Olá Habr! Meu nome é Sergey Prutskikh, sou responsável pela direção de monitoramento da Sberbank-Technology. O principal objetivo de nossa organização é o desenvolvimento e teste de produtos de software para o Sberbank. Para isso, a empresa possui uma grande infraestrutura de TI - 15 mil servidores são divididos em aproximadamente 1.500 ambientes de teste, relacionados a mais de 500 sistemas automatizados. No total, cerca de 10 mil especialistas trabalham com eles.
Em 2015, começamos a criar um serviço de monitoramento centralizado. Além disso, tudo estava limitado não apenas à implementação. Era necessário elaborar muitos regulamentos, instruções e o relacionamento entre as unidades da Sbertech no âmbito do monitoramento. Neste post, mostrarei em detalhes como escolhemos a plataforma, em quais princípios criamos tudo e com o que acabamos.

Os principais objetivos e ideologia do projeto
Aqui estão os objetivos que buscamos no projeto:
- Obtenção de dados confiáveis sobre o tamanho e a composição da infraestrutura de TI;
- Otimização do uso de instalações de TI;
- Reduzir os custos de suporte e operação da infraestrutura de TI dos ambientes de desenvolvimento e teste;
- Suporte à infraestrutura de TI, pronta para desenvolvimento e teste;
- Avisar os especialistas sobre problemas no trabalho em ambientes de teste;
- Auditar a conformidade de ambientes de teste e AFMs industriais não é uma tarefa muito típica para nós;
- Coleta de dados para relatórios sobre os resultados dos testes, fornecendo a medição de parâmetros críticos em todas as etapas do teste.
Olhando para o futuro, posso dizer que todos os objetivos, em um grau ou outro, já foram cumpridos até o momento. E alguns problemas relacionados, o monitoramento também ajudou a resolver.
Além das metas, formulamos princípios, uma ideologia, à qual aderimos ao longo do projeto:
- A satisfação do usuário é um dos principais indicadores de monitoramento. Na conferência ITSMf 2017, falei sobre o monitoramento da infraestrutura de TI, e o quinto NÃO está nesse relatório: "NÃO force os funcionários a trabalhar com o sistema de monitoramento". O objetivo é motivar, não obrigar. Isso é alcançado por meio de KPIs criados corretamente. No início do serviço, esses KPIs ainda não podem aparecer. No entanto, é muito importante, desde os primeiros dias de monitoramento, começar a beneficiar potenciais clientes.
- Tempo mínimo para refinamento. Para isso, usamos elementos ágeis. Eles ajudam a fornecer novos recursos o mais rápido possível e a receber feedback dos clientes.
- A abertura do sistema, tanto para melhorias, que é expressa na criação de um único atraso, solicitações nas quais qualquer funcionário pode escrever e em termos de fornecimento de informações - nosso serviço permite obter informações sobre a configuração de monitoramento, que geralmente é oculta.
- Alto grau de integração no trabalho diário. Nossa prioridade é implementar a funcionalidade que os usuários precisam diariamente. Isso ajudou em um tempo relativamente curto a popularizar o serviço de monitoramento dentro da empresa.
A escolha do sistema de monitoramento
Em quase todos os projetos em que participei, mais cedo ou mais tarde uma tabela apareceu comparando a funcionalidade de vários sistemas, nos quais um determinado sistema recebeu uma vantagem óbvia.
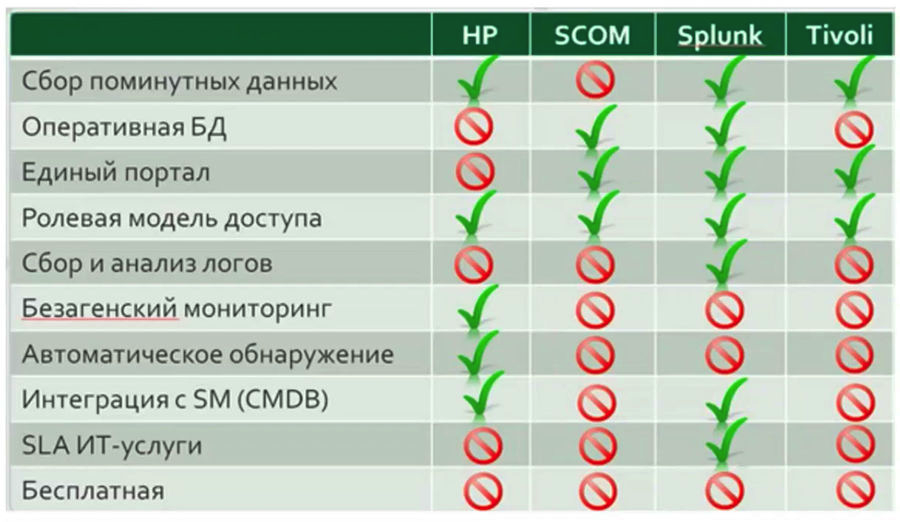
Na minha opinião, essa análise comparativa
não pode ser feita antes do início imediato do trabalho com o serviço de monitoramento e, mais ainda, não vale a pena tomar uma decisão sobre a escolha de uma ou outra solução com base nessa análise. Enquanto o sistema da sua empresa não funcionar por pelo menos um curto período de tempo, é impossível julgar sem ambiguidade quais funções específicas da sua empresa estarão em demanda. Essas tabelas podem ajudar se você desejar alterar o sistema de monitoramento por algum motivo.
Comparação com outras instalações do Zabbix
Você pode falar muito sobre como comparar o tamanho de várias instalações de sistemas de monitoramento, mas todas as características selecionadas para isso, na minha opinião, são bastante subjetivas. Para que você tenha uma idéia mais precisa do tamanho de nossa instalação, decidi dar exemplos de serviços semelhantes em outras empresas, sobre os quais os representantes da Zabbix falaram na conferência Highload.
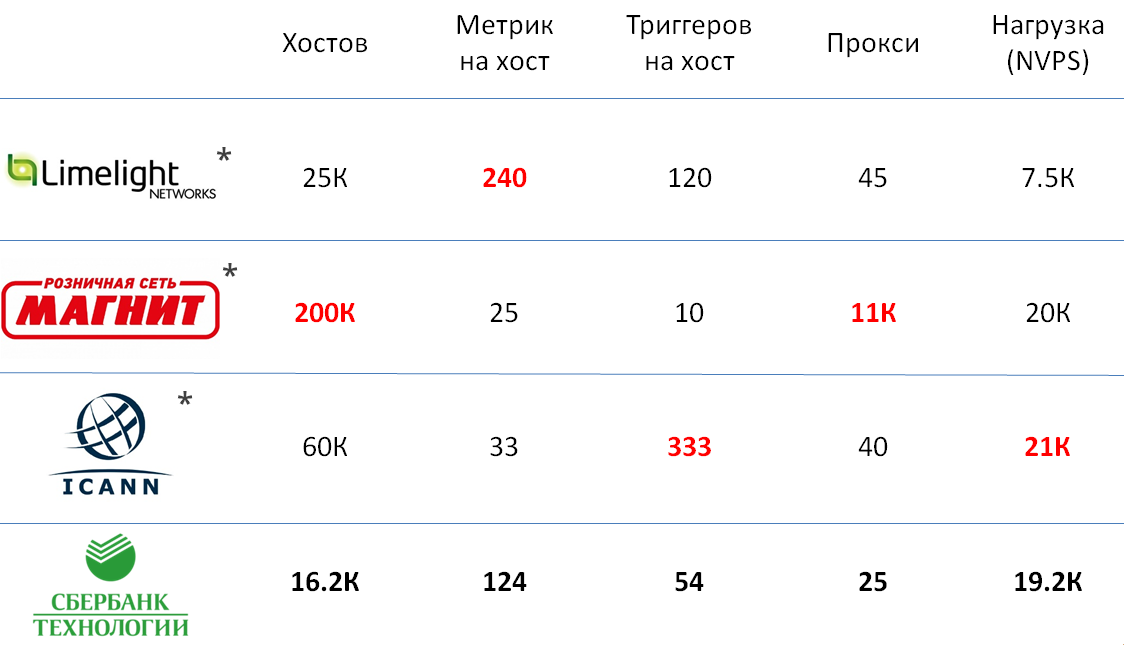
Como você pode ver, a instância do Zabbix em Sbertech não é muito inferior às maiores instalações e, em termos de carga total, está em pé de igualdade com elas.
Benefícios do Zabbix
No segundo semestre de 2017, realizamos um piloto do Zabbix para monitorar a infraestrutura da PROM. Em seguida, formulamos vários critérios qualitativos que atribuímos às vantagens absolutas do Zabbix:
- Código aberto Possibilidades ilimitadas para processamento e personalização.
- Abertura do mecanismo e fonte de coleta de métricas. Nas soluções empresariais comerciais, muitas métricas são incompreensíveis - várias botnets, vazamentos de memória, que nem mesmo o suporte técnico do fornecedor pode explicar. O Zabbix não tem esse problema - você sempre pode dizer claramente como ele coleta determinadas métricas. Assim, a credibilidade do sistema pelos administradores do sistema aumenta.
- Facilidade relativa de dimensionamento - principalmente devido à introdução de servidores proxy adicionais, para os quais você pode transferir parte da carga. Se você atingir o limite de desempenho de uma instância, é possível aumentar a segunda e combinar as duas em um sistema de visualização (Grafana).
- API legal - na minha opinião, essa é uma das principais vantagens do Zabbix. Uma API de alta qualidade, bem desenvolvida e compreensível abre enormes oportunidades para integração com sistemas relacionados, automação etc.
- Monitorar objetos dinâmicos é um pouco, mas agradável. No Zabbix, esse monitoramento é simples e intuitivo, permitindo alcançar bons resultados muito rapidamente. Objetos dinâmicos são todos os objetos que aparecem e desaparecem nos servidores durante a vida útil: sistemas de arquivos, interfaces de rede e outros. Portanto, é necessário automatizar a configuração e a remoção desses objetos do monitoramento.
- Um número relativamente pequeno de componentes. Em soluções comerciais, cada componente é um subsistema separado com sua própria base, que deve ser instalada separadamente. E o Zabbix é um sistema único, no qual todos os métodos de monitoramento estão concentrados de uma só vez: agente, sem agente, rede e outros - apenas 14 tipos.
- Visualização de dados com Grafana. A integração com o Grafana possibilita a criação de gráficos e a criação de painéis realmente convenientes.
- Disponibilidade de monitoramento da disponibilidade de serviços de TI. O Zabbix possui um subsistema interno que pode calcular a disponibilidade de serviços de TI para uso futuro no SLA.
- A flexibilidade para criar métricas e seus valores limite. Aqui, o Zabbix tem muitas oportunidades para configurar métricas complexas de monitoramento:
- Antes de tudo, é a criação de métricas calculadas : com base em várias métricas simples, uma complexa é calculada.
- o pré - processamento do valor das métricas está disponível - isto é, por exemplo, quando você carrega uma grande matriz de dados no Zabbix e, antes de colocar uma métrica específica no banco de dados, o Zabbix analisa a matriz e extrai exatamente os dados que você deseja salvar como métrica. .
- métricas principais. É possível coletar uma matriz de dados de um objeto em uma pesquisa em uma métrica grande e usá-la como fonte de dados para outras métricas. Isso permite reduzir o número de consultas e sincronizar a coleção de todas as métricas no tempo.
- Possibilidade de monitoramento interno. O Zabbix, como um produto de código aberto, tem problemas de desempenho. No entanto, um sistema de monitoramento interno bem pensado ajuda a lidar rapidamente com esses problemas.
Desvantagens do Zabbix
Para ser justo, não posso deixar de mencionar as principais, na minha opinião, as deficiências do Zabbix. Você também pode fazer uma lista decente deles:
- Baixo grau de automação de back-end. Farei uma reserva que não tive a oportunidade de experimentar com todas as variantes do DBMS. Nossa empresa usa o Oracle DBMS como um back-end do Zabbix. As operações em massa podem levar mais de uma hora - por exemplo, atualizando ou alterando métricas, que estão ligadas a um grande número de objetos (15 mil nós de rede).
- Falta de ferramentas de gerenciamento de agente de monitoramento integradas. Esses produtos estão disponíveis em produtos comerciais. O Zabbix ainda não tem isso. Não há sequer uma atualização do kit de ferramentas para agentes. Obviamente, tudo pode ser feito independentemente, mas seria melhor obter esses recursos imediatamente.
- Até o momento, baixa elaboração do monitoramento da disponibilidade de serviços de TI. É ótimo que haja monitoramento, mas ele precisa ser mais desenvolvido. Agora, não é possível, de alguma forma, restringir o acesso do usuário a qualquer parte individual do modelo de recursos de serviço (a seguir, CPM). Se a árvore do CPM for grande, a interface da web começará a ficar mais lenta. E as possibilidades de personalizar o cálculo de disponibilidade neste subsistema ainda são baixas.
- Atualizações longas. A última atualização do banco de dados levou cerca de oito horas. No momento, o serviço de monitoramento não estava disponível. Como alternativa, você pode solicitar scripts de suporte e atualizar separadamente.
- A funcionalidade modesta do subsistema de visualização interno. Grafana resolve esse problema, mas a visualização integrada deixa muito a desejar.
- Monitoramento integrado de DBMS (ODBC). O fato é que esse monitoramento abre uma conexão separada para o Zabbix toda vez que a métrica é pesquisada. E se o seu banco de dados for grande (com um grande número de métricas coletadas), o conjunto de conexões nele poderá ficar cheio e o banco de dados deixará de responder, inclusive nos sistemas de destino. O Zabbix possui uma ferramenta de monitoramento alternativa (por exemplo, DBforBIX), mas configurá-la para um grande número de objetos é uma tarefa bastante trabalhosa. Além disso, você precisa escrever uma automação separada.
- Falta de flexibilidade de inventário para a infraestrutura de TI. Por um lado, é bom tê-lo. Por outro lado, parece uma guia separada para qualquer objeto de monitoramento no qual exista um conjunto fixo de campos de inventário com nomes codificados. Para mudar algo, você precisa entrar no código fonte do frontend. Também é impossível alterar o número desses campos e tamanhos - existe o risco de quebrar algo durante a próxima atualização.
- Falta de automação para a construção de mapas de rede. Para comparação, podemos citar o HP OpenView Network Node Manager, que é perfeitamente capaz de criar mapas de topologia de rede no modo automático. O Zabbix terá que construir tudo manualmente. Talvez, por esse motivo, essa funcionalidade praticamente não seja procurada entre nós.
- Falta de flexibilidade no modelo. O Zabbix fornece apenas quatro funções de usuário com recursos fixos. Além disso, não há uma maneira imediata de restringir o acesso do usuário à API do Zabbix. Ou seja, se o usuário tiver acesso ao front-end, ele automaticamente terá acesso à API. Para nós, isso levou ao fato de que os usuários com solicitações ineptas carregaram seriamente o sistema. Além disso, não há como conceder acesso ao usuário, por exemplo, para ler métricas sem acesso, editar as configurações do objeto de monitoramento.
Arquitetura do sistema
Agora, algumas palavras sobre os indicadores quantitativos e a arquitetura do nosso sistema.
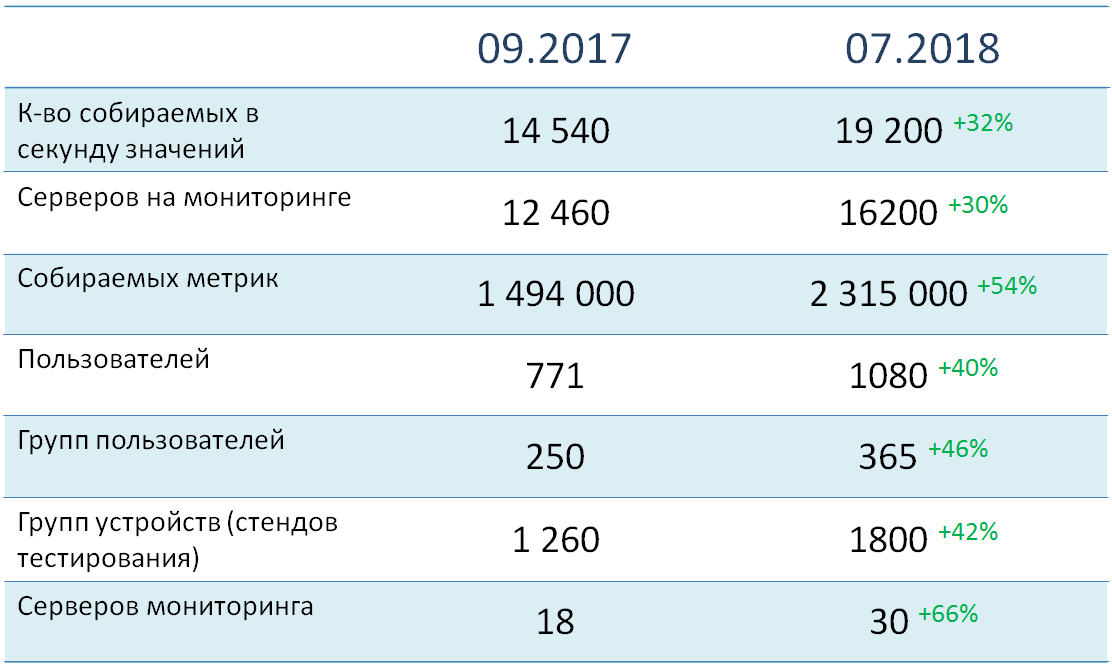
No momento, existem mais de 16 mil objetos (principalmente servidores) sob monitoramento, dos quais quase dois milhões e meio de métricas são coletadas no total. Sua carga total no sistema é de cerca de 19 mil valores por segundo. Todos os objetos de monitoramento são distribuídos em mais de 1800 grupos de dispositivos, a grande maioria dos quais corresponde a ambientes de teste específicos. Atualmente, mais de 1.000 usuários estão registrados no sistema, divididos em 365 grupos funcionais.
Como você pode ver, prestamos muita atenção à distribuição de dispositivos e usuários em grupos. Isso permite aumentar significativamente a precisão dos alertas de nosso serviço.
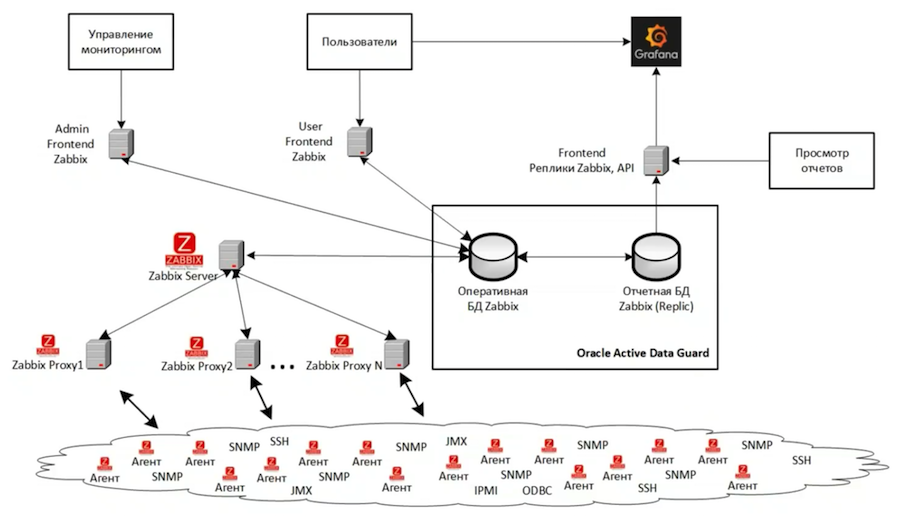
No total, temos três instâncias do Zabbix. O diagrama mostra a arquitetura da maior delas, que monitora a principal infraestrutura de TI de desenvolvimento e teste. Outra instância supervisiona a infraestrutura de monitoramento. E a terceira instância é usada conosco para o desenvolvimento e teste de novas ferramentas de monitoramento. Toda a estrutura da instância principal é virtualizada com base no VMWare. Em geral, se possível, é melhor não usar nenhum sistema de virtualização, porque é muito mais difícil pesquisar e resolver problemas de desempenho no caso de infraestrutura virtual.
O back-end é baseado no Oracle Active Data Guard e consiste em dois bancos de dados - o principal e a réplica. Temos três frentes:
- Para tarefas administrativas - é configurado para executar operações pesadas, complexas e de longo prazo que carregam muito o servidor;
- Personalizado - com configurações mais rígidas que não permitem que os usuários sobrecarregem demais o sistema de monitoramento principal;
- Para gerar relatórios, ele analisa a réplica e foi adaptado para interagir com bancos de dados somente leitura. O Grafana está conectado a ele, fornecendo visualização de alta qualidade dos dados de monitoramento.
Recursos de implementação
Nesta história, decidi não me concentrar na funcionalidade básica implementada em quase todas as falhas de monitoramento - consertando, coletando informações sobre o desempenho ou a disponibilidade dos sistemas de TI. Vou me concentrar nas características distintivas do nosso serviço.
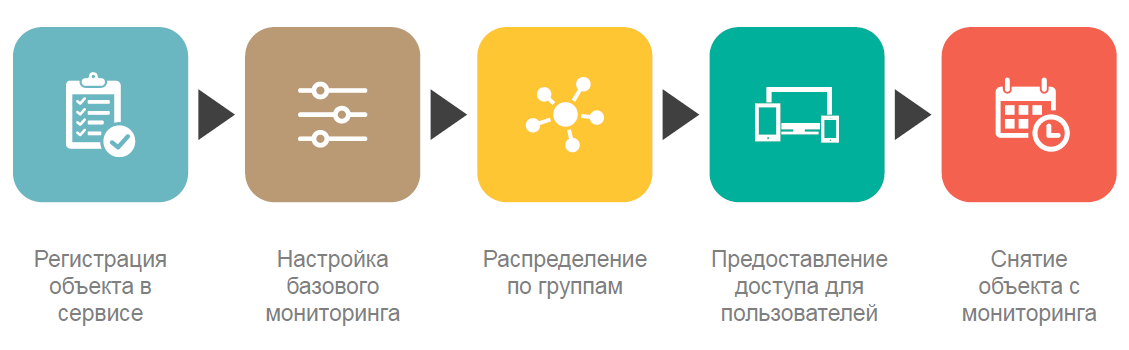
Esses recursos incluem principalmente um alto grau de automação de tarefas típicas. Praticamente não gastamos tempo configurando servidores para monitoramento, fornecendo acesso aos resultados do monitoramento, mas focamos principalmente no desenvolvimento do serviço e na adição de novos recursos não padronizados. Mais de 200 scripts de automação desenvolvidos a partir do momento em que o serviço de monitoramento foi colocado em operação de teste nos ajudam muito nisso.
Mas antes de registrar o agente no Zabbix, ele ainda precisa ser instalado. Como escrevi acima, uma das desvantagens do Zabbix é a falta de ferramentas de gerenciamento de agentes de monitoramento. Portanto, para instalar agentes, organizamos uma tarefa separada como parte de nossos processos de DevOps. A figura abaixo mostra o diagrama de instalação do agente.
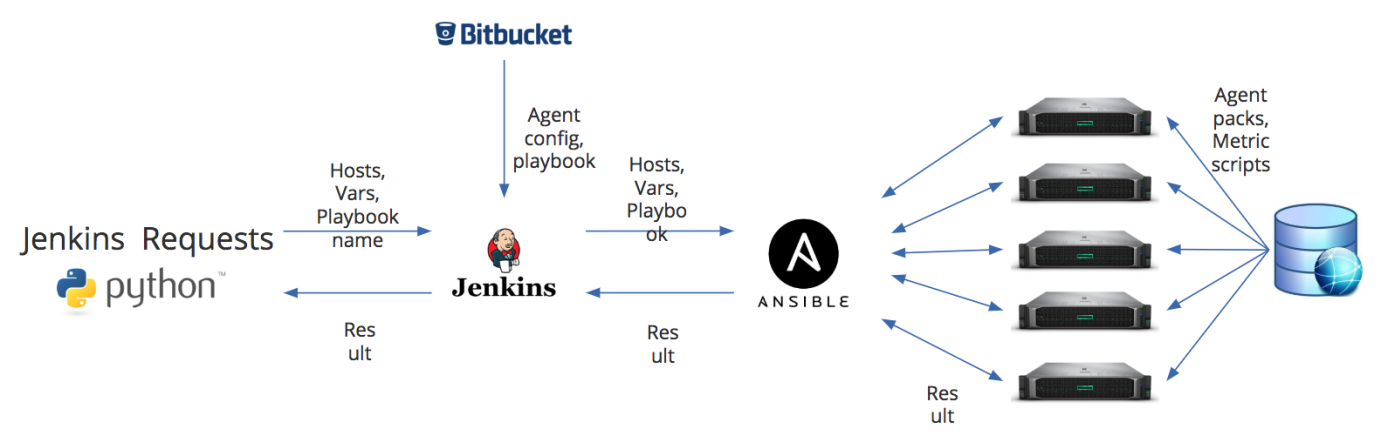
Temos dois pontos de entrada principais. Esse é um script Python - por meio da API REST, ele passa informações para o trabalho Jenkins sobre os hosts nos quais você deseja instalar ou atualizar o agente, uma lista de variáveis adicionais e o nome do manual que você precisa executar no Ansible. Ou os dados padrão podem vir do Bitbucket. Mas em Jenkins, eles podem ser completamente substituídos de acordo com as variáveis que passamos. E isso nos ajuda, por exemplo, a atualizar agentes que são monitorados por diferentes servidores proxy. A peculiaridade do nosso processo é que a configuração do agente Zabbix é formada quase em movimento.
Relatórios
Já no início do projeto, ficou claro que as ferramentas de relatório padrão fornecidas pelas ferramentas do Zabbix não nos permitiam atender a todas as nossas necessidades. Nesse sentido, com base na arquitetura de microsserviço, foi implementado um subsistema de geração de relatórios separado, que expande significativamente os recursos dos relatórios básicos de monitoramento. Agora, temos mais de vinte relatórios em operação. Aqui estão alguns exemplos, juntamente com os objetivos que estão sendo implementados:

Alertas
Durante todo o trabalho do serviço, os alertas por email evoluíram. Aqui está a aparência deles no momento:
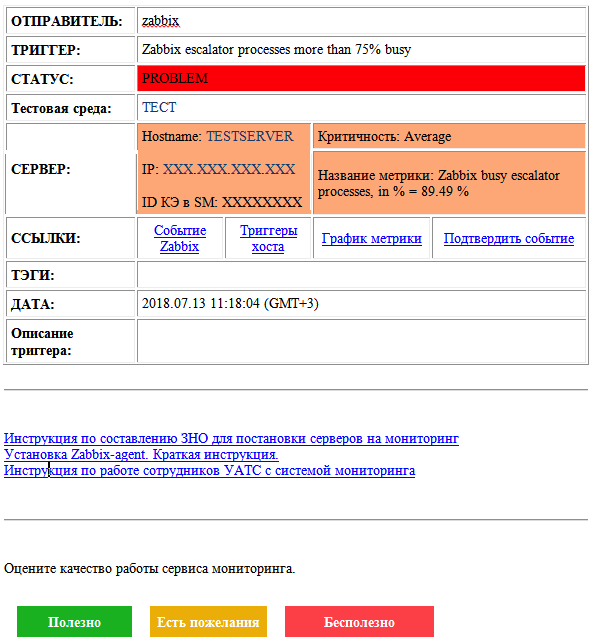
Há informações sobre o problema e seu status, bem como sobre o objeto de monitoramento. Existem links para métricas e eventos relacionados, um campo para descrever o problema, links para instruções e um formulário de feedback. Para acidentes mais críticos, é claro, também temos uma distribuição de SMS.
Esses alertas informativos nos permitiram minimizar a comunicação da maioria de nossos usuários com o próprio Zabbix. É o suficiente para receber esta lista de discussão. Agrupamos bem os usuários - existem 365 grupos para 1080 pessoas. Portanto, o boletim se mostra bastante pontilhado - e, portanto, não é irritante. Muitos de nossos usuários quase se esqueceram de que nós temos, de fato, o Zabbix - eles usam o boletim de notícias e o sistema de visualização Grafana.
Integração com processos de gerenciamento
O projeto inicialmente envolveu o monitoramento da integração com alguns de nossos processos de gerenciamento de infraestrutura de TI. Se o serviço de monitoramento registrou um acidente, você poderá criar um ticket para as equipes que trabalham mais com Jira. Para departamentos de serviço, é possível criar incidentes no HP Service Manager:

Com base no Zabbix, uma metodologia para otimizar a utilização da infraestrutura de TI também foi desenvolvida e automatizada. Três parâmetros principais são otimizados: a quantidade de CPU, RAM e discos rígidos. Essa técnica funciona com base em uma média móvel e um percentil de 90%. Com base nessa técnica, qualquer objeto ou servidor se enquadra em uma das três categorias: subcarregado, otimamente carregado, sobrecarregado.
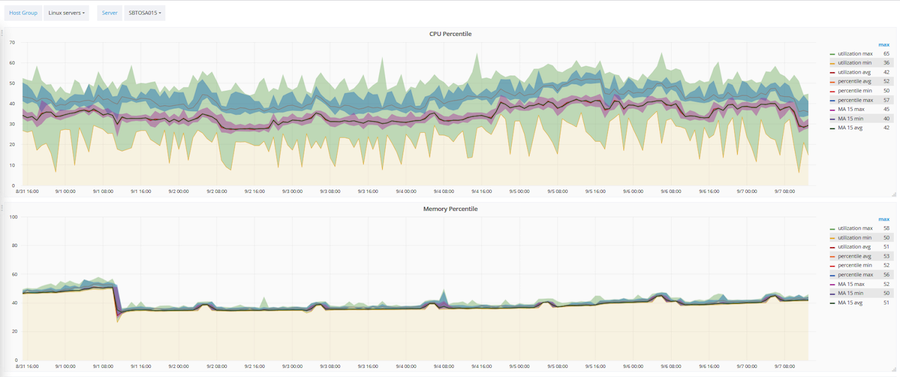
O exemplo acima mostra como essa técnica é aplicada a um servidor específico. O corredor rosa é o valor da média móvel. Corredor verde amplo - dados brutos. E o azul é um percentil 90%.
A integração com o banco de dados de configuração tornou possível automatizar a maioria das tarefas associadas ao fornecimento de acesso e à construção de um modelo de recurso de serviço. , . , , , .
Zabbix . , .
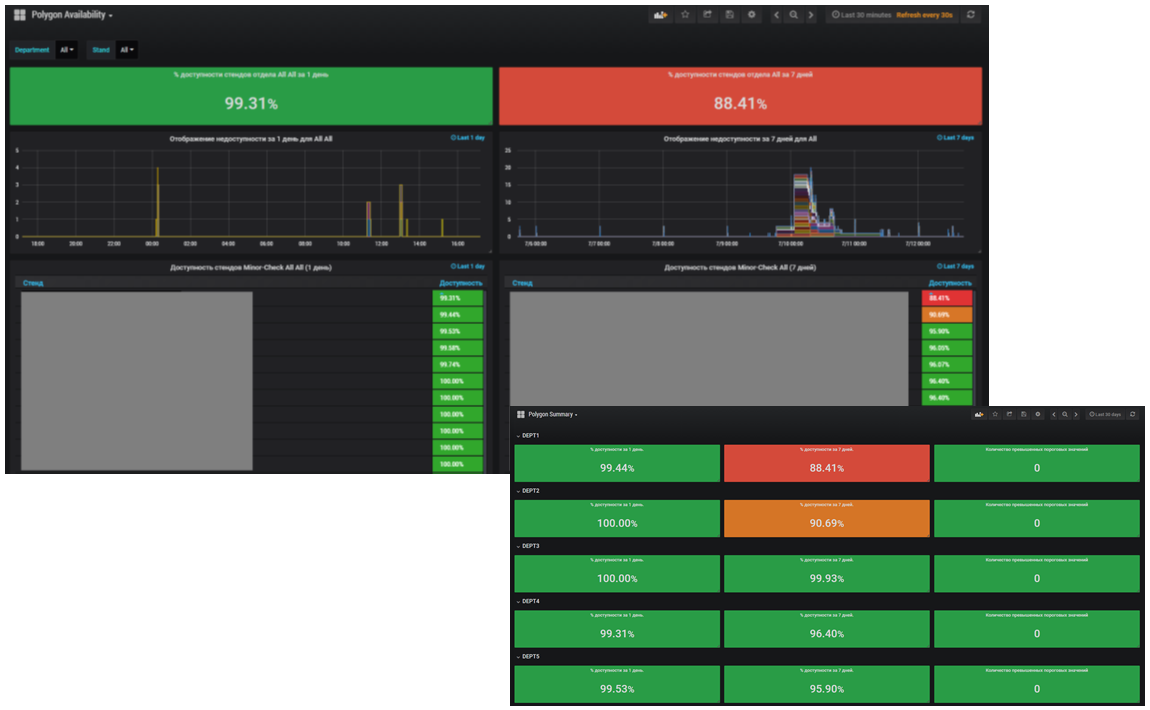
, . , . .
, . 2017 :
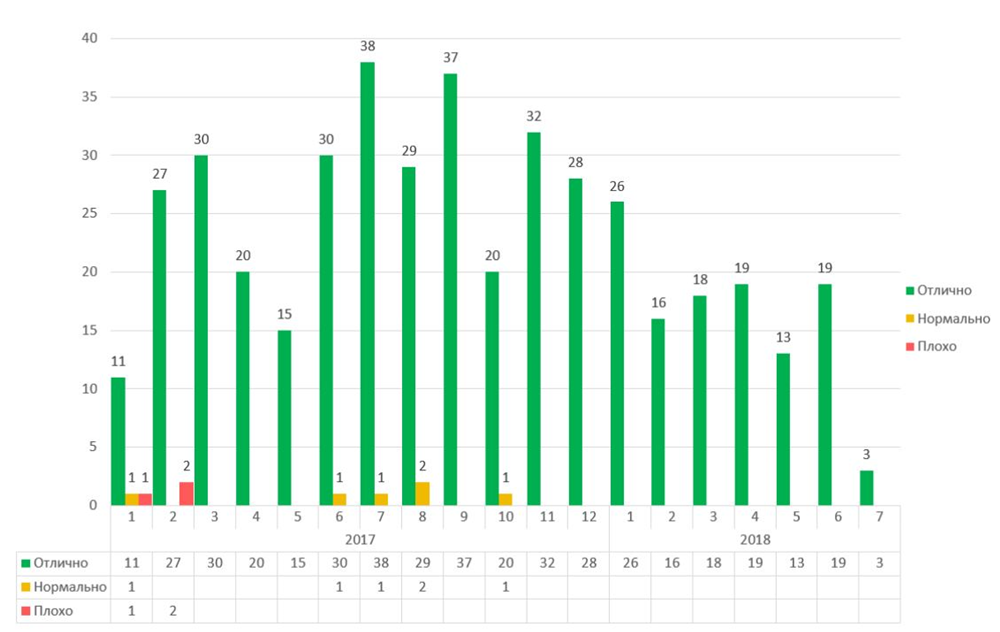
2017 .
, :
, . 70% . , , , .
2016 . . , , .
2016 . - , . . ,
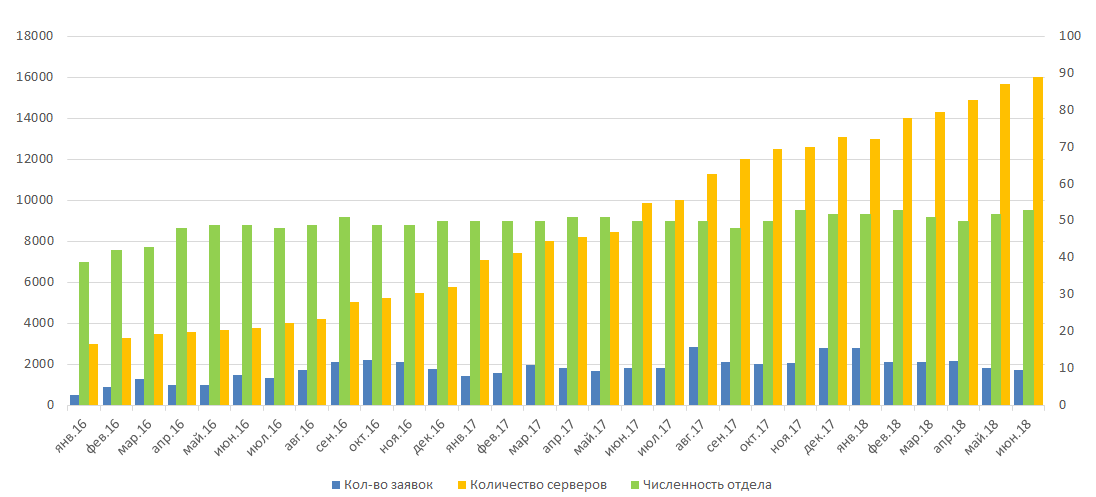
2016 , : 600 CPU, 7,5 50 .