
Nos dias 18 e 19 de agosto, a Tele2 realizou um Hackathon de Ciência de Dados. Este hackathon se concentra na análise de diálogos de suporte técnico nas redes sociais, acelerando e simplificando as interações com os clientes.
A tarefa não tinha uma métrica específica que precisava ser otimizada; a tarefa pode ser inventada por você. O principal é melhorar o serviço. O júri da competição foi o diretor de várias áreas da Tele2, bem como Pavel Pleskov, o conhecido na comunidade de Data Science do Kaggle Grandmaster.
Sob o corte, a história da equipe que ficou em 1º lugar.
Quando um colega me convidou para participar deste hackathon, eu concordei rapidamente.
Eu estava interessado no tópico da PNL e também havia alguns desenvolvimentos de redes neurais que eu queria testar na prática.
Os organizadores do Hackathon enviaram pequenos fragmentos de conjuntos de dados com antecedência, que davam uma idéia de que tipo de dados estaria disponível no evento.
Os dados revelaram-se bastante sujos, trolls estranhos entraram nos diálogos, nem sempre era óbvio que tipo de pergunta o operador responde.
Ficou claro que não seria fácil implementar a idéia nas 24 horas previstas, então tirei 1 dia de folga do trabalho e gastei-o na preparação da rede neural que queria experimentar. Isso nos permitiu não perder tempo hackathon procurando por bugs, mas focar nos aplicativos e nos casos de negócios.
O escritório da Tele2 está localizado no território de Nova Moscou, no parque empresarial Rumyantsevo. Quanto a mim, chegar lá por um bom tempo, mas o parque de negócios causa uma boa impressão (com exceção das linhas de energia).
 Linhas de energia no contexto de um centro de negócios
Linhas de energia no contexto de um centro de negóciosBem na estação de metrô, os organizadores nos encontraram, nos mostraram como chegar ao escritório. O prédio do centro de negócios em si é ocupado por muitas empresas, o escritório da Tele2 está localizado no 5º andar. Os participantes da Hackathon receberam uma área especial dentro do escritório, havia uma cozinha, uma área de relaxamento com um PlayStation e otomanos. Particularmente satisfeito com a velocidade do wi-fi, não foram observados problemas inerentes a eventos de massa.
 Pequeno almoço
Pequeno almoçoO conjunto de dados real fornecido pelo Tele2 consistia em 3 arquivos CSV grandes com diálogos de suporte técnico: diálogos em redes sociais, telegrama e email. No total, são necessários mais de 4 milhões de acessos para treinar uma rede neural.
O que era uma rede neural?
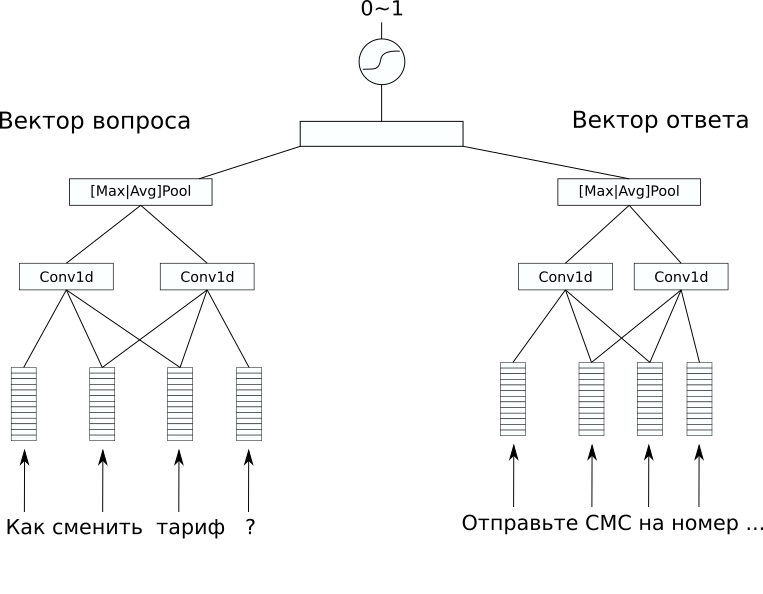 Arquitetura de rede
Arquitetura de redeNo conjunto de dados, não havia marcação adicional que seria interessante prever, mas eu queria resolver um problema supervisionado. Portanto, decidimos tentar prever respostas para as perguntas, para que pelo menos um bot de bate-papo simples desse modelo possa ser feito. Para isso, escolhemos a arquitetura CDSSM (Convolution Deep Semantic Similarity Model). Este é um dos modelos simples de rede neural para comparar textos por significado, originalmente proposto pela Microsoft para classificar os resultados da pesquisa do Bing.
Sua essência é a seguinte: primeiro, cada texto é convertido em um vetor usando uma sequência de camadas de convolução e pool.
Então os vetores resultantes são comparados de alguma maneira. Em nosso problema, uma camada linear adicional combinando ambos os vetores com um sigmóide como uma função de ativação deu um bom resultado. Os pesos da rede que codifica sentenças em vetores podem ser os mesmos para um par de textos (essas redes são chamadas siamesas) e podem diferir.
No nosso caso, a variante com pesos diferentes deu o melhor resultado, uma vez que os textos da pergunta e resposta foram significativamente diferentes.
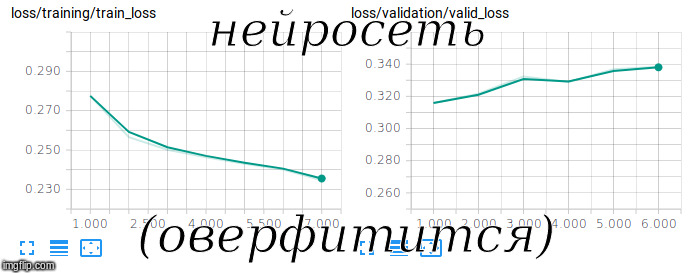 Tentando treinar uma rede siamesa
Tentando treinar uma rede siamesaO FastText com RusVectōs foi usado como
embeddings pré-treinados; é resistente a erros de digitação, frequentemente encontrados nas perguntas dos usuários.
Para treinar esse modelo, ele precisa ser treinado não apenas em exemplos positivos, mas também negativos. Para fazer isso, adicionamos pares aleatórios de perguntas e respostas em uma proporção de 1 a 10 para o conjunto de treinamento.
Para avaliar a qualidade dessa amostra desequilibrada, foi utilizada a métrica ROC-AUC. Após 3 horas de treinamento na GPU, conseguimos atingir um valor de 0,92 nesta métrica.
Usando esse modelo, é possível resolver não apenas o problema direto - escolher a resposta apropriada para a pergunta, mas também o oposto - para encontrar erros do operador, respostas de baixa qualidade e estranhas às perguntas do usuário.
Conseguimos encontrar algumas dessas respostas diretamente no hackathon e incluí-las na apresentação final. Parece-me que isso causou a maior impressão no júri.
Uma aplicação interessante também pode ser encontrada na representação vetorial de textos que a rede gera no processo de seu trabalho.
Usando-o, você pode procurar anomalias nas perguntas e respostas por
vários métodos não supervisionados .
Como resultado, nossa decisão foi bem tomada, tanto do ponto de vista técnico quanto do ponto de vista comercial. O restante das equipes, basicamente, tentou resolver o problema da análise de chave e da modelagem temática; portanto, nossa solução diferia favoravelmente. Como resultado, conquistamos o 1º lugar, nos separamos satisfeitos e cansados.
 Na foto (da esquerda para a direita): Alexander Abramov, Konstanin Ivanov, Andrey Vasnetsov (autor) e Shvetsov Egor
Na foto (da esquerda para a direita): Alexander Abramov, Konstanin Ivanov, Andrey Vasnetsov (autor) e Shvetsov EgorO que mais se pode ler: