
Hoje no KDD 2018 é um dia de seminário - juntamente com uma grande conferência que começa amanhã, vários grupos reuniram ouvintes sobre alguns tópicos específicos. Já esteve em duas dessas festas.
Análise de Séries Temporais
De manhã, eu queria ir a um seminário sobre análise de
gráficos , mas ele foi detido por 45 minutos, então mudei para o próximo, analisando séries temporais. De repente, um
professor loiro da Califórnia abre o seminário com o tópico "Inteligência Artificial em Medicina". Estranho, porque para isso existe uma faixa separada na próxima sala. Acontece que ela tem vários alunos de pós-graduação que falarão sobre séries temporais aqui. Mas, na verdade, ao ponto.
Inteligência Artificial em Medicina
Erros médicos são a causa de 10% das mortes nos EUA, esta é uma das três principais causas de morte no país. O problema é que não há médicos suficientes; aqueles que estão sobrecarregados e os computadores têm mais probabilidade de criar problemas para os médicos do que podem resolver, pelo menos os médicos. No entanto, a maioria dos dados não é realmente usada para tomada de decisão. Tudo isso deve ser combatido. Por exemplo, uma bactéria,
Clostridium difficile, é altamente virulenta e resistente a medicamentos. No ano passado, ela infligiu US $ 4 bilhões em danos. Vamos tentar avaliar o risco de infecção com base nas séries temporais de registros médicos. Diferentemente dos trabalhos anteriores, tomamos muitos sinais (vetor de 10 mil por dia) e criaremos modelos individuais para cada hospital (de várias maneiras, aparentemente, uma medida necessária, pois todos os hospitais têm seu próprio conjunto de dados). Como resultado, obtemos uma precisão de cerca de 0,82 AUC com um prognóstico de risco CDI após 5 dias.
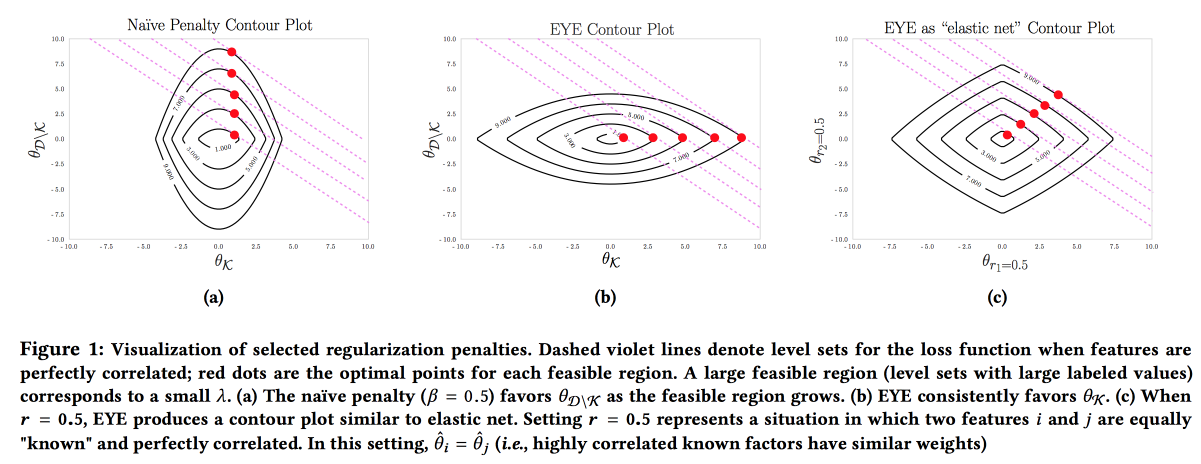
É importante que o modelo seja preciso, interpretável e robusto; precisamos mostrar o que podemos fazer para prevenir a doença. Esse modelo pode ser construído usando ativamente o conhecimento da área de assunto. É o desejo de interpretabilidade que muitas vezes reduz o número de recursos e leva à criação de modelos simples. Mas mesmo um modelo simples com um grande espaço de recursos perde a capacidade de interpretação, e o uso da regularização L1 geralmente leva ao fato de que o modelo seleciona aleatoriamente um dos recursos colineares. Como resultado, os médicos não acreditam no modelo, apesar de uma boa AUC. Os autores propõem o uso de um tipo diferente de regularização
EYE (estimativa de rendimento de especialistas). Dado se há dados conhecidos sobre o efeito no resultado, acaba focando o modelo nos recursos necessários. Dá bons resultados, mesmo se o especialista errar, além disso, comparando a qualidade com regularizações padrão, você pode avaliar quanto o especialista está certo.
Em seguida, prosseguimos para a análise de séries temporais. Acontece que, para melhorar a qualidade deles, é importante procurar invariantes (de fato - levar a alguma forma canônica). Em um
artigo recente, um grupo de professores propôs uma abordagem baseada em duas redes convolucionais. O primeiro, Sequence Transformer, leva a série para uma forma canônica, e o segundo, Sequence Decoder, resolve o problema de classificação.
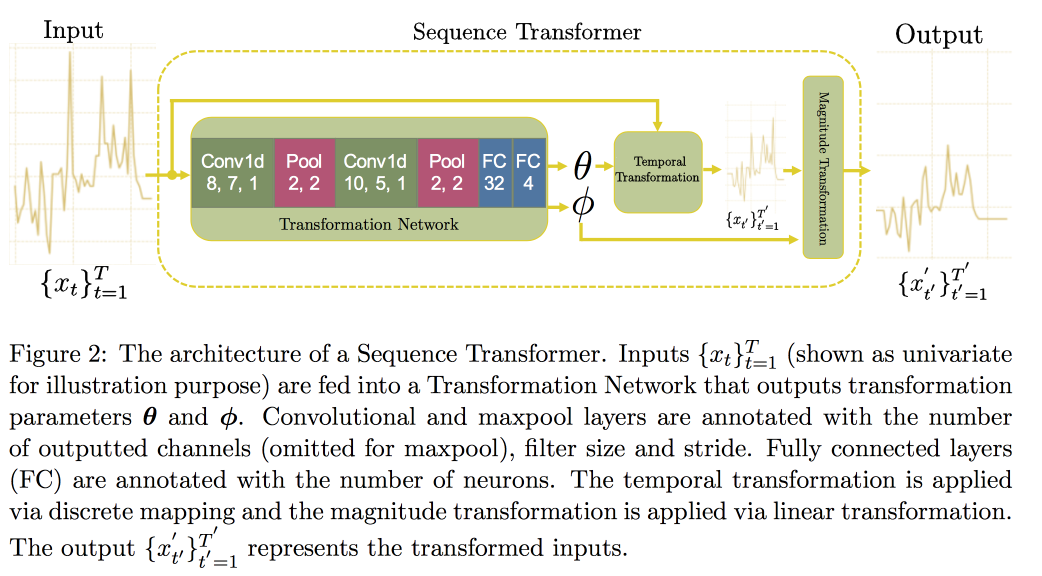
O uso da CNN, em vez da RNN, é explicado pelo fato de eles trabalharem com linhas de comprimento fixo. Verificado no
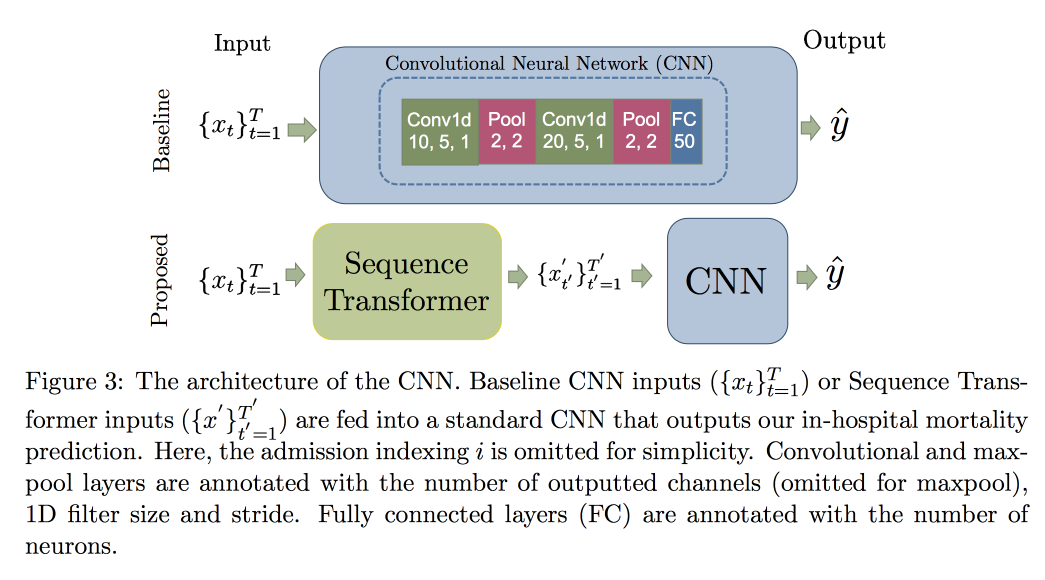
conjunto de dados MIMIC, tentou prever a morte no hospital em 48 horas. O resultado foi uma melhoria de 0,02 AUC em comparação com a CNN simples com camadas adicionais, mas os intervalos de confiança se sobrepõem.
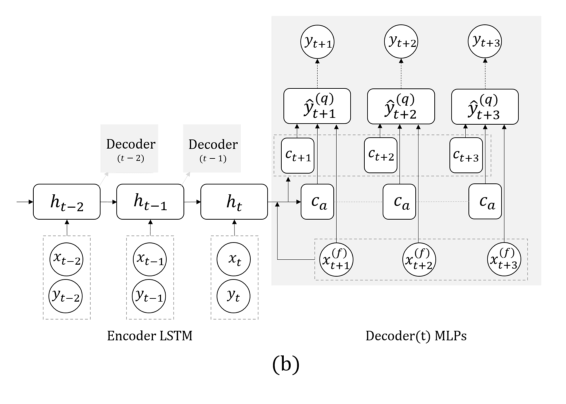
Agora outra tarefa: preveremos apenas com base nas séries reais, sem sinais externos (que comeram, etc.). Aqui, a equipe propôs substituir a RNN por prever alguns passos à frente por uma grade com várias saídas, sem recursão entre elas. A explicação para esta solução é que um erro não se acumula durante a recursão. Combine esta técnica com a anterior (procure invariantes). Imediatamente após a apresentação do professor, o pós-doc falou detalhadamente sobre esse modelo, então aqui terminamos, observando apenas que, ao validar, é importante observar não apenas o erro geral, mas também o erro de classificação de casos perigosos de glicose muito alta ou baixa.
Fiz uma pergunta sobre o feedback do modelo: embora essa seja uma pergunta muito aberta, eles dizem que devemos tentar entender quais mudanças na distribuição dos sintomas ocorrem como resultado do fato da intervenção e quais são as mudanças naturais causadas por fatores externos. Na verdade, a presença de tais mudanças complica muito a situação: é impossível treinar novamente o modelo, pois a qualidade é degradante, misturar aleatoriamente (não tratar alguém e verificar se ele vai morrer) não é ético, mas aprender com os dados em que todos foram tratados de acordo com a recomendação do modelo é garantido. preconceito ...
Geração de caminho de amostra
Um exemplo de como não fazer apresentações: muito rápido, difícil de ouvir e captar a idéia é quase impossível. O trabalho em si está disponível
aqui .
Os caras desenvolvem seu resultado de previsão anterior vários passos à frente. Há duas idéias principais no trabalho anterior: em vez de RNN, use uma rede com várias saídas para diferentes pontos no tempo, além de números específicos, tentamos prever distribuições e avaliar quantis. Isso tudo é chamado de
MQ-RNN / CNN (regressão quantílica de previsão Multi-Horizont).
Desta vez, tentamos refinar a previsão usando o pós-processamento. Consideradas duas abordagens. Como parte da primeira, estamos tentando “calibrar” a distribuição da rede neural usando dados posteriores e aprendendo a matriz de covariância de saídas e observações, o chamado Encolhimento por Covariância. O método é bastante simples e funcional, mas quero mais. A segunda abordagem foi usar modelos generativos para criar uma "amostra de caminho": eles usam a abordagem generativa para previsão (GAN, VAE). Resultados bons, porém instáveis, foram obtidos com a ajuda do
WaveNet, desenvolvido para
geração de som.
Redes estruturadas em gráfico
Um trabalho interessante sobre a transferência de "conhecimento da área temática" na rede neural. Eles mostraram o exemplo da previsão do nível de criminalidade no espaço (por regiões da cidade) e no tempo (por dias e horas). A principal dificuldade: fortes dados esparsos e a presença de eventos locais raros. Como resultado, muitos métodos não funcionam bem; em média, ainda é possível adivinhar diariamente, mas não para áreas e horas específicas. Vamos tentar combinar uma estrutura de alto nível e micropadrões em uma rede neural.
Construímos um gráfico de comunicação usando códigos postais e determinamos a influência de um sobre o outro usando o
Processo Multivariado de Hawkes . Em seguida, com base no gráfico obtido, construímos a topologia da rede neural, ligando os blocos das regiões da cidade a um crime que mostrou uma correlação.
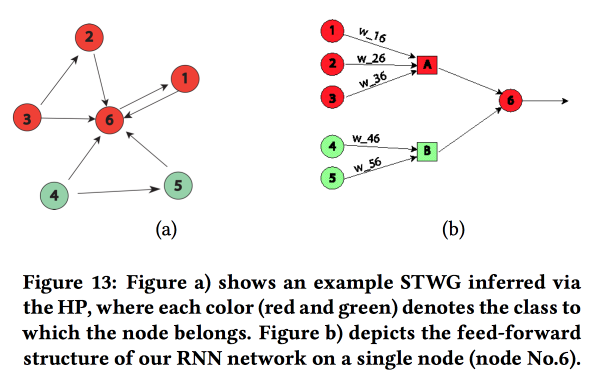
Comparamos essa abordagem com outras duas: o treinamento em uma grade para um distrito ou em uma grade para um grupo de regiões com uma taxa de criminalidade semelhante mostrou um aumento na precisão. Para cada região, é introduzido um LSTM de duas camadas com duas camadas totalmente conectadas.
Além dos crimes, eles também mostraram exemplos de trabalhos sobre previsão de tráfego. Aqui, o gráfico para construir uma rede já é obtido geograficamente pelo kNN. Não está totalmente claro quanto seus resultados podem ser comparados com outros (eles mudaram livremente as métricas na análise), mas, em geral, a heurística para construir uma rede parece adequada.
Abordagem não paramétrica para previsão de conjuntos
Os conjuntos são um tópico muito popular, mas como obter o resultado de previsões individuais nem sempre é óbvio. Em seus trabalhos, os autores propõem uma
nova abordagem .
Muitas vezes, conjuntos simples funcionam bem, melhor ainda. que o novo
modelo bayesiano de média e média-NN. A regressão também não é ruim, mas geralmente gera resultados estranhos em termos de escolha de pesos (por exemplo, isso dará a algumas previsões um peso negativo etc.). De fato, o motivo disso geralmente reside no fato de o método de agregação usar algumas suposições sobre como o erro de previsão é distribuído (por exemplo, de acordo com Gauss ou normal), mas quando é usado, eles esquecem de verificar essa suposição. Os autores tentaram propor uma abordagem livre de suposições.
Consideramos dois processos aleatórios: o processo de geração de dados (DGP) modela a realidade e pode depender do tempo, e o processo de geração de previsão (FGP) modela a construção das previsões (existem muitas delas - uma por membro do conjunto). A diferença entre esses dois processos também é aleatória, que tentaremos analisar.
- Coletamos dados históricos e construímos a densidade de distribuição de erros para os preditores usando a Estimativa de densidade do kernel.
- Em seguida, criamos uma previsão e a transformamos em uma variável aleatória adicionando o erro construído.
- Então resolvemos o problema de maximizar a probabilidade.
O método resultante é quase como EMOS (Ensemble Model Output Statistics) com um erro gaussiano e muito melhor com não gaussiano. Muitas vezes, na realidade, por exemplo, (
conjunto de dados de tráfego de páginas da Wikipedia ) é um erro não gaussiano.
LSTM aninhado: modelando taxonomia e dinâmica temporal em redes sociais baseadas em localização
O trabalho é enviado por autores do Google. Estamos tentando prever a próxima verificação do usuário. usando sua história de chekins recentes e metadados de lugares, antes de tudo, a relação deles com tags / categorias. As categorias são de três níveis, usamos os dois níveis superiores: a categoria pai descreve a intenção do usuário (por exemplo, o desejo de comer) e a categoria filho descreve as preferências do usuário (por exemplo, o usuário gosta de comida espanhola). A categoria subsidiária da próxima verificação deve ser mostrada para obter mais receita com publicidade on-line.
Usamos dois LSTMs aninhados: o superior, como de costume, de acordo com a sequência de verificações, e o aninhado - de acordo com as transições na árvore de categorias de pai para filho.
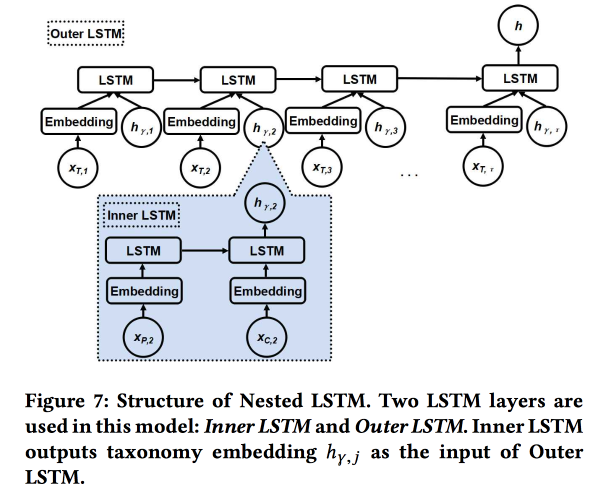
Acontece 5-7% melhor em comparação com o LSTM simples com incorporações de categoria bruta. Além disso, mostramos que as junções de transição LSTM na árvore de categorias parecem mais bonitas que as simples e estão melhor agrupadas.
Identificando mudanças no espaço semântico evolutivo
Discurso alegre o suficiente do
professor chinês . O ponto principal é tentar entender como as palavras mudam de significado.
Agora, todo mundo está treinando com sucesso as combinações de palavras, elas funcionam bem, mas ser treinado em momentos diferentes não é adequado para comparação - você precisa fazer alinhamento.
- Você pode usar o antigo para inicialização, mas isso não dá garantias.
- Você pode aprender a função de transformação para alinhar, mas nem sempre funciona, pois as dimensões nem sempre são compartilhadas igualmente.
- E você pode usar topológico, não espaço vetorial!
No final, a essência da solução: construímos um gráfico knNN nos vizinhos da palavra em diferentes períodos para avaliar a mudança de significado e tentamos entender se há uma mudança significativa. Para isso, usamos o modelo
Surpresa Bayesiana . De fato, observamos a
divergência de KL da distribuição de uma hipótese (anterior) e uma hipótese sujeita a observações (posterior) - isso é uma surpresa. Com palavras e gráficos cnn, usamos Dirichlet com base nas frequências de vizinhos no passado como uma distribuição a priori e a comparamos com o real multinomial na história recente. Total:
- Nós cortamos a história.
- Construímos incorporações (LINE com preservação da inicialização).
- Consideramos o KNN nas incorporações.
- Aprecie a surpresa.
Nós validamos pegando duas palavras aleatórias com a mesma frequência e trocamos entre si - o aumento de qualidade como surpresa é de 80%. Então pegamos 21 palavras com desvios de significado conhecidos e verificamos se podemos encontrá-las automaticamente. As fontes abertas ainda não têm uma descrição detalhada dessa abordagem, mas
há uma no SIGIR 2018 .
AdKDD e TargetAd
Depois do almoço, fui para um seminário sobre publicidade online. Existem muitos mais palestrantes da indústria e todo mundo está pensando em como ganhar mais dinheiro.
Ad tech na airbnb
Por ser uma grande empresa com uma grande equipe de DS, o AirBnB investe bastante na promoção correta de si e de suas ofertas internas em sites externos. Um dos desenvolvedores falou um pouco sobre os desafios.
Vamos começar com a publicidade em um mecanismo de pesquisa: ao pesquisar hotéis no Google, as duas primeiras páginas são publicidade :(. Mas o usuário geralmente nem entende isso, porque a publicidade é muito relevante. Esquema padrão: correspondemos às solicitações de publicidade por palavras-chave e obtemos o significado do padrão / padrão ( cidade, barato ou luxo, etc.)
Após a seleção dos candidatos, organizamos um leilão entre eles (agora o
Segundo Preço Generalizado é usado em todos os lugares). Ao participar do leilão, o objetivo é maximizar o efeito em um orçamento fixo, usando um modelo com uma combinação da probabilidade de um clique e uma renda: Lance = P (clique | consulta de pesquisa) * valor da reserva. Um ponto importante: não gaste todo o dinheiro muito rapidamente, então adicione Spend pacer.
O AirBnB possui um sistema poderoso para testes A / B, mas não pode ser aplicado aqui, pois controla a maior parte do processo do Google. Lá eles prometeram adicionar mais ferramentas para os anunciantes, os grandes players estão realmente ansiosos.
Problema separado: contato do usuário com publicidade em vários locais. Viajamos em média duas vezes por ano, o ciclo de preparação de uma viagem e reserva é muito longo (semanas e até meses), existem vários canais nos quais podemos alcançar o usuário e precisamos dividir o orçamento por canal. Este tópico é muito doloroso, existem métodos simples (linearmente, com cuidado, pelo último clique ou pelos resultados do
teste de elevação ). O AirBnB tentou duas novas abordagens: baseadas nos modelos de Markov e
no modelo de Shapley .
Com o modelo de Markov, tudo fica mais ou menos claro: estamos construindo uma cadeia discreta, cujos nós correspondem aos pontos de contato com a publicidade, há também um nó para conversão. De acordo com os dados, selecionamos pesos para transições, fornecemos mais orçamento aos nós em que a probabilidade de transição é maior. Fiz uma pergunta: por que usar uma cadeia simples de Markov, enquanto é mais lógico usar o MDP; Eles disseram que estão trabalhando neste tópico.
É mais interessante com Shapley: na verdade, este é um esquema conhecido para avaliar o efeito aditivo, no qual diferentes combinações de efeitos são consideradas, o efeito de cada um deles é avaliado e, em seguida, é determinado um agregado para cada efeito individual. A dificuldade é que pode haver sinergia entre os efeitos (menos frequentemente antagonismo), e o resultado da soma não é igual à soma dos resultados. Em geral, uma teoria bastante interessante e bonita,
aconselho você a ler .
No caso do AirBnB, a aplicação do modelo Shapley é mais ou menos assim:
- Nos exemplos de dados observados, temos diferentes combinações de efeitos e o resultado real.
- Preencha as lacunas nos dados (nem todas as combinações são apresentadas) usando ML.
- Calculamos o empréstimo para cada tipo de impacto de Shapley.
Microsoft: Pressionando limites de {AI}
Mais um pouco sobre isso. como a Microsoft está envolvida em publicidade, agora do lado do site, principalmente o Bing. Um pouco de matança:
- O mercado publicitário está crescendo muito rapidamente (exponencialmente).
- A publicidade em uma página canibaliza uma à outra, você precisa analisar a página inteira.
- A conversão em algumas páginas é maior, apesar do CTP ser pior.
Existem cerca de 70 modelos no mecanismo de publicidade do Bing, 2000 experimentos offline e 400 online. Uma mudança significativa na plataforma a cada semana. Em geral, eles trabalham incansavelmente. Quais são as mudanças na plataforma:
- O mito de uma métrica: não funciona dessa maneira, as métricas crescem e competem.
- Redesenhamos o sistema de solicitações de correspondência de publicidade da PNL para a DL, calculado no FPGA.
- Eles usam modelos federais e bandidos contextuais: modelos internos produzem probabilidade e incerteza, o bandido de cima toma uma decisão. Ela falou muito sobre bandidos, eles são usados para lançar modelos e lançamentos em velocidade de cruzeiro, contornam o fato de que, muitas vezes, melhorar o modelo leva a uma renda mais baixa :(
- É muito importante avaliar a incerteza (bem, sim, sem ela você não pode construir um bandido).
- Para pequenos anunciantes, a instituição da publicidade por meio de bandidos não funciona, há poucas estatísticas, é necessário criar modelos separados para um começo a frio.
- É importante monitorar o desempenho em diferentes coortes de usuários, pois eles têm um sistema automático para fatiar de acordo com os resultados do experimento.
Conversamos um pouco sobre a análise de vazão. Nem sempre as hipóteses dos vendedores sobre as causas da saída são verdadeiras, você precisa se aprofundar. Para fazer isso, você precisa criar modelos interpretáveis (ou um modelo especial para explicar previsões) e pensar muito. E então faça os experimentos. Mas sempre é difícil fazer experimentos com a saída, eles recomendam o uso de métricas de segunda ordem e
um artigo do Google .
Eles também usam o Commercial Knowledge Graph, que descreve a área de assunto: marcas, produtos, etc. O gráfico é construído de forma totalmente automática, sem supervisão. As marcas são marcadas com categorias, isso é importante, pois em geral nem sempre é possível não supervisionar o isolamento da marca como um todo, mas dentro de um determinado tópico da categoria o sinal é mais forte. Infelizmente, não encontrei trabalhos abertos pelo método deles.
Anúncios do Google
O mesmo cara que falou ontem sobre as contagens conta que tudo é tão triste e arrogante. Andamos em vários tópicos.
Parte Um: Alocação Estocástica de Anúncios Robusta. Temos nós orçados (anúncios) e online (usuários), e também existem alguns pesos entre eles. Agora você precisa escolher quais anúncios exibir o novo nó. Você pode fazê-lo com avidez (sempre com o peso máximo), mas então corremos o risco de elaborar um orçamento prematuramente e obter uma solução ineficaz (o limite teórico é 1/2 do ideal). Você pode lidar com isso de diferentes maneiras; de fato, aqui temos um conflito tradicional entre revenu e wellfair.
Ao escolher o método de alocação, pode-se assumir uma ordem aleatória de aparência dos nós on-line de acordo com alguma distribuição, mas na prática também pode haver uma ordem contraditória (isto é, com elementos de algum efeito oposto). Os métodos nesses casos são diferentes, eles fornecem links para os artigos mais recentes:
1 e
2 .
Parte II: Aprendizagem com percepção inconsciente / Preços robustos. Agora, estamos tentando resolver a questão de escolher o preço da reserva para aumentar a receita dos sites de publicidade. Também consideramos o uso de outros leilões, como o
leilão Myerson ,
BINTAC , reversão para o leilão do primeiro preço em caso de contato com a reserva. Eles não entram em detalhes, enviam para
o artigo .
Parte Três: Pacote Online. Mais uma vez, resolvemos o problema de aumentar a renda, mas agora vamos do outro lado. Se você pudesse comprar anúncios em massa (pacote off-line), em muitas situações poderá oferecer uma solução mais ideal. Mas você não pode fazer isso em um leilão on-line, precisa criar modelos complexos com memória e, em condições adversas, o RTB não o empurra.
Então, um modelo mágico aparece, onde toda a memória é reduzida para um dígito (conta bancária), mas o tempo está se esgotando e o alto-falante começa a folhear freneticamente os slides. , ,
.
Deep Policy optimization by Alibaba
«sponsored search». RL, — .
.
offline- , , online-, .
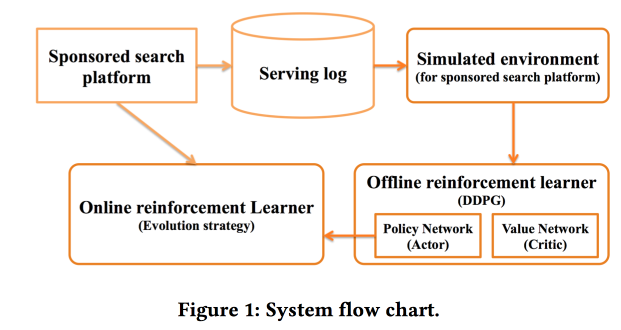
CTR ,
DDPG .
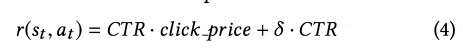
- , « »:
Criteo Large Scale Benchmark for Uplift Modeling
( ). Criteo
Criteo-UPLIFT1 (450 ) .
. -, , ( ). — (, ).
? . - , — , (AUUC).
Qini- (
Gini ), Qini, .
. : , . .
revert label. , , , , ; . , , .
, . .
Deep Net with Attention for Multi-Touch Attribution
, ,
Adobe . , , ! , attention- LSTM, . LSTM- .
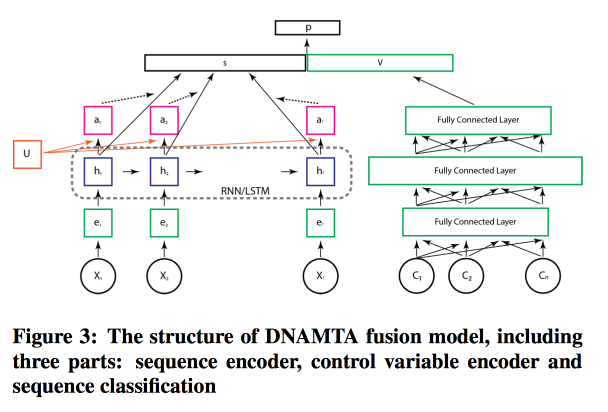
, attention- .
Conclusão
Depois, houve uma sessão de abertura pathos com um vídeo IMAX com a melhor tradição de trailers de grande sucesso, muito obrigado a todos que ajudaram a organizar tudo isso - um KDD recorde em todos os aspectos (incluindo patrocínio de US $ 1,2 milhão), separando palavras de Lord Bytes (Ministro da Inovação) Reino Unido) e uma sessão de pôsteres para a qual não há mais força. Nós devemos nos preparar para amanhã.