mas use menos camadas e filtros.
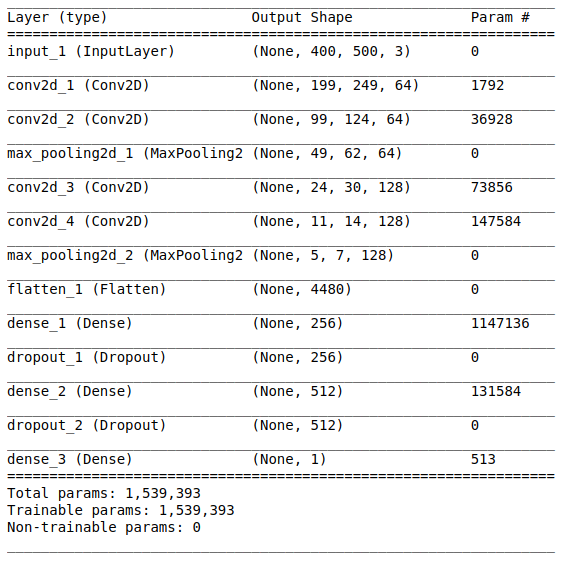

A arquitetura de rede consiste nas seguintes partes:
[Camada de convolução + camada de convolução + seleção de valor máximo] × 2A primeira parte contém duas camadas convolucionais sobrepostas com 64 filtros (com tamanho 3 e etapa 2) e uma camada para selecionar o valor máximo (com tamanho 2 e etapa 2) localizado após eles. Essa parte também é chamada de
unidade de extração de recurso , já que os filtros extraem com eficiência recursos significativos dos dados de entrada (consulte o artigo
Visão geral das redes neurais convolucionais para obter mais informações).
AlinhamentoEsta parte é obrigatória, pois tensores quadridimensionais são obtidos na saída da parte convolucional (exemplos, altura, largura e canais). No entanto, para uma camada comum totalmente conectada, precisamos de um tensor bidimensional (exemplos, recursos) como entrada. Portanto, é necessário
alinhar o tensor em torno dos três últimos eixos para combiná-los em um eixo. De fato, isso significa que consideramos cada ponto em cada mapa de recursos como uma propriedade separada e os alinhamos em um vetor. A figura abaixo mostra um exemplo de uma imagem 4 × 4 com 128 canais, que é alinhada em um vetor estendido com um comprimento de 1024 elementos.
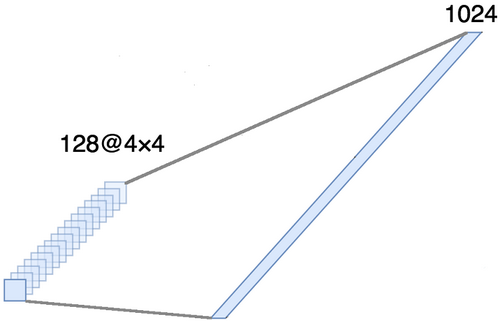 [Camada completa + método de exclusão] × 2
[Camada completa + método de exclusão] × 2Aqui está a
parte de classificação da rede. Ela tem uma visão alinhada das características das imagens e tenta classificá-las da melhor maneira possível. Essa parte da rede consiste em dois blocos sobrepostos que consistem em uma camada totalmente conectada e
um método de exclusão . Já nos familiarizamos com camadas totalmente conectadas - geralmente são camadas com uma conexão totalmente conectada. Mas qual é o "método de exclusão"? O método de exclusão é uma
técnica de regularização que ajuda a evitar o ajuste excessivo. Um dos possíveis sinais de sobreajuste são valores extremamente diferentes dos coeficientes de peso (ordens de grandeza). Existem muitas maneiras de resolver esse problema, incluindo a redução de peso e o método de eliminação. A idéia do método de eliminação é desconectar neurônios aleatórios durante o treinamento (a lista de neurônios desconectados deve ser atualizada após cada era do pacote / treinamento). Isso evita fortemente a obtenção de valores completamente diferentes para os coeficientes de ponderação - dessa maneira a rede é regularizada.
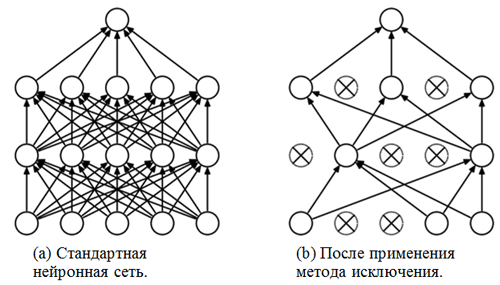
Um exemplo de uso do método de exclusão (a figura é retirada do artigo
Método de exclusão: uma maneira simples de evitar o ajuste excessivo em redes neurais ):
Módulo sigmoideA camada de saída deve corresponder à declaração do problema. Nesse caso, estamos lidando com o problema de classificação binária, por isso precisamos de um neurônio de saída com uma função de ativação
sigmóide , que estima a probabilidade P de pertencer à classe com o número 1 (no nosso caso, serão imagens positivas). Então a probabilidade de pertencer à classe com o número 0 (imagens negativas) pode ser facilmente calculada como 1 - P.
Configurações e opções de treinamento
Escolhemos a arquitetura do modelo e a especificamos usando a biblioteca Keras para a linguagem Python. Além disso, antes de iniciar o treinamento do modelo, é necessário
compilá- lo.

Na fase de compilação, o modelo é ajustado para treinamento. Nesse caso, três parâmetros principais devem ser especificados:
- O otimizador . Nesse caso, usamos o otimizador padrão Adam *, que é um tipo de algoritmo estocástico de descida de gradiente com um momento e velocidade de aprendizado adaptável (para obter mais informações, consulte a entrada de blog de S. Ruder Visão geral dos algoritmos de otimização de descida de gradiente ).
- Função de perda . Nossa tarefa é um problema de classificação binária, portanto, seria apropriado usar a entropia cruzada binária como uma função de perda.
- Métricas . Esse é um argumento opcional com o qual você pode especificar métricas adicionais a serem rastreadas durante o processo de treinamento. Nesse caso, precisamos rastrear a precisão junto com a função objetivo.
Agora estamos prontos para treinar o modelo. Observe que o procedimento de treinamento é realizado usando os geradores inicializados na seção anterior.
O número de eras é outro hiperparâmetro que pode ser personalizado. Aqui, simplesmente atribuímos um valor a 10. Também queremos salvar o modelo e o histórico de aprendizado para poder fazer o download mais tarde.

Classificação
Agora vamos ver o quão bem o nosso modelo funciona. Primeiro, consideramos a mudança nas métricas no processo de aprendizado.
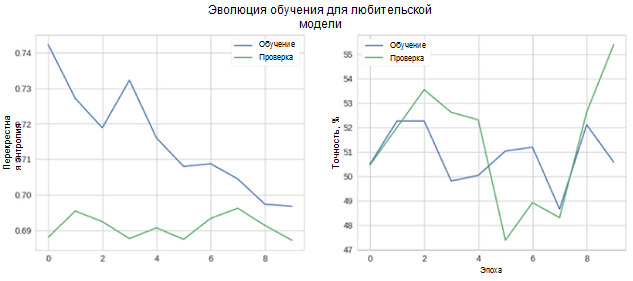
Na figura, você pode ver que a entropia cruzada da verificação e precisão não diminui com o tempo. Além disso, a métrica de precisão para o conjunto de treinamento e teste simplesmente flutua em torno do valor de um classificador aleatório. A precisão final para o conjunto de testes é de 55%, o que é apenas ligeiramente melhor do que uma estimativa aleatória.
Vamos ver como as previsões do modelo são distribuídas entre as classes. Para esse fim, é necessário criar e visualizar uma
matriz de imprecisões usando a função correspondente do pacote Sklearn * para a linguagem Python.
Cada célula na matriz de imprecisões tem seu próprio nome:
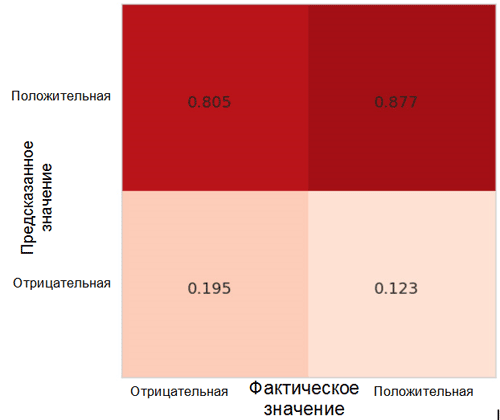
- Taxa positiva verdadeira = TPR (célula superior direita) representa a proporção de exemplos positivos (classe 1, ou seja, emoções positivas no nosso caso), classificados corretamente como positivos.
- Taxa de falsos positivos = FPR (célula inferior direita) representa a proporção de exemplos positivos incorretamente classificados como negativos (classe 0, ou seja, emoções negativas).
- Taxa negativa verdadeira = TNR (célula inferior esquerda) representa a proporção de exemplos negativos que são classificados corretamente como negativos.
- Taxa de Falso Negativo = FNR (célula superior esquerda) representa a proporção de exemplos negativos que são incorretamente classificados como positivos.
No nosso caso, tanto o TPR quanto o FPR estão próximos de 1. Isso significa que quase todos os objetos foram classificados como positivos. Portanto, nosso modelo não está muito distante do modelo ingênuo de base, com previsões constantes de uma classe maior (no nosso caso, são imagens positivas).
Outra métrica interessante que é interessante observar é a curva de desempenho do receptor (curva ROC) e a área sob essa curva (ROC AUC). Uma definição formal desses conceitos pode ser encontrada
aqui . Em poucas palavras, a curva ROC mostra como o classificador binário funciona.
O classificador de nossa rede neural convolucional tem um módulo sigmóide como saída, que atribui a probabilidade do exemplo à classe 1. Agora, suponha que nosso classificador mostre bom trabalho e atribua baixos valores de probabilidade para exemplos da classe 0 (o histograma verde na figura abaixo), altos valores de probabilidade para exemplos Classe 1 (histograma azul).
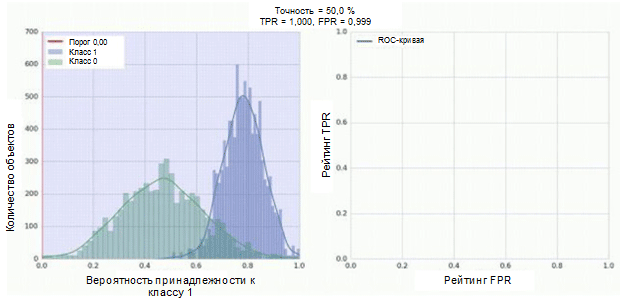
A curva ROC mostra como o indicador TPR depende do indicador FPR ao mover o limiar de classificação de 0 para 1 (figura à direita, parte superior). Para uma melhor compreensão do conceito de limite, lembre-se de que temos a probabilidade de pertencer à classe 1 para cada exemplo. No entanto, a probabilidade ainda não é um rótulo de classe. Portanto, ele deve ser comparado com um limite para determinar a qual classe o exemplo pertence. Por exemplo, se o valor limite for 1, todos os exemplos devem ser classificados como pertencentes à classe 0, pois o valor da probabilidade não pode ser maior que 1 e os valores dos indicadores FPR e TPR nesse caso serão 0 (uma vez que nenhuma das amostras é classificada como positiva ) Esta situação corresponde ao ponto mais à esquerda na curva ROC. No outro lado da curva, há um ponto em que o valor limite é 0: isso significa que todas as amostras são classificadas como pertencentes à classe 1, e os valores de TPR e FPR são iguais a 1. Os pontos intermediários mostram o comportamento da dependência de TPR / FPR quando o valor limite é alterado.
A linha diagonal no gráfico corresponde a um classificador aleatório. Quanto melhor o nosso classificador funcionar, mais próxima sua curva estará do ponto superior esquerdo do gráfico. Assim, o indicador objetivo da qualidade do classificador é a área sob a curva ROC (indicador ROC AUC). O valor desse indicador deve ser o mais próximo possível de 1. O valor de AUC de 0,5 corresponde a um classificador aleatório.
A AUC em nosso modelo (veja a figura acima) é 0,57, o que está longe de ser o melhor resultado.
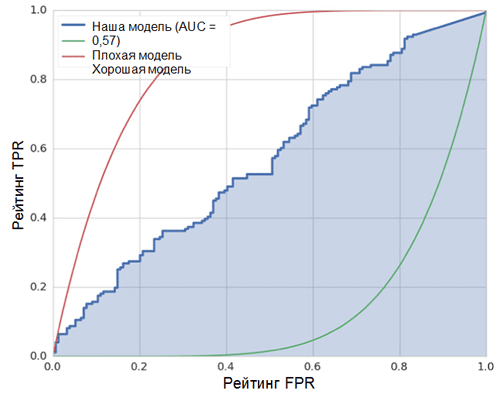
Todas essas métricas indicam que o modelo resultante é apenas ligeiramente melhor que o classificador aleatório. Existem várias razões para isso, as principais são descritas abaixo:
- Quantidade muito pequena de dados para treinamento, insuficiente para destacar os recursos característicos das imagens. Mesmo o aumento de dados não poderia ajudar nesse caso.
- Um modelo de rede neural convolucional relativamente complexo (comparado a outros modelos de aprendizado de máquina) com um grande número de parâmetros.
Conclusão
Neste artigo, criamos um modelo de rede neural convolucional simples para reconhecer emoções em imagens. Ao mesmo tempo, na fase de treinamento, vários métodos foram utilizados para o aumento dos dados, e o modelo também foi avaliado usando um conjunto de métricas como precisão, curva ROC, ROC AUC e matriz de imprecisão. O modelo mostrou resultados, apenas alguns dos melhores aleatórios. .