Há um ano, adicionamos ao nosso agente uma coleção de métricas dos atributos do disco SMART nos servidores clientes. Nesse momento, não os adicionamos à interface e os mostramos aos clientes. O fato é que não utilizamos métricas através do smartctl, mas extraímos o ioctl diretamente do código para que essa funcionalidade funcione sem a instalação de smartmontools nos servidores clientes.
O agente não remove todos os atributos disponíveis, mas apenas os mais significativos em nossa opinião e os menos específicos do fornecedor (caso contrário, você teria que manter uma base de disco semelhante aos smartmontools).
Agora, as mãos finalmente chegaram ao ponto de verificar o que filmamos lá. E foi decidido começar com o atributo "indicador de desgaste de mídia", que mostra a porcentagem do recurso de gravação SSD restante. Abaixo, algumas histórias em fotos sobre como esse recurso é gasto na vida real em servidores.
Existem SSDs mortos?
Acredita-se que novos e mais produtivos ssds sejam lançados com mais freqüência do que os antigos conseguem ser mortos. Portanto, a primeira coisa que foi interessante foi ver os mais mortos em termos de disco de recursos de gravação. O valor mínimo para todo o ssd de todos os clientes é de 1%.
Nós escrevemos imediatamente para o cliente sobre isso, que acabou sendo um Dedik na hetzner. O suporte de hospedagem substituiu imediatamente o ssd:

Seria muito interessante ver como a situação parece do ponto de vista do sistema operacional quando o ssd parar de atender a um registro (agora estamos procurando a oportunidade de zombar deliberadamente do ssd para examinar as métricas desse cenário :)
Qual a rapidez com que os SSDs são mortos?
Desde que começamos a coletar métricas há um ano, e não estamos excluindo métricas, é possível analisar essa métrica a tempo. Infelizmente, o servidor com a maior taxa de fluxo foi conectado ao okmeter apenas 2 meses atrás.

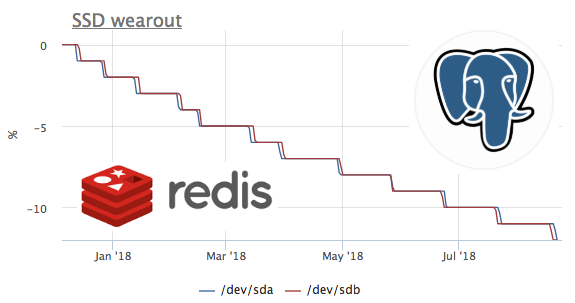
Neste gráfico, vemos como em 2 meses eles queimaram 8% do recurso de gravação. Ou seja, com o mesmo perfil de gravação, esses ssd serão suficientes para 100 / (8/2) = 25 meses. Não sei muito ou pouco, mas vamos ver que tipo de carga existe?

Vemos que apenas o ceph funciona com o disco, mas entendemos que o ceph é apenas uma camada. Nesse caso, o cliente ceph atua como um repositório para o cluster kubernetes em vários nós, vamos ver o que dentro do k8s gera mais gravações de disco:

Os valores absolutos não coincidem muito provavelmente devido ao fato de o ceph estar funcionando no cluster e o registro de redis estar aumentando devido à replicação de dados. Mas o perfil de carregamento permite que você diga com confiança que o registro inicia exatamente o redis. Vamos ver o que acontece no rabanete:

aqui você pode ver que, em média, menos de 100 solicitações por segundo são executadas, o que pode alterar os dados. Lembre-se de que o redis possui 2 maneiras de gravar dados no disco :
- RDB - instantâneos periódicos de todo o banco de dados em disco, ao iniciar o redis, lemos o último despejo na memória e perdemos dados entre os despejos
- AOF - escrevemos um log de todas as alterações, no início o redis perde esse log e todos os dados aparecem na memória, perdemos apenas dados entre fsync desse log
Como todo mundo provavelmente já adivinhou nesse caso, o RDB é usado com uma frequência de despejo de 1 minuto:

SSD + RAID
De acordo com nossas observações, existem três configurações principais do subsistema de disco de servidores com a presença de SSDs:
- no servidor 2 SSDs coletados no RAID-1 e tudo mora lá
- o servidor possui HDD + raid-10 do ssd, geralmente é usado para RDBMSs clássicos (sistema, WAL e parte dos dados no disco rígido e no SSD os dados mais quentes em termos de leitura)
- o servidor possui um SSD independente (JBOD), geralmente usado para cassandra do tipo nosql
Se o ssd for coletado no RAID-1, a gravação vai para os dois discos, portanto, o desgaste ocorre na mesma velocidade:
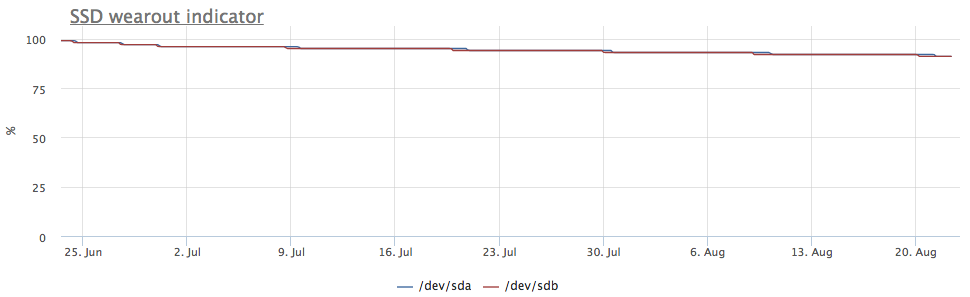
Mas o servidor chamou minha atenção, na qual a imagem é diferente:

Nesse caso, apenas as partições mdraid são montadas (todas as matrizes RAID-1):

As métricas de gravação também mostram que há mais entradas em / dev / sda:

Aconteceu que uma das partições em / dev / sda é usada como swap, e a E / S de troca neste servidor é bastante perceptível:

Depreciação de SSD e PostgreSQL
Na verdade, eu queria ver a taxa de desgaste do ssd em várias cargas de gravação no Postgres, mas, como regra, eles são usados com muito cuidado em bancos de dados ssd carregados e gravações massivas vão para o HDD. Ao procurar um caso adequado, deparei-me com um servidor muito interessante:

O desgaste de dois ssd no raid-1 por 3 meses foi de 4%, mas, a julgar pela velocidade de gravação do WAL, este postgres grava menos de 100 Kb / s:
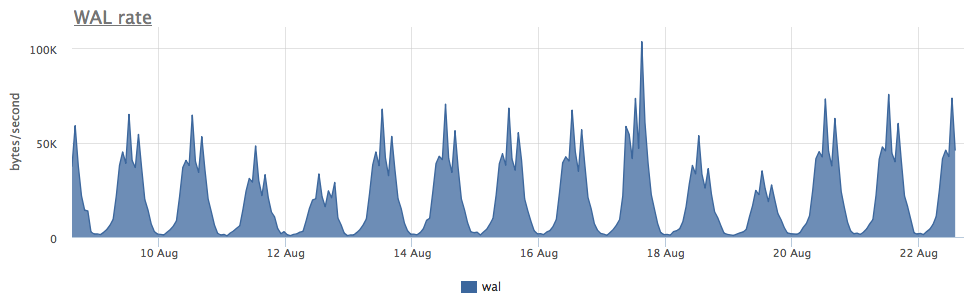
Descobriu-se que o postgres usa ativamente arquivos temporários, trabalhando com os quais cria um fluxo constante de gravação no disco:

Como o postgresql com diagnóstico é muito bom, podemos, até a solicitação, descobrir exatamente o que precisamos corrigir:

Como você pode ver aqui, esse SELECT em particular gera um monte de arquivos temporários. Em geral, no SELECT postgres, às vezes eles geram um registro sem nenhum arquivo temporário - aqui já falamos sobre isso.
Total
- A quantidade de gravação em disco criada pelo Redis + RDB não depende do número de modificações no banco de dados, mas do tamanho do intervalo do banco de dados + dump (e, em geral, este é o nível mais alto de amplificação de gravação nos data warehouses conhecidos por mim)
- A troca ativamente usada no ssd é ruim, mas se você precisar adicionar jitter ao desgaste do ssd (para confiabilidade do RAID-1), pode ser uma opção :)
- Além do WAL e dos arquivos de dados, os bancos de dados ainda podem gravar todos os tipos de dados temporários no disco.
Em okmeter.io, acreditamos que, para chegar ao ponto mais baixo da causa do problema, o engenheiro precisa de muitas métricas sobre todas as camadas da infraestrutura. Estamos fazendo o nosso melhor para ajudar :)