Acredita-se que o desenvolvimento leva cerca de 10% do tempo e a depuração, 90%. Talvez essa declaração seja exagerada, mas qualquer desenvolvedor concorda que a depuração é um processo extremamente intensivo em recursos, especialmente em grandes sistemas multithread.
Assim, a otimização e sistematização do processo de depuração pode trazer benefícios significativos na forma de horas de trabalho salvas, aumentando a velocidade da resolução de problemas e, finalmente, aumentando a lealdade de seus usuários.
 Sergey Shchegrikovich
Sergey Shchegrikovich (dotmailer) na conferência
DotNext 2018 Piter sugeriu considerar a depuração como um processo que pode ser descrito e otimizado. Se você ainda não tem um plano claro para encontrar bugs - abaixo da transcrição em vídeo e texto do relatório de Sergey.
(E no final da postagem, adicionamos
o apelo de
John Skeet a todos os afiliados, não deixe de conferir)
Meu objetivo é responder à pergunta: como corrigir erros de forma eficiente e qual deve ser o foco. Eu acho que a resposta para esta pergunta é um processo. O processo de depuração, que consiste em regras muito simples, e você as conhece bem, mas provavelmente o usa sem saber. Portanto, minha tarefa é sistematizá-los e mostrar como se tornar mais eficaz usando um exemplo.
Vamos desenvolver uma linguagem comum para comunicação durante a depuração e também veremos um caminho direto para encontrar os principais problemas. Nos meus exemplos, mostrarei o que aconteceu devido a uma violação dessas regras.
Utilitários de depuração
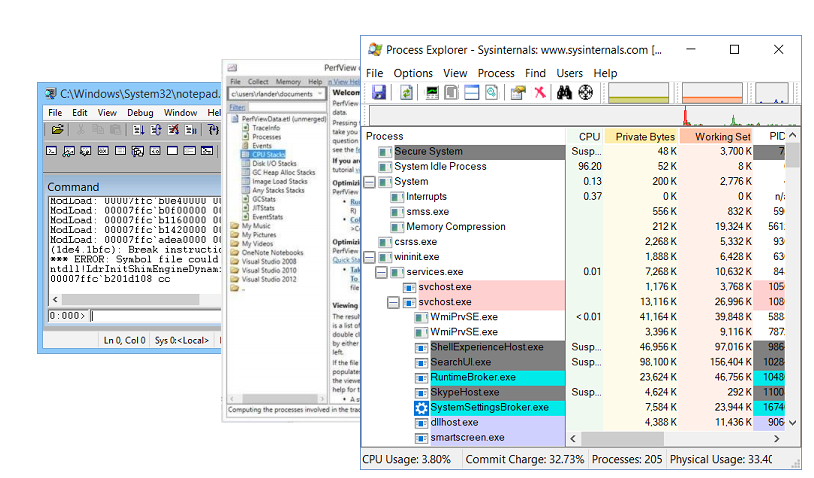
Obviamente, qualquer depuração não é possível sem os utilitários de depuração. Meus favoritos são:
- O Windbg , que além do próprio depurador, possui uma funcionalidade rica para estudar despejos de memória. Um despejo de memória é uma fatia do estado de um processo. Nele você pode encontrar o valor dos campos de objetos, pilhas de chamadas, mas, infelizmente, o despejo de memória é estático.
- O PerfView é um profiler escrito sobre a tecnologia ETW .
- Sysinternals é um utilitário escrito por Mark Russinovich , que permite que você mergulhe um pouco mais no dispositivo do sistema operacional.
Serviço em queda
Vamos começar com um exemplo da minha vida em que mostrarei como a natureza não sistemática do processo de depuração leva à ineficiência.
Provavelmente, isso aconteceu com todo mundo, quando você chega a uma nova empresa em uma nova equipe para um novo projeto e, desde o primeiro dia, deseja obter benefícios irreparáveis. Então foi comigo. Naquela época, tínhamos um serviço que recebia html para entrada e imagens de saída para saída.
O serviço foi escrito em .Net 3.0 e foi há muito tempo. Este serviço tinha um pequeno recurso - travou. Caiu frequentemente, cerca de uma vez a cada duas a três horas. Corrigimos essas propriedades de reinicialização elegantemente definidas nas propriedades do serviço após a queda.
O serviço não foi crítico para nós e pudemos sobreviver. Mas entrei para o projeto e a primeira coisa que decidi fazer foi corrigi-lo.
Para onde vão os desenvolvedores do .NET se algo não funcionar? Eles vão para o EventViewer. Mas lá não encontrei nada, exceto o registro de que o serviço caiu. Não houve mensagens sobre o erro nativo nem uma pilha de chamadas.
Existe uma ferramenta comprovada para o que fazer a seguir - envolvemos todo o
main no
try-catch .
try { ProcessRequest(); } catch (Exception ex) { LogError(ex); }
A idéia é simples: o
try-catch funcionará, nos incomodará, vamos ler e corrigir o serviço. Nós compilamos, implantamos na produção, o serviço trava, não há erro. Adicione outra
catch .
try { ProcessRequest(); } catch (Exception ex) { LogError(ex); } catch { LogError(); }
Repetimos o processo: o serviço trava, não há erros nos logs. A última coisa que pode ajudar é
finally , que é sempre chamada.
try { ProcessRequest(); } catch (Exception ex) { LogError(ex); } catch { LogError(); } finally { LogEndOfExecution(); }
Compilamos, implantamos, o serviço falha, não há erros. Três dias se passaram atrás desse processo, agora já estão chegando os pensamentos de que devemos finalmente começar a pensar e fazer outra coisa. Você pode fazer muitas coisas: tente reproduzir o erro na máquina local, assista a despejos de memória etc. Pareceu mais dois dias e vou corrigir esse bug ...
Duas semanas se passaram.
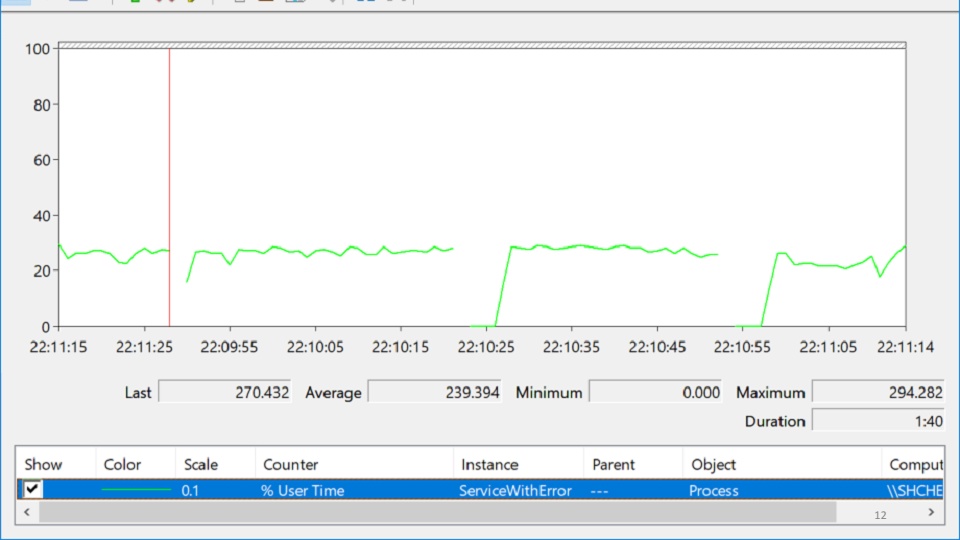
Procurei no PerformanceMonitor, onde vi um serviço que trava, depois sobe e cai novamente. Essa condição é chamada
desespero e fica assim:
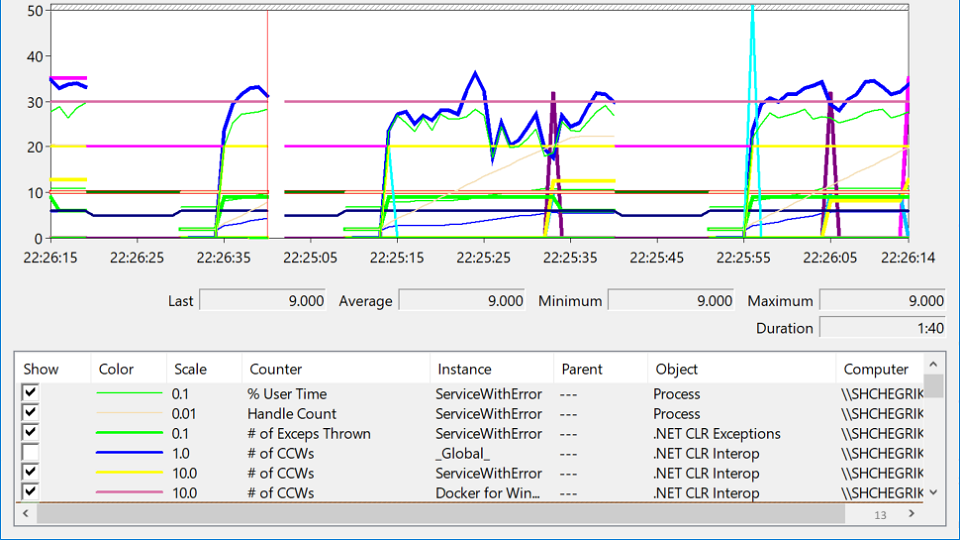
Nesta variedade de rótulos, você está tentando descobrir onde realmente está o problema? Após várias horas de meditação, o problema aparece repentinamente:
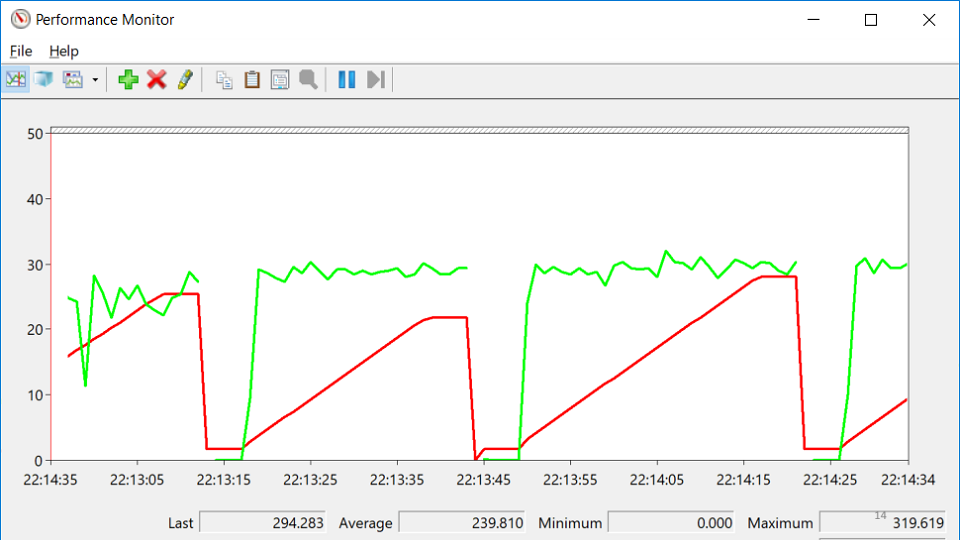
A linha vermelha é o número de identificadores nativos que o processo possui. Um identificador nativo é uma referência a um recurso do sistema operacional: arquivo, registro, chave do registro, mutex, etc. Para alguma estranha combinação de circunstâncias, a queda no crescimento do número de identificadores coincide com os momentos em que o serviço caiu. Isso leva à idéia de que em algum lugar há um vazamento de alças.
Tomamos um despejo de memória, abri-lo no WinDbg. Começamos a executar comandos. Vamos tentar ver a fila de finalização desses objetos que devem ser liberados pelo aplicativo.
0:000> !FinalizeQueue
No final da lista, encontrei um navegador da web.
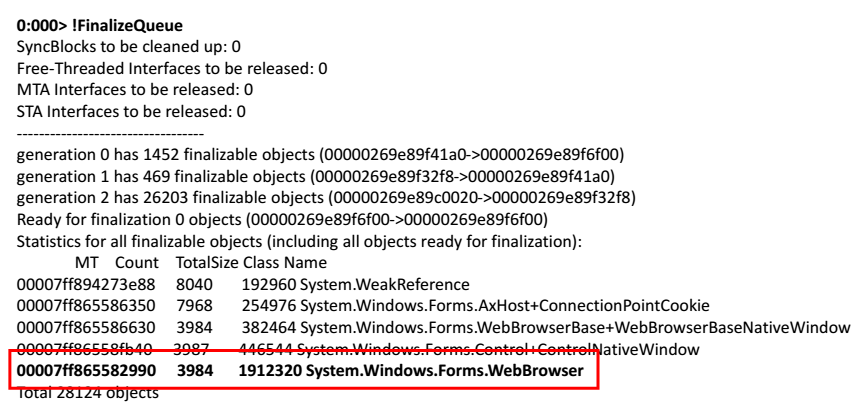
A solução é simples - pegue o WebBrowser e ligue para
dispose -lo:
private void Process() { using (var webBrowser = new WebBrowser()) {
As conclusões desta história podem ser tiradas da seguinte forma: duas semanas são longas e longas demais para encontrar um
dispose não convidado; que encontramos uma solução para o problema - sorte, uma vez que não havia uma abordagem específica, não havia uma natureza sistemática.
Depois disso, tive uma pergunta: como estrear efetivamente e o que fazer?
Para fazer isso, você precisa saber apenas três coisas:
- Regras de depuração
- Algoritmo para encontrar erros.
- Técnicas de depuração proativas.
Regras de depuração
- Repita o erro.
- Se você não tiver corrigido o erro, ele não será corrigido.
- Entenda o sistema.
- Verifique a ficha.
- Divida e conquiste.
- Refresque-se.
- Este é o seu erro.
- Cinco porque.
Essas são regras bem claras que se descrevem.
Repita o erro. Uma regra muito simples, porque se você não cometer um erro, não há nada a corrigir. Mas existem casos diferentes, especialmente para erros em um ambiente multithread. De alguma forma, tivemos um erro que apareceu apenas nos processadores Itanium e apenas nos servidores de produção. Portanto, a primeira tarefa no processo de depuração é encontrar uma configuração do banco de testes no qual o erro seria reproduzido.
Se você não tiver corrigido o erro, ele não será corrigido. Às vezes isso acontece: um rastreador de erros contém um erro que apareceu há meio ano, ninguém o vê há muito tempo e existe um desejo de simplesmente fechá-lo. Mas, neste momento, perdemos a chance de saber, a chance de entender como nosso sistema funciona e o que realmente acontece com ele. Portanto, qualquer bug é uma nova oportunidade para aprender algo, aprender mais sobre o seu sistema.
Entenda o sistema. Brian Kernighan disse uma vez que se éramos tão inteligentes ao escrever esse sistema, precisamos ser duplamente inteligentes para lançá-lo.
Um pequeno exemplo para a regra. Nosso monitoramento desenha gráficos:
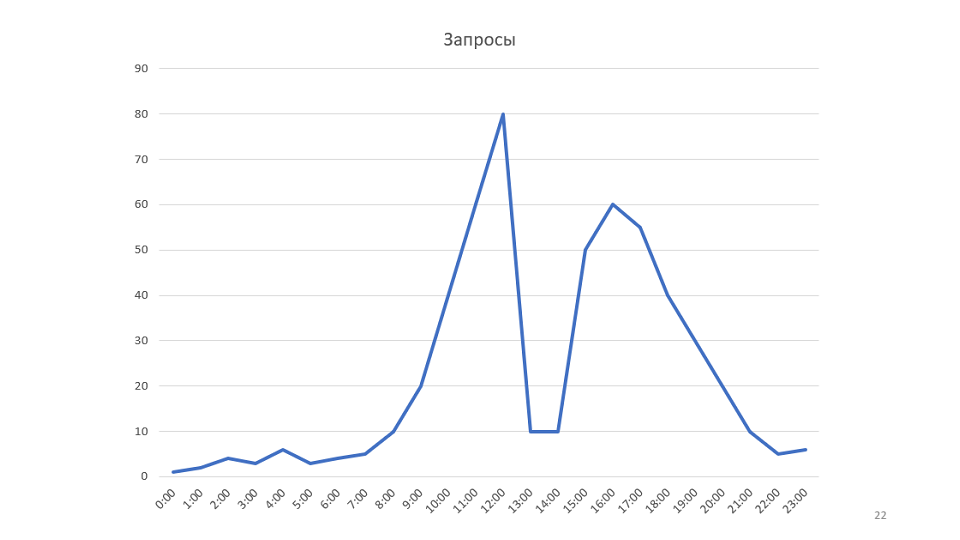
Este é um gráfico do número de solicitações processadas por nosso serviço. Depois de analisá-lo, tivemos a ideia de que seria possível aumentar a velocidade do serviço. Nesse caso, a programação aumenta, pode ser possível reduzir o número de servidores.
A otimização do desempenho da Web é feita de forma simples: pegamos o PerfView, executamos na máquina de produção, removemos o rastreio dentro de 3-4 minutos, levamos esse rastreio para a máquina local e começamos a estudá-lo.
Uma das estatísticas que o PerfView mostra é o coletor de lixo.
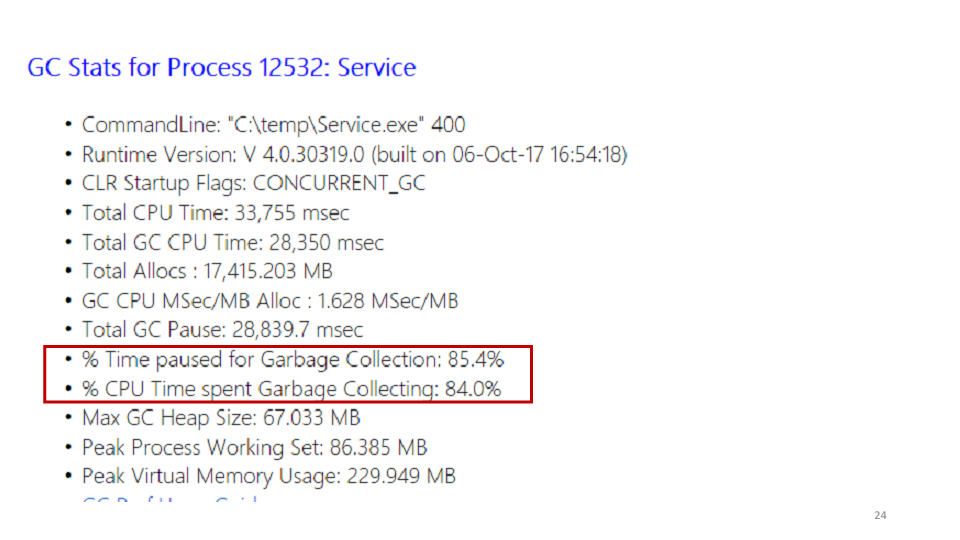
Observando essas estatísticas, vimos que o serviço gasta 85% de seu tempo coletando lixo. Você pode ver no PerfView exatamente onde esse tempo é gasto.
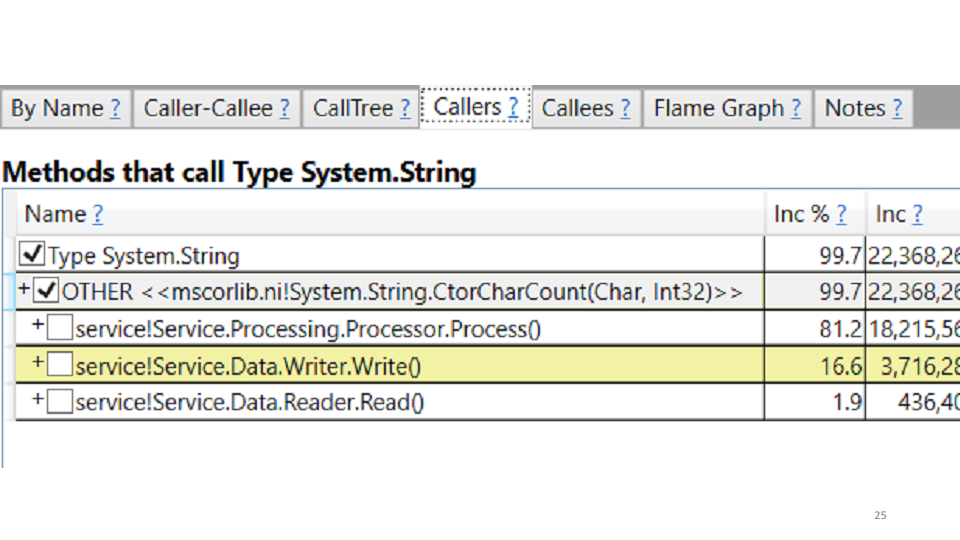
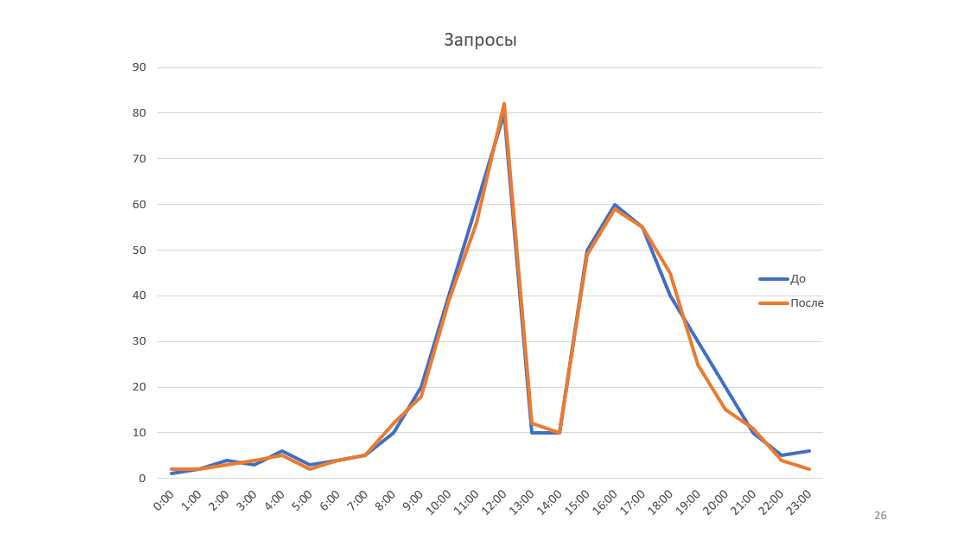
No nosso caso, isso está criando cadeias. A correção propriamente dita se sugere: substituímos todas as strings por StringBuilders. Localmente, obtemos um aumento de produtividade de 20 a 30%. Implante na produção, veja os resultados em comparação com o cronograma antigo:
A regra "Compreender o sistema" não é apenas entender como as interações estão acontecendo no sistema, como as mensagens são, mas tentar modelar o sistema.
No exemplo, o gráfico mostra a largura de banda. Mas se você observar todo o sistema do ponto de vista da teoria das filas, a taxa de transferência de nosso sistema depende de apenas um parâmetro - a velocidade de chegada de novas mensagens. De fato, o sistema simplesmente não possuía mais de 80 mensagens por vez, portanto não há como otimizar esse agendamento.
Verifique a ficha. Se você abrir a documentação de qualquer eletrodoméstico, ela definitivamente será escrita: se o aparelho não funcionar, verifique se o plugue está inserido na tomada. Depois de várias horas no depurador, muitas vezes me pego pensando que só precisava recompilar ou simplesmente pegar a versão mais recente.
A regra "verifique o plugue" é sobre fatos e dados. A depuração não inicia executando o WinDbg ou PerfView nas máquinas de produção, mas começa verificando fatos e dados. Se o serviço não estiver respondendo, talvez ele não esteja sendo executado.
Divida e conquiste. Esta é a primeira e provavelmente a única regra que inclui a depuração como um processo. Trata-se de hipóteses, sua promoção e teste.
Um de nossos serviços não queria parar.
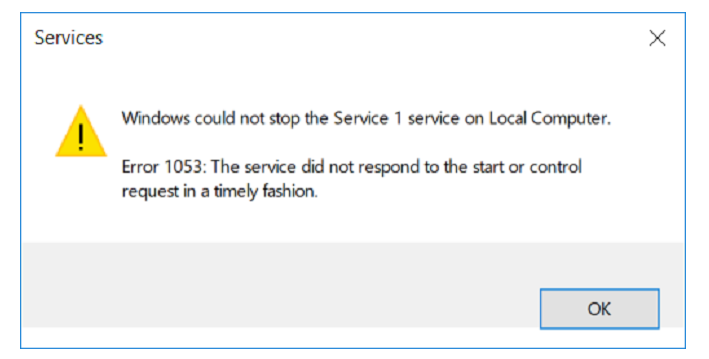
Nós fazemos uma hipótese: talvez exista um ciclo no projeto que processe algo sem fim.
Você pode testar a hipótese de maneiras diferentes, uma opção é fazer um despejo de memória.
~*e!ClrStack pilhas de chamadas do despejo e de todos os threads usando o
~*e!ClrStack . Começamos a olhar e ver três fluxos.
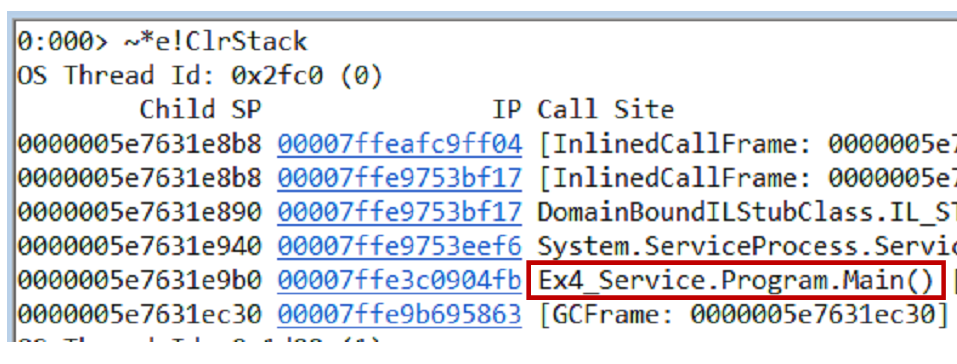
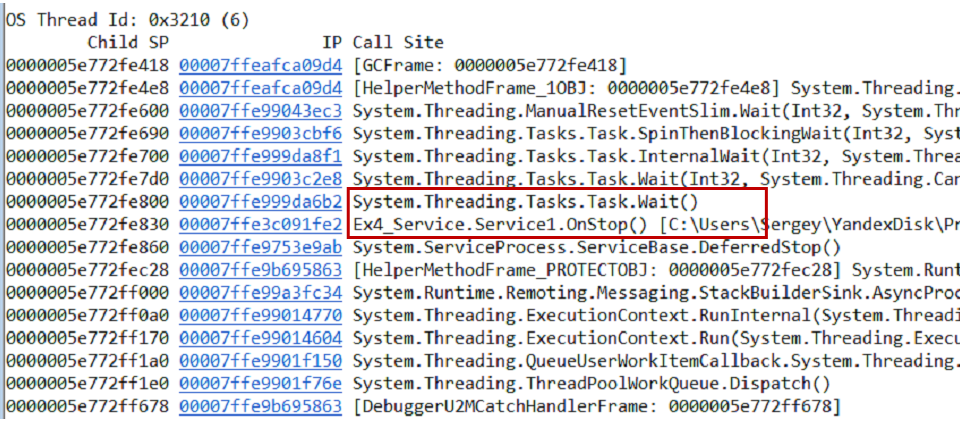
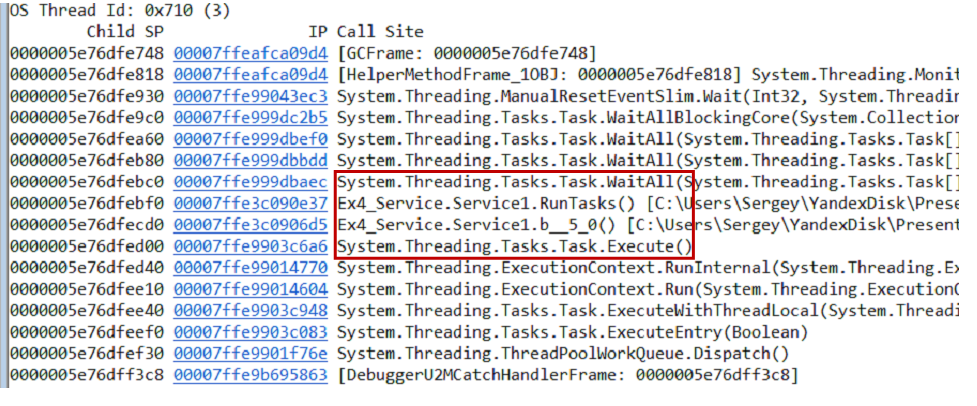
O primeiro thread está em Main, o segundo está no manipulador
OnStop() e o terceiro thread estava aguardando algumas tarefas internas. Assim, nossa hipótese não se justifica. Não há loop, todos os threads estão esperando por algo. Provavelmente impasse.
Nosso serviço funciona da seguinte maneira. Existem duas tarefas - inicialização e trabalho. A inicialização abre uma conexão com o banco de dados, o trabalhador começa a processar os dados. A comunicação entre eles ocorre através de um sinalizador comum, que é implementado usando
TaskCompletionSource .
Criamos a segunda hipótese: talvez tenhamos um impasse de uma tarefa para a segunda. Para verificar isso, você pode ver cada tarefa separadamente através do WinDbg.
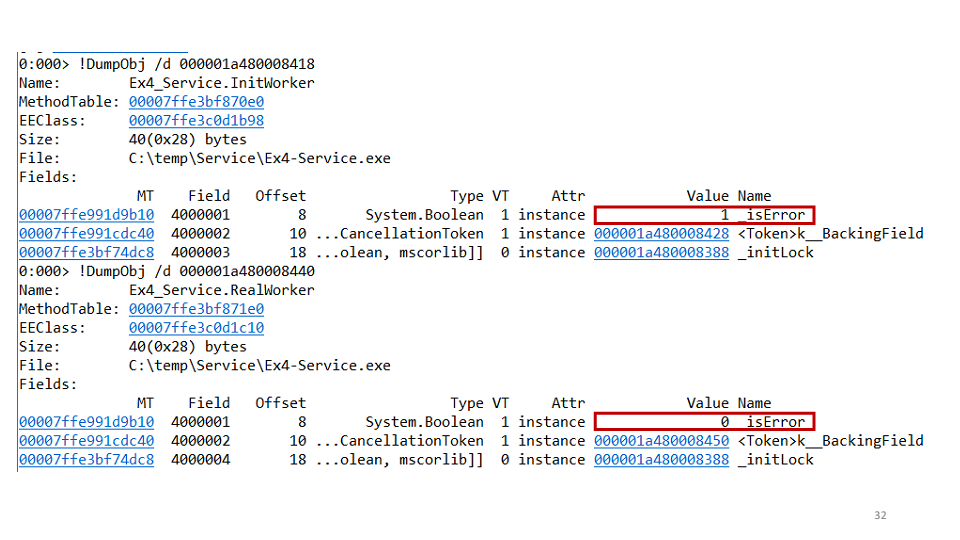
Acontece que uma das tarefas caiu e a segunda não. No projeto, vimos o seguinte código:
await openAsync(); _initLock.SetResult(true);
Isso significa que a tarefa de inicialização abre a conexão e, em seguida, define
TaskCompletionSource como true. Mas e se uma exceção cair aqui? Como não temos tempo para definir
SetResult como true, a correção desse bug foi assim:
try { await openAsync(); _initLock.SetResult(true); } catch(Exception ex) { _initLock.SetException(ex); }
Neste exemplo, apresentamos duas hipóteses: o loop infinito e o impasse. A regra "dividir e conquistar" ajuda a localizar o erro. Aproximações sucessivas resolvem esses problemas.
O mais importante nessa regra são hipóteses, porque com o tempo elas se transformam em padrões. E, dependendo da hipótese, usamos ações diferentes.
Refresque-se. Essa regra é que você só precisa se levantar da mesa e caminhar, beber água, suco ou café, fazer qualquer coisa, mas a coisa mais importante é se distrair do seu problema.
Existe um método muito bom chamado pato. De acordo com o método, devemos falar sobre o problema de se
esquivar . Você pode usar um colega como um
pato . Além disso, ele não precisa responder, apenas ouvir e concordar. E, muitas vezes, após a primeira conversa sobre o problema, você mesmo encontra uma solução.
Este é o seu erro. Vou contar sobre esta regra por um exemplo.
Houve um problema em uma
AccessViolationException . Olhando na pilha de chamadas, vi que ocorreu quando geramos a consulta LinqToSql dentro do cliente sql.

A partir desse bug, ficou claro que em algum lugar a integridade da memória é violada. Felizmente, naquela época, já usamos o sistema de gerenciamento de alterações. Como resultado, após algumas horas, ficou claro o que aconteceu: instalamos o .Net 4.5.2 em nossas máquinas de produção.
Assim, enviamos o bug para a Microsoft, eles o examinam, nos comunicamos com eles, eles corrigem o bug no .Net 4.6.1.
Para mim, isso resultou em 11 meses de trabalho com o suporte da Microsoft, é claro, não todos os dias, mas levou 11 meses desde o início para ser corrigido. Além disso, enviamos dezenas de gigabytes de despejos de memória, colocamos centenas de assemblies particulares para detectar esse erro. E durante todo esse tempo, não podíamos dizer aos nossos clientes que a Microsoft era a culpada, não a nós. Portanto, o bug é sempre seu.
Cinco porque. Nós da nossa empresa usamos o Elastic. Elastic é bom para agregação de logs.
Você vem trabalhar de manhã, e Elastic mente.
A primeira pergunta é por que o Elastic? Quase imediatamente ficou claro - os nós principais caíram. Eles coordenam o trabalho de todo o cluster e, quando caem, o cluster inteiro deixa de responder. Por que eles não se levantaram? Talvez deva haver um arranque automático? Depois de procurar a resposta, descobrimos que a versão do plugin não corresponde. Por que os nós mestres caíram? Eles foram mortos pelo OOM Killer. Isso é algo que ocorre nas máquinas Linux, que, em caso de falta de memória, fecha processos desnecessários. Por que não há memória suficiente? Porque o processo de atualização foi iniciado, que segue os logs do sistema. Por que funcionou antes, mas não agora? E como adicionamos novos nós uma semana antes, os nós principais precisavam de mais memória para armazenar índices e configurações de cluster.
As perguntas "por quê?" ajudar a encontrar a raiz do problema. No exemplo, podemos desativar o caminho certo várias vezes, mas a correção completa é assim: atualize o plug-in, inicie serviços, aumente a memória e anote o futuro; na próxima vez em que adicionar novos nós ao cluster, será necessário garantir que a memória no Master seja suficiente Nós
A aplicação dessas regras permite revelar problemas reais, muda seu foco para a solução desses problemas e ajuda a se comunicar. Mas seria ainda melhor se essas regras formassem um sistema. E existe esse sistema, chamado de algoritmo de depuração.
Algoritmo de depuração
Pela primeira vez, li sobre o algoritmo de depuração no livro Debugging Applications de John Robbins. Ele descreve o processo de depuração da seguinte maneira:
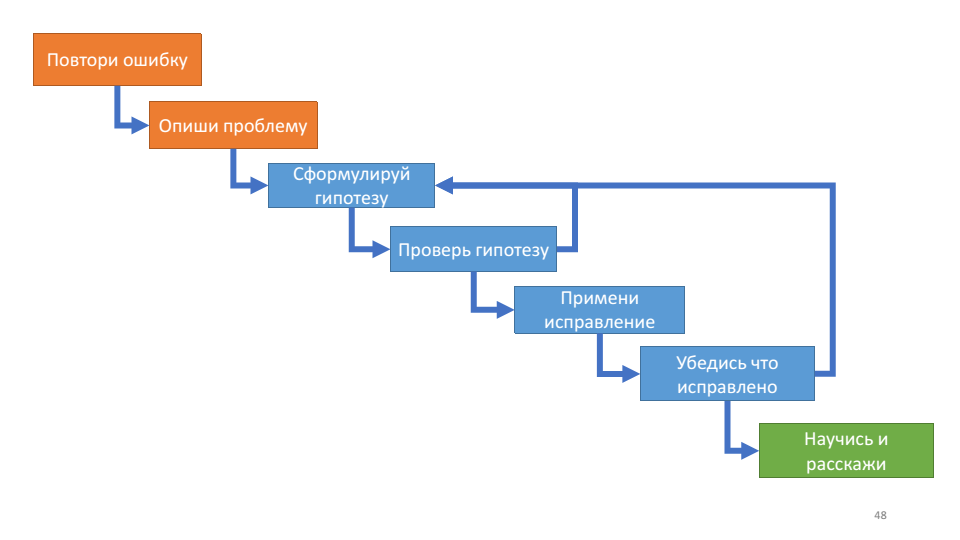
Este algoritmo é útil para seu loop interno - trabalhando com uma hipótese.
A cada volta do ciclo, podemos nos controlar: sabemos mais sobre o sistema ou não? Se apresentarmos hipóteses, verifique, elas não funcionam, não aprendemos nada de novo sobre a operação do sistema, provavelmente é hora de refrescar-nos. Duas perguntas atuais neste momento: quais hipóteses você testou e qual hipótese você está testando agora.
Esse algoritmo concorda muito bem com as regras de depuração de que falamos acima: repita o erro - este é o seu erro, descreva o problema - entenda o sistema, formule uma hipótese - divida e conquiste, teste a hipótese - verifique o plug, verifique se está consertado - cinco por que.
Eu tenho um bom exemplo para este algoritmo. Uma exceção ocorreu em um de nossos serviços da web.
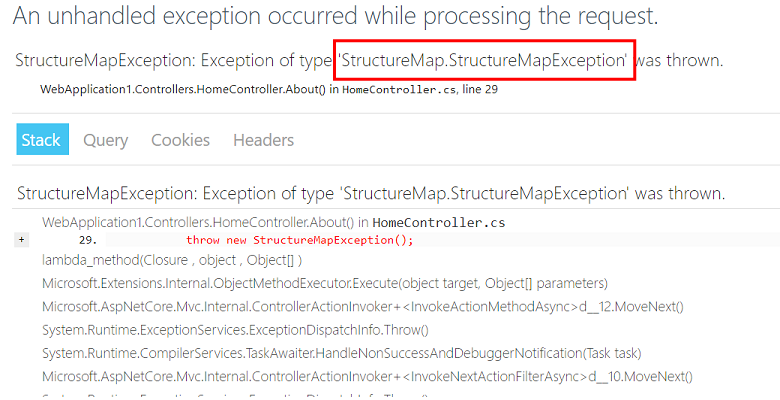
Nosso primeiro pensamento não é nosso problema. Mas, de acordo com as regras, esse ainda é nosso problema.
Primeiro, repita o erro. Para cada mil solicitações, há aproximadamente uma
StructureMapException , para que possamos reproduzir o problema.
Em segundo lugar, estamos tentando descrever o problema: se o usuário fizer uma solicitação http para o nosso serviço no momento em que o StructureMap estiver tentando criar uma nova dependência, ocorrerá uma exceção.
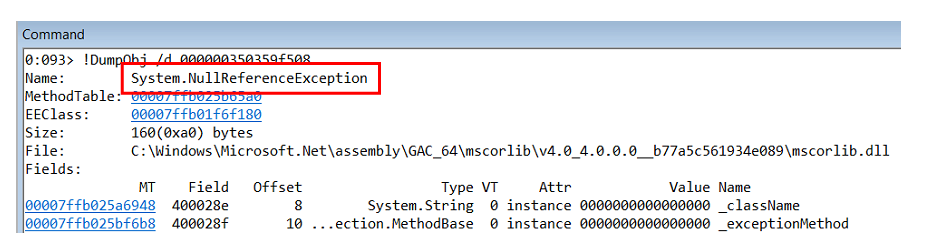
Em terceiro lugar, supomos que o StructureMap é um invólucro e existe algo dentro que gera uma exceção interna. Testamos a hipótese usando procdump.exe.
procdump.exe -ma -e -f StructureMap w3wp.exe
Acontece que dentro é uma
NullReferenceException .
Estudando a pilha de chamadas dessa exceção, entendemos que isso acontece dentro do construtor de objetos no próprio StructureMap.
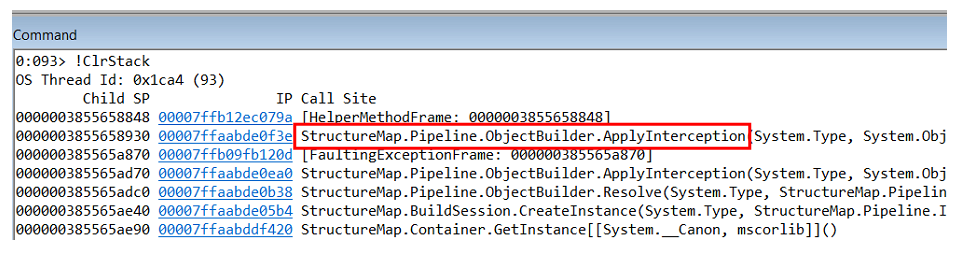
Mas
NullReferenceException não é o problema em si, mas a consequência. Você precisa entender onde isso ocorre e quem o gera.
Apresentamos a seguinte hipótese: por algum motivo, nosso código retorna uma dependência nula. Dado que no .Net todos os objetos na memória estão localizados um a um, se observarmos os objetos no heap que estão antes da
NullReferenceException , eles provavelmente apontarão para o código que lançou a exceção.
No WinDbg existe um comando - Listar objetos
!lno . Isso mostra que o objeto em que estamos interessados é a função lambda, que é usada no código a seguir.
public CompoundInterceptor FindInterceptor(Type type) { CompoundInterceptop interceptor; if (!_analyzedInterceptors.TryGetValue(type, out interceptor)) { lock (_locker) { if (!_analyzedInterceptors.TryGetValue(type, out interceptor)) { var interceptorArray = _interceptors.FindAll(i => i.MatchesType(type)); interceptor = new CompoundInterceptor(interceptorArray); _analyzedInterceptors.Add(type, interceptor); } } } return interceptor; }
Nesse código, primeiro verificamos se o valor no
Dictionary _analyzedInterceptors em
_analyzedInterceptors ; se não o encontrarmos, adicionamos um novo valor dentro do
lock .
Em teoria, esse código nunca pode retornar nulo. Mas o problema aqui está em
_analyzedInterceptors , que usa um
Dictionary regular em um ambiente com vários threads, não um
ConcurrentDictionary .
A raiz do problema foi encontrada, atualizamos para a versão mais recente do StructureMap, implantada, e garantimos que tudo estava corrigido. O último passo do nosso algoritmo é "aprender e contar". No nosso caso, foi uma pesquisa no código de todos os
Dictionary que são usados no bloqueio e verificação de que todos eles são usados corretamente.
Portanto, o algoritmo de depuração é um algoritmo intuitivo que economiza tempo significativamente. Ele se concentra na hipótese - e isso é a coisa mais importante na depuração.
Depuração proativa
Na sua essência, a depuração proativa responde à pergunta "o que acontece quando um bug aparece".
A importância das técnicas de depuração proativas pode ser vista no diagrama do ciclo de vida do bug.
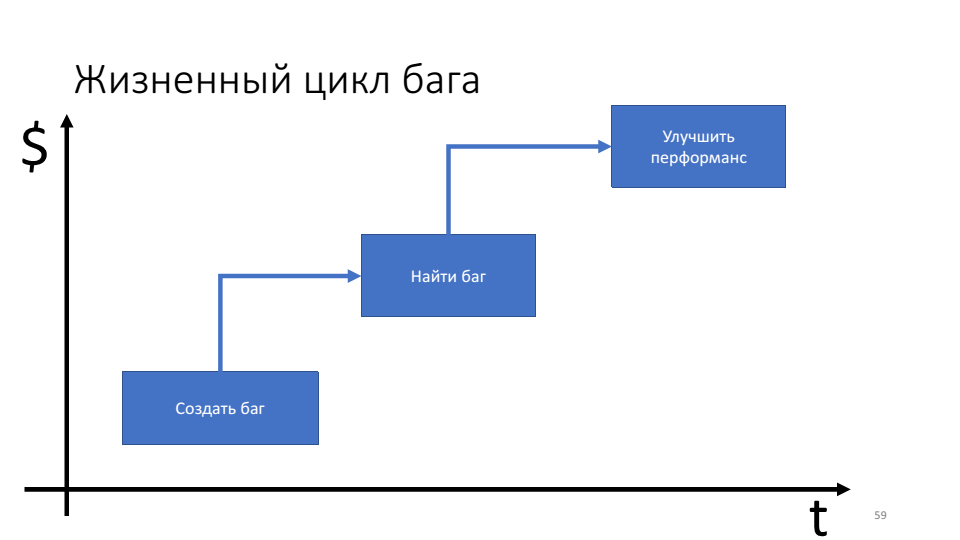
O problema é que quanto mais tempo o bug vive, mais recursos (tempo) gastamos nele.
As regras de depuração e o algoritmo de depuração nos concentram no momento em que o bug é encontrado e podemos descobrir o que fazer a seguir. De fato, queremos mudar nosso foco no momento em que o bug foi criado. Acredito que devemos fazer o Produto Mínimo Debugável (MDP), ou seja, um produto que possua o conjunto mínimo de infraestrutura necessário para uma depuração eficiente da produção.
O MDP consiste em duas coisas: função de condicionamento físico e método USE.
Recursos de fitness. Eles foram popularizados por Neil Ford e co-autores no livro Building Evolutionary Architectures. Na essência, as funções de condicionamento físico, de acordo com os autores do livro, têm a seguinte aparência: existe uma arquitetura de aplicativo que podemos cortar em ângulos diferentes, obtendo propriedades arquitetônicas como capacidade de
manutenção ,
desempenho etc. e, para cada seção, devemos escrever um teste - condicionamento físico -função. Assim, uma função de condicionamento físico é um teste de arquitetura.
No caso do MDP, a função de adequação é um teste de depuração. Você pode usar o que quiser para escrever esses testes: NUnit, MSTest e assim por diante. Porém, como a depuração geralmente funciona com ferramentas externas, demonstrarei o uso do Pester (estrutura de teste de unidade do powershell) como exemplo. Sua vantagem aqui é que ele funciona bem com a linha de comando.
Por exemplo, dentro da empresa, concordamos que usaremos bibliotecas específicas para o log; ao registrar, usaremos padrões específicos; caracteres pdb sempre devem ser dados ao servidor de símbolos. Essas serão as convenções que testaremos em nossos testes.
Describe 'Debuggability' { It 'Contains line numbers in PDBs' { Get-ChildItem -Path . -Recurse -Include @("*.exe", "*. dll ") ` | ForEach-Object { &symchk.exe /v "$_" /s "\\network\" *>&1 } ` | Where-Object { $_ -like "*Line nubmers: TRUE*" } ` | Should -Not –BeNullOrEmpty } }
Este teste verifica se todos os caracteres pdb foram fornecidos ao servidor de símbolos e foram dados corretamente, ou seja, aqueles que contêm números de linhas no interior. Para fazer isso, pegamos a versão compilada da produção, localizamos todos os arquivos exe e dll, passamos todos esses binários pelo utilitário syschk.exe, que está incluído no pacote de ferramentas de depuração do Windows. O utilitário syschk.exe verifica o binário com o servidor de símbolos e, se encontrar um arquivo pdb, imprime um relatório sobre ele. No relatório, procuramos a linha "Números de linha: VERDADEIRO". E na final, verificamos que o resultado não é "nulo ou vazio".
Esses testes devem ser integrados a um pipeline de implantação contínua. Após os testes de integração e os testes de unidade, as funções de condicionamento físico são iniciadas.
Vou mostrar mais um exemplo com a verificação das bibliotecas necessárias no código.
Describe 'Debuggability' { It 'Contains package for logging' { Get-ChildItem -Path . -Recurse -Name "packages.config" ` | ForEach-Object { Get-Content "$_" } ` | Where-Object { $_ -like "*nlog*" } ` | Should -Not –BeNullOrEmpty } }
No teste, pegamos todos os arquivos packages.config e tentamos encontrar as bibliotecas nlog neles. Da mesma forma, podemos verificar se o campo de identificação de correlação é usado dentro do campo nlog.
Métodos de USE. A última coisa que o MDP consiste são as métricas que você precisa coletar.
Vou demonstrar pelo exemplo do método USE, que foi popularizado por Brendan Gregg. : - , : utilization (), saturation (), errors (), .
, Circonus ( monitoring soft),
.
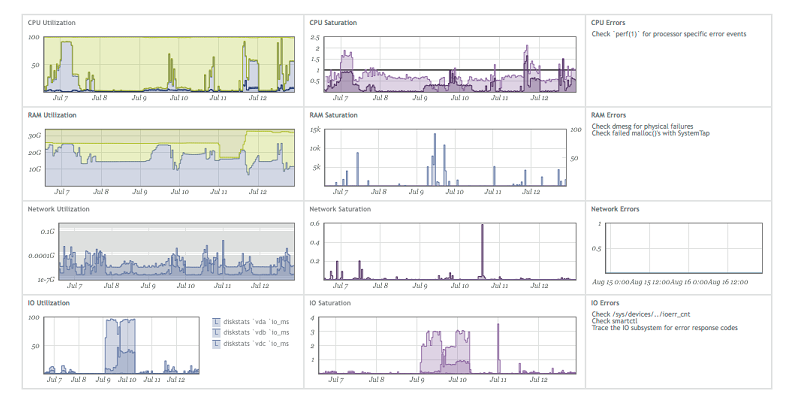
, , , — , — , — , . , USE- .
- -, , , :
, . , .
, , — . , , 4-5% CPU.
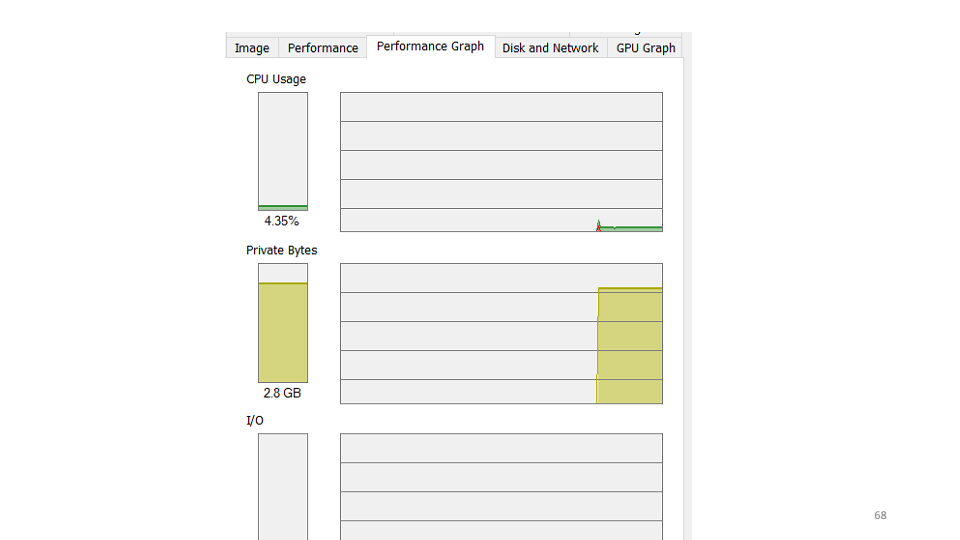
— , . etrace.
etrace --kernel Process ^ --where ProcessName=Ex5-Service ^ --clr Exception
realtime ETW-events .
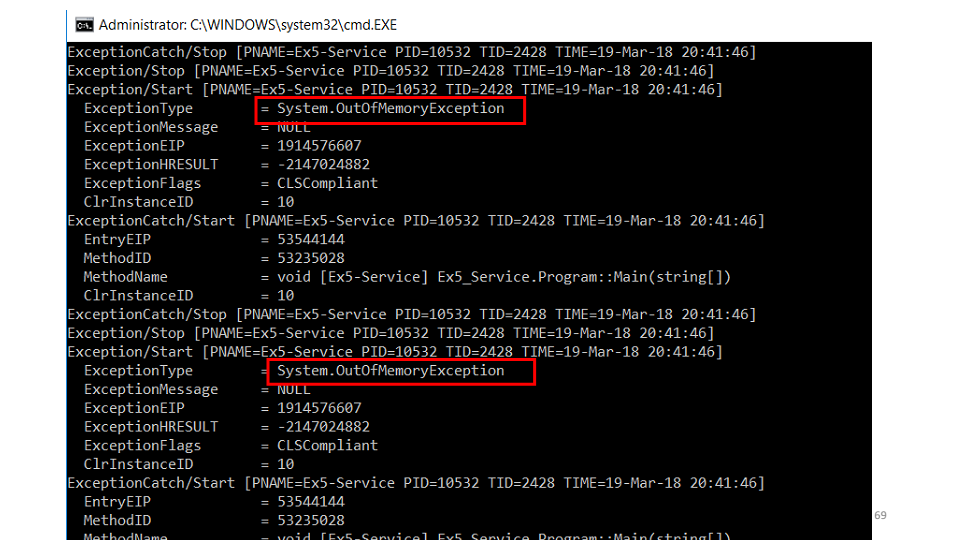
,
OutOfMemoryException . , , ? — , , .
while (ShouldContinue()) { try { Do(); } catch (OutOfMemoryException) { Thread.Sleep(100); GC.CollectionCount(2); GC.WaitForPendingFinalizers(); } }
— - . , .
public class Cache { private static ConcurrentDictionary<int, String> _items = new ... private static DateTime _nextClearTime = DateTime.UtcNow; public String GetFromCache(int key) { if (_nextClearTime < DateTime.UtcNow) { _nextClearTime = DateTime.UtcNow.AddHours(1); _items.Clear(); } return _items[key]; } }
, . , . USE .
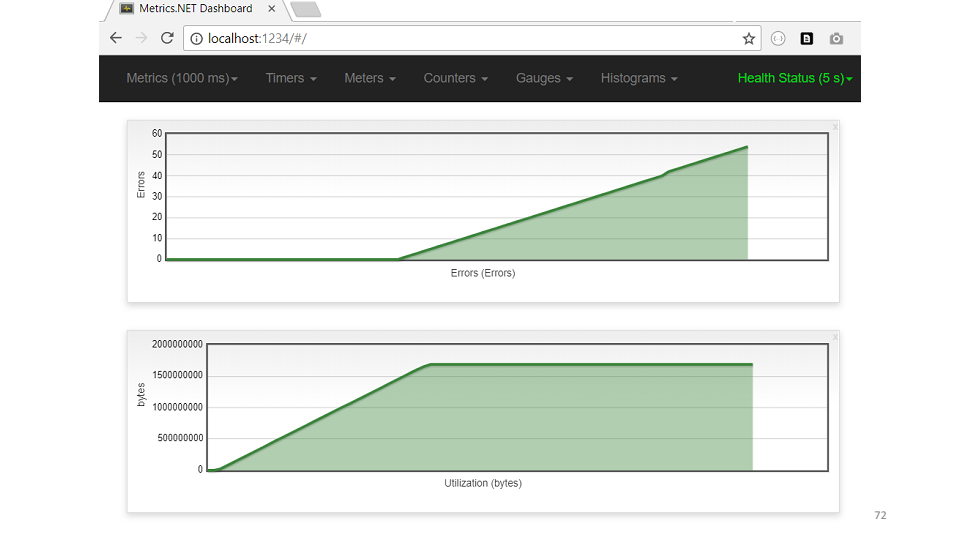
— , .
, , .
- — . , , — . — , -. , .
- . ; Exception , , - .
- Minimum Debuggable Product — , .
, ?
- .
- .
- .
— Jon Skeet.
DotNext , ( ).