Olá colegas.
Esperamos começar a tradução de um
livro pequeno, mas verdadeiramente
básico, sobre a implementação dos recursos de IA em Python antes do final de agosto.

O Sr. Gift, talvez, não precise de publicidade adicional (para os curiosos - o
perfil do mestre no GitHub):

O artigo que está sendo oferecido hoje falará brevemente sobre a biblioteca Ray, desenvolvida na Universidade da Califórnia (Berkeley) e mencionada no livro de Peter por petite. Esperamos que, como um teaser inicial - o que você precisa. Bem-vindo sob gato
Com o desenvolvimento de algoritmos e técnicas de aprendizado de máquina, mais e mais aplicativos de aprendizado de máquina precisam ser executados em muitas máquinas ao mesmo tempo, e eles não podem prescindir da simultaneidade. No entanto, a infraestrutura para executar o aprendizado de máquina em clusters ainda é formada situacionalmente. Agora já existem boas soluções (por exemplo, servidores de parâmetros ou pesquisa por hiperparâmetros) e sistemas distribuídos de alta qualidade (por exemplo, Spark ou Hadoop), originalmente criados não para trabalhar com IA, mas os profissionais geralmente criam a infraestrutura para seus próprios sistemas distribuídos do zero. Muito esforço extra é gasto nisso.
Como exemplo, considere um algoritmo conceitualmente simples, digamos,
Estratégias evolutivas para o aprendizado por reforço . No pseudo-código, esse algoritmo se encaixa em cerca de uma dúzia de linhas, e sua implementação no Python é um pouco maior. No entanto, o uso efetivo desse algoritmo em uma máquina ou cluster maior requer uma engenharia de software significativamente mais sofisticada. Na implementação desse algoritmo pelos autores deste artigo - milhares de linhas de código, é necessário determinar protocolos de comunicação, estratégias de serialização e desserialização de mensagens, bem como vários métodos de processamento de dados.
Um dos objetivos de
Ray é ajudar um profissional a transformar um algoritmo de protótipo que é executado em um laptop em um aplicativo distribuído de alto desempenho que funciona eficientemente em um cluster (ou em uma única máquina com vários núcleos) adicionando relativamente poucas linhas de código. Em termos de desempenho, essa estrutura deve ter todas as vantagens de um sistema otimizado manualmente e não exigir que o usuário pense em agendamento, transferência de dados e falhas na máquina.
Free AI FrameworkVincular-se a outras estruturas de aprendizado profundo : Ray é totalmente compatível com estruturas de aprendizado profundo, como TensorFlow, PyTorch e MXNet; portanto, em muitos aplicativos, é completamente natural usar uma ou mais estruturas de aprendizado profundo com Ray (por exemplo, em nossas bibliotecas de aprendizado reforçadas ativamente aplique TensorFlow e PyTorch).
Comunicação com outros sistemas distribuídos : Hoje, muitos sistemas distribuídos populares são usados, no entanto, a maioria deles foi projetada sem levar em conta as tarefas associadas à IA; portanto, eles não têm o desempenho necessário para dar suporte à IA e não possuem uma API para expressar os aspectos aplicados da IA. Nos sistemas distribuídos modernos, não existem (necessários, dependendo do sistema) esses recursos necessários:
- Suporte a tarefas em milissegundos e milhões de tarefas por segundo
- Paralelismo aninhado (paralelização de tarefas dentro de tarefas, por exemplo, simulações paralelas ao procurar hiperparâmetros) (consulte a figura a seguir)
- Dependências arbitrárias entre tarefas, dinamicamente durante a execução (por exemplo, para não ter que esperar, ajustando-se ao ritmo dos trabalhadores lentos)
- Tarefas que operam em um estado variável compartilhado (por exemplo, pesos em redes neurais ou em um simulador)
- Suporte para recursos heterogêneos (CPU, GPU, etc.)
 Um exemplo simples de simultaneidade aninhada. Em nossa aplicação, dois experimentos são realizados em paralelo (cada um deles é uma tarefa de longo prazo) e em cada experimento vários processos paralelos são simulados (cada processo também é uma tarefa).
Um exemplo simples de simultaneidade aninhada. Em nossa aplicação, dois experimentos são realizados em paralelo (cada um deles é uma tarefa de longo prazo) e em cada experimento vários processos paralelos são simulados (cada processo também é uma tarefa).Existem duas maneiras principais de usar o Ray: através de suas APIs de baixo nível e através de bibliotecas de alto nível. Bibliotecas de alto nível são construídas sobre APIs de baixo nível. Atualmente, eles incluem o
Ray RLlib (uma biblioteca escalável para aprendizado por reforço) e o
Ray.tune , uma biblioteca eficiente para pesquisa distribuída de hiperparâmetros.
APIs de baixo nível RayO objetivo da API Ray é fornecer uma expressão natural dos padrões e aplicativos computacionais mais comuns, sem se limitar a padrões fixos como o MapReduce.
Gráficos de tarefas dinâmicasO primitivo básico no aplicativo (tarefa) Ray é um gráfico de tarefas dinâmico. É muito diferente do gráfico computacional no TensorFlow. Enquanto no TensorFlow um gráfico computacional representa uma rede neural e é executado várias vezes em cada aplicativo separado, no Ray o gráfico de tarefas corresponde a todo o aplicativo e é executado apenas uma vez. O gráfico da tarefa não é conhecido antecipadamente. Ele é construído dinamicamente enquanto o aplicativo está em execução, e a execução de uma tarefa pode desencadear a execução de muitas outras tarefas.
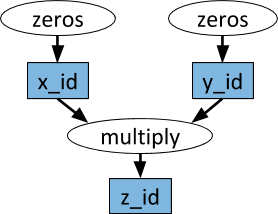 Um exemplo de um gráfico computacional. Nas ovais brancas, as tarefas são mostradas e nos retângulos azuis - objetos. As setas indicam que algumas tarefas dependem de objetos, enquanto outras criam objetos.
Um exemplo de um gráfico computacional. Nas ovais brancas, as tarefas são mostradas e nos retângulos azuis - objetos. As setas indicam que algumas tarefas dependem de objetos, enquanto outras criam objetos.As funções arbitrárias do Python podem ser executadas como tarefas e, em qualquer ordem, podem depender da saída de outras tarefas. Veja o exemplo abaixo.
AtoresCom a ajuda de funções remotas e o manuseio de tarefas acima, é impossível conseguir que várias tarefas funcionem simultaneamente no mesmo estado mutável compartilhado. Esse problema com o aprendizado de máquina surge em diferentes contextos, onde o estado do simulador, pesos na rede neural ou algo completamente diferente podem ser compartilhados. A abstração do ator é usada no Ray para encapsular um estado mutável compartilhado entre muitas tarefas. Aqui está um exemplo ilustrativo que demonstra como fazer isso com o simulador Atari.
import gym @ray.remote class Simulator(object): def __init__(self): self.env = gym.make("Pong-v0") self.env.reset() def step(self, action): return self.env.step(action)
Por toda a sua simplicidade, o ator é muito flexível em uso. Por exemplo, um simulador ou política de rede neural pode ser encapsulada em um ator, também pode ser usada para treinamento distribuído (como em um servidor de parâmetros) ou para fornecer políticas em um aplicativo "ativo".
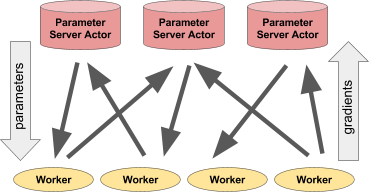 Esquerda: O ator fornece previsões / ações para vários processos do cliente. Direita: Muitos atores do servidor de parâmetros realizam treinamento distribuído para muitos fluxos de trabalho.Exemplo de servidor de parâmetros
Esquerda: O ator fornece previsões / ações para vários processos do cliente. Direita: Muitos atores do servidor de parâmetros realizam treinamento distribuído para muitos fluxos de trabalho.Exemplo de servidor de parâmetrosO servidor de parâmetros pode ser implementado como um ator Ray da seguinte maneira:
@ray.remote class ParameterServer(object): def __init__(self, keys, values): # , . values = [value.copy() for value in values] self.parameters = dict(zip(keys, values)) def get(self, keys): return [self.parameters[key] for key in keys] def update(self, keys, values): # , # for key, value in zip(keys, values): self.parameters[key] += value
Aqui está um
exemplo mais completo .
Para instanciar um servidor de parâmetros, fazemos isso.
parameter_server = ParameterServer.remote(initial_keys, initial_values)
Para criar quatro trabalhadores de longa duração, constantemente extraindo e atualizando parâmetros, faremos isso.
@ray.remote def worker_task(parameter_server): while True: keys = ['key1', 'key2', 'key3'] # values = ray.get(parameter_server.get.remote(keys)) # updates = … # parameter_server.update.remote(keys, updates) # 4 for _ in range(4): worker_task.remote(parameter_server)
Bibliotecas de alto nível RayO Ray RLlib é uma biblioteca de aprendizado de reforço escalonável, projetada para uso em várias máquinas. Ele pode ser ativado usando os scripts de treinamento fornecidos como exemplo, bem como por meio da API Pytho. Atualmente, inclui implementações de algoritmos:
- A3C
- Dqn
- Estratégias evolutivas
- PPO
Estão em andamento trabalhos na implementação de outros algoritmos. O RLlib é totalmente compatível com o
ginásio OpenAI .
Ray.tune é uma biblioteca eficiente para pesquisa distribuída de hiperparâmetros. Ele fornece uma API Python para aprendizado profundo, aprendizado por reforço e outras tarefas que exigem muito poder de processamento. Aqui está um exemplo ilustrativo desse tipo:
from ray.tune import register_trainable, grid_search, run_experiments
Os resultados atuais podem ser visualizados dinamicamente usando ferramentas especiais, por exemplo, Tensorboard e VisKit do rllab (ou leia diretamente os logs JSON). O Ray.tune suporta pesquisa em grade, pesquisa aleatória e algoritmos não-triviais de parada precoce, como o HyperBand.
Mais sobre Ray