Uma demonstração do uso de ferramentas de código aberto, como Packer e Terraform, para fornecer continuamente alterações na infraestrutura a um ambiente em nuvem amigável.
O material foi baseado em uma apresentação de Paul Stack em nossa conferência de outono do
DevOops 2017. Paul é um desenvolvedor de infraestrutura que trabalhava na HashiCorp e participou do desenvolvimento de ferramentas usadas por milhões de pessoas (por exemplo, Terraform). Ele frequentemente fala em conferências e transmite a prática da vanguarda das implementações de CI / CD, os princípios da organização adequada da parte de operações, e é capaz de explicar claramente por que os administradores fazem isso. O restante do artigo é narrado na primeira pessoa.
Então, vamos começar imediatamente com algumas descobertas importantes.
Servidor de longa duração é uma porcaria

Anteriormente, trabalhei em uma organização em que implantamos o Windows Server 2003 em 2008 e hoje eles ainda estão em produção. E essa empresa não está sozinha. Usando a área de trabalho remota nesses servidores, eles instalam o software manualmente, baixando arquivos binários da Internet. Essa é uma péssima idéia, porque os servidores não são típicos. Você não pode garantir que o mesmo aconteça na produção e no ambiente de desenvolvimento, no ambiente intermediário, no ambiente de controle de qualidade.
Infraestrutura Imutável
Em 2013, apareceu um artigo no blog de Chad Foiler intitulado “Jogue seus servidores e grave seu código: infraestrutura imutável e componentes descartáveis” (Chad Foiler
“ Jogue
lixo nos servidores e grave seu código: infraestrutura imutável e componentes descartáveis” ). Isso é principalmente uma conversa de que a infraestrutura imutável é o caminho a seguir. Criamos a infraestrutura e, se precisarmos alterá-la, estamos criando uma nova infraestrutura. Essa abordagem é muito comum na nuvem, porque aqui é rápida e barata. Se você possui data centers físicos, isso é um pouco mais complicado. Obviamente, se você executa a virtualização do data center, as coisas ficam mais fáceis. No entanto, se você ainda iniciar servidores físicos a cada vez, demorará um pouco mais para inserir um novo do que para modificar um existente.
Infraestrutura descartável
Segundo os programadores funcionais, "imutável" é realmente o termo errado para esse fenômeno. Como para ser realmente imutável, sua infraestrutura precisa de um sistema de arquivos somente leitura: nenhum arquivo será gravado localmente, ninguém poderá usar SSH ou RDP, etc. Assim, parece que, de fato, a infraestrutura não é imutável.
A terminologia foi discutida no Twitter por seis ou até oito dias por várias pessoas. No final, eles concordaram que uma “infraestrutura única” é uma formulação mais apropriada. Quando o ciclo de vida da “infraestrutura única” termina, ele pode ser facilmente destruído. Você não precisa se apegar a isso.
Eu darei uma analogia. Vacas de fazenda geralmente não são consideradas animais de estimação.

Quando você tem gado na fazenda, não lhes dá nomes individuais. Cada indivíduo tem um número e uma etiqueta. O mesmo acontece com os servidores. Se você ainda criou servidores em produção manualmente em 2006, eles têm nomes significativos, por exemplo, "Banco de Dados SQL na Produção 01". E eles têm um significado muito específico. E se um dos servidores travar, o inferno começa.
Se um dos animais do rebanho morre, o fazendeiro simplesmente compra um novo. Essa é a "infraestrutura única".
Entrega contínua
Então, como você combina isso com a entrega contínua?
Tudo o que estou falando agora já existe há algum tempo. Estou apenas tentando combinar as idéias de desenvolvimento de infraestrutura e desenvolvimento de software.
Os desenvolvedores de software estão comprometidos com a entrega contínua e a integração contínua. Por exemplo, Martin Fowler escreveu sobre a integração contínua em seu blog no início dos anos 2000. Jez Humble promove há muito tempo a entrega contínua.
Se você der uma olhada mais de perto, não há nada criado especificamente para o código-fonte do software. Existe uma definição padrão da Wikipedia:
entrega contínua é um conjunto de práticas e princípios que visam criar, testar e liberar software o mais rápido possível .
A definição não significa aplicativos da Web ou APIs, trata-se de software em geral. Criar software de quebra-cabeça requer muitas peças de quebra-cabeça. Dessa forma, você pode praticar a entrega contínua de código de infraestrutura da mesma maneira.
O desenvolvimento de infraestrutura e aplicativos são orientações bastante próximas. E as pessoas que escrevem código de aplicativo também escrevem código de infraestrutura (e vice-versa). Esses mundos começam a se unir. Não existe mais essa separação e as armadilhas específicas de cada um dos mundos.
Princípios e práticas de entrega contínua
A entrega contínua possui vários princípios:
- O processo de liberação / implantação de software deve ser repetível e confiável.
- Automatize tudo!
- Se um procedimento for difícil ou doloroso, faça-o com mais frequência.
- Mantenha tudo no controle de origem.
- Concluído - significa "inédito".
- Integre trabalho com qualidade!
- Todos são responsáveis pelo processo de liberação.
- Aumentar a continuidade.
Mais importante, porém, a entrega contínua tem quatro práticas. Leve-os e transfira diretamente para a infraestrutura:
- Crie arquivos binários apenas uma vez. Crie seu servidor uma vez. Aqui estamos falando sobre “descartabilidade” desde o início.
- Use o mesmo mecanismo de implantação em cada ambiente. Não pratique implantações diferentes no desenvolvimento e produção. Você deve usar o mesmo caminho em cada ambiente. Isso é muito importante.
- Teste sua implantação. Eu criei muitos aplicativos. Criei muitos problemas porque não segui o mecanismo de implantação. Você deve sempre verificar o que acontece. E não estou dizendo que você deva gastar cinco ou seis horas em testes em larga escala. Chega "teste de fumaça". Você tem uma parte essencial do sistema, que, como você sabe, permite que você e sua empresa ganhem dinheiro. Não tenha preguiça de começar o teste. Caso contrário, pode haver interrupções que custarão dinheiro à sua empresa.
- E, finalmente, a coisa mais importante. Se algo quebrar, pare e corrija-o imediatamente! Você não pode permitir que o problema cresça e fique cada vez pior. Você tem que consertar isso. Isso é realmente importante.
Alguém já leu o livro
Entrega contínua ?

Tenho certeza de que suas empresas pagarão uma cópia que você pode transferir dentro da equipe. Não estou dizendo que você deveria se sentar e passar um dia de folga lendo. Se você o fizer, provavelmente desejará sair da TI. Mas eu recomendo periodicamente o domínio de pequenos pedaços do livro, digerindo-os e pensando em como transferir isso para o seu ambiente, para a sua cultura e para o seu processo. Um pequeno pedaço de cada vez. Porque o fornecimento contínuo é uma conversa sobre melhoria contínua. Não é fácil sentar no escritório com colegas e o chefe e iniciar uma conversa com a pergunta: “Como implementaremos a entrega contínua?”. Depois, escreva 10 coisas no quadro e depois de 10 dias entenda que você a implementou. Isso leva muito tempo, causa muitos protestos, porque com a introdução de mudanças na cultura.
Hoje vamos usar duas ferramentas: Terraform e Packer (ambos são desenvolvimentos da Hashicorp). Uma discussão adicional será sobre por que devemos usar o Terraform e como integrá-lo ao nosso ambiente. Não é por acaso que falo sobre essas duas ferramentas. Até recentemente, eu também trabalhava na Hashicorp. Mas mesmo depois de deixar o Hashicorp, ainda contribuo com o código dessas ferramentas, porque as acho realmente úteis.
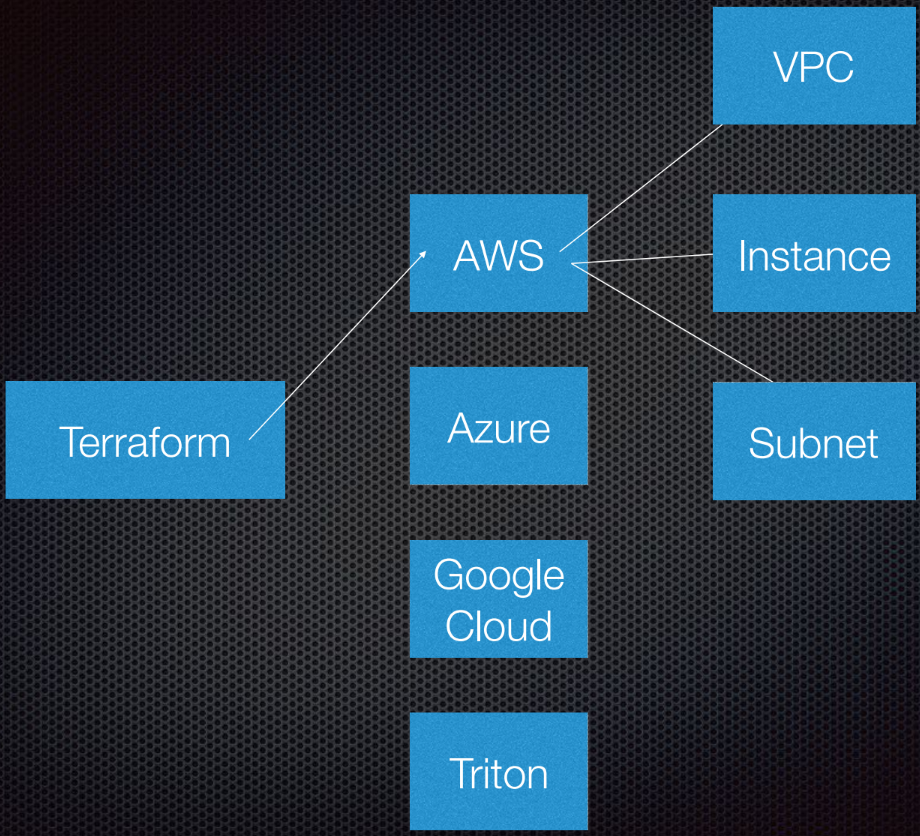
O Terraform suporta a interação com os provedores. Provedores são nuvens, serviços Saas, etc.
Dentro de cada provedor de serviços em nuvem, existem vários recursos, como sub-rede, VPC, balanceador de carga, etc. Usando o DSL (idioma específico do domínio), você informa à Terraform como será sua infraestrutura.
Terraform usa a teoria dos grafos.

Você provavelmente conhece a teoria dos grafos. Os nós fazem parte da nossa infraestrutura, como um balanceador de carga, sub-rede ou VPC. Costelas são as relações entre esses sistemas. Isso é tudo o que eu pessoalmente considero necessário saber sobre a teoria dos grafos para usar o Terraform. Deixamos o resto para os especialistas.

O Terraform realmente usa um gráfico direcionado porque conhece não apenas os relacionamentos, mas também sua ordem: que A (suponha que A seja VPC) deve ser definido como B, que é uma sub-rede. E B deve ser criado antes de C (instância), porque existe um procedimento prescrito para criar abstrações no Amazon ou em qualquer outra nuvem.
Mais informações sobre esse tópico estão disponíveis no
YouTube por Paul Hinze, que ainda é diretor de infraestrutura da Hashicorp. Por referência - uma ótima conversa sobre infraestrutura e teoria de grafos.
Prática
Escrever um código é muito melhor do que discutir uma teoria.
Eu criei anteriormente a AMI (Amazon Machine Images). Eu uso o Packer para criá-los e vou mostrar como fazer isso.
A AMI é uma instância de um servidor virtual na Amazon, é predefinida (em termos de configuração, aplicativos etc.) e é criada a partir de uma imagem. Adoro poder criar novas AMIs. Essencialmente, as AMIs são meus contêineres do Docker.
Então, eu tenho AMI, eles têm identificação. Indo para a interface da Amazon, vemos que temos apenas uma AMI e nada mais:

Eu posso lhe mostrar o que há nesta AMI. Tudo é muito simples.
Eu tenho um modelo de arquivo JSON:
{ "variables": { "source_ami": "", "region": "", "version": "" }, "builders": [{ "type": "amazon-ebs", "region": "{{user 'region'}}", "source_ami": "{{user 'source_ami'}}", "ssh_pty": true, "instance_type": "t2.micro", "ssh_username": "ubuntu", "ssh_timeout": "5m", "associate_public_ip_address": true, "ami_virtualization_type": "hvm", "ami_name": "application_instance-{{isotime \"2006-01-02-1504\"}}", "tags": { "Version": "{{user 'version'}}" } }], "provisioners": [ { "type": "shell", "start_retry_timeout": "10m", "inline": [ "sudo apt-get update -y", "sudo apt-get install -y ntp nginx" ] }, { "type": "file", "source": "application-files/nginx.conf", "destination": "/tmp/nginx.conf" }, { "type": "file", "source": "application-files/index.html", "destination": "/tmp/index.html" }, { "type": "shell", "start_retry_timeout": "5m", "inline": [ "sudo mkdir -p /usr/share/nginx/html", "sudo mv /tmp/index.html /usr/share/nginx/html/index.html", "sudo mv /tmp/nginx.conf /etc/nginx/nginx.conf", "sudo systemctl enable nginx.service" ] } ] }
Temos variáveis que passamos e o Packer possui uma lista dos chamados Construtores para diferentes áreas; existem muitos deles. O Builder usa uma fonte AMI especial, que eu transmito em um identificador AMI. Dou a ele o nome de usuário e a senha do SSH e também indico se ele precisa de um endereço IP público para que as pessoas possam acessá-lo de fora. No nosso caso, isso realmente não importa, porque é uma instância da AWS para o Packer.
Também definimos o nome e as tags da AMI.
Você não precisa analisar esse código. Ele está aqui apenas para mostrar como ele funciona. A parte mais importante aqui é a versão. Isso se tornará relevante mais tarde, quando entrarmos no Terraform.
Depois que o construtor chama a instância, os agentes de fornecimento são ativados nela. Na verdade, eu instalo o NCP e o nginx para mostrar o que posso fazer aqui. Copio alguns arquivos e apenas faço a configuração do nginx. Tudo é muito simples. Em seguida, ativei o nginx para que ele inicie quando a instância for iniciada.
Então, eu tenho um servidor de aplicativos e funciona. Eu posso usá-lo no futuro. No entanto, eu sempre verifico meus modelos do Packer. Porque é uma configuração JSON onde você pode encontrar alguns problemas.
Para fazer isso, eu executo o comando:
make validate
Recebo a resposta de que o modelo do Packer foi verificado com sucesso:
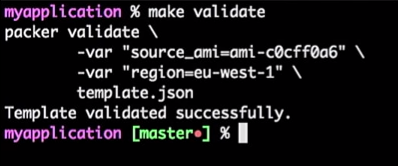
Este é apenas um comando, para que eu possa conectá-lo à ferramenta de IC (qualquer um). Na verdade, será um processo: se o desenvolvedor alterar o modelo, a solicitação pull for gerada, a ferramenta de IC verificará a solicitação, executará o equivalente à verificação do modelo e publicará o modelo em caso de verificação bem-sucedida. Tudo isso pode ser combinado no "Master".
Temos um fluxo para modelos de AMI - você só precisa aumentar a versão.
Suponha que o desenvolvedor tenha criado uma nova versão da AMI.
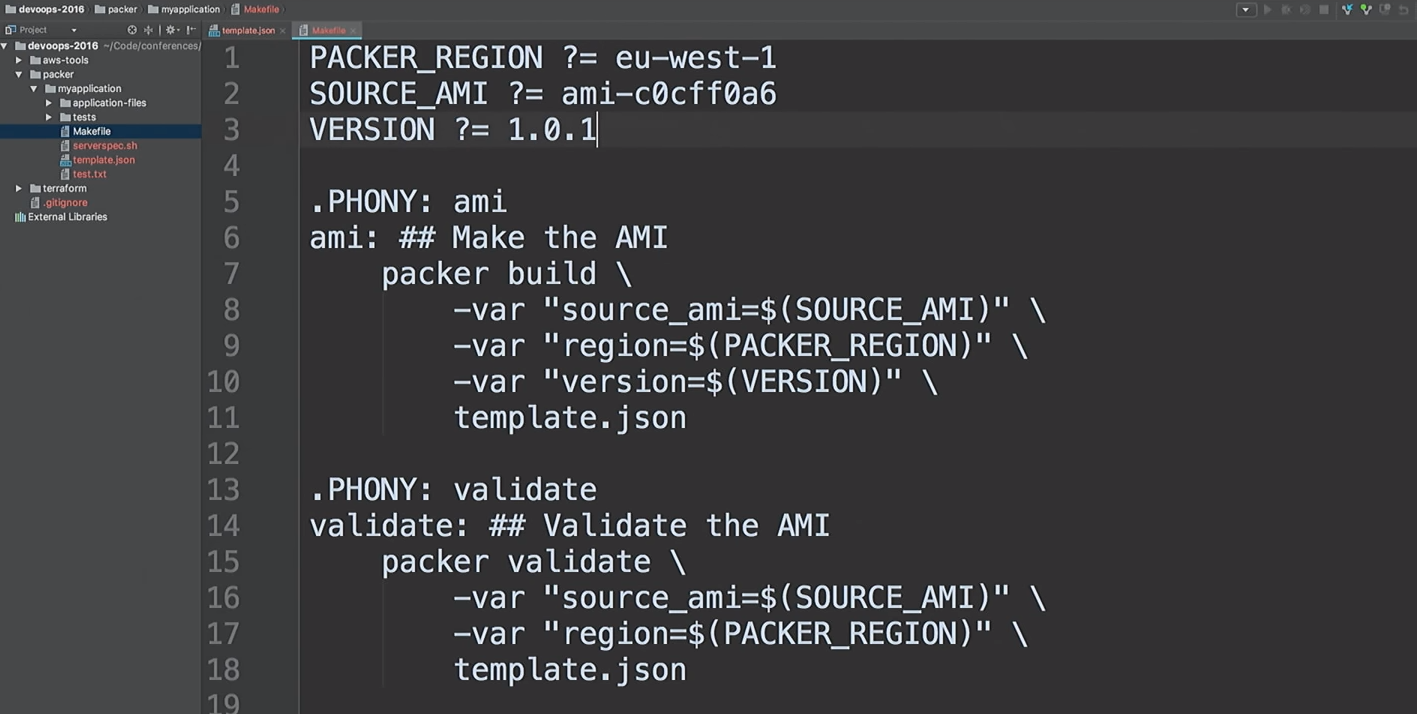
Vou apenas corrigir a versão nos arquivos 1.0.0 a 1.0.1 para mostrar a diferença:
<html> <head> <tittle>Welcome to DevOops!</tittle> </head> <body> <h1>Welcome!</h1> <p>Welcome to DevOops!</p> <p>Version: 1.0.1</p> </body> </html>
Voltarei à linha de comando e começarei a criação da AMI.
Não gosto de dirigir as mesmas equipes. Eu gosto de criar AMI rapidamente, então eu uso makefiles. Vamos dar uma olhada com o
cat no meu makefile:
cat Makefile

Este é o meu makefile. Eu até forneci a Ajuda: digito
make e clico na guia, e isso me mostra todo o destino.

Então, vamos criar uma nova versão 1.0.1 da AMI.
make ami

De volta ao Terraform.
Enfatizo que este não é um código de produção. Isto é uma demonstração. Existem maneiras de fazer a mesma coisa melhor.
Eu uso os módulos Terraform em todos os lugares. Como não trabalho mais no Hashicorp, posso expressar minha opinião sobre os módulos. Para mim, os módulos estão no nível de encapsulamento. Por exemplo, eu gosto de encapsular tudo relacionado à VPC: redes, sub-redes, tabelas de roteamento, etc.
O que está acontecendo lá dentro? Os desenvolvedores que trabalham com isso podem não se importar com isso. Eles precisam ter um entendimento básico de como a nuvem funciona, o que é a VPC. Mas não é necessário se aprofundar nos detalhes. Somente as pessoas que realmente precisam alterar um módulo devem entendê-lo.
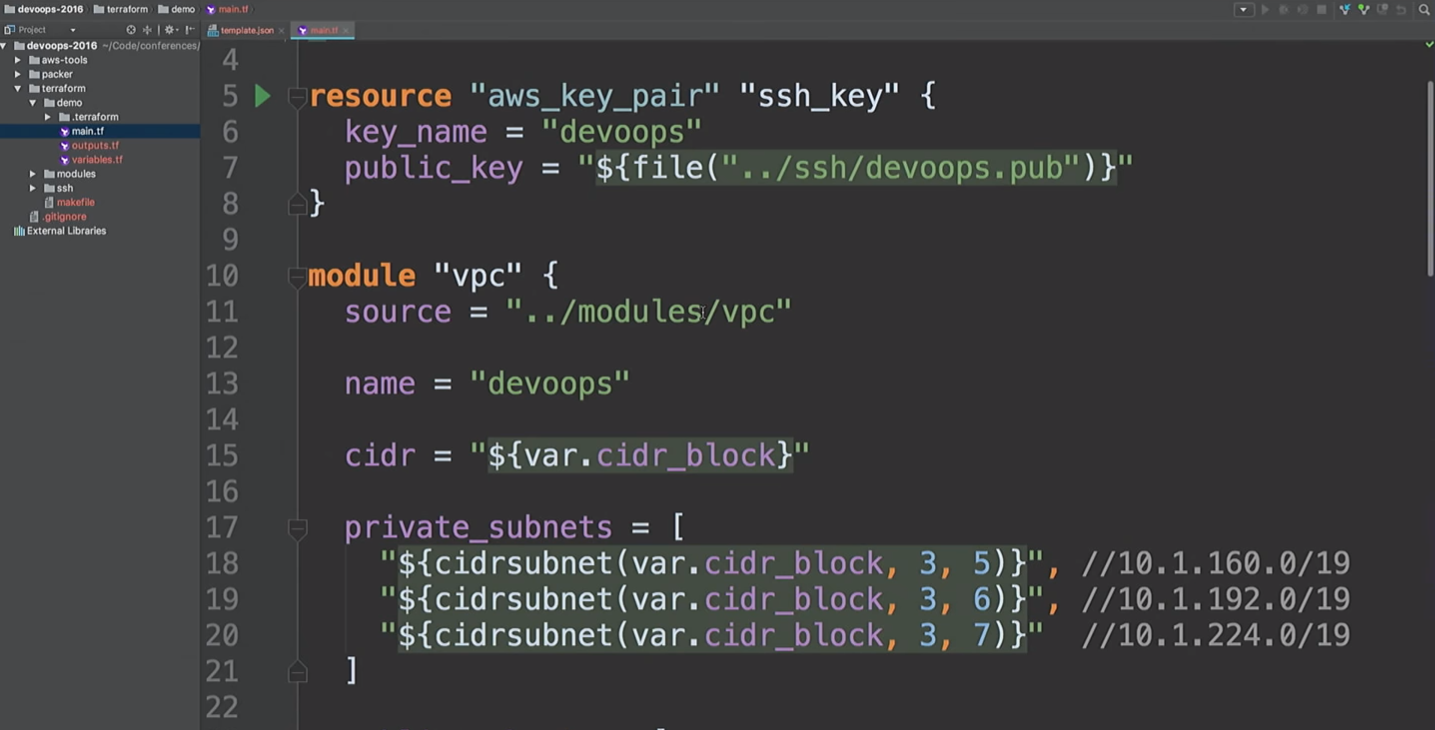

Aqui, vou criar um recurso da AWS e um módulo VPC. O que está acontecendo aqui? Pegue o
cidr_block nível
cidr_block e crie três sub-redes privadas e três sub-redes públicas. A seguir, é apresentada uma lista de áreas de disponibilidade. Mas não sabemos o que são essas zonas de acessibilidade.

Nós estamos indo para criar uma VPN. Apenas não use este módulo VPN. É o openVPN, que cria uma instância da AWS que não possui um certificado. Ele usa apenas o endereço IP público e é mencionado aqui apenas para mostrar que podemos conectar-se à VPN. Existem ferramentas mais convenientes para criar uma VPN. Levei cerca de 20 minutos e duas cervejas para escrever a minha.
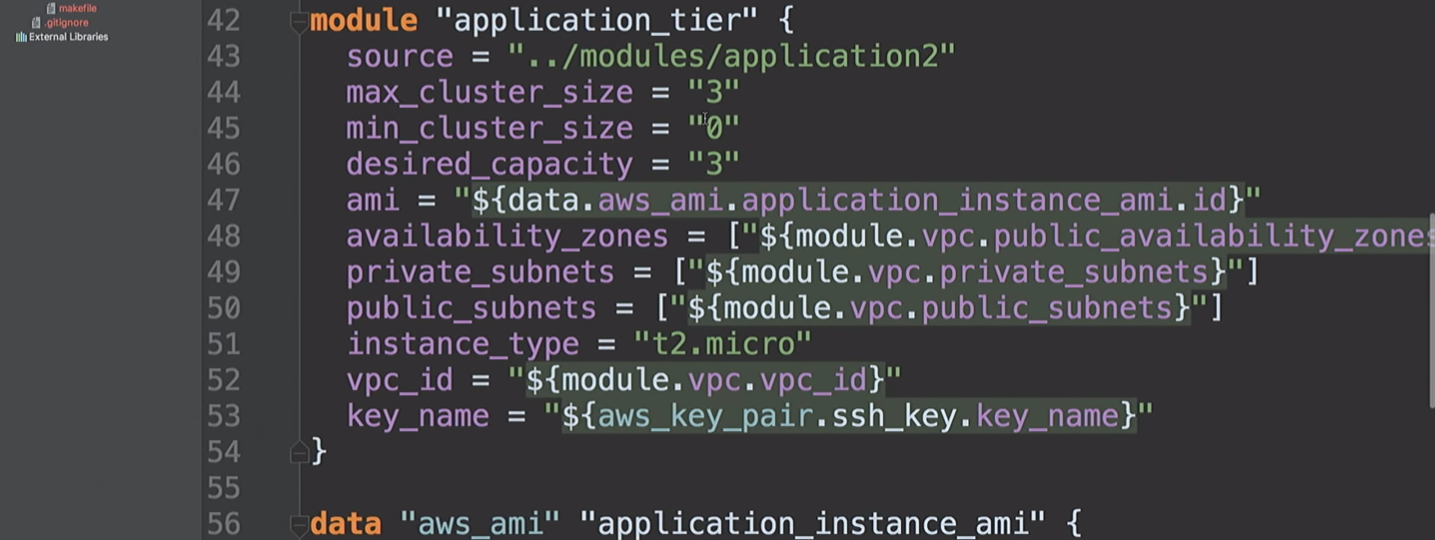


Em seguida, criamos uma camada de
application_tier , que é um grupo de dimensionamento automático - um balanceador de carga. Algumas configurações de inicialização são baseadas no AMI-ID e combinam várias sub-redes e zonas de disponibilidade e também usam uma chave SSH.
Vamos voltar a isso em um segundo.
Eu já mencionei zonas de disponibilidade. Eles diferem para diferentes contas da AWS. Minha conta nos EUA no leste pode ter acesso às zonas A, B e D. Sua conta da AWS pode ter acesso a B, C e E. Portanto, ao fixar esses valores no código, encontraremos problemas. Na Hashicorp, sugerimos que pudéssemos criar essas fontes de dados para poder perguntar à Amazon o que estava disponível para nós. Sob o capô, solicitamos uma descrição das zonas de disponibilidade e, em seguida, retornamos uma lista de todas as zonas da sua conta. Graças a isso, podemos usar fontes de dados para a AMI.
Agora chegamos ao fundo da minha demonstração. Criei um grupo de dimensionamento automático no qual três instâncias estão em execução. Por padrão, todos eles têm a versão 1.0.0.
Quando implantarmos a nova versão da AMI, inicio a configuração do Terraform novamente, isso mudará a configuração de inicialização e o novo serviço receberá a próxima versão do código, etc. E podemos controlá-la.

Vemos que o Packer está pronto e temos uma nova AMI.
Volto à Amazon, atualizo a página e vejo uma segunda AMI.

De volta ao Terraform.
A partir da versão 0.10, o Terraform dividiu os provedores em repositórios separados. E o comando
init terraform obtém uma cópia do provedor necessária para executar.

Fornecedores carregados. Estamos prontos para avançar.
Em seguida, temos que executar o
terraform get - carregar os módulos necessários. Eles estão agora na minha máquina local. Então o Terraform obterá todos os módulos localmente. Em geral, os módulos podem ser armazenados em seus próprios repositórios no GitHub ou em outro local. Foi por isso que falei sobre o módulo VPC. Você pode conceder à equipe de rede acesso para fazer alterações. E esta é a API para a equipe de desenvolvimento trabalhar com eles. Realmente útil.
O próximo passo é construir um gráfico.
Comece com
terraform plan

O Terraform pegará o estado local atual e será comparado com a conta da AWS, indicando as diferenças. No nosso caso, ele criará 35 novos recursos.
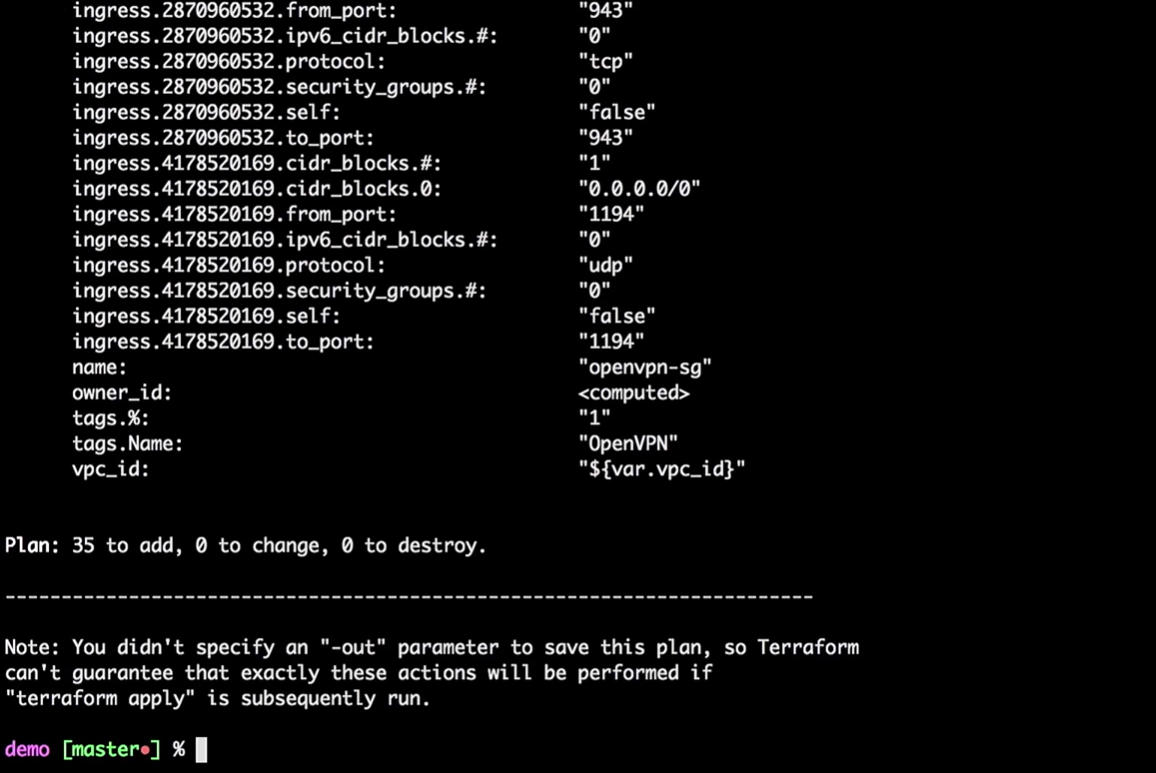
Agora aplicamos as alterações:
terraform apply
Você não precisa fazer tudo isso na máquina local. Estes são apenas comandos, passando variáveis para o Terraform. Você pode portar esse processo para ferramentas de IC.
Se você deseja mover isso para o CI, deve usar o estado remoto. Eu gostaria que todos que usassem o Terraform trabalhassem com um estado remoto. Por favor, não use o estado local.
Um de meus amigos observou que, mesmo depois de todos os anos de trabalho com Terraform, ele ainda está descobrindo algo novo. Por exemplo, se você estiver criando uma instância da AWS, precisará fornecer uma senha e ela poderá salvá-la no seu estado. Quando trabalhei na Hashicorp, assumimos que haveria um processo colaborativo que altera essa senha. Portanto, não tente armazenar tudo localmente. E então você pode colocar tudo isso nas ferramentas de IC.
Então, a infraestrutura é criada para mim.

Terraform pode criar um gráfico:
terraform graph
Como eu disse, ele está construindo uma árvore. De fato, oferece a oportunidade de avaliar o que está acontecendo em sua infraestrutura. Ele mostrará a relação entre todas as partes diferentes - todos os nós e arestas. Como as conexões têm instruções, estamos falando de um gráfico direcionado.
O gráfico será uma lista JSON que pode ser salva em um arquivo PNG ou DOC.
De volta ao Terraform. Estamos realmente criando um grupo de dimensionamento automático.

O grupo de dimensionamento automático tem capacidade para 3.

Uma pergunta interessante: podemos usar o Vault para gerenciar segredos no Terraform? Infelizmente, não. Não há fonte de dados do Vault para ler segredos no Terraform. Existem outras maneiras, como variáveis de ambiente. Com a ajuda deles, você não precisa inserir segredos no código; pode lê-los como variáveis de ambiente.
Portanto, temos algumas instalações de infraestrutura:
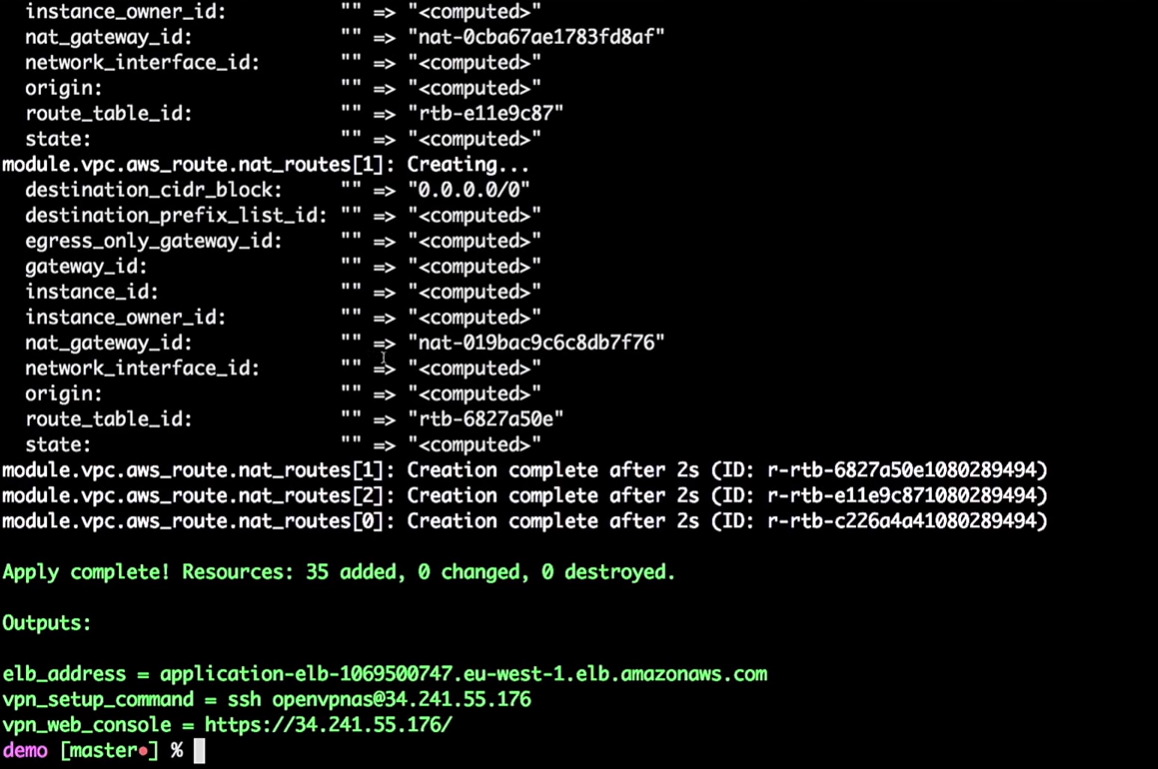
Entro na minha VPN muito secreta (não quebre minhas VPNs).
O mais importante aqui é que temos três instâncias do aplicativo. É verdade que eu deveria ter notado qual versão do aplicativo está sendo executada neles. Isso é muito importante.
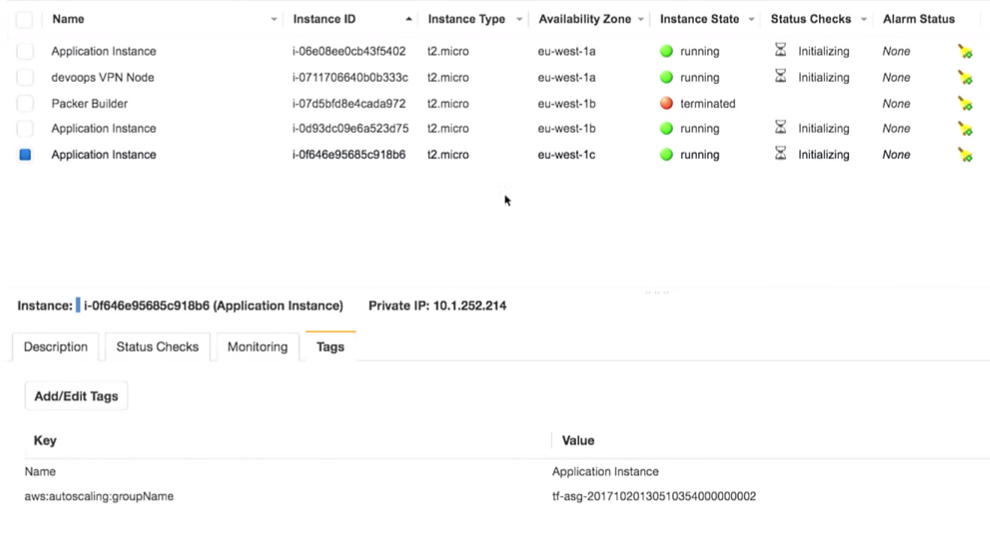
Tudo realmente está por trás da VPN:

Se eu pegar isso (
application-elb-1069500747.eu-west-1.elb.amazonaws.com ) e colá-lo na barra de endereços do navegador, obtive o seguinte:

Deixe-me lembrá-lo de que estou conectado a uma VPN. Se eu sair, o endereço especificado estará indisponível.
Vemos a versão 1.0.0. E não importa o quanto atualizamos a página, obtemos a 1.0.0.
O que acontece se eu alterar a versão de 1.0.0 para 1.0.1 no código?
filter { name = "tag:Version" values = ["1.0.1"] }
Obviamente, as ferramentas de IC garantirão a criação da versão correta.
Não observo atualizações manuais! Somos imperfeitos, cometemos erros e podemos colocar a versão 1.0.6 em vez da 1.0.1 ao atualizar manualmente.
filter { name = "tag:Version" values = ["1.0.6"] }
Mas vamos para a nossa versão (1.0.1).
terraform plan
O Terraform atualiza o estado:
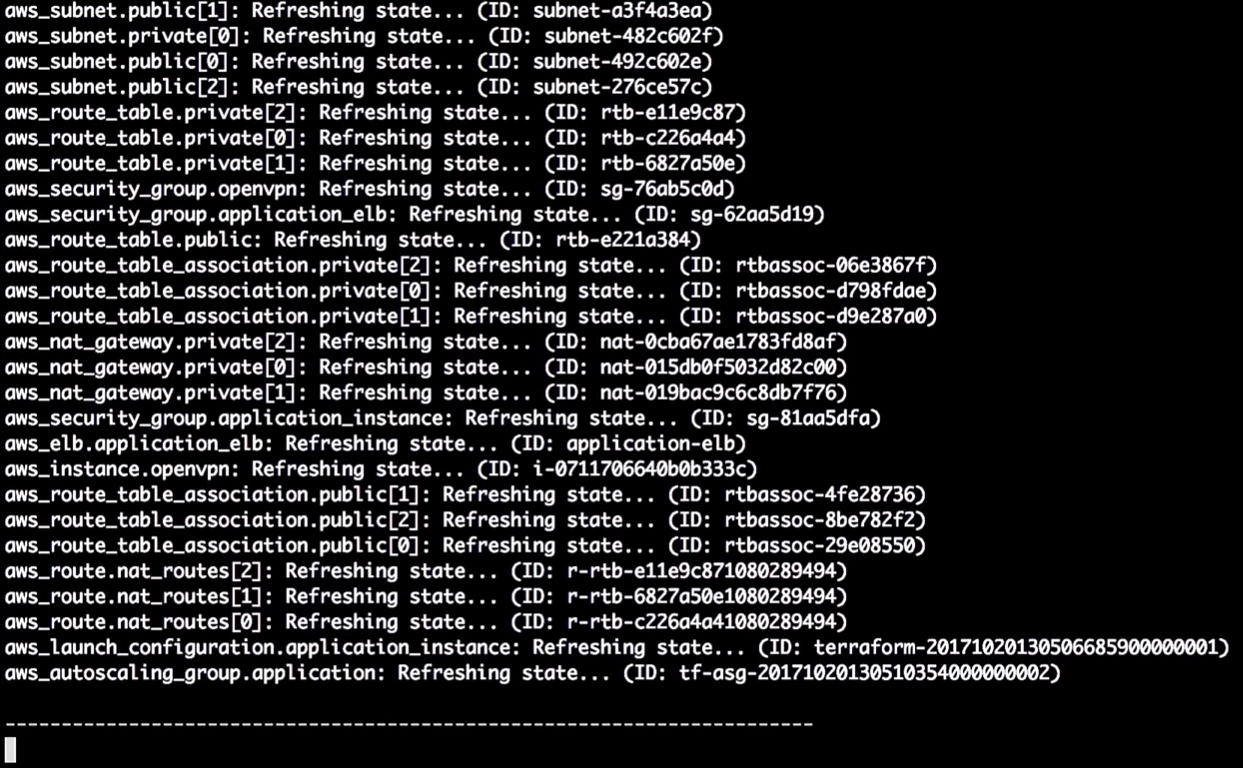

Então, neste momento, ele me diz que vai mudar a versão na configuração de lançamento. Devido à alteração no identificador, forçará o reinício da configuração e o grupo de dimensionamento automático será alterado (isso é necessário para ativar a nova configuração de inicialização).
Isso não altera as instâncias em execução. Isso é realmente importante. Você pode seguir esse processo e testá-lo sem alterar as instâncias na produção.
Nota: você sempre deve criar uma nova configuração de ativação antes de destruir a antiga, caso contrário, haverá um erro.
Vamos aplicar as alterações:
terraform apply
Agora, de volta à AWS. Quando todas as alterações são aplicadas, vamos para o grupo de dimensionamento automático.
Vamos seguir para a configuração da AWS. Vemos que há três instâncias com uma configuração de inicialização. Eles são iguais.
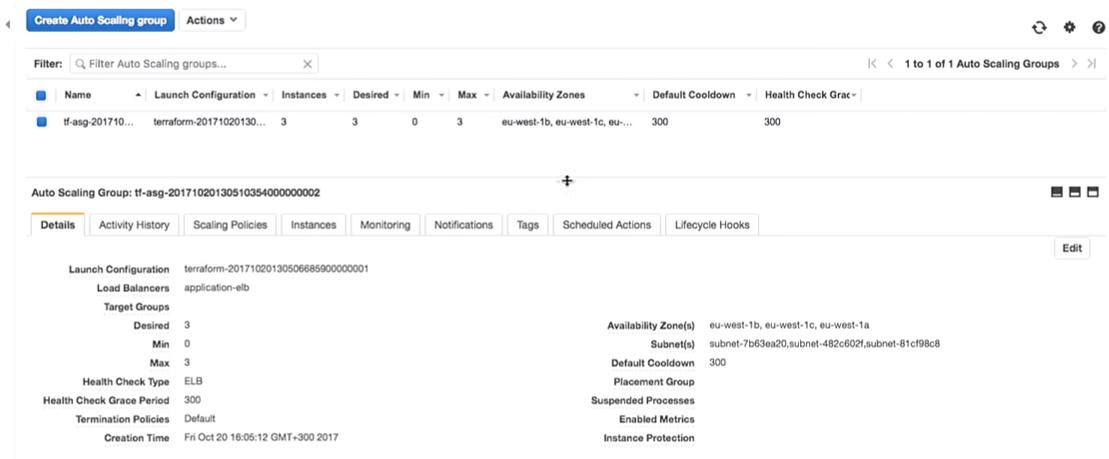
A Amazon garante que, se quisermos executar três instâncias do serviço, elas serão realmente lançadas. É por isso que lhes pagamos dinheiro.
Vamos seguir para os experimentos.
Uma nova configuração de inicialização foi criada. Portanto, se eu excluir uma das instâncias, o restante não será danificado. Isso é importante. No entanto, se você usar as instâncias diretamente, ao alterar os dados do usuário, isso destruirá as instâncias "ativas". Por favor, não faça isso.
Portanto, exclua uma das instâncias:

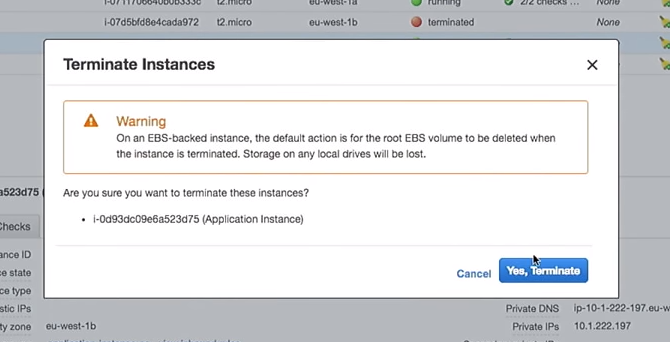
O que acontecerá no grupo de dimensionamento automático quando ele for desligado? Uma nova instância aparecerá em seu lugar.
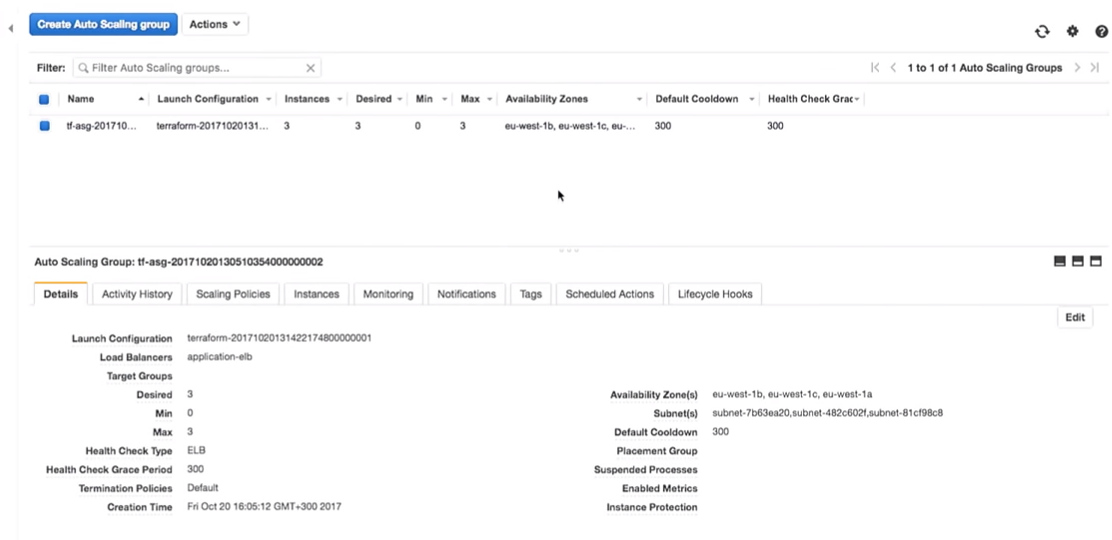
Aqui você se encontra em uma situação interessante. A instância será iniciada com a nova configuração. Ou seja, no sistema você pode ter várias imagens diferentes (com configurações diferentes). Às vezes, é melhor não excluir imediatamente a antiga configuração de inicialização para conectar-se conforme necessário.
Aqui tudo se torna ainda mais interessante. Por que não fazer isso com scripts e ferramentas de IC, e não manualmente, como mostro? Existem ferramentas que podem fazer isso, como as excelentes ferramentas ausentes da AWS no GitHub.

E o que essa ferramenta faz? Este é um script bash que executa todas as instâncias no balanceador de carga, destruindo-as uma por vez, garantindo a criação de novas em seu lugar.
Se eu perdesse uma das minhas instâncias com a versão 1.0.0 e uma nova aparecesse - 1.1.1, eu gostaria de matar todo o 1.0.0, transferindo tudo para a nova versão. Porque eu sempre segui em frente. Deixe-me lembrá-lo de que não gosto quando o servidor de aplicativos permanece por muito tempo.
Em um dos projetos, a cada sete dias, eu tinha um script de controle que destruía todas as instâncias da minha conta. Portanto, o servidor não tinha mais de sete dias. Outra coisa (a minha favorita) é marcar os servidores como "manchados" usando SSH em uma caixa e destruí-los a cada hora usando um script - não queremos que as pessoas façam isso manualmente.
Esses scripts de controle permitem que você sempre tenha a versão mais recente com bugs corrigidos e atualizações de segurança.
Você pode usar o script apenas executando:
aws-ha-relesae.sh -a my-scaling-group
-a é o seu grupo de dimensionamento automático. O script passará por todas as instâncias do seu grupo de dimensionamento automático e o substituirá. Você pode executá-lo não apenas manualmente, mas também a partir da ferramenta CI.
Você pode fazer isso no controle de qualidade ou na produção. Você pode fazer isso mesmo na sua conta local da AWS. Você faz o que quiser, sempre usando o mesmo mecanismo.
De volta à Amazônia. Temos uma nova instância:

Depois de atualizar a página no navegador, onde vimos a versão 1.0.0, obtemos:

O interessante é que, desde que criamos o script de criação da AMI, podemos testar a criação da AMI.
Existem ótimas ferramentas, como ServerScript ou Serverspec.
O Serverspec permite criar especificações no estilo Ruby para testar a aparência do servidor de aplicativos. Por exemplo, abaixo, faço um teste que verifica se o nginx está instalado no servidor.
require 'spec_helper' describe package('nginx') do it { should be_installed } end describe service('nginx') do it { sould be_enabled } it { sould be_running } end describe port(80) do it { should be_listening } end
O Nginx deve estar instalado e em execução no servidor e atendendo na porta 80. Você pode dizer que o usuário X deve estar disponível no servidor. E você pode colocar todos esses testes no lugar deles. Portanto, quando você cria uma AMI, a ferramenta de IC pode verificar se essa AMI é adequada para uma determinada finalidade. Você saberá que a AMI está pronta para produção.
Em vez de uma conclusão
Mary Poppendieck é provavelmente uma das mulheres mais incríveis que eu já ouvi falar. Ao mesmo tempo, ela falou sobre como o desenvolvimento de software lean se desenvolveu ao longo dos anos. E como ela estava associada à 3M nos anos 60, quando a empresa estava realmente engajada no desenvolvimento enxuto.
E ela fez a pergunta: quanto tempo levará para sua organização implantar as alterações associadas a uma linha de código? Você pode tornar esse processo confiável e repetível?
Como regra, essa pergunta sempre dizia respeito ao código do software. Quanto tempo levarei para corrigir um erro neste aplicativo ao implantar na produção? Mas não há razão para não podermos usar a mesma pergunta para infraestrutura ou bancos de dados.
Eu trabalhei para uma empresa chamada OpenTable. Nele, chamamos isso de duração do ciclo. E no OpenTable ela tinha sete semanas. E isso é relativamente bom. Conheço empresas que levam meses para enviar um código para produção. No OpenTable, revisamos o processo por quatro anos. Isso levou muito tempo, porque a organização é grande - 200 pessoas. E reduzimos o tempo do ciclo para três minutos. Isso foi possível graças a medidas do efeito de nossas transformações.
Agora tudo está em script. Temos muitas ferramentas e exemplos, existe o GitHub. Portanto, pegue idéias de conferências como DevOops, implemente-as em sua organização. Não tente implementar tudo. Pegue uma coisinha e venda. Mostre a alguém. O impacto de uma pequena mudança pode ser medido, medido e seguir em frente!
Paul Stack chegará a São Petersburgo na conferência do DevOops 2018 com um relatório "Teste de sistema sustentável com o caos" . Paul falará sobre a metodologia Chaos Engineering e mostrará como usar essa metodologia em projetos reais.