
Consegui coletar minha estação de trabalho como estudante. Logicamente, eu preferia as soluções de computação AMD. porque barato rentável em termos de preço / qualidade. Peguei os componentes por um longo tempo, no final, entrei com 40k com um conjunto de FX-8320 e RX-460 2GB. No começo, este kit parecia perfeito! Meu colega de quarto e eu extraímos Monero um pouco e meu set mostrou 650h / s contra 550h / s em um conjunto de i5-85xx e Nvidia 1050Ti. É verdade que do meu aparelho na sala estava um pouco quente à noite, mas isso foi decidido quando comprei um refrigerador de torre para a CPU.
A história acabou
Tudo era como em um conto de fadas exatamente até que me interessei pelo aprendizado de máquina no campo da visão computacional. Ainda mais precisamente - até que eu tive que trabalhar com imagens de entrada com uma resolução superior a 100x100px (até esse momento, meu FX de 8 núcleos lidava rapidamente). A primeira dificuldade foi a tarefa de determinar emoções. 4 camadas ResNet, insira imagens 100x100 e 3000 no conjunto de treinamento. E agora - 9 horas de treinamento 150 eras na CPU.
Obviamente, devido a esse atraso, o processo de desenvolvimento iterativo sofre. No trabalho, tínhamos a Nvidia 1060 6GB e treinando para uma estrutura semelhante (embora a regressão tenha sido treinada lá para localizar objetos), ela voou em 15 a 20 minutos - 8 segundos para uma era de 3,5 mil imagens. Quando você tem esse contraste embaixo do nariz, a respiração fica ainda mais difícil.
Bem, adivinha o meu primeiro passo depois de tudo isso? Sim, fui negociar 1050Ti com meu vizinho. Com argumentos sobre a inutilidade da CUDA para ele, com uma oferta para trocar meu cartão por um custo extra. Mas tudo em vão. E agora estou postando meu RX 460 no Avito e revendo o aclamado 1050Ti nos sites da Citylink e TechnoPoint. Mesmo no caso de uma venda bem-sucedida do cartão, eu precisaria encontrar outros 10 mil (eu sou um estudante, embora esteja trabalhando).
Google
Ok Vou ao google como usar o Radeon no Tensorflow. Sabendo que essa era uma tarefa exótica, não esperava encontrar nada sensato. Colete no Ubuntu, seja ele inicializado ou não, pegue frases com frases dos fóruns.
E então segui o outro caminho - não pesquisei no Tensorflow AMD Radeon, mas no Keras AMD Radeon. Ele instantaneamente me lança na página do PlaidML . Inicio em 15 minutos (embora eu tenha que fazer o downgrade do Keras para 2.0.5) e configurei a rede para aprender. A primeira observação - a era é de 35 segundos em vez de 200.
Suba para explorar
Os autores do PlaidML são vertex.ai , que faz parte do grupo de projetos da Intel (!). O objetivo de desenvolvimento é o máximo entre plataformas. Obviamente, isso adiciona confiança ao produto. O artigo deles diz que o PlaidML é competitivo com o Tensorflow 1.3 + cuDNN 6 devido à "otimização completa".
No entanto, continuamos. O artigo a seguir, em certa medida, nos revela a estrutura interna da biblioteca. A principal diferença de todas as outras estruturas é a geração automática de núcleos de cálculo (na notação Tensorflow, o "núcleo" é o processo completo de executar uma certa operação em um gráfico). Para a geração automática de kernel no PlaidML, as dimensões exatas de todos os tensores, constantes, etapas, tamanhos de convolução e valores de limite com os quais você precisará trabalhar mais tarde são muito importantes. Por exemplo, argumenta-se que a criação adicional de núcleos efetivos difere para 1 e 32 em lotes ou para convoluções dos tamanhos 3x3 e 7x7. Com esses dados, a própria estrutura gerará a maneira mais eficiente de paralelizar e executar todas as operações para um dispositivo específico com características específicas. Se você observar o Tensorflow, ao criar novas operações, também precisamos implementar o kernel para elas - e as implementações são muito diferentes para kernels de thread único, multi-thread ou compatíveis com CUDA. I.e. O PlaidML é claramente mais flexível.
Nós vamos além. A implementação é escrita no bloco de linguagem auto-escrita. Essa linguagem tem as seguintes vantagens principais - a proximidade da sintaxe com as notações matemáticas (mas enlouqueça!):
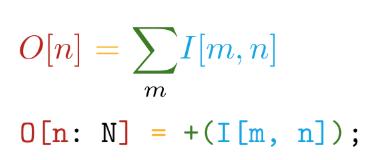
E diferenciação automática de todas as operações declaradas. Por exemplo, no TensorFlow, ao criar uma nova operação personalizada, é altamente recomendável que você escreva uma função para calcular os gradientes. Assim, ao criar nossas próprias operações na linguagem Tile, precisamos apenas dizer O QUE queremos calcular sem pensar em COMO considerar isso em relação aos dispositivos de hardware.
Além disso, é realizada a otimização do trabalho com DRAM e um análogo do cache L1 na GPU. Lembre-se do dispositivo esquemático:
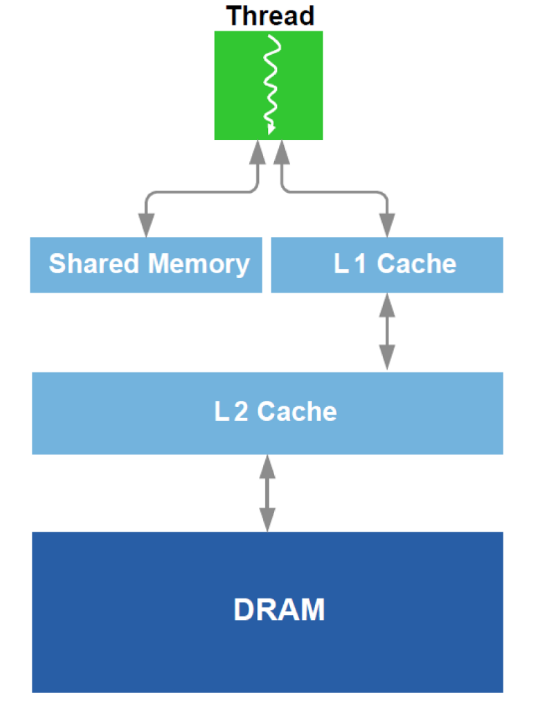
Para otimização, todos os dados disponíveis sobre o equipamento são usados - tamanho do cache, largura da linha de cache, largura de banda da DRAM, etc. Os métodos principais são fornecer leitura simultânea de blocos grandes o suficiente da DRAM (uma tentativa de evitar o endereçamento para áreas diferentes) e conseguir que os dados carregados no cache sejam usados várias vezes (uma tentativa de evitar recarregar os mesmos dados várias vezes).
Todas as otimizações ocorrem durante a primeira era do treinamento, enquanto aumentam bastante o tempo da primeira execução:
Além disso, vale ressaltar que essa estrutura está vinculada ao OpenCL . A principal vantagem do OpenCL é que ele é um padrão para sistemas heterogêneos e nada impede que você execute o kernel na CPU . Sim, é aqui que reside um dos principais segredos do PlaidML de plataforma cruzada.
Conclusão
Obviamente, o treinamento no RX 460 ainda é 5-6 vezes mais lento que no 1060, mas você pode comparar as categorias de preço das placas de vídeo! Então eu recebi um RX 580 8gb (eles me emprestaram!) E o tempo que levou para correr a era foi reduzido para 20 segundos, o que é quase comparável.
O blog vertex.ai possui gráficos honestos (mais é melhor):
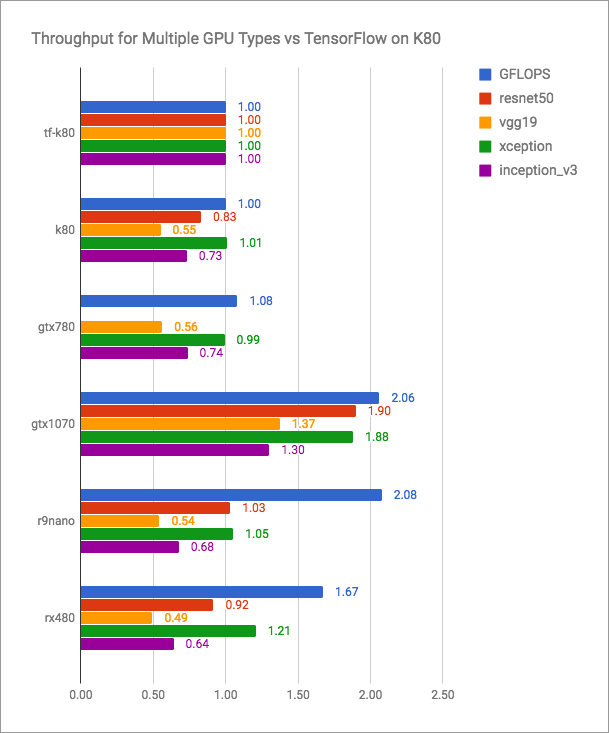
Pode-se observar que o PlaidML é competitivo com o Tensorflow + CUDA, mas certamente não é mais rápido nas versões atuais. Mas os desenvolvedores do PlaidML provavelmente não planejam entrar em uma batalha tão aberta. Seu objetivo é universalidade, multiplataforma.
Deixarei aqui uma tabela não comparativa com minhas medidas de desempenho:
| Dispositivo de computação | Tempo de execução da época (lote - 16), s |
|---|
| AMD FX-8320 tf | 200 |
| RX 460 2GB xadrez | 35 |
| RX 580 8 GB xadrez | 20 |
| 1060 6GB TF | 8 |
| 1060 6GB plaid | 10 |
| Intel i7-2600 tf | 185 |
| Intel i7-2600 plaid | 240 |
| GT 640 plaid | 46. |
A publicação mais recente do blog vertex.ai e as edições mais recentes do repositório estão datadas de maio de 2018. Parece que se os desenvolvedores dessa ferramenta não pararem de lançar novas versões e mais e mais pessoas ofendidas pela Nvidia estiverem familiarizadas com o PlaidML, elas falarão sobre o vertex.ai com muito mais frequência.
Descubra seus radeons!