
Hoje, finalmente, o principal programa da conferência começou. A taxa de aceitação neste ano foi de apenas 8%, ou seja, deve ser o melhor dos melhores dos melhores. Os fluxos aplicados e de pesquisa são claramente separados, além de várias atividades relacionadas separadas. Os fluxos aplicados parecem mais interessantes, existem relatórios principalmente de empresas principais (Google, Amazon, Alibaba, etc.). Vou falar sobre as apresentações que consegui assistir.
Dados para o bem
O dia começou com uma apresentação suficientemente longa para que os dados fossem úteis e usados para o bem. Um
professor da Universidade da Califórnia está
falando (vale a pena notar que há muitas mulheres no KDD, tanto entre estudantes quanto entre palestrantes). Tudo isso está expresso na abreviatura FATES:
- Justiça - sem preconceitos nas previsões de modelos, tudo é neutro em termos de gênero e tolerante.
- Responsabilidade - deve haver alguém ou algo responsável pelas decisões tomadas pela máquina.
- Transparência - transparência e explicabilidade das decisões.
- Ética - ao trabalhar com dados, ênfase especial deve ser na ética e na privacidade.
- Segurança e proteção - o sistema deve ser seguro (não prejudicial) e protegido (resistente a influências manipulativas externas)
Infelizmente, esse manifesto expressa um desejo e está fracamente correlacionado com a realidade. O modelo estará politicamente correto somente se todos os sinais forem removidos; a responsabilidade de transferir para alguém específico é sempre muito difícil; quanto mais o DS se desenvolve, mais difícil é interpretar o que está acontecendo dentro do modelo; em ética e privacidade, houve alguns bons exemplos no primeiro dia, mas, caso contrário, os dados são frequentemente tratados com bastante liberdade.
Bem, não podemos deixar de admitir que os modelos modernos geralmente não são seguros (um piloto automático pode abandonar um carro com um motorista) e não são protegidos (você pode pegar exemplos que interrompem o trabalho de uma rede neural sem nem mesmo saber como a rede funciona). Um trabalho recente interessante do
DeepExplore : um sistema de busca de vulnerabilidades em redes neurais gera, entre outras coisas, imagens que fazem o piloto automático dirigir na direção errada.

A seguir, é apresentada outra definição de ciência de dados como "DS é o estudo da extração de dados de forma de valor". Em princípio, muito bom. No início do discurso, o palestrante mencionou especificamente que o DS frequentemente olha dados apenas a partir do momento da análise, enquanto o ciclo de vida completo é muito mais amplo, e isso, entre outras coisas, se refletiu na definição.
Bem, houve alguns exemplos de trabalho de laboratório.
Mais uma vez, analisaremos a tarefa de avaliar a influência de muitos fatores no resultado, mas não da posição da publicidade, mas em geral. Existe um
artigo ainda não publicado. Considere, por exemplo, a questão de quais atores escolher para o filme para coletar uma boa bilheteria. Analisamos as listas de atuação dos filmes com maior bilheteria e tentamos prever a contribuição de cada um dos atores. Mas! Existem os chamados
fatores de confusão que afetam a eficácia de um ator (por exemplo, Stallone vai bem em um filme de ação thrash, mas não em uma comédia romântica). Para escolher o caminho certo, você precisa encontrar todos os fatores de confusão e avaliá-los, mas nunca teremos certeza de que encontramos todos. Na verdade, o artigo propõe uma nova abordagem - desconfiada. Em vez de destacar fatores de confusão, introduzimos explicitamente variáveis latentes e as avaliamos em um modo não supervisionado e, em seguida, estudamos o modelo com base nelas. Tudo soa estranho o suficiente, porque parece uma variante simples de casamentos, o que há de novo não está claro.
Algumas fotos bonitas foram mostradas, exemplos de como na IA da universidade, etc. estão avançando.
Comércio eletrônico e criação de perfil
Foi para a seção de aplicativos sobre comércio. No começo, havia alguns relatórios muito interessantes; no final, havia uma certa quantidade de mingau, mas primeiro as primeiras coisas.
Nova modelagem de usuário e previsão de rotatividade
O
trabalho interessante do Snapchat sobre a previsão de saídas. Os caras usam a ideia, que também executamos com sucesso há cerca de 4 anos: antes de prever a saída, os usuários precisam ser divididos em clusters de acordo com o tipo de comportamento. Ao mesmo tempo, o espaço vetorial pelos tipos de ações que eles mostraram ser bastante pobres, de apenas alguns tipos de interações (nós, no devido tempo, tivemos que fazer uma seleção de sinais para passar de trezentos para um ano e meio), mas eles enriquecem o espaço com estatísticas adicionais e o consideram uma série temporal. , como resultado, os clusters são obtidos não tanto sobre o que os usuários fazem, mas com
que frequência eles fazem isso.
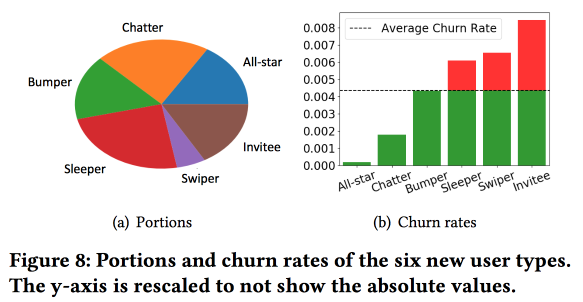
Uma observação importante: a rede possui o “núcleo” dos usuários mais conectados e ativos, com um tamanho de 1,7 milhão de pessoas. Ao mesmo tempo, o comportamento e a retenção do usuário dependem muito de saber se ele pode se comunicar com alguém do "núcleo".
Então começamos a construir um modelo. Vamos levar os recém-chegados em quinze dias (511 mil), recursos simples e redes de ego (tamanho e densidade), e ver se eles estão associados ao "núcleo", etc. Alimentamos o comportamento do usuário com o LSTM e obtemos a precisão da previsão de vazão um pouco maior que a do logreg (em 7-8%). Mas então a diversão começa. Para levar em conta as especificidades de grupos individuais, treinaremos vários LSTMs em paralelo e anexaremos uma camada de atenção na parte superior. Como resultado, esse esquema começa a trabalhar tanto em cluster (quais dos LSTMs receberam atenção) quanto na previsão de vazão. Dá outro aumento de + 5-7% na qualidade e o logreg já parece pálido. Mas! Na verdade, seria justo compará-lo com um logreg segmentado treinado separadamente para clusters (que podem ser obtidos de maneiras mais simples).
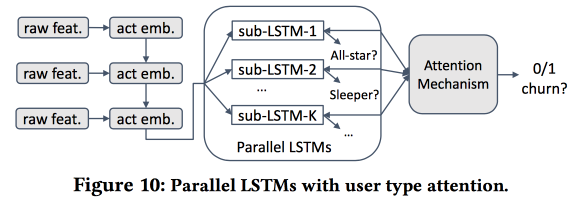
Perguntei sobre interpretabilidade: afinal de contas, as saídas geralmente são previstas não para obter uma previsão, mas para entender quais fatores a influenciam. O orador estava claramente pronto para esta pergunta: para isso, clusters dedicados são usados e analisados, em que aqueles onde as previsões de vazão são maiores são diferenciados dos outros.
Representação universal do usuário
Os caras do Alibaba
falam sobre como criar associações de usuários. Acontece que ter muitos envios de usuários é ruim: muitos não são finalizados, forças são desperdiçadas. Eles conseguiram fazer uma apresentação universal e mostrar que funciona melhor. Naturalmente em redes neurais. A arquitetura é bastante padrão, já de uma forma ou de outra que foi descrita repetidamente na conferência. Os fatos do comportamento do usuário são inseridos na entrada, nós os desenvolvemos, damos tudo ao LSTM, penduramos uma camada de atenção por cima e, ao lado, uma grade adicional para recursos estáticos, coroada com uma multitarefa (na verdade, várias grades pequenas para uma tarefa específica) . Treinamos tudo isso juntos, a saída com atenção será a incorporação do usuário.
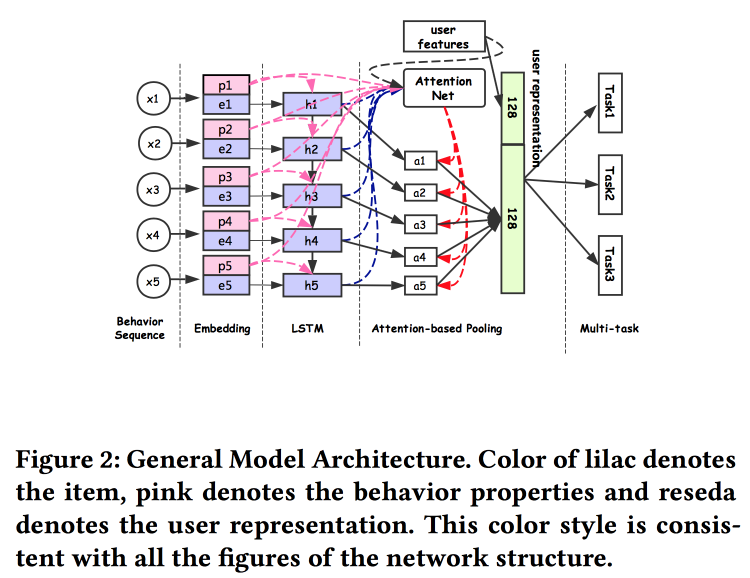
Existem várias adições mais complexas: além da atenção simples, elas adicionam uma rede de atenção "profunda" e também usam uma versão modificada do LSTM - LSTM com propriedade de propriedade
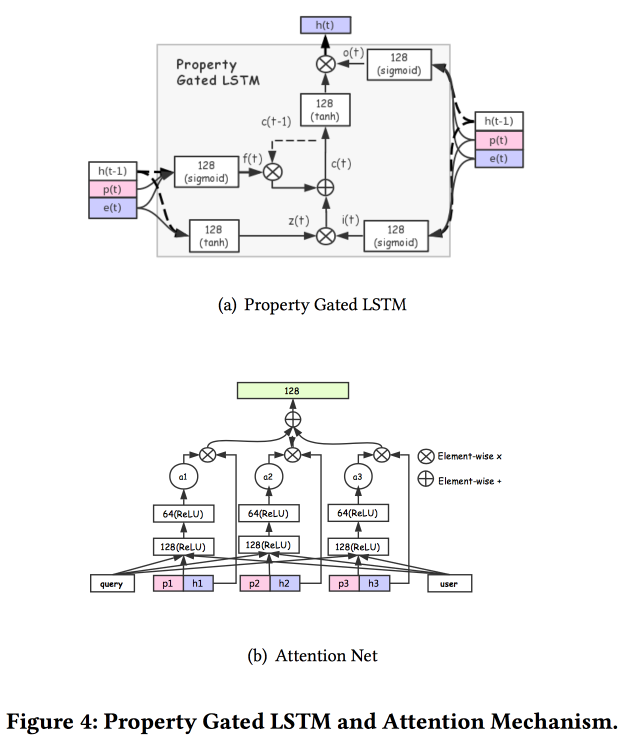
Tarefas nas quais tudo isso ocorre: previsão de CTR, previsão de preferência de preço, aprendendo a classificar, previsão de moda a seguir, previsão de preferência de loja. O conjunto de dados por 10 dias inclui 6 * 10
9 exemplos de treinamento.
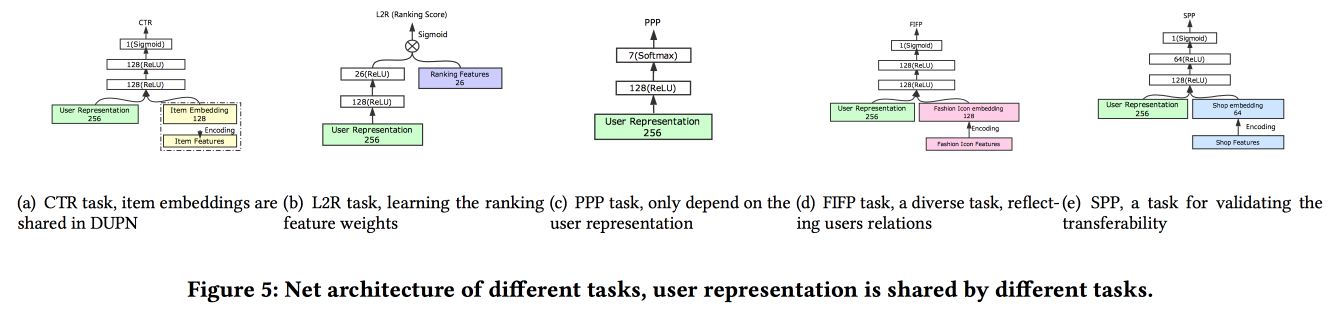
Havia uma pessoa inesperada: eles treinam tudo isso no TensorFlow, em um cluster de CPU de 2000 máquinas com 15 núcleos cada, são necessários 4 dias para completar os dados por 10 dias. Portanto, eles continuam a treinar dia após dia (10 horas nesse cluster). O GPU / FPGA não teve tempo de perguntar :(. A adição de uma nova tarefa é feita através da reciclagem como um todo ou da reciclagem de uma grade superficial (ajuste fino de rede). No tempo de execução da inferência, eles armazenam representações (saída com atenção para usuários específicos) e apenas os chefes das grades são calculados para tarefas específicas O teste A / B mostrou um aumento de 2-3% para vários indicadores.
Previsão de retorno de produto de cauda eletrônica
Eles prevêem a devolução de mercadorias pelo usuário após a compra, o
trabalho é apresentado pela IBM. Infelizmente, até o momento não há texto em acesso aberto. A devolução de mercadorias é uma questão séria no valor de US $ 200 bilhões por ano. Para construir uma previsão de retornos, ele usa um modelo de um hipergrafo que conecta produtos e cestas, usando esta cesta, eles tentam encontrar os mais próximos por hipergrafo, após o que estimam a probabilidade de um retorno. Para impedir um retorno, uma loja online tem muitas possibilidades, por exemplo, oferecendo um desconto para remover determinados produtos da cesta.
Observamos imediatamente que há uma diferença significativa entre cestas com duplicatas (por exemplo, duas camisetas idênticas de tamanhos diferentes) e sem, portanto, devemos construir imediatamente modelos diferentes para esses dois casos.
O algoritmo geral é chamado HyperGo:
- Estamos construindo um hipergrafo para representar compras e devoluções com informações do usuário, produto e cesta.
- Em seguida, usamos o corte local do gráfico com base na caminhada aleatória para obter informações locais para a previsão.
- Consideramos separadamente cestas com tomadas e sem tomadas.
- Utilizamos métodos bayesianos para avaliar o impacto de um produto individual na cesta.
Comparando a qualidade da previsão de retorno com KNN para cestas, ponderada de acordo com Jacquard KNN, racionando pelo número de duplicatas, obtemos um aumento no resultado. Um link para o GitHub tremulava nos slides, mas eles não conseguiam encontrar sua fonte e não há nenhum link no artigo.
OpenTag: Abrir extração de valor de atributo de perfis de produto
Trabalho bastante interessante da Amazônia. Desafio: analise vários fatos para o Alexa responder melhor às perguntas. Eles dizem que tudo é complicado, os sistemas antigos não sabem trabalhar com novas palavras, geralmente exigem um grande número de regras e heurísticas escritas à mão; os resultados são mais ou menos. É claro que as redes neurais com a arquitetura já incorporada de atenção ao LSTM ajudarão a resolver todos os problemas, mas faremos o LSTM dobrar e também colocaremos o
campo aleatório condicional no topo.

Vamos resolver o problema de marcar uma sequência de palavras. As tags mostrarão onde começamos e terminamos as seqüências de certos atributos (por exemplo, o sabor e a composição da comida de cachorro), e o LSTM tentará prevê-las. Como um coque e uma reverência para o Mechanical Turk, o treinamento ativo do modelo é usado. Para selecionar exemplos que precisam ser enviados para mais marcações, use a heurística "para pegar os exemplos em que as tags geralmente trocam entre as eras".
Aprendendo e transferindo representação de códigos no comércio eletrônico
Em seu
trabalho, colegas do Alibaba voltam novamente à questão da construção de casamentos, desta vez olhando não apenas para os usuários, mas para os IDs em princípio: produtos, marcas, categorias, usuários, etc. As sessões de interação são usadas como uma fonte de dados e atributos adicionais também são levados em consideração. Skipgrams são usados como o algoritmo principal.
O orador tem uma pronúncia muito pesada com um forte sotaque chinês, para entender o que está acontecendo é quase impossível. Um dos "truques" do trabalho é a mecânica da transferência de representações com falta de informações, por exemplo, dos itens para o usuário através da média (rapidamente, você não precisa aprender todo o modelo). A partir dos itens antigos, é possível inicializar novos (aparentemente por similaridade de conteúdo), bem como transferir a visualização do usuário de um domínio (eletrônicos) para outro (roupas).
No geral, não está totalmente claro onde está a novidade, aparentemente os detalhes precisam ser desenterrados; além disso, não está claro como isso se compara à história anterior sobre as representações unificadas dos usuários.
Seleção de parâmetros on-line para problemas de classificação baseados na Web
Trabalho muito interessante de amigos no LinkedIn. A essência do trabalho é selecionar on-line os parâmetros ideais da operação do algoritmo, levando em consideração vários objetivos concorrentes. Como um escopo, considere a fita e tente aumentar o número de sessões de certos tipos:
- Sessão com alguma ação viral (VA).
- Retomar a sessão de envio (JA).
- Interação de conteúdo na sessão Feed (EFS).
A função de classificação no algoritmo é uma média ponderada das previsões de conversão para esses três objetivos. Na verdade, pesos são aqueles parâmetros que tentaremos otimizar online. Inicialmente, eles formulam uma tarefa comercial como “maximizar o número de sessões de vírus, mantendo os outros dois tipos pelo menos em um determinado nível”, mas depois os transformam um pouco para facilitar a otimização.
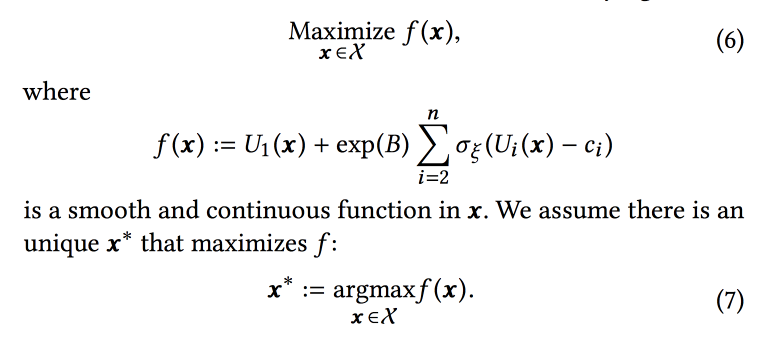
Simulamos os dados com um conjunto de distribuições binomiais (o usuário converterá para o objetivo desejado ou não, vendo a fita com certos parâmetros), onde a probabilidade de sucesso com os parâmetros fornecidos é um
processo gaussiano (próprio para cada tipo de conversão). Em seguida, usamos o
amostrador Thompson com bandidos "infinitamente
robustos " para selecionar os parâmetros ideais (não online, mas offline em dados históricos, por muito tempo). Eles dão algumas dicas: use pontos em negrito para criar a grade inicial e adicione
uma amostragem
epsilon-gananciosa (com a probabilidade de o epsilon tentar um ponto aleatório no espaço); caso contrário, você poderá ignorar o máximo global.
Eles simulam coletar amostras offline uma vez por hora (você precisa de muitas amostras), o resultado é uma certa distribuição de parâmetros ideais. Além disso, quando um usuário entra nessa distribuição, ele usa parâmetros específicos para construir a fita (é importante fazer isso de forma consistente com a semente do ID do usuário para inicialização, para que a fita do usuário não seja alterada radicalmente).
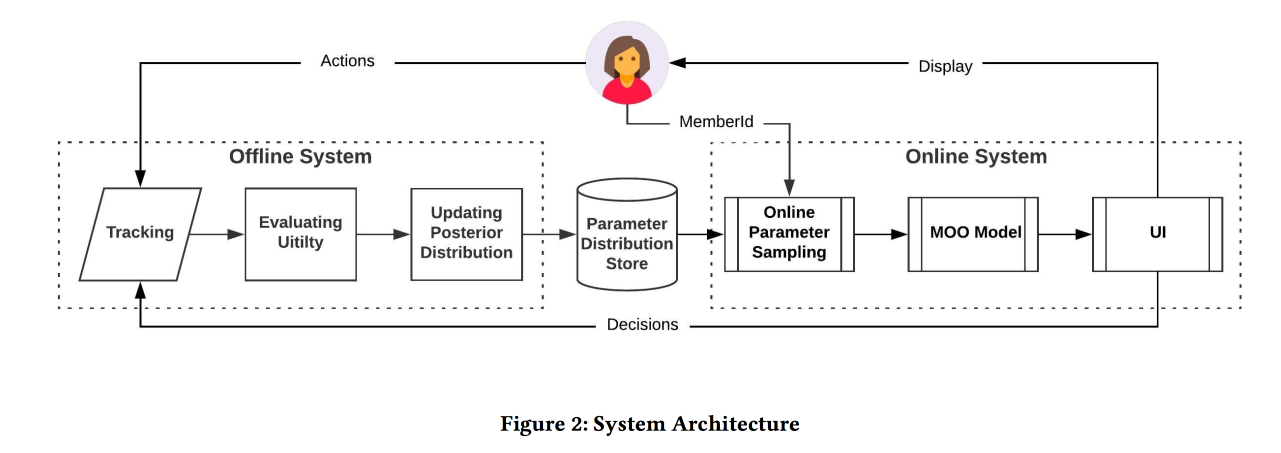
De acordo com os resultados do experimento A / B, eles receberam um aumento no envio de currículos em 12% e curtidas em 3%. Compartilhe algumas observações:
- É mais fácil experimentar mais do que tentar adicionar mais informações ao modelo (por exemplo, o dia da semana / hora).
- Assumimos independência de objetivos nessa abordagem, mas não está claro se é (pelo contrário, não). No entanto, a abordagem funciona.
- Os negócios devem definir metas e limites.
- É importante excluir uma pessoa do processo e deixá-la fazer algo útil.
Otimização quase em tempo real da notificação baseada em atividade
Outro
trabalho do LinkedIn, desta vez sobre o gerenciamento de notificações. Temos pessoas, eventos, canais de entrega e metas de longo prazo para aumentar o envolvimento do usuário sem negatividade significativa na forma de reclamações e cancelamentos de assinatura de pushes. A tarefa é importante e difícil, e você precisa fazer tudo certo: para as pessoas certas, na hora certa, para enviar o conteúdo certo no canal certo e na quantidade certa.
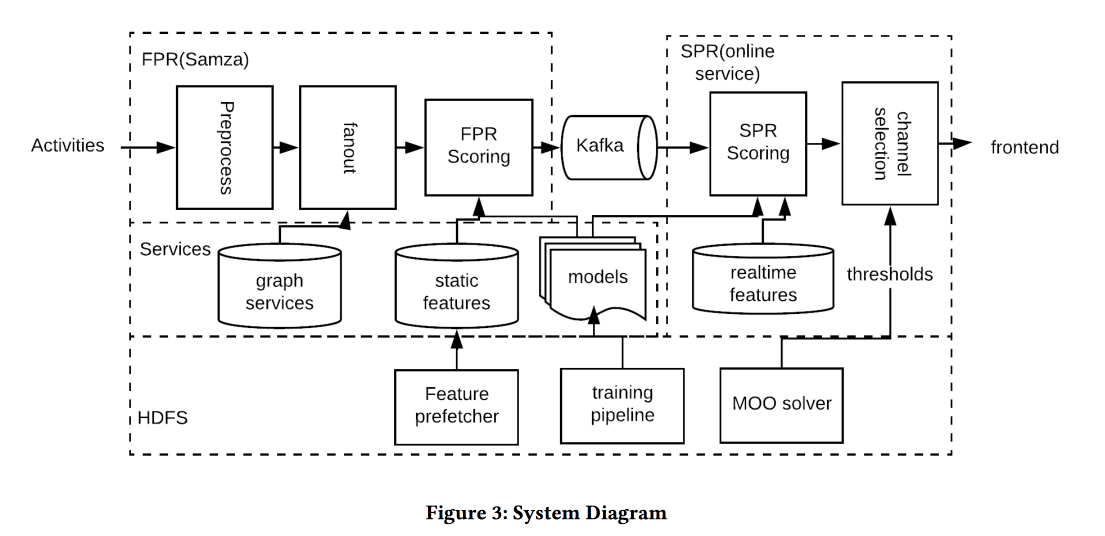
A arquitetura do sistema na imagem acima, a essência do que está acontecendo é aproximadamente o seguinte:
- Nós filtramos qualquer spam na entrada.
- Pessoas certas: um capacete para todos os que estão fortemente conectados com o autor / conteúdo, equilibrando o limiar com a força da comunicação, gerenciando a cobertura e a relevância.
- O momento certo: envie conteúdo imediatamente, para o qual o tempo é importante (eventos de amigos), o restante pode ser mantido por canais menos dinâmicos.
- O conteúdo certo: use logreg! Um modelo de previsão de um clique em um monte de sinais é construído, separadamente para o caso em que uma pessoa está no aplicativo e quando não está.
- Canal correto: definimos diferentes limites de relevância, os mais rigorosos para envio, menor - se o usuário estiver agora no aplicativo, ainda mais baixo - para correio (ele contém todos os tipos de resumos / anúncios).
- Volume correto: o modelo de circuncisão por volume está na saída, também considera relevante, é recomendável fazê-lo individualmente (uma boa heurística de limite é uma pontuação mínima de objetos enviados nos últimos dias)
No teste A / B, houve um aumento de alguns por cento no número de sessões.
Personalização em tempo real usando o ranking de casamentos para pesquisa no Airbnb
E esse foi o
melhor documento de aplicação do AirBnB. Objetivo: otimizar a emissão de canais e resultados de pesquisa semelhantes. Decidimos através da construção de incorporações de veiculações e usuários em um espaço para avaliar ainda mais a semelhança. É importante lembrar que existe um histórico de longo prazo (preferências do usuário) e de curto prazo (intenção atual do usuário / sessão).
Sem mais delongas, usamos para criar canais word2vec nas seqüências de cliques nas sessões de pesquisa (uma sessão - um documento). Mas ainda fazemos algumas modificações (KDD, afinal):
- Tomamos a sessão durante a qual houve uma reserva.
- O que é reservado em última análise, é o contexto global de todos os elementos da sessão durante a atualização do w2v.
- Os negativos no treinamento são amostrados na mesma cidade.

A eficácia desse modelo é verificada de três maneiras padrão:
- Verifique offline: com que rapidez podemos elevar o hotel certo na sessão de pesquisa.
- Teste por avaliadores: construiu uma ferramenta especial para visualizar similares.
- Teste A / B: spoiler, a CTR aumentou significativamente, as reservas não aumentaram, mas agora elas acontecem mais cedo
Tentamos classificar os resultados dos resultados da pesquisa não apenas antecipadamente, mas também reorganizar (portanto, em tempo real) após o recebimento de uma resposta - um clique em uma frase e ignorar outra. A abordagem é coletar os locais clicados e ignorados em dois grupos, encontrar inserções em cada centróide (existe uma fórmula especial) e, em seguida, no ranking, aumentamos como cliques e diminuímos como pulos.
O teste A / B recebeu um aumento nas reservas, a abordagem resistiu ao teste do tempo: foi inventada há um ano e meio e ainda está girando na produção.
E se você precisar procurar em outra cidade? Você não poderá priorizar por cliques, não há informações sobre a atitude dos usuários em relação a lugares neste acordo. Para contornar esse problema, introduzimos "incorporações de conteúdo". Primeiro, criaremos um espaço simples e discreto de placas (barato / caro, no centro / nos arredores, etc.) do tamanho de cerca de 500 mil tipos (para lugares e pessoas). Em seguida, criamos casamentos por tipo. Ao aprender, não se esqueça de adicionar um negativo claro às recusas (quando o proprietário do local não confirmou a reserva).
Redes neurais convolucionais para sistemas de recomendação em escala da Web
Trabalhe no Pinterest com a recomendação de alfinetes. Consideramos os pinos do usuário do gráfico bipartido e adicionamos recursos de rede às recomendações. O gráfico é muito grande - 3 bilhões de pinos, 16 bilhões de interações; não foi possível criar incorporações clássicas de gráficos. ,
GraphSAGE , ( , message passing),
PinSAGE . , , .
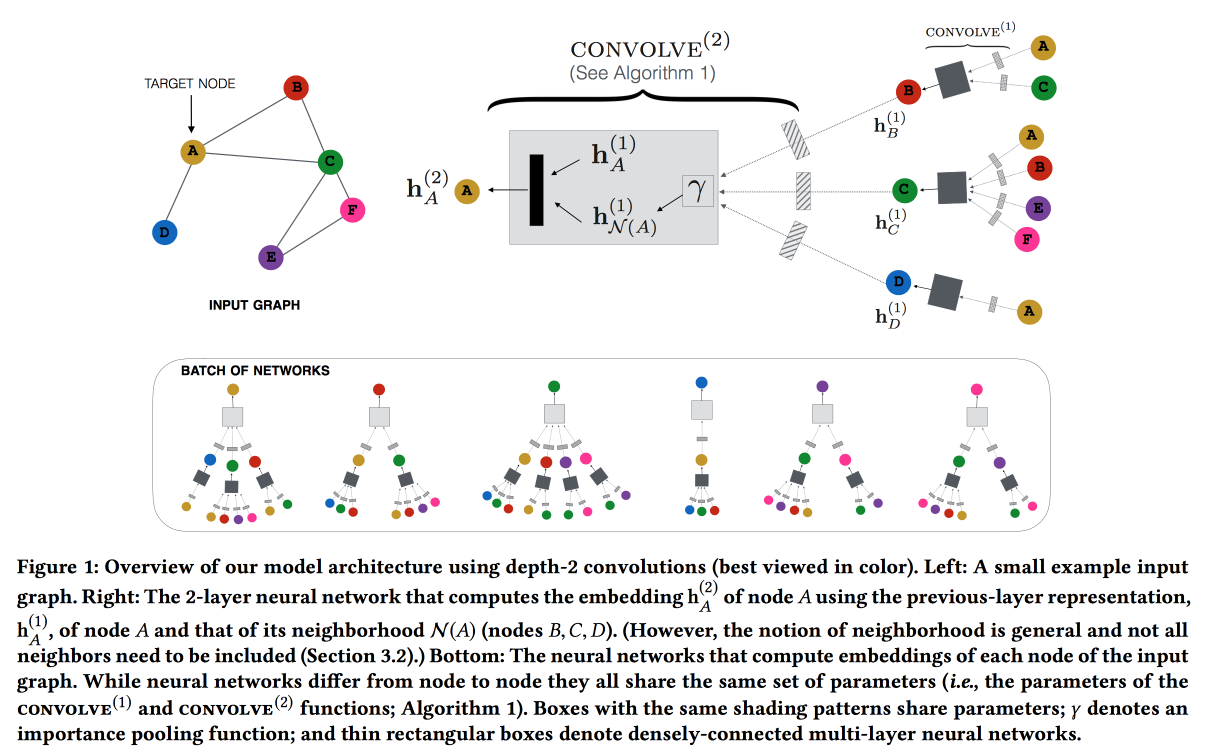
« »:
- max margin loss.
- CPU/GPU: CPU ( GPU ) GPU. , .
- , random walk-.
- Curriculum Learning: hard negative-. .
- Map reduce, .
, , . , /-.
Q&R: A Two-Stage Approach Toward Interactive Recommendation
« , , ?» — YouTube
. : « ?». «» (, , YouTube , ).
YouTube Video-RNN, ID . , ID , (post fusion). (- -
GRU , LSTM LSTM).

7 , 8-, . , 8 % , --. /-
interleaving- +0,7 % , +1,23 % .
: 18 % , +4 % .
Graph and social nets
, , , .
Graph Classification using Structural Attention
, « ». , , .
, , .
, LSTM , attention-, , . . , , , .
: , , . attention, , LSTM self-attention, ( ). «», , .
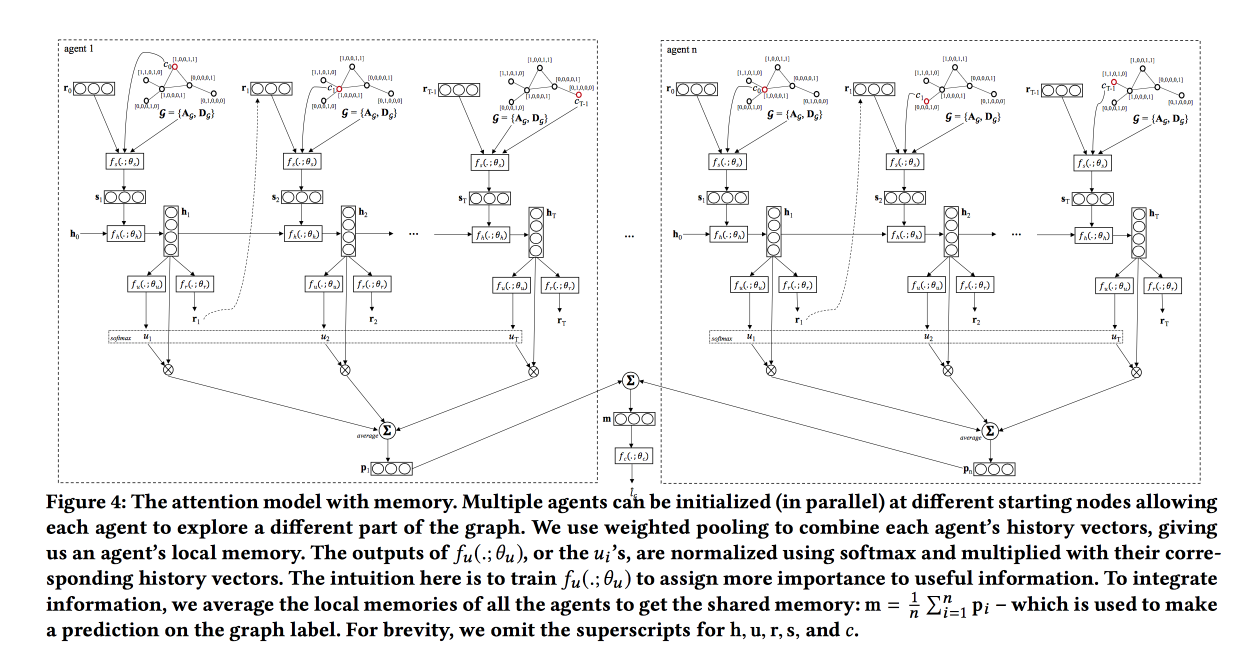
, baseline — . ,
TreeLSTM .
SpotLight: Detecting Anomalies in Streaming Graphs
, , -, , . « ». , , .
«» . - - , .
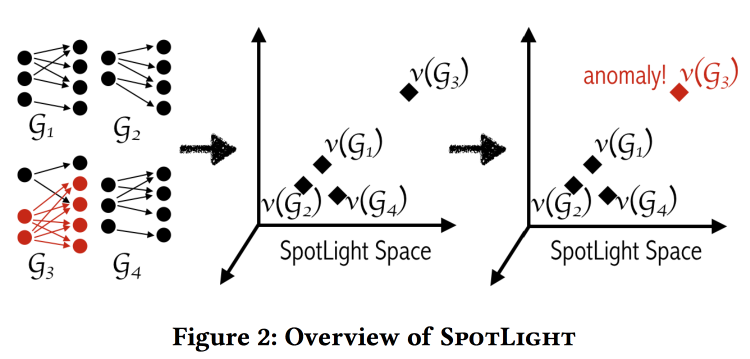
: , . . . , / .
, .
labeled DARPA dataset . , baseline- (.. ).
Adversarial Attacks on Graph Networks
. Adversary , , ..: / . , — ( — )? .
, :
- «» .
- «» .
- «» .
- , (poisoning).
. , , , — . . .
, unnoticeability: , ?
Multi-Round Influence maximization
. , , .
, ( , ).
-- :
- : , .
- : , .
- - : inffluencer- . , .
Reverse-Reachable sets: inffluencer-, , .
EvoGraph: An Effective and Efficient Graph Upscaling Method for Preserving Graph Properties
. ,
, .
, , power law. , , «» , : «» .

, , .
.
data science . De fato. , . .
All models are wrong, but some are useful — data science, , , . «» ( , , adversarial ..)
www.embo.org/news/articles/2015/the-numbers-speak-for-themselves — (overfitting, selection bias, , ..)
1762
The Equitable Life Assurance Society , .
Agora, as companhias de seguros têm dificuldade: em 2011, a discriminação com base no sexo foi finalmente proibida, agora o gênero não pode ser levado em consideração no seguro (o que é muito difícil - mesmo que você oculte explicitamente o recurso "gênero", é provável que o modelo o aproxime por outros motivos). Isso levou a um efeito interessante no Reino Unido:- As mulheres dirigem com mais precisão e têm menos probabilidade de sofrer acidentes, portanto, o seguro era mais barato para elas.
- Após o nivelamento, o custo do seguro para as mulheres aumentou e para os homens caiu.
- O mercado funciona: como resultado, há mais homens e menos mulheres nas ruas.
- Como a "precisão" média dos motoristas nas estradas diminuiu, houve mais acidentes.
- Depois disso, o seguro, é claro, começou a subir de preço.
- O seguro de viagem começou a acabar com os motoristas legais ainda mais.
Como resultado, eles obtiveram a "espiral da morte".
Este tema ecoa a apresentação de abertura do dia. F - Justiça, este é um castelo inatingível de nuvens. Os modelos de ML aprendem a separar exemplos (incluindo pessoas) no espaço de atributos; portanto, eles não podem ser "justos" por definição.