Olá pessoal! Desta vez, quero escrever sobre como consegui vencer a competição
Mini AI Cup 2 . Como no meu
último artigo , praticamente não haverá detalhes de implementação. Desta vez, a tarefa era menos volumosa, mas, no entanto, havia muitas nuances e pequenas coisas que afetavam o comportamento do bot. Como resultado, mesmo após quase três semanas de trabalho ativo no bot, ainda havia idéias sobre como melhorar a estratégia.
Sob o corte de muitos gifs e tráfego.
Os persistentes descobrirão, o resto fugirá horrorizado (dos comentários na breve parte comprimida).Quem tem muita preguiça de ler muito pode ir ao penúltimo spoiler do artigo para ver uma breve descrição concisa do algoritmo , e então você pode começar a ler desde o início .Link para a fonte
no github .
Seleção de ferramenta
Como na última vez, levei muito tempo para pensar por onde começar. A escolha foi, entre outras coisas, entre duas linguagens: Java, familiar para mim, e já bastante esquecido dos dias de estudante em C ++. Mas, desde o início, pareceu-me que o principal obstáculo para escrever um bom bot não seria tanto a velocidade de desenvolvimento quanto a produtividade da solução final, mas a escolha caiu em C ++.
Após a experiência bem-sucedida de usar meu próprio visualizador para depurar o bot em competições anteriores, também não queria passar sem um. Mas o visualizador que escrevi para mim no Qt for
CodeWars não parecia uma solução ideal para mim e decidi usar
esse visualizador. Também foi feito sob o CodeWars, mas não exigiu processamento sério para uso nesta competição. A relativa simplicidade da conexão e a conveniência de invocar a renderização em qualquer lugar do código foram a seu favor.
Como antes, eu realmente queria depurar qualquer marca no jogo - a capacidade de executar uma estratégia em um momento arbitrário do jogo testado. Como o visualizador de plug-in não conseguiu resolver esse problema, com a ajuda do par #ifdef (no qual também agrupei as partes do código responsável pela renderização), adicionei a cada tick a gravação da classe Context, que continha todos os valores necessários das variáveis do tick anterior. No fundo, a solução era semelhante à que eu usei no Code Wizards, mas desta vez a abordagem não foi tão espontânea. Depois de simular o jogo inteiro, você foi solicitado a inserir o número do tick do jogo, que deve ser reiniciado. Informações sobre o estado das variáveis antes que esse tick fosse retirado da matriz, bem como a linha recebida pela estratégia de entrada, o que me permitiu executar os movimentos da minha estratégia em qualquer ordem necessária.
Iniciar
No dia em que as regras foram abertas, eu não passei e, na primeira noite, olhei o que nos esperava. Ele não hesitou em se indignar com o formato de entrada json (sim, é conveniente, mas alguns participantes começam a aprender YPs antigos, novos ou esquecidos em tais competições, e começar com a análise de json não é o mais agradável), olhou para a estranha fórmula do movimento e de alguma forma começou a formar o quadro do futuro estratégias (para entender o artigo no futuro, é útil ler as
regras ). Por 2 dias, escrevi várias classes como Ejection, Virus, Player e outras, lendo json, conectando uma biblioteca de arquivo único para registro ... E na noite da abertura de uma sandbox sem classificação, eu já tinha uma estratégia quase idêntica em princípio ao C ++, mas código significativamente maior.
E então ... comecei a descobrir opções, como desenvolvê-las. Pensamentos naquela época:
- A busca por estados mundiais não pode ser reduzida àqueles valores que podem dominar o minimax e as modificações;
- Campos potenciais são bons, mas respondem mal à pergunta de como o mundo mudará os próximos n tiques;
- A genética e algoritmos semelhantes funcionarão, mas apenas 20 ms são dados por golpe, e a profundidade do cálculo seria desejável, à primeira vista, mais do que as sensações podem ser processadas usando o GA. Sim, e você pode brincar com a seleção de parâmetros de mutação "felizes para sempre".
Definitivamente, decidi uma coisa: precisamos fazer uma simulação do mundo. Afinal, os cálculos aproximados podem "superar" um cálculo frio e preciso? Tais considerações, é claro, me levaram a examinar o código que deveria ser responsável por simular o mundo no servidor, porque desta vez foi colocado em domínio público junto com as regras. Afinal, não há nada melhor do que o código que descreva com precisão as regras do mundo?
Então pensei exatamente até começar a estudar o código que deveria testar nossos bots no servidor e localmente. Inicialmente, em termos de compreensibilidade e correção do código, nem tudo estava muito bem, e os organizadores, juntamente com os participantes, começaram a processá-lo ativamente. Durante o teste beta (captura alguns dias depois), as alterações no mecanismo de jogo foram muito graves e muitas não começaram a participar até o momento em que o mecanismo de teste não se estabilizou. Mas no final, na minha opinião, eles esperaram por um mecanismo que funcionasse bem para um jogo muito adequado ao formato da competição. Também não comecei a implementar abordagens sérias até que o corredor local se estabilizasse e, durante a primeira semana, nada mais sensato foi feito no meu robô, exceto pelo visualizador aparafusado.
Na véspera do primeiro fim de semana no telegrama, os organizadores criaram um grupo separado, no qual se supunha que as pessoas seriam capazes de ajudar a corrigir e melhorar o corredor local. Também participei do trabalho no motor do mundo. Após discussões neste bate-papo, como teste, fiz 2 solicitações pull para o local do corredor: ajustando a fórmula de
comer (e pequenas mudanças na ordem de comer) às regras e mesclando várias partes em um agárico,
mantendo a inércia e o centro de massa ). Então comecei a pensar em como inserir a física de colisão sã nesse código, porque a física presente no mundo dos jogos naquela época funcionava de maneira muito ilógica. Como as colisões entre os dois agáricos não foram descritas nas regras, solicitei aos organizadores critérios segundo os quais minha implementação dessa lógica seria aceitável. A resposta foi a seguinte: os agáricos em uma colisão devem ser "suaves" (ou seja, eles podem se chocar um pouco), enquanto a lógica de uma colisão com as paredes não deve ser tocada (ou seja, as paredes devem simplesmente parar os agáricos, mas não os afastar). E meu próximo
pedido de retirada foi uma alteração séria da física.
Antes e depois da alteração da físicaEssa física de colisão foi: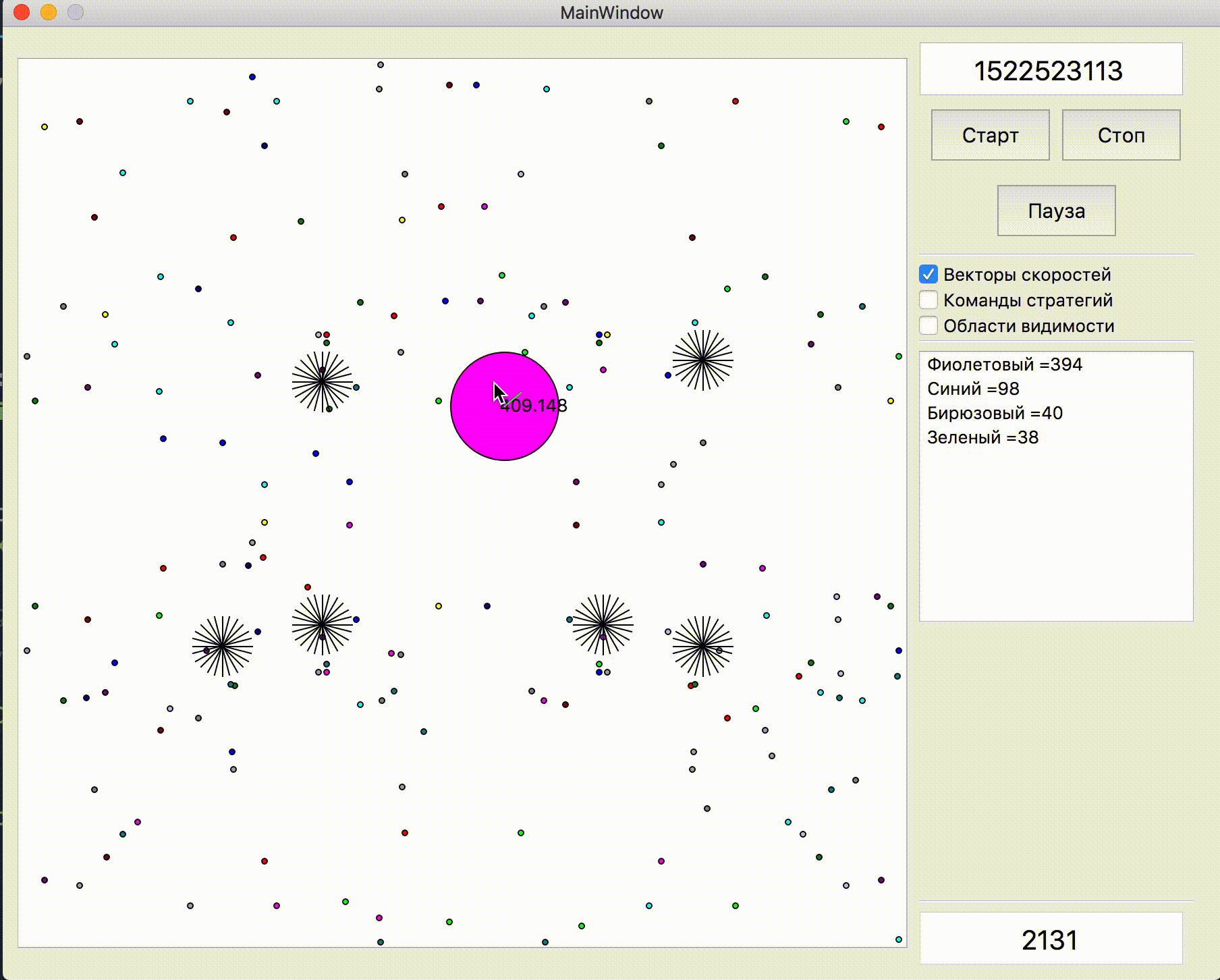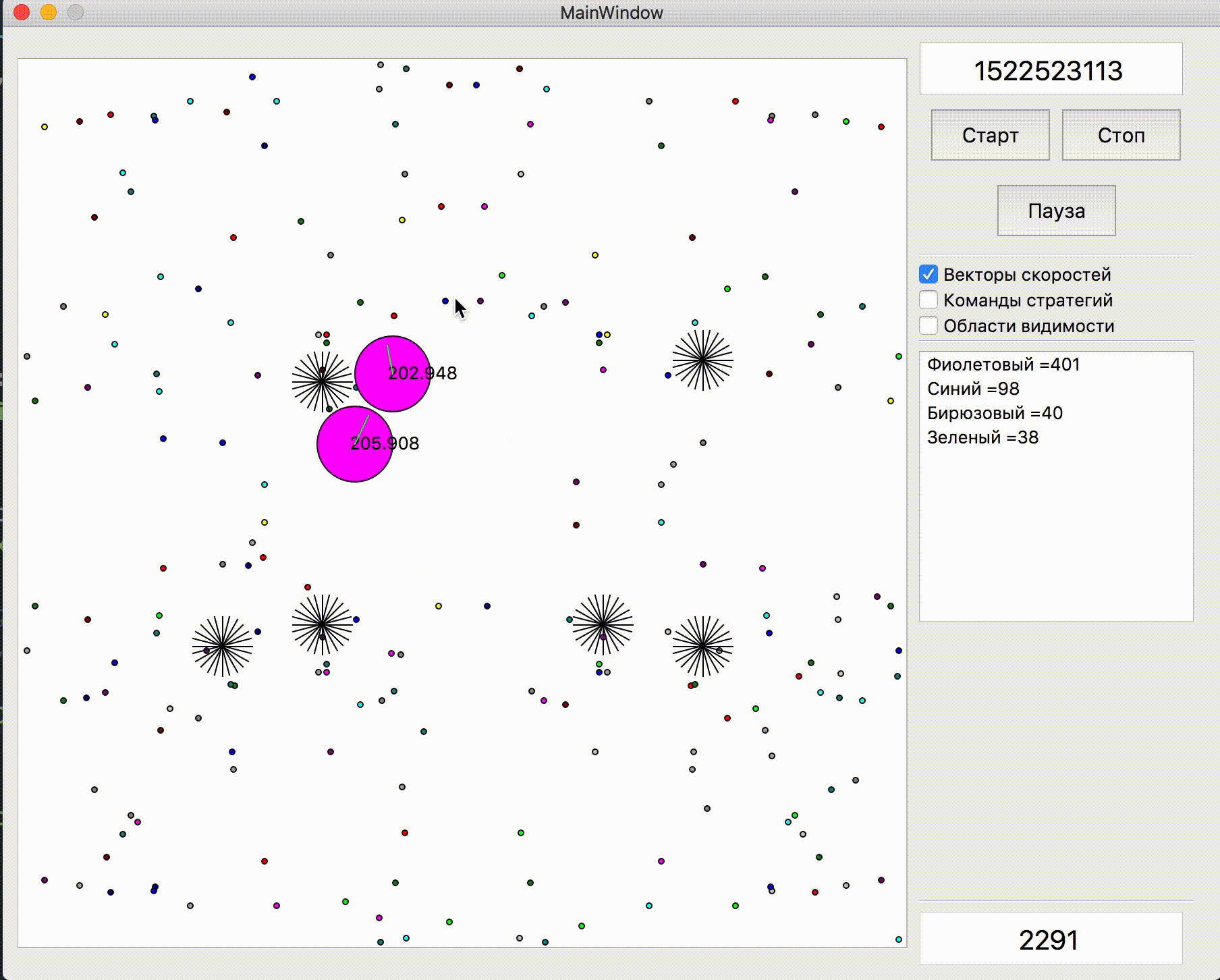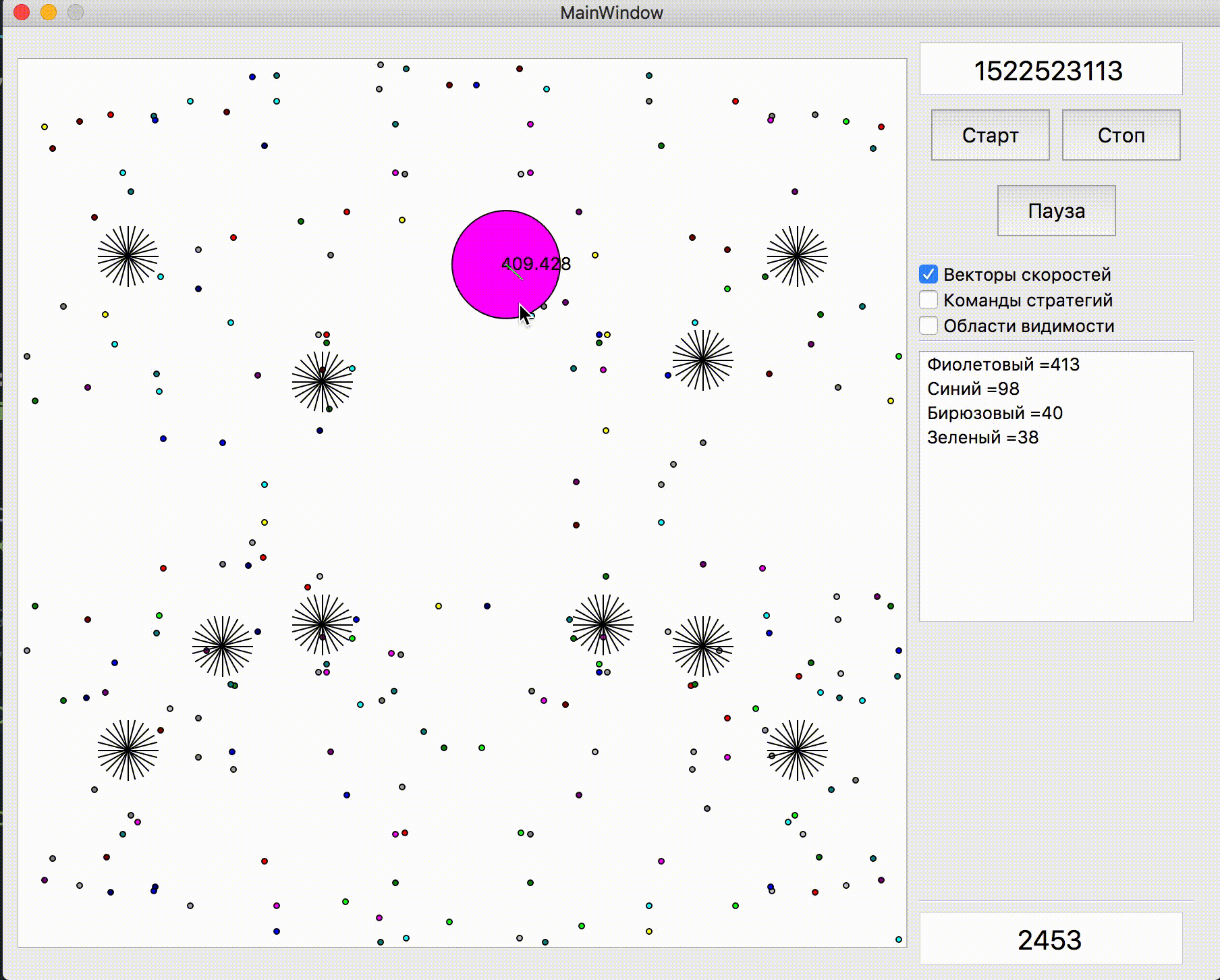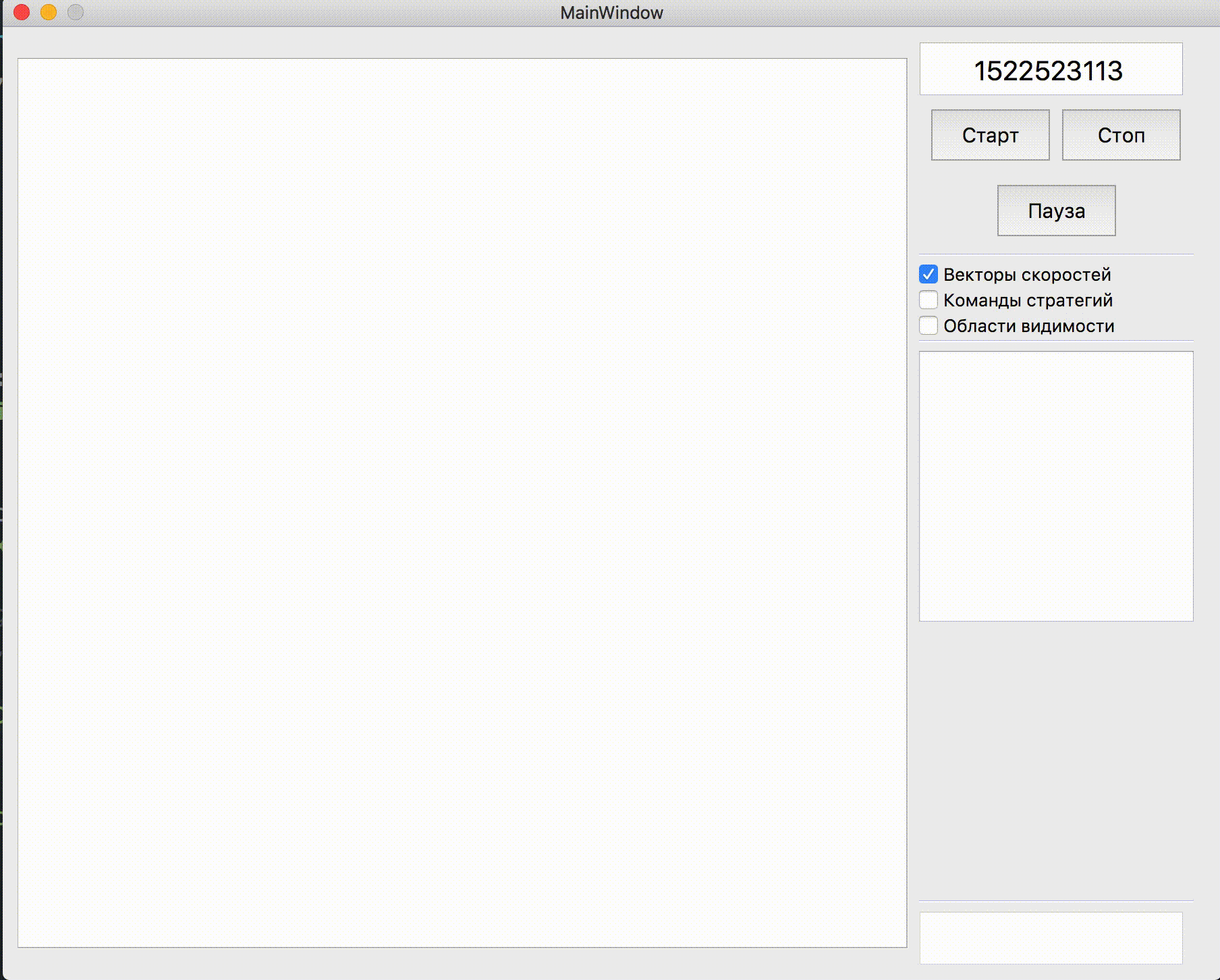 E ela ficou assim após as atualizações:
E ela ficou assim após as atualizações:
Também gostaria de destacar
essa solicitação de recebimento, que reduziu significativamente o código confuso com a análise de estado e um grande número de erros encontrados (e potenciais) em algo muito mais inteligível.
Escrevendo uma simulação
Depois de colocar o código de localidade do corredor em uma forma sã, gradualmente comecei a transferir o código de simulação mundial do local do corredor para o meu bot. Antes de tudo, era, é claro, um código para simular o movimento dos agáricos e, ao mesmo tempo, um código para calcular a física das colisões. Foram necessárias algumas noites para salvar o código reprojetado de reescrever bugs (a transferência lógica não foi realizada copiando o código) e estimativas aproximadas de quão profundo os cálculos devem ser feitos.
A função de classificação para cada carrapato naquele momento era +1 para o alimento que eu como e -1 para o inimigo que comeu, assim como valores ligeiramente maiores para comer os agáricos um do outro. Nas constantes para comer outros agáricos, havia inicialmente uma diferença entre comer meu oponente, meu oponente (e, é claro, uma multa muito grande por comer minha última agarika pelo oponente), bem como dois oponentes diferentes um do outro (depois de alguns dias, o último coeficiente se tornou 0). Além disso, a velocidade total de todos os ticks anteriores da simulação, cada tick foi multiplicado por 1 + 1e-5 para incentivar meu bot a executar ações mais úteis pelo menos um pouco antes e, no final da simulação, a velocidade do último tick foi adicionada como bônus, também muito pequena . Para simular o movimento dos agáricos, os pontos foram selecionados na borda do mapa com um passo de 15 graus a partir das coordenadas médias aritméticas de todos os meus agáricos, e um ponto foi selecionado ao simular o movimento no qual a função de estimativa assumiu o maior valor. E já com uma simulação aparentemente primitiva e uma avaliação simples na época, o bot firmemente entrincheirou-se no top 10.
Demonstração de pontos, o comando de movimento ao qual o algoritmo originalmente simulou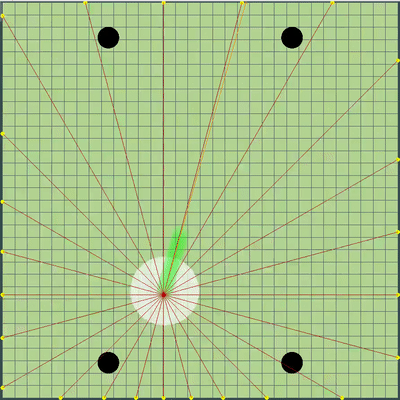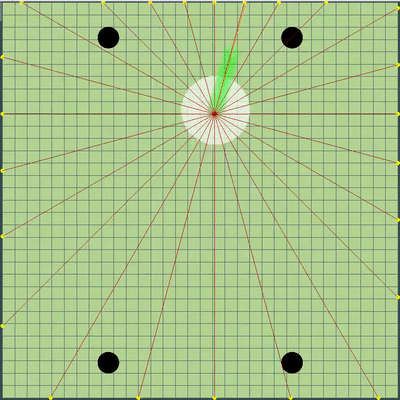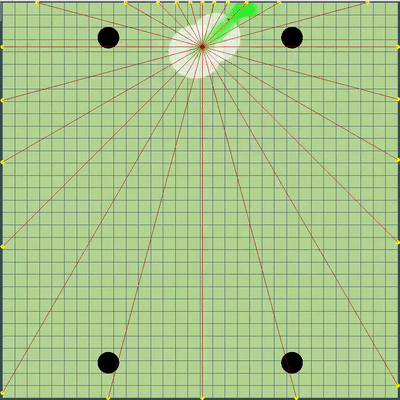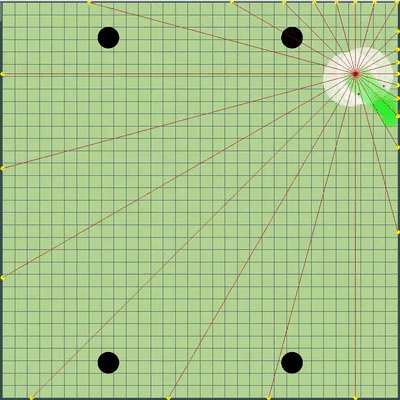 Pontos, cujo comando de movimento foi dado durante várias simulações. Se você olhar bem de perto - o comando final dado às vezes é alterado em relação aos pontos que estão sendo pesquisados, mas são conseqüências de alterações futuras.
Pontos, cujo comando de movimento foi dado durante várias simulações. Se você olhar bem de perto - o comando final dado às vezes é alterado em relação aos pontos que estão sendo pesquisados, mas são conseqüências de alterações futuras. Na noite de sexta e sábado, foi adicionada uma simulação de fusão de agáricos, uma simulação de "minar" os vírus e adivinhar o TTF do oponente. O TTF do oponente era um valor calculado bastante interessante, e era possível entender em que ponto o oponente fez uma divisão ou chegou ao vírus apenas capturando o momento do voo não controlado, que poderia durar de um número muito pequeno de carrapatos com uma grande viscosidade e até o vôo por todo o mapa. Como as colisões de agáricos podem levar a um ligeiro excesso de sua velocidade máxima, para calcular o TTF do oponente, verifiquei que a velocidade dele em dois tiques seguidos corresponde realmente à velocidade em que você pode obter dois tiques seguidos em voo livre (em voo livre, os agáricos voavam estritamente em linha reta e com desacelerar cada escala estritamente igual à viscosidade). Isso quase eliminou completamente a possibilidade de falsos positivos. Além disso, durante o teste dessa lógica, notei que um TTF maior sempre corresponde a um ID maior do agaric (do qual mais tarde fiquei convencido ao transferir o código de
explosão para o vírus e
processar a divisão ), o que também valeu a pena.
Tendo analisado as constantes divisões no top 3 (o que lhes permitiu coletar significativamente comida no mapa), como teste, adicionei um comando de divisão permanente ao bot se não houvesse inimigo no raio de visibilidade, e no domingo de manhã encontrei meu bot na segunda linha da classificação. Gerenciar um punhado de pequenos agáricos aumentou muito o ranking, mas perdê-los era muito mais fácil se você se deparar com um oponente. E como o medo de ser comido pelos meus agáricos era muito condicional (a penalidade era apenas por comer em uma simulação, mas não por abordar um oponente que pudesse comer), a primeira coisa foi adicionada uma penalidade por cruzar com um oponente que pudesse comer. E essa mesma avaliação funcionou como um bônus por perseguir um oponente. Depois de verificar o consumo de CPU com minha estratégia, decidi adicionar mais uma rodada de simulação quando a divisão foi feita no primeiro tick (essa lógica, é claro, também teve que ser transferida para o meu código a partir do código do idioma do corredor) e, em seguida, a simulação foi exatamente a mesma de antes . Esse tipo de lógica não era muito adequado para "atirar" no inimigo (embora, às vezes, por acidente se partisse em um momento muito adequado), mas era muito bom para coletar comida mais rapidamente, o que todo o topo estava fazendo naquele momento. Tais modificações nos permitiram entrar na próxima semana na primeira linha do rating, embora a margem não tenha sido significativa.
Naquele momento, isso foi o suficiente, a "espinha dorsal" da estratégia foi elaborada, a estratégia parecia bastante primitiva e expansível. Mas o que eu realmente notei foi o consumo da CPU e a estabilidade geral do código. Portanto, principalmente as noites da próxima parte da semana de trabalho foram dedicadas a melhorar a precisão das simulações (que o visualizador ajudou muito), estabilizando o código (valgrind) e algumas otimizações da velocidade de trabalho.
Vamos em frente
Minha próxima estratégia enviada, que mostrou um resultado significativamente melhor e foi à frente dos adversários (na época), continha duas mudanças significativas: adicionar um campo potencial para coletar comida e dobrar o número de simulações se houver um oponente com um TTF desconhecido nas proximidades.
O campo potencial para a coleta de alimentos na primeira versão era bastante simples e toda a sua essência era lembrar os alimentos que desapareciam da zona de visibilidade, reduzindo o potencial nos locais próximos aos quais o bot inimigo estava e zerando na minha zona de visibilidade (com restauração subseqüente a cada n carrapatos de acordo com as regras). Isso parecia uma melhoria útil, mas, na prática, na minha opinião subjetiva, a diferença era pequena ou completamente ausente. Por exemplo, em cartões com alta inércia e velocidade, o bot geralmente pulava a comida e tentava voltar a ela, perdendo muita velocidade. No entanto, se ele decidisse manter a velocidade e simplesmente ignorasse os alimentos ignorados, ele comeria muito mais.
Campo potencial de coleta de alimentos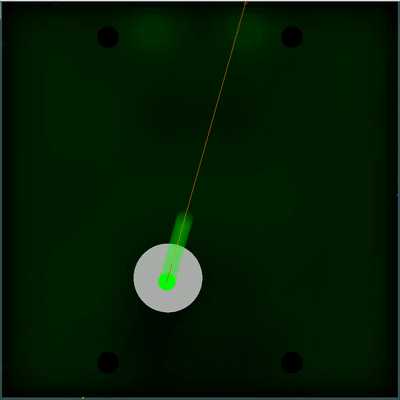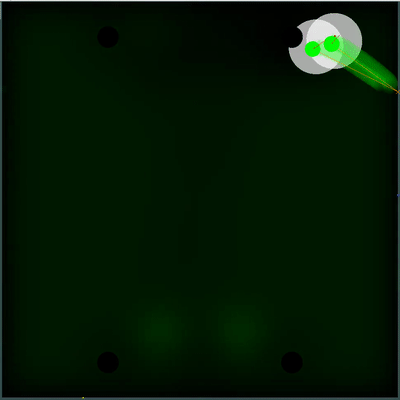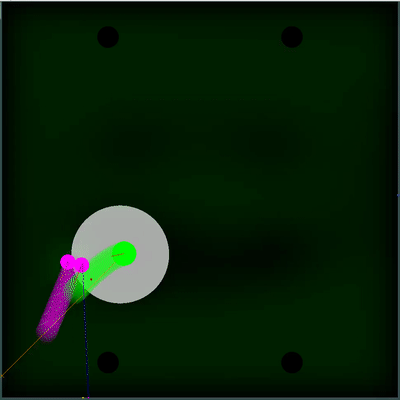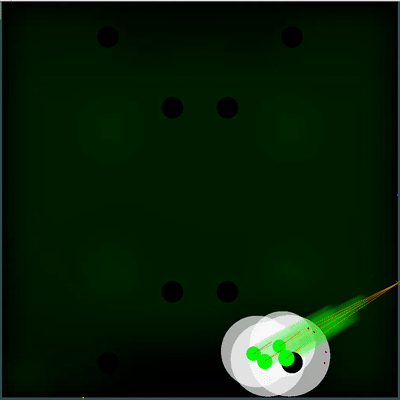 Você pode prestar atenção em como a cada 40 ticks o campo fica um pouco mais brilhante. A cada 40 carrapatos, o campo é atualizado de acordo com a forma como os alimentos são adicionados no mapa, e a probabilidade de os alimentos aparecerem é "manchada" uniformemente no campo. Se neste carrapato, vemos que há comida que veríamos no carrapato anterior - a probabilidade de aparecimento desse alimento não é "manchada" com o restante, mas é definida por pontos específicos (o alimento aparece a cada 40 carrapatos estritamente simetricamente).
Você pode prestar atenção em como a cada 40 ticks o campo fica um pouco mais brilhante. A cada 40 carrapatos, o campo é atualizado de acordo com a forma como os alimentos são adicionados no mapa, e a probabilidade de os alimentos aparecerem é "manchada" uniformemente no campo. Se neste carrapato, vemos que há comida que veríamos no carrapato anterior - a probabilidade de aparecimento desse alimento não é "manchada" com o restante, mas é definida por pontos específicos (o alimento aparece a cada 40 carrapatos estritamente simetricamente). Uma utilidade subjetiva completamente diferente acabou sendo uma simulação dupla do inimigo com diferentes TTFs - o mínimo e o máximo possível (caso eu não conheça o TTF para todos os agáricos visíveis no mapa). E se antes meu bot pensava que o grupo inimigo de agáricos se tornaria um todo e se moveria lentamente, então agora ele escolheria o pior dos dois cenários e não arriscaria estar perto do inimigo, sobre quem ele sabe menos do que gostaria.
Depois de ganhar uma vantagem significativa, tentei aumentá-la adicionando uma definição do ponto em que o oponente instrui seus agarics a se moverem, e embora esse ponto tenha sido calculado na maioria dos casos com bastante precisão, isso por si só não melhorou os resultados do bot. De acordo com minhas observações, ficou ainda pior do que o caso quando os agáricos do oponente simplesmente se moveram na mesma direção e na mesma velocidade como se o oponente não tivesse feito nada, então essas edições foram salvas em um ramo de violão separado até melhores tempos.
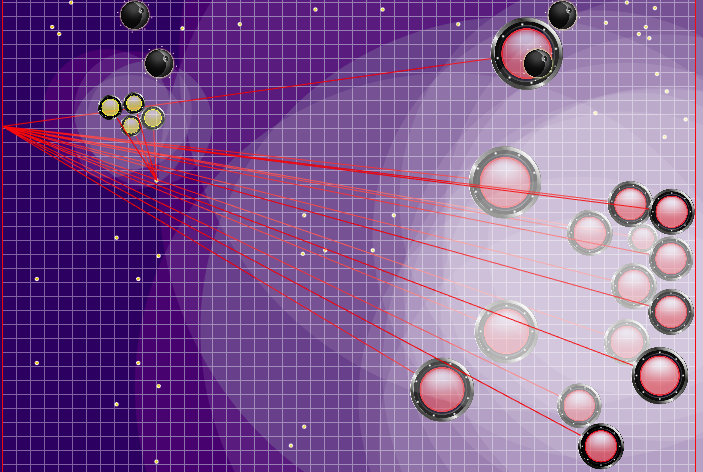
A definição da equipe adversária que foi usada posteriormente Os raios dos agarics do oponente mostram o suposto time que o oponente deu aos agarics no tick anterior. Os raios azuis são a direção exata em que o agarik mudou de direção no último tique. Preto é o pretendido. Era possível determinar com mais precisão a direção da equipe apenas se o ágar estivesse completamente na zona de nossa visibilidade (era possível calcular o efeito de colisões na mudança de velocidade). A interseção dos raios é a equipe pretendida do oponente. Gif feito com base no jogo aicups.ru/session/200710 , cerca de 3.000 carrapatos.
Os raios dos agarics do oponente mostram o suposto time que o oponente deu aos agarics no tick anterior. Os raios azuis são a direção exata em que o agarik mudou de direção no último tique. Preto é o pretendido. Era possível determinar com mais precisão a direção da equipe apenas se o ágar estivesse completamente na zona de nossa visibilidade (era possível calcular o efeito de colisões na mudança de velocidade). A interseção dos raios é a equipe pretendida do oponente. Gif feito com base no jogo aicups.ru/session/200710 , cerca de 3.000 carrapatos. Houve também tentativas de transferir a função de avaliação para a avaliação da massa ganha, tentativas de mudar a função de avaliar o perigo do oponente ... Mas, novamente, todas essas mudanças de sentimentos tornaram-se ainda piores. A única coisa que foi útil com a função de avaliar o perigo de estar perto do inimigo foi outra otimização de desempenho, além de estender essa estimativa para um raio muito maior que o raio de interseção com o inimigo (essencialmente todo o mapa, mas com uma redução quadrática, se um pouco simplificado - presença em cinco ou mais raios do oponente na região de 1/25 do risco máximo de ser comido). A última mudança também não planejada levou ao fato de que meus agariks ficaram com muito medo de se aproximar de um inimigo significativamente maior, e, no caso de seus tamanhos muito superiores, estavam mais inclinados a se mover em direção ao oponente. Portanto, acabou sendo um substituto bem-sucedido e não intensivo em recursos para o código planejado para o futuro, que deveria ser responsável pelo medo de um ataque de um oponente por meio da divisão (e uma pequena ajuda nesse ataque para mim mais tarde).
Depois de longas e relativamente infrutíferas tentativas de melhorar algo, voltei novamente a prever a direção do movimento do oponente. Decidi tentar se não é apenas substituir os rivais fictícios, e fazer como fiz com a opção TTF mínima e máxima - simule duas vezes e escolha a melhor. Mas, para isso, a CPU pode não ser suficiente e, em muitos jogos do meu bot, eles podem simplesmente se desconectar do sistema devido a um apetite insaciável. Portanto, antes de implementar esta opção, adicionei uma definição aproximada do tempo gasto e, se os limites forem excedidos, comecei a reduzir o número de movimentos de simulação. Ao adicionar uma simulação dupla do inimigo para o caso em que conheço o local para onde ele está indo, recebi novamente um aumento bastante sério na maioria das configurações de jogo, exceto pela mais intensiva em recursos (com alta inércia / baixa velocidade / baixa viscosidade), que devido a uma forte diminuição de profundidade As simulações podem ficar ainda um pouco piores.
Antes do início dos jogos de 25k tick, foram feitas mais duas melhorias úteis: a penalidade por terminar a simulação longe do centro do mapa, além de lembrar a posição anterior do oponente se ele deixasse a linha de visão (além de simular seu movimento naquele momento).
A implementação da penalidade para a posição final do bot na simulação foi um campo de perigo estático pré-calculado com zero perigo em um raio um pouco maior que a metade do comprimento do campo de jogo e aumentando gradualmente à medida que se afasta do campo de jogo. A aplicação de uma multa desse campo nos pontos finais da simulação quase não exigia uma CPU e evitava corridas extras nos cantos, às vezes evitando os ataques inimigos. E a memorização com a simulação subsequente de rivais, na maioria das vezes, nos permitiu evitar dois problemas às vezes manifestados. O primeiro problema é apresentado no GIF abaixo. O segundo problema era que, se um inimigo maior se perdia do campo de visão (por exemplo, após a fusão de suas partes), era possível "com êxito" se unir a ele, alimentando adicionalmente um oponente já perigoso.Exemplo de um campo de perigo no final de uma curva em um canto e carrapatos desperdiçados Inicialmente, as multas foram planejadas perto das paredes, mas no final foram adicionadas apenas nos cantos.
Inicialmente, as multas foram planejadas perto das paredes, mas no final foram adicionadas apenas nos cantos.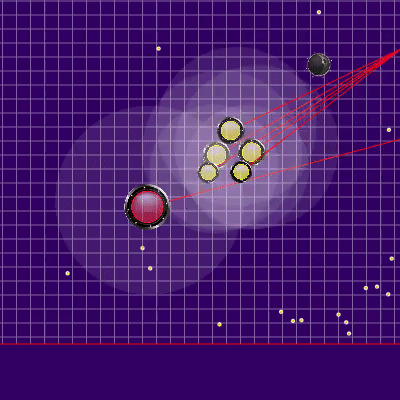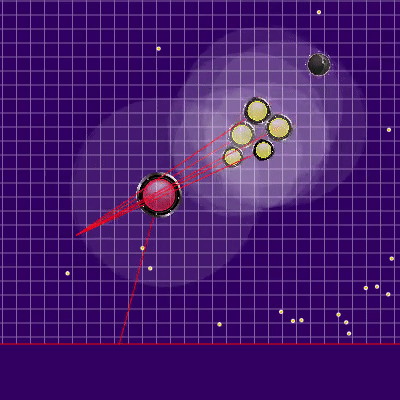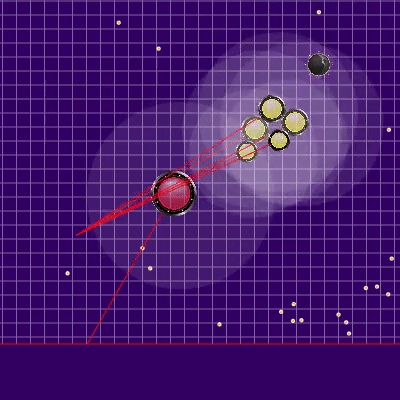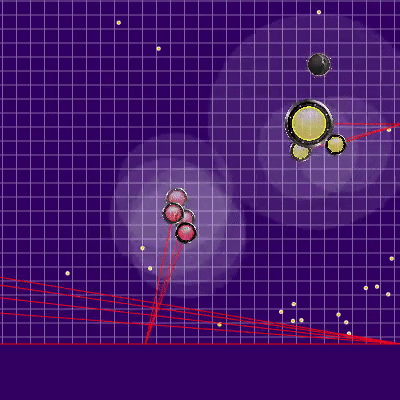 O que pode acontecer se você não se lembrar da localização anterior do inimigo? Nesse caso, a geléia durou pouco, mas havia muito mais graves.
O que pode acontecer se você não se lembrar da localização anterior do inimigo? Nesse caso, a geléia durou pouco, mas havia muito mais graves. Além disso, pontos de simulação de movimento foram adicionados aos pontos na borda do mapa: a cada agarik de rivais e dentro de um raio da coordenada média aritmética do meu agariki a cada 45 graus. O raio foi definido para uma distância média das coordenadas aritméticas médias dos meus agáricos.Novos pontos de simulação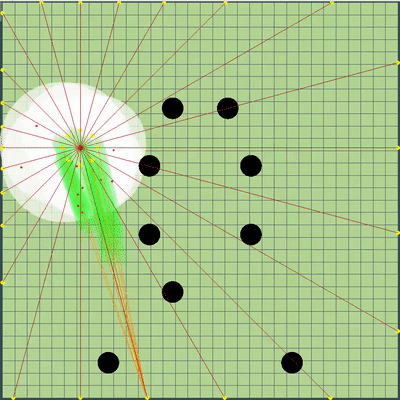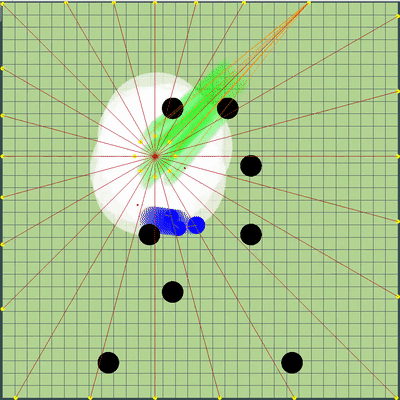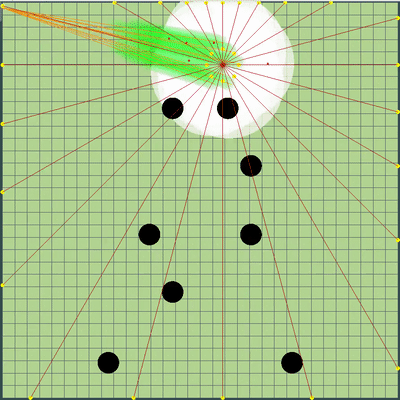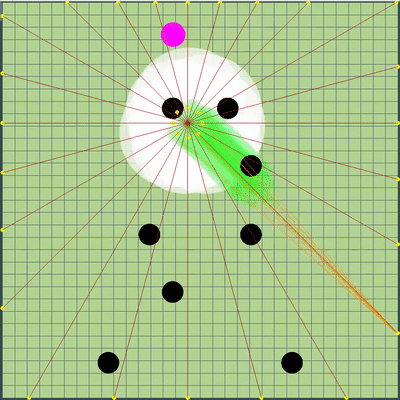 Ao redor do ponto central dos meus agariks, adicionamos pontos de simulação adicionais. Ocasionalmente, eles ajudavam os agariks a "se reunir" no lugar certo para comer seus rivais. O resto do tempo, eles eram praticamente inúteis.
Ao redor do ponto central dos meus agariks, adicionamos pontos de simulação adicionais. Ocasionalmente, eles ajudavam os agariks a "se reunir" no lugar certo para comer seus rivais. O resto do tempo, eles eram praticamente inúteis. Preparação final
No momento da abertura dos jogos para 25k ticks e da passagem para a final, eu tinha uma margem sólida, mas não planejava relaxar.Juntamente com os novos jogos de 25k, chegou a notícia: os jogos durante a final também terão 25k de duração e o prazo da estratégia para os ticks se tornou um pouco mais. Depois de avaliar o tempo que minha estratégia gasta no jogo nas novas condições, decidi adicionar outra versão da simulação: fazemos tudo como de costume, mas durante a simulação em movimento n dividimos. Isso, entre outras coisas, exigiu o uso da simulação encontrada na etapa anterior, mas com um deslocamento de 1 movimento (por exemplo, se descobrimos que a separação de 7 tiques do atual, no próximo passo, repetimos o mesmo, mas faremos a divisão já no sexto passo). Isso acrescentou ataques agressivos aos rivais, mas consumiu mais tempo de estratégia.Deveria ter havido uma descrição concisa do algoritmoE ficou assim: Avaliação da simulação: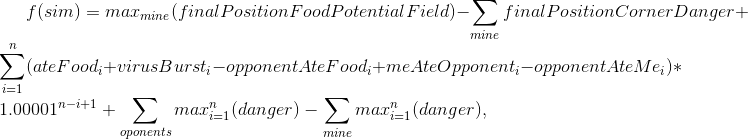
- f — , ;
- sim — ( , , TTF , );
- finalPositionFoodPotentialField — , , ;
- finalPositionCornerDanger — . , ;
- n — , . 10 50 ;
- ateFood — i;
- virusBurst — i;
- opponentAteFood — i;
- meAteOpponent — ;
- opponentAteMe — ;
- mine/opponents — . I.e. — ;
- danger — , , .
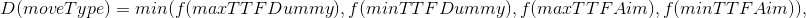
- moveType — , ;
- max/min TTF — , TTF ( TTF );
- dummy/aim — Dummy ( , ).
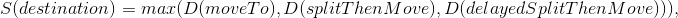
- destination — , ;
- moveTo — , n “ ” ;
- splitThenMove — split ;
- delayedSplitThenMove — , split .
1 . I.e. splitThenMove moveTo, delayedSplitThenMove 7 6 , 6 5 .. , — 7 . .
destination :
- 15 ( — ). 24 ;
- , ( );
- :
- “” , ;
- 8 . .
destination , .
Todos os refinamentos adicionais estavam relacionados exclusivamente à eficiência das simulações no caso de falta de TL: otimização da sequência de desconectar certas partes da lógica, dependendo da CPU consumida. Na maioria dos jogos, isso não deveria mudar nada, mas criar algo mais correto do que não funcionou.Pontos finais na final. 808 2424 , . .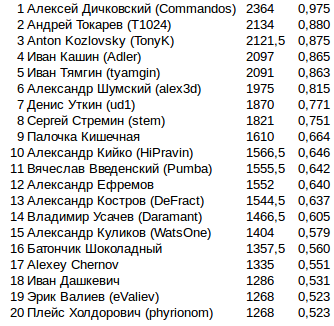
Em vez de uma conclusão
Em geral, o início dessa competição acabou sendo bastante polido, mas nas primeiras uma semana e meia a tarefa foi levada a uma forma bastante jogável com a ajuda dos participantes. Inicialmente, a tarefa era muito variável e escolher a abordagem correta para resolvê-la não parecia uma tarefa trivial. Ainda mais interessante foi encontrar maneiras de melhorar o algoritmo sem ultrapassar os limites do consumo de CPU. Muito obrigado aos organizadores da competição e por apresentarem os códigos-fonte do mundo para acesso aberto. Este último, é claro, acrescentou muito problemas a eles no início, mas facilitou muito (se não para dizer, o que tornou possível em princípio) a compreensão dos participantes sobre o dispositivo do simulador de mundo. Agradecimentos especiais pela oportunidade de escolher um prêmio! Portanto, o prêmio saiu muito mais útil :-) Por que preciso de outro MacBook?