
Temos duas abordagens para a recuperação de falhas: um cluster "estendido" (instalação ativo-ativo) e uma plataforma com máquinas virtuais (réplicas) desativadas. Eles têm vários pontos para salvar instantâneos.
Há um pedido de tolerância a desastres e muitos de nossos clientes realmente precisam. Portanto, começamos a elaborar os dois esquemas como parte de nossa produção.
Os métodos têm prós e contras, agora vou falar sobre eles.
Cluster Esticado
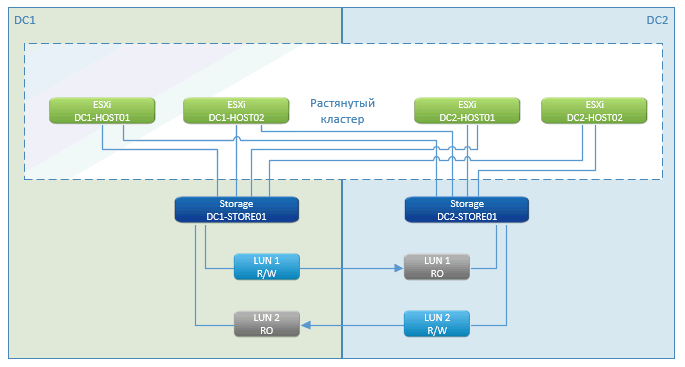
Como você pode ver, esta é uma história padrão do cluster de metrô. Nos profissionais - quase zero tempo de inatividade, uma pausa apenas no momento de iniciar as máquinas virtuais. Esse recurso funciona - VMware High Availability (HA). Ela vê que os hosts estão perdidos e reinicia imediatamente a VM no site remoto.
O lançamento é feito imediatamente a partir do armazenamento, localizado no cluster.
O armazenamento com um cluster distribuído geograficamente é um recurso de marketing da NetApp. Outros fabricantes têm algo com um nome semelhante. Em essência, essa é uma replicação assíncrona pensada de um lado para o outro. Escrevemos para um nó na rede local e sincronizamos através de canais de comunicação especializados com outro.
No caso de uma falha de um dos sistemas de armazenamento, o restante (em outro site) apresenta o caminho dos discos para os hosts restantes. VMs que morreram são reiniciadas nelas. Tudo acontece automaticamente - o data center travou, tudo reiniciou, o armazenamento funcionou, o VMware funcionou. O cliente viu que tudo piscou e reiniciou.
O único cache da RAM da VM pode ser perdido. Mas se o banco de dados jogou fora, a perda é zero no tempo.
Se perdermos a comunicação entre os sites, tudo continuará funcionando em seu lugar e, assim que a conexão for restaurada, ela começará a ser sincronizada.
A desvantagem é o preço alto. Porque você realmente precisa de um SHD duplo (além disso, semelhante em tipo, velocidade e volume de discos do primeiro SHD no site principal), que não pode ser usado de alguma forma, exceto como reserva. Além de ligação ao armazenamento para o cluster metropolitano, são pontes FC, rede FC e muito mais.
Temos dois DPCs, entre eles um pacote FC ao longo de dois feixes (quatro linhas ópticas escuras e DWDM). Esses são dois pedaços de ferro, cada um com 200 Gbps de largura de banda para FC e Ethernet.
Alternativa com DR

Há software com um nome intuitivamente memorável - VMware vCloud Availability para DR de nuvem para nuvem.
Este é um sistema para criar uma VM idêntica em um site remoto uma vez, relativamente falando, em 15 minutos. Um sistema para apresentar tudo isso da maneira correta aos mecanismos de controle da nuvem é anexado a ele em fita isolante.
Ou seja, a tecnologia VMware Replication está no back-end. No caso de uma falha, lançamos manualmente o plano de recuperação de desastres no segundo site, ele para de tentar replicar automaticamente, registra a VM no vCloud Director, personaliza os endereços IP (para que não precise ser alterado para a VM) e inicia a VM na ordem necessária. Em nossa solução, não é necessário alterar o endereçamento, estendemos as redes para os dois data centers.
As máquinas estão sendo replicadas constantemente, mas não o data center inteiro, mas apenas os selecionados são processos críticos. Ele é replicado de vez em quando, o intervalo mínimo é de 15 minutos (esse é o caso ideal quando tudo voa e há um servidor de replicação dedicado e um mínimo de alterações na VM). Na prática, você tem uma cópia meia hora ou uma hora atrás. Se algo desse errado, os dados que caíam no intervalo eram perdidos. 15 minutos é a questão do agente que coleta a nova replicação. A Veeam diz que eles podem levar menos de 15 minutos, mas na verdade também é mais demorado se eles não usarem recursos de armazenamento. Eu não vi em uma máquina industrial (não em um teste) que seria o contrário.
Por um longo tempo, a NetApp, como muitos outros fabricantes de sistemas de armazenamento, possui a tecnologia SnapMirror, que permite mudar o trabalho de replicação de hipervisores para sistemas de armazenamento, e o VMware Replication pode usá-lo.
À medida que o serviço de replicação é executado, o trem vai longe. Mas é barato.
Por que ainda é barato - como você pode usar qualquer armazenamento de qualquer lado (de diferentes fabricantes, classes diferentes), não é necessário alocar um grande volume de discos com antecedência.
Não há necessidade de alocar um grande grupo de discos, dentro do qual as luas são cortadas. Ele apenas ocupa um lugar no armazenamento local e é aplicado com base na disponibilidade do registro da máquina virtual. Por esse motivo, o local no sistema de armazenamento é otimamente ocupado, se usado para outras tarefas. E é usado, pois não prestamos esse serviço a todos os clientes.
Menos - você precisa configurar a replicação no nível da VM, ou seja, controlar se tudo está configurado corretamente, que esta é a máquina, garantir que a replicação seja aprovada, que não haja erros. Crie planos de DR para cada cliente, realize seus testes.
No primeiro caso, o armazenamento é realizado, condicionalmente, infraestruturalmente, quase por setores (mais precisamente, por objetos). E então uma máquina pode cair devido a uma tarefa que cai devido a alguns motivos de software relacionados a um bug em níveis altos ou devido a problemas de acessibilidade. Isso acontece um pouco mais frequentemente do que se você tomar apenas níveis baixos.
No plus - DR armazena vários pontos. Você pode reverter alguns instantâneos.
Fora do sistema operacional convidado, você precisa de software adicional.
Para obter todas as redes necessárias para o Vcloud Director, precisamos do trabalho de nosso administrador. Em geral, toda a conectividade de rede nesta versão permanece com nosso administrador. Para um cliente de nuvem, isso significa um aplicativo, que também leva tempo.
A replicação também é configurada através do aplicativo. VM adicionada - você precisa enviar uma solicitação para replicá-la. Não se enquadra nas tarefas de replicação automaticamente. É necessário prestar atenção ao administrador.
A diferença
Como resultado, o preço pode diferir em mais de duas vezes. A replicação multiplicará o custo do espaço em disco por duas ou mais (duas cópias completas + histórico de alterações), além de algo para o serviço e a reserva de recursos de computação. No caso do cluster metropolitano, o custo do espaço será multiplicado por dois, mas o espaço em si custará significativamente mais, além de você precisar reservar firmemente os nós em um site remoto. Ou seja, os recursos de computação devem ser multiplicados por dois, não podemos utilizá-los para mais nada.
No caso do cluster metro, podemos usar apenas os mesmos tipos de discos para que haja um espelho completo. Se no data center principal, algumas das unidades são rápidas, outras lentas, com 10 mil rotações por minuto, é necessária uma configuração idêntica. No caso de uma réplica, são possíveis discos mais lentos no site de backup, o que é mais barato devido ao armazenamento. Mas ao mudar para uma reserva, o desempenho será menor. Ou seja, se ele armazena algo no SSD no cluster principal e é replicado para discos regulares, o armazenamento fica muito mais barato com o custo de diminuir a infraestrutura de reserva.
No momento, estamos escolhendo o que será incluído em uma versão anterior, portanto, queremos consultar: você pode nos dizer brevemente como você organiza seus sites de recuperação de desastres e o que você gostaria que eles fizessem em geral?