
Muitas pessoas que estudam o aprendizado de máquina estão familiarizadas com o projeto OpenAI, um dos fundadores, Elon Musk, e usam a plataforma
OpenAI Gym para treinar seus modelos de redes neurais.
O ginásio contém um enorme conjunto de ambientes, alguns deles são vários tipos de simulações físicas: os movimentos de animais, humanos,
robôs . Essas simulações são baseadas no
mecanismo de física
MuJoCo , gratuito para fins educacionais e científicos.
Neste artigo, criaremos uma simulação física extremamente simples, semelhante ao ambiente OpenAI Gym, mas baseada no mecanismo de física livre Bullet (
PyBullet ). E também crie um agente para trabalhar com esse ambiente.
PyBullet é um módulo python para criar um ambiente de simulação física baseado no mecanismo de física
Bullet Physics . Como MuJoCo, é frequentemente usado como estímulo de vários robôs, que estão interessados em habr. Existe
um artigo com exemplos reais.
Existe um
QuickStartGuide bastante bom para PyBullet que contém links para exemplos na página de origem no
GitHub .
PyBullet permite carregar modelos já criados no formato URDF, SDF ou MJCF. Nas fontes, existe uma biblioteca de
modelos nesses formatos, bem como ambientes completamente prontos para uso de simuladores de
robôs reais.No nosso caso, nós mesmos criaremos o ambiente usando PyBullet. A interface do ambiente será
semelhante à interface do OpenAI Gym. Dessa forma, podemos treinar nossos agentes tanto em nosso ambiente quanto no ambiente da academia.
Todo o código (iPython), bem como a operação do programa, podem ser vistos no
Google Colaboratory .
Meio ambiente
Nosso ambiente consistirá em uma bola que pode se mover ao longo do eixo vertical dentro de um certo intervalo de alturas. A bola tem massa e a gravidade atua sobre ela, e o agente deve, controlando a força vertical aplicada à bola, trazê-la ao alvo. A altitude alvo muda a cada reinício da experiência.

A simulação é muito simples e, de fato, pode ser considerada como uma simulação de algum mecanismo elementar.
Para trabalhar com o ambiente, são utilizados três métodos:
redefinir (reiniciar o experimento e criar todos os objetos do ambiente),
etapa (aplicar a ação selecionada e obter o estado resultante do ambiente),
render (exibição visual do ambiente).
Ao inicializar o ambiente, é necessário conectar nosso objeto à simulação física. Existem 2 opções de conexão: com uma interface gráfica (GUI) e sem (DIRECT), que, no nosso caso, é DIRECT.
pb.connect(pb.DIRECT)
redefinir
A cada nova experiência, redefinimos a simulação
pb.resetSimulation () e criamos todos os objetos do ambiente novamente.
No PyBullet, os objetos têm duas formas: uma
forma de colisão e uma
forma visual . O primeiro é usado pelo mecanismo físico para calcular colisões de objetos e, para acelerar o cálculo da física, geralmente tem uma forma mais simples que um objeto real. O segundo é opcional e é usado apenas ao formar a imagem do objeto.
Os formulários são coletados em um único objeto (corpo) -
MultiBody . Um corpo pode ser composto de uma forma (par
CollisionShape / Visual Shape ), como no nosso caso, ou várias.
Além das formas que compõem o corpo, é necessário determinar sua massa, posição e orientação no espaço.
Algumas palavras sobre corpos com vários objetos.Por via de regra, em casos reais, para simular vários mecanismos, são utilizados corpos constituídos por várias formas. Ao criar o corpo, além da forma básica de colisões e visualização, o corpo é transferido para cadeias de formas de objetos filhos (
Links ), sua posição e orientação em relação ao objeto anterior, bem como os tipos de conexões (juntas) de objetos entre si (
Articulação ). Os tipos de conexões podem ser fixos, prismáticos (deslizando no mesmo eixo) ou rotacionais (girando em um eixo). Os dois últimos tipos de conexões permitem definir os parâmetros dos tipos correspondentes de motores (
JointMotor ), como força de atuação, velocidade ou torque, simulando assim os motores das "juntas" do robô. Mais detalhes na
documentação .
Vamos criar 3 corpos: bola, avião (terra) e ponteiro alvo. O último objeto terá apenas uma forma de visualização e massa zero, portanto, não participará da interação física entre os corpos:
Defina a gravidade e o tempo da etapa de simulação.
pb.setGravity(0,0,-10) pb.setTimeStep(1./60)
Para evitar que a bola caia imediatamente após o início da simulação, equilibramos a gravidade.
pb_force = 10 * PB_BallMass pb.applyExternalForce(pb_ballId, -1, [0,0,pb_force], [0,0,0], pb.LINK_FRAME)
passo
O agente seleciona ações com base no estado atual do ambiente, após o qual chama o método
step e recebe um novo estado.
São definidos 2 tipos de ação: aumento e diminuição da força que atua na bola. Os limites de força são limitados.
Após alterar a força que atua na bola, uma nova etapa da simulação física
pb.stepSimulation () é iniciada e os seguintes parâmetros são retornados ao agente:
observação - observações (estado do ambiente)
recompensa - recompensa pela ação perfeita
done - a bandeira do fim da experiência
info - informações adicionais
Como o estado do ambiente, são retornados 3 valores: a distância do alvo, a força atual aplicada à bola e a velocidade da bola. Os valores são retornados normalizados (0..1), pois os parâmetros ambientais que determinam esses valores podem variar dependendo do nosso desejo.
A recompensa pela ação perfeita é 1 se a bola estiver próxima do alvo (altura do alvo mais / menos o valor aceitável de rolamento
TARGET_DELTA ) e 0 em outros casos.
O experimento é concluído se a bola sair da zona (cair no chão ou voar alto). Se a bola atingir a meta, o experimento também termina, mas somente após um certo tempo (
STEPS_AFTER_TARGET etapas do experimento). Assim, nosso agente é treinado não apenas para avançar em direção à meta, mas também para parar e se aproximar dela. Dado que a recompensa quando você está perto da meta é 1, uma experiência totalmente bem-sucedida deve ter uma recompensa total igual a
STEPS_AFTER_TARGET .
Como informações adicionais para a exibição de estatísticas, o número total de etapas executadas no experimento, bem como o número de etapas executadas por segundo, é retornado.
render
O PyBullet possui 2 opções de renderização de imagem - renderização GPU baseada em OpenGL e CPU baseada em TinyRenderer. No nosso caso, apenas uma implementação de CPU é possível.
Para obter o quadro atual da simulação, é necessário determinar a
matriz de espécies e a
matriz de projeção e obter a imagem
rgb do tamanho especificado na câmera.
camTargetPos = [0,0,5]
No final de cada experiência, um vídeo é gerado com base nas imagens coletadas.
ani = animation.ArtistAnimation(plt.gcf(), render_imgs, interval=10, blit=True,repeat_delay=1000) display(HTML(ani.to_html5_video()))
Agente
O código de usuário do GitHub
jaara foi tomado como base para o Agent, como um exemplo simples e compreensível de implementação de treinamento de reforço para o ambiente da academia.
O agente contém 2 objetos:
Memória - um armazenamento para a formação de exemplos de treinamento e o
próprio cérebro é a rede neural que ele treina.
A rede neural treinada foi criada no TensorFlow usando a biblioteca Keras, que recentemente foi totalmente
incluída no TensorFlow.
A rede neural tem uma estrutura simples - 3 camadas, ou seja, Apenas 1 camada oculta.
A primeira camada contém 512 neurônios e possui um número de entradas igual ao número de parâmetros do estado do meio (3 parâmetros: distância ao alvo, força e velocidade da bola). A camada oculta tem uma dimensão igual à primeira camada - 512 neurônios, na saída está conectada à camada de saída. O número de neurônios da camada de saída corresponde ao número de ações executadas pelo agente (2 ações: diminuir e aumentar a força de atuação).
Assim, o estado do sistema é fornecido à entrada da rede e, na saída, temos um benefício para cada uma das ações.
Para as duas primeiras camadas,
ReLU (unidade linear retificada) é usada como função de ativação; para a última - uma
função linear (a soma dos valores de entrada é simples).
Em função do erro,
MSE (erro padrão), como algoritmo de otimização -
RMSprop (Propagação do Quadrado Médio Raiz).
model = Sequential() model.add(Dense(units=512, activation='relu', input_dim=3)) model.add(Dense(units=512, activation='relu')) model.add(Dense(units=2, activation='linear')) opt = RMSprop(lr=0.00025) model.compile(loss='mse', optimizer=opt)
Após cada etapa da simulação, o Agente salva os resultados dessa etapa na forma de uma lista
(s, a, r, s_) :
s - observação anterior (estado do ambiente)
a - ação concluída
r - recompensa recebida pela ação executada
s_ - observação final após a ação
Depois disso, o Agente recebe da memória um conjunto aleatório de exemplos para períodos anteriores e forma um pacote de treinamento (
lote ).
Os estados iniciais das etapas aleatórias selecionadas na memória são tomados como valores de entrada (
X ) do pacote.
Os valores reais da saída de aprendizado (
Y ' ) são calculados da seguinte forma: Na saída (
Y ) da rede neural para s, haverá valores da
função Q para cada uma das ações
Q (s) . Nesse conjunto, o agente selecionou a ação com o valor mais alto
Q (s, a) = MAX (Q (s)) , concluiu e recebeu o prêmio
r . O novo valor
Q para a ação selecionada
a será
Q (s, a) = Q (s, a) + DF * r , onde
DF é o fator de desconto. Os valores de saída restantes permanecerão os mesmos.
STATE_CNT = 3 ACTION_CNT = 2 batchLen = 32
O treinamento em rede ocorre no pacote formado
self.model.fit(x, y, batch_size=32, epochs=1, verbose=0)
Após a conclusão da experiência, um vídeo é gerado
e estatísticas são exibidas
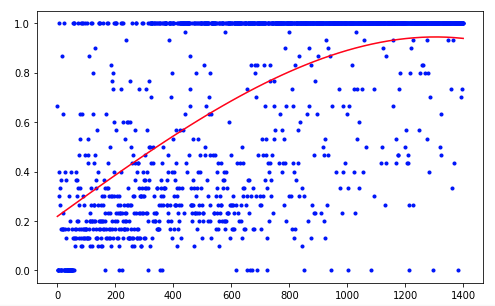
O agente precisou de 1.200 ensaios para alcançar um resultado de cerca de 95% (número de etapas bem-sucedidas). E no 50º experimento, o Agente havia aprendido a mover a bola para o alvo (experimentos malsucedidos desaparecem).
Para melhorar os resultados, você pode tentar alterar o tamanho das camadas da rede (LAYER_SIZE), o parâmetro do fator de desconto (GAMMA) ou a taxa de redução na probabilidade de escolher uma ação aleatória (LAMBDA).
Nosso agente possui a arquitetura mais simples - DQN (Deep Q-Network). Em uma tarefa tão simples, basta obter um resultado aceitável.
Usando, por exemplo, a arquitetura DDQN (Double DQN) deve fornecer um treinamento mais suave e preciso. E a rede RDQN (DQN recorrente) poderá rastrear os padrões de mudança ambiental ao longo do tempo, o que tornará possível se livrar do parâmetro de velocidade da bola, reduzindo o número de parâmetros de entrada da rede.
Você também pode expandir nossa simulação adicionando uma massa variável da bola ou o ângulo de inclinação do seu movimento.
Mas esta é a próxima vez.