Nota perev. : O autor do artigo original, Nicolas Leiva, é um arquiteto de soluções da Cisco que decidiu compartilhar com seus colegas, engenheiros de rede, como a rede Kubernetes funciona por dentro. Para fazer isso, ele explora sua configuração mais simples no cluster, usando ativamente o bom senso, seu conhecimento de redes e utilitários padrão do Linux / Kubernetes. Ficou volumoso, mas muito claramente.
Além do fato de o guia
Kubernetes The Hard Way de Kelsey Hightower funcionar (
até na AWS! ), Eu gostei que a rede fosse mantida limpa e simples; e esta é uma ótima oportunidade para entender o papel, por exemplo, da
CNI (Container Network Interface). Dito isto, acrescentarei que a rede Kubernetes não é realmente muito intuitiva, especialmente para iniciantes ... e também não se esqueça de que “
simplesmente não existe uma rede de contêineres”.
Embora já existam bons materiais sobre esse tópico (veja os links
aqui ), não consegui encontrar um exemplo que combinasse tudo o necessário com as conclusões das equipes que os engenheiros de rede amam e odeiam, demonstrando o que realmente está acontecendo nos bastidores. Portanto, decidi coletar informações de várias fontes - espero que isso ajude e você entenda melhor como tudo está conectado. Esse conhecimento é importante não apenas para testar a si mesmo, mas também para simplificar o processo de diagnóstico de problemas. Você pode seguir o exemplo em seu cluster no
Kubernetes The Hard Way : todos os endereços IP e configurações são obtidos de lá (a partir das confirmações de maio de 2018, antes de usar os
contêineres Nabla ).
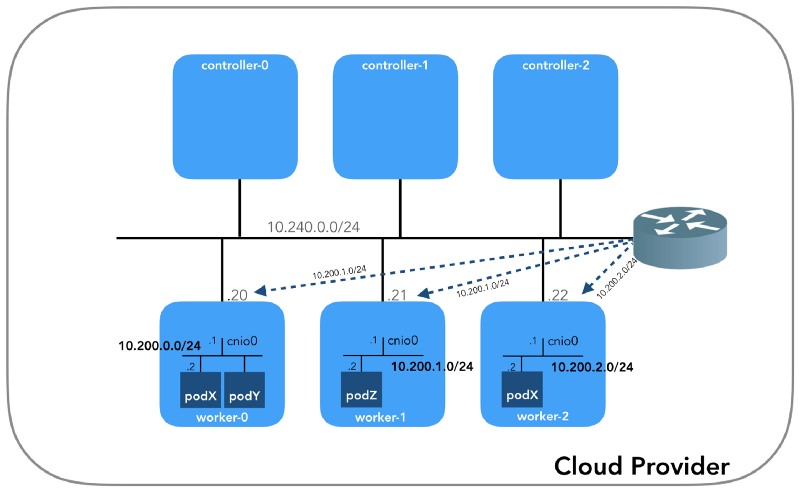
E começaremos do final, quando tivermos três controladores e três nós de trabalho:
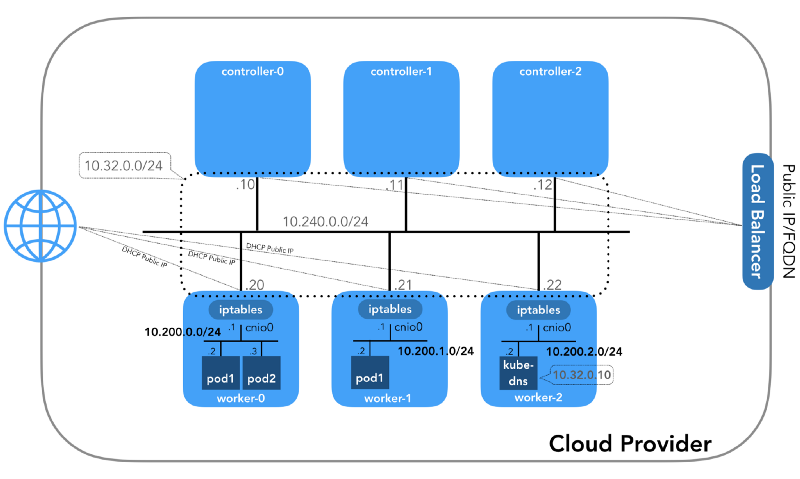
Você pode perceber que também há pelo menos três sub-redes privadas aqui! Um pouco de paciência, e todos serão considerados. Lembre-se de que, apesar de nos referirmos a prefixos IP muito específicos, eles são simplesmente retirados do
Kubernetes The Hard Way , portanto, eles têm apenas significado local e você pode escolher qualquer outro bloco de endereço para o seu ambiente, de acordo com a
RFC 1918 . Para o caso do IPv6, haverá um artigo de blog separado.
Rede do host (10.240.0.0/24)
Essa é uma rede interna da qual todos os nós fazem parte. Definido pelo
--private-network-ip no
GCP ou pela opção
--private-ip-address na
AWS ao alocar recursos de computação.
Inicializando nós do controlador no GCP
for i in 0 1 2; do gcloud compute instances create controller-${i} \
(
controllers_gcp.sh )
Inicializando nós do controlador na AWS
for i in 0 1 2; do declare controller_id${i}=`aws ec2 run-instances \
(
controllers_aws.sh )
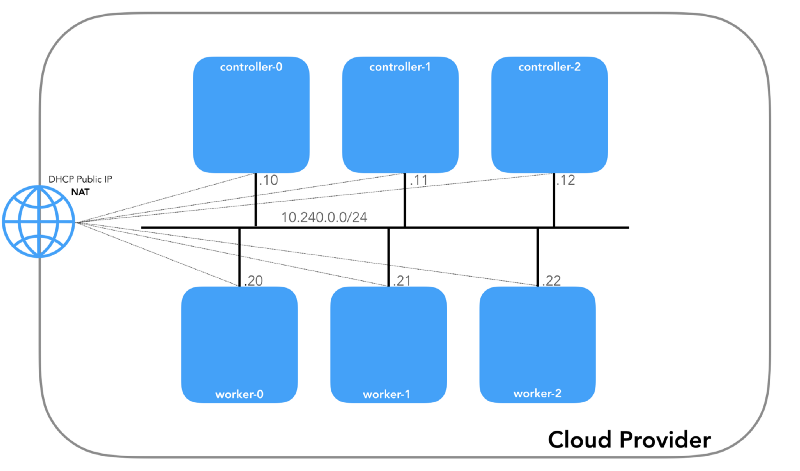
Cada instância terá dois endereços IP: privado da rede host (controladores -
10.240.0.1${i}/24 , trabalhadores -
10.240.0.2${i}/24 ) e um público, nomeado pelo provedor de nuvem, sobre o qual falaremos mais adiante como chegar ao
NodePorts .
Gcp
$ gcloud compute instances list NAME ZONE MACHINE_TYPE PREEMPTIBLE INTERNAL_IP EXTERNAL_IP STATUS controller-0 us-west1-c n1-standard-1 10.240.0.10 35.231.XXX.XXX RUNNING worker-1 us-west1-c n1-standard-1 10.240.0.21 35.231.XX.XXX RUNNING ...
Aws
$ aws ec2 describe-instances --query 'Reservations[].Instances[].[Tags[?Key==`Name`].Value[],PrivateIpAddress,PublicIpAddress]' --output text | sed '$!N;s/\n/ /' 10.240.0.10 34.228.XX.XXX controller-0 10.240.0.21 34.173.XXX.XX worker-1 ...
Todos os nós devem poder executar ping se as
políticas de segurança estiverem corretas (e se o
ping instalado no host).
Rede da lareira (10.200.0.0/16)
Essa é a rede na qual os pods vivem. Cada nó de trabalho usa uma sub-rede desta rede. No nosso caso,
POD_CIDR=10.200.${i}.0/24 para o
worker-${i} .
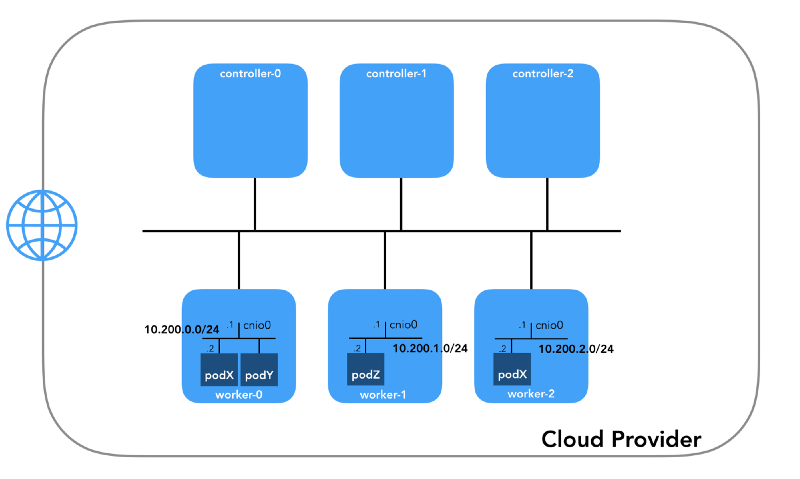
Para entender como tudo está configurado, dê um passo para trás e observe
o modelo de rede Kubernetes , que requer o seguinte:
- Todos os contêineres podem se comunicar com outros contêineres sem usar o NAT.
- Todos os nós podem se comunicar com todos os contêineres (e vice-versa) sem usar o NAT.
- O IP que o contêiner vê deve ser o mesmo que os outros o veem.
Tudo isso pode ser implementado de várias maneiras, e o Kubernetes passa a configuração de rede para o
plugin CNI .
“O plugin CNI é responsável por adicionar uma interface de rede ao namespace de rede do contêiner (por exemplo, uma extremidade de um par veth ) e fazer as alterações necessárias no host (por exemplo, conectar a segunda extremidade do veth a uma ponte). Depois, ele deve atribuir uma interface IP e configurar as rotas de acordo com a seção Gerenciamento de endereço IP, chamando o plug-in IPAM desejado. ” (da especificação de interface de rede de contêiner )
Namespace de rede
“O espaço para nome agrupa o recurso global do sistema em uma abstração que é visível aos processos nesse espaço para nome, de forma que eles tenham sua própria instância isolada do recurso global. Alterações no recurso global são visíveis para outros processos incluídos neste espaço para nome, mas não são visíveis para outros processos. ” ( na página do manual namespaces )
O Linux fornece sete namespaces diferentes (
Cgroup ,
IPC ,
Network ,
Mount ,
PID ,
User ,
UTS ). Os espaços para nome da rede (
CLONE_NEWNET ) definem os recursos de rede disponíveis para o processo: "Cada espaço para nome da rede possui seus próprios dispositivos de rede, endereços IP, tabelas de roteamento IP, diretório
/proc/net , números de porta e assim por diante"
( do artigo “ Namespaces in operation ”) .
Dispositivos Ethernet virtuais (Veth)
“Um par de rede virtual (veth) oferece uma abstração na forma de um“ canal ”, que pode ser usado para criar túneis entre namespaces de rede ou para criar uma ponte para um dispositivo de rede físico em outro espaço de rede. Quando o espaço para nome é liberado, todos os dispositivos veth nele são destruídos. ” (na página do manual namespaces de rede )
Vá para o chão e veja como tudo isso se relaciona com o cluster. Primeiro,
os plugins de rede no Kubernetes são diversos, e os plugins CNI são um deles (
por que não o CNM? ).
O Kubelet em cada nó informa ao
tempo de execução do contêiner qual
plug-in de rede usar. A interface de rede de contêiner (
CNI ) está entre o tempo de execução do contêiner e a implementação da rede. E o plugin CNI já configura a rede.
“O plugin CNI é selecionado passando a --network-plugin=cni linha de comando --network-plugin=cni cni para o Kubelet. O Kubelet lê o arquivo em --cni-conf-dir (o padrão é /etc/cni/net.d ) e usa a configuração CNI deste arquivo para configurar a rede para cada arquivo. " (a partir de Requisitos de plug-in de rede )
Os binários reais do plugin CNI estão em
-- cni-bin-dir (o padrão é
/opt/cni/bin ).
Observe que os
kubelet.service chamada
--network-plugin=cni incluem
--network-plugin=cni :
[Service] ExecStart=/usr/local/bin/kubelet \\ --config=/var/lib/kubelet/kubelet-config.yaml \\ --network-plugin=cni \\ ...
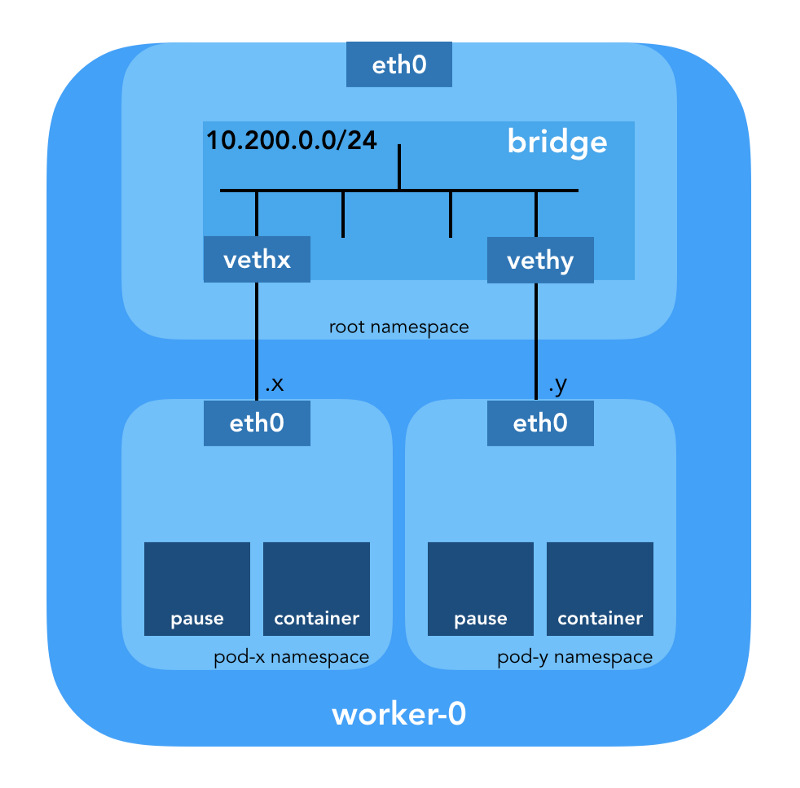
Primeiro de tudo, o Kubernetes cria um espaço para nome de rede para a lareira, mesmo antes de chamar qualquer plug-in. Isso é implementado usando o contêiner de
pause especial, que "serve como o" contêiner pai "para todos os contêineres da lareira"
(do artigo " O Contêiner Todo-Poderoso para Pausa ") . O Kubernetes então executa o plugin CNI para anexar o contêiner de
pause à rede. Todos os contêineres de pod usam o
netns desse contêiner de
pause .
{ "cniVersion": "0.3.1", "name": "bridge", "type": "bridge", "bridge": "cnio0", "isGateway": true, "ipMasq": true, "ipam": { "type": "host-local", "ranges": [ [{"subnet": "${POD_CIDR}"}] ], "routes": [{"dst": "0.0.0.0/0"}] } }
A
configuração CNI usada indica o uso do plug-in de
bridge para configurar a ponte do software Linux (L2) no espaço de nomes raiz chamado
cnio0 (o
nome padrão é
cni0 ), que atua como um gateway (
"isGateway": true ).

Um par veth também será configurado para conectar a lareira à ponte recém-criada:
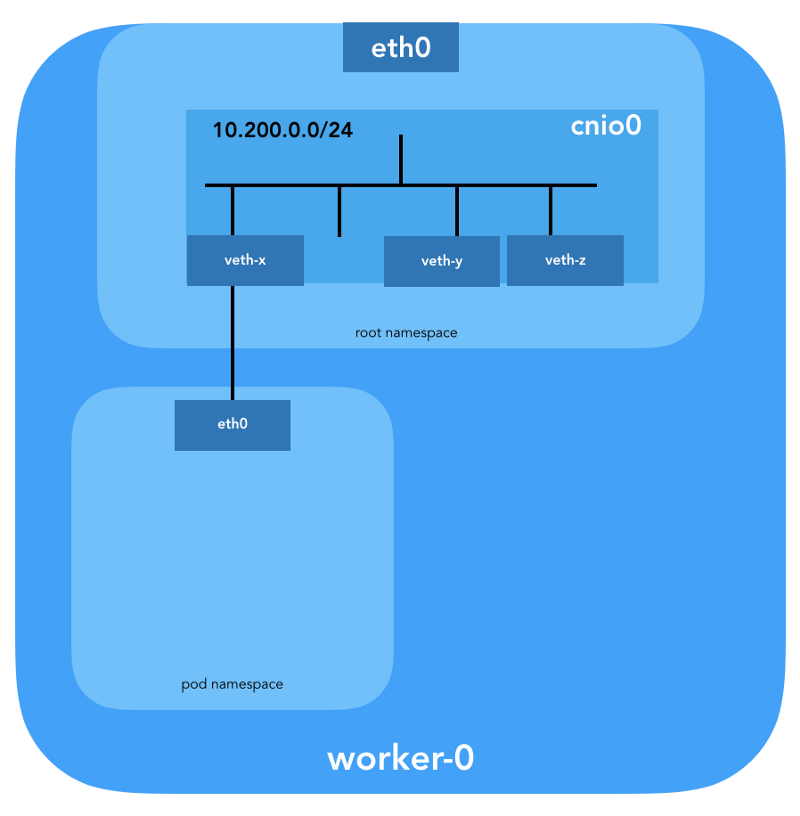
Para atribuir informações L3, como endereços IP, o
plug -
in IPAM (
ipam ) é chamado. Nesse caso, o tipo
host-local é usado ", que armazena o estado localmente no sistema de arquivos host, o que garante a exclusividade dos endereços IP em um host"
(a partir da host-local ) . O plug-in IPAM retorna essas informações para o plug-in anterior (
bridge ), para que todas as rotas especificadas na configuração possam ser configuradas (
"routes": [{"dst": "0.0.0.0/0"}] ). Se
gw não
gw especificado, ele
será retirado da sub-rede . A rota padrão também é configurada no espaço para nome da rede da lareira, apontando para a ponte (que é configurada como a primeira sub-rede IP da lareira).
E o último detalhe importante: solicitamos o mascaramento (
"ipMasq": true ) para o tráfego proveniente da rede da lareira. Realmente não precisamos de NAT aqui, mas essa é a configuração do
Kubernetes The Hard Way . Portanto, para ser completo, devo mencionar que as entradas nas
iptables plug-in de
bridge estão configuradas para este exemplo específico. Todos os pacotes da lareira, cujo destinatário não está no intervalo
224.0.0.0/4 ,
estarão atrás do NAT , que não atende exatamente ao requisito "todos os contêineres podem se comunicar com outros contêineres sem usar o NAT". Bem, provaremos por que o NAT não é necessário ...

Roteamento da lareira
Agora estamos prontos para personalizar os pods. Vamos examinar todos os espaços de rede dos nomes de um dos nós de trabalho e analisar um deles depois de criar a implantação do
nginx partir daqui . Usaremos
lsns com a opção
-t para selecionar o tipo de espaço para nome desejado (ou seja,
net ):
ubuntu@worker-0:~$ sudo lsns -t net NS TYPE NPROCS PID USER COMMAND 4026532089 net 113 1 root /sbin/init 4026532280 net 2 8046 root /pause 4026532352 net 4 16455 root /pause 4026532426 net 3 27255 root /pause
Usando a opção
-i para
ls , podemos encontrar seus números de inode:
ubuntu@worker-0:~$ ls -1i /var/run/netns 4026532352 cni-1d85bb0c-7c61-fd9f-2adc-f6e98f7a58af 4026532280 cni-7cec0838-f50c-416a-3b45-628a4237c55c 4026532426 cni-912bcc63-712d-1c84-89a7-9e10510808a0
Você também pode listar todos os namespaces de rede usando
ip netns :
ubuntu@worker-0:~$ ip netns cni-912bcc63-712d-1c84-89a7-9e10510808a0 (id: 2) cni-1d85bb0c-7c61-fd9f-2adc-f6e98f7a58af (id: 1) cni-7cec0838-f50c-416a-3b45-628a4237c55c (id: 0)
Para ver todos os processos em execução no espaço de rede
cni-912bcc63–712d-1c84–89a7–9e10510808a0 (
4026532426 ), é possível executar, por exemplo, o seguinte comando:
ubuntu@worker-0:~$ sudo ls -l /proc/[1-9]*/ns/net | grep 4026532426 | cut -f3 -d"/" | xargs ps -p PID TTY STAT TIME COMMAND 27255 ? Ss 0:00 /pause 27331 ? Ss 0:00 nginx: master process nginx -g daemon off; 27355 ? S 0:00 nginx: worker process
Pode-se observar que, além da
pause neste pod, lançamos o
nginx . O contêiner de
pause compartilha os namespaces
net e
ipc com todos os outros contêineres de pod. Lembre-se do PID da
pause - 27255; nós retornaremos a ele.
Agora vamos ver o que o
kubectl diz sobre este pod:
$ kubectl get pods -o wide | grep nginx nginx-65899c769f-wxdx6 1/1 Running 0 5d 10.200.0.4 worker-0
Mais detalhes:
$ kubectl describe pods nginx-65899c769f-wxdx6
Name: nginx-65899c769f-wxdx6 Namespace: default Node: worker-0/10.240.0.20 Start Time: Thu, 05 Jul 2018 14:20:06 -0400 Labels: pod-template-hash=2145573259 run=nginx Annotations: <none> Status: Running IP: 10.200.0.4 Controlled By: ReplicaSet/nginx-65899c769f Containers: nginx: Container ID: containerd://4c0bd2e2e5c0b17c637af83376879c38f2fb11852921b12413c54ba49d6983c7 Image: nginx ...
Vemos o nome do pod -
nginx-65899c769f-wxdx6 - e o ID de um de seus contêineres (
nginx ), mas nada foi dito sobre a
pause . Cavar um nó de trabalho mais profundo para corresponder a todos os dados. Lembre-se de que o
Kubernetes The Hard Way não usa o
Docker , portanto, para obter detalhes sobre o contêiner, consultamos o utilitário console consoleerderd-ctr
(consulte também o artigo " Integração do containererd com o Kubernetes, substituindo o Docker, pronto para produção " - aprox. Transfer ) :
ubuntu@worker-0:~$ sudo ctr namespaces ls NAME LABELS k8s.io
Conhecendo o
k8s.io (
k8s.io ), é possível obter o ID do contêiner
nginx :
ubuntu@worker-0:~$ sudo ctr -n k8s.io containers ls | grep nginx 4c0bd2e2e5c0b17c637af83376879c38f2fb11852921b12413c54ba49d6983c7 docker.io/library/nginx:latest io.containerd.runtime.v1.linux
... e faça uma
pause também:
ubuntu@worker-0:~$ sudo ctr -n k8s.io containers ls | grep pause 0866803b612f2f55e7b6b83836bde09bd6530246239b7bde1e49c04c7038e43a k8s.gcr.io/pause:3.1 io.containerd.runtime.v1.linux 21640aea0210b320fd637c22ff93b7e21473178de0073b05de83f3b116fc8834 k8s.gcr.io/pause:3.1 io.containerd.runtime.v1.linux d19b1b1c92f7cc90764d4f385e8935d121bca66ba8982bae65baff1bc2841da6 k8s.gcr.io/pause:3.1 io.containerd.runtime.v1.linux
O ID do contêiner
nginx que termina em
…983c7 corresponde ao que obtivemos do
kubectl . Vamos ver se conseguimos descobrir qual contêiner de
pause pertence ao pod do
nginx :
ubuntu@worker-0:~$ sudo ctr -n k8s.io task ls TASK PID STATUS ... d19b1b1c92f7cc90764d4f385e8935d121bca66ba8982bae65baff1bc2841da6 27255 RUNNING 4c0bd2e2e5c0b17c637af83376879c38f2fb11852921b12413c54ba49d6983c7 27331 RUNNING
Lembre-se de que os processos com o PID 27331 e 27355 estão em execução no espaço para nome da rede
cni-912bcc63–712d-1c84–89a7–9e10510808a0 ?
ubuntu@worker-0:~$ sudo ctr -n k8s.io containers info d19b1b1c92f7cc90764d4f385e8935d121bca66ba8982bae65baff1bc2841da6 { "ID": "d19b1b1c92f7cc90764d4f385e8935d121bca66ba8982bae65baff1bc2841da6", "Labels": { "io.cri-containerd.kind": "sandbox", "io.kubernetes.pod.name": "nginx-65899c769f-wxdx6", "io.kubernetes.pod.namespace": "default", "io.kubernetes.pod.uid": "0b35e956-8080-11e8-8aa9-0a12b8818382", "pod-template-hash": "2145573259", "run": "nginx" }, "Image": "k8s.gcr.io/pause:3.1", ...
... e:
ubuntu@worker-0:~$ sudo ctr -n k8s.io containers info 4c0bd2e2e5c0b17c637af83376879c38f2fb11852921b12413c54ba49d6983c7 { "ID": "4c0bd2e2e5c0b17c637af83376879c38f2fb11852921b12413c54ba49d6983c7", "Labels": { "io.cri-containerd.kind": "container", "io.kubernetes.container.name": "nginx", "io.kubernetes.pod.name": "nginx-65899c769f-wxdx6", "io.kubernetes.pod.namespace": "default", "io.kubernetes.pod.uid": "0b35e956-8080-11e8-8aa9-0a12b8818382" }, "Image": "docker.io/library/nginx:latest", ...
Agora sabemos com certeza quais contêineres estão sendo executados neste pod (
nginx-65899c769f-wxdx6 ) e o espaço para nome da rede (
cni-912bcc63–712d-1c84–89a7–9e10510808a0 ):
- nginx (ID:
4c0bd2e2e5c0b17c637af83376879c38f2fb11852921b12413c54ba49d6983c7 ); - pausa (ID:
d19b1b1c92f7cc90764d4f385e8935d121bca66ba8982bae65baff1bc2841da6 ).

Como isso está (
nginx-65899c769f-wxdx6 ) conectado à rede? Usamos o PID 27255 recebido anteriormente da
pause para executar comandos em seu namespace de rede (
cni-912bcc63–712d-1c84–89a7–9e10510808a0 ):
ubuntu@worker-0:~$ sudo ip netns identify 27255 cni-912bcc63-712d-1c84-89a7-9e10510808a0
Para esses fins, usaremos o
nsenter com a opção
-t que define o PID de destino e
-n sem especificar um arquivo para entrar no espaço de nomes de rede do processo de destino (27255). Aqui está o que o
ip link show dirá:
ubuntu@worker-0:~$ sudo nsenter -t 27255 -n ip link show 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 3: eth0@if7: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default link/ether 0a:58:0a:c8:00:04 brd ff:ff:ff:ff:ff:ff link-netnsid 0
... e
ifconfig eth0 :
ubuntu@worker-0:~$ sudo nsenter -t 27255 -n ifconfig eth0 eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 10.200.0.4 netmask 255.255.255.0 broadcast 0.0.0.0 inet6 fe80::2097:51ff:fe39:ec21 prefixlen 64 scopeid 0x20<link> ether 0a:58:0a:c8:00:04 txqueuelen 0 (Ethernet) RX packets 540 bytes 42247 (42.2 KB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 177 bytes 16530 (16.5 KB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
Isso confirma que o endereço IP obtido anteriormente pelo
kubectl get pod está configurado na interface
eth0 . Essa interface faz parte de um
par veth , uma extremidade na lareira e a outra no espaço para nome raiz. Para descobrir a interface do segundo lado, usamos o
ethtool :
ubuntu@worker-0:~$ sudo ip netns exec cni-912bcc63-712d-1c84-89a7-9e10510808a0 ethtool -S eth0 NIC statistics: peer_ifindex: 7
Vemos que o
ifindex banquete é 7. Verifique se ele está no espaço para nome raiz. Isso pode ser feito usando o
ip link :
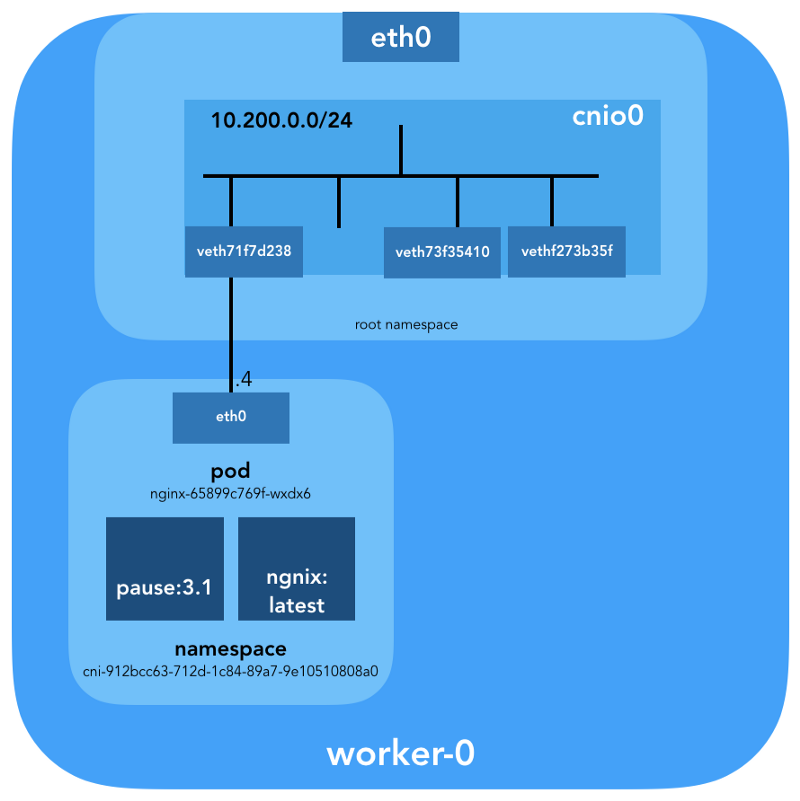
ubuntu@worker-0:~$ ip link | grep '^7:' 7: veth71f7d238@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master cnio0 state UP mode DEFAULT group default
Para ter certeza disso, finalmente, vamos ver:
ubuntu@worker-0:~$ sudo cat /sys/class/net/veth71f7d238/ifindex 7
Ótimo, agora tudo está claro com o link virtual. Usando
brctl vamos ver quem mais está conectado à ponte Linux:
ubuntu@worker-0:~$ brctl show cnio0 bridge name bridge id STP enabled interfaces cnio0 8000.0a580ac80001 no veth71f7d238 veth73f35410 vethf273b35f
Então, a imagem é a seguinte:
Verificação de roteamento
Como realmente encaminhamos o tráfego? Vejamos a tabela de roteamento no pod de namespace da rede:
ubuntu@worker-0:~$ sudo ip netns exec cni-912bcc63-712d-1c84-89a7-9e10510808a0 ip route show default via 10.200.0.1 dev eth0 10.200.0.0/24 dev eth0 proto kernel scope link src 10.200.0.4
Pelo menos sabemos como chegar ao espaço para nome raiz (
default via 10.200.0.1 ). Agora vamos ver a tabela de roteamento de host:
ubuntu@worker-0:~$ ip route list default via 10.240.0.1 dev eth0 proto dhcp src 10.240.0.20 metric 100 10.200.0.0/24 dev cnio0 proto kernel scope link src 10.200.0.1 10.240.0.0/24 dev eth0 proto kernel scope link src 10.240.0.20 10.240.0.1 dev eth0 proto dhcp scope link src 10.240.0.20 metric 100
Sabemos como encaminhar pacotes para um roteador VPC (o VPC
possui um roteador "implícito", que
geralmente possui um segundo endereço do espaço de endereço IP principal da sub-rede). Agora: o roteador VPC sabe como acessar a rede de cada lareira? Não, ele não, portanto, presume-se que as rotas serão configuradas pelo plug-in da CNI ou
manualmente (como no manual). Aparentemente, o
AWS CNI-plugin faz exatamente isso para nós na AWS. Lembre-se de que existem
muitos plugins CNI e estamos considerando um exemplo de uma
configuração de rede simples :
Imersão profunda no NAT
kubectl create -f busybox.yaml crie dois contêineres idênticos com o Replication Controller:
apiVersion: v1 kind: ReplicationController metadata: name: busybox0 labels: app: busybox0 spec: replicas: 2 selector: app: busybox0 template: metadata: name: busybox0 labels: app: busybox0 spec: containers: - image: busybox command: - sleep - "3600" imagePullPolicy: IfNotPresent name: busybox restartPolicy: Always
(
busybox.yaml )
Temos:
$ kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE busybox0-g6pww 1/1 Running 0 4s 10.200.1.15 worker-1 busybox0-rw89s 1/1 Running 0 4s 10.200.0.21 worker-0 ...
Pings de um contêiner para outro devem ser bem-sucedidos:
$ kubectl exec -it busybox0-rw89s -- ping -c 2 10.200.1.15 PING 10.200.1.15 (10.200.1.15): 56 data bytes 64 bytes from 10.200.1.15: seq=0 ttl=62 time=0.528 ms 64 bytes from 10.200.1.15: seq=1 ttl=62 time=0.440 ms --- 10.200.1.15 ping statistics --- 2 packets transmitted, 2 packets received, 0% packet loss round-trip min/avg/max = 0.440/0.484/0.528 ms
Para entender o movimento do tráfego, você pode ver os pacotes usando
tcpdump ou
conntrack :
ubuntu@worker-0:~$ sudo conntrack -L | grep 10.200.1.15 icmp 1 29 src=10.200.0.21 dst=10.200.1.15 type=8 code=0 id=1280 src=10.200.1.15 dst=10.240.0.20 type=0 code=0 id=1280 mark=0 use=1
O IP de origem do pod 10.200.0.21 é convertido no endereço IP do host 10.240.0.20.
ubuntu@worker-1:~$ sudo conntrack -L | grep 10.200.1.15 icmp 1 28 src=10.240.0.20 dst=10.200.1.15 type=8 code=0 id=1280 src=10.200.1.15 dst=10.240.0.20 type=0 code=0 id=1280 mark=0 use=1
No iptables, você pode ver que as contagens estão aumentando:
ubuntu@worker-0:~$ sudo iptables -t nat -Z POSTROUTING -L -v Chain POSTROUTING (policy ACCEPT 0 packets, 0 bytes) pkts bytes target prot opt in out source destination ... 5 324 CNI-be726a77f15ea47ff32947a3 all -- any any 10.200.0.0/24 anywhere /* name: "bridge" id: "631cab5de5565cc432a3beca0e2aece0cef9285482b11f3eb0b46c134e457854" */ Zeroing chain `POSTROUTING'
Por outro lado, se você remover
"ipMasq": true da configuração do plugin CNI, poderá ver o seguinte (esta operação é realizada exclusivamente para fins educacionais - não recomendamos alterar a configuração em um cluster ativo!):
$ kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE busybox0-2btxn 1/1 Running 0 16s 10.200.0.15 worker-0 busybox0-dhpx8 1/1 Running 0 16s 10.200.1.13 worker-1 ...
Ping ainda deve passar:
$ kubectl exec -it busybox0-2btxn -- ping -c 2 10.200.1.13 PING 10.200.1.6 (10.200.1.6): 56 data bytes 64 bytes from 10.200.1.6: seq=0 ttl=62 time=0.515 ms 64 bytes from 10.200.1.6: seq=1 ttl=62 time=0.427 ms --- 10.200.1.6 ping statistics --- 2 packets transmitted, 2 packets received, 0% packet loss round-trip min/avg/max = 0.427/0.471/0.515 ms
E neste caso - sem usar o NAT:
ubuntu@worker-0:~$ sudo conntrack -L | grep 10.200.1.13 icmp 1 29 src=10.200.0.15 dst=10.200.1.13 type=8 code=0 id=1792 src=10.200.1.13 dst=10.200.0.15 type=0 code=0 id=1792 mark=0 use=1
Portanto, verificamos que "todos os contêineres podem se comunicar com outros contêineres sem usar o NAT".
ubuntu@worker-1:~$ sudo conntrack -L | grep 10.200.1.13 icmp 1 27 src=10.200.0.15 dst=10.200.1.13 type=8 code=0 id=1792 src=10.200.1.13 dst=10.200.0.15 type=0 code=0 id=1792 mark=0 use=1
Rede de cluster (10.32.0.0/24)
Você deve ter notado no exemplo do
busybox que os endereços IP atribuídos ao
busybox eram diferentes em cada caso. E se quiséssemos disponibilizar esses contêineres para comunicação de outros lares? Pode-se pegar os endereços IP atuais do pod, mas eles mudarão. Por esse motivo, você precisa configurar o recurso
Service , que fará proxy de solicitações para muitos lares de vida curta.
"O serviço no Kubernetes é uma abstração que define o conjunto lógico de lareiras e as políticas pelas quais elas podem ser acessadas." (da documentação dos Serviços Kubernetes )
Existem várias maneiras de publicar um serviço; o tipo padrão é
ClusterIP , que define o endereço IP do bloco CIDR do cluster (ou seja, acessível apenas a partir do cluster). Um exemplo é o complemento de cluster DNS configurado no Kubernetes The Hard Way.
# ... apiVersion: v1 kind: Service metadata: name: kube-dns namespace: kube-system labels: k8s-app: kube-dns kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile kubernetes.io/name: "KubeDNS" spec: selector: k8s-app: kube-dns clusterIP: 10.32.0.10 ports: - name: dns port: 53 protocol: UDP - name: dns-tcp port: 53 protocol: TCP # ...
(
kube-dns.yaml )
kubectl mostra que o
Service lembra dos pontos finais e os converte:
$ kubectl -n kube-system describe services ... Selector: k8s-app=kube-dns Type: ClusterIP IP: 10.32.0.10 Port: dns 53/UDP TargetPort: 53/UDP Endpoints: 10.200.0.27:53 Port: dns-tcp 53/TCP TargetPort: 53/TCP Endpoints: 10.200.0.27:53 ...
Como exatamente? ..
iptables novamente. Vamos examinar as regras criadas para este exemplo. Sua lista completa pode ser vista com o comando
iptables-save .
Assim que os pacotes são criados pelo processo (
OUTPUT ) ou chegam à interface de rede (
PREROUTING ), eles passam pelas seguintes cadeias de
iptables :
-A PREROUTING -m comment --comment "kubernetes service portals" -j KUBE-SERVICES -A OUTPUT -m comment --comment "kubernetes service portals" -j KUBE-SERVICES
Os seguintes destinos correspondem aos pacotes TCP enviados para a 53ª porta em 10.32.0.10 e são transmitidos ao destinatário 10.200.0.27 com a 53ª porta:
-A KUBE-SERVICES -d 10.32.0.10/32 -p tcp -m comment --comment "kube-system/kube-dns:dns-tcp cluster IP" -m tcp --dport 53 -j KUBE-SVC-ERIFXISQEP7F7OF4 -A KUBE-SVC-ERIFXISQEP7F7OF4 -m comment --comment "kube-system/kube-dns:dns-tcp" -j KUBE-SEP-32LPCMGYG6ODGN3H -A KUBE-SEP-32LPCMGYG6ODGN3H -p tcp -m comment --comment "kube-system/kube-dns:dns-tcp" -m tcp -j DNAT --to-destination 10.200.0.27:53
O mesmo para pacotes UDP (destinatário 10.32.0.10:53 → 10.200.0.27:53):
-A KUBE-SERVICES -d 10.32.0.10/32 -p udp -m comment --comment "kube-system/kube-dns:dns cluster IP" -m udp --dport 53 -j KUBE-SVC-TCOU7JCQXEZGVUNU -A KUBE-SVC-TCOU7JCQXEZGVUNU -m comment --comment "kube-system/kube-dns:dns" -j KUBE-SEP-LRUTK6XRXU43VLIG -A KUBE-SEP-LRUTK6XRXU43VLIG -p udp -m comment --comment "kube-system/kube-dns:dns" -m udp -j DNAT --to-destination 10.200.0.27:53
Existem outros tipos de
Services no Kubernetes. Em particular, o Kubernetes The Hard Way
NodePort sobre o
NodePort - consulte
Smoke Test: Services .
kubectl expose deployment nginx --port 80 --type NodePort
NodePort publica o serviço no endereço IP de cada nó, colocando-o em uma porta estática (chamada
NodePort ).
NodePort pode ser acessado de fora do cluster. Você pode verificar a porta dedicada (neste caso - 31088) usando o
kubectl :
$ kubectl describe services nginx ... Type: NodePort IP: 10.32.0.53 Port: <unset> 80/TCP TargetPort: 80/TCP NodePort: <unset> 31088/TCP Endpoints: 10.200.1.18:80 ...
Agora, Under está disponível na Internet como
http://${EXTERNAL_IP}:31088/ . Aqui
EXTERNAL_IP é o endereço IP público de
qualquer instância de trabalho . Neste exemplo, usei o endereço IP público do
worker-0 . A solicitação é recebida por um host com um endereço IP interno 10.240.0.20 (o provedor de nuvem está envolvido no NAT público); no entanto, o serviço é realmente iniciado em outro host (
worker-1 , que pode ser visto pelo endereço IP do terminal - 10.200.1.18):
ubuntu@worker-0:~$ sudo conntrack -L | grep 31088 tcp 6 86397 ESTABLISHED src=173.38.XXX.XXX dst=10.240.0.20 sport=30303 dport=31088 src=10.200.1.18 dst=10.240.0.20 sport=80 dport=30303 [ASSURED] mark=0 use=1
O pacote é enviado do
trabalhador-0 para o
trabalhador-1 , onde encontra seu destinatário:
ubuntu@worker-1:~$ sudo conntrack -L | grep 80 tcp 6 86392 ESTABLISHED src=10.240.0.20 dst=10.200.1.18 sport=14802 dport=80 src=10.200.1.18 dst=10.240.0.20 sport=80 dport=14802 [ASSURED] mark=0 use=1
Esse circuito é ideal? Talvez não, mas funciona. Nesse caso, as regras do
iptables programadas são as seguintes:
-A KUBE-NODEPORTS -p tcp -m comment --comment "default/nginx:" -m tcp --dport 31088 -j KUBE-SVC-4N57TFCL4MD7ZTDA -A KUBE-SVC-4N57TFCL4MD7ZTDA -m comment --comment "default/nginx:" -j KUBE-SEP-UGTFMET44DQG7H7H -A KUBE-SEP-UGTFMET44DQG7H7H -p tcp -m comment --comment "default/nginx:" -m tcp -j DNAT --to-destination 10.200.1.18:80
Em outras palavras, o endereço para o destinatário dos pacotes com porta 31088 é transmitido em 10.200.1.18. A porta também está transmitindo, de 31088 a 80.
Não tocamos em outro tipo de serviço - o
LoadBalancer - que disponibiliza publicamente o serviço usando um balanceador de carga do provedor de nuvem, mas o artigo já era grande.
Conclusão
Pode parecer que há muita informação, mas apenas tocamos a ponta do iceberg. No futuro, vou falar sobre IPv6, IPVS, eBPF e alguns plugins CNI atuais interessantes.
PS do tradutor
Leia também em nosso blog: