Há pouco tempo, no data center em que alugamos servidores, outro mini-incidente aconteceu. Como resultado, não houve sérias conseqüências para o nosso serviço; de acordo com as métricas disponíveis, conseguimos entender o que estava acontecendo literalmente em um minuto. E então eu imaginei como teria que quebrar meu cérebro se apenas duas métricas simples estivessem ausentes. Sob o corte, uma pequena história em imagens.
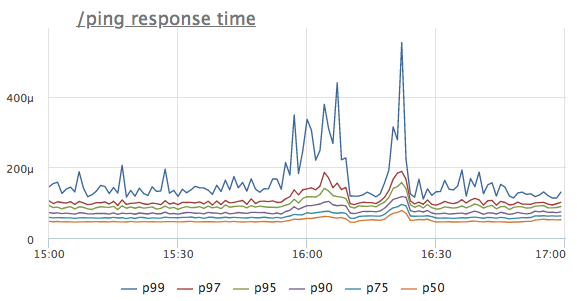
Imagine que vimos uma anomalia na linha do tempo de resposta de um determinado serviço. Para simplificar, usamos o manipulador / ping, que não acessa o banco de dados ou os serviços vizinhos, mas simplesmente retorna '200 OK' (é necessário para balanceadores de carga e k8s para o serviço de verificação de integridade)

Qual é o primeiro pensamento? É isso mesmo, o serviço não possui recursos suficientes, provavelmente a CPU! Nós olhamos para o consumo do processador:
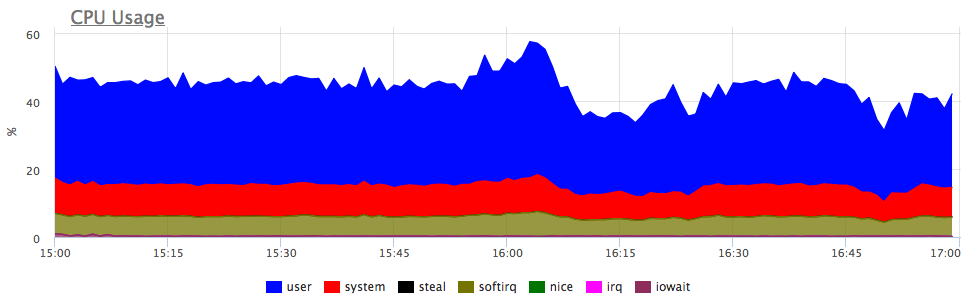
Sim, existem explosões semelhantes. A seguir, analisamos o consumo por serviços no servidor:
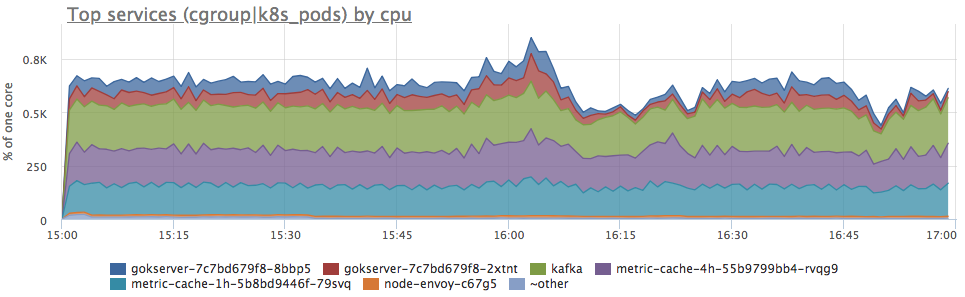
Vemos que o consumo de proca aumentou proporcionalmente para todos os serviços. Você não pode dizer mais nada explicitamente: pode ver se o perfil de carregamento mudou (já que todos os componentes estão conectados e um aumento nas solicitações de entrada pode realmente causar um aumento proporcional no consumo de recursos) ou entender o que aconteceu com os recursos do servidor.
Obviamente, tentei preservar a intriga da melhor maneira possível, mas no início do artigo você provavelmente já imaginou que o servidor simplesmente reduzia o número de ticks de CPU disponíveis. No dmesg, é algo como isto:
CPU3: Core temperature above threshold, cpu clock throttled (total events = 88981)
Grosso modo, reduzimos a frequência devido ao superaquecimento do processador. Nós olhamos para a temperatura:
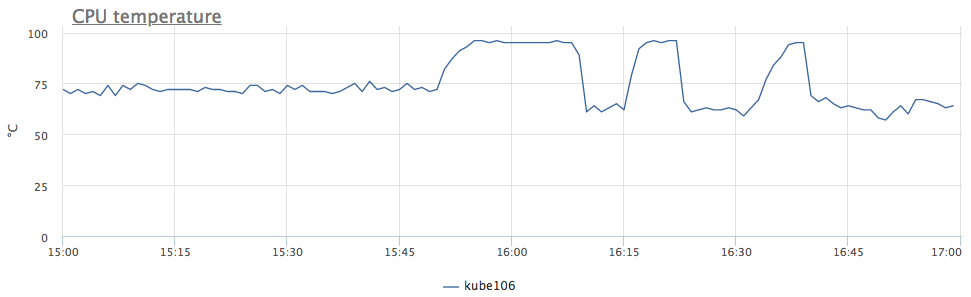
agora está tudo claro. Como tivemos um comportamento semelhante imediatamente em 6 servidores, percebemos que o problema está no controlador de domínio, e não em tudo, mas apenas em algumas linhas de racks.
Mas voltando às métricas. Potencialmente, queremos saber se os servidores superaquecerão no futuro, mas esse não é um motivo para adicionar um gráfico das temperaturas do processador a todos os painéis e verificar isso sempre.
Geralmente, os gatilhos são usados para rastrear algumas métricas para otimizar o processo. Mas qual limite devo escolher para um gatilho pela temperatura do processador?
É por causa da dificuldade de escolher um bom limiar para o gatilho, muitos engenheiros sonham com um detector de anomalias, que sem configurações se encontrará, não sei o que :)O primeiro pensamento é definir a temperatura limite em que nosso serviço começou a ter problemas. E se você nunca teve superaquecimento? Claro que você pode olhar para minha agenda e decidir por si mesmo que 95 ° C é o que você precisa, mas vamos pensar um pouco mais.
O problema conosco não é por causa dos graus, mas porque a frequência diminuiu! Vamos acompanhar o número de tais eventos.
No linux, isso pode ser removido do sysfs:
/sys/devices/system/cpu/cpu*/thermal_throttle/package_throttle_count

Para ser sincero, nem exibimos essa métrica em nenhum lugar, só temos um acionador automático para todos os clientes que são acionados quando o limite "> 10 eventos / segundo" é atingido. De acordo com nossas estatísticas, praticamente não há falsos positivos nesse limite.
Sim, esse gatilho raramente funciona, mas quando isso acontece, torna a vida muito fácil!
Na okmeter.io, na maioria das vezes, estamos envolvidos no desenvolvimento de nosso banco de dados de gatilhos automáticos, o que facilita aos nossos clientes encontrarem problemas desconhecidos para eles.