 O código do projeto está disponível no repositório.
O código do projeto está disponível no repositório.1. Introdução
Quando leio as descrições da aparência dos personagens nos livros, sempre me interessei em como eles eram na vida. É bem possível imaginar uma pessoa como um todo, mas a descrição dos detalhes mais visíveis é uma tarefa difícil, e os resultados variam de pessoa para pessoa. Muitas vezes eu não conseguia imaginar nada além de um rosto muito embaçado do personagem até o final do trabalho. Somente quando o livro se transforma em filme é que o rosto desfocado se enche de detalhes. Por exemplo, eu nunca poderia imaginar como o rosto de Rachel se parece com o livro "
Garota no trem ". Mas quando o filme saiu, eu pude combinar o rosto de Emily Blunt com o personagem de Rachel. Certamente, as pessoas envolvidas na seleção de atores levam muito tempo para retratar corretamente os personagens do roteiro.
Esse problema me inspirou e me motivou a encontrar uma solução. Depois disso, comecei a estudar a literatura sobre aprendizado profundo em busca de algo semelhante. Felizmente, existem muitos estudos sobre a síntese de imagens a partir de texto. Aqui estão alguns dos que eu construí:
[os
projetos usam redes adversárias generativas, GSS (rede adversária generativa, GAN) / aprox. perev. ]
Depois de estudar a literatura, escolhi uma arquitetura simplificada em comparação ao StackGAN ++ e lida muito bem com o meu problema. Nas seções a seguir, explicarei como resolvi esse problema e compartilhei resultados preliminares. Também descreverei alguns dos detalhes de programação e treinamento nos quais passei muito tempo.
Análise de dados
Sem dúvida, o aspecto mais importante do trabalho são os dados usados para treinar o modelo. Como o professor Andrew Eun disse em seus cursos deeplearning.ai: "No campo do aprendizado de máquina, não é quem tem o melhor algoritmo, mas quem tem os melhores dados". Assim começou minha busca por um conjunto de dados sobre rostos com boas, ricas e variadas descrições textuais. Me deparei com diferentes conjuntos de dados - eram apenas rostos, ou rostos com nomes ou rostos com uma descrição da cor dos olhos e do formato do rosto. Mas não havia nada que eu precisasse. Minha última opção foi usar
um projeto inicial - gerando uma descrição dos dados estruturais em uma linguagem natural. Mas essa opção adicionaria ruído extra a um conjunto de dados já bastante barulhento.
O tempo passou e, em algum momento, um novo projeto do
Face2Text apareceu . Era uma coleção de um banco de dados com descrições detalhadas de textos de pessoas. Agradeço aos autores do projeto pelo conjunto de dados fornecido.
O conjunto de dados continha descrições textuais de 400 imagens selecionadas aleatoriamente no banco de dados LFW (faces marcadas). As descrições foram limpas para eliminar características ambíguas e menores. Algumas descrições continham não apenas informações sobre os rostos, mas também algumas conclusões feitas com base nas imagens - por exemplo, “a pessoa na foto é provavelmente um criminoso”. Todos esses fatores, bem como o pequeno tamanho do conjunto de dados, levaram ao fato de que meu projeto até agora apenas demonstra evidências da operacionalidade da arquitetura. Posteriormente, esse modelo pode ser dimensionado para um conjunto de dados maior e mais diversificado.
Arquitetura
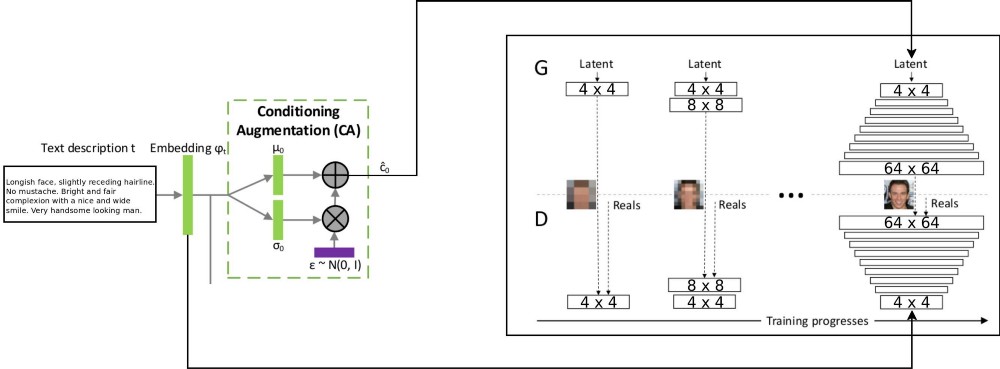
A arquitetura do projeto T2F combina duas arquiteturas stackGAN para codificar texto incrementado condicionalmente e o ProGAN (
crescimento progressivo do GSS ) para sintetizar imagens de rosto. A arquitetura stackgan ++ original usava vários GSSs com diferentes resoluções espaciais, e eu decidi que essa era uma abordagem muito séria para qualquer tarefa de distribuição de correspondência. Mas o ProGAN usa apenas um GSS, treinado progressivamente em resoluções cada vez mais detalhadas. Eu decidi combinar essas duas abordagens.
Há uma explicação do fluxo de dados: descrições de texto são codificadas no vetor final incorporando-se à rede LSTM (Incorporação) (psy_t) (veja o diagrama). Em seguida, a incorporação é transmitida através do bloco de Aumento de Condicionamento (uma camada linear) para obter a parte de texto do vetor próprio (usando a técnica de reparameterização VAE) para o GSS como entrada. A segunda parte do vetor próprio é o ruído gaussiano aleatório. O vetor próprio resultante é alimentado ao gerador GSS e a incorporação é alimentada à última camada discriminadora para distribuição condicional da correspondência. O treinamento dos processos GSS é exatamente igual ao do artigo ProGAN - em camadas, com um aumento na resolução espacial. Uma nova camada é introduzida usando a técnica fade-in para evitar a exclusão de resultados de aprendizado anteriores.
Implementação e outros detalhes
O aplicativo foi escrito em python usando a estrutura PyTorch. Eu trabalhava com pacotes tensorflow e keras, mas agora queria experimentar o PyTorch. Gostei de usar o depurador python embutido para trabalhar com a arquitetura de rede - tudo graças à estratégia de execução antecipada. O Tensorflow também ativou recentemente o modo de execução ansioso. No entanto, não quero julgar qual estrutura é melhor, só quero enfatizar que o código deste projeto foi escrito usando o PyTorch.
Algumas partes do projeto me parecem reutilizáveis, especialmente o ProGAN. Portanto, escrevi um código separado para eles como uma
extensão do módulo PyTorch e também pode ser usado em outros conjuntos de dados. É necessário apenas indicar a profundidade e o tamanho dos recursos do GSS. O GSS pode ser treinado progressivamente para qualquer conjunto de dados.
Detalhes do treinamento
Treinei algumas versões da rede usando diferentes hiperparâmetros. Os detalhes do trabalho são os seguintes:
- O discriminador não possui operações de lote ou norma, portanto a perda de WGAN-GP pode crescer explosivamente. Eu usei penalidade de deriva com lambda igual a 0,001.
- Para controlar sua própria diversidade, obtida a partir do texto codificado, é necessário usar a distância Kullback - Leibler nas perdas do Gerador.
- Para fazer com que as imagens resultantes correspondam melhor à distribuição de texto recebida, é melhor usar a versão WGAN do discriminador correspondente (compatível com correspondência).
- O tempo de espera para os níveis superiores deve exceder o tempo de espera para os níveis inferiores. Eu usei 85% como o valor do fade-in durante o treinamento.
- Descobri que exemplos de alta resolução (32 x 32 e 64 x 64) produzem mais ruído de fundo do que exemplos de baixa resolução. Eu acho que isso é devido à falta de dados.
- Durante um treino progressivo, é melhor gastar mais tempo em resoluções mais baixas e reduzir o tempo gasto trabalhando com resoluções mais altas.
O vídeo mostra o lapso de tempo do gerador. O vídeo é compilado a partir de imagens com diferentes resoluções espaciais obtidas durante o treinamento do GSS.
Conclusão
De acordo com resultados preliminares, pode-se julgar que o projeto T2F é viável e tem aplicações interessantes. Suponha que ele possa ser usado para compor photobots. Ou para os casos em que é necessário aumentar a imaginação. Continuarei trabalhando no dimensionamento deste projeto em conjuntos de dados como Flicker8K, legendas do Coco e assim por diante.
O crescimento progressivo do GSS é uma tecnologia fenomenal para um treinamento mais rápido e mais estável do GSS. Pode ser combinado com várias tecnologias modernas mencionadas em outros artigos. O GSS pode ser usado em diferentes áreas do MO.